如果把 Agent 想成一个新来的同事,ReAct 解决的其实是一个很朴素的问题。
这个同事很会说,也很会推理。你问他一个问题,他能顺着线索分析半天,语气还挺笃定。问题是,很多任务不能只靠"想"。
借用我导师说过的一句话: 乱拳打死老师傅
有时候他一路猛猜,确实也能猜对,但这更像是"乱拳",不是一个稳定、可复用、可交付的工作方式。
你问今天某个仓库的最新发布版本,他得去查。
你让他总结一篇论文,他至少要先读到论文。
只会想,容易在脑子里绕圈。
只会动,又容易变成没有方向的点点点。
ReAct 有意思的地方,就在于它把这两件事放到同一个节奏里:先想一下,决定下一步做什么;做完之后看结果;再根据结果继续想。
听起来不玄。
这恰好是它最值得学的地方。
先用一句话说清楚 ReAct
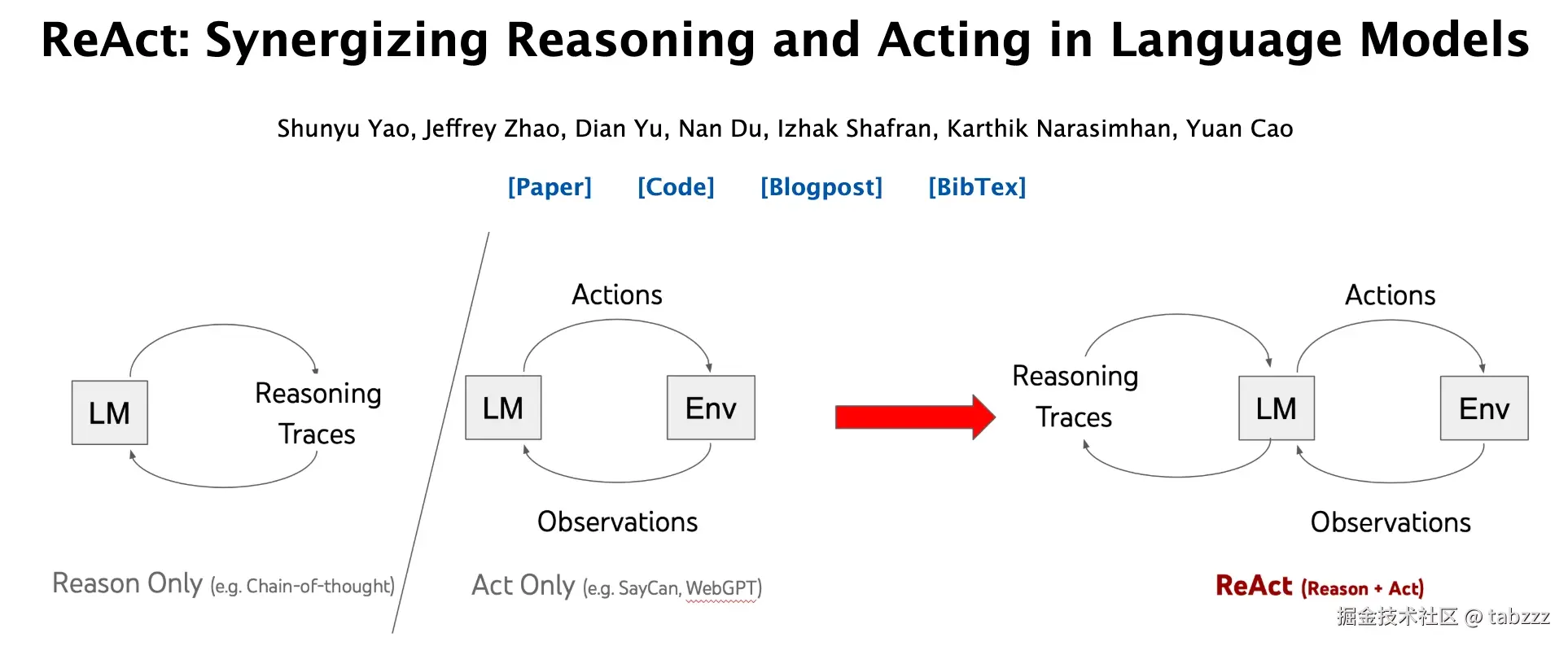
ReAct 是 Reasoning and Acting 的缩写,可以粗略翻译成"推理 + 行动"。
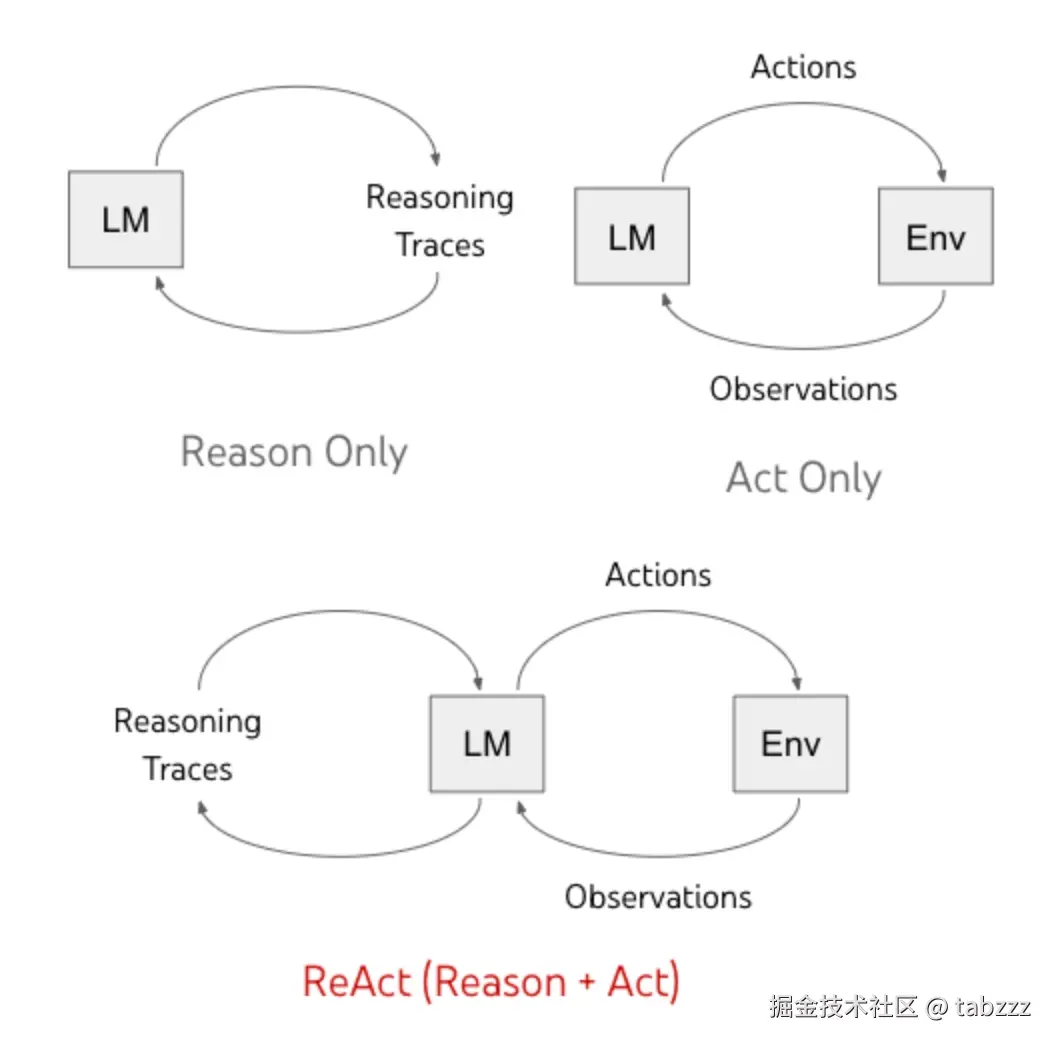 在大模型里,它指的是一种让模型交替进行推理和动作的模式:模型先根据当前问题判断下一步该做什么,然后调用一个工具或执行一个动作,拿到观察结果之后,再继续判断下一步。
在大模型里,它指的是一种让模型交替进行推理和动作的模式:模型先根据当前问题判断下一步该做什么,然后调用一个工具或执行一个动作,拿到观察结果之后,再继续判断下一步。
