前面我们已经使用过Claude Code CLI, OpenCode, VSCode+Roo-code插件等不同的方式,给我们的编程配上了一个智能助手,当然上面的这些不仅仅限于AI编程,它们能够更多样化的解决我们生活和工作中遇到的问题。因此使用AI智能体的原则是怎么简单高效怎么来,以前我们都是通过编程hard code来解决大部分的问题,但现在很多时候解决问题不需要编程,或者不需要全部编程,我们完全可以把自己的程序和LLM的调用混合起来,发挥出更大的效果。
于是我们可以从零开始,用python做一个编程助手,通过调用大模型的API实现与大模型互连互通,然后随着我们对Agentic的不断深入的了解,把一个能够落地使用的智能编程助手给制作出来。
AI使用中最佳实践就是套娃,所以我们完全可以借助其他AI工具不断的迭代来完成我们的智能编程助手的开发。
参考文档
智能体开发全流程,从0到1做一个可用的智能体,新手也能学会_如何开发一个智能体-CSDN博客
01_python调用API
1.1_申请Api_key
国外的免费的中转站的API_Key申请也不难,难就难在常常连不上,好不容易连上了响应又慢的出奇,想要稳定的连接还是需要国内的平台,所以需要先到某个平台上去注册账号然后个人认证,通常都会有一定额度的免费Token可以使用,接着申请API_key保存下来就好。
1.2_OpenAI兼容
- 先导OpenAI的包;
- 把1.1的三个关键内容先填上去(API_KEY, BASE_URL, MODEL);
- 用OpenAI(api_key,base_url)进行客户端初始化,从而创建一个OpenAI客户端实例;
- 使用 response = client.chat.completions.create( model, messages)调用大模型并得到回答;
- 打印回答中的文本内容。
python
from openai import OpenAI # 导包
# 三个关键
API_KEY = "Your API Key"
BASE_URL = 'https://xxx.com/compatible-mode/v1'
BASE_MODEL = 'glm-5'
client = OpenAI(
api_key=API_KEY,
base_url=BASE_URL
)
messages=[{'role': 'user', 'content': '你好,请介绍一下你自己'}]
response = client.chat.completions.create(
model=BASE_MODEL,
messages=messages,
stream=False, # glm-5 支持非 stream 模式
extra_body={"enable_thinking": False} # 禁用推理,节省 Token
)
print(f"\n回复内容:\n{response.choices[0].message.content}")
------
回复内容:
你好!很高兴认识你。
我是一个人工智能 助手,旨在通过自然语言处理技术为用户提供信息和帮助。1.3_第一次提问和回答
上面已经实现了一个调用LLM进行的提问和回答,我们就第一次的提问和回答稍微展开来讲一下。这个其实跟网页版AI进行对话是完全一样的,我们在输入框输入我们的问题(就是prompt提示词),然后调用LLM后会把生成的回答的文本内容展现在对话框中。如果你了解过Dify或Coze的智能体,你会知道提示词还分为系统 提示词和用户提示词二种,虽然系统提示词一般只需要发送一次,但它的内容往往决定了当前智能体的角色定位、技能描述、约束限制以及输出格式,是非常关键的。这些我们或许以后会再详细说,当前我们只需要知道它在消息里面是分成2个部分的。
python
messages = [
{
"role": "system", # 系统提示词
"content": "你是一个专业的AI助手..."
},
{
"role": "user", # 用户提示词
"content": "什么是 LangChain?..."
