
核心结论
指令微调让模型从"会续写文本"变成"会按任务格式完成请求";对齐技术让模型进一步学会什么回答更有帮助、更安全、更诚实、更符合产品规范。2026 年再讲对齐,不能只讲 SFT + 奖励模型 + PPO 这条经典 RLHF 流程,还必须覆盖 DPO/IPO/KTO/ORPO/SimPO、RLAIF/Constitutional AI、RLVR/GRPO、红队评估、reward hacking 和上线监控。
更准确的一句话是:
text
预训练模型 -> SFT 学会遵循指令 -> 偏好/规则/验证奖励优化行为 -> 安全评估与线上监控对齐不是把模型"训乖"这么简单。它是一套产品行为工程:既要保留模型能力,又要约束不可靠、不安全、不合规的输出,还要让模型在真实用户场景中稳定工作。
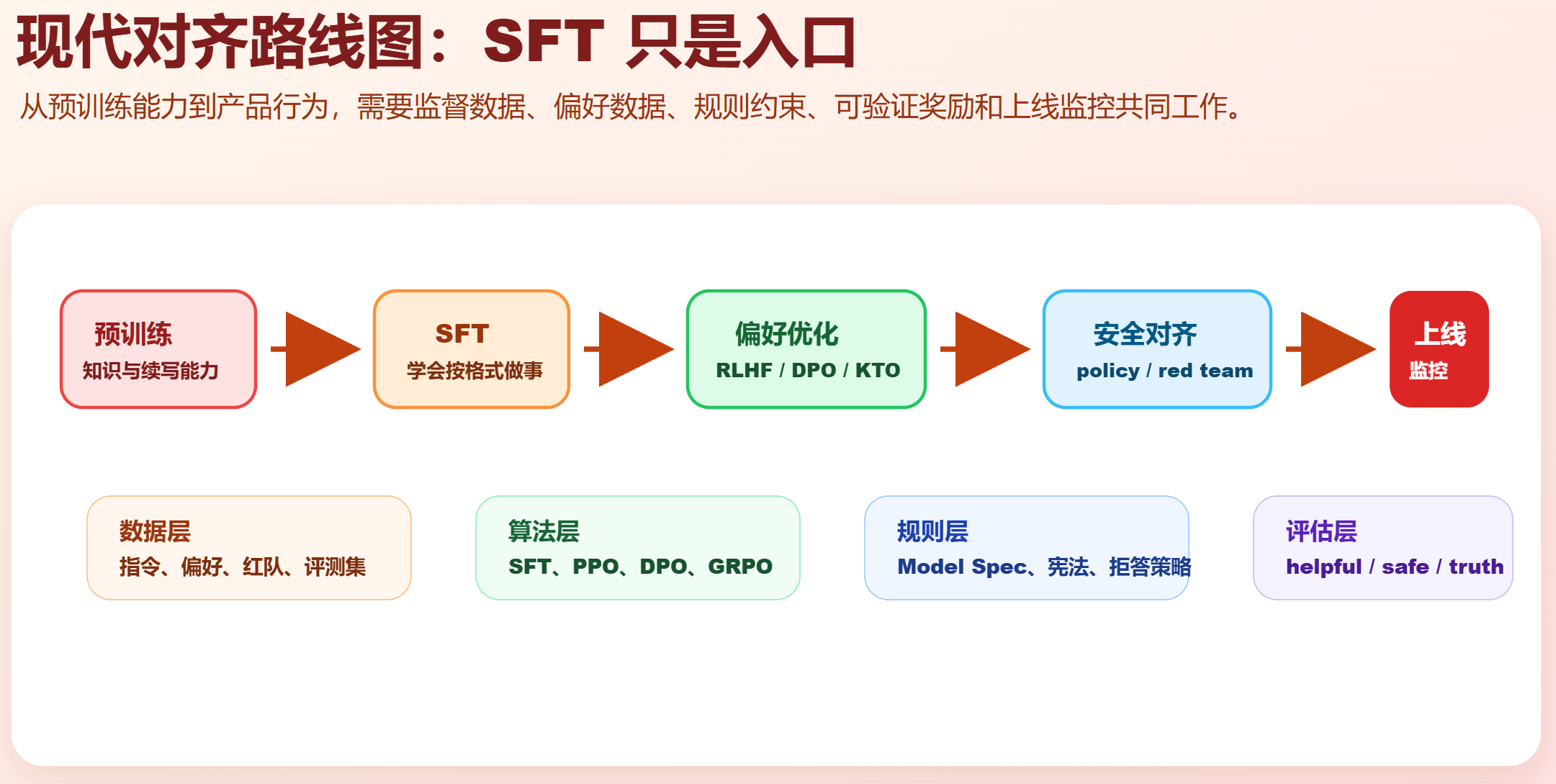
第 0 层:30 秒理解
把一个基座模型做成可用助手,通常经过几步:
- 预训练:模型学到语言、知识和续写能力。
- SFT:用高质量指令-回答数据,让模型学会对话格式、任务格式和基础指令遵循。
- 偏好优化:用人类或 AI 的偏好,让模型在多个候选回答中偏向更好的那个。
- 安全对齐:用规则、红队样本和安全分类器减少有害输出。
- 可验证奖励训练:在数学、代码、工具调用等任务中,用单元测试、答案校验器或规则奖励训练推理行为。
- 评估与监控:持续检查能力、安全、真实性、鲁棒性和用户体验。
一句话:
SFT 让模型"像助手一样回答",偏好优化让模型"更像好助手",安全与验证奖励让模型"在关键场景少犯错"。
第 1 层:基础概念
1.1 SFT:监督微调
SFT 的数据通常长这样:
json
{
"messages": [
{"role": "system", "content": "你是一个严谨的技术助手。"},
{"role": "user", "content": "解释 DPO 和 PPO 的区别。"},
{"role": "assistant", "content": "DPO 直接用偏好对优化策略,PPO 通常需要奖励模型和在线采样..."}
]
}训练时关键不是简单拼接文本,而是:
- 使用正确的 chat template。
- 只对 assistant 的目标 token 计算 loss。
- 保留 system/user/assistant/tool 的边界。
- 正确处理 EOS、padding、attention mask 和多轮对话。
SFT 的目标是最大化参考回答的似然:
text
L_SFT = - sum log p_theta(y_assistant | prompt)但要注意:SFT 学的是数据分布。如果 SFT 数据冗长,模型会变啰嗦;如果数据喜欢道歉,模型会过度道歉;如果数据拒答泛化过宽,模型会过度拒答。
