一、起因:一段把我看笑了的代码
前阵子聊 Figma MCP,大家都说香------稿子链接一丢,组件代码自动出来,不香吗?
直到我亲眼看到一份转出来的产物:
ini
<div className="frame-22">
<div className="frame-15">
<div className="rectangle-509" />
<div className="frame-14">
<div className="rectangle-506" />
<div className="rectangle-507" />
</div>
</div>
</div>frame-22 套 frame-15 套 rectangle-509。这玩意儿前端拿到要重写一遍,那 MCP 的意义在哪?
冷静想了下,锅其实不在 MCP。MCP 就是个翻译机,把节点树原样翻译成 DOM。你节点叫 Frame 22,它就只能写 frame-22,你能怪它?
真正的问题在更上游:大量稿子根本没有为"被机器读"做过准备。
| 稿子里长什么样 | 翻出来代码长什么样 |
|---|---|
节点名 Frame 47 / Rectangle 12 |
一堆没语义的 className |
| 三张几乎一样的卡片各画各的 | 三段重复 JSX,前端还要二次抽象 |
| 同一个品牌红在 20 处裸用 hex | 代码里 hardcode 20 次,换主题要逐个改 |
| 容器没开 Auto Layout | 满屏 position: absolute; left:...; top:... |
MCP 再聪明,也救不回一份"不配被翻译"的稿子。
那能不能反过来:先把稿子修到能被翻译,再让 MCP 翻译?
这就是我后来搓那个 Skill 的初衷。
二、它干嘛的,一句话
扫稿子,告诉你哪里会让 MCP 出垃圾,能修的直接给你修了。
四个维度,覆盖我观察到的大部分翻车点:
scss
🟪 A · 命名与图层结构 --- Frame N、空 Group、嵌套过深
🟦 L · Auto Layout 与间距 --- 假等距对齐、应开未开、padding 不一致
🟩 C · Component 复用 --- 同构没提为 Component、Detached、缺 Variant
🟧 T · 变量与 Design Token --- 颜色裸值、字号没抽 Text Style、阴影重复每条问题分三级严重度:🔴 阻塞 / 🟡 建议 / ⚪ 提示。能一键修的我会标 ✅,不能修的(涉及设计意图的)只标位置,让设计师自己定。
写操作前永远先打印影响范围、等用户确认。我特别不喜欢偷偷改稿子的工具------你都不知道它动了什么,怎么 review。
三、整体流程
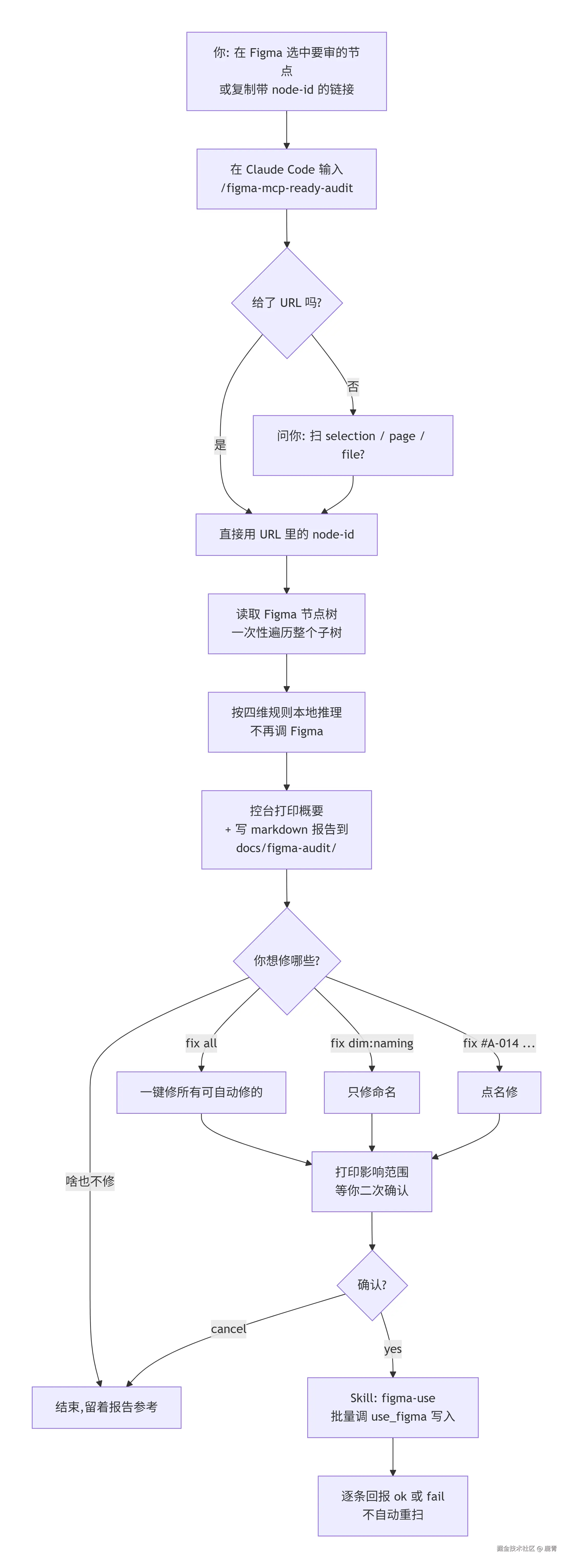 几个我比较在意的设计点:
几个我比较在意的设计点:
- 一次拉树,全程本地推理:减少和 Figma 的往返;扫几百节点也就秒级
