目录
[1 · 排序基础概念](#1 · 排序基础概念)
[1 - 1 · 排序的重要性](#1 - 1 · 排序的重要性)
[1 - 2 · 排序算法评估](#1 - 2 · 排序算法评估)
[2 · 插入排序](#2 · 插入排序)
[2 - 1 · 演示](#2 - 1 · 演示)
[2 - 2 · 思路构筑](#2 - 2 · 思路构筑)
[2 - 3 · 代码实现(C)](#2 - 3 · 代码实现(C))
[2 - 4 · 时间复杂度证明](#2 - 4 · 时间复杂度证明)
[3 · 希尔排序](#3 · 希尔排序)
[3 - 1 · Donald Shell的改进思路](#3 - 1 · Donald Shell的改进思路)
[3 - 2 · 代码实现(C)](#3 - 2 · 代码实现(C))
[3 - 3 · 希尔排序时间复杂度计算](#3 - 3 · 希尔排序时间复杂度计算)
[3 - 3 - 1 · 外层循环时间复杂度](#3 - 3 - 1 · 外层循环时间复杂度)
[3 - 3 - 2 · 内层循环时间复杂度](#3 - 3 - 2 · 内层循环时间复杂度)
[3 - 4 · 希尔排序效率提升原理](#3 - 4 · 希尔排序效率提升原理)
[4 · 实验性能对比](#4 · 实验性能对比)
[5 · 总结](#5 · 总结)
插入排序的核心思想是通过构建有序序列,对于未排序元素,在已排序序列中从后向前扫描并找到合适位置插入,适用于小规模或部分有序数据集的排序;希尔排序作为其高效优化版本,通过分组插入和递减间隔策略显著提升性能。本文将全面覆盖希尔排序的数学推导、时间复杂度分析及代码实现部分,深入解析其高效性。
1 · 排序基础概念
1 - 1 · 排序的重要性
所谓排序,就是使⼀串记录,按照其中的某个或某些关键字的大小,递增或递减的排列起来的操作。
高效排序不仅能显著提升计算效率,还能简化后续操作,从而优化整个系统性能。比如:
在一个已排序的数据集中,搜索特定元素的速度远高于无序数据;许多算法如数据合并、聚合和切片依赖于数据的有序状态。
当然,排序的实际应用也很广泛:例如电子商务中的商品排序、金融数据分析时间序列序列化等。高效排序能提供更好的用户体验和决策支持,降低处理延迟一个数量级。
1 - 2 · 排序算法评估
评估排序算法主要考虑时间复杂度、空间复杂度、稳定性三个指标。
这里简单介绍一下稳定性:稳定性指的是在排序后,相等元素之间的顺序关系不变,例如:排序前: ai1 和 aj1 相等,且 i1 > j1 ,排序后,ai1 和 aj1 位置发生变化,分别移动到了 ai2和 aj2,而此时仍保持 i2 > j2 ,则是稳定排序。
2 · 插入排序
2 - 1 · 演示
插入排序其实有点类似于扑克牌,抽一张牌,然后将其插入自己的手牌,并保持有序。
2 - 2 · 思路构筑
把待排序的记录按其关键码值的大小逐个插入到⼀个已经排好序的有序序列中,直到所有的记录插入完为止,得到⼀个新的有序序列 。
简单来说,将待排序的记录分为已排序区和未排序区,每次从已排序区的后一个元素开始向前比较,找到自己将要插入的位置,而原来位置上的元素依次后移。
2 - 3 · 代码实现(C)
下面按照排升序,实现插入排序:
void InsertSort(int* a, int n)
{
//前 [0,k]个视为有序,将k+1位置的值插入到前面
//最后一次是 下标[0,n-2]有序,将下标 n-1进行插入
for (int i = 0; i < n - 1; i++)
{
int end = i;
int tmp = a[end + 1];
//找插入位置
while (end >= 0)
{
if (a[end] > tmp)
{
a[end + 1] = a[end];
--end;
}
else
{
break;
}
}
a[end + 1] = tmp;
}
}2 - 4 · 时间复杂度证明
最好情况是原待排序记录已有序,此时只需走一趟最外层循环,时间复杂度是 。
最坏情况是原待排序记录逆序,此时内层循环每走一趟,下一趟需要多移动一次,构成等差序列,计算公式如下:
根据等差数列公式,可化为:
因此在最坏情况下,插入排序的时间复杂度是
3 · 希尔排序
3 - 1 · Donald Shell的改进思路
希尔排序是在直接插入排序算法的基础上进行改进而来的。
希尔排序法又称缩小增量法。希尔排序法的基本思想是:先选定⼀个整数(通常是),把待排序文件所有记录分成各组,所有的距离相等的记录分在同⼀组内,并对每⼀组内的记录进行排序,然后
得到下⼀个整数,再将数组分成各组,进行插入排序,当gap=1时,就相当于直接插入排序。
3 - 2 · 代码实现(C)
下面按照升序排序,实现希尔排序:
void ShellSort(int* a, int n)
{
//分gap组
// gap > 1 时 是预排序
//当gap == 1 ,即为插入排序
int gap = n;
while (gap > 1)
{
// +1 保证gap最后能取到1
gap = gap / 3 + 1;
for (int i = 0; i < n - gap; i++)
{
int end = i;
int tmp = a[end + gap];
//确定插入位置
while (end >= 0)
{
if (a[end] > tmp)
{
a[end + gap] = a[end];
end = end - gap;
}
else
{
break;
}
}
a[end + gap] = tmp;
}
}
}3 - 3 · 希尔排序时间复杂度计算
3 - 3 - 1 · 外层循环时间复杂度
外层循环的时间复杂度与 gap 的取值有关,按照我们上面的 ,那么外层循环的时间复杂度为:
3 - 3 - 2 · 内层循环时间复杂度
按照最坏情况来计算。假设 总待排序数据有 n 个。因此,在每个 gap 组中,数据总数为 ,那么每组中的最坏情况为:
, 一共有 gap 组,因此最坏情况下的移动总数为:
下面我们带入 gap 的取值来找寻规律(以):
首次gap 取到 ,代入公式可以得到:
,
第二次gap 取到 , 代入公式可得:
......