它最经典的形式通常长这样:
Thought: 我需要先弄清楚 X。 Action: 调用某个工具,查询 X。 Observation: 工具返回了结果。 Thought: 根据这个结果,我还需要确认 Y。 Action: 再调用另一个工具。 Observation: 得到新的信息。 Final Answer: 给出最终回答。
这里的 Thought、Action、Observation 不是为了把文章写得像剧本。它们分别对应三件事:
Thought 是模型的中间判断。
Action 是模型选择的下一步动作,比如搜索、查数据库、打开网页、调用函数、移动机器人。
Observation 是动作之后得到的新信息。
如果用更普通的话说,ReAct 就是让模型不要一次性把答案憋出来,而是边做边看,边看边改。
这很接近人类处理复杂任务时的样子。
我们很少会在什么都不查的情况下,把一个涉及外部信息的问题从头推到尾。更多时候是先有一个判断,再去验证一下;验证完发现不对,再调整路线。ReAct 把这个过程写成了一种可复用的提示和执行模式。
为什么会需要 ReAct
理解 ReAct 之前,可以先看两个更早、更容易理解的方向。
一个方向叫 Chain-of-Thought,也就是常说的 CoT。它让模型在回答复杂问题时写出中间推理步骤。比如数学题、逻辑题、需要多步分析的问题,模型如果直接给答案,容易跳步;如果先把过程写出来,往往更稳定。
