1.CScript"<<"重载
我们看到之前写脚本的方式,都是通过<<符号将脚本写进CScript里面。
CScript继承 public vector<unsigned char> 如下:
cpp
class CScript : public vector<unsigned char>
{
protected:
CScript& push_int64(int64 n)所以它是一个容器,vector数组,用来储存脚本代码。
然后通过重载<<操作符,来将脚本写进容器里,我们可以看到<<重载,参数分为分很多类型,支持很多类型代码的写进script里:
cpp
CScript& operator<<(char b) { return (push_int64(b)); }
CScript& operator<<(short b) { return (push_int64(b)); }
CScript& operator<<(int b) { return (push_int64(b)); }
CScript& operator<<(long b) { return (push_int64(b)); }
CScript& operator<<(int64 b) { return (push_int64(b)); }
CScript& operator<<(unsigned char b) { return (push_uint64(b)); }
CScript& operator<<(unsigned int b) { return (push_uint64(b)); }
CScript& operator<<(unsigned short b) { return (push_uint64(b)); }
CScript& operator<<(unsigned long b) { return (push_uint64(b)); }
CScript& operator<<(uint64 b) { return (push_uint64(b)); }
CScript& operator<<(opcodetype opcode)
{
if (opcode <= OP_SINGLEBYTE_END)
{
insert(end(), (unsigned char)opcode);
}
else
{
assert(opcode >= OP_DOUBLEBYTE_BEGIN);
insert(end(), (unsigned char)(opcode >> 8));
insert(end(), (unsigned char)(opcode & 0xFF));
}
return (*this);
}
CScript& operator<<(const uint160& b)
{
insert(end(), sizeof(b));
insert(end(), (unsigned char*)&b, (unsigned char*)&b + sizeof(b));
return (*this);
}
CScript& operator<<(const uint256& b)
{
insert(end(), sizeof(b));
insert(end(), (unsigned char*)&b, (unsigned char*)&b + sizeof(b));
return (*this);
}
CScript& operator<<(const CBigNum& b)
{
*this << b.getvch();
return (*this);
}
CScript& operator<<(const vector<unsigned char>& b)
{
if (b.size() < OP_PUSHDATA1)
{
insert(end(), (unsigned char)b.size());
}
else if (b.size() <= 0xff)
{
insert(end(), OP_PUSHDATA1);
insert(end(), (unsigned char)b.size());
}
else
{
insert(end(), OP_PUSHDATA2);
unsigned short nSize = b.size();
insert(end(), (unsigned char*)&nSize, (unsigned char*)&nSize + sizeof(nSize));
}
insert(end(), b.begin(), b.end());
return (*this);
}
CScript& operator<<(const CScript& b)
{
// I'm not sure if this should push the script or concatenate scripts.
// If there's ever a use for pushing a script onto a script, delete this member fn
assert(("warning: pushing a CScript onto a CScript with << is probably not intended, use + to concatenate", false));
return (*this);
}底层都是通过push_back或insert将这些数据插入到vector容器里。
其中一些常用的整型类型是调用了下面这两个函数,用push_back的方式(小于等于16):
cpp
protected:
CScript& push_int64(int64 n)
{
if (n == -1 || (n >= 1 && n <= 16))
{
push_back(n + (OP_1 - 1));
}
else
{
CBigNum bn(n);
*this << bn.getvch();
}
return (*this);
}
CScript& push_uint64(uint64 n)
{
if (n == -1 || (n >= 1 && n <= 16))
{
push_back(n + (OP_1 - 1));
}
else
{
CBigNum bn(n);
*this << bn.getvch();
}
return (*this);
}关于这里为什么还带个操作码op_1-1,这只是一些优化,当数字小于等于16时,就把它换算成1个字节的操作码,能节省空间(不需要长度标记+字节的描述方式来写入数字)。现在我们大概了解即可。后续看情况再详细说明其实原理。
当解析器读脚本时,是1个字节读取的,那如果有一段数据,比如说是32字节,一个哈希值,那你怎么确定这段数据的起始和结束位置呢?