1.2 RLHF:从人类偏好学习
经典 RLHF 通常包含三步:
- 用 SFT 得到初始助手模型。
- 让模型对同一 prompt 生成多个回答,人类标注 chosen/rejected,训练奖励模型。
- 用 PPO 等强化学习算法优化策略,同时用 KL 约束避免偏离 SFT 模型太远。
RLHF 的核心不是"强化学习"本身,而是把人类偏好转化成可优化信号。
1.3 DPO:不用显式奖励模型的偏好优化
DPO 使用偏好对直接优化模型,让 chosen 的相对概率高于 rejected。它绕开了单独训练奖励模型和在线 PPO rollout,工程上更简单,微调场景很常见。
直观理解:
text
同一个 prompt 下:
提高 chosen response 的概率
降低 rejected response 的概率
同时不要偏离参考模型太多1.4 RLAIF 与 Constitutional AI
RLAIF 使用 AI feedback 代替或补充人工反馈。Constitutional AI 则把一组原则、规范或"宪法"写成模型行为准则,让模型根据规则自我批评、自我修正,或让 AI judge 按规则给偏好。
它们不能完全替代人类监督,但能降低反馈成本,并提升风格、安全和规则一致性。
1.5 RLVR 与 GRPO
RLVR 是 Reinforcement Learning with Verifiable Rewards,核心是用可验证信号训练模型。数学题有答案校验,代码有单元测试,格式任务有 parser,工具调用有执行结果。
GRPO 是 Group Relative Policy Optimization,一类用组内相对奖励优化的策略,常出现在数学、代码、推理任务训练中。它的价值在于:当奖励可验证时,不一定需要人类偏好或奖励模型。
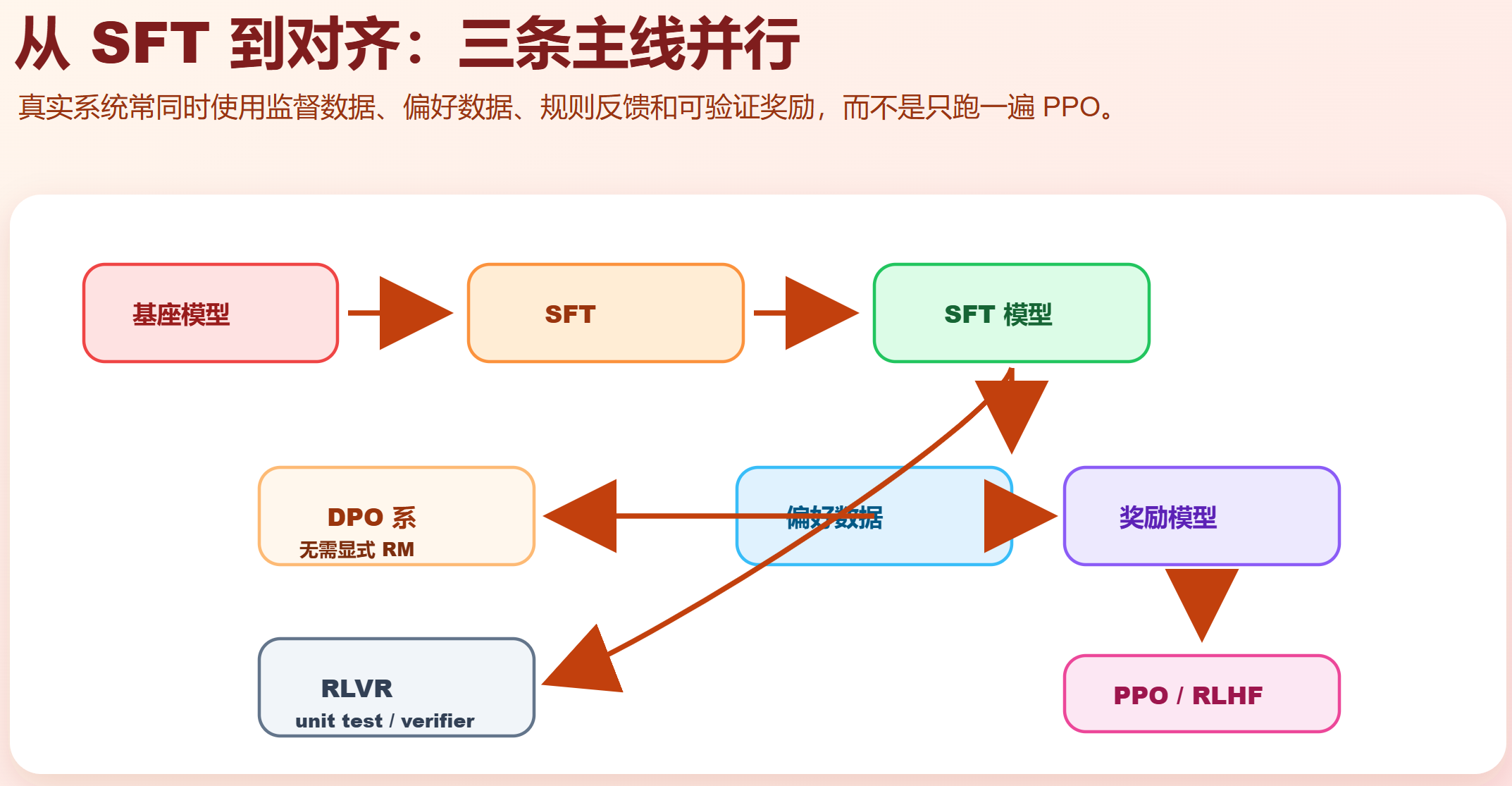
第 2 层:数据是对齐的上限
2.1 SFT 数据
高质量 SFT 数据应覆盖:
| 数据类型 | 作用 |
|---|---|
| 单轮指令 | 建立基础任务执行能力 |
| 多轮对话 | 学会上下文延续、澄清和记忆当前对话 |
| 工具调用 | 学会函数参数、JSON、错误恢复 |
| 拒答与安全 | 学会边界和替代性帮助 |
| 长文档任务 | 学会摘要、抽取、引用和结构化输出 |
| 代码/数学 | 学会严格格式和可验证解答 |
SFT 数据的关键指标:
- 指令多样性。
- 回答准确性。
- 风格一致性。
- 安全边界清晰度。
- assistant loss mask 正确率。