- 规则文件按需懒加载 :四个维度的规则各占一个
.md,只在该维度首次命中时才读,不需要的不进上下文 - 扫出来的问题只活在本次会话:报告 Markdown 会落盘,但内存里的 ID 列表不跨会话------这点后面会展开说
四、四个维度,分别在管什么
🟪 A · 命名与图层结构
这一档最高频,也最容易修。
| 规则 | 报什么 | 严重度 | 自动修 |
|---|---|---|---|
A.default-name |
节点叫 Frame N / Rectangle N / Group <数字> 等 |
🔴 | ✅ |
A.max-depth |
嵌套超过 6 层 | 🟡 | ❌ |
A.empty-frame |
空 Frame / 子节点全隐藏 | 🟡 | ✅ |
A.redundant-single-child-group |
只有一个子节点的冗余 Group | ⚪/🟡 | ✅ |
自动改名不能瞎改,所以有一套启发式优先级 : 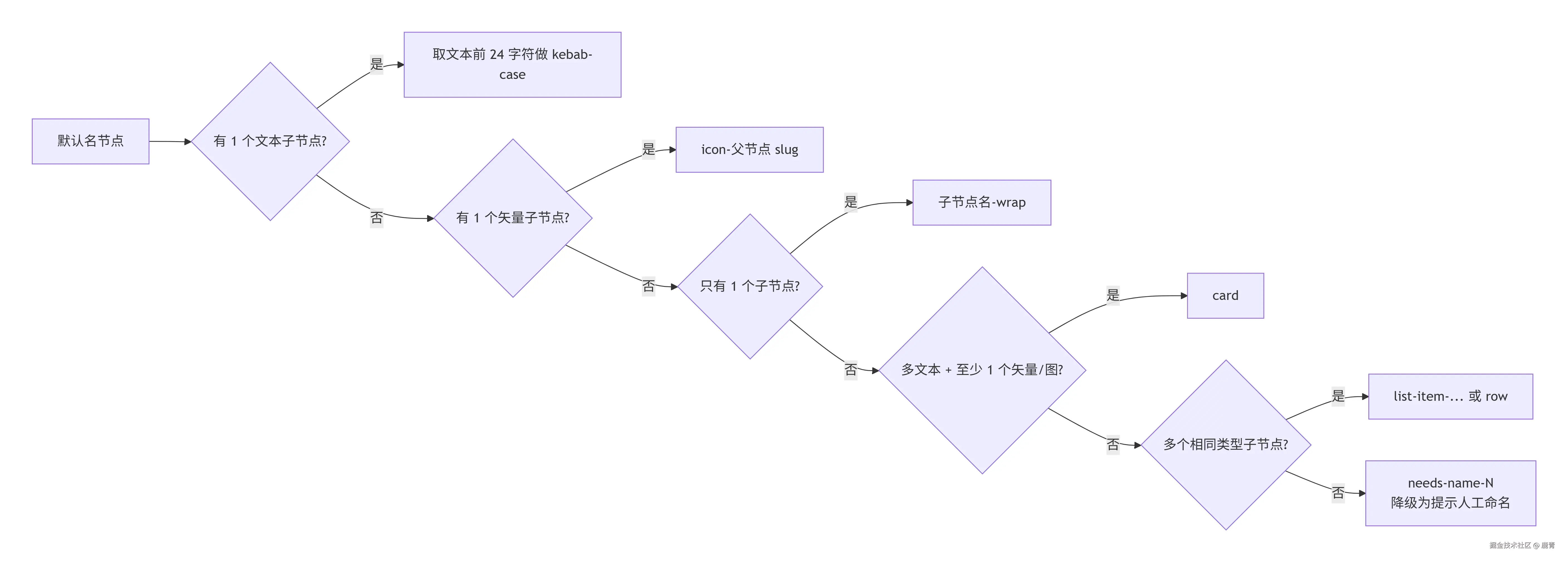
注意:带数字但已经有语义的名字不会被误报 。grid-12-col、top-3-features 这种正则不命中,它们没问题。
另外,"实在猜不出怎么改"的,会降级为 🟡 标 needs-name-N,让人工接手。不强行编一个名字混过去------那只是把垃圾从一处搬到另一处。
🟦 L · Auto Layout 与间距
这一档值钱在哪里:没开 Auto Layout 的容器,会被 MCP 翻成绝对定位。 一旦绝对定位进了代码,响应式就基本告别了。
我最看重的三条:
L.pseudo-auto-layout:4 个以上子节点 + 等距方差 < 1px → 这明显是手动一个一个对齐出来的,应开 Auto Layout。🔴 + ✅L.padding-inconsistent:同一 Frame 内 padding 出现 3 个以上"接近但不相等"的值(差 ≤ 4px)→ 归一到中位数L.gap-variance:子节点间距方差超 4px → 归一到众数
故意错位、堆叠装饰这种我会避开------方差超阈才报,所以"看起来就该错开的"不会触发。
🟩 C · Component / Variants 复用
整个工具里最克制的一档:只标不修。
为什么?因为"要不要把这几张卡提为 Component"、"要不要做 Variant"、"要不要 Detach"------每一个都是设计决策,不是机械操作。算法看着像但实际是两个不同业务模型的两张卡,提为 Component 反而是污染。
工具能做的是给一个可信的"候选名单"。底层是视觉指纹:
ini
fingerprint = type @ width × height # 主色 hex | 文本结构哈希- 宽高四舍五入到最近的 4 像素,容忍微小偏差
- 文本结构 = 所有后代 TEXT 按位置排序后,
<字重>:<字号>拼起来再哈希
