大语言模型推理时,每一轮生成都会产生 Key-Value 缓存(KV Cache),用于避免重复计算历史 token的注意力。但在多轮对话、少样本学习等场景中,不同请求之间往往存在大量相同的前缀,这些前缀对应的 KV缓存如果各自独立计算,就是纯粹的浪费。SGLang 是一个面向 LLM 的程序化推理框架,它用基数树(RadixTree)统一管理所有请求的 KV 缓存,并配合缓存感知调度策略最大化复用率,从而显著提升推理吞吐。
本文基于 SGLang 的相关技术资料,围绕以下三个问题展开:语言模型程序的定义和特点、如何用基数树管理和复用 KV缓存、基于最长匹配序列的缓存感知调度策略。
一、LLM 推理中的 KV 缓存共享机会
在实际业务中,至少有四种对话模式存在大量可共享的 KV 缓存前缀:
少样本学习(Few-shot Learning)中的示例部分。每次请求都会携带若干条示范样本,这些样本在所有请求中完全相同,对应的 KV 缓存理论上只需计算一次。
自洽问答(Self-consistent QA)中的问题部分。同一个问题被发给模型多次以获取不同回答再做投票,问题本身的 KV 缓存完全可以共享。
多轮对话(Multi-turn Chat)中的历史记录。用户每一轮追问都在前几轮的基础上追加,之前轮次的 KV 缓存无需重新计算。
思考树(Tree of Thought)中的搜索历史。搜索过程中多条路径共享相同的前缀节点,前缀部分的 KV 缓存也可以复用。
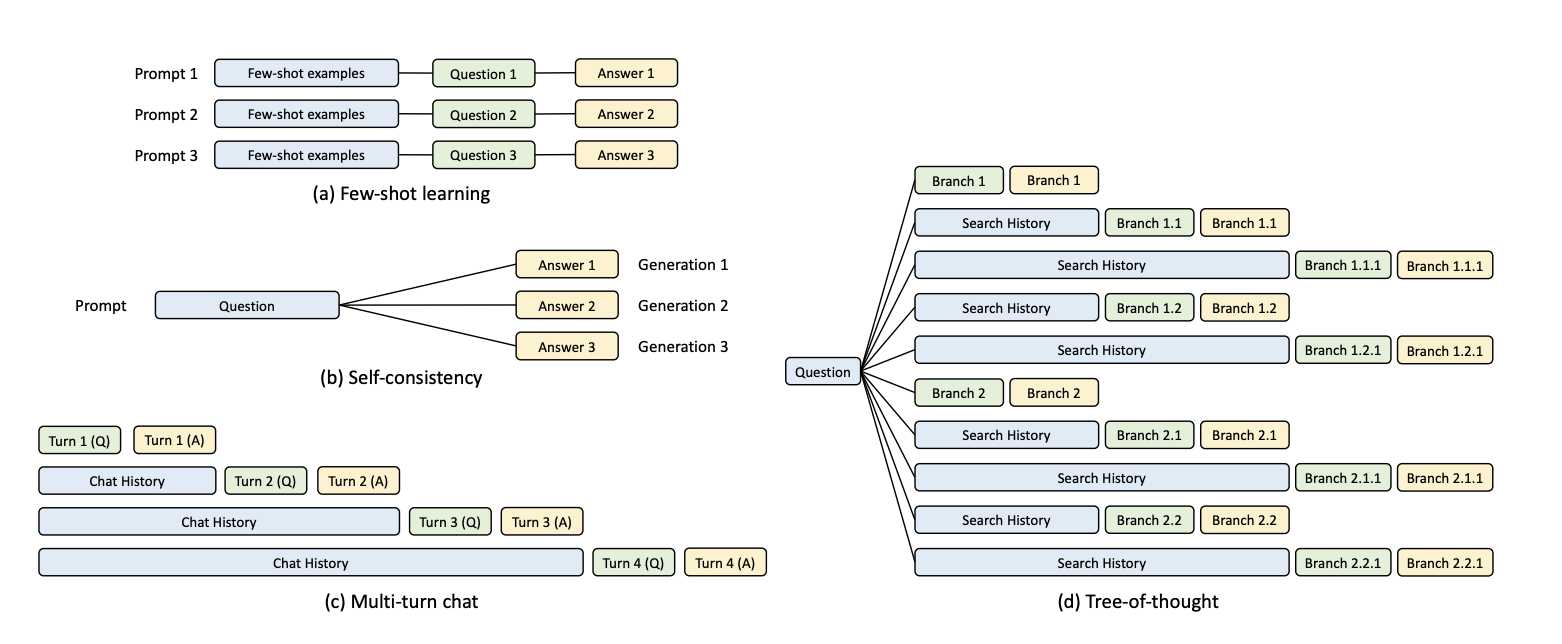
图1:四种典型的 KV 缓存共享对话模式。(a) 少样本学习中多个 Prompt 共享 Few-shot examples;(b) 自洽问答中同一 Question 对应多次独立生成;© 多轮对话中每轮共享之前的 Chat History;(d) 思考树中多条搜索路径共享 Search History。