- 模板与推理格式一致性。
2.2 偏好数据
偏好数据通常是:
json
{
"prompt": "请解释 RLHF 的风险。",
"chosen": "RLHF 可能出现奖励黑客、过度优化奖励模型、能力回退...",
"rejected": "RLHF 很好,没有明显风险。"
}偏好标注时要避免:
- 长度偏见:长回答不一定更好。
- 讨好偏见:迎合用户不等于诚实。
- 风格偏见:华丽措辞不等于正确。
- 安全偏见失衡:安全不等于任何问题都拒答。
- 标注者不一致:不同标注者标准冲突。
2.3 红队与安全数据
安全对齐不能只靠普通偏好对。还需要:
- jailbreak prompt。
- prompt injection。
- 危险能力请求。
- 隐私泄露诱导。
- 自伤、违法、恶意代码等高风险场景。
- 过度拒答测试。
安全数据要包含"应该拒答"和"应该安全地帮助"两类样本。只训练拒答会导致模型遇到敏感词就退缩。
第 3 层:主要对齐算法

3.1 SFT 的正确训练骨架
下面只展示 loss mask 思路,不是完整训练脚本:
python
def build_sft_labels(input_ids, assistant_mask):
labels = input_ids.clone()
labels[~assistant_mask] = -100
return labels
def sft_step(model, batch, optimizer):
outputs = model(
input_ids=batch["input_ids"],
attention_mask=batch["attention_mask"],
labels=batch["labels"],
)
loss = outputs.loss
optimizer.zero_grad(set_to_none=True)
loss.backward()
optimizer.step()
return loss.item()真实项目中,assistant_mask 来自 chat template 或数据构造阶段,而不是靠字符串位置临时猜。
3.2 奖励模型
奖励模型通常学习 Bradley-Terry 形式的偏好:
text
P(chosen > rejected) = sigmoid(r(prompt, chosen) - r(prompt, rejected))损失:
text
L_RM = - log sigmoid(r_chosen - r_rejected)奖励模型的风险:
- 学到长度偏见。
- 对分布外 prompt 不可靠。
- 被策略模型钻空子。
- 分数不可当作绝对真理。