}
]好的,让我们再基于翻译助手的例子看一下带有系统提示词以及翻译内容可变的操作代码:我们把系统提示词写为 "你是一个翻译助手...",而用户提示词为请翻译这句话,具体的话用trans_text变量,实现每一次可变动。
python
trans_text = "你好,请简单介绍一下你自己。"
messages = [
{"role": "system", "content": "你是一个翻译助手..." },
{"role": "user", "content": f"请翻译这句话:{trans_text}" }
]
response = client.chat.completions.create(
model=BASE_MODEL,
messages=messages,
stream=False, # glm-5 支持非 stream 模式
extra_body={"enable_thinking": False} # 禁用推理,节省 Token
)
print(f"\n回复内容:\n{response.choices[0].message.content}")
-----------
回复内容:
这句话翻译成英语是:
**"Hello, please briefly introduce yourself."**
或者更自然一点的说法:
**"Hi, could you please briefly introduce yourself?"**继续展开讨论一下回答的内容,这里打印的是response.choices0.message.content,为什么这么复杂的结构?
这里的response是一个json的结构,我们可以直接打印`print(response)`,但结构会比较混乱,因此用json的结构来打印从而获取比较清晰的内容。现在不需要全面的解析它,只要看response.choices0的内容,再找到它的.message.content的部分就可以了,这里就是回答的文本部分。
python
# 打印json
print(json.dumps(response.model_dump(), indent=2, ensure_ascii=False))
--------------
{
"id": "chatcmpl-9cea652f-490d-9405-8867-7322796ae322",
"choices": [
{
"finish_reason": "stop",
"index": 0,
"logprobs": null,
"message": {
"content": "这句话翻译成英语是:\n\n**\"Hello, please briefly introduce yourself.\"**\n\n或者更自然一点的说法:\n\n**\"Hi, could you please briefly introduce yourself?\"**",
"refusal": null,
"role": "assistant",
"annotations": null,
"audio": null,
"function_call": null,
"tool_calls": null
}
}
],
"created": 1779616443,
"model": "glm-5",
"object": "chat.completion",
"service_tier": null,
"system_fingerprint": null,
"usage": {
"completion_tokens": 34,
"prompt_tokens": 23,
"total_tokens": 57,
"completion_tokens_details": null,
"prompt_tokens_details": {
"audio_tokens": null,
"cached_tokens": 0
}
}
}1.4_实现多轮对话
至此,我们已经实现了调用大模型进行提问和获取回答,也知道了提示词有系统提示词和用户提示词,也知道了回答的文本应该从哪里去获取。但上面的程序每次只能提问一次,而且是程序写死的,因此达不到一个交互的程度。
实现循环
这一节,我们就通过while True的循环,让调用API的提问和回答变成交互式的。使用循环的关键是先要确定它的退出条件否则很容易造成死循环,我们参考当前流行的slash commands(斜杠命令)来进行退出循环条件的控制,设定第一个命令为/exit (跟Claude Code CLI或OpenCode一致)。
python
client = OpenAI(
api_key=API_KEY,
base_url=BASE_URL
)
while True:
user_input = input("\n你: ") # 用户输入
if user_input == "/exit": # /exit退出循环
print("再见!")
break
response = client.chat.completions.create(
model=BASE_MODEL,
messages=[{"role": "user", "content": user_input}],
stream=False
)
reply = response.choices[0].message.content
print(f"\nAI: {reply}")
-----------------
你: 中国的直辖市有?
AI: 中国目前共有**4个**直辖市,分别是:
1. **北京市**
2. **天津市**
3. **上海市**
4. **重庆市**
你: 第2个有哪些著名景点?
AI: 您好,您的问题中提到"第2个",但由于我无法看到之前的对话内容,我不确定您所指的具体对象是什么。 为了能准确回答您的问题,请您告诉我**您是在询问哪 个列表或类别的"第2个"?**
例如,您可能是在问:
1. **世界七大奇迹**的第2个?
2. **中国四大名著**的第2部?
一旦您提供了具体的主题或列表,我会很乐意为您详细 介绍相关的著名景点!
你: /exit
再见!消息列表与多轮对话
根据上面的程序,我们的确实现了多轮的提问并得到回答;于是发现了一个很严重的问题,LLM似乎每次都只能回答当前 的问题,而不知道上一次说了什么,我们在网页版AI上可没有这个问题,所以问题出在我们的程序上。
python
"message": {
"content": "中国目前共有**4个**直辖市,分别是:\n\n1. **北京市**\n2. **天津市**\n3. **上海市**\n4. **重庆市**\n\n",
"refusal": null,
"role": "assistant",
...
