文章标题:
- 一、前言
- 二、pytest测试框架详解
-
- 1、测试框架是什么
- 2、pytest常见的插件
- [2.1 插件介绍以及](#2.1 插件介绍以及)
- [2.2 安装插件](#2.2 安装插件)
-
- [2.2.1 单独安装](#2.2.1 单独安装)
- [2.2.2 批量安装](#2.2.2 批量安装)
- [2.2.3 验证安装](#2.2.3 验证安装)
- 3、pytest框架功能
-
- [3.1 pytest功能-发现测试用例](#3.1 pytest功能-发现测试用例)
- 三、pytest创建和执行用例
- 四、pytest常用参数和配置文件
-
- 1、命令行参数
-
- [1.1 常用的命令行参数](#1.1 常用的命令行参数)
- [1.2 -v](#1.2 -v)
- [1.3 -q](#1.3 -q)
- [1.4 -s](#1.4 -s)
- [1.5 -k](#1.5 -k)
- [1.6 -m](#1.6 -m)
- [1.7 -n](#1.7 -n)
- [1.8 --reruns](#1.8 --reruns)
- [1.9 --html](#1.9 --html)
- 2、配置文件(pytest.ini)
- [2.1 使用](#2.1 使用)
-
- [2.2 解释](#2.2 解释)
- 五、pytest标记:mark
一、前言
各位老铁们好,从本期开始,我们就进入到自动化测试的学习了,我会陆续更新接口自动化、UI自动化、app自动化等等笔记干货,我们本期会从接口自动化开始,那么话不多说,我们开始本期的内容:
本期我们会带你了解什么是pytest、测试框架和测试插件、pytest框架执行测试用例的逻辑、pytest参数以及标记等等
我们Python的自动化绝大部分是基于框架去执行的,所以我们的自动化会围绕着pytest测试框架展开。
二、pytest测试框架详解
目标:
- 测试框架是什么
- pytest常见的插件
- pytest框架功能
1、测试框架是什么
不同的编程语言都会有对应的测试框架,比如在Python这门语言中的测试框架是unittest和pytest。
再比如我们Java这门语言中,它的测试框架是JUnit和testing。
我们要认识到1点,软件测试是我们软件工程中必不可少的一环,那么类似的测试框架是我们编程语言中进行编码和开发必不可少的东西。
我们为什么会这样的去做呢?为什么有框架呢?也就是说我们为什么做自动化测试的时候一定要有框架呢?因为它能够很方便的去帮助我们实现自动化的落地,比如我们的测试框架它可以和selenium、requests、appium进行一个集成,从而呢很方便的实现web自动化、api自动化、app自动化的落地。
其实我们不用测试框架,也是可以能够实现落地的,但是他们会有很多的阻碍和困难,相当之麻烦,所以我们借助测试框架比如pytest,然后集成一些对应的库,其实我们做自动化测试就会相当之轻松。
2、pytest常见的插件
2.1 插件介绍以及
我们的Python语言中测试框架主要有两个:unittest和pytest,我们选择使用pytest。
在这里我们为什么会选择pytest,而不选择unittest?
首先unittest它是我们Python自带的一个测试框架,而这个pytest的是需要我们去安装的,那为什么我们不用它自带的,而用第三方安装的呢?
因为pytest它有一个很庞大的插件生态,可以有很多的插件去支持它安装,这样的话这些插件就可以给框架提供很多很多的功能。
- pytest:框架本身,框架本身它的功能是有限的,所以得需要一些插件来对其功能进行扩展。
- pytest-html插件:可以为pytest框架扩展的功能是能够生成html报告。
- pytest-xdist插件:可以为pytest框架扩展的功能是能够分布式执行,也就是在不同的电脑上执行。
- pytest-order插件:可以为pytest框架扩展的功能是自定义用例的执行顺序,哪些用例先执行,哪些后执行?
- pytest-rerunfailures插件:可以为pytest框架扩展的功能是,当某个用例失败的时候,我们可以重新运行。
- pytest-base-url插件: 可以为pytest框架扩展功能是我们可以管理我们的base url环境路径
- allure-pytest:可以为pytest框架扩展功能是生成allure的测试报告。
2.2 安装插件
了解完上述这些之后,我们就知道会用什么?该用什么?那具体怎么用呢?首先我们的这些框架和插件给安装了。
pytest的这个框架本身是需要安装的,安装完之后再去安装它的插件。
怎么安装?主要有两种方式:单独安装和批量安装
2.2.1 单独安装
单独安装使用的语法如下:
bash
pip install 第三方库名2.2.2 批量安装
首先我们将内容保存到文件requirements.txt中
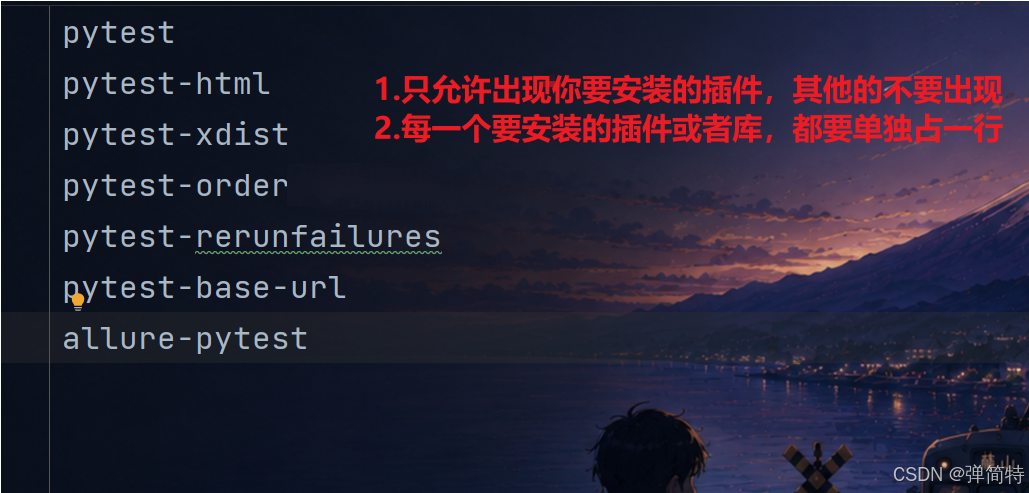
注意: 文件中只能出现你要安装的库,不要出现其他东西;每一个库单独占一行
然后再去读取这个文件,再将里面的插件进行安装
执行以下命令:
bash
pip install -r requirements.txt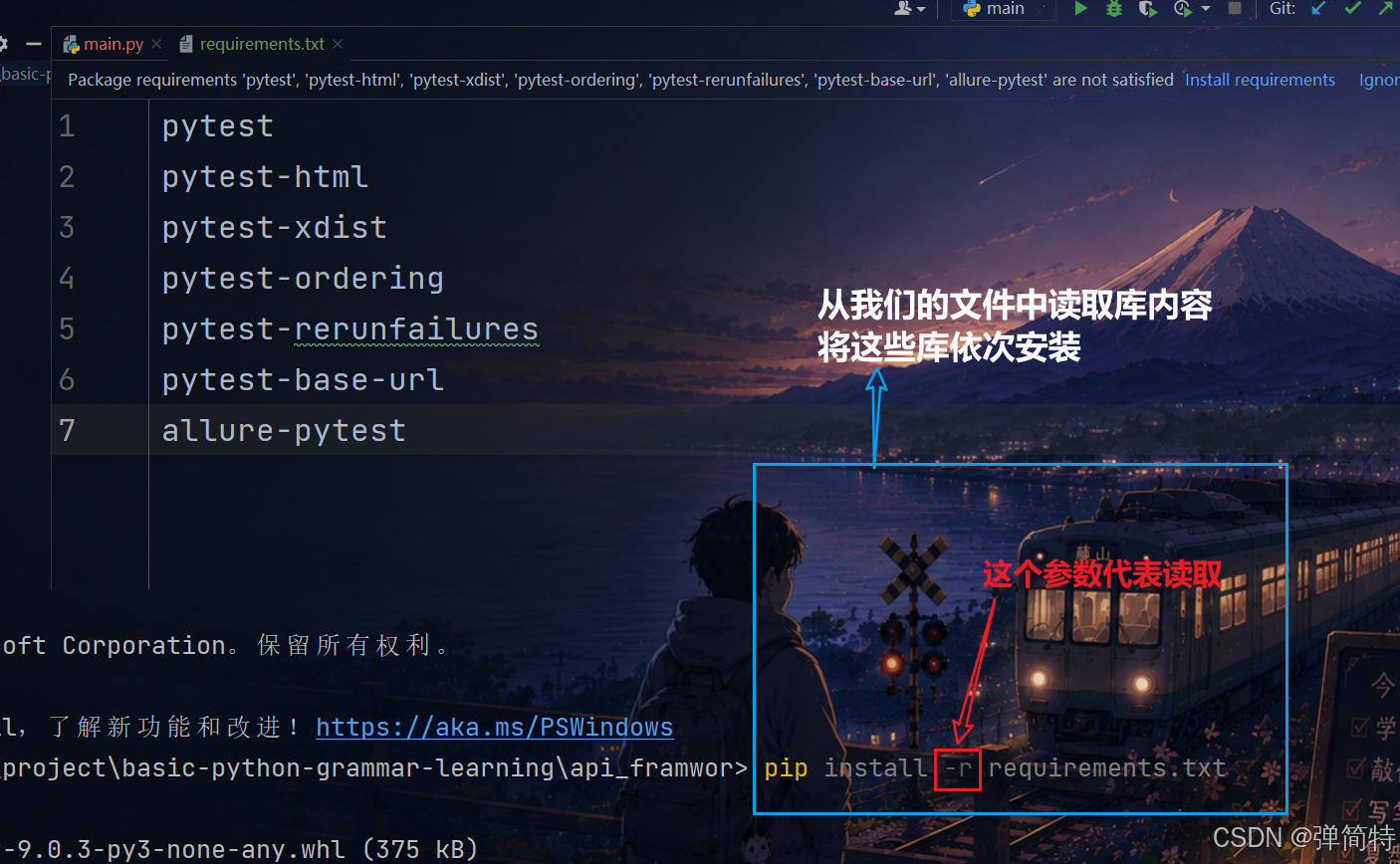
2.2.3 验证安装
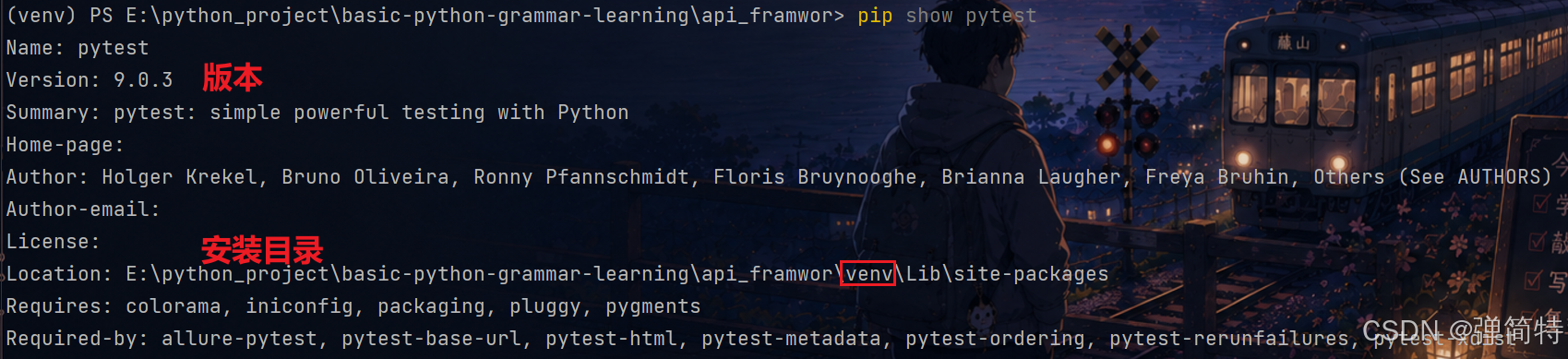
命令:
bash
pip show 库名 示例:
pip show pytest
3、pytest框架功能
pytest作为一个测试框架,它的功能是什么呢?
3.1 pytest功能-发现测试用例
-
pytest框架他可以从多个Python文件中去收集加载测试用例,你不需告诉他是哪个Python文件,它有一个自己的加载规则:
- a. 首先它会遍历本项目所有的目录(注意:venv目录除外,这个目录不会被遍历)
- b. 找到目录之后,它会遍历这些目录中的所有
.py文件(并不是所有的.py文件给我的遍历 ,只有名字是以test_开头 或者_test结尾的文件才会被遍历。为什么会有这样的一个规定呢?因为pytest是测试框架,我只加载你测试相关的文件,那么你py文件有的是数据处理的,有的是开发的,我如何区分我要加载哪一个文件呢?我就通过名称的维度来辨别我要加载的是测试相关的文件。) - c. 找到对应的文件之后,我们要收集该文件中所有一
test_开头的函数(重点:只有函数才是用例,一个函数就是一个测试用例,我们真正要加载收集的用例其实最终就是找到你的函数)
-
在第1步中收集加载完测试用例之后,我们pytest就会去执行测试用例:按照一定的顺序和条件进行执行。
-
执行完测试用例之后,pytest框架它会判断测试用例的结果:判断测试结果,我们有个术语叫做断言,它会判断我们预期结果 和实际结果是否一致。
-
判断完毕用例之后,我们的这个pytest框架会生成测试报告:报告中包含有用例数量,花费的时间,失败的原因,测试通过率等等。
框架能为我们做上述的事情,如果你不用框架,纯手搓的话,每一个过程你都得自己设计,会非常之麻烦。
三、pytest创建和执行用例
我们的工作都是围绕着测试用例展开的,那么我们上述说了pytest框架可以干什么之后,我们现在来体验一下这个框架。
这个框架简单流程就是:你输入测试用例,他会输出测试结果
所以我们需要掌握什么:
- 你得创建测试用例吧
- 让框架给我们执行测试用例
- 框架执行完测试用例之后会有执行结果,你得看得懂执行结果吧
所以接下来就围绕这三个步骤展开。
1、创建测试用例
你怎么创建测试用例呢?
