上一篇《cfs调度类深入解刨------irq科普篇》中讲述了kernel中的irq的工作原理及上半部和下半部的分工。
本篇文章讲述CFS调度器的EAS特性具体作用及原理。
EAS
EAS(Energy Aware Scheduling,能量感知调度) 是Linux内核针对非对称多核拓扑架构(如ARM的big.LITTLE大小核、DynamIQ结构)开发的一种CFS调度器扩展特性。
它的核心使命是:在智能手机等对续航和发热极其敏感的移动设备中,改变传统CFS"只看性能、盲目堆高负载"的粗暴作风,转而通过预测每个调度决策对电量消耗的影响,挑选出"能效比最高"的CPU核心来放置任务,实现性能与功耗的终极平衡。
EAS的由来 :
在标准的完全公平调度器(CFS)设计之初,世界上绝大部分CPU都是对称多核(SMP,比如服务器上的数十个完全相同的Intel/AMD核心)。
传统CFS的盲区 :它默认所有核心的"算力"和"功耗成本"完全对等。它在唤醒进程时,只要看到哪个核空闲,就会直接把进程塞过去。
异构多核(如高通/联想/联发科SoC)的残酷现实 :手机芯片拥有超大核(Prime)、大核(Gold)和小核(Silver)。小核哪怕拉满到最高频率,其功耗也远远小于大核的低频状态;而大核一旦启动,虽然算力爆炸,但电池电量也会呈指数级(电压的平方)流失。
如果依然沿用传统CFS,可能一个普通的微信后台心跳任务,由于刚好碰到大核空闲,就被丢进大核去执行,造成极其严重的"大炮打蚊子"式的电量浪费。
EAS能够实现"运筹帷幄、精细算力",完全依赖于内核中三个核心子系统的精密耦合:
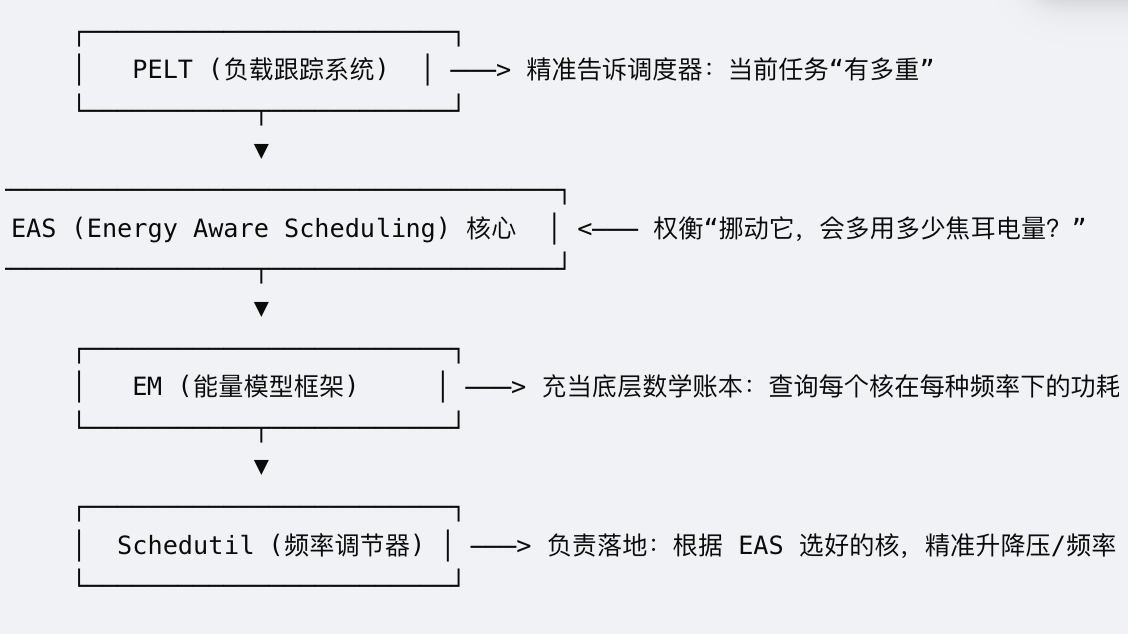
① PELT(Per-Entity Load Tracking,实体负载跟踪)
作用 :EAS必须拥有预测未来的能力。PELT系统为每一个线程维护了一个动态衰减的历史负载曲线(util_avg,使用率平均值)。
当一个任务被唤醒时,EAS可以直接读取PELT值,精准得知 :"这个任务在过去一段时间里平均需要消耗多少算力(Utilization,参考《cfs调度类深入解刨------核心结构的用意》)"。
② EM(Energy Model,能量模型)
作用 :EM是芯片厂商(如 ARM、高通)在出厂前,通过精确测试硬编码写入Linux内核的一张"功耗/频率对照表"。
它告诉内核:小核在1.0GHz时消耗多少毫瓦,在2.0GHz时消耗多少毫瓦;大核在最低频和最高频下的能效开销分别是多少。EM 充当了EAS决策时的"价格账本"。