如果各请求独立处理,这些重复前缀会被反复计算,直接拖慢推理速度。vLLM 实现了基础的共享前缀树方案,SGLang 则进一步提出用基数树同时覆盖上述四种模式的统一 KV 缓存共享方案。
二、语言模型程序:用程序化方式编排大模型调用
为了应对上面这些多样化的对话模式,SGLang 提出了"语言模型程序"的概念,即用程序化的方式去调度和管理大模型的生成过程。核心思路是把语言模型的调用逻辑与程序化控制流(条件判断、循环、函数封装等)结合,形成可编排、可交互、可扩展的执行单元。
语言模型程序有三个主要特点。第一是控制流驱动的多轮调用:一个语言模型程序通常包含多次大模型调用,整个过程在一个控制流中推进,而不是单次独立请求。第二是结构化的输入输出:程序接收结构化输入(如 JSON 模板、提示词拼接),也要求模型输出结构化结果(如 JSON、特定格式)。第三是缓存感知与状态持续性:多轮调用中反复出现相似甚至相同的输入前缀(任务描述、历史对话、示例模板),因此对 KV 缓存的复用需求比单次调用高得多。
这个概念的意义在于:一旦把对话流程看作"程序",就可以用数据结构的思维去优化其中重复出现的计算,而基数树就是承载这个优化的核心数据结构。
三、基数树(Radix Tree)基础与构建过程
基数树(Radix Tree)也叫压缩前缀树(Compact Prefix Tree),是前缀树(Trie)的空间优化版本,用于高效存储和检索具有公共前缀的键值对。
它和标准 Trie 的区别在于:每个节点可以存储多个字符而不仅限于单个字符,只有当节点需要分叉(存在多个子节点方向)时才创建新分支。这样压缩路径后,基数树比标准 Trie 更节省空间,尤其适合存储长键或大量相似前缀的数据。
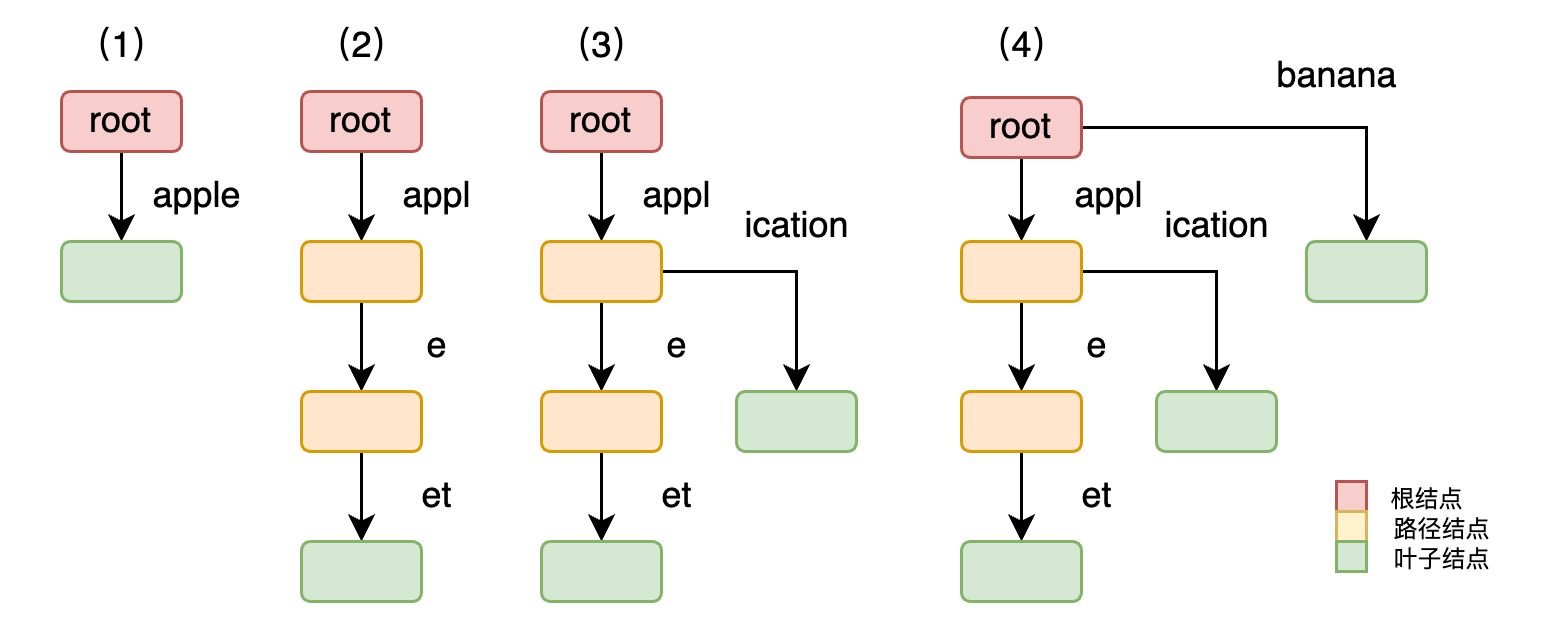