我们前面已经了解过了这个框架去加载测试用地的规则,所以我们创建测试用例得遵循人家的规则,才能让框架找得到。这种思想就是我们的约定大于配置,想用人家的框架,那么你就得遵守人家的约定。
1、约定:我们创建py文件的时候要以test_开头
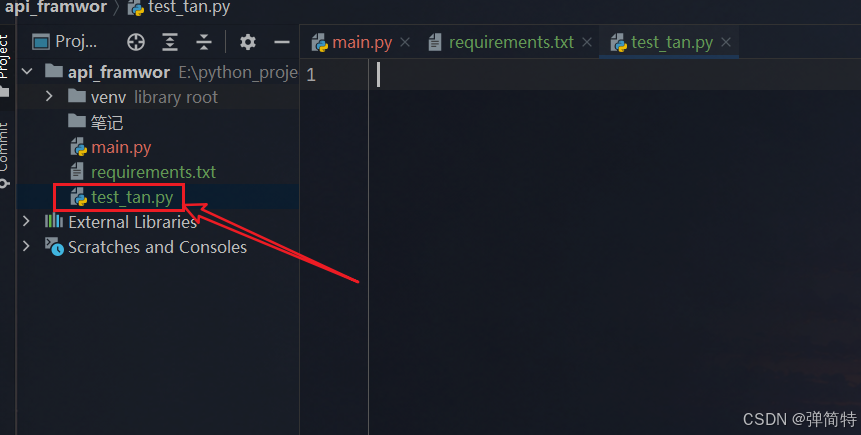
2、约定:在这个测试文件中,创建以test_开头的测试用例(函数),一个函数就是一个测试用例
py
def test_tan():
# 在此处开始断言
# 断言有两个值:一个是预期结果,一个是实际结果
# 那么预期结果和实际结果不一致,我们的断言就会失败
assert 1 == 2
def test_my():
# 断言成功
assert 1 == 1
2、执行测试用例
此处我们说是执行用例,其实实际上是我们要去启动我们的pytest测试框架,然后我们的框架会自动的发现和执行测试用例。
2.1 启动框架方式1:命令行方式
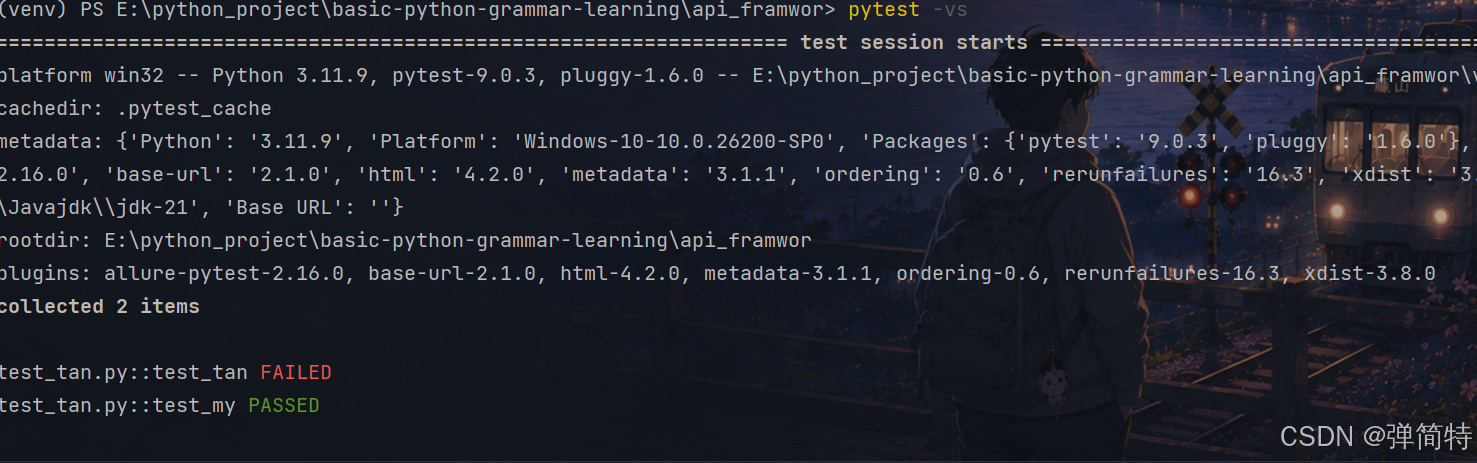
bash
pytest -vs结果:
2.2 启动框架方式2:主函数main方法
1、创建一个main.py的文件
2、将我们的pytest导入进来
3、调用pytest框架的主函数
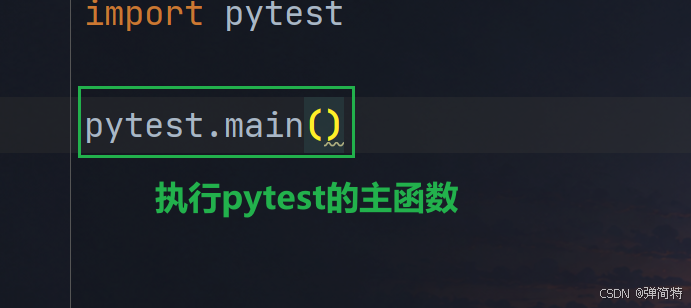
py
import pytest
pytest.main()结果:
3、看懂执行的结果
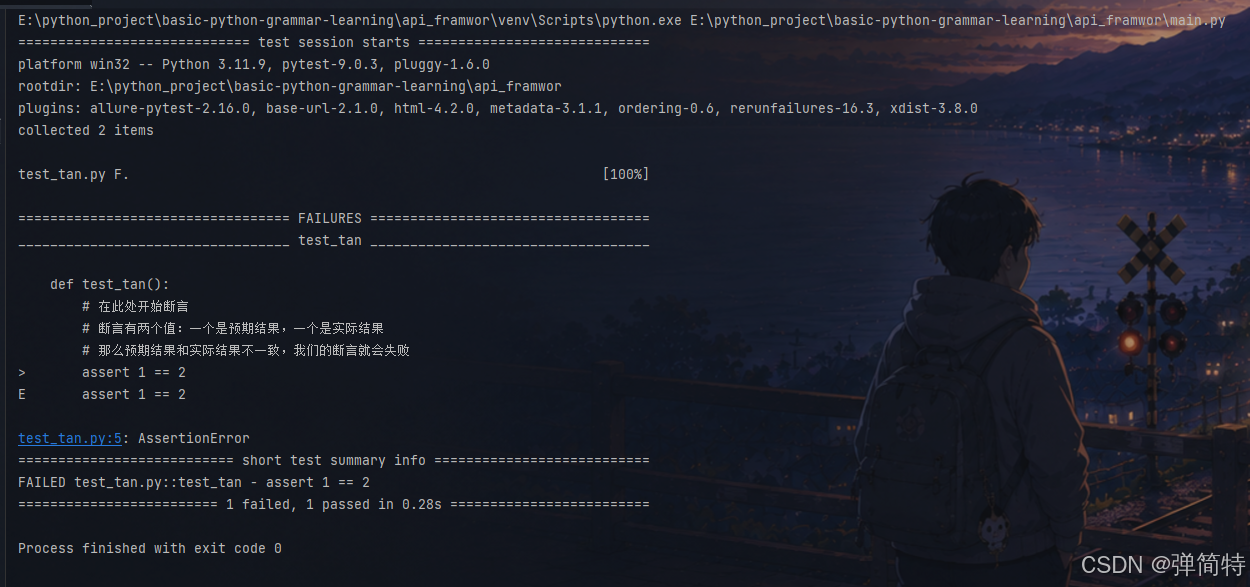
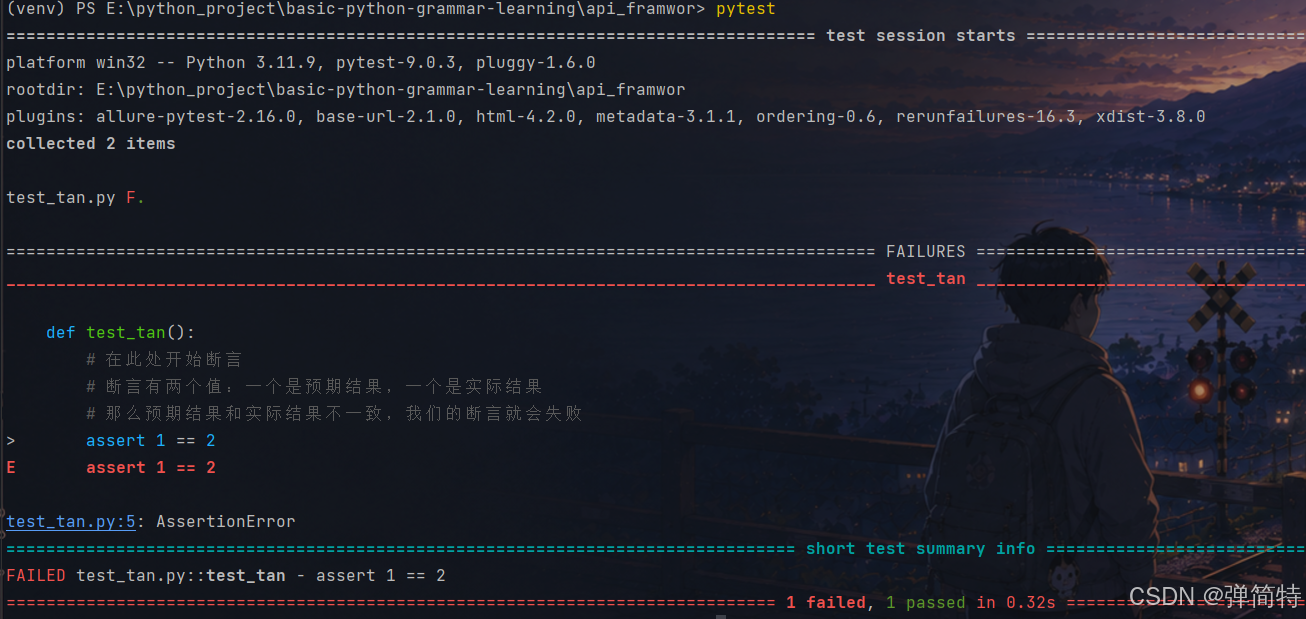
执行结果:
py
============================= test session starts =============================
platform win32 -- Python 3.11.9, pytest-9.0.3, pluggy-1.6.0
rootdir: E:\python_project\basic-python-grammar-learning\api_framwor
plugins: allure-pytest-2.16.0, base-url-2.1.0, html-4.2.0, metadata-3.1.1, ordering-0.6, rerunfailures-16.3, xdist-3.8.0
collected 2 items
test_tan.py F. [100%]
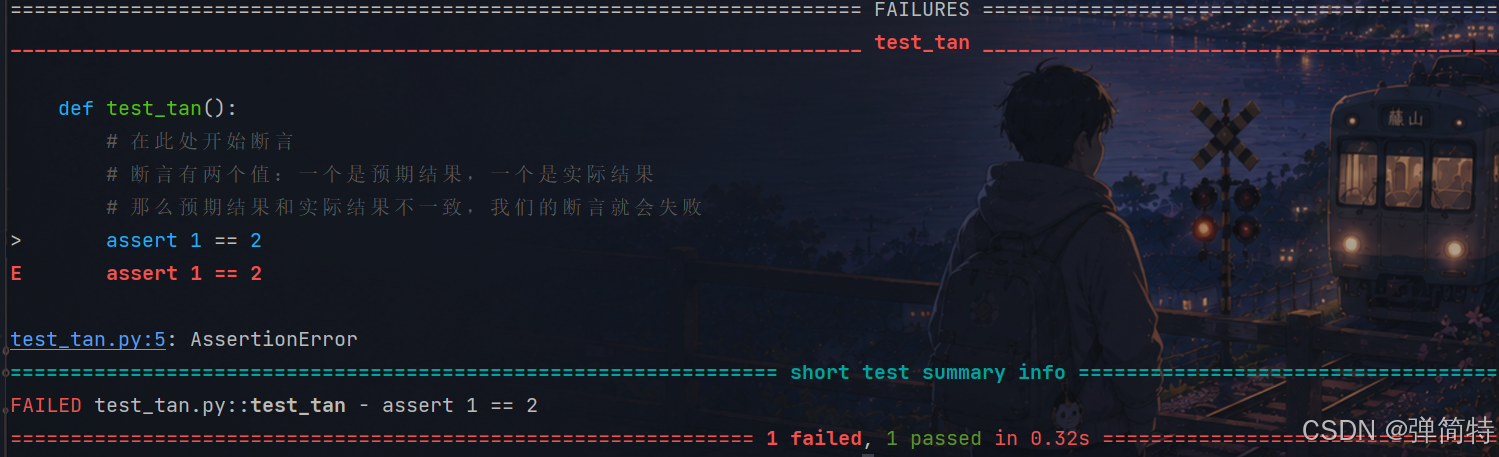
================================== FAILURES ===================================
__________________________________ test_tan ___________________________________
def test_tan():
# 在此处开始断言
# 断言有两个值:一个是预期结果,一个是实际结果
# 那么预期结果和实际结果不一致,我们的断言就会失败
> assert 1 == 2
E assert 1 == 2
test_tan.py:5: AssertionError
=========================== short test summary info ===========================
FAILED test_tan.py::test_tan - assert 1 == 2
