图结构断点实现Agent与人进行交互
人在环路与断点
人在环路(Human-in-the-loop,简称 HIL)交互对于 Agent 系统至关重要,特别是在一些特定领域的 Agent 中,需要经过人类的允许或者指示才能进入下一步(例如某些敏感或者重要操作),而 HIL 最重要的部分就是 断点。
断点 建立在 LangGraph 检查点之上,检查点在每个节点执行后保存图的状态,并且 检查点 可以使得图执行可以在特定点暂停,等待人为批准,然后从最后一个检查点恢复执行。
流程图如下:
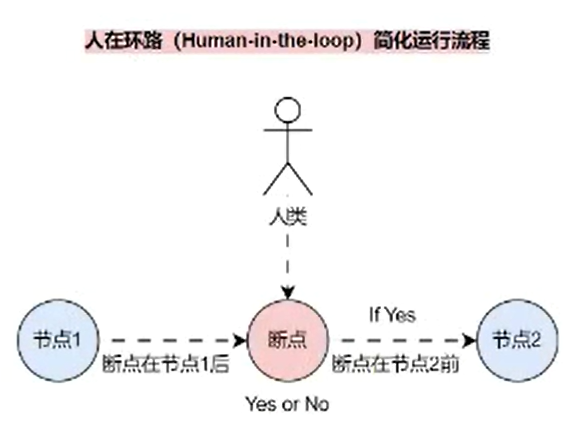
通过流程图很容易可以知道,要想实现 断点 与 人机交互,其实要做的事情很简单:
- 在图中设置 断点,这样图结构应用程序才可以知道在哪个节点中断;
- 针对人类的交互进行判断,执行相应的操作,恢复执行,亦或者更换执行;
在 LangGraph 中可以通过在 .compile() 编译的时候传递 interrupt_before(前置断点)或者 interrupt_after(后置断点),这样在图结构程序执行到 特定的节点 时就会暂停执行,等待其他操作(例如人类提示,修改状态等)。
如果需要回复图执行,只需要再次调用 invoke/stream 等,并传递 inputs=None,传递输入为 None 意味着像中断没有发生一样继续执行,基于这个思路就可以实现让人类干预图的执行。
例如实现一个 ReACT 智能体,在需要调用工具时向人类发起提问,只有当人类输入 yes 的时候才继续执行工具,否则结束程序,示例:
python
from typing import TypedDict, Annotated, Any, Literal
import dotenv
from langchain_community.tools import GoogleSerperRun
from langchain_community.tools.openai_dalle_image_generation import OpenAIDALLEImageGenerationTool
from langchain_community.utilities import GoogleSerperAPIWrapper
from langchain_community.utilities.dalle_image_generator import DallEAPIWrapper
from langchain_core.pydantic_v1 import BaseModel, Field
from langchain_openai import ChatOpenAI
from langgraph.checkpoint.memory import MemorySaver
from langgraph.graph import START, END, StateGraph
from langgraph.graph.message import add_messages
from langgraph.prebuilt import ToolNode
dotenv.load_dotenv()
class GoogleSerperArgsSchema(BaseModel):
query: str = Field(description="执行谷歌搜索的查询语句")
class DallEArgsSchema(BaseModel):
query: str = Field(description="输入应该是生成图像的文本提示(prompt)")
# 1.定义工具与工具列表
google_serper = GoogleSerperRun(
name="google_serper",
description=(
"一个低成本的谷歌搜索API。"
"当你需要回答有关时事的问题时,可以调用该工具。"
"该工具的输入是搜索查询语句。"
),
args_schema=GoogleSerperArgsSchema,
api_wrapper=GoogleSerperAPIWrapper(),
)
dalle = OpenAIDALLEImageGenerationTool(
name="openai_dalle",
api_wrapper=DallEAPIWrapper(model="dall-e-3"),
args_schema=DallEArgsSchema,
)
class State(TypedDict):
"""图状态数据结构,类型为字典"""
messages: Annotated[list, add_messages]
tools = [google_serper, dalle]
llm = ChatOpenAI(model="gpt-4o-mini")
llm_with_tools = llm.bind_tools(tools)
def chatbot(state: State, config: dict) -> Any:
"""聊天机器人函数"""
# 1.获取状态里存储的消息列表数据并传递给LLM
ai_message = llm_with_tools.invoke(state["messages"])
# 2.返回更新/生成的状态
return {"messages": [ai_message]}
def route(state: State, config: dict) -> Literal["tools", "__end__"]:
"""动态选择工具执行亦或者结束"""
# 1.获取生成的最后一条消息
ai_message = state["messages"][-1]
# 2.检测消息是否存在tool_calls参数,如果是则执行`工具路由`
if hasattr(ai_message, "tool_calls") and len(ai_message.tool_calls) > 0:
return "tools"
# 3.否则生成的内容是文本信息,则跳转到结束路由
return END
# 1.创建状态图,并使用GraphState作为状态数据
graph_builder = StateGraph(State)
# 2.添加节点
graph_builder.add_node("llm", chatbot)