所以他会在数据前面加标记,指示压入多少数据到栈中。
比如2 5 op_add这个脚本,我们看到前面并没有标记呢?这是一种高级的表达方式。事实上
在写入2到script里面,底层函数会给前面加上标记(仅举例,以实际情况为准,见下面备忘录),表明后面将是数据,读取多少字节。
而如果符合条件16以下的数字,那么转换成操作码直接写入(如转换成op_1,直接知道要写入1到栈顶中),不需要在前面多加一个标记。
(注关于这里为什么不会把op_1这样的操作码当成是数据长度描述,因为这些操作码都是有一定的范围值,如大于某个值解析器不会把它当成push 多少字节,而是认为它是操作码,这一点将在我们了解解析器的具体逻辑时就会明白)
2.重载<<操作码
好,我们知道,除了<<吃入常用类型外,他还支持操作码,所以也有一定有个<<操作码类型的重载如下(吃入操作码):
cpp
CScript& operator<<(opcodetype opcode)
{
if (opcode <= OP_SINGLEBYTE_END)
{
insert(end(), (unsigned char)opcode);
}
else
{
assert(opcode >= OP_DOUBLEBYTE_BEGIN);
insert(end(), (unsigned char)(opcode >> 8));
insert(end(), (unsigned char)(opcode & 0xFF));
}
return (*this);
}3.opcodetype
opcodetype是个枚举类型,定义如下:
cpp
enum opcodetype
{
// push value
OP_0 = 0,
OP_FALSE = OP_0,
OP_PUSHDATA1 = 76,
OP_PUSHDATA2,
OP_PUSHDATA4,
OP_1NEGATE,
OP_RESERVED,
OP_1,
OP_TRUE = OP_1,
OP_2,
OP_3,
OP_4,
OP_5,
OP_6,
OP_7,
OP_8,
OP_9,
OP_10,
OP_11,
OP_12,
OP_13,
OP_14,
OP_15,
OP_16,
// control
OP_NOP,
OP_VER,
OP_IF,
OP_NOTIF,
OP_VERIF,
OP_VERNOTIF,
OP_ELSE,
OP_ENDIF,
OP_VERIFY,
OP_RETURN,
// stack ops
OP_TOALTSTACK,
OP_FROMALTSTACK,
OP_2DROP,
OP_2DUP,
OP_3DUP,
OP_2OVER,
OP_2ROT,
OP_2SWAP,
OP_IFDUP,
OP_DEPTH,
OP_DROP,
OP_DUP,
OP_NIP,
OP_OVER,
OP_PICK,
OP_ROLL,
OP_ROT,
OP_SWAP,
OP_TUCK,
// splice ops
OP_CAT,
OP_SUBSTR,
OP_LEFT,
OP_RIGHT,
OP_SIZE,
// bit logic
OP_INVERT,
OP_AND,
OP_OR,
OP_XOR,
OP_EQUAL,
OP_EQUALVERIFY,
OP_RESERVED1,
OP_RESERVED2,
// numeric
OP_1ADD,
OP_1SUB,
OP_2MUL,
OP_2DIV,
OP_NEGATE,
OP_ABS,
OP_NOT,
OP_0NOTEQUAL,
OP_ADD,
OP_SUB,
OP_MUL,
OP_DIV,
OP_MOD,
OP_LSHIFT,
OP_RSHIFT,
OP_BOOLAND,
OP_BOOLOR,
OP_NUMEQUAL,
OP_NUMEQUALVERIFY,
OP_NUMNOTEQUAL,
OP_LESSTHAN,
OP_GREATERTHAN,
OP_LESSTHANOREQUAL,
OP_GREATERTHANOREQUAL,
OP_MIN,
OP_MAX,
OP_WITHIN,
// crypto
OP_RIPEMD160,
OP_SHA1,
OP_SHA256,
OP_HASH160,
OP_HASH256,
OP_CODESEPARATOR,
OP_CHECKSIG,
OP_CHECKSIGVERIFY,
OP_CHECKMULTISIG,
OP_CHECKMULTISIGVERIFY,
// multi-byte opcodes
OP_SINGLEBYTE_END = 0xF0,
OP_DOUBLEBYTE_BEGIN = 0xF000,
// template matching params
OP_PUBKEY,
OP_PUBKEYHASH,
OP_INVALIDOPCODE = 0xFFFF,
};以上都是操作码,关于每个操作码的意思,后续如有用到将做说明。
4.EvalScript
然后我们来看EvalScript函数是如何执行脚本的,先1个字节的读取数据,如下:
cpp
bool EvalScript(const CScript& script, const CTransaction& txTo, unsigned int nIn, int nHashType,
vector<vector<unsigned char> >* pvStackRet)
{
CAutoBN_CTX pctx;
CScript::const_iterator pc = script.begin();
CScript::const_iterator pend = script.end();
CScript::const_iterator pbegincodehash = script.begin();
vector<bool> vfExec;
vector<valtype> stack;
vector<valtype> altstack;
if (pvStackRet)
pvStackRet->clear();
while (pc < pend)
{先获取第一个字节的迭代器pc,和最后一个字节的迭代器pend;
然后循环语句pc<pend里,以1个字节为单位的读取,直到遍历完。