========================= 1 failed, 1 passed in 0.28s =========================
Process finished with exit code 03.1 pytest的执行环境
py
platform win32 -- Python 3.11.9, pytest-9.0.3, pluggy-1.6.0 # 版本
rootdir: E:\python_project\basic-python-grammar-learning\api_framwor # 目录
plugins: allure-pytest-2.16.0, base-url-2.1.0, html-4.2.0, metadata-3.1.1, ordering-0.6, rerunfailures-16.3, xdist-3.8.0 # 插件3.2 用例的收集情况
py
collected 2 items # 收集了两个用例3.3 用例的执行情况
py
test_tan.py F. [100%]

用例结果的缩写:
.: 表示通过(pass)- F:表示失败(Failed)
F.:表示有一个失败,有一个通过,也说明这个文件有两个用例s:表示跳过(skip)x:表示预期外的通姑(xpassed)X:表示预期内的失败(Xfailed)
3.4 用例的执行失败原因
注意:通姑的用例我们不关心,我们关心失败的用例,所以我们才会有显示失败的原因
py
================================== FAILURES ===================================
__________________________________ test_tan ___________________________________
def test_tan():
# 在此处开始断言
# 断言有两个值:一个是预期结果,一个是实际结果
# 那么预期结果和实际结果不一致,我们的断言就会失败
> assert 1 == 2
E assert 1 == 2
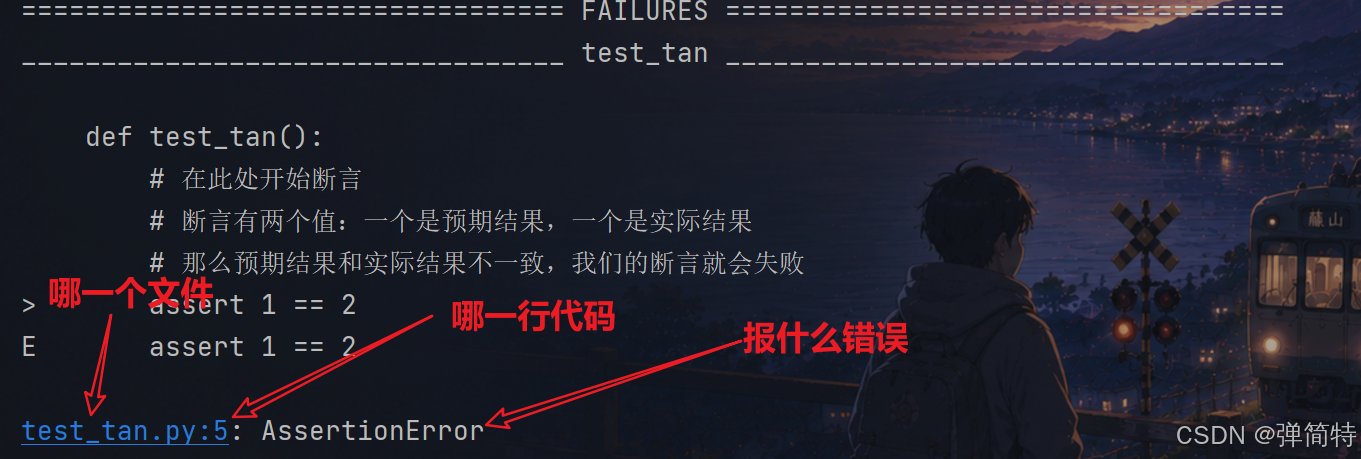
test_tan.py:5: AssertionError # 断言错误❌️首先会显示代码:
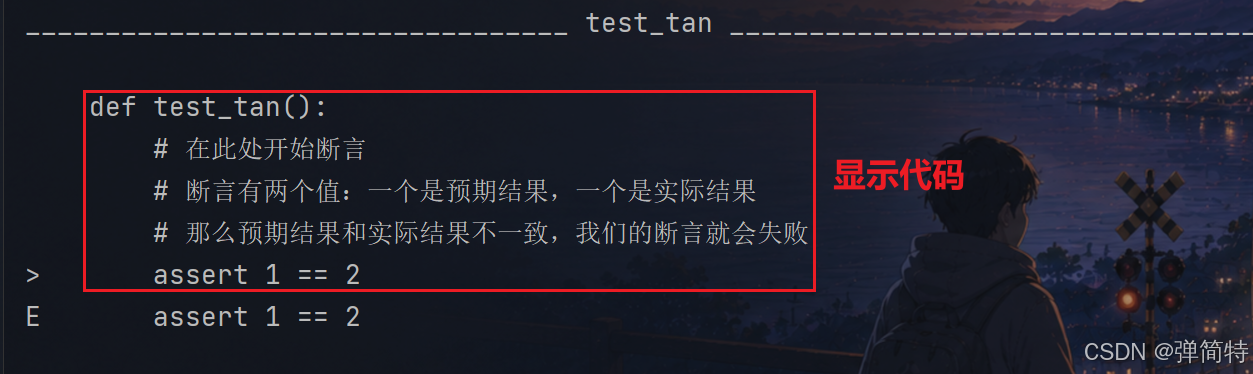
这个代码中哪一个代码报错:
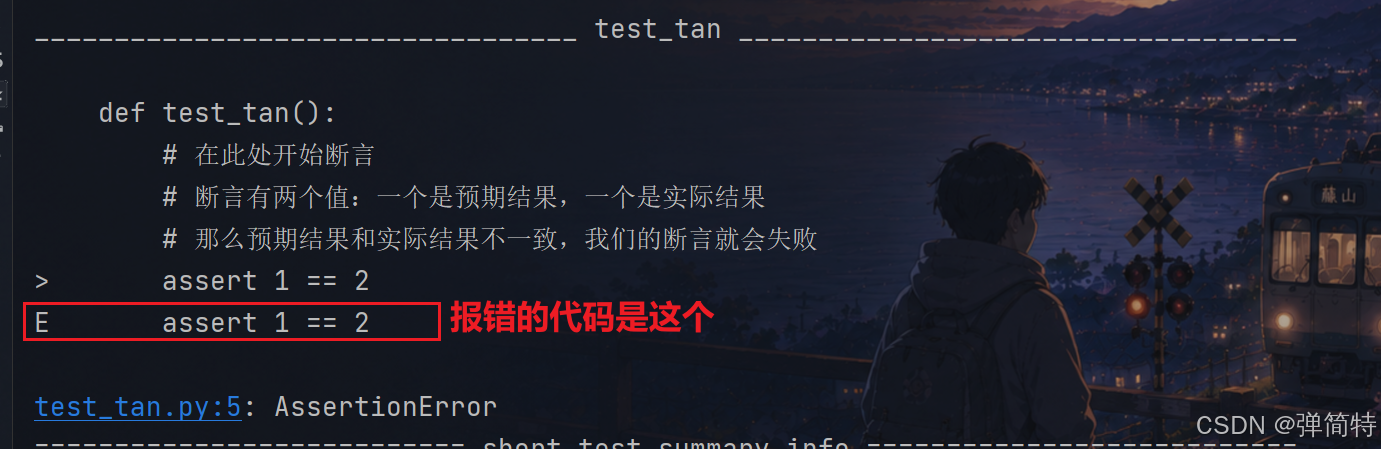
哪一个文件的哪一行代码,报了什么错:
3.5 总结性的信息
py
=========================== short test summary info ===========================
FAILED test_tan.py::test_tan - assert 1 == 2
========================= 1 failed, 1 passed in 0.28s =========================哪一个文件的哪一个用例因为什么原因失败了:
py
FAILED test_tan.py::test_tan - assert 1 == 2 成功的有几个?失败的有几个?一共花费多少时间?
py
========================= 1 failed, 1 passed in 0.28s =========================四、pytest常用参数和配置文件
我们为什么要去用这个框架的参数以及配置?其实原因很简单,如果你不去配置。那么你就是按照他的默认规则去使用这个框架。而如果我们不想按照它的默认规则,那就得进行一些配置。
不同的参数,不同的配置能够实现不同的效果,我们主要介绍:
- 命令行参数
- 配置文件(pytest.ini)
1、命令行参数
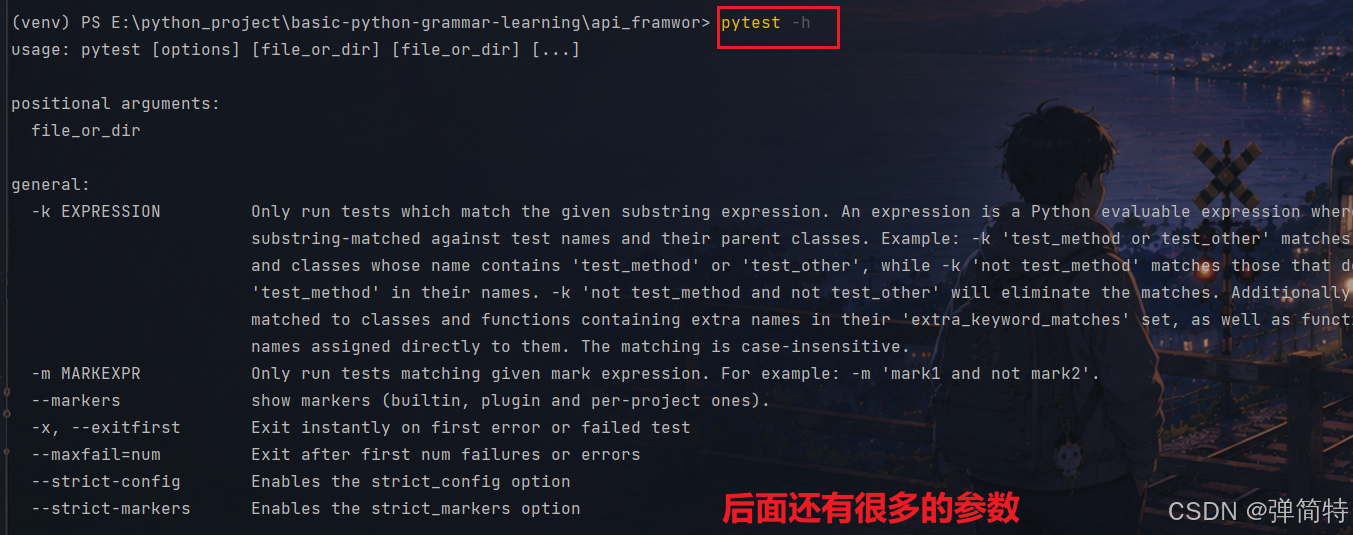
获取pytest框架中的所有参数命令:
bash
pytest -h- pytest是命令
-h是参数
结果:
1.1 常用的命令行参数
-h:显示帮助信息和参数、配置信息-v:增加结果的详细程度-q:减少结果的详细程度-s:关闭IO捕获,input和print可以正常执行-m:根据标签筛选用例-k:根据用例名筛选用例-n:使用多进程分布式执行(插件提供)--reruns:失败重跑的次数(插件提供)--html:生成HTML报告(插件提供)
例如:
pytest
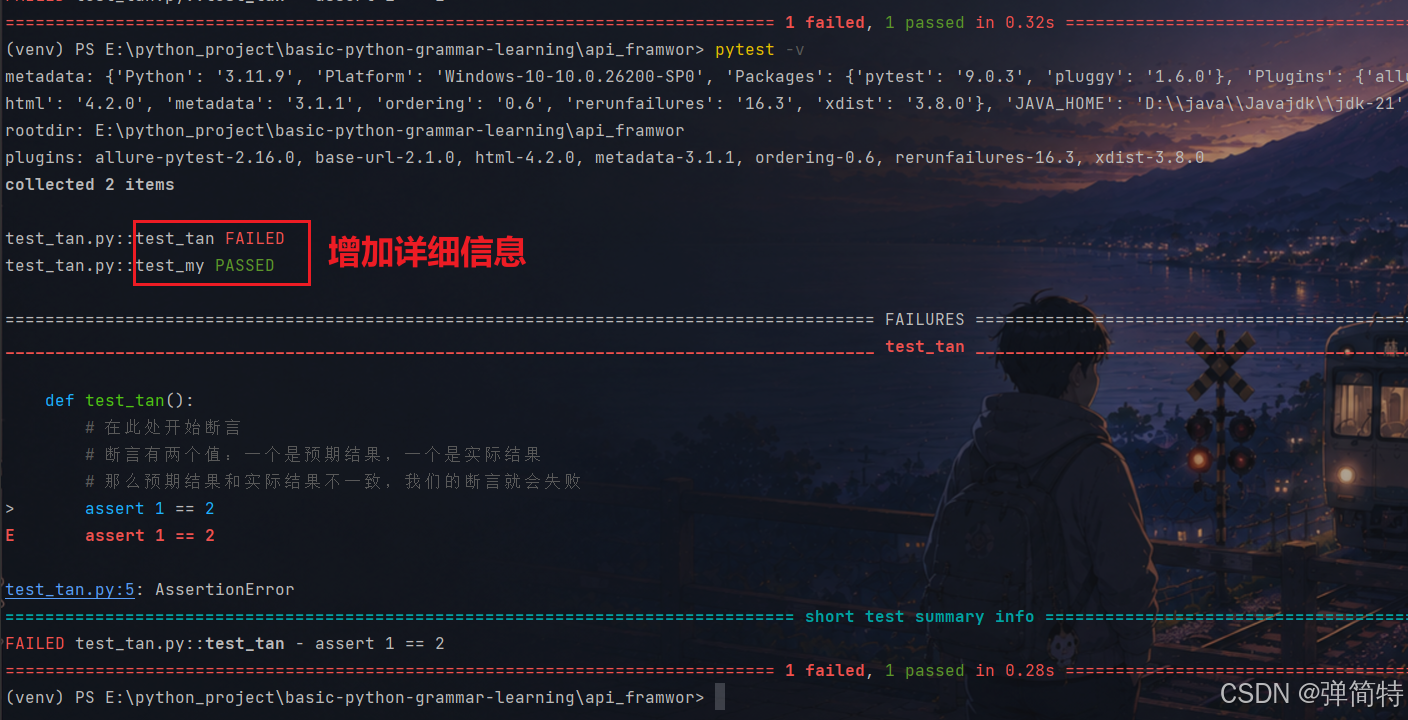
1.2 -v
pytest -v
1.3 -q
pytest -q
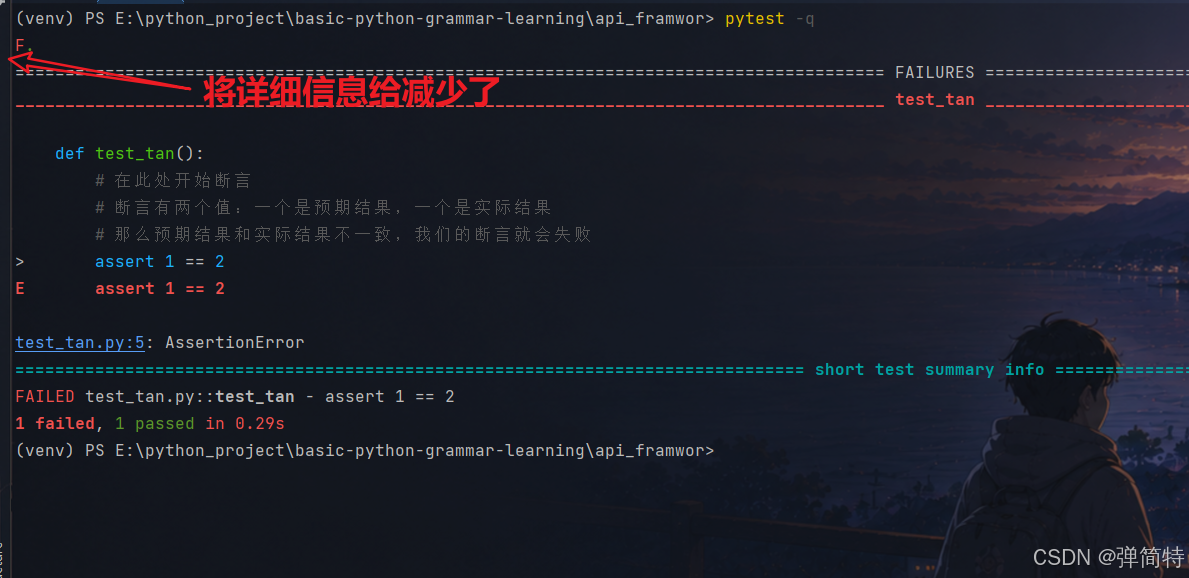
1.4 -s
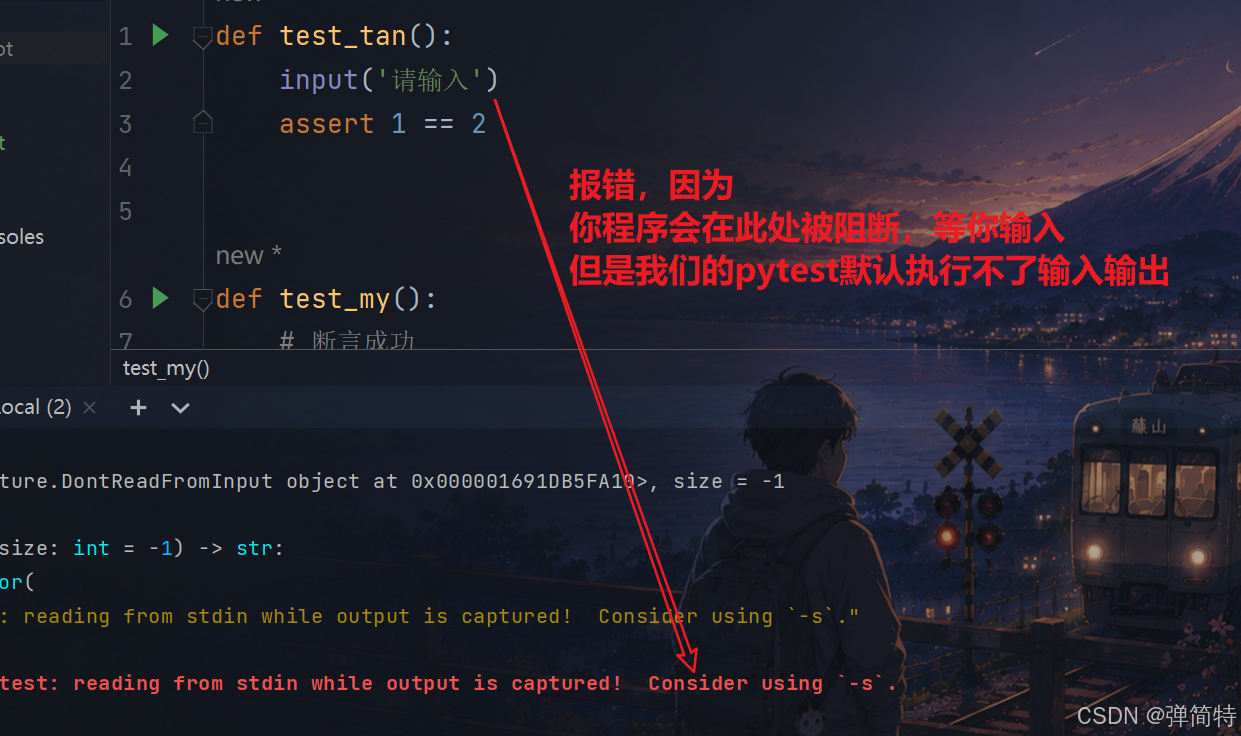
pytest -s
首先看一个例子:
我们如果测试用例中有输入输出,那么就会被捕获
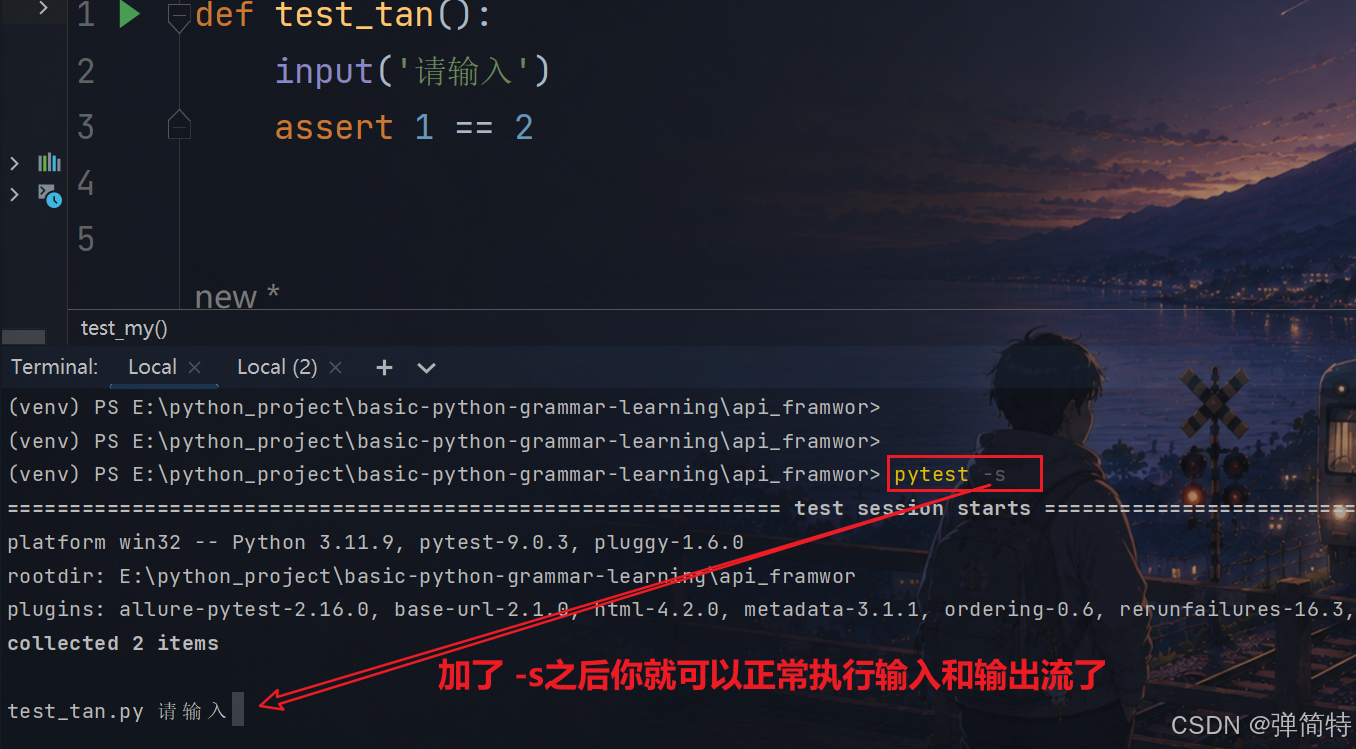
解决办法就是加一个-s参数
1.5 -k
-k 参数是根据用例名筛选用例
语法:
pytest -k 名字
- 名字:代表筛选想要执行的测试用例文件或者函数名(用例名),他是一个通配符,你不用写完整的用例名(哪一个文件哪一个函数),他会去匹配。
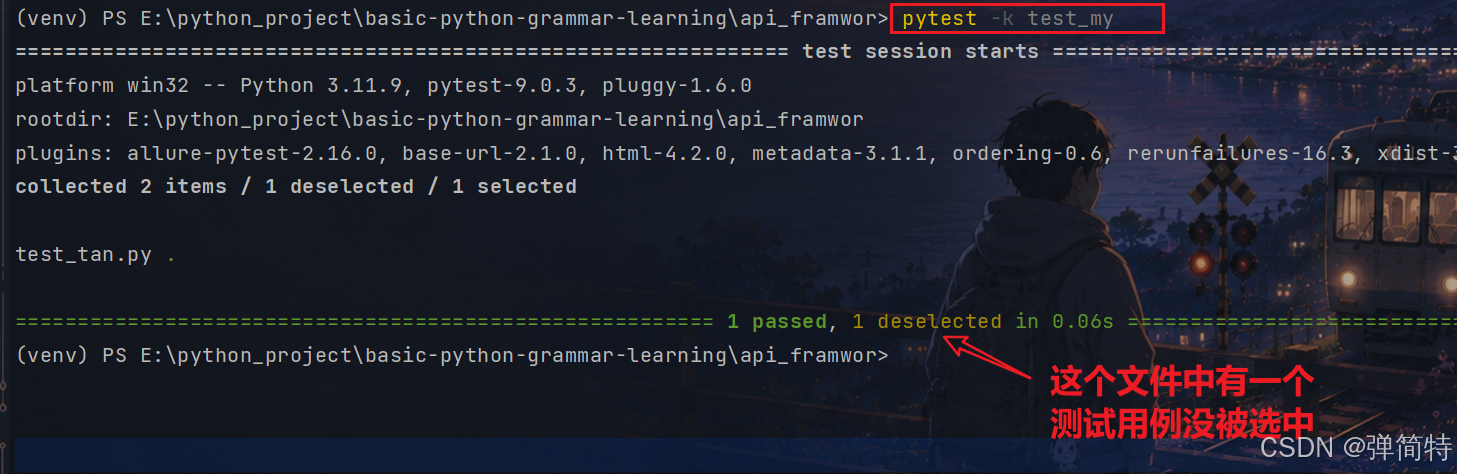
比如你看,我现在两个测试用例,有一个是通过的,有一个是不通过的,那么现在我要筛选执行,我只执行正确的测试用例
py
============================================================== test session starts ==============================================================
platform win32 -- Python 3.11.9, pytest-9.0.3, pluggy-1.6.0
rootdir: E:\python_project\basic-python-grammar-learning\api_framwor
plugins: allure-pytest-2.16.0, base-url-2.1.0, html-4.2.0, metadata-3.1.1, ordering-0.6, rerunfailures-16.3, xdist-3.8.0
collected 2 items / 1 deselected / 1 selected
test_tan.py . [100%]
======================================================== 1 passed, 1 deselected in 0.06s ========================================================可以看到collected 2 items / 1 deselected / 1 selected 这个用例的收集情况代表的是,我找到两个用例,但是有一个用例我是未选中状态,你执行的是你筛选的用例;我们选择了一个用例,另一个我们不选择,所以不选择的我们不执行。
1.6 -m
我们说-k 你后面跟的参数不是精准匹配,说白了,他不是哪一个具体的测试用例,他是模糊匹配的,我们怎么做让他变为精准匹配呢?