graph_builder.add_node("tools", ToolNode(tools=tools))
# 3.添加边
graph_builder.add_edge(START, "llm")
graph_builder.add_edge("tools", "llm")
graph_builder.add_conditional_edges("llm", route)
# 4.编译图为Runnable可运行组件
checkpointer = MemorySaver()
graph = graph_builder.compile(checkpointer=checkpointer, interrupt_before=["tools"])
# 5.调用图架构应用
config = {"configurable": {"thread_id": 1}}
state = graph.invoke(
{"messages": [("human", "2024年北京半程马拉松的前3名成绩是多少")]},
config=config,
)
print(state)
# 6.进行人机交互
if hasattr(state["messages"][-1], "tool_calls") and len(state["messages"][-1].tool_calls) > 0:
print("现在准备调用工具: ", state["messages"][-1].tool_calls)
human_input = input("如果需要执行工具请输入yes,否则请输入no: ")
if human_input.lower() == "yes":
print(graph.invoke(None, config)["messages"][-1].content)
else:
print("图程序执行完毕")如果在二次执行 invoke/stream 的时候传递的并不是 None,而是对相应的状态进行更新然后继续执行。
在这种情况下,在这里额外更新状态要确保消息列表符合大语言模型的消息列表规范,避免发生错误,也尽可能不在这里额外修改有函数调用的状态。
在图结构上更新对应状态
在 LangGraph 的图结构上,除了能通过 节点 更新 数据状态,还可以在图的外部通过调用图的 get_state() 与 update_state() 的方式来实现对数据状态的更新(特定线程下),并且 get_state() 和 update_state() 功能必须在 检查点 模式下才支持。
例如在上述的案例中,我们在 中断 程序后,修改 工具消息 的内容变成 2024年北京半程马拉松的第一名为慕小课01:59:40,第二名为慕二课成绩为02:04:16,第三名为慕三课02:15:17,这个时候大语言模型会收到如下的消息列表:
- Human:请帮我绘制一幅老爷爷爬山的图片。
- Ai:调用 google_serper() 工具,并搜索 "2024 年北京半程马拉松前 3 名成绩"。
- Tool:2024 年北京半程马拉松的第一名为慕小课 01:59:40,第二名为慕二课成绩为 02:04:16,第三名为慕三课 02:15:17。
在上述示例中,我们人为篡改了 工具调用 返回的结果,让 ReACT 智能体去输出基于这个工具得到的答案。
代码示例如下:
python
from typing import TypedDict, Annotated, Any, Literal
import dotenv
from langchain_community.tools import GoogleSerperRun
from langchain_community.tools.openai_dalle_image_generation import OpenAIDALLEImageGenerationTool
from langchain_community.utilities import GoogleSerperAPIWrapper
from langchain_community.utilities.dalle_image_generator import DallEAPIWrapper
from langchain_core.messages import ToolMessage
from langchain_core.pydantic_v1 import BaseModel, Field
from langchain_openai import ChatOpenAI
from langgraph.checkpoint.memory import MemorySaver
from langgraph.graph import START, END, StateGraph
from langgraph.graph.message import add_messages
from langgraph.prebuilt import ToolNode
dotenv.load_dotenv()
class GoogleSerperArgsSchema(BaseModel):
query: str = Field(description="执行谷歌搜索的查询语句")
class DallEArgsSchema(BaseModel):
query: str = Field(description="输入应该是生成图像的文本提示(prompt)")
# 1.定义工具与工具列表
google_serper = GoogleSerperRun(
name="google_serper",
description=(
"一个低成本的谷歌搜索API。"
"当你需要回答有关时事的问题时,可以调用该工具。"
"该工具的输入是搜索查询语句。"
),
args_schema=GoogleSerperArgsSchema,
api_wrapper=GoogleSerperAPIWrapper(),
)
dalle = OpenAIDALLEImageGenerationTool(
name="openai_dalle",
api_wrapper=DallEAPIWrapper(model="dall-e-3"),
args_schema=DallEArgsSchema,
)
class State(TypedDict):
"""图状态数据结构,类型为字典"""