5.GetOp
我们来看一个关键的函数:
cpp
bool fExec = !count(vfExec.begin(), vfExec.end(), false);
//
// Read instruction
//
opcodetype opcode;
valtype vchPushValue;
if (!script.GetOp(pc, opcode, vchPushValue))
return false;这里的GetOp是获取操作码,而现在pc指向第一个字节,也就是说,脚本的第一字节须是操作码或者数据标记(推送多少数据),而不是数据起始位置。这样包括循环后的pc,也遵循上述原则。
比如说要压入多少数据后,pc就会累加多少从而指向下一个操作码。这样循环调用GetOp就不会有问题。而不会出现数据干扰。
我们来看一下这个函数的代码和逻辑:
cpp
bool GetOp(iterator& pc, opcodetype& opcodeRet, vector<unsigned char>& vchRet)
{
// This is why people hate C++
const_iterator pc2 = pc;
bool fRet = GetOp(pc2, opcodeRet, vchRet);
pc = begin() + (pc2 - begin());
return fRet;
}
bool GetOp(const_iterator& pc, opcodetype& opcodeRet, vector<unsigned char>& vchRet) const
{
opcodeRet = OP_INVALIDOPCODE;
vchRet.clear();
if (pc >= end())
return false;
// Read instruction
unsigned int opcode = *pc++;
if (opcode >= OP_SINGLEBYTE_END)
{
if (pc + 1 > end())
return false;
opcode <<= 8;
opcode |= *pc++;
}
// Immediate operand
if (opcode <= OP_PUSHDATA4)
{
unsigned int nSize = opcode;
if (opcode == OP_PUSHDATA1)
{
if (pc + 1 > end())
return false;
nSize = *pc++;
}
else if (opcode == OP_PUSHDATA2)
{
if (pc + 2 > end())
return false;
nSize = 0;
memcpy(&nSize, &pc[0], 2);
pc += 2;
}
else if (opcode == OP_PUSHDATA4)
{
if (pc + 4 > end())
return false;
memcpy(&nSize, &pc[0], 4);
pc += 4;
}
if (pc + nSize > end())
return false;
vchRet.assign(pc, pc + nSize);
pc += nSize;
}
opcodeRet = (opcodetype)opcode;
return true;
}我们注意到GetOp有两个版本,关键点在于pc参数,一个是非const一个是const版本,在非const版本中,定义了 const_iterator pc2 = pc;,然后再调用const版本,所以实际干活的是const版本。
而在EvalScript中也是定义了const pc,调用的是const版本,所以我们这里主要了解const版本的代码就行。
我们先来看三个参数,pc这个就是要读取的脚本了,传入的数据了,指向操作码(或标记)的迭代器。
opcodeRet,返回解析出来的迭代器,如op_1,op_add等。
vchRet 用来接收push的数据,如果有,比如是push指令,则这里跟着的是要push的数据。
另外GetOp里也负责维护pc的指针,它会根据情况将pc移动到下一条操作码。
6.清空初始化
我们来看开头的代码:
cpp
opcodeRet = OP_INVALIDOPCODE;
vchRet.clear();
if (pc >= end())
return false;就是清空一下数据,防止被之前的数据污染,op_invalid...一个特殊的值,无效的意思,无效操作码,你可以看作赋null之类的含义。
然后判断一下要求之类的,如果pc>=end说明读不了。已经超过了end.
接下来正式读取字节:
cpp
// Read instruction
unsigned int opcode = *pc++;把它赋予给opcode,并将pc后移一位,注意这里是pc++而不是++pc,所以是先赋值再自增。
- OP_SINGLEBYTE_END
然后开始解析这个opcode:
cpp
// Read instruction
unsigned int opcode = *pc++;
if (opcode >= OP_SINGLEBYTE_END)
{
if (pc + 1 > end())
return false;
opcode <<= 8;
opcode |= *pc++;
}这里是判断,这个操作码是单字节操作码还是双字节操作码,这是为后来扩展而设计,为后续增加操作码,基本上可以无视。几乎不会被触发。原理是这样的,OP_SINGLEBYTE_END是单字节操作码的范围,如果第一个字节大于这个范围,那么说明是双字节操作码,那么把第一个字节左移8位,然后再加上第二个字节(因为是双字节操作码)。注意这里的opcode是unsinged int类型,虽然它接收的是一个字节的操作码。所以左移8位,第一个字节的数据并不会丢失。
8.OP_PUSHDATA
然后我们来看这个判断:
cpp
// Immediate operand
if (opcode <= OP_PUSHDATA4)
{为什么会有OP_PUSHDATA这些操作码呢?