我们使用-m参数 此时我们就使用标记,我给你某个参数打上标签,然后你就可以通过这个标签名直接精准匹配到我这个测试用例,标记Mark我们在后面第五点中有介绍。
最后一个知识点,我们在后面用户的标记中有介绍
1.7 -n
-n就是使用多进程分布式执行
举一个例子:
下面两个方法,我如果不使用分布式,那么他们是串行执行的,此时我们会花费20秒
py
import time
import pytest
def test_tan():
time.sleep(10)
assert 1 == 2
def test_my():
time.sleep(10)
assert 1 == 1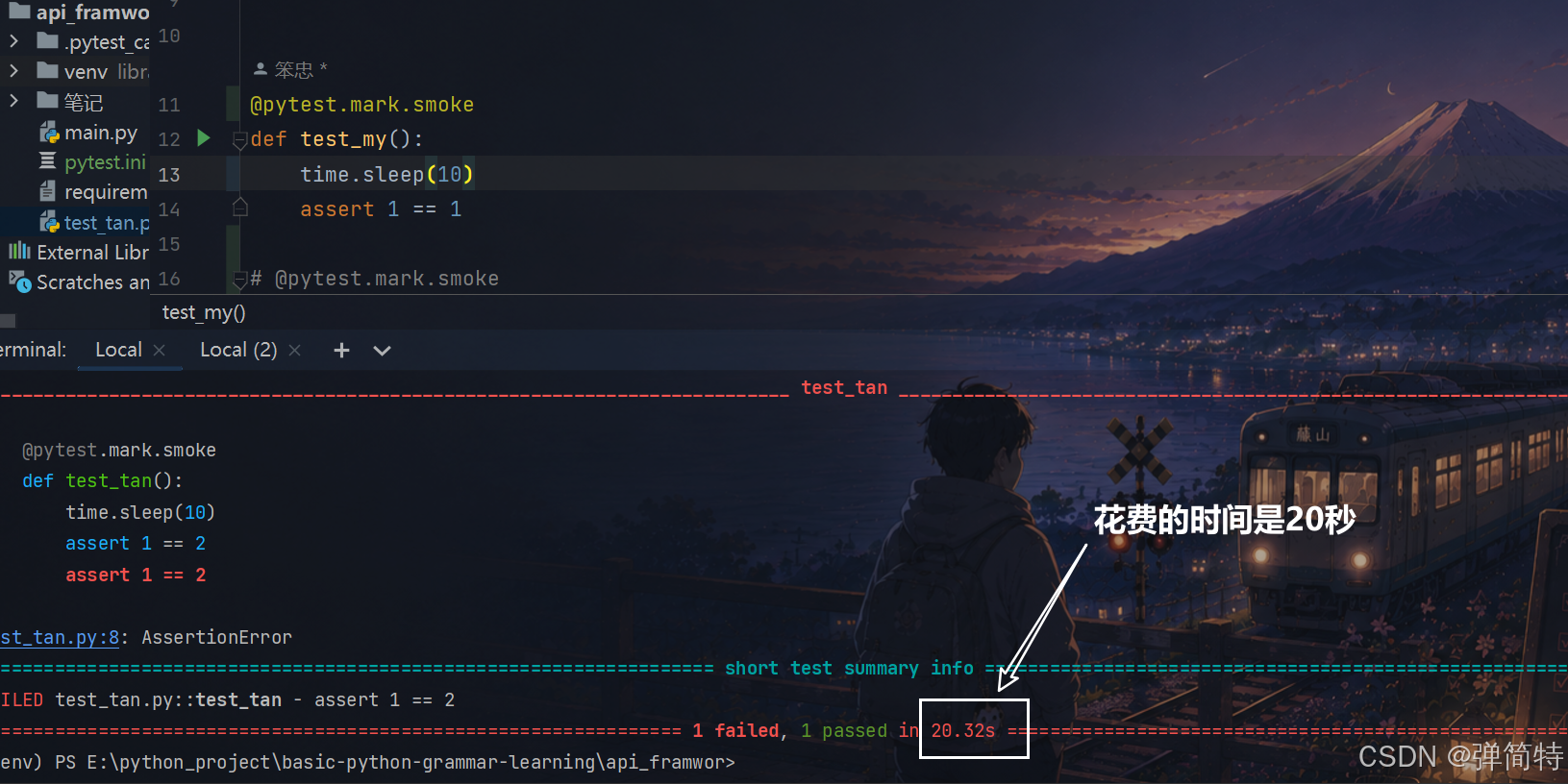
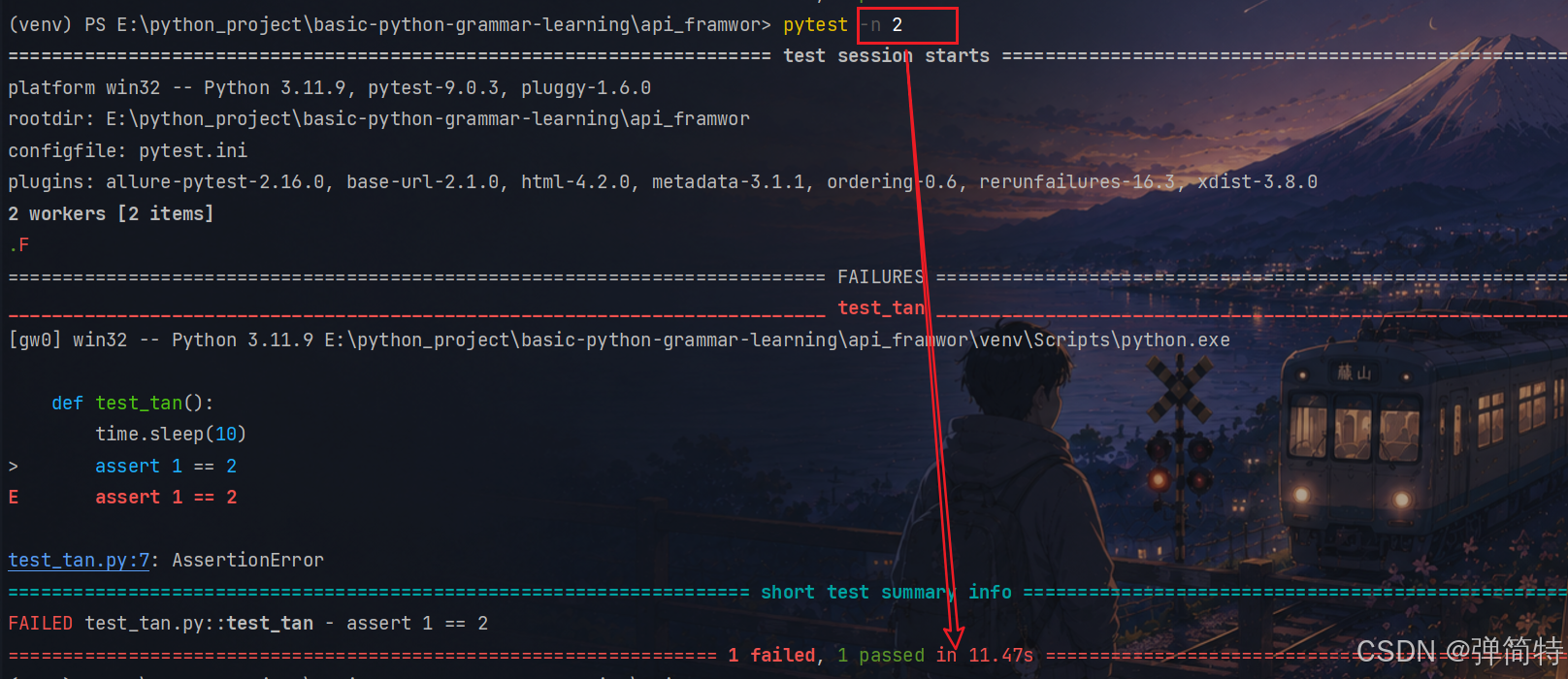
那么此时如果我们使用-n参数
pytest -n 2
那么此时我们就会有两个线程干活,他们会并行干活,一个10秒左右,同时执行,那么我们总的时间就是10秒左右
1.8 --reruns
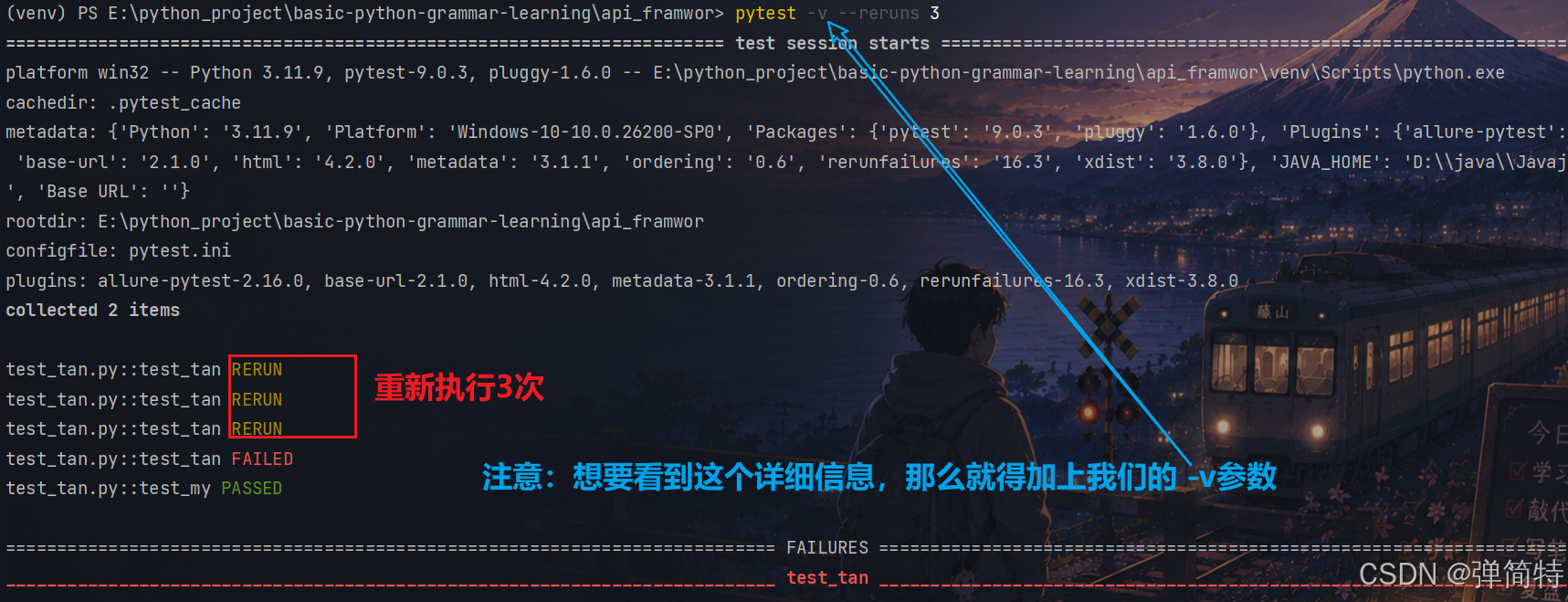
--reruns:失败重跑的次数
如果你测试用例跑失败了,那么我就会让你重新执行
pytest -v --reruns 3 重新执行三次,三次你还失败,那么我就不执行了。
1.9 --html
--html会生成我们的HTML报告
pytest --html=定文件名.html
比如:pytest --html=./report/report.html
我们先创建一个report目录:
结果:
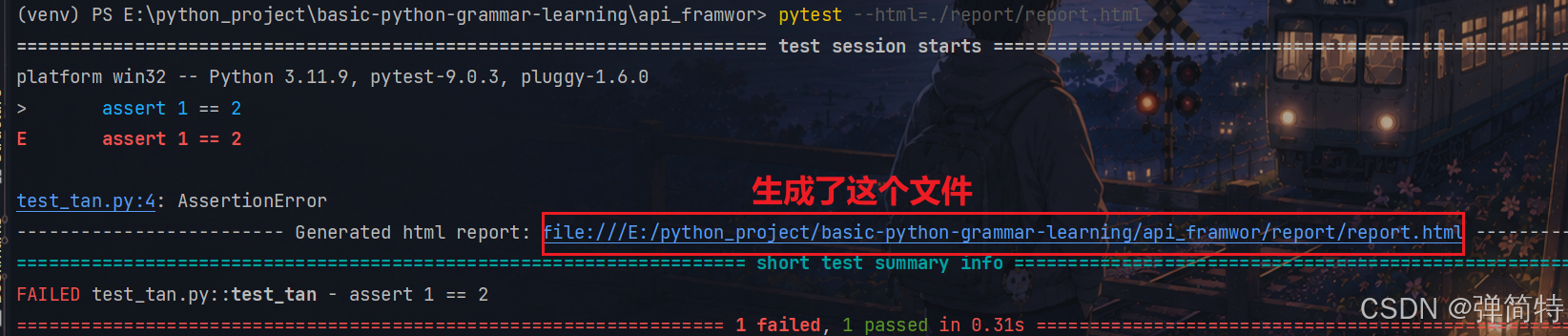
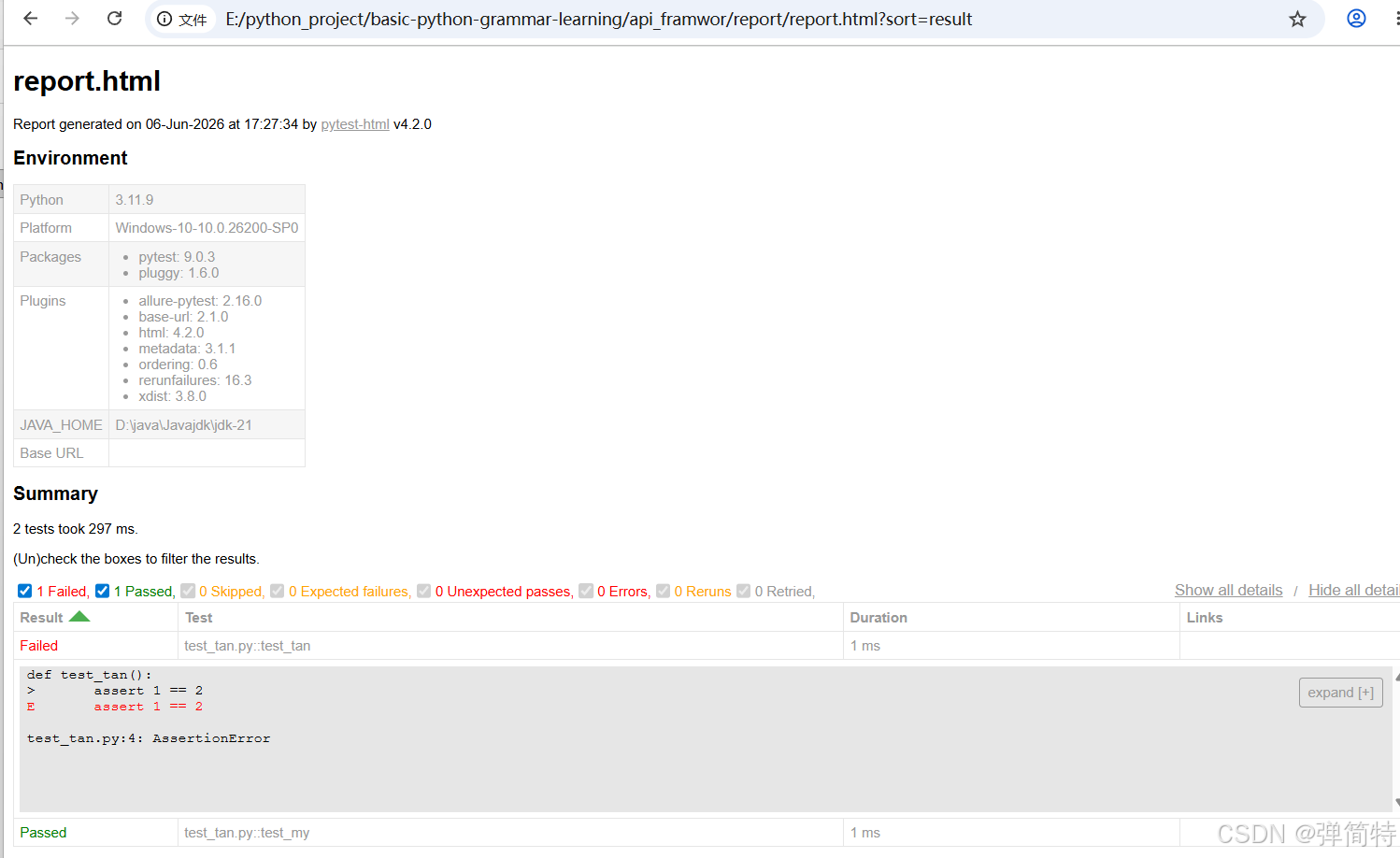
打开这个文件如图:
2、配置文件(pytest.ini)
2.1 使用
1、我们在根目录中创建配置文件,也就是在项目名称下创建配置文件:pytest.ini
 2、创建好配置文件之后不是可以直接使用了,而是需要在我们的配置文件中创建一个节(section) pytest
2、创建好配置文件之后不是可以直接使用了,而是需要在我们的配置文件中创建一个节(section) pytest
pytest 会读取这个节下的配置。
3、然后我们可以按行的写入配置内容:比如写入参数
bash
addopts = -vs -k test_my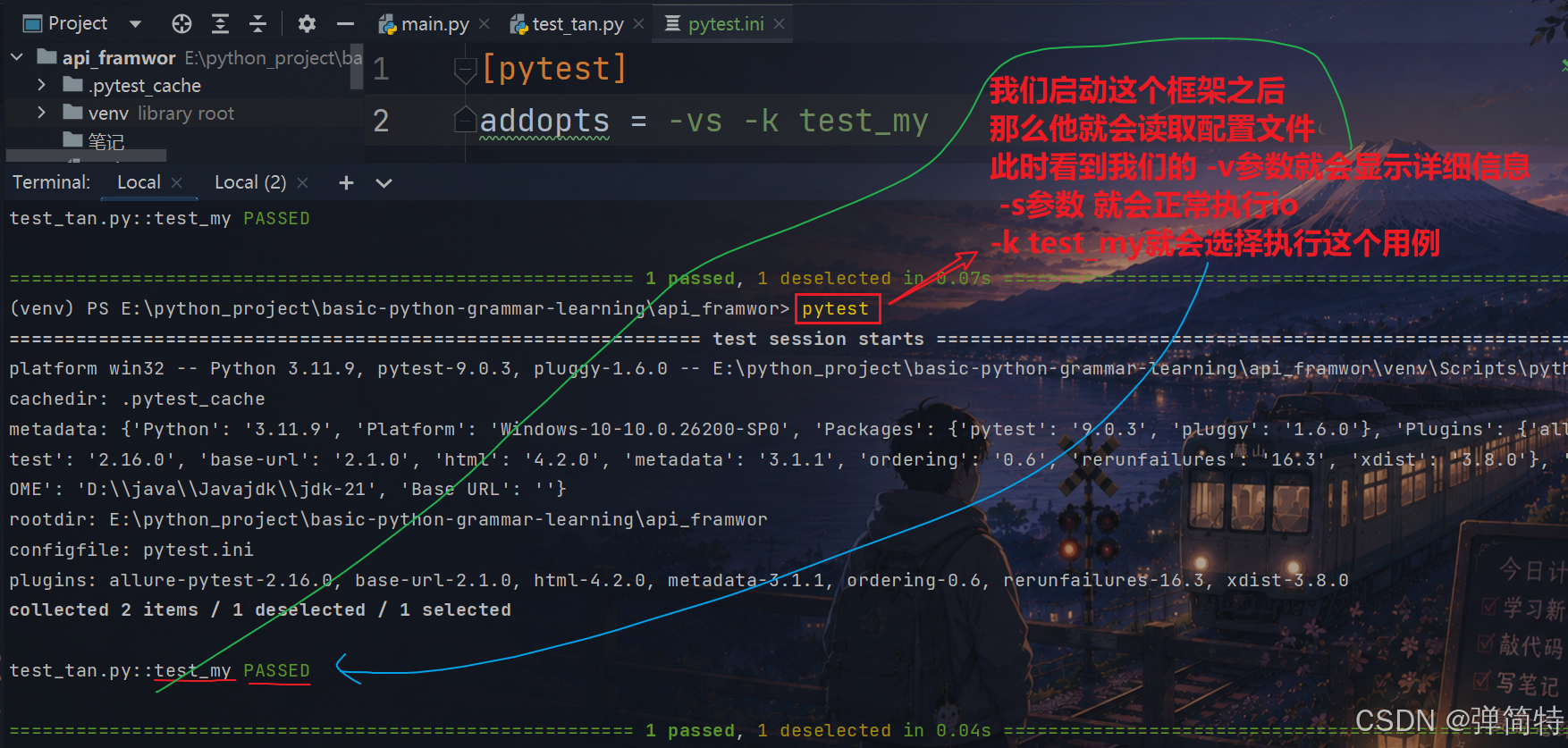
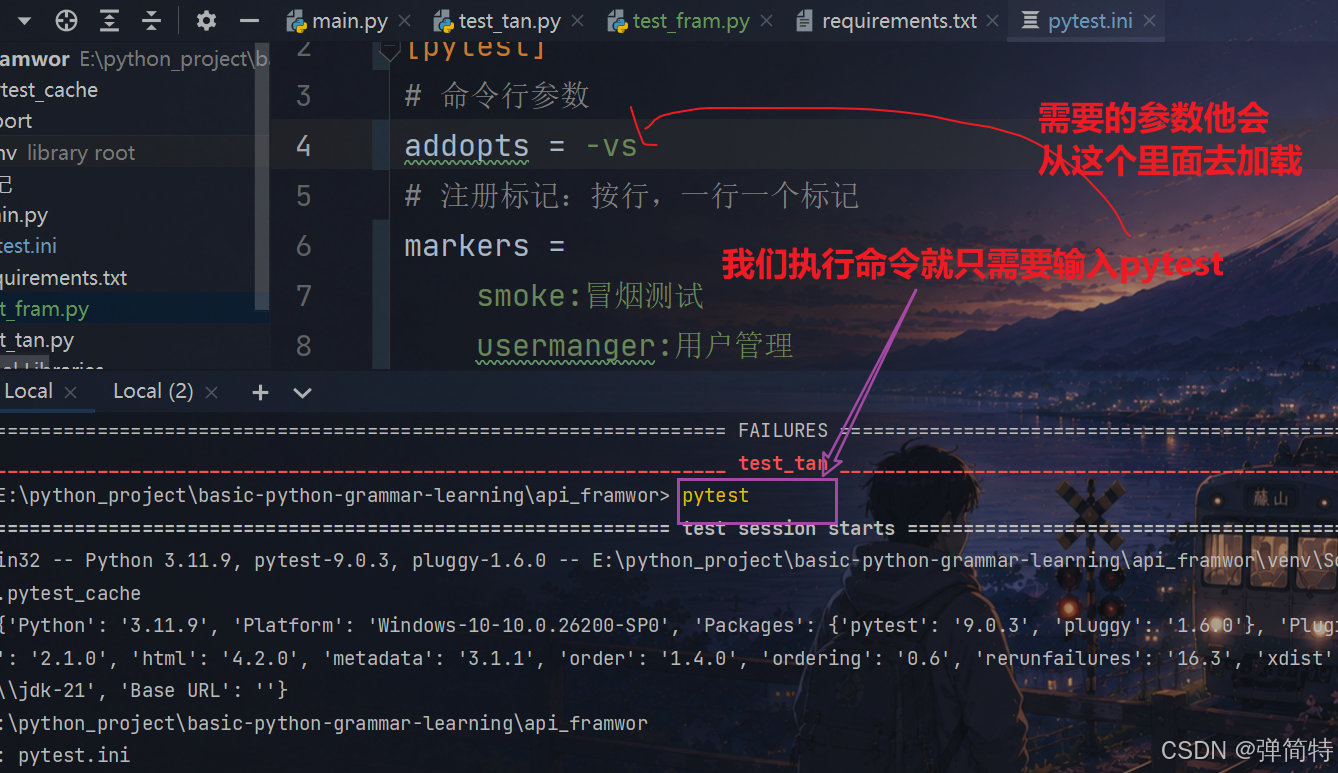
那么你使用配置文件的好处是什么呢?
之前我们没有使用配置文件的时候:我们的命令执行都是pytest -参数