messages: Annotated[list, add_messages]
tools = [google_serper, dalle]
llm = ChatOpenAI(model="gpt-4o-mini")
llm_with_tools = llm.bind_tools(tools)
def chatbot(state: State, config: dict) -> Any:
"""聊天机器人函数"""
# 1.获取状态里存储的消息列表数据并传递给LLM
ai_message = llm_with_tools.invoke(state["messages"])
# 2.返回更新/生成的状态
return {"messages": [ai_message]}
def route(state: State, config: dict) -> Literal["tools", "__end__"]:
"""动态选择工具执行亦或者结束"""
# 1.获取生成的最后一条消息
ai_message = state["messages"][-1]
# 2.检测消息是否存在tool_calls参数,如果是则执行`工具路由`
if hasattr(ai_message, "tool_calls") and len(ai_message.tool_calls) > 0:
return "tools"
# 3.否则生成的内容是文本信息,则跳转到结束路由
return END
# 1.创建状态图,并使用GraphState作为状态数据
graph_builder = StateGraph(State)
# 2.添加节点
graph_builder.add_node("llm", chatbot)
graph_builder.add_node("tools", ToolNode(tools=tools))
# 3.添加边
graph_builder.add_edge(START, "llm")
graph_builder.add_edge("tools", "llm")
graph_builder.add_conditional_edges("llm", route)
# 4.编译图为Runnable可运行组件
checkpointer = MemorySaver()
graph = graph_builder.compile(checkpointer=checkpointer, interrupt_after=["tools"])
# 5.调用图架构应用
config = {"configurable": {"thread_id": 1}}
state = graph.invoke(
{"messages": [("human", "2024年北京半程马拉松的前3名成绩是多少")]},
config,
)
print(state)
# 6.更新图的状态,去篡改工具消息
graph_state = graph.get_state(config)
tool_message = ToolMessage(
# id是告诉归纳函数我和原始数据重复了,请直接覆盖
id=graph_state[0]["messages"][-1].id,
# 告诉大语言模型工具调用id,这里的工具调用id是让大语言模型知道这条消息是和哪个函数关联
tool_call_id=graph_state[0]["messages"][-2].tool_calls[0]["id"],
name=graph_state[0]["messages"][-2].tool_calls[0]["name"],
content="2024年北京半程马拉松的第一名为慕小课01:59:40,第二名为慕二课成绩为02:04:16,第三名为慕三课02:15:17"
)
print("下一个步骤:", graph_state[1])
graph.update_state(config, {"messages": [tool_message]})
print(graph.invoke(None, config)["messages"][-1].content)langGraph子图架构实现AI工作流
子图结构与应用场景
对于一些更加复杂的系统,子图是一个非常有用的设计原则。使用子图允许在图的不同部分创建和管理不同的状态,这样可以轻松利用 LangGraph 实现类似 多智能体 亦或者 AI 工作流 之类的功能,每个功能之间相互独立隔离,最后组装成一个大型复杂应用。
大家如果有使用过 Dify、Coze 等 AI 应用开发平台的 工作流,亦或者是 MetaGPT、AutoGPT、BabyAGI 等智能体框架,在这些功能下就涉及到了 多智能体 亦或者 多 Agent 应用 的相互协作与组成。
前面我们说过,LangGraph 的节点可以是任意的 Python 函数或者是 Runnable 可运行组件,并且 图程序 经过编译后就是一个 Runnable 可运行组件,所以我们可以考虑将其中一个 图程序 作为另外一个 图程序 的节点,这样就变相在 LangGraph 中去实现子图,从而将一些功能相近的节点单独组装成图,单独进行状态的管理。
而创建 子图 最核心的部分要认识到 图 之间的信息传递,入口图 是父级,两个子图都被定义成 入口图 的节点,并且两个子图都继承了父级 入口图 的状态,并且每个子图都可以拥有自己的私有状态,任何想传回父级 入口图 的值,只需要在入口图中定义即可。
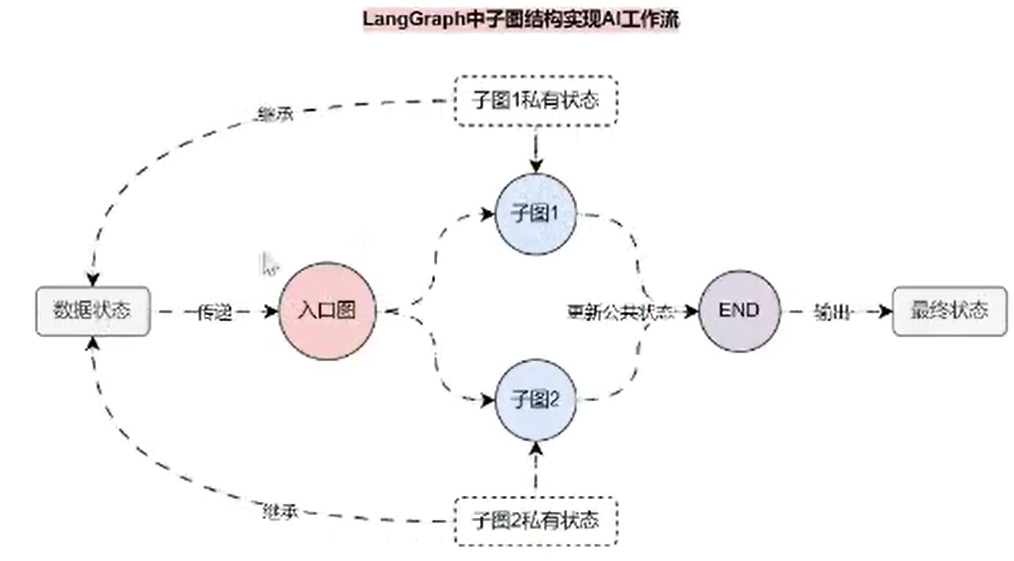
另外需要注意的是,如果定义了 多边,那么必须定义 归约函数,因为多边的执行是 并行的,如果不定义归约函数,数据会直接覆盖。由于并行的顺序是不确定的,如果不定义归约函数,数据可能会出现相互覆盖的问题。实际上在 LangGraph 编译的过程中,如果一个图有多边并行的情况,并且没有为每个字段都定义 归约函数,会直接抛出错误。
langGraph实现示例
例如我们实现一个 营销智能体,其功能为根据用户传递的原始问题生成一篇【直播带货】脚本、一篇【小红书推广】文案,在这里用户传递一段原始 Prompt,会调用两个 Agent 智能体并行完成各自的任务,最后再进行合并输出。
针对这类需求,我们可以使用 单图结构 来构建,也可以创建 多图结构 来构建,更推荐使用 多图结构,其优势也非常明显:
- 多图结构状态设计更简单,不用一次性考虑所有 Agent 智能体的状态,可以每个智能体单独管理自己的状态。
- 多图结构更易于扩展,后续需要添加多一个 百度 SEO 推广文案 Agent,只需添加多一个节点即可,程序无需大量调整。
实现示例如下:
python
from typing import TypedDict, Any, Annotated
import dotenv
from langchain_community.tools import GoogleSerperRun
from langchain_community.utilities import GoogleSerperAPIWrapper
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.pydantic_v1 import BaseModel, Field
from langchain_core.runnables import RunnableConfig
from langchain_openai import ChatOpenAI
from langgraph.graph import MessagesState, StateGraph
from langgraph.prebuilt import ToolNode, tools_condition
dotenv.load_dotenv()
llm = ChatOpenAI(model="gpt-4o-mini")
class GoogleSerperArgsSchema(BaseModel):
query: str = Field(description="执行谷歌搜索的查询语句")
google_serper = GoogleSerperRun(
api_wrapper=GoogleSerperAPIWrapper(),
args_schema=GoogleSerperArgsSchema,
)
def reduce_str(left: str | None, right: str | None) -> str:
if right is not None and right != "":
return right
return left
class AgentState(TypedDict):
query: Annotated[str, reduce_str] # 原始问题
live_content: Annotated[str, reduce_str] # 直播文案
xhs_content: Annotated[str, reduce_str] # 小红书文案
class LiveAgentState(AgentState, MessagesState):
"""直播文案智能体状态"""
pass
class XHSAgentState(AgentState):
"""小红书文案智能体状态"""
pass
def chatbot_live(state: LiveAgentState, config: RunnableConfig) -> Any:
"""直播文案智能体聊天机器人节点"""
# 1.创建提示模板+链应用
prompt = ChatPromptTemplate.from_messages([
(
"system",
"你是一个拥有10年经验的直播文案专家,请根据用户提供的产品整理一篇直播带货脚本文案,如果在你的知识库内找不到关于该产品的信息,可以使用搜索工具。"
),
("human", "{query}"),
("placeholder", "{chat_history}"),
])
chain = prompt | llm.bind_tools([google_serper])
# 2.调用链并生成ai消息
ai_message = chain.invoke({"query": state["query"], "chat_history": state["messages"]})
return {
"messages": [ai_message],
"live_content": ai_message.content,
}
# 1.创建子图1并添加节点、添加边
live_agent_graph = StateGraph(LiveAgentState)
live_agent_graph.add_node("chatbot_live", chatbot_live)
live_agent_graph.add_node("tools", ToolNode([google_serper]))
live_agent_graph.set_entry_point("chatbot_live")
live_agent_graph.add_conditional_edges("chatbot_live", tools_condition)
live_agent_graph.add_edge("tools", "chatbot_live")
def chatbot_xhs(state: XHSAgentState, config: RunnableConfig) -> Any:
"""小红书文案智能体聊天节点"""
# 1.创建提示模板+链
prompt = ChatPromptTemplate.from_messages([
("system",
"你是一个小红书文案大师,请根据用户传递的商品名,生成一篇关于该商品的小红书笔记文案,注意风格活泼,多使用emoji表情。"),
("human", "{query}"),
])
chain = prompt | llm | StrOutputParser()
# 2.调用链并生成内容更新状态
return {"xhs_content": chain.invoke({"query": state["query"]})}
# 2.创建子图2并添加节点、添加边
xhs_agent_graph = StateGraph(XHSAgentState)
xhs_agent_graph.add_node("chatbot_xhs", chatbot_xhs)
xhs_agent_graph.set_entry_point("chatbot_xhs")
xhs_agent_graph.set_finish_point("chatbot_xhs")