}并且我们观察到了message里有个"role"的角色是assistant。其实除了system和user这两个角色之外,我们还有一个重要的角色就是 assistant,它是AI的回复,我们需要把它加到下一次的提问里面去,这样才能让LLM知道前面问过什么,它才知道这次应该怎么回答。而保存在我的messages的列表中的所有消息构成了我们的上下文 (Context),有的大模型的Context比较小(比如32k),目前大多数能有128k或200k,比较优秀的LLM已经提供1M的上下文空间了。
| 角色 | 作用 | 示例 |
|---|---|---|
| system | 设定AI的行为、身份、规则 | "你是一个翻译助手" |
| user | 用户的输入/问题 | "请翻译这句话" |
| assistant | AI的历史回复(多轮对话时使用) | "好的,我来翻译..." |
| [三种角色说明] |
所以,我们怎么来实现这个上下文以及带着记忆的多轮会话呢?用 messages这个列表来实现!
python
while True:
user_input = input("\n你: ")
if user_input == "/exit":
print("再见!")
break
# messages=[{"role": "user", "content": user_input}]
# 带记忆:追加用户输入
messages.append({"role": "user", "content": user_input})
response = client.chat.completions.create(
model=BASE_MODEL,
# messages=[{"role": "user", "content": user_input}],
messages=messages,
stream=False
)
reply = response.choices[0].message.content
print(f"\nAI: {reply}")
# 带记忆:追加AI回复,以便下一轮使用
messages.append({"role": "assistant", "content": reply})运行这个程序,我们的带记忆的多轮会话功能就已经实现了,但同时就会发现输入的Token和总Token数量急剧增加,自己申请的免费模型的Token用量一会就被用光了。

因此,Token的总量以及当前的消耗量就是我们需要进行监测的,防止一些惨痛的事件发生!
1.5_记录和显示Token
我们通过打印response的json信息,可以获取usage的信息内容:
javascript
usage": {
"completion_tokens": 568,
"prompt_tokens": 9,
"total_tokens": 577,
"completion_tokens_details": {
"accepted_prediction_tokens": null,
"audio_tokens": null,
"reasoning_tokens": 492,
"rejected_prediction_tokens": null
},
"prompt_tokens_details": {
"audio_tokens": null,
"cached_tokens": 0
}
}从这段文字来看,输入 是prompt_tokens, 输出 是completion_tokens,而总计 是total_tokens,在数学关系上, 568+9=577 。也就是我们可以通过记录每一轮对话的Token消耗量,以致于得到本次多轮会话的最终累计 的Token消耗,再用我们的额度 减掉最终累计Token消耗从而得到剩余Token额度。
在这里面有个值得注意的地方,completion_tokens是568,而reasoning_tokens是492,也就是当前这个大模型会把推理的消耗计算到输出里面去,导致一旦开启了Thinking推理模式,Token的消耗就会超级快,对于这样的情况,还是最好确认关闭推理以节省Token吧。(当然也有的LLM是不把推理消耗计入输出或者总计的,这类LLM开或关闭推理都对Token没有影响。)
TOKEN的基本统计
python
# 打印 Token 统计
print("\n" + "=" * 60)
print("Token 统计")
print("=" * 60)
print(f"输入 Token: {response.usage.prompt_tokens}")
print(f"输出 Token: {response.usage.completion_tokens}")
print(f"总计 Token: {response.usage.total_tokens}")
print("=" * 60)| | 内容 | 不带推理 | 带推理 |
| 中国的直辖市是? | AI: 中国的直辖市共有四个,分别是: 1. **北京市** 2. **上海市** 3. **天津市** 4. **重庆市** | Token 统计 ============= 输入 Token: 20 输出 Token: 47 总计 Token: 67 ============= | Token 统计 ============= 输入 Token: 20 输出 Token: 340 总计 Token: 360 ============= |
| 第2个有哪些著名景点,列出5个,每个用一句话简单描述 | 略 | 输入 Token: 86 输出 Token: 176 总计 Token: 262 | 输入 Token: 86 输出 Token: 862 总计 Token: 948 |
| 简单描述第1个景点,控制在200字以内 | 略 | 输入 Token: 276 输出 Token: 93 总计 Token: 369 | 输入 Token: 263 输出 Token: 440 总计 Token: 703 |
|---|
不带推理的计算:第一个问题输入20,输出47,总计67;第二个问题是67的基础上加上19得86,输出176,总计262;第三个问题是262的基础上加上14得276,输出93,总计369... 很明显,每轮的总计是下一轮的基数,是迭代的
带推理的计算:第一个问题输入 20,输出340(有推理),总计360,但推理部分不会进入messages列表,因此第二个问题在第一个问题的输入+有效输出上+第二个问题输入得86;然后第三个问题是在第二个问题输入+有效输出再加上第三个喝到输入得263。我们从数据分析可知:带推理的Context上下文并不会变大,但实际消耗的Token会多很多!