指纹相同的节点数 ≥ 3 且都没提为 Component → 🔴。报告里会给一个建议的 Component 命名 ,比如某种带 state Variant 的形式。但要不要按建议提,永远是设计师拍板。
🟧 T · 变量与 Design Token
绑了 Variable / Style 的字段,MCP 会翻成 var(--xxx);裸值会写死成 hex 和像素。所以这一档的目标就一句话:让该绑的都绑上。
| 规则 | 报什么 | 自动修 |
|---|---|---|
T.color-duplicate-unbound |
同色 ≥ 2 次都没绑 Variable | ✅ |
T.color-similar |
两色 ΔE < 3 但不相等(视觉几乎看不出) | ❌ |
T.text-style-duplicate-unbound |
字号/行高/字重组合重复 ≥ 2 次 | ✅ |
T.shadow-duplicate-unbound |
阴影裸值重复 ≥ 2 次 | ✅ |
自动建出来的命名我故意搞得很"丑":
- Color Variable →
color/auto-1color/auto-2... - Text Style →
text/auto-1text/auto-2... - 都带
description: "needs-rename"
为什么不一上来取个像样名字?因为"该叫什么"是设计语义的事,工具不该越俎代庖。这个丑名字反而是个提醒 ------你扫完看到一堆 auto-N,会知道下一步要做的是过一遍语义化命名。
如果你已经有了 design token 体系,可以放一份白名单,让工具优先复用:
css
{
"tokenWhitelist": {
"color": {
"#fe467f": { "name": "brand/primary-red" },
"#ffffff": { "name": "neutral/white" }
}
}
}那扫到 #fe467f 就不再建 color/auto-1,而是直接绑 brand/primary-red。
ΔE < 3 的相似色为什么不自动合?因为我吃过亏。看起来一模一样的两个颜色,有时候真的就是不同语义(比如品牌色 vs 失效态),合掉会出事。所以只标位置,让人去判断。
五、跑起来是什么体感
控台概要大概长这样:
bash
📋 Figma 审计:<文件名> · <范围> · <节点数>
🔴 阻塞 X 🟡 建议 Y ⚪ 提示 Z
─────────────────────────────────────
🔴 命名与结构 ........ N (其中 ✅ 可一键修复 M)
🟡 Auto Layout ....... N (✅ M)
🔴 复用 .............. N (✅ 0,本维度仅标记)
🟡 Token ............. N (✅ M)
Top 5 阻塞项:
#A-001 🔴 Frame "..." 命名为默认值 ✅
path: ...