另一个方向是 Acting,也就是让模型和外部环境交互。比如 WebGPT 让模型使用文本浏览器搜索和浏览网页,SayCan 把语言模型和机器人可执行动作结合起来,让模型不只是"说计划",还要考虑某个动作在当前环境里能不能做。
这两个方向各有价值。
CoT 让模型更会想,但它仍然主要依赖模型内部已有知识。遇到实时信息、私有数据、外部状态,它想得再认真,也可能只是认真地猜。
Acting 让模型可以接触外部世界,但如果缺少推理,它可能会机械地执行动作,不知道为什么做、做错了怎么改、什么时候该停。
ReAct 的原始论文想解决的,就是这两个能力分开时的尴尬:推理需要外部反馈,行动也需要推理来保持方向。
 所以它把二者交错起来。
所以它把二者交错起来。
不是先写一份完整计划,然后一口气执行到底;也不是没有计划地一路调用工具。它更像一个小循环:
想一下 -> 做一步 -> 看结果 -> 再想一下 -> 再做一步
这个循环很小,但它打开了一扇门。
因为从这一刻起,模型的回答不再只是"生成文本",而开始变成"完成任务"。
一个小例子:从直接回答到 ReAct
假设用户问:
ReAct 这篇论文是谁写的?它主要想解决什么问题?
如果模型直接回答,它可能凭记忆给出作者和摘要。
运气好的时候是对的,运气差的时候会混进错误。
问题在于,用户很难知道它到底是查过,还是背出来的。
如果只用 CoT,模型可能会这样处理:
这看起来是一篇关于 Reasoning and Acting 的论文。我需要回忆它的背景,可能和大模型工具使用有关......