记录本次会话全部消耗
由上面内容,记录消耗逻辑很清晰,首先需要三个列表 分别记录每一轮对话的输入,输出和总计;然后在程序退出 时把这三个列表分别汇总计算;根据总计Token的累积值得到本次的全部消耗。
python
# 记录每轮对话的 Token 使用量
input_tokens_list = []
output_tokens_list = []
total_tokens_list = []
while True:
user_input = input("\n你: ")
if user_input == "/exit":
# 计算本轮会话总消耗
total_input = sum(input_tokens_list)
total_output = sum(output_tokens_list)
total_session = sum(total_tokens_list)
print("\n" + "=" * 60)
print("本次会话 Token 消耗统计")
print("=" * 60)
print(f"总输入 Token: {total_input:,}")
print(f"总输出 Token: {total_output:,}")
print(f"总会话消耗: {total_session:,}")
print("=" * 60)
# 追加用户输入到消息历史
messages.append({"role": "user", "content": user_input})
# 发送完整消息历史
response = client.chat.completions.create(
model=BASE_MODEL,
messages=messages,
stream=False,
extra_body={"enable_thinking": False}
)
reply = response.choices[0].message.content
print(f"\nAI: {reply}")
# 追加AI回复到消息历史
messages.append({"role": "assistant", "content": reply})
# 记录本轮 Token 使用量
input_tokens = response.usage.prompt_tokens
output_tokens = response.usage.completion_tokens
total_tokens = response.usage.total_tokens
input_tokens_list.append(input_tokens)
output_tokens_list.append(output_tokens)
total_tokens_list.append(total_tokens)
# 打印本轮 Token 统计
print("\n" + "-" * 60)
print(f"第 {len(input_tokens_list)} 轮 Token 统计")
print("-" * 60)
print(f"输入 Token: {input_tokens:,}")
print(f"输出 Token: {output_tokens:,}")
print(f"总计 Token: {total_tokens:,}")
print("-" * 60)
------------------------------------------------------------
第 1 轮 Token 统计
------------------------------------------------------------
输入 Token: 20
输出 Token: 31
总计 Token: 51
------------------------------------------------------------
第 2 轮 Token 统计
------------------------------------------------------------
输入 Token: 66
输出 Token: 209
总计 Token: 275
------第 3 轮 Token 统计
------------------------------------------------------------
输入 Token: 289
输出 Token: 269
总计 Token: 558
------------------------------------------------------------
你: /exit
============================================================
本次会话 Token 消耗统计
============================================================
总输入 Token: 375
总输出 Token: 509
总会话消耗: 884
============================================================根据不同大模型分别记录