图2:基数树逐步构建过程。从阶段 (1) 插入 apple 到阶段 (4) 形成包含 apple、applet、application、banana 的完整基数树,粉色为根节点,橙色为路径节点,绿色为叶子节点。
用一个例子来看构建过程。假设依次插入 apple、applet、application、banana 四个键。插入 apple 时,根节点直接连接到一个存储 "apple" 的叶子节点。插入 applet 时,发现 "apple" 是 "applet" 的前缀,于是将 "apple" 节点拆分为 "appl" 和 "e" 两段,再把 "et" 作为 "e" 的子节点挂上去。插入 application 时,在 "appl" 节点后产生分叉:一个方向是 "e"(对应已有的 apple 系列),另一个方向是 "ication"(对应 application)。插入 banana 时,它与 apple 系列无公共前缀,因此在根节点创建一个全新分支。
搜索 application 时,从根节点出发匹配 "appl",进入子节点后在分叉处选择 "ication" 方向,到达叶子节点完成完整匹配,搜索成功。值得注意的是,搜索 apple 时虽然能匹配到对应节点,但该节点不一定是叶子节点,需要看它是否被标记为某个键的终止点。
基数树天然适合管理 KV 缓存:把 token 序列作为键,对应的 KV 缓存作为值,相同前缀的 token 序列共享同一条路径上的缓存。
四、用基数树管理 KV 缓存的完整流程
这一节通过九个时刻的演进,描述基数树在实际服务中如何动态管理 KV 缓存。
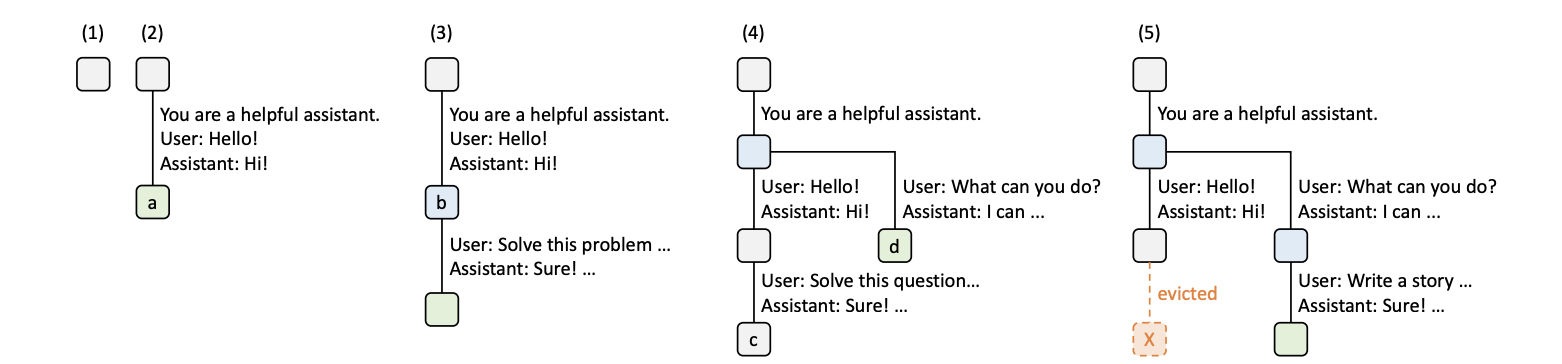
图3:基数树 KV 缓存管理的前五个时刻。(1) 初始空树;(2) 第一轮对话 R1 进入,系统提示词和用户输入构成路径;(3) R1 多轮追问,复用前轮缓存并追加新节点;(4) R2 开始,与 R1 共享系统提示词后分叉;(5) R2 多轮时按 LRU 清除 R1 最近一轮缓存。