#C-001 🔴 三张卡片视觉指纹相同,均未提为 Component
建议: <Component 命名建议>
#T-001 🔴 文本色 #xxx 重复 N 次未绑 Variable ✅
...
完整报告 → docs/figma-audit/<日期>-<slug>.md
下一步:回复 "fix #A-014" / "fix all ✅" / "fix dim:tokens"详细 Markdown 会落到 docs/figma-audit/ 下,每条 finding 包含:位置、节点 ID、为什么影响 MCP、建议、是否能一键修。
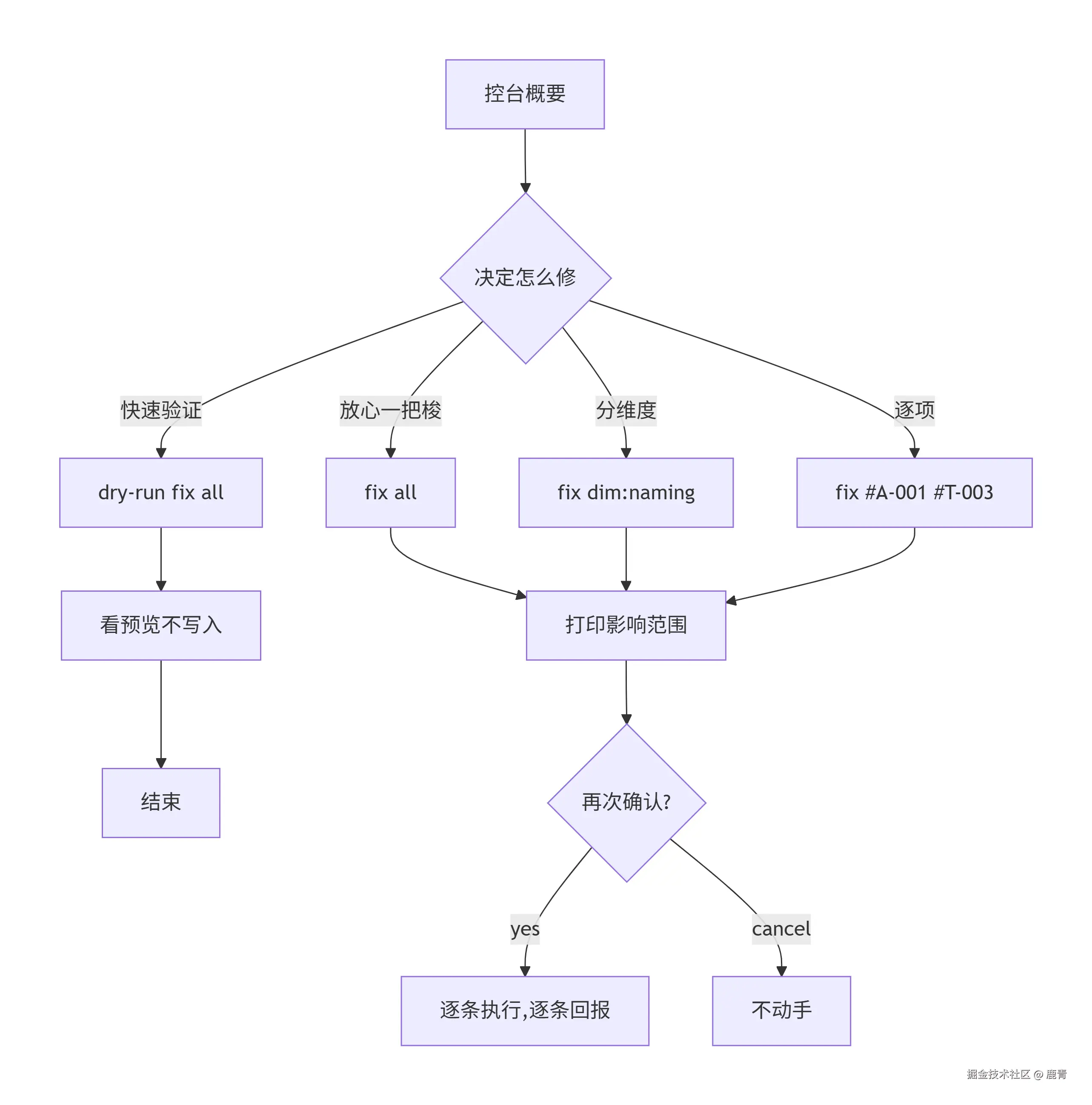
修复命令对照:
| 命令 | 行为 |
|---|---|
fix all ✅ |
修所有带 ✅ 的 finding |
fix dim:naming ✅ |
只修命名维度 |
fix dim:tokens ✅ |
只修 Token 维度 |
fix #A-014 #L-003 |
点名修 |
dry-run fix ... |
只打印将执行的脚本,不写入 |
fix ... --yes |
跳过本批确认,直接开干 |
我自己用得最多的是 dry-run fix all ------ 先看一眼工具到底打算怎么改,确认没问题再去掉 dry-run。
六、做这玩意时踩到的几个坑
1. 硬规则写在 Skill 提示词最顶上
模型偶尔会自作聪明想"省一步"------比如跳过用户确认直接改,或者觉得"这个稿子明显没问题"就懒得读规则文件。所以我在 Skill 的最前面留了一段违反即停的硬规则:
- 写操作前必须打印影响范围 + 等用户确认(除非显式
--yes) - 不自动做:提为 Component / Detach / 删非空节点 / 改文本 / 合近似色