那么现在我们在配置文件中将参数也给配合好,所以你执行命令的时候只需要pytest即可,不需要带参数:
2.2 解释
py
# 节[pytest]:使用pytest的时候会读取这个配置文件
[pytest]
# 命令行参数
addopts = -vs
# 注册标记:按行,一行一个标记
markers =
smoke:冒烟测试
usermanger:用户管理
api:接口用例
ut:单元测试用例在 pytest.ini 中,[pytest] 这一节下面只能使用 pytest 官方定义的配置项名称 ,不能自己随意命名(随意写的键会被忽略)。
下面列出最常用的固定键名及其作用:
| 固定键名 | 作用 |
|---|---|
addopts |
添加默认命令行参数,例如 -vs、-m smoke |
markers |
注册自定义标记(marker),每个标记一行,可带说明 |
testpaths |
指定 pytest 默认搜索测试的目录(相对于配置文件) |
norecursedirs |
指定不递归搜索的目录名,默认有 .git, __pycache__, node_modules 等 |
python_files |
匹配测试文件的命名模式,默认 test_*.py 和 *_test.py |
python_classes |
匹配测试类的类名模式,默认 Test* |
python_functions |
匹配测试函数的函数名模式,默认 test_* |
minversion |
要求 pytest 的最低版本 |
xfail_strict |
设置 xfail 标记的严格模式(布尔值) |
filterwarnings |
设置警告过滤器 |
log_cli |
是否在命令行实时输出日志(布尔值) |
log_file |
日志输出文件路径 |
结论:键名不能随便写,只能用上述约定好的名称。
五、pytest标记:mark
标记分为:
- 用户的标记
- 框架的内置标记
- 插件的标记
1、用户的标记
1.1 标记的使用
怎么使用呢?
先注册,后使用
我们在配置文件 中注册,在命令行参数中使用。
1、在配置文件中注册用例:
py
# 节[pytest]:使用pytest的时候会读取这个配置文件
[pytest]
# 命令行参数
addopts = -vs
# 注册标记:按行,一行一个标记
markers =
smoke:冒烟测试
usermanger:用户管理
api:接口用例
ut:单元测试用例2、给用例加上标记
py
import pytest
@pytest.mark.smoke
def test_tan():
assert 1 == 2
def test_my():