时刻 1,系统初始化,基数树为空,只有一个根节点。
时刻 2,第一轮对话 R1 进入。系统提示词为 "You are a helpful assistant.",用户提问 "hello",助手回答 "Hi!"。此时基数树从根节点生长出一个节点 a,用户的输入 token 序列作为连接边,该边上存储了对应的 KV 缓存。
时刻 3,R1 的多轮追问 "Solve this problem",助手回答 "Sure"。基数树在节点 a 后追加新节点,新输入作为边。这一步的关键在于:前一轮对话的 KV 缓存被直接复用,只需计算新输入部分的 KV 值,减少了计算量。
时刻 4,第二轮对话 R2 开始。R2 和 R1 可以共享系统提示词的 KV 缓存,因此在共享前缀处分叉出一个新节点 d,R2 的用户输入作为新的边。此时基数树中出现了第一个分叉结构。
时刻 5,R2 进入多轮对话,需要腾出 KV 缓存空间。系统按 LRU(最近最少使用)规则,将 R1 最近一轮的 KV 缓存节点及其边清除,为新缓存腾出空间。
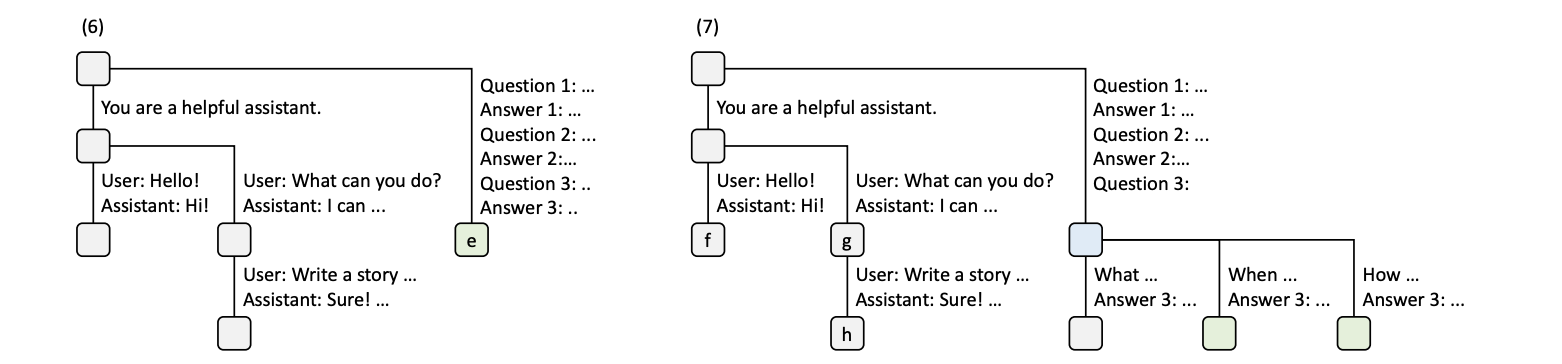
图4:基数树 KV 缓存管理的第六和第七个时刻。(6) 少样本学习请求 R3 到达,与已有对话无共享前缀,在根节点处生长新分支 e;(7) R3 框架下用户提出多个问题,从节点 e 分出三个分支。
时刻 6,少样本学习请求 R3 到达。R3 的系统提示词与 R1、R2 完全不同,无法共享任何前缀,因此在根节点处直接生长一个新分支 e。
时刻 7,在 R3 的少样本学习框架下,用户同时提出了多个问题。基数树从节点 e 处分出三个分支,每个问题对应一条边和一个新节点。
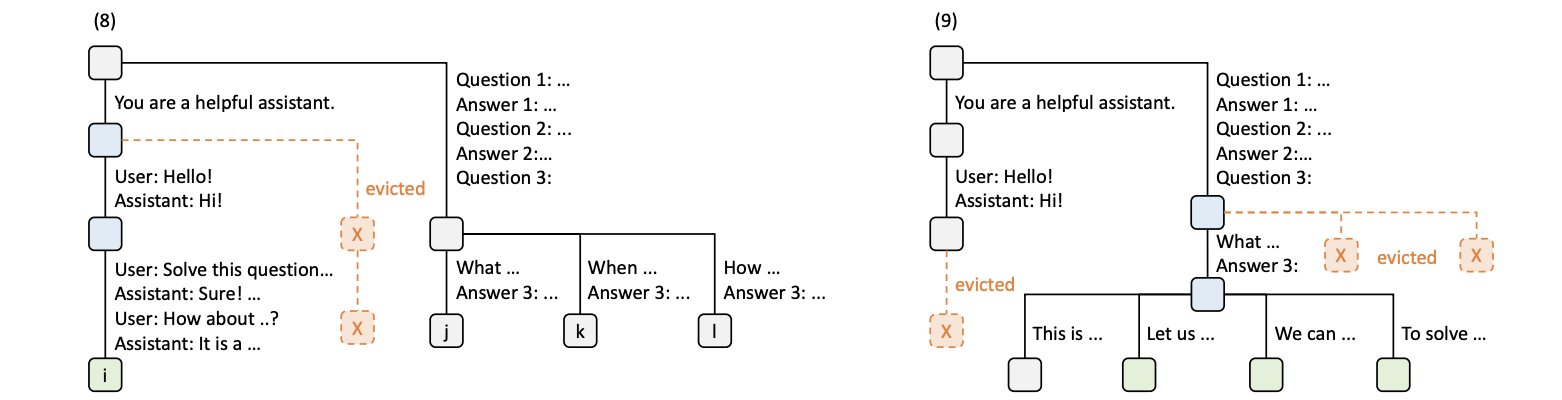