- Figma 读失败立即停,不要 retry,不要静默吞错
- 报告产物固定写到
docs/figma-audit/<日期>-<slug>.md
写在顶部的好处是 reload 频率高,模型不容易"忘"。
2. 规则文件按维度懒加载
四个维度的细则各占一个 references/<dim>.md,只在该维度首次命中时读 。一份只有命名问题的稿子,永远不会把 tokens.md 加载进上下文。在大稿子上能省不少 token。
3. Findings 不跨会话持久化
报告 Markdown 会落盘,但内存里的 findings[] 只活在当次会话。新会话里直接 fix #A-014,工具会拒绝并提示"请重扫"。
这点我犹豫过------用户体验明显变差。但更怕的是稿子在你新会话之前已经改过了:旧 ID 对应的节点可能改名、删除、移位。凭过期报告盲改,是把一个清晰的错变成一个隐蔽的错。
4. 视觉指纹一开始太粗了
最初版指纹只用 type @ w × h,结果把"四个按钮"和"四个标签"都判为同构。补上主色和文本结构哈希之后稳定了下来。但即便稳了,C 维度仍然只标不修 ------ 算法精度不能替代设计意图。
5. 阈值全部配置化
json
{
"naming": { "maxDepth": 6 },
"layout": { "paddingTolerance": 4, "gapVariance": 4 },
"components": { "duplicateThreshold": 3 },
"tokens": { "colorDuplicateMin": 2, "colorSimilarDeltaE": 3 }