由于可以免费使用多个大模型,所以希望对每个模型进行单独计算消耗以及剩余额度。这样的情况下,用一个外部文件来记录每个大模型的剩余额度是有必要的,经过对比后我们选择了json文件来保存,每次调用指定的大模型的时候,先从json文件中加载,然后获取对应大模型的剩余额度,然后每轮对话都记录消耗量,最后在/exit时累计本次会话的最终消耗总量,再用额度减去全部消耗从而得到当前剩余额度,把当前剩余额度再写回json文件中即可实现使用的闭环。
javascript
{
"glm-5": {
"total_quota": 1000000,
"remaining_quota": 96113,
"last_session_consumption": 884
},
"qwen3.5-flash": {
"total_quota": 1000000,
"remaining_quota": 871613,
"last_session_consumption": 0
}
}
python
# 加载额度文件
def load_quota():
if os.path.exists(QUOTA_FILE):
with open(QUOTA_FILE, 'r', encoding='utf-8') as f:
return json.load(f)
return {}
# 保存额度文件
def save_quota(quota_data):
with open(QUOTA_FILE, 'w', encoding='utf-8') as f:
json.dump(quota_data, f, indent=4, ensure_ascii=False)
# 读取当前模型的额度
quota_data = load_quota()
if BASE_MODEL in quota_data:
remaining_quota = quota_data[BASE_MODEL]["remaining_quota"]
print(f"\n当前模型: {BASE_MODEL}")
print(f"剩余额度: {remaining_quota:,} Token")
else:
print(f"\n警告: 未在 {QUOTA_FILE} 中找到模型 {BASE_MODEL} 的额度信息")
remaining_quota = None
while True:
user_input = input("\n你: ")
if user_input == "/exit":
# 更新额度
if remaining_quota is not None:
new_remaining = remaining_quota - total_session
quota_data[BASE_MODEL]["remaining_quota"] = new_remaining
quota_data[BASE_MODEL]["last_session_consumption"] = total_session
save_quota(quota_data)1.6_参数设置
流式STREAM
前面我们已经做了一个乞丐版 的AI助手,当然还只能进行文本的提问和回答。在使用的过程中,我们会发现当我们已经发送了提问之后,很长的时间内是没有任何反应的,就好像卡死在那里一样,特别是开启推理之后,卡在那里的时间就会更长,直到最后所有的信息一起获取到并打印出来,给人一种突兀的感觉。可以说这种体验对用户来说非常的不好。
于是,我们需要开始使用流式(Stream),当使用流式的时候,会把LLM的推理以及回答分成多个块chunk,一旦有一个chunk的信息好了就会直接发出来,给人的感觉就是连贯的。
但是注意,使用stream会让代码变得更加的复杂,初次接触python调用API的情况下容易出现问题;而且在 stream=True 模式下,API 会逐块返回内容, 默认不会返回 usage 信息 ,也就是不能简单的获取到Token的消耗量信息。
不过已经研究到这里,再使用stream流式已经是水到渠成的了。
-
在client.chat.completions.create( )中把stream 由前面一直使用的'False'改成'True'或者不写(某些平台默认开启流式)
-
当发送消息后,需要使用循环,根据chunk in response进行判断和打印,但需要把这些分散开的chunk的content,放到full_reply中从而得到完整的回答(历史消息)
-
过程中没有usage,因此需要额外设置stream_options={"include_usage": True},
python
from openai import OpenAI
# 三个关键
API_KEY = "YOUR API Key"
BASE_URL = 'https://xxx.com/compatible-mode/v1'
BASE_MODEL = 'glm-5'
client = OpenAI(
api_key=API_KEY,
base_url=BASE_URL
)
# 初始化消息列表
messages = [
{"role": "system", "content": "你是一个AI助手,请用中文回答。"}
]
while True:
user_input = input("\n你: ")
if user_input == "/exit":
print("再见!")