# 3.创建入口图并添加节点、边
def parallel_node(state: AgentState, config: RunnableConfig) -> Any:
return state
agent_graph = StateGraph(AgentState)
agent_graph.add_node("parallel_node", parallel_node)
agent_graph.add_node("live_agent", live_agent_graph.compile())
agent_graph.add_node("xhs_agent", xhs_agent_graph.compile())
agent_graph.set_entry_point("parallel_node")
agent_graph.add_edge("parallel_node", "live_agent")
agent_graph.add_edge("parallel_node", "xhs_agent")
agent_graph.set_finish_point("live_agent")
agent_graph.set_finish_point("xhs_agent")
# 4.编译入口图
agent = agent_graph.compile()
# 5.执行入口图并打印结果
print(agent.invoke({"query": "潮汕牛肉丸"}))需求转换图架构的技巧
CRAG图结构拆解与状态管理
在前面的课时中,我们学习了 CRAG(纠正性索引增强生成)优化策略,在该优化策略中引入了一个轻量级的评估器用于评估检索到的文档的质量,并根据评估结果触发不同的知识检索动作,其整体运行流程如下:
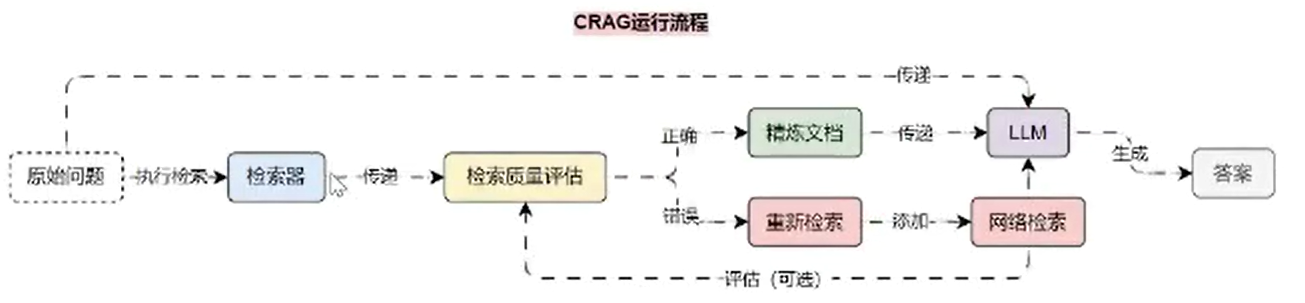
在 CRAG 优化策略中,存在条件分支,即通过检索质量评估后,需要条件选择精炼文档亦或者是网络检索,所以没办法利用 LCEL 表达式进行构建,判断是使用 LCEL 亦或者 LangGraph 来构建程序的标准如下:
- 应用是顺序线性,并且无条件分支、无循环,优先考虑 LCEL 表达式;
- 存在任意条件分支亦或者任意循环,则该部分可以使用 LangGraph 构建,其余部分仍然可以使用 LCEL 表达式进行拼接;
- 在节点组件交多,并且难以提取出公共数据状态的情况下,可以优先使用 LCEL 表达式,然后再使用 LangGraph 改造;
而无论是构建 LCEL 亦或者是 LangGraph 应用,其步骤都是大差不差:
- 分析使用 LCEL 还是使用 LangGraph 来实现,亦或者是混合使用。
- 确定整个程序的节点和各个边,涵盖了起点、终点、条件边、循环等。
- 提炼各个节点之间的公共数据,制作数据状态,确定归纳函数逻辑,或者使用覆盖更新的方式。
- 完成应用程序的各个节点函数,并构建图,添加节点。
- 按照应用程序的流向为各个节点添加边,从起点开始,直到结束。
- 编译程序,检测是否需要检查点、是否需要断点等功能
- 调用程序并提取输出内容
LangGraph实现示例
python
from typing import TypedDict, Any
import dotenv
import weaviate
from langchain_community.tools import GoogleSerperRun
from langchain_community.utilities import GoogleSerperAPIWrapper
from langchain_core.documents import Document
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.pydantic_v1 import BaseModel, Field
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain_weaviate import WeaviateVectorStore
from langgraph.graph import StateGraph
from weaviate.auth import AuthApiKey
dotenv.load_dotenv()
class GradeDocument(BaseModel):
"""文档评分Pydantic模型"""
binary_score: str = Field(description="文档与问题是否关联,请回答yes或者no")
class GoogleSerperArgsSchema(BaseModel):
query: str = Field(description="执行谷歌搜索的查询语句")
class GraphState(TypedDict):
"""图结构应用程序数据状态"""
question: str # 原始问题
generation: str # 大语言模型生成内容
web_search: str # 网络搜索内容
documents: list[str] # 文档列表
def format_docs(docs: list[Document]) -> str:
"""格式化传入的文档列表为字符串"""
return "\n\n".join([doc.page_content for doc in docs])
# 1.创建大语言模型
llm = ChatOpenAI(model="gpt-4o-mini")
# 2.创建检索器
vector_store = WeaviateVectorStore(
client=weaviate.connect_to_wcs(
cluster_url="https://uiufdvagtjkaf9i4ey0a.c0.us-west3.gcp.weaviate.cloud",
auth_credentials=AuthApiKey("zGnUn1q5oI3hQUtmqP4NiRty83LNLqDaGoqw"),
),
index_name="LLMOps",
text_key="text",
embedding=OpenAIEmbeddings(model="text-embedding-3-small"),