}内置默认值是过了一批 fixture 心算验证的,大多数稿子不配也能跑得很准。但留出口子很重要------总有团队的工作流就是和默认值不一样。
七、和别的 Figma 工具的关系
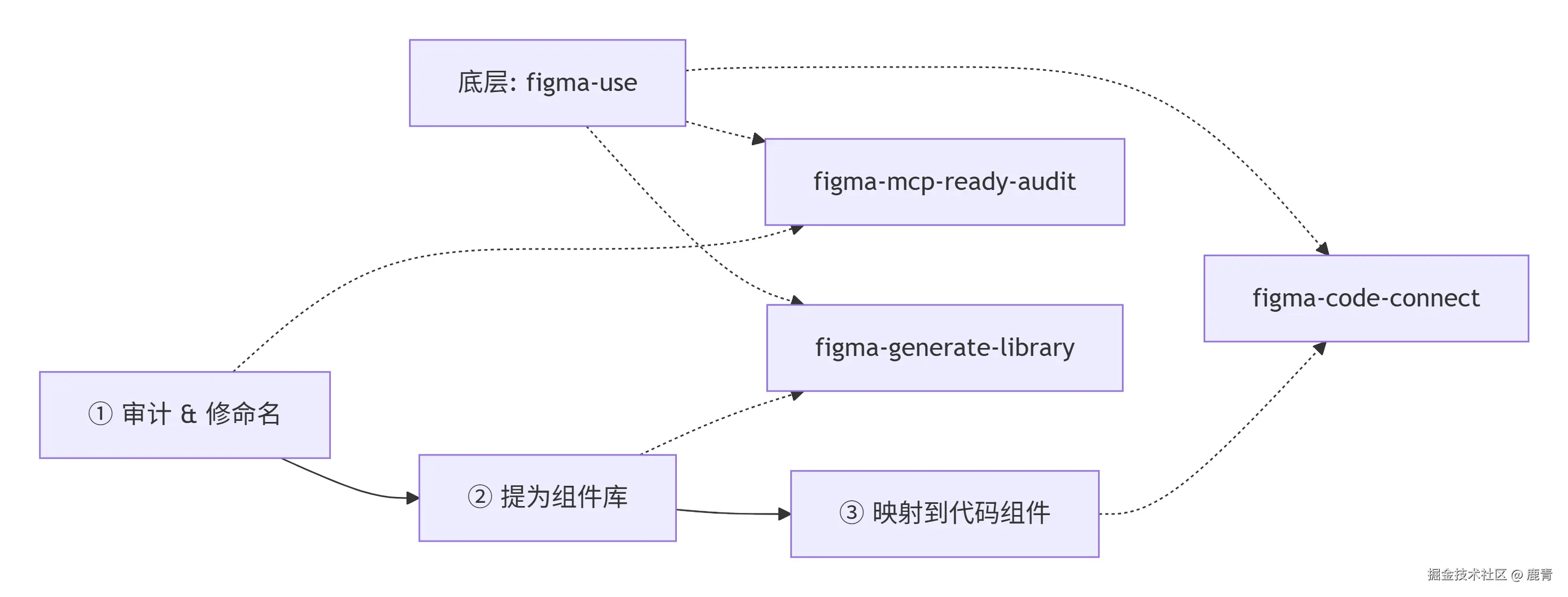 我推荐的工作流:
我推荐的工作流:
- 稿子画好 → 跑一遍审计 → 一键修命名 + Token
- 审计建议提为 Component 的那些,设计师过一眼、决定是否真的要提
- 前端把 Figma Component 映射到代码库里的 React/Vue 组件
- 之后任何人用 MCP 转代码,拿到的都是带语义的 className +
var(--xxx),而不是frame-22套frame-15
每一步都不是新东西,但顺序很重要------命名和 Token 没修干净就去提 Component,提出来的 Component 本身就带垃圾名字,后面 Code Connect 映射的时候还得回头改。
八、最后想说的
做这个 Skill 的核心感受其实很朴素:
AI 生成代码的质量上限,由人写的"输入"决定。 稿件就是 MCP 的输入。
很多对"MCP 体验差"的吐槽,本质是稿子没整理。这件事本来一直是口头规范------大家都知道节点要起名、颜色要抽 token、能复用的要提 Component,但谁也不会真的逐节点 review 几百个节点。
工具的价值不在"AI 多牛",在于把"大家都知道但谁也不会做"的事变成一行命令。规范从口头约定,变成可执行的检查项。
把它接到设计交付链路里,相当于在 Figma 和代码之间加了一道质检。设计师那边多花几分钟,下游所有用 MCP 的人都受益。
如果你也在被 Figma → 代码这条链折磨,欢迎照这个思路改一个适合自己团队的版本。
最后附上仓库地址: figma_skill