图5:基数树 KV 缓存管理的第八和第九个时刻。(8) R1 发起新提问,在已有缓存路径上追加节点 i,同时不活跃节点被 LRU 清除(标记 evicted);(9) R3 第一个问题进入多轮,其余分支缓存被清除。
时刻 8,R1 又发起了新提问。系统找到 R1 之前留存的缓存路径,在其上追加新节点 i,复用了之前的 KV 缓存并缓存新输入的 KV 值。同时 R2 下不活跃的节点被 LRU 清除。
时刻 9,R3 的第一个问题进入多轮问答,生成新节点;R3 其他问题分支的缓存以及 R1 最新节点 i 被按 LRU 清除。
整个演进过程体现了基数树管理 KV 缓存的三个核心原则:相同前缀共享路径、新输入追加节点和边、空间不足时按 LRU 淘汰最不活跃的分支。相比简单的列表或字典存储,基数树让共享前缀的查找和复用变成了 O(前缀长度) 的路径匹配操作。
五、缓存感知调度:最长匹配序列与持续批处理
有了基数树管理缓存,还需要决定"哪些请求优先进入当前 batch 执行"。如果调度器简单地按先来先服务(FCFS)排列请求,频繁的跨请求切换会导致缓存不断被替换,命中率很低。SGLang 用最长匹配序列排序来解决这个问题。
SGLang 的缓存感知调度策略用一个更聪明的方式决定优先级:对等待队列中的所有请求,通过基数树计算每个请求能匹配到的最长前缀长度;按长度降序排列,长度相同的请求再按缓存命中率降序排序;优先选择排序靠前的请求进入当前 batch。
这种策略的好处是:连续匹配的请求可以共享缓存块,减少 KV 缓存的频繁切换,降低显存带宽压力;连续的缓存块可以直接复用,避免重复计算。

图6:Algorithm 1 --- Cache-Aware Scheduling for RadixAttention with Continuous Batching。算法接收基数树 T、内存池 P、当前运行 batch B 和等待队列 Q 作为输入,通过按最长匹配序列排序决定请求优先级,再根据可用显存决定本 batch 执行的请求数量。