这比直接回答多了一点过程,但仍然没有接触外部资料。
如果只用 Act,模型可能直接搜索论文标题,拿到页面之后就把搜索结果贴出来。信息有了,但没有整理。
ReAct 会更像这样:
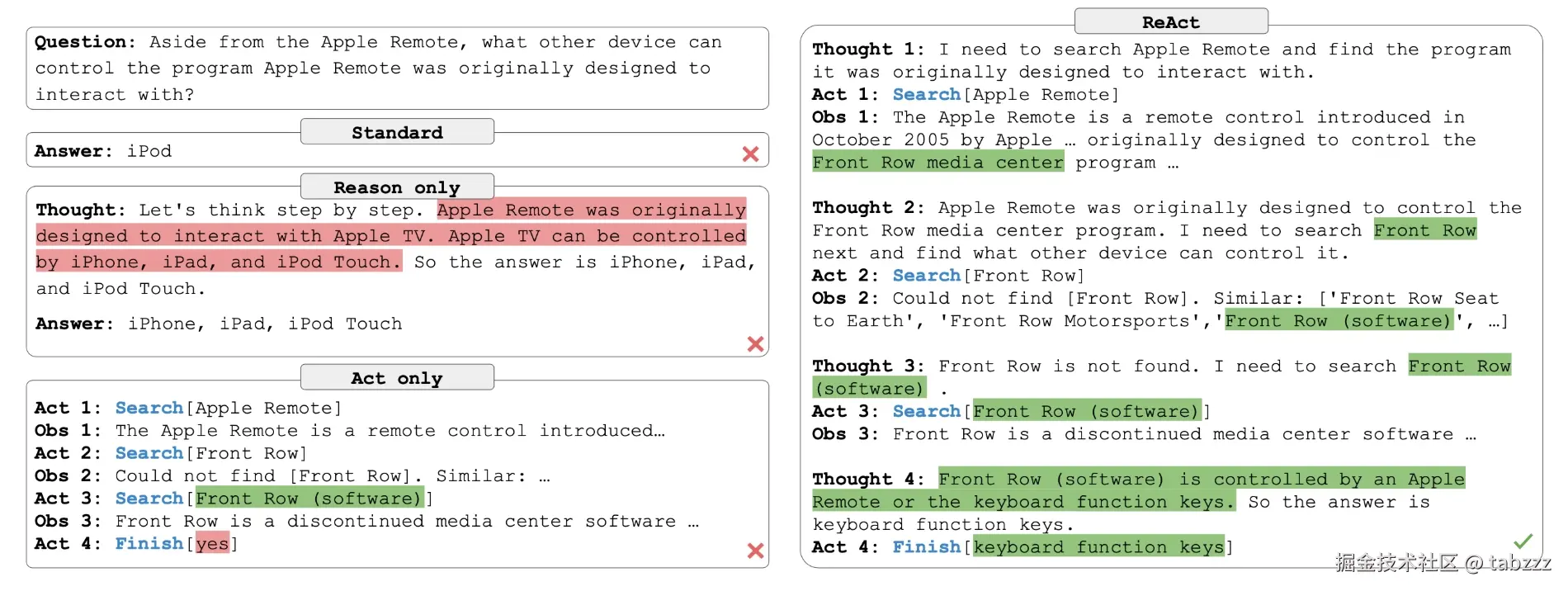
Thought: 我需要确认 ReAct 论文的作者和核心观点,不能凭印象回答。 Action: search("ReAct Synergizing Reasoning and Acting in Language Models") Observation: 搜索结果显示,ReAct 由 Shunyu Yao 等人提出,核心思想是让模型交替进行推理和行动。 Thought: 信息已经确认,可以用通俗语言解释 ReAct 的作用。 Final Answer: ReAct 的核心是让大模型一边思考,一边调用工具获取信息,再根据观察结果继续调整答案。它解决的是模型只靠内部推理容易出错、只调用工具又缺少规划的问题。
这段示例不重要,重要的是它的节奏。
模型没有假装自己一开始就知道全部答案。它先承认需要查证,然后通过工具获得信息,再把信息整理成回答。
对用户来说,这种过程更容易信任。
对工程系统来说,这种过程也更容易调试。因为你能看到每一步到底调用了什么工具、拿到了什么结果、为什么走到下一步。
ReAct 到底让模型变强在哪里
现在市面上绝大部分 Agent 框架,底层都是 ReAct 循环,WHY?
