从 0 到 1 构建 AI 创意工具:独立开发者的 LLM 应用实战
一、AI 浪潮下的独立开发机遇
去年 3 月,ChatGPT 发布了。
作为一个一直关注 AI 领域的独立开发者,我敏锐地感觉到:这次不一样。
之前的 AI 概念热了一波又一波,但真正能落地到独立开发者可用程度的,寥寥无几。而 ChatGPT 的出现,让我看到了可能性------一个普通人可以通过 API 调用强大的 AI 能力,然后用它来解决实际问题。
这意味着什么?意味着独立开发者第一次有机会与大公司的 AI 能力站在同一起跑线上。
接下来的半年,我做了三款 AI 创意工具,有两款扑街了,一款活了下来。今天聊聊我做 AI 产品的方法论,以及踩过的坑。
二、产品设计:从"AI 能做什么"到"用户需要什么"
最容易犯的错误:看到 AI 能做什么,就想做什么。
比如 AI 能生成图片,我就做一个"AI 生成头像"的工具。结果呢?用户来了,问"能不能生成二次元的?"、"能不能生成写实的?"、"生成的我不太满意怎么办?"
每个问题背后都是一个产品决策,而我没有提前想清楚。
后来我学聪明了:先做用户调研,再决定做什么。
我的第一款成功的 AI 产品"AI 邮件助手",就是在用户调研中发现的痛点:
"每天要处理 100+ 封邮件,大部分都是可以模板化回复的,但手动写太耗时。"
这个痛点清晰、可验证、付费意愿强(节省时间 = 节省金钱)。
产品定位的关键:
- 目标用户是谁:不是所有人,而是特定场景下的特定用户
- 解决什么问题:不是泛泛的"提高效率",而是具体的、可以量化的痛点
- 为什么选你而不是用 ChatGPT:差异化在哪里
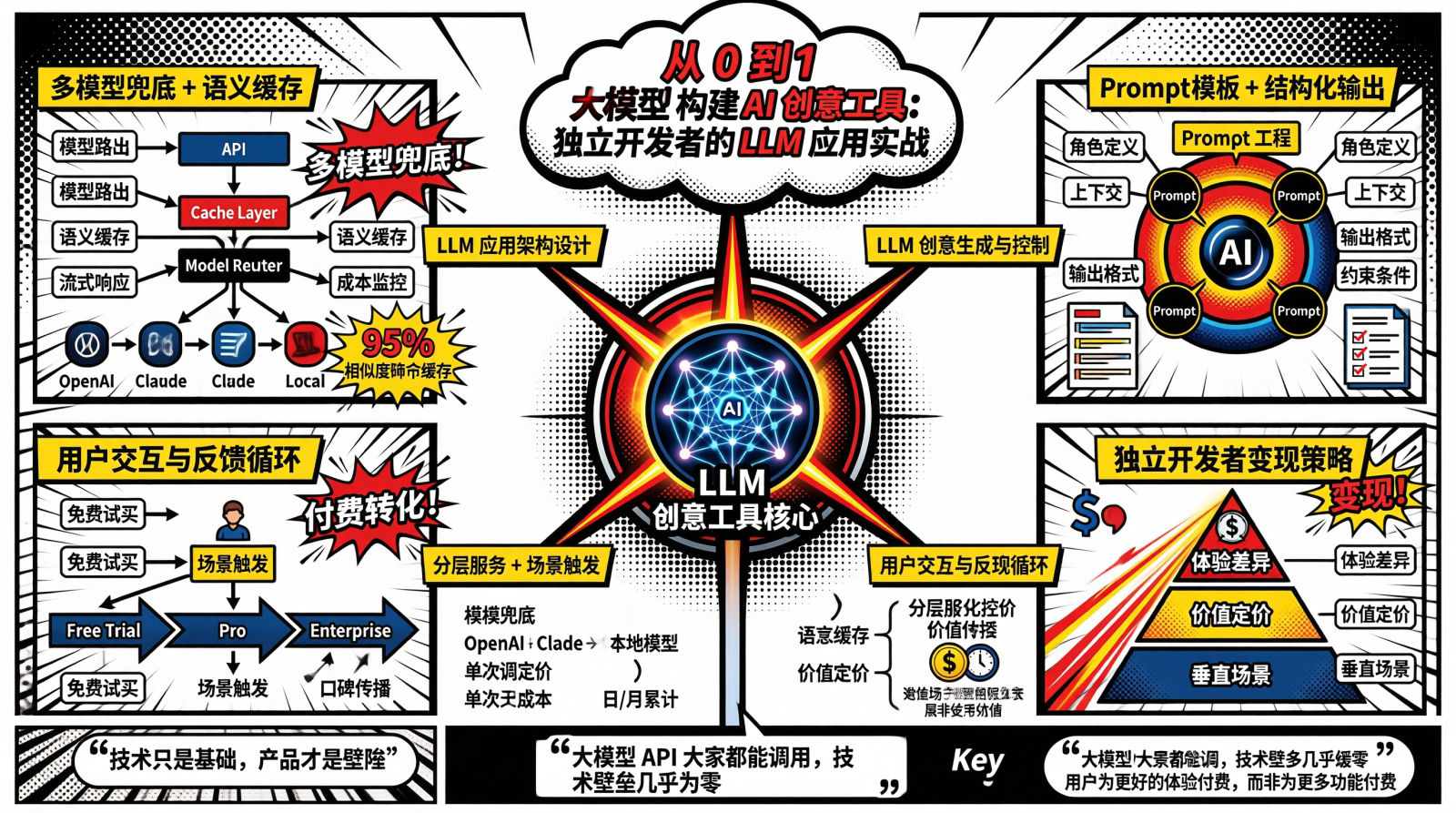
三、技术架构:大模型 API 的工程实践
核心问题:如何稳定地调用大模型 API?