# 断言成功
assert 1 == 1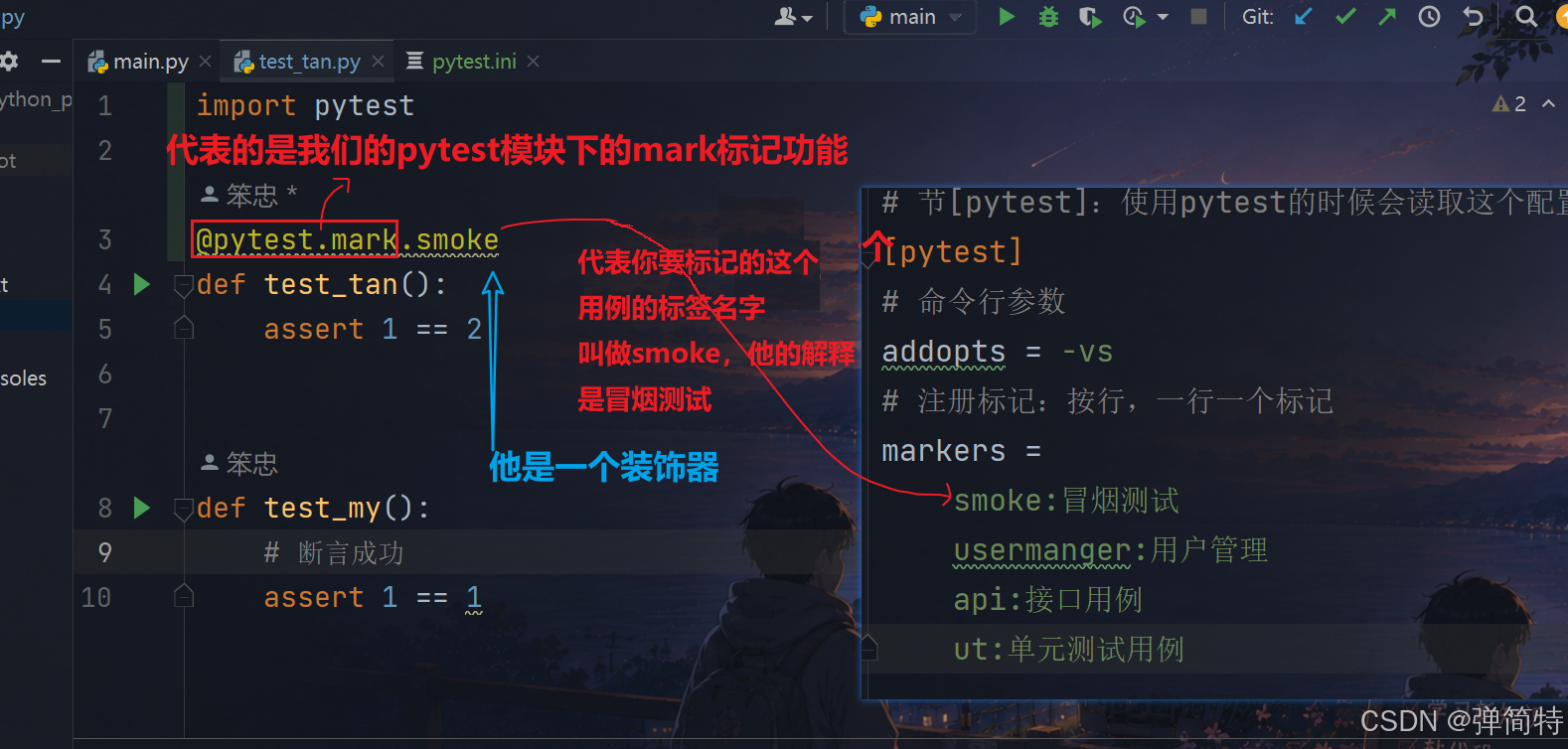
3、在配置文件中 加入命令行参数 -m smoke
py
# 节[pytest]:使用pytest的时候会读取这个配置文件
[pytest]
# 命令行参数
addopts = -vs -m smoke
# 注册标记:按行,一行一个标记
markers =
smoke:冒烟测试
usermanger:用户管理
api:接口用例
ut:单元测试用例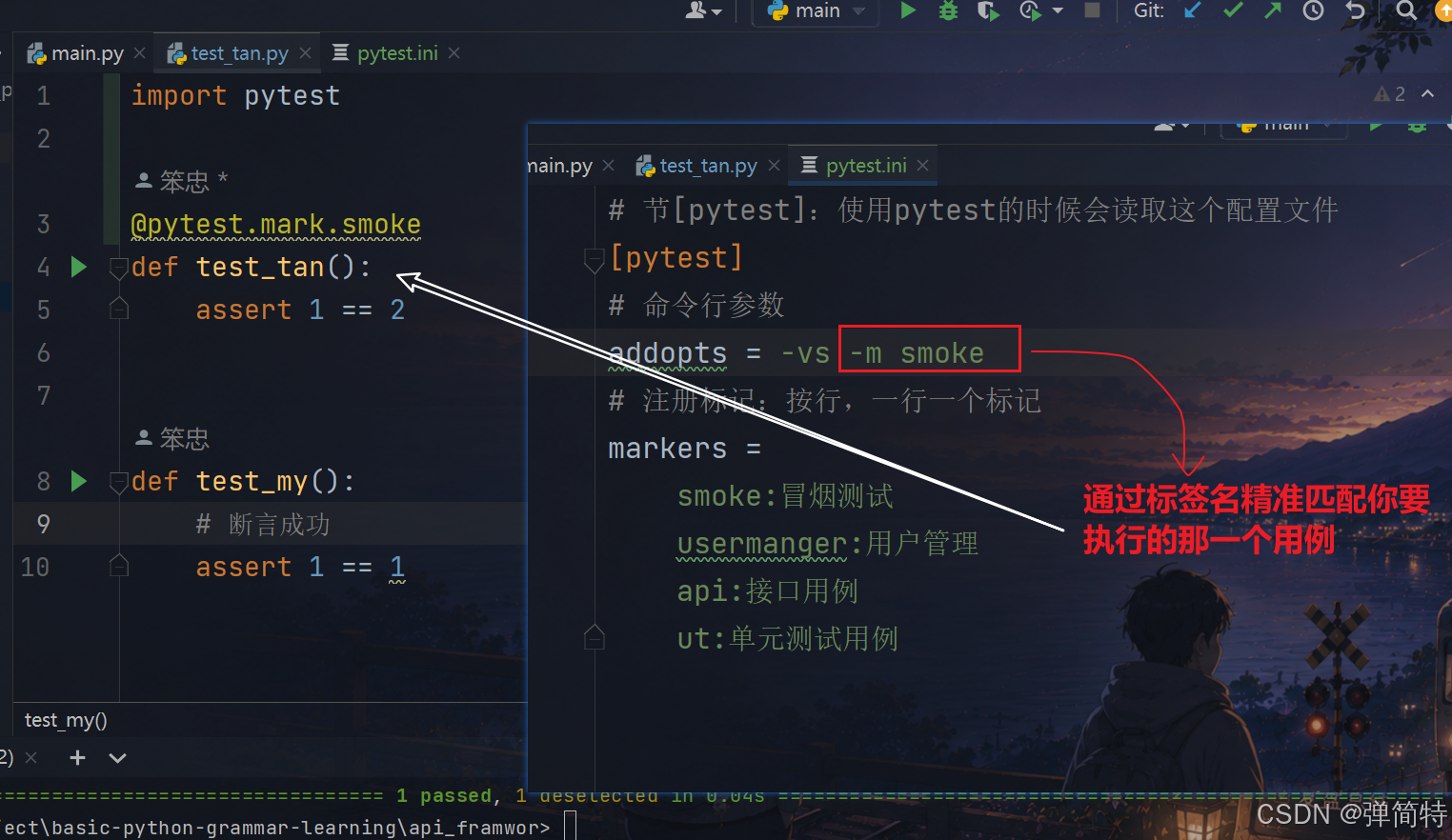
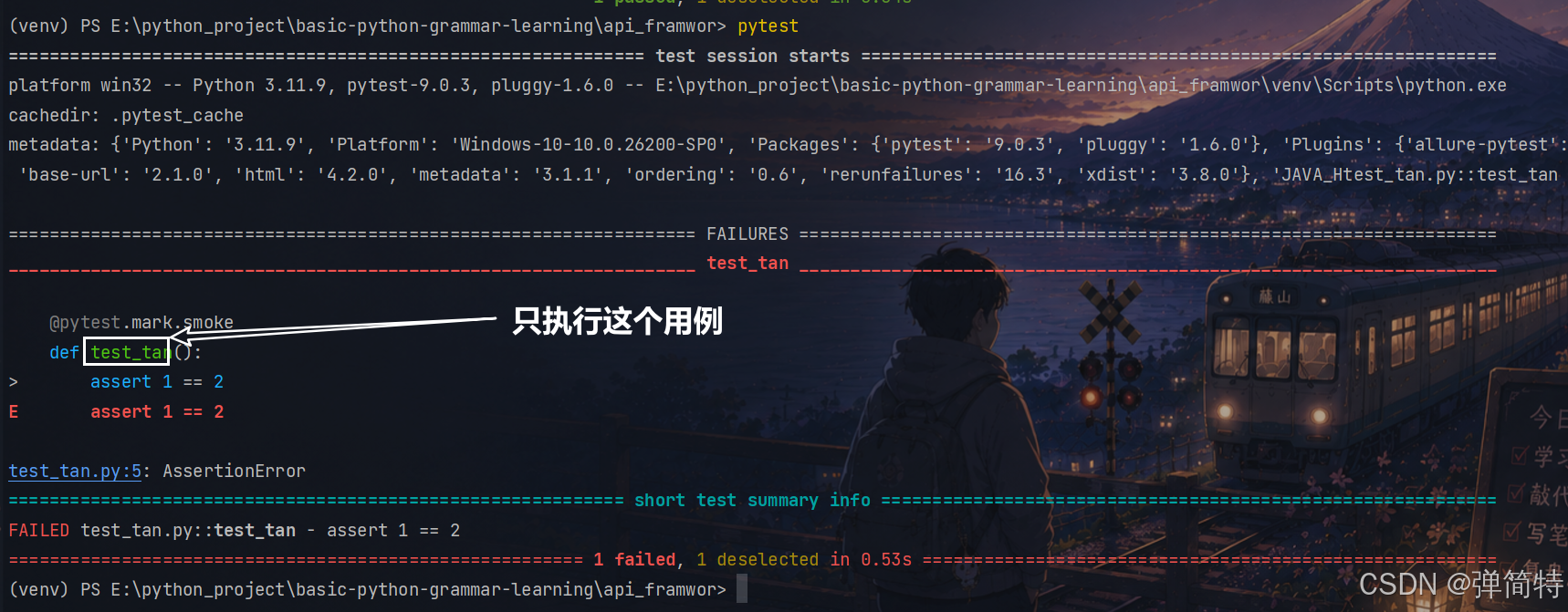
结果:哪一个用例有我们的smoke标记,那么他就只执行哪一个用例,比如我们的
test_tan()用例有这个标记,那么此时他就只会执行我们的test_tan()用例,如下:
1.2 标记的作用以及原理
打上标记有什么作用呢?
我们好比就是给不同的瓶子贴上标签一样
然后你选择装水的瓶子,那么你就直接告诉他,我要装水的,就可以拿到装水的瓶子。
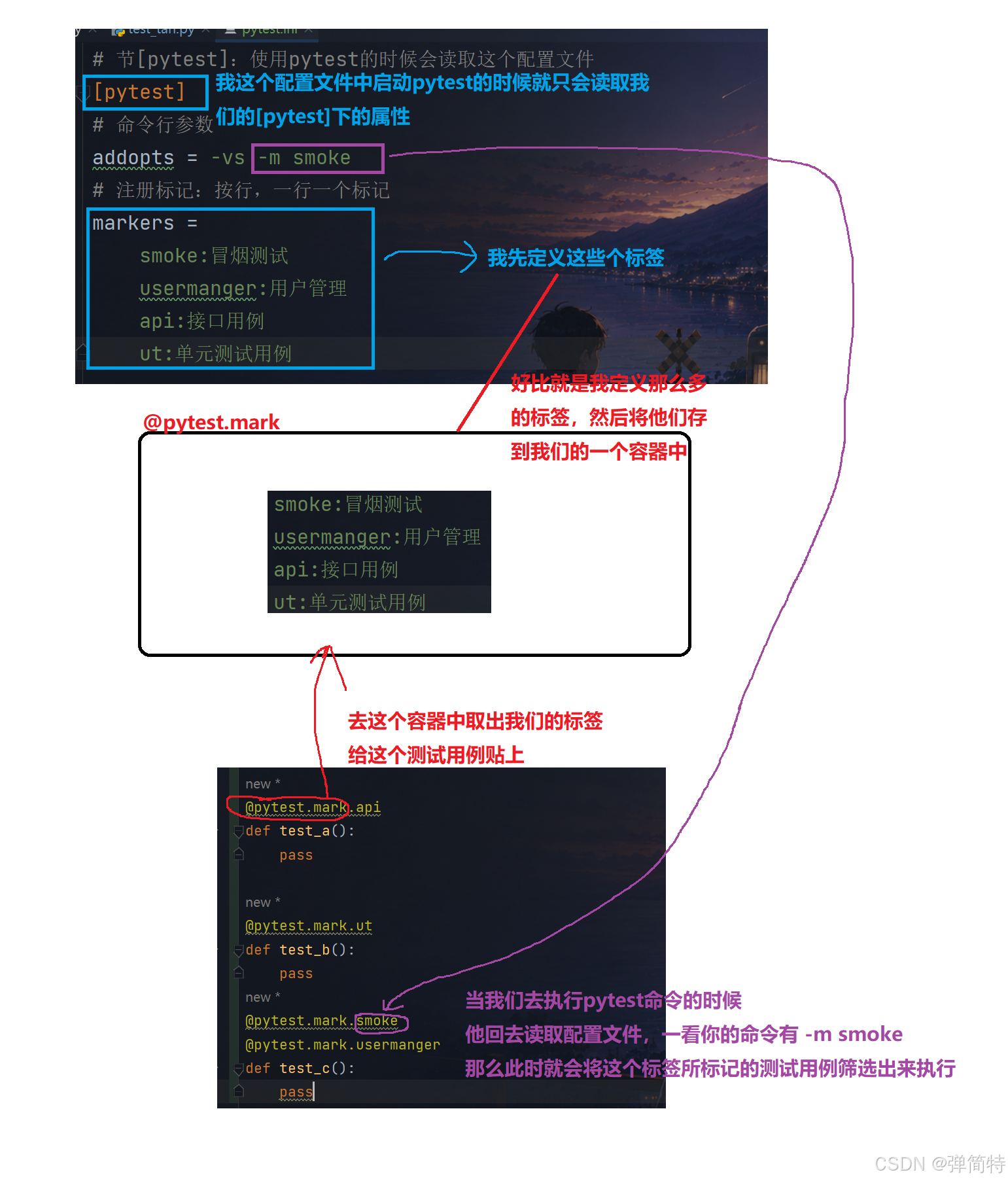
我们pytest中一个功能叫做mark,通过这个功能,我们可以去配置文件中选择对应的标签给我们的测试用例(方法名)打上,如下:
py
@pytest.mark.api
def test_a():
pass
@pytest.mark.ut
def test_b():
pass
@pytest.mark.smoke
@pytest.mark.usermanger
def test_c():
pass
那么梳理他的原理如下:
2、插件带的标记
插件带的标记不需要注册(他自己已经注册了),但是需要安装。
我们插件他也提供了一些标记(标签):
order 标记:用来改变顺序的,值越大那么顺序就越靠后
注意:order这个是一个插件,你得提前安装好(我们之前已经安装过的)
@pytest.mark,order(数字) 使用order标记控制用例的执行顺序,数字越小顺序越靠前,他其实就是排序算法,顺序是从小到大的,所以数字越小,我们顺序越靠前。
py
import pytest
@pytest.mark.order(2)
def test_tan():
assert 1 == 2
@pytest.mark.order(1)
def test_my():
assert 1 == 1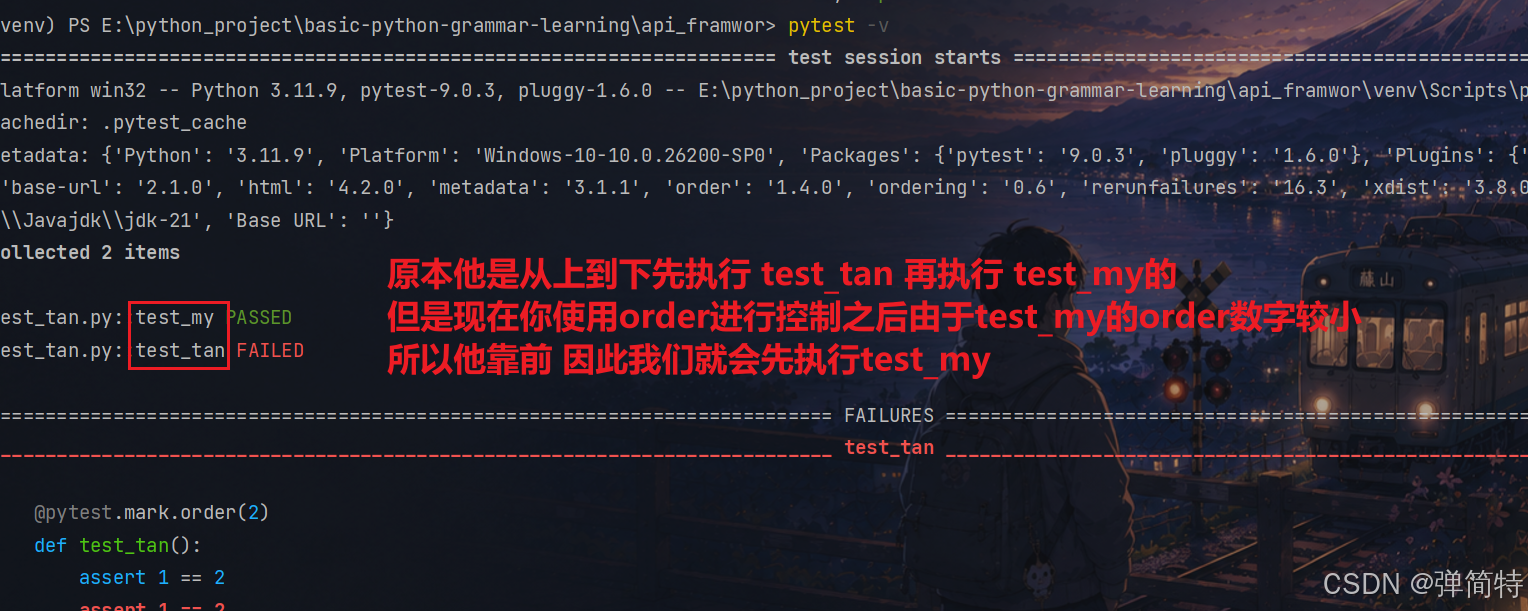
3、框架带的标记
pytest框架自带的标记也是不需要注册的,他也不需要安装,他自己已经注册好了。
pytest自带的标记,拥有不同的效果:
- ship:无条件跳过(我不执行了)
- skipif:有条件跳过