还记得之前的这段话吗:
(注关于这里为什么不会把op_1这样的操作码当成是数据长度描述,因为这些操作码都是有一定的范围值,如大于某个值解析器不会把它当成push多少字节)
这里的OP_PUSHDATA4就是那个临界值,只要小于这个OP_PUSHDATA4,就会把它解析为push操作。我们来看下这个OP_PUSHDATA4是怎么被定义的赋值的:
cpp
enum opcodetype
{
// push value
OP_0 = 0,
OP_FALSE = OP_0,
OP_PUSHDATA1 = 76,
OP_PUSHDATA2,
OP_PUSHDATA4,
OP_1NEGATE,
OP_RESERVED,
OP_1,
OP_TRUE = OP_1,
OP_2,
OP_3,
OP_4,
OP_5,
OP_6,
OP_7,
OP_8,
OP_9,
OP_10,
OP_11,
OP_12,
OP_13,
OP_14,
OP_15,
OP_16,
// control
OP_NOP,
OP_VER,
OP_IF,
OP_NOTIF,
OP_VERIF,关键的看这里:
cpp
enum opcodetype
{
// push value
OP_0 = 0,
OP_FALSE = OP_0,
OP_PUSHDATA1 = 76,
OP_PUSHDATA2,
OP_PUSHDATA4,OP_PUSHDATA1=76,我们知道enum类型默认赋值是从0开始依次递增的。如果显式指定,那么下一个将会在赋值的基础上递增。所以OP_PUSHDATA2为77,OP_PUSHDATA4为78。而OP_1,OP_ADD这样的操作码肯定是大于OP_PUSHDATA4的。因为它们排在后面(在编译器里,鼠标停留在枚举项上,会显示出值来)。
所以当opcode小于等于OP_PUSHDATA4那么它就不是操作码(常规),这就是原理。
但是它是怎么指定push多少字节的数据呢?看到后缀的数字吗?OP_PUSHDATA1,表示这个操作码后面的1个字节,用来描述数据长度。2则表示2个字节,4则表示4个字节。
而如果是小于OP_PUSHDATA1=76,则直接表示数据长度。也就是说,当后面要push的数据小于76个字节时,则可以用数字直接表示,比如32个字节,就写32可以了,而不是OP_PUSHDATA1+32.
事实上这里没写出来,你可以看低于76的数值,都可以理解成默认的push的操作码,比如op_push1=1,push一个字节,op_push2=2,push 两个字节,虽然这里没显示定义,但解析时就是这么理解的。
而超过了76字节(包括),那么就得用OP_PUSHDATA1的方法,依此类推,超过255字节,就得用OP_PUSHDATA2的方法。
9.数据大小读取
明白了上面,那么我们再来看这三个判断,就非常好理解了:
cpp
unsigned int nSize = opcode;
if (opcode == OP_PUSHDATA1)
{
if (pc + 1 > end())
return false;
nSize = *pc++;
}
else if (opcode == OP_PUSHDATA2)
{
if (pc + 2 > end())
return false;
nSize = 0;
memcpy(&nSize, &pc[0], 2);
pc += 2;
}
else if (opcode == OP_PUSHDATA4)
{
if (pc + 4 > end())
return false;
memcpy(&nSize, &pc[0], 4);
pc += 4;
}如果是pushdata1,则读后面的1个字节,用来描述大小。如果是pushdata2则读两个字节.....