③ Schedutil(基于调度的CPUFreq调速器)
过去(旧调速器如 Interactive/Conservative) :定时器周期性去抓拍CPU利用率,发现高了就升频,反应迟钝。
现在(Schedutil):它直接挂载在CFS调度器内部。当EAS决定把任务放进某个CPU的那一瞬间,Schedutil就能立刻同步计算出这个CPU接下来应有的频率,并通知底层的DVFS(动态电压频率调节)硬件进行瞬间升降压,消除了调频延迟。
EAS的核心决策机制:唤醒路径探秘
EAS的核心干预点发生在一个线程的 "唤醒阶段(Wake-up Path)"。当一个原本休眠的线程被IRQ或其他任务唤醒时,内核会调用select_task_rq_fair() 寻找目标CPU。
如果系统启用了EAS(sysctl_sched_energy_aware = 1,sched_energy_enabled),内核会摒弃传统CFS的负载均衡路线,转而强行切入EAS的黄金通道:
第一步:筛选可行性核心(Feasible CPUs)
EAS会先通过任务的PELT负载,剔除掉那些无法满足性能要求的核心。
如果一个游戏渲染线程极其沉重,当前小核即便拉满频率也装不下它,小核就会被直接一票否决,只在大核和超大核之间做挑选。
第二步:能量模拟计算(Energy Estimation)
对于通过初审的几个候选CPU(例如CPU 0小核,CPU 4大核),EAS状态机会在内存中启动模拟演练(compute_energy()):
假设把这个任务放进 CPU 0(小核):小核的利用率会推高,引发Schedutil升频。EAS去查阅EM能量模型算出小核升频后整个集群会多消耗X焦耳的能量。
假设把这个任务放进CPU 4(大核):大核不需要升频就能吃下它。EAS再次算出大核维持原频率运行该任务会多消耗Y焦耳的能量。
第三步:一锤定音(Energy-Efficient Placement)
EAS最终会对比模拟出的X和Y。谁能让整颗SoC芯片在容纳该任务后的总体能量增量(Delta Energy)最小,任务就会被直接投递给谁。
EAS与普通CFS负载均衡的边界与安全阀
EAS虽然极其省电,但算力预估需要耗费CPU的计算开销(每次唤醒都要查表、做数学加减法)。因此,Linux内核为EAS设立了严格的"安全阀门",防止其在极端高载下拖累系统:
安全阀一:超载自动熔断(Overutilized)
当系统整体负载极高,某些核心的利用率超过了自身算力的80%(内核源码中的is_rd_overutilized() 变为真)时,系统会判定:"现在保流畅度第一,别跟我算这点电费了!"