因此 PPO/RLHF 一定要监控 KL、奖励分布、回答长度、重复率、拒答率和真实评估指标。
3.3 PPO / RLHF
PPO 的优点是可表达复杂奖励,并能在线从当前模型采样。缺点是工程复杂、成本高、容易不稳定。
真实 PPO 训练至少涉及:
- rollout 生成。
- response token logprob。
- reference model logprob。
- reward model score。
- KL penalty。
- value head。
- advantage estimation。
- response mask。
- 多轮指标监控。
不建议用手写玩具 PPO 训练大语言模型。工程上应使用成熟框架,例如 TRL、OpenRLHF、verl 或内部 RLHF 系统。
3.4 DPO、IPO、KTO、ORPO、SimPO
这些方法都试图降低 RLHF 的复杂度。
| 方法 | 特点 | 适合场景 |
|---|---|---|
| DPO | 直接用 chosen/rejected 优化策略,不显式训练奖励模型 | 通用偏好微调 |
| IPO | 修正 DPO 在偏好过强时的过拟合倾向 | 偏好噪声较大时 |
| KTO | 可使用单条好/坏反馈,不要求严格成对 | 反馈不是 pairwise 时 |
| ORPO | 把 SFT 和偏好项合并,流程更轻 | 快速对齐微调 |
| SimPO | 参考模型依赖更少,形式简化 | 资源有限或快速实验 |
DPO 类方法更稳定、更便宜,但也不是万能。它们依赖偏好数据质量,且通常不如在线 RL 那样灵活探索。
3.5 GRPO / RLVR
对数学、代码、工具调用来说,最强的反馈未必来自人类,而是 verifier:
- 数学答案是否正确。
- 代码是否通过单元测试。
- JSON 是否能解析。
- SQL 是否执行正确。
- 工具调用参数是否有效。
RLVR 的关键是奖励可验证,GRPO 等方法则用组内多个候选答案的相对表现来更新模型。它们特别适合推理训练,但也容易过拟合 verifier,因此要保留分布外测试。
第 4 层:安全与规则对齐
4.1 Model Spec / 行为规范
现代对齐需要明确行为规范,例如:
- 遵循合法且安全的用户请求。
- 对危险请求拒答,并给出安全替代建议。
- 不编造不确定事实。
- 区分 system、developer、user 指令优先级。
- 遇到冲突指令时遵循更高优先级。
- 对隐私、版权、医疗、法律等高风险领域更谨慎。
这些规范应进入:
- SFT 数据。
- 偏好标注准则。
- AI judge prompt。
- 红队评估。
- 线上策略和审计。
4.2 安全不是简单拒答