我觉得关键在于,最核心的提升不是"模型突然聪明了",而是它让模型的聪明有了落点。
第一,它能把外部信息纳入推理。
模型内部知识再丰富,也不等于知道此刻数据库里的订单状态、网页上的最新内容、文件系统里的真实代码。
ReAct 让模型在需要信息时先去取信息,再根据取回来的结果继续判断。
这对减少幻觉很重要。
当然,工具不保证真理。搜索结果也可能错,数据库也可能脏,接口也可能超时。但至少系统不再只靠模型记忆回答。它多了一条接触现实的路。
第二,它能在过程中修正方向。
复杂任务里,第一步经常不是最优的。人也是这样。
我们查一个关键词,发现不准,会换关键词;打开一个页面,发现不是目标,会退回来;调用一个接口,发现权限不够,会换一种路径。
ReAct 的 Observation 就是给模型一个"看见反馈"的机会。
没有 Observation,模型只能把错误一路带下去。
有了 Observation,它至少有机会停一下,说:诶,刚才这步不对,我换个办法。
第三,它让过程更可解释。
这里要稍微谨慎一点。
ReAct 论文强调这种轨迹更容易被人理解和信任,因为我们能看到模型的中间步骤和动作。但在今天的许多生产系统里,模型完整的内部推理并不一定会直接展示给用户,也不一定应该原样暴露。
更稳妥的做法,是记录可审计的执行轨迹:模型调用了哪个工具,参数是什么,工具返回了什么,系统做了哪些校验,最后为什么给出这个答案。
这类轨迹未必等于模型真正的全部思考,但它对工程调试已经很有价值,用户看到这些信息,也会很大程度提高信服度。
第四,它让 Agent 从"聊天"走向"办事"。
聊天模型回答问题,核心动作是生成文本。
Agent 完成任务,核心动作是推进状态。
ReAct 提供的就是一种最小的推进方式:每次只走一步,每步都能得到反馈,每次反馈都能影响下一步。
这比一次性生成完整计划更慢一点,但也更稳一点。
ReAct 不是什么
一个概念被用得多了,就容易长出一圈雾。ReAct 也一样。
它不是让模型拥有真正的自主意识。
它只是让模型按照某种格式生成中间判断和动作请求。模型说要调用搜索工具,并不代表它真的自己打开了浏览器。
真正执行动作的,仍然是外部程序、框架或工具执行器。
它也不是正确性的保证。
ReAct 可以让模型查资料、看结果、修正方向,但如果工具返回的信息质量差,或者提示写得含糊,或者循环控制做得不好,结果仍然会错。
一个会使用搜索的人,也可能搜到错误页面,然后一本正经地引用。工具并不会自动让判断变高尚,它只是把判断放到了更真实的地面上。
它也不适合所有任务。
如果问题很简单,比如"把这段话改得更口语一点",或者"解释一下什么是 JSON",直接回答可能就够了。强行套 ReAct,会让简单任务变得很啰嗦。
这就好比想打印个 console.log,没必要先装一堆无用包。
它更适合一些需要外部信息、多步操作或者留下记录过程的任务。
判断一个任务要不要用 ReAct,我一般会思考一个简单问题:
这个任务的下一步,会不会依赖刚刚那一步的结果?
如果会,ReAct 往往值得考虑。
如果不会,直接做可能更清楚。
放到现代 Agent 里,ReAct 长什么样
刚才提到过市面上很多框架其实都有 ReAct 的影子,但是事实上今天很多 Agent 框架已经不会让你刀耕火种去手写 Thought:、Action:、Observation: 这三个字段了。
尤其在工具调用能力变成熟之后,模型可能通过结构化的 tool call 返回动作意图。框架负责执行工具,再把工具结果追加回上下文。
LangGraph 这类框架也会把这种循环包装成图结构:一个节点调用模型,一个节点执行工具,根据模型是否还要调用工具决定继续循环还是结束。
但底层节奏没有变。
它仍然是"三步走"。
从这个角度看,ReAct 更像一种工作模式,而不是某个固定 prompt 模板。
早期 ReAct 示例里,Thought 常常是可见文本。现代产品里,推理步骤可能被隐藏、压缩、结构化,或者替换成更短的执行说明。但只要系统还在做"模型选择动作 -> 工具返回观察 -> 模型继续决策"的循环,它就仍然带着 ReAct 的骨架。
这里有个小提醒:不要把"能看到 Thought"当成 ReAct 的唯一标志。
更值得关心的是三件事:
模型能不能根据上下文选择合适动作。
工具结果能不能可靠地回到模型视野里。
系统能不能控制这个循环,不让它乱跑。
工程里最容易忽略的几件小事
ReAct 看起来像提示词技巧,但真正落地时,很多问题都在工程细节里。
第一,工具描述要清楚。
模型选择工具时,依赖的是工具名、参数结构、描述和上下文。如果工具叫 search,描述只有一句 "search something",模型就只能猜。更好的工具描述要说清楚它查哪里、适合什么问题、不适合什么问题、参数应该怎么写。