- xfail:预期失败(就是这个用例正常来说是成功的,但是我不要他成功,我要他失败,我的预期是让他失败,所以我就加上这个标记)
- parametrize:参数化测试(后续我们介绍数据驱动测试的时候会讲解)
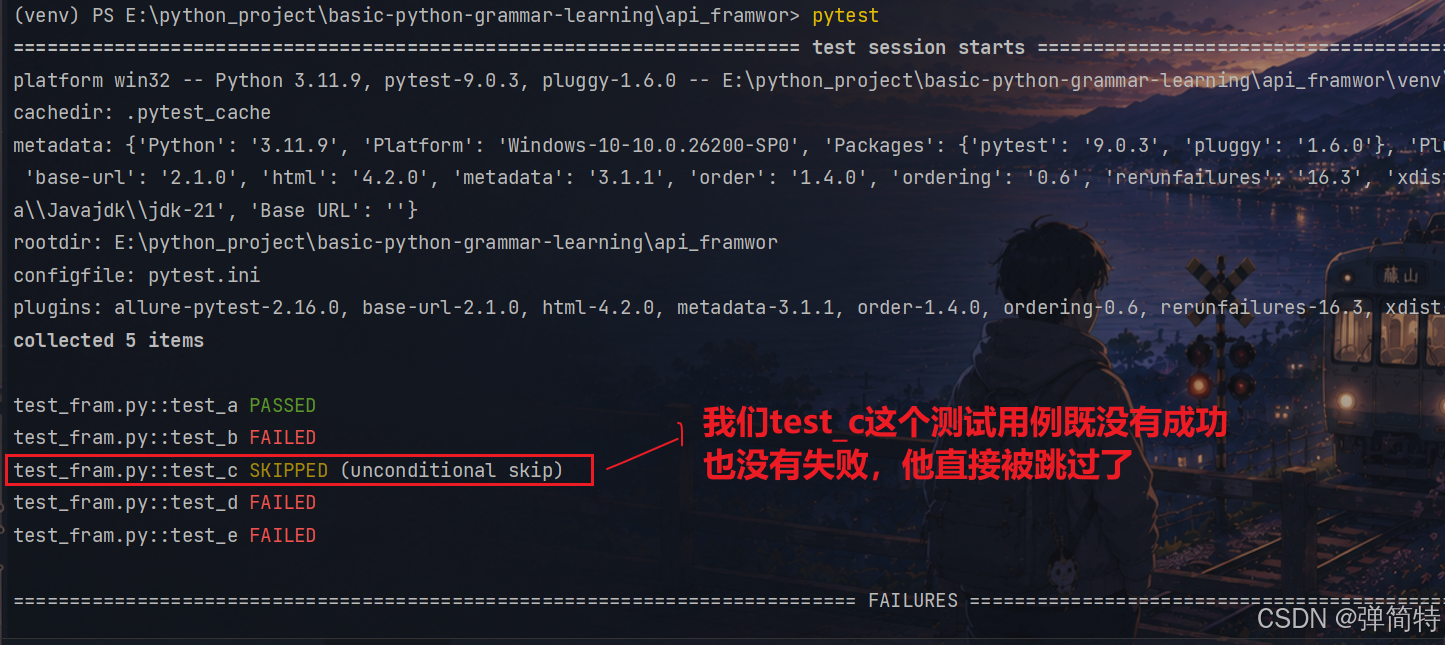
3.1 skip
py
import pytest
def test_a():
assert 1 == 1
def test_b():
assert 1 == 2
@pytest.mark.skip # 会跳过这个用例
def test_c():
assert 3 == 3
def test_d():
assert 3 == 4
def test_e():
assert 3 == 4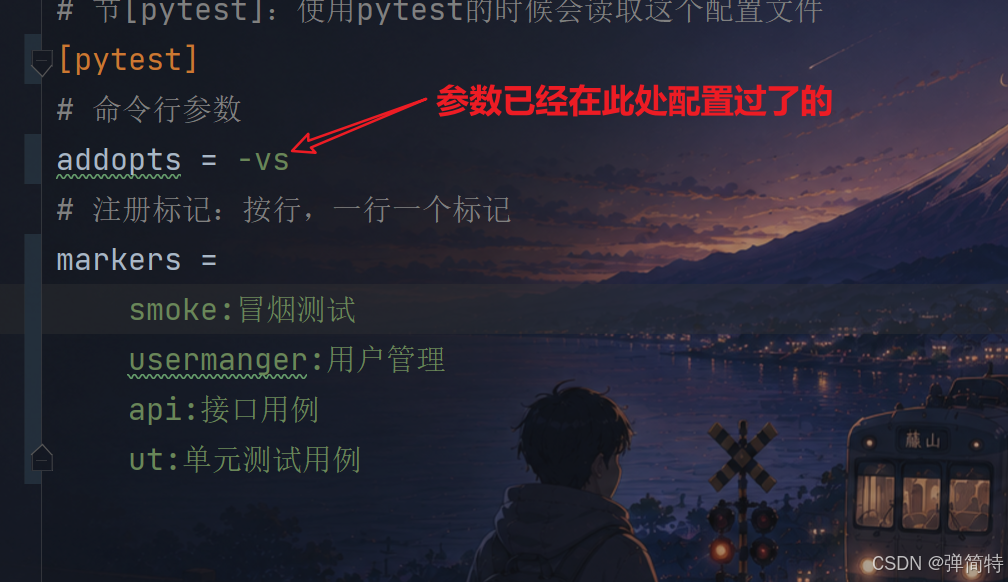
运行参数我们在配置文件中配置了的,我们执行的时候,直接使用pytest即可
3.2 skipif
py
import pytest
def test_a():
assert 1 == 1
def test_b():
assert 1 == 2
@pytest.mark.skipif(1 == 1, reason='当条件为1==1的时候跳过')
def test_c():
assert 3 == 3
def test_d():
assert 3 == 4
def test_e():
assert 3 == 4reason译为理由
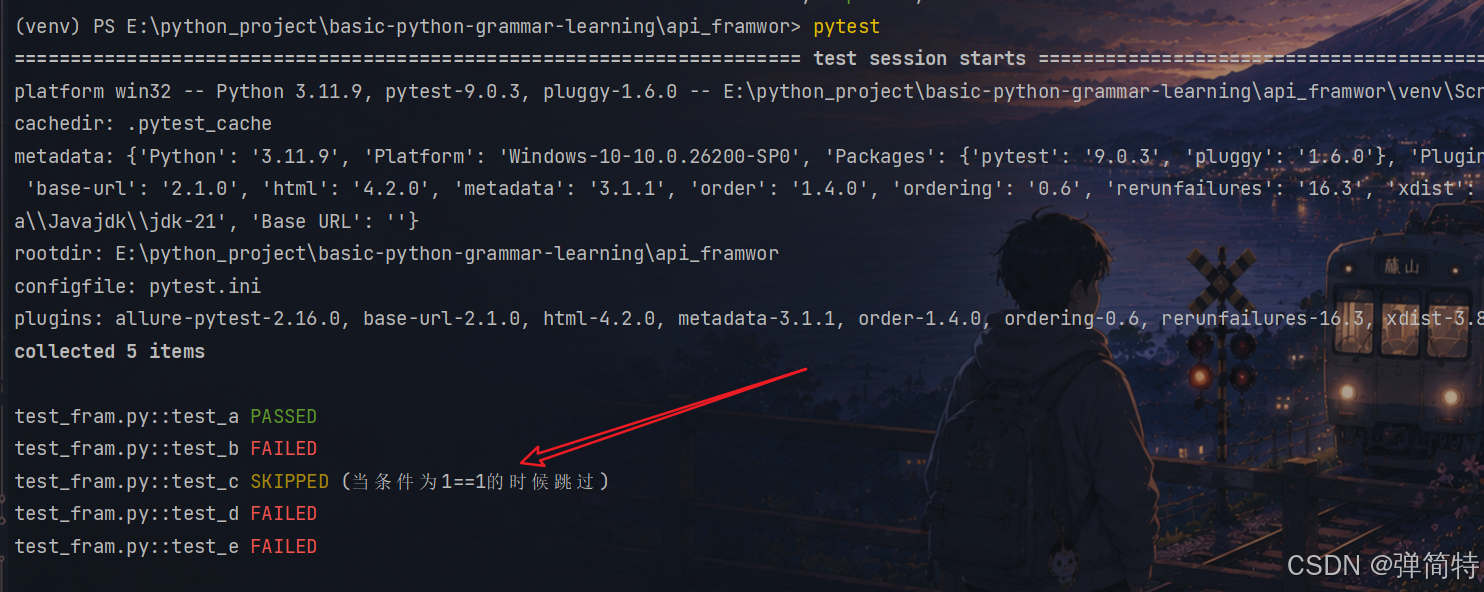
那么如果条件不成立,我就不跳过了
py
import pytest
def test_a():
assert 1 == 1
def test_b():
assert 1 == 2
@pytest.mark.skipif(1 == 2, reason='当条件为1==1的时候跳过')
def test_c():
assert 3 == 3
def test_d():
assert 3 == 4
def test_e():
assert 3 == 4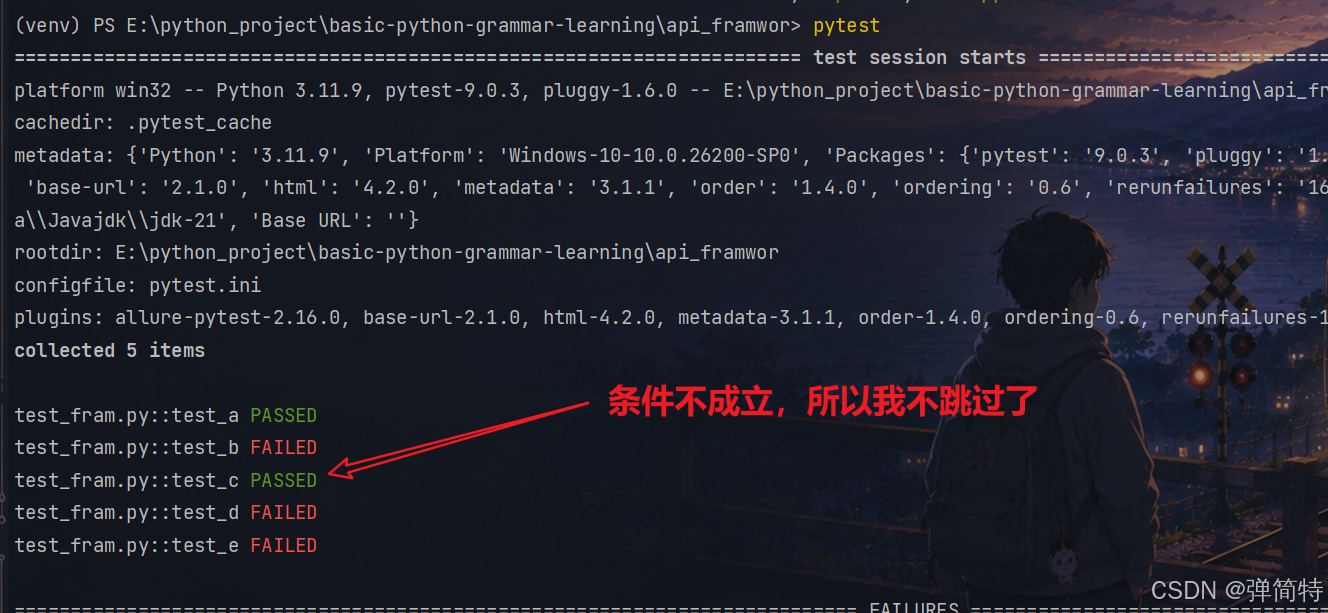
3.3 xfail
py
import pytest
@pytest.mark.xfail # 预期失败
def test_a():
assert 1 == 1 # 实际成功
@pytest.mark.xfail # 预期失败
def test_b():
assert 1 == 2 # 实际失败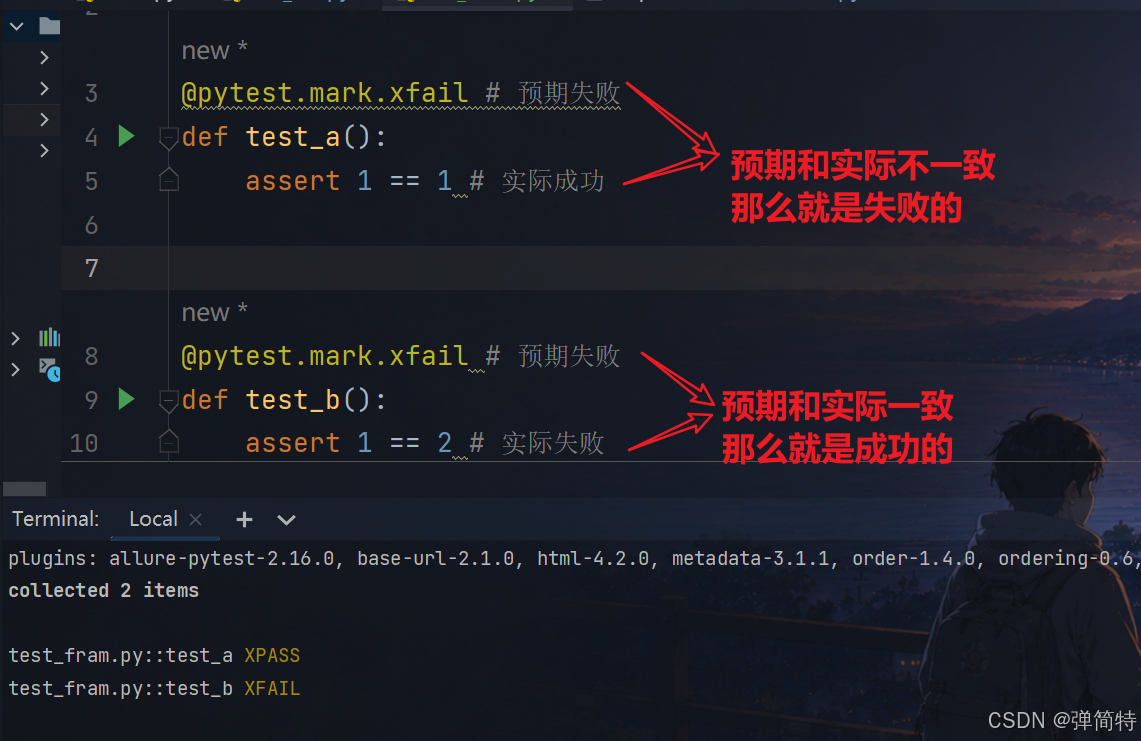
老铁们,我们本期就到此结束了,如果对你有用,记得点赞👍关注,后续我会持续输出更多测试干货。