EAS机制会立刻自动熔断关闭,调度器瞬间退回到传统CFS的性能模式(以最大化吞吐量为核心的负载均衡算法),不惜一切代价拉满频率、平分任务,直到负载回落。
安全阀二:不适用于SMP对称架构
如果是一台PC或者服务器,所有核心一模一样,EAS模拟计算出的总体能量变动几乎永远是对等的。因此,在Intel/AMD的多核机器上,EAS不会被内核开启,避免无谓的查表开销。
手机厂商在EAS上的魔改(以Android为例)
虽然Linux 5.0+已经将EAS彻底并入了主线(Mainline),但手机厂商为了追求极致的游戏帧率平稳度,在通用内核的EAS基础上进行了大量的硬核定制:
UCLAMP(Util Clamp,负载钳制机制) :
这是现代手机魔改EAS的绝对核心。厂商可以给特定的高优先级前台应用强行打上一个uclamp_min标签(例如强制认定该任务最低利用率为512)。
这样一来,当该任务唤醒时,即便它当前实际很闲,EAS在模拟计算时也会误以为它很重,从而强行将其丢进大核并命令Schedutil瞬间拉高大核频率。这完美解决了游戏团战、进图加载时由于EAS反应过慢导致的掉帧卡顿。
相关结构
c
struct root_domain { 根域是调度域的一个概念,主要用于实时调度(RT),Deadline调度及CFS调度的EAS版本,它定义了一组CPU集合,这些CPU之间可以进行负载均衡,并且共享一些调度资源
atomic_t refcount; 用于管理根域的生命周期。当引用计数为0时,可以释放根域
atomic_t rto_count; 记录处于RT overload(实时任务过载)状态的CPU数量
struct rcu_head rcu; 用于安全地释放根域
cpumask_var_t span; 位图,表示该根域所覆盖的所有CPU
cpumask_var_t online; 位图,表示该根域中在线的CPU
int overload; 表示至少有一个CPU上有可迁移的负载(例如:多于一个可运行任务,或者正在运行的任务是不适合的(misfit))
int overutilized; 表示至少有一个CPU的利用率超过了其容量(tipping point),即过载
cpumask_var_t dlo_mask; 位图,记录有超过一个可运行的Deadline任务的CPU
atomic_t dlo_count; 记录dlo_mask中设置的CPU数量,即有多少个CPU有超过一个可运行的Deadline任务
struct dl_bw dl_bw; 用于Deadline调度器的带宽管理
struct cpudl cpudl; 用于Deadline调度器的CPU优先级管理
u64 visit_gen; 一个单调递增的值,用于记录根域的dl_bw检查或更新的次数。用于避免一些竞态条件
#ifdef HAVE_RT_PUSH_IPI 用于RT任务的推送(push)IPI(处理器间中断)机制
struct irq_work rto_push_work; 用于触发IPI的中断工作
raw_spinlock_t rto_lock; 保护以下字段的自旋锁
int rto_loop; 在锁内更新和读取,用于IPI推送循环
int rto_cpu;
atomic_t rto_loop_next; 原子变量,在锁外更新,用于IPI推送循环
atomic_t rto_loop_start;
#endif
cpumask_var_t rto_mask; 位图,记录有超过一个可运行的RT任务的CPU(即RT过载的CPU)
struct cpupri cpupri; 用于实时调度器的CPU优先级管理
unsigned long max_cpu_capacity; 记录根域中CPU的最大容量(capacity)
struct perf_domain __rcu *pd; 一个以NULL结尾的性能域(performance domain)链表,这些性能域与根域的CPU相交。使用RCU机制保护
};
struct perf_domain { 用于管理性能域(Performance Domain)的数据结构。性能域是CPUFreq框架和能效模型(Energy Model)的一部分,用于表示一组具有相同性能特性的CPU,这些CPU可以一起调整频率,并且共享电源管理资源
struct em_perf_domain *em_pd; 能效模型提供了该性能域中每个性能状态(频率/电压对)的功耗和性能数据,用于做出能效感知的调度决策
struct perf_domain *next; 系统可能存在多个性能域(例如,在异构系统中,大核和小核属于不同的性能域),它们通过链表连接
struct rcu_head rcu; 当性能域被更新或删除时,可以确保在没有任何读者引用该结构体后再进行内存回收
};