好的安全回答有三种能力:
- 识别高风险意图。
- 拒绝不可帮助的部分。
- 提供安全替代方案。
例如用户问危险化学操作,模型不应提供步骤,但可以解释风险、建议联系专业机构、提供安全合规的背景知识。
4.3 RLAIF 与 Constitutional AI 的位置
RLAIF 适合:
- 扩大偏好标注规模。
- 用规则检查回答是否合规。
- 做自我批评和自我修订。
- 生成红队数据。
但 AI feedback 会继承 judge 模型偏差,必须用人工抽检和真实评估校准。
第 5 层:评估体系
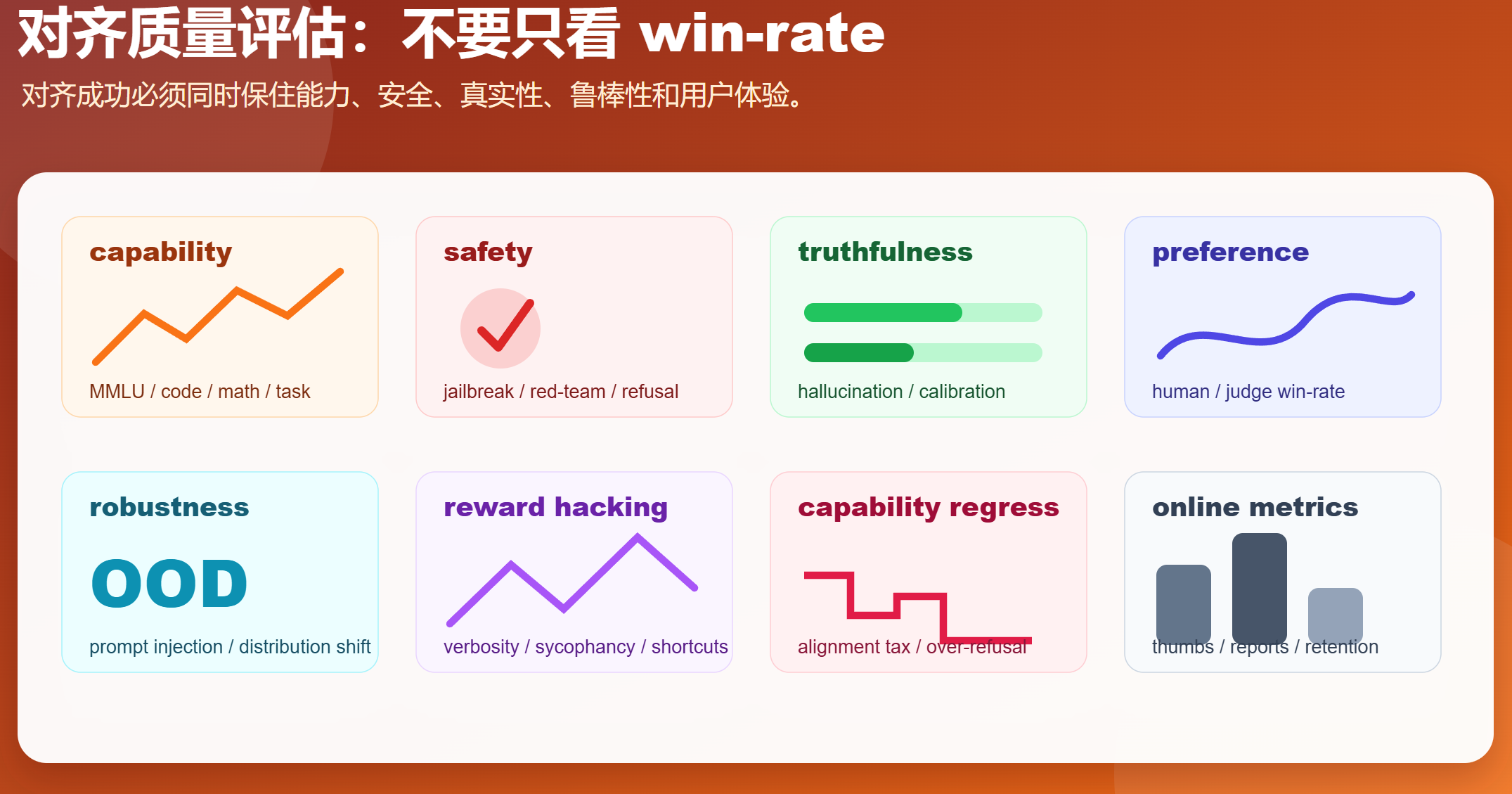
只看 win-rate 是不够的。对齐模型至少要评估八类指标:
| 维度 | 例子 |
|---|---|
| 能力 | MMLU、GSM、HumanEval、领域任务、工具调用成功率 |
| 指令遵循 | 格式遵循、多约束任务、拒绝无关输出 |
| 偏好 | 人类 win-rate、AI judge win-rate、pairwise eval |
| 真实性 | 幻觉率、引用准确率、校准能力 |
| 安全 | jailbreak、红队、隐私、有害内容、恶意代码 |
| 过度拒答 | benign prompt refusal rate |
| 鲁棒性 | prompt injection、分布外、多语言、长上下文 |
| 线上指标 | 用户反馈、投诉率、留存、人工升级率 |
还要特别监控:
- reward hacking:模型学会讨好奖励模型,而不是真正变好。
- sycophancy:用户说错时模型迎合。
- verbosity bias:回答变长但信息密度下降。
- mode collapse:回答风格单一。
- capability regression:对齐后数学、代码或领域能力下降。
- over-refusal:安全策略过宽,正常请求也拒绝。
第 6 层:工程落地流程
6.1 低资源路线
适合团队刚开始做对齐:
text
选择强基座模型
-> 清洗高质量 SFT 数据
-> 正确构造 chat template 与 loss mask
-> LoRA/QLoRA SFT
-> 小规模 DPO 或 ORPO
-> 能力 + 安全 + 过拒评估低资源场景下,不建议一开始就做完整 PPO。
6.2 中资源路线
text
SFT
-> 收集 chosen/rejected 偏好数据
-> DPO/IPO/KTO 多组实验
-> 安全数据补强
-> AI judge + 人工抽检
-> 红队评估重点是数据质量和评估闭环,而不是算法堆叠。
6.3 高资源路线
text
SFT
-> RM 训练