SGLang 还将基数树与持续批处理(Continuous Batching)相结合。持续批处理的核心是打破静态批处理"一次性打包"的限制:在模型推理的每轮迭代后,移除已完成生成的请求(释放缓存),加入新到达的请求(接收新任务),实现 batch 的动态调整。
基数树的引入让这种动态调整能基于实时缓存状态优化。具体流程是:在一个 batch 周期内,等待队列中的所有请求先按匹配序列长度排序;排序后再根据当前可用的显存空间,决定本 batch 实际执行的请求数量。这样最大程度保证了 KV 缓存的利用率和整体推理效率。
两者结合带来了两个关键优势。在实时性与复用率平衡方面,持续批处理保证新请求及时入队、完成请求及时出队,基数树的实时查询确保每次重组 batch 时优先选择能复用最多连续缓存的请求。在避免缓存碎片化方面,通过基数树的路径管理,KV 缓存始终以连续前缀块的形式被复用,减少了碎片化缓存导致的显存浪费。
六、总结与延伸
SGLang 的 KV 缓存复用体系可以用一句话概括:用基数树统一管理所有请求的 KV 缓存元信息,用最长匹配序列排序决定调度优先级,用持续批处理动态调整执行 batch,三者协同工作以最大化缓存复用率、降低显存读写开销。
从这个设计中可以提炼出一个可迁移的工程判断方法:当系统中存在大量重复前缀计算时(不限于 LLM 推理,也包括编译器的中间表示缓存、数据库的查询计划缓存等),用前缀树类数据结构组织缓存,再配合前缀感知的调度策略,往往能用最小的额外管理开销换取最大的计算复用。
如果对 SGLang 的另一个核心能力------用压缩有限状态机实现结构化输出加速------感兴趣,可以进一步查阅 SGLang 的官方论文和文档。