)
retriever = vector_store.as_retriever(search_type="mmr")
# 3.构建检索评估器
system = """你是一名评估检索到的文档与用户问题相关性的评估员。
如果文档包含与问题相关的关键字或语义,请将其评级为相关。
给出一个是否相关得分为yes或者no,以表明文档是否与问题相关。"""
grade_prompt = ChatPromptTemplate.from_messages([
("system", system),
("human", "检索文档: \n\n{document}\n\n用户问题: {question}"),
])
retrieval_grader = grade_prompt | llm.with_structured_output(GradeDocument)
# 4.RAG检索增强生成
template = """你是一个问答任务的助理。使用以下检索到的上下文来回答问题。如果不知道就说不知道,不要胡编乱造,并保持答案简洁。
问题: {question}
上下文: {context}
答案: """
prompt = ChatPromptTemplate.from_template(template)
rag_chain = prompt | llm.bind(temperature=0) | StrOutputParser()
# 5.网络搜索问题重写
rewrite_prompt = ChatPromptTemplate.from_messages([
(
"system",
"你是一个将输入问题转换为优化的更好版本的问题重写器并用于网络搜索。请查看输入并尝试推理潜在的语义意图/含义。"
),
("human", "这里是初始化问题:\n\n{question}\n\n请尝试提出一个改进问题。")
])
question_rewriter = rewrite_prompt | llm.bind(temperature=0) | StrOutputParser()
# 6.网络搜索工具
google_serper = GoogleSerperRun(
name="google_serper",
description="一个低成本的谷歌搜索API。当你需要回答有关时事的问题时,可以调用该工具。该工具的输入是搜索查询语句。",
args_schema=GoogleSerperArgsSchema,
api_wrapper=GoogleSerperAPIWrapper(),
)
# 7.构建图相关节点函数
def retrieve(state: GraphState) -> Any:
"""检索节点,根据原始问题检索向量数据库"""
print("---检索节点---")
question = state["question"]
documents = retriever.invoke(question)
return {"documents": documents, "question": question}
def generate(state: GraphState) -> Any:
"""生成节点,根据原始问题+上下文内容调用LLM生成内容"""
print("---LLM生成节点---")
question = state["question"]
documents = state["documents"]
generation = rag_chain.invoke({"context": format_docs(documents), "question": question})
return {"question": question, "documents": documents, "generation": generation}
def grade_documents(state: GraphState) -> Any:
"""文档与原始问题关联性评分节点"""
print("---检查文档与问题关联性节点---")
question = state["question"]
documents = state["documents"]
filtered_docs = []
web_search = "no"
for doc in documents:
score: GradeDocument = retrieval_grader.invoke({
"question": question, "document": doc.page_content,
})
grade = score.binary_score
if grade.lower() == "yes":
print("---文档存在关联---")
filtered_docs.append(doc)
else:
print("---文档不存在关联---")
web_search = "yes"
continue
return {**state, "documents": filtered_docs, "web_search": web_search}
def transform_query(state: GraphState) -> Any:
"""重写/转换查询节点"""
print("---重写查询节点---")
question = state["question"]
better_question = question_rewriter.invoke({"question": question})
return {**state, "question": better_question}
def web_search(state: GraphState) -> Any:
"""网络检索节点"""
print("---网络检索节点---")
question = state["question"]
documents = state["documents"]
search_content = google_serper.invoke({"query": question})
documents.append(Document(
page_content=search_content,
))
return {**state, "documents": documents}