-> PPO / GRPO / RLVR
-> RLAIF 扩展反馈
-> 多轮 red-team
-> 线上灰度和监控高资源路线的难点是系统工程:rollout 吞吐、奖励模型稳定性、KL 控制、分布漂移、评估污染、线上反馈闭环。
第 7 层:常见问题诊断
| 现象 | 可能原因 | 处理方式 |
|---|---|---|
| SFT loss 下降但回答格式混乱 | chat template 或 labels mask 错 | 检查 role token、EOS、assistant mask |
| 模型变得很啰嗦 | SFT/RM 有长度偏见 | 加入简洁偏好,监控长度分布 |
| DPO 后能力下降 | beta 不合适、偏好数据窄、过拟合 | 降低训练步数,混合 SFT,扩大评估 |
| PPO reward 升高但人工评价下降 | reward hacking | 降低奖励模型权重,加入人工评估和红队 |
| 安全性提升但正常请求被拒 | 安全数据过宽或拒答奖励过高 | 加入 benign 请求和安全替代回答 |
| 数学/代码提升只在训练题有效 | verifier 过拟合 | 增加 OOD 测试和隐藏测试 |
| 多语言安全不一致 | 偏好/安全数据语言覆盖不足 | 分语言评估,补多语言红队数据 |
| 模型迎合用户错误观点 | sycophancy 偏好 | 加入纠错数据和真实性评估 |
实用建议
- 不要用固定百分比承诺对齐收益,用评估结果说话。
- 不要把 RLHF 等同于 PPO;DPO 系和 RLVR 已是现代工具箱的一部分。
- 不要只优化人类偏好 win-rate,要同时看能力、安全、真实性和过度拒答。
- 不要让 AI judge 自说自话,关键评估要有人类抽检和对抗集。
- 不要把安全训练成"全部拒绝",要训练安全替代帮助。
- 不要手写玩具 PPO 上生产,使用成熟 RLHF/偏好优化框架。
- 不要忽略数据协议:chat template、loss mask、EOS、tool schema 错了,算法再好也会偏。
总结
指令微调和对齐的本质,是把一个会预测下一个 token 的模型,塑造成一个能遵循意图、尊重边界、解决问题、知道何时拒绝、能在真实环境中稳定工作的助手。
现代对齐不再是单一的 SFT + RM + PPO,而是一套组合技术:
- SFT 建立基础助手行为。
- RLHF/PPO 优化复杂偏好。
- DPO/IPO/KTO/ORPO/SimPO 降低偏好优化成本。
- RLAIF/Constitutional AI 用规则和 AI feedback 扩展对齐数据。
- RLVR/GRPO 用可验证奖励提升数学、代码和推理能力。
- 红队、安全评估和线上监控保证模型不会只在离线榜单上好看。
