可直接落地的生产级架构设计、框架选型与模型路由策略
4.1 整体架构设计
一个生产级的长任务 AI 系统,推荐采用以下六层架构。这张图是本课程最重要的工程参考图:
 图 2:长任务 AI 开发整体架构图------六层架构,每层职责清晰,可独立演进
图 2:长任务 AI 开发整体架构图------六层架构,每层职责清晰,可独立演进
各层职责说明:
- 用户层:接收需求输入,展示结果,收集反馈
- 任务规划层:将模糊需求分解为明确的子任务 DAG(有向无环图)
- 状态管理层:维护上下文摘要、长期记忆、当前进度、错误重试状态
- 执行引擎层:按 Workflow 模式调度子任务,实现模型路由
- 评估层:每步 Gate 检查,不通过则携带反馈重新执行
- 输出层:格式化输出,收集反馈,驱动迭代
4.2 框架选型建议(2026 年实测)
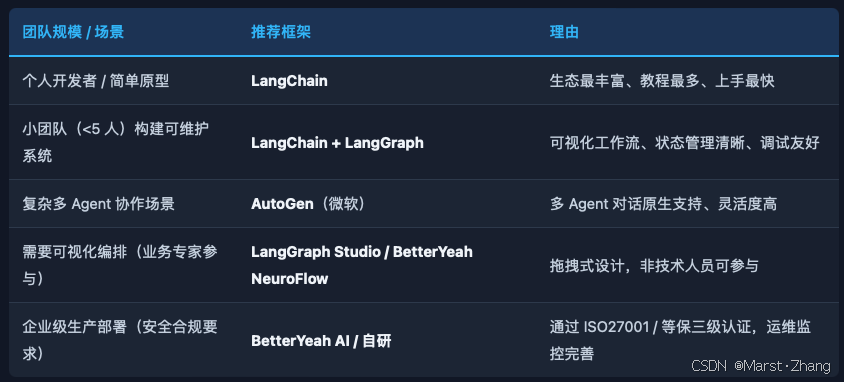 5个场景推荐框架 Anthropic 重要提醒 :建议优先直接使用 LLM API,框架创建的额外抽象层会使底层 prompt 和 response 难以调试。框架适合在原型验证成功后引入,而不是一开始就上框架。
5个场景推荐框架 Anthropic 重要提醒 :建议优先直接使用 LLM API,框架创建的额外抽象层会使底层 prompt 和 response 难以调试。框架适合在原型验证成功后引入,而不是一开始就上框架。
4.3 模型路由策略(成本控制核心)
长任务开发的最大成本陷阱是:所有步骤都用 GPT-4o / Claude 3.5 级别模型。
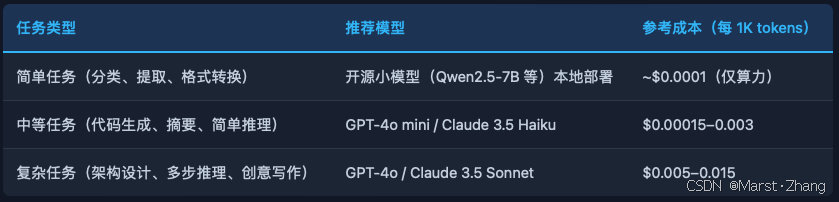
2026 年的最佳实践是按任务复杂度动态路由到不同模型:
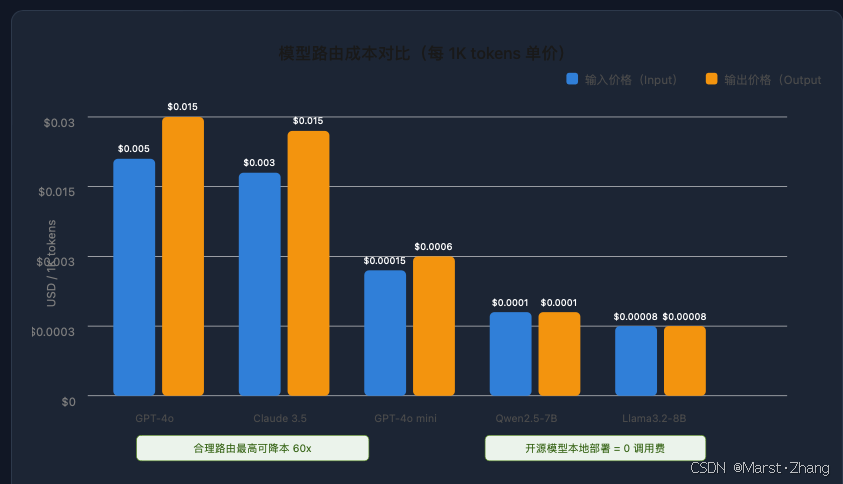 图 3:模型路由成本对比------合理路由最高可降本 60 倍
图 3:模型路由成本对比------合理路由最高可降本 60 倍
实测数据(BetterYeah) :未使用路由策略单次长任务平均消耗 3.2** ;使用路由策略(70% 走小模型)后降至 **0.8 ,降本 75%。
4.4 记忆与上下文管理方案
长任务开发最核心的工程问题之一是上下文管理 。推荐三级策略:
Level 1:上下文摘要压缩
每 N 轮对话,用 LLM 生成对话摘要替代原始内容:
python
# LangChain 中的实现方式
from langchain.memory import ConversationSummaryMemory
memory = ConversationSummaryMemory(
llm=llm, # 用小型 LLM 做摘要,降低成本
max_token_limit=2000
)Level 2:外部向量记忆库
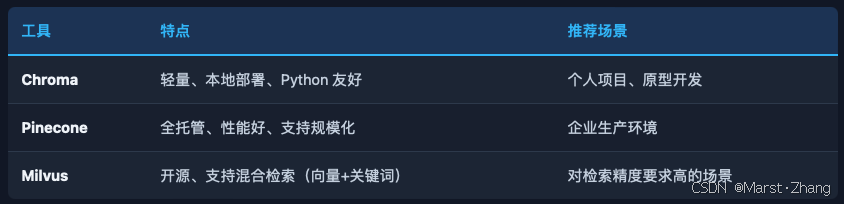
Level 3:结构化状态文件(最可靠)
用 JSON/YAML 文件维护任务状态,每次调用前读取,执行后更新:
javascript
{
"task_id": "proj-20250604-001",
"current_stage": "architecture_design",
"completed_stages": ["requirement_analysis"],
"key_decisions": [
{"stage": "requirement_analysis", "decision": "使用 Python + FastAPI"}
],
"context_summary": "用户需要构建多租户 SaaS 平台...",
"retry_count": 0,
"max_retry": 3
}实践建议 :三级策略中,Level 3(状态文件)是最可靠的,不依赖任何框架,直接文件读写,建议所有长任务项目都实现这一层。
本章要点
生产级长任务 AI 系统应采用六层架构;框架选型遵循"能简则简"原则;模型路由是成本控制核心,合理路由可降本 60 倍以上;记忆管理采用"摘要 + 向量库 + 状态文件"三级策略。