break
# 追加用户输入到消息历史
messages.append({"role": "user", "content": user_input})
# 发送完整消息历史(流式模式)
response = client.chat.completions.create(
model=BASE_MODEL,
messages=messages,
stream=True, # 开启流式
stream_options={"include_usage": True}, # 记录usage
extra_body={"enable_thinking": False}
)
# 流式输出
print("\nAI: ", end="", flush=True)
full_reply = ""
usage = None
for chunk in response: # 循环
# 获取内容片段
if chunk.choices and chunk.choices[0].delta.content:
content = chunk.choices[0].delta.content
print(content, end="", flush=True)
full_reply += content
# 最后一个 chunk 包含 usage 信息
if chunk.usage:
usage = chunk.usage
print() # 换行
# 追加AI回复到消息历史
messages.append({"role": "assistant", "content": full_reply})
# 打印 Token 统计
if usage:
print("\n" + "=" * 60)从而就实现了流式以及流式下的Token消耗计算。
推理与流式
有的大模型的推理(thinking)会比较充分,因此时间会很长,往往我们希望它以流式的方式显示出来,让用户即时了解到大模型正在分析什么,而不需要它在最后一股脑儿的输出出来。所以,要把推理用好,前提是先开启流式。
python
# 发送完整消息历史(流式模式 + 推理)
response = client.chat.completions.create(
model=BASE_MODEL,
messages=messages,
stream=True,
stream_options={"include_usage": True},
extra_body={"enable_thinking": True}
)需要说明的是,对于不同的平台,推理的开关参数可能是不一样的,你用上面这段代码可能在某些平台上就没有效果,这个时候没有必要慌张,更不要轻言放弃。因为它就那么几种可能性,用上AI做个循环,可能2到3次运行下来就找到了对应的推理的开关的设定的参数了。
当推理开关打开了,就可以分别对推理内容和最终回复内容进行流式输出了,这里备注一下有的LLM在流式中没有推理的内容,所以有可能反而在流式中不显示推理。
还有就是自己的API程序中历史消息里不要把推理的消息加进去,要不然Context很容易就炸了。
python
for chunk in response:
if chunk.choices and chunk.choices[0].delta:
# 推理内容
if chunk.choices[0].delta.reasoning_content:
if not is_thinking:
print("\n[推理过程]: ", end="", flush=True)
is_thinking = True
thinking = chunk.choices[0].delta.reasoning_content
print(thinking, end="", flush=True)
full_thinking += thinking
# 最终回复内容
if chunk.choices[0].delta.content:
if is_thinking:
print("\n\n[最终回复]: ", end="", flush=True)