工具描述写得像谜语,模型调用起来就像猜灯谜。
第二,Observation 要短而有用。
工具返回结果不是越多越好。你把一整页 HTML、一大段日志、几百行 JSON 全塞回上下文,Context容易爆掉暂且不说,模型反而容易抓不住重点。
更好的做法是把返回结果整理成结构稳定、信息密度合适的观察。比如搜索工具可以返回标题、摘要、链接、时间;错误结果也应该清楚写出错误类型,而不是只给一个 failed。
第三,错误也要变成可理解的观察。
工具失败时,不要只让 Agent 崩掉。可以把错误包装成模型能理解的信息:权限不足、参数缺失、接口超时、结果为空、需要用户确认。
这样模型才有机会调整下一步。
比如:
Observation: 查看页面失败。原因:当前用户没有查看该页面的管理员权限。
这比直接抛异常更适合 Agent 循环。
第四,要有停止条件。
ReAct 是循环,循环就需要刹车。
人类也会钻牛角尖,只是人类一般会被饭点拯救。程序不会。
最大调用次数、最大耗时、重复工具调用检测、危险动作确认,这些都不是装饰。没有这些控制,Agent 很可能在"再试一次"里一直打转。
第五,权限不能交给模型。
在 Agent 系统里,我更愿意把模型看成一个会表达意图的协作者,而不是一个可以直接拿钥匙的人。
如果要学习 ReAct,我会怎么走
如果完全没接触过,我不建议一上来就读框架源码。
坦诚而言,我第一次接触的时候,根本看不懂框架源码。
框架很好,但它会一次性把很多抽象推到你面前:Graph、Node、State、Tool、Executor、Memory、Checkpoint、Middleware。每个都不难,但一起出现时,很容易让人以为 Agent 是一座很大的机器。
可以先从一个最小版本开始。
第一步,理解普通聊天模型。
输入用户问题,模型输出回答。这个阶段先不要想工具。知道模型本质上是在根据上下文生成下一段内容就够了。
第二步,理解工具调用。
给模型一组工具说明,让它在需要时输出结构化的调用请求。注意,这个请求本身不会执行任何东西。真正执行函数的是你的程序。
第三步,把工具结果放回上下文。
程序执行工具之后,把结果作为一条新消息交还给模型。模型看到结果,再继续回答。
第四步,加上循环。
如果模型还需要第二个工具,就继续执行。直到模型给出最终答案,或者达到最大轮数。
这就是最小 ReAct Agent。
它可能只有几十行代码,但足够让你摸到核心。
等这个循环跑通之后,再看 LangGraph、LangChain、AutoGen 或其他 Agent 框架,会轻松很多。
理解了地基,再看楼层,就不会晕。
我眼中的 ReAct
我眼中的 ReAct,不是一个过时的 prompt 模板,也不是一个万能的 Agent 答案。
它更像一个学习 Agent 的入口。
它把很多后来变得复杂的东西,压缩成一个很小的循环:想一想,做一步,看结果,再想一想。
这个循环朴素到容易被低估。
但 Agent 的很多关键问题,都能从这里长出来:工具怎么设计,结果怎么返回,错误怎么处理,权限怎么控制,循环什么时候停止,过程怎么记录,用户为什么应该信任最后的回答。
学 ReAct 的意义,也许不在于记住三个关键词。
更重要的是建立一种边界感:模型负责判断和表达意图,工具负责接触外部世界,程序负责执行和约束,观察结果负责把现实带回上下文。
这几个边界清楚之后,Agent 就没那么玄了。
它仍然复杂,也仍然会出错,但至少可以拆开看、一步步调、慢慢改。
很多技术都是这样。
站远了看,像一团雾。
走近一点,发现里面其实是一串脚印。
ReAct 做的事,就是让模型每走一步,都尽量在地上留下一个印子。我们顺着这些印子,才知道它到底走到了哪里。
参考链接
- ReAct: Synergizing Reasoning and Acting in Language Models
- ReAct arXiv: 2210.03629
- Google Research Blog: ReAct: Synergizing Reasoning and Acting in Language Models
- Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
- WebGPT: Browser-assisted question-answering with human feedback
- Do As I Can, Not As I Say: Grounding Language in Robotic Affordances
- LangGraph Agents 文档:ReAct pattern 与工具循环
- On the Brittle Foundations of ReAct Prompting for Agentic Large Language Models