def decide_to_generate(state: GraphState) -> Any:
"""决定执行生成还是搜索节点"""
print("---路由选择节点---")
web_search = state["web_search"]
if web_search.lower() == "yes":
print("---执行Web搜索节点---")
return "transform_query"
else:
print("---执行LLM生成节点---")
return "generate"
# 8.构件图/工作流
workflow = StateGraph(GraphState)
# 9.定义工作流节点
workflow.add_node("retrieve", retrieve)
workflow.add_node("grade_documents", grade_documents)
workflow.add_node("generate", generate)
workflow.add_node("transform_query", transform_query)
workflow.add_node("web_search_node", web_search)
# 10.定义工作流边
workflow.set_entry_point("retrieve")
workflow.add_edge("retrieve", "grade_documents")
workflow.add_conditional_edges("grade_documents", decide_to_generate)
workflow.add_edge("transform_query", "web_search_node")
workflow.add_edge("web_search_node", "generate")
workflow.set_finish_point("generate")
# 11.编译工作流
app = workflow.compile()
print(app.invoke({"question": "能介绍下什么是LLMOps么?"}))LangGraph两种基础流式响应技巧
LangGraph两种流式模型
在 LangGraph 中,编译后的 图程序 也是一个 Runnable 可运行组件,并支持多种流式模式输出。和 LLM 使用流式模式输出一个一个词不一样,在 LangGraph 中,流式响应每次输出的都是一个节点的 数据状态。在 LangGraph 中流式模式有两种:
- values:此流式模式返回图的值,这是每个节点调用后图的 完整状态(总量);
- updates:此流式模式返回图的更新,这是每个节点调用后图的 状态的更新(增量);
要想使用流式模式非常简单,在调用 stream() 函数时,传递 stream_mode 参数即可配置不同的流式响应模式。以 ReACT 智能体为例,使用流式模式输出 values 模式的数据,代码如下:
python
inputs = {"messages": [("human", "2024年北京半程马拉松的前3名成绩是多少?")]}
for chunk in agent.stream(
inputs,
stream_mode="values",
):
print(chunk["messages"][-1].pretty_print())在上述的代码中,由于使用 values 模式,所以每个节点流式输出的内容都是完整的 数据状态,每次都取出消息中的最后一条并进行格式化输出,输出内容如下:

在上述代码中,可以很清晰看到在 LangGraph 中,流式输出是以 节点 作为单位生成内容的,将 stream_mode 切换成 updates,这样每次流式响应返回的内容是节点对应 状态的更新,调整的代码如下:
python
inputs = {"messages": [("human", "2024年北京半程马拉松的前3名成绩是多少?")]}
for chunk in agent.stream(
inputs,
stream_mode="updates",
):
print(chunk)扩展与思考
在上述的两种流式模式中,虽然可以正确获取每个节点的数据,但是等待的时间仍然过长,特别是和大语言模型相关的节点,其根本原因在于 节点也应该进行流式输出,例如大语言模型节点,在图的流式输出下,也应该保持流式输出,而不是完整输出。
这也是常见的 Agent 的输出方式,例如 Coze、Dify、智谱、GPTs 等,如下:

在上述的动图演示中,可以看到 Agent 执行了几个步骤:知识库检索、工具调用、LLM 生成内容,当每个步骤完成之后都会流式返回内容给前端,并且在一些相对耗时的步骤,例如 LLM 生成内容,也在该步骤内进行了流式输出,这样可以避免用户亦或者 API 接口长时间没有响应导致连接中断,也能提升用户体验。
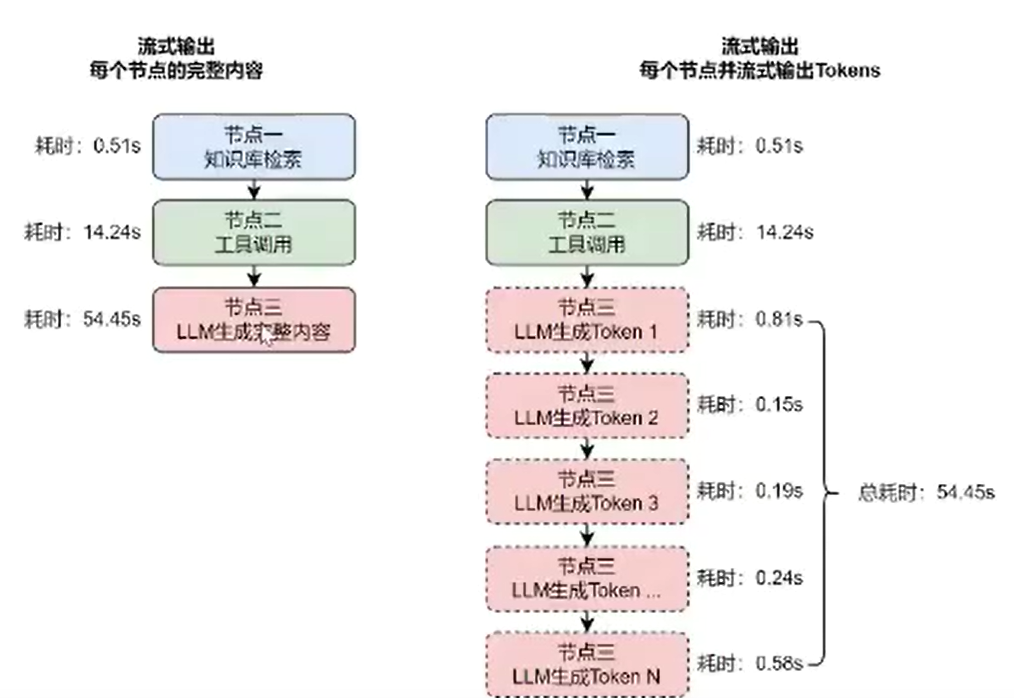
在 LangGraph 中,可以通过 LangGraph 原生的支持来实现 外层节点流式输出 + 节点内部流式事件 方案,不过该方案使用到了异步流式事件的功能;除此之外,也可以通过为节点添加 队列 + 异步 的方式来实现,两种实现方式各有差异与优缺点
LangGraph 的相关参考资料:https://langchain-ai.github.io/langgraph/how-tos/stream-values/
LangGraph总结与注意事项
数据状态与归纳函数
在前面的课时中,我们说过在 LangGraph 中 节点 在默认情况下返回的字典数据会将原始数据覆盖,例如下面的代码最终返回结果是 {"messages": 4} 而不是 1,2,3,4,如下:
python
class MyState(TypedDict):
messages: list
def fn1(state: MyState):
return {"messages": [4]}
# ... (ignore codes of start->fn1->end, blah blah)
r = graph.invoke({"messages": [1, 2, 3]})如果就是想要 1, 2, 3, 4 呢?第一种方法就是拿到 原始状态 的值,更新新数据,然后返回:
python
def fn1(state: MyState):
old = state.get("messages", [])
return {"messages": old + [4]}除此之外,在 LangGraph 中,还针对 Annotated 进行了封装,在 Python 中 Annotated 只是另外一种形态的注释,对类型的声明用并没有任何影响,例如:
python
salary: int # 这是一个整数
# 注释说明 cn_salary 不仅仅是一个int类型数据,数据还必须比27470大
cn_salary: Annotated[int, "must be > 27470"]
cn_salary = 22000 # 但是实际使用时赋值小于的数也不会报错,这是因为这仅仅是一个注释不过这样声明有一个好处,在程序中,我们可以通过 .metadata 元数据属性拿到这个值,如下:
python
cn_salary.__metadata__于是在 LangGraph 中就针对 注释 + 元数据 进行了封装,使用 Annotated 外挂需要处理数据的 归纳函数,如果外挂了则使用,不外挂也没有任何影响,这就是利用 归纳函数 来更新状态的核心。
代码经过更新后,就可以正常对数据执行相应操作了:
python
def concat_lists(original: list, new: list) -> list:
return original + new
class MyState(TypedDict):
# messages: list
messages: Annotated[list, concat_lists]
def fn1(state: MyState):
return {"messages": [4]}
r = graph.invoke({"messages": [1, 2, 3]})
print(r)
# 输出是 {'messages': [1, 2, 3, 4]}使用 归纳函数 的优点也非常明显,可以让每个 节点 独立执行,不用理会别人在做啥,不需要花额外的功夫去处理 state 里的其他数据,而且在更新 state 结构时,也不需要逐个节点更新。但是添加 归纳函数 后要想执行一些特殊的操作也非常麻烦,要额外花很多功夫,例如在 add_messages() 中的 RemoveMessage 和更新消息,就进行了额外的判断与处理。
多节点并行同时执行
在 LangGraph 中,END 节点非常特殊,并不是 图结构 程序走到 END 节点就终止了,只是 当前路线结束了,也就是说 END 是结束当前路线,并不是结束 图,理解好这个概念才能处理好 多节点并行执行 的情况。
例如如下并行路线:
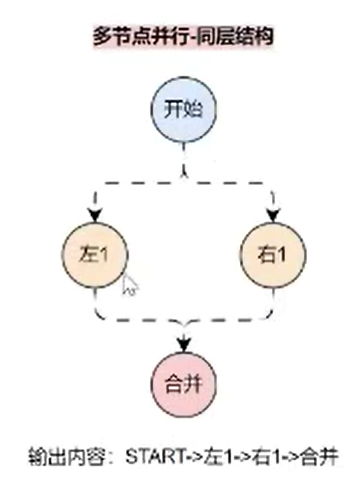
在上述的节点中,如果将图结构转换成带有层级的图,则 左 1 和 右 1 处于同一层级上,所以这两个节点是并行执行的,但是顺序不一定能保证,虽然在 LangGraph 中会按照连接的顺序来执行,最终输出就是:START -> 左1 -> 右1 -> 合并。
如果是以下的并行路线:
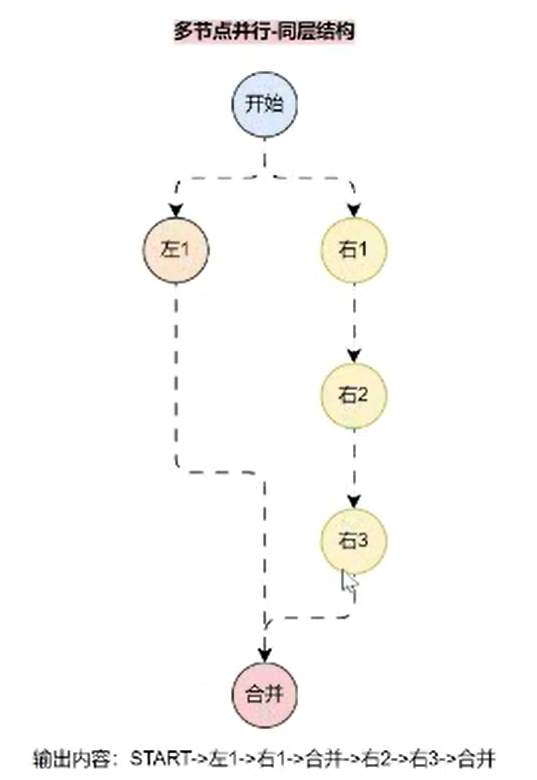
在这个 图结构 中,合并 虽然属于 END 节点,并且在 左 1 执行完成之后就会执行 合并,但是 合并节点 并不会终止整个图的执行,而是会和 右 2 作为同一层一起执行(并行执行,顺序不确定),所以最终输出:START -> 左1 -> 右1 -> 合并 -> 右2 -> 右3 -> 合并。
如果想让 合并 节点只执行一次,只要把 左 1 和 右 3 合并同时连接到 合并 节点上即可,这样这两个节点就处于同一层,更新代码如下:
python
graph.add_edge(["left1", "right3"], "merge")检查点CheckPoint
检查点的概念因为它的名字,初次使用理解起来可能会比较吃力,其实只需要把 检查点 看成是一个 存储介质,用来记录这些资料,就好比游戏存档、不同玩家不同场次,可以存起来,然后载入,甚至篡改更新!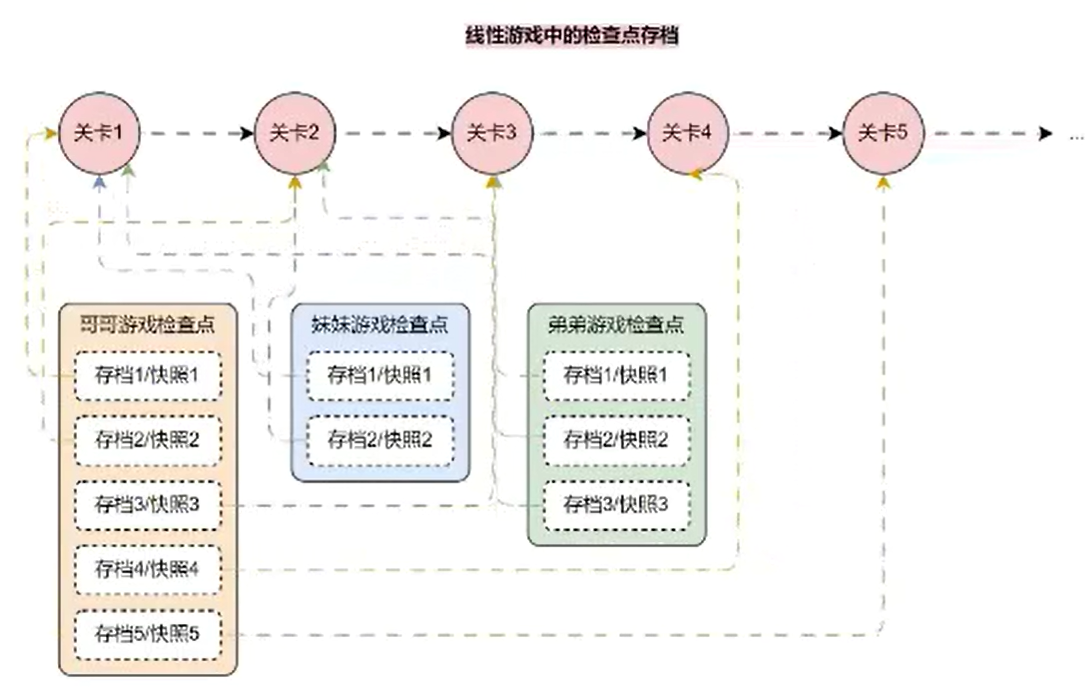
所以在 LangGraph 图程序中加入 检查点 就等同于加入了一个 外部存储介质,会将每一个节点的 状态 都存储起来(StateSnapshot),变成一个历史的 list,所以对于 图程序 必须配置检查点才可以拿到 snapshot 游戏存档:
- graph.get_state(config):拿到 检查点 的最后一次存档(最后一个节点更新后的状态)。
- graph.get_state_history(config):拿到检查点的所有存档(每个节点更新后的状态列表)。
在前面的课时中,我们传递的 config 里只有 thread_id,但是在 get_state_history(config) 拿到的所有存档列表中,还存在另外一个字段 thread_ts 代表线程的执行时间,通过该字段就可以唯一定位检查点中的某个存档,例如:
python
StateSnapshot(..., config={'configurable': {'thread_id': '1', 'thread_ts': '1eff2985c-bed5-6dee-8003-6037939ae5aa'}}, ...)和游戏存档回退一样,如果我们想回退到指定的存档,只需调用 invoke() 玩游戏,并载入指定存档的配置即可:
python
for s in graph.stream(
input=None,
config=past_config, # <--
stream_mode="values"
):
print(s)甚至是我们想篡改 存档 的数据也是可以的,还记得 update_state() 这个函数么,同样可以传入对应的 config,只需要在修改时,传递需要更改的 存档配置 即可,例如:
python
graph.update_state(
config=past_config,
values={"crew": [66, 77], "v": "BAD GUY"}
)不过因为回退机制用得比较少,所以该功能在 LangGraph 的官网藏得也比较深,也没有过多文章做出详细的讲解。