大模型 API 的调用跟普通 API 不同:
- 响应时间长:一次调用可能需要几秒到几十秒
- 成本高:按 token 计费,需要优化使用量
- 不稳定:服务商可能限流、涨价、甚至倒闭
- 需要特殊处理:流式响应、系统提示词等
我的架构演进史
一开始我用的是最简单的方案:用户请求 → 调用 OpenAI API → 返回结果。结果第一个月就遇到问题:OpenAI 限流,高峰期 API 调用失败率超过 30%。
后来加了缓存,效果好了一些。但缓存命中率不高,因为用户输入的变体太多。
再后来我加了多模型兜底,并接入了 Claude 作为备选。同时优化了 Prompt,减少 token 消耗。
现在我的架构是这样的:每个用户请求先进入 API 网关,网关会检查缓存是否命中。命中则直接返回,未命中则进入 AI 模型路由层。路由层会依次尝试 OpenAI、Claude、本地模型,直到有一个成功。每个成功的响应都会存入缓存,供后续相似请求使用。
这个架构的代价是开发复杂度增加了很多。但对于一个需要稳定运行的产品来说,这点复杂度是值得的。
关键工程决策:
1. 多模型兜底:不能只依赖一个 API 服务商。OpenAI 挂了怎么办?Claude 限流了怎么办?需要设计降级策略。
javascript
class AIModelRouter {
constructor() {
this.providers = [
{ name: 'openai', priority: 1, client: new OpenAIClient() },
{ name: 'claude', priority: 2, client: new ClaudeClient() },
{ name: 'local', priority: 3, client: new LocalModelClient() }
];
}
async complete(prompt, options = {}) {
const startTime = Date.now();
for (const provider of this.providers) {
try {
const result = await this.callWithTimeout(
provider.client.complete(prompt, options),
30000 // 30秒超时
);
return {
content: result.content,
provider: provider.name,
latency: Date.now() - startTime,
cached: false
};
} catch (error) {
console.warn(`${provider.name} failed:`, error.message);
// 尝试下一个 provider
continue;
}
}
throw new Error('All AI providers failed');
}
async callWithTimeout(promise, timeout) {
return Promise.race([
promise,
new Promise((_, reject) =>
setTimeout(() => reject(new Error('Timeout')), timeout)
)
]);
}
}2. 缓存策略:大模型 API 调用成本高、耗时长。对于相同或相似的输入,可以使用缓存减少 API 调用。
javascript
class SemanticCache {
constructor(embeddings, vectorDB) {
this.embeddings = embeddings;
this.vectorDB = vectorDB;
this.similarityThreshold = 0.95; // 95% 相似度才命中
}
async getOrCompute(prompt, computeFn) {
// 将 prompt 转为向量
const embedding = await this.embeddings.embed(prompt);
// 查询相似缓存
const cached = await this.vectorDB.search({
vector: embedding,
topK: 1,
filter: { promptHash: this.hashPrompt(prompt) }
});
if (cached.length > 0 && cached[0].score >= this.similarityThreshold) {
return {
content: cached[0].content,
cached: true,
latency: 0
};
}
// 计算新结果
const startTime = Date.now();
const content = await computeFn(prompt);
const latency = Date.now() - startTime;
// 存入缓存