is_thinking = False
content = chunk.choices[0].delta.content
print(content, end="", flush=True)
full_reply += content
# 最后一个 chunk 包含 usage 信息
if chunk.usage:
usage = chunk.usage
# 追加AI回复到消息历史(只保存最终回复,不保存推理过程)
messages.append({"role": "assistant", "content": full_reply})其他参数
python
messages array (必选)
传递给大模型的上下文,按对话顺序排列。
stream boolean (可选) 默认值为 false
是否以流式输出方式回复。相关文档:流式输出
temperature float (可选)
采样温度,控制模型生成文本的多样性。
temperature越高,生成的文本更多样,反之,生成的文本更确定。
取值范围: [0, 2)
temperature与top_p均可以控制生成文本的多样性,建议只设置其中一个值。
top_p float (可选)
核采样的概率阈值,控制模型生成文本的多样性。
top_p越高,生成的文本更多样。反之,生成的文本更确定。
取值范围:(0,1.0]
temperature与top_p均可以控制生成文本的多样性,建议只设置其中一个值。
top_k integer (可选)
指定生成过程中用于采样的候选 Token 数量。值越大,输出越随机;值越小,输出越确定。若设为 null 或大于 100,则禁用 top_k 策略,仅 top_p 策略生效。取值必须为大于或等于 0 的整数。
repetition_penalty float (可选)
模型生成时连续序列中的重复度。提高repetition_penalty时可以降低模型生成的重复度,1.0表示不做惩罚。没有严格的取值范围,只要大于0即可。
presence_penalty float (可选)
控制模型生成文本时的内容重复度。
取值范围:[-2.0, 2.0]。正值降低重复度,负值增加重复度。
在创意写作或头脑风暴等需要多样性、趣味性或创造力的场景中,建议调高该值;在技术文档或正式文本等强调一致性与术语准确性的场景中,建议调低该值。
response_format object (可选) 默认值为{"type": "text"}
返回内容的格式。可选值:
{"type": "text"}:输出文字回复;
{"type": "json_object"}:输出标准格式的JSON字符串。
max_tokens integer (可选,即将废弃)
该参数即将废弃,新接入请使用 max_completion_tokens。
用于限制模型输出的最大 Token 数。若生成内容超过此值,生成将提前停止,且返回的finish_reason为length。
默认值与最大值均为模型的最大输出长度
reasoning_effort string (可选)默认值为 high
控制DeepSeek-V4系列模型的推理力度。1.7_response调用
这几天经常刷到Codex的使用教学视频,其中有一个视频中使用了MiniMax2.7的大模型,除了CC-switch之外,还要下载和安装一个ccswitch-minimax,而这个是让 Codex CLI 通过 MiniMax 模型运行。(Codex 使用 OpenAI Responses API 协议,MiniMax 只提供 Chat Completions API。本项目在本地启动一个协议翻译代理,在两者之间无缝转换。)
这就引出了我们的response调用,我们上面所使用的都是chat.completion,并且其实很多的LLM只支持这个,但近期出来的新的LLM,又很多都采用了Responses API。
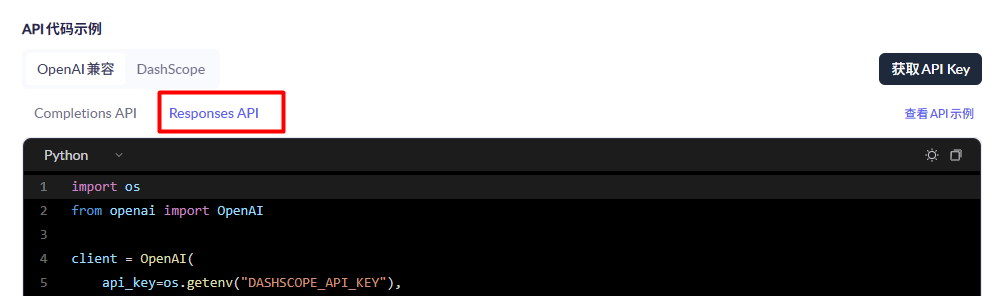
- API 是跟着模型训练范式配套开发