如果只记一句话:
SFT 解决"会不会按指令回答",偏好优化解决"哪个回答更好",安全与验证奖励解决"能不能可靠地做对的事"。
参考资料
- Ouyang et al., Training language models to follow instructions with human feedback:https://arxiv.org/abs/2203.02155
- Bai et al., Constitutional AI: Harmlessness from AI Feedback:https://arxiv.org/abs/2212.08073
- Rafailov et al., Direct Preference Optimization:https://arxiv.org/abs/2305.18290
- Azar et al., A General Theoretical Paradigm to Understand Learning from Human Preferences:https://arxiv.org/abs/2310.12036
- Ethayarajh et al., KTO: Model Alignment as Prospect Theoretic Optimization:https://arxiv.org/abs/2402.01306
- Hong et al., ORPO: Monolithic Preference Optimization without Reference Model:https://arxiv.org/abs/2403.07691
- Meng et al., SimPO: Simple Preference Optimization with a Reference-Free Reward:https://arxiv.org/abs/2405.14734
- Shao et al., DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models:https://arxiv.org/abs/2402.03300
- DeepSeek-AI, DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning:https://arxiv.org/abs/2501.12948
- Hugging Face TRL 文档:https://huggingface.co/docs/trl/index
- OpenAI Model Spec:https://model-spec.openai.com/