await this.vectorDB.insert({
vector: embedding,
content,
promptHash: this.hashPrompt(prompt),
createdAt: Date.now()
});
return { content, cached: false, latency };
}
hashPrompt(prompt) {
// 简单的 hash 用于快速过滤
return crypto.createHash('md5').update(prompt).digest('hex');
}
}3. 流式响应:大模型生成内容需要时间,如果等生成完毕再返回,用户会等待很久。使用流式响应可以让用户立即看到输出,体验好很多。
javascript
// 流式 API 实现
async function* streamAIResponse(prompt) {
const stream = await openai.complete(prompt, { stream: true });
for await (const chunk of stream) {
const token = chunk.choices[0]?.delta?.content || '';
if (token) {
yield token;
}
}
}
// 前端消费流式响应
async function displayStreamResponse(prompt) {
const container = document.getElementById('response');
for await (const token of streamAIResponse(prompt)) {
container.textContent += token;
// 滚动到底部
container.scrollTop = container.scrollHeight;
}
}4. 成本监控:大模型 API 的成本很容易失控。我设置了多层监控:
- 单次调用成本:监控每次 API 调用的 token 消耗
- 日/月累计成本:设置预算上限,超出后自动降级
- 异常检测:检测异常大量的 API 调用(比如死循环)
四、商业化:从免费到付费的转化路径
AI 产品的商业化是个难题。用户习惯了免费使用 ChatGPT,如何让他们愿意为你的工具付费?
我的策略是分层服务:
关键转化点:
-
展示价值:免费用户也能体验核心功能,但要限制使用次数。这个限制要恰到好处------既能展示价值,又能让用户感到不便。
-
场景触发:当用户遇到限制时,正是教育付费价值的最佳时机。比如弹窗提示"今日免费次数已用完,解锁无限使用,仅需 $9.9/月"。
-
口碑传播:好的产品自己会说话,让用户愿意主动推荐。我设置了邀请奖励机制,邀请好友双方都能获得额外使用次数。
定价策略:
定价不是拍脑袋决定的。我对比了竞品的定价,然后根据自己的成本结构和目标用户付费能力来定价。
AI 产品的定价不能只看成本,还要看价值。用户用你的工具省了多少时间?这个时间值多少钱?如果省的时间价值远高于订阅费用,用户就会付费。
五、总结
做 AI 产品一年多,我的最大感受是:技术只是基础,产品才是壁垒。
大模型 API 大家都能调用,技术壁垒几乎为零。真正的壁垒来自于:
-
垂直场景的深度理解:理解用户的具体需求,比泛泛的 AI 应用更有价值。比如同样是 AI 写作,写代码和写营销文案是完全不同的场景,需要不同的优化。
-
体验的打磨:响应速度、交互设计、错误提示,每个细节都影响用户留存。用户不会因为你的技术有多先进而留下,而是因为你的产品用起来有多顺畅而留下。
-
数据的积累:用户使用过程中产生的数据,可以用于优化模型和个性化推荐。这些数据是你的护城河,别人抄不走。
-
品牌信任:AI 产品存在信任问题。用户会担心数据安全、隐私泄露、输出质量不稳定。通过品牌建设,建立用户对产品的信任,是长期竞争的关键。
独立开发者在 AI 时代的机遇在于:用 AI 解决细分场景的问题,用产品力建立用户忠诚度。
技术会越来越便宜,但好产品永远稀缺。这才是独立开发者应该追求的方向。
附录:AI 产品开发的常见陷阱
根据我这一年的经验,总结了 AI 产品开发中容易踩的坑,供大家参考:
陷阱一:技术先行,产品在后
这是最容易犯的错误。看到 AI 能做什么,就想做这个,而不考虑用户是否真的需要。
陷阱二:功能堆砌,忽视体验
以为功能越多越好,结果产品变得臃肿,用户体验差。
陷阱三:忽视成本,定价失当
AI 的成本结构跟传统软件不同,不能简单套用 SaaS 的定价模型。
陷阱四:过度依赖单一 API
把业务完全绑定在某个 AI 服务商上,风险太大。
陷阱五:忽视数据安全
AI 产品涉及用户数据,必须重视数据安全和隐私保护。
如何避免这些陷阱?
首先,始终以用户为中心。技术只是手段,满足用户需求才是目的。
其次,从小处着手,快速验证。不要一开始就做一个大而全的产品,先验证核心假设,再逐步迭代。
最后,保持学习和迭代。AI 领域变化很快,需要持续关注行业动态,及时调整策略。
AI 时代的独立开发者,既是挑战,也是机遇。希望我的经验能给你一些启发。