- 2020 年只有续写式大模型 → OpenAI 配套上线 Completions
- 2023 对话微调普及 → 上线 ChatCompletions
- 2025 Agent 时代 → 推出 Responses 适配新一代 Agent 模型
| 接口 | 路径 | 输入结构 | 状态 | 工具能力 |
|---|---|---|---|---|
| Completions | /v1/completions | prompt 字符串 | 无状态 | 不原生支持 |
| ChatCompletions | /v1/chat/completions | messagesrole+content | 无状态手动拼历史 | 标准 FunctionCall |
| Responses | /v1/responses | input+instructions | 有状态 response_id | 内置全类型工具链 |
Codex 分版本:0.80 以下 = ChatCompletions;0.81+ 彻底移除 chat wire 协议,强制仅 Responses
据说OpenRouter上的LLM基本上都是chat.Completion的,所以需要某种方式进行转换。
1.8 安装和使用Codex接入国内大模型
- 下载CC_Switch,然后选择Codex的下面进行添加供应商
farion1231/cc-switch![]() https://github.com/farion1231/cc-switch
https://github.com/farion1231/cc-switch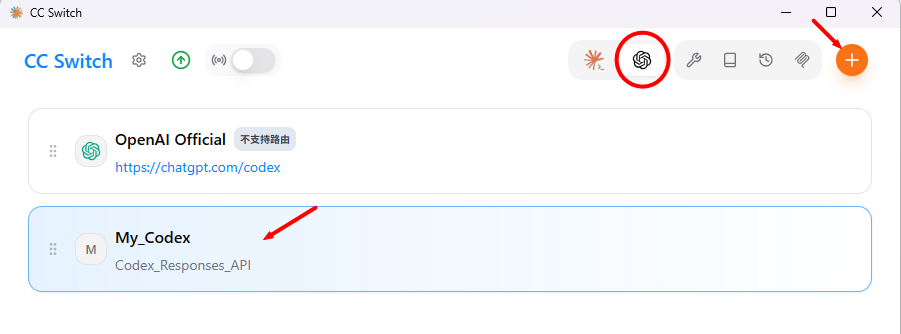
前面刚说过Codex的新版本是强制Responses API,因此最简单的做法是找到支持的国内平台以及近期新的大模型,比如某问的3.6-plus,先在cc-switch的设置中填写url, API_Key等关键信息,然后在相应的【文档】中找到Codex的页面,根据说明操作。
- 安装Codex CLI和desktop
安装CLI跟前面文章里讲的OpenCode CLI、Claude Code CLI基本上一致,先确保自己已经安装了Node.js v18.0以上版本,然后直接在终端中执行命令就可以
bash
npm install -g @openai/codex
codex --version这里注意看说明文档,首先Codex 0.8以下版本能支持chat.Completion,于是可以接比较老的Model或者其他平台的比如minimax等,但不推荐。
其次可以从github中获取例如ccx,ccswitch-minimax等应用,将API的协议进行转换,也就是创建一个本地服务器,把你的Codex的Responses API通过暴露出来的本地的API请求(所以这里你的API_Key可以乱输,但你需要把它保存到.env文件中)转换成Completions API,再去到minimax或者Deepseek的API调用(因此你还是需要在平台上申请API_Key,然后还是刚刚讲过的在CC Switch中设置好)。当然,如果请求的LLM是支持Responses API的,就完全不需要本段所提到的那些应用了。
如果在配置好CC Switch的情况下安装好codex CLI,则可以在终端中输入
bash
codex进入codex CLI
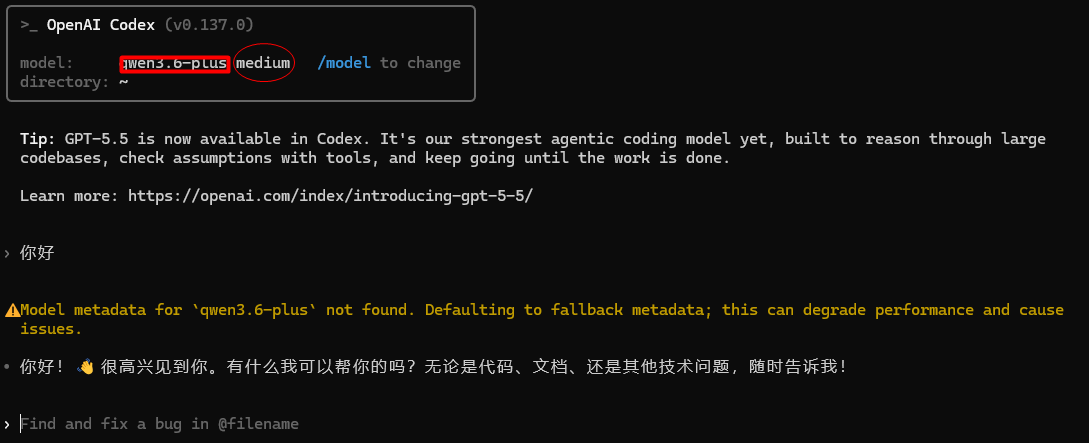
请打开user/.codex/config.toml进行查看,配置信息里的供应商以及模型等应该与我们在CC Switch中设置的相同,到这里我们能正常使用codex CLI了。
然后我们再来安装codex的desktop应用, Codex | OpenAI 打造的 AI 编码助手 | OpenAI 到官网点击下载(以windows版为例)
下载会得到一个1.2M的 Codex Installer文件,运行会下载并安装Codex的desktop,安装完成后自动启动Codex,这时就直接进入使用了,不需要进行注册和登录。