10.读取数据
得到了数据大小,接下来根据这个大小,就是读取对应的数据了:
cpp
if (pc + nSize > end())
return false;
vchRet.assign(pc, pc + nSize);
pc += nSize;先判断一下大小逻辑检错问题,无意外,则调用assign拷贝数据,将pc到pc+nSize这个数据读到vchRet里,然后位移pc指针。
11.opCodeRet
然后就是转换一下操作码,返还回去,因为这里的opcode只是数值类型,将它转换为enum类型:
cpp
opcodeRet = (opcodetype)opcode;
return true;好,现在我们回到EvalScript函数。
执行完GetOp后:
12.if流程控制
cpp
bool fExec = !count(vfExec.begin(), vfExec.end(), false);
//
// Read instruction
//
opcodetype opcode;
valtype vchPushValue;
if (!script.GetOp(pc, opcode, vchPushValue))
return false;
if (fExec && opcode <= OP_PUSHDATA4)
stack.push_back(vchPushValue);
else if (fExec || (OP_IF <= opcode && opcode <= OP_ENDIF))这段代码是什么意思呢?我们可以看到这段代码有个fExec参数深度参与其中,并且还有OP_IF和OP_ENDIF之类的判断,想理解这部分代码,我们必须先得了解脚本的if使用方法,即如何写脚本判断语句,我们先来看OP_IF操作码,OP_IF判断的是栈顶的值,然后根据真和假执行相应的语句流程写法如下:
cpp
OP_0 //测试条件
OP_IF
执行语句 (为真时执行)
OP_ELSE (否则)
执行语句
OP_ENDIF (结束)我们把之前的例子改一下用来测试脚本,如下:
cpp
int main()
{
printf("Bitcoin v0.1.0 Simple Script Test\n");
printf("Script: 2 3 OP_ADD 5 OP_EQUAL\n\n");
// 1. 构造脚本
CScript script;
script << OP_0;//栈顶压入0
script << OP_IF << 3 << 5 << OP_ADD;//如果为真则执行3+5
script << OP_ELSE << 1 << 9 << OP_ADD;//如果为假则执行1+9
script << OP_ENDIF;
// 2. 执行脚本
vector<vector<unsigned char> > stack;
bool success = EvalScript(script, CTransaction(), 0, 0, &stack);
if (success)
{
printf("EvalScript executed successfully!\n");
if (!stack.empty())
{
const std::vector<unsigned char>& top = stack.back();
bool finalResult = (top.size() > 0 && top[0] != 0);
printf("Final stack size : %zu\n", stack.size());
printf("Top of stack (bool): %s\n", finalResult ? "TRUE" : "FALSE");
if (finalResult)
printf("Script result: PASSED (as expected)\n");
else
printf("Script result: FAILED\n");
}
else
{
printf("Stack is empty!\n");
}
}
else
{
printf("EvalScript failed!\n");
}
// 可选:打印栈中所有元素(调试用)
printf("\nStack content (bottom to top):\n");
for (size_t i = 0; i < stack.size(); ++i)
{
// 简单打印前几个字节
printf("[%zu] size=%zu ", i, stack[i].size());
for (size_t j = 0; j < stack[i].size() && j < 8; ++j)
printf("结果值:%d ", stack[i][j]);
printf("\n");
}
return 0;
}结果为10:
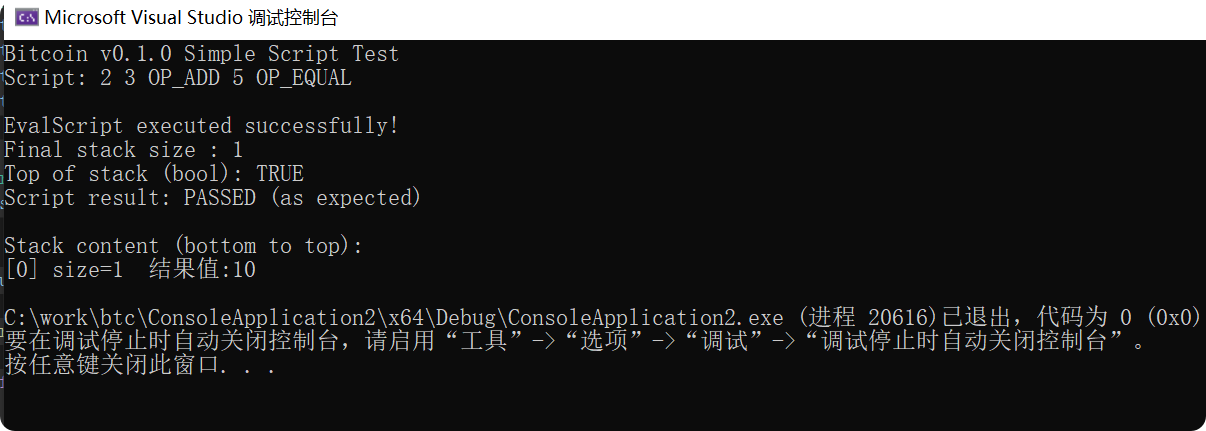
说明执行了else语句,逻辑正常,如果将OP_0改为OP_1,则会输出8,我实际测试正常,这里就不贴结果了。
好,但这里我是直接给个结果压入栈顶的,如果要判断3>5这样比大小的脚本,应该怎么写呢?
这里就留待下一章说明吧,今天就到这里。