最后一次gap 取到 1 ,由于前面的预排序,此时记录已接近有序,当gap取到1时,此时相当于插入排序,而且是一个接近最好情况的插入排序,消耗为
那么整体的函数我们可以得到下面这样的图:
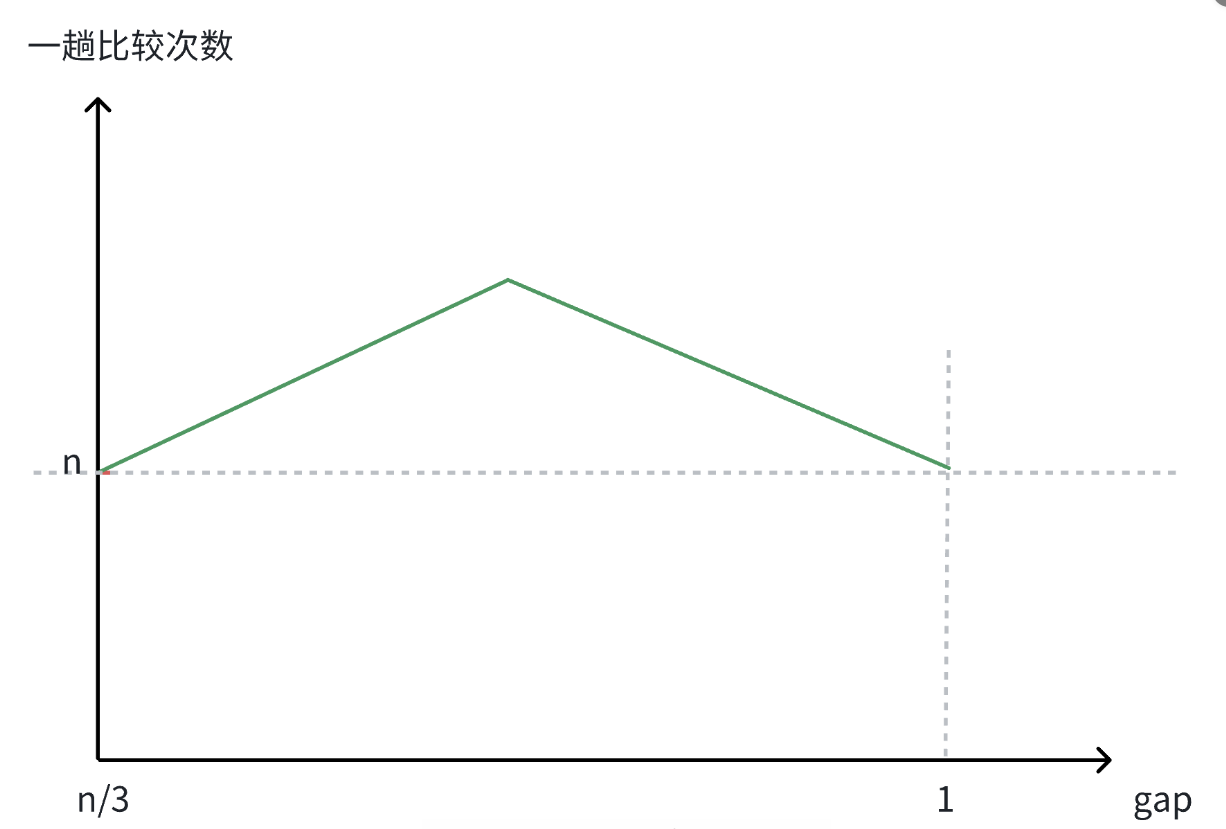
可以看出,整体呈先增后降的趋势,且首尾为。
希尔排序的时间复杂度很不好计算,因为gap的取值很多,很多书中给出的希尔排序的时间复杂度也都不固定,我们可以直接记希尔排序的时间复杂度为
3 - 4 · 希尔排序效率提升原理
插入排序在逆序时效率低是因为元素需多次移动。希尔排序通过分治策略(大间隔优先处理大范围乱序)显著减少无效位移:
- 初期大间隔使元素快速接近目标位置
- 后期小间隔( gap=1 )时数据已基本有序,插入排序高效完成收尾
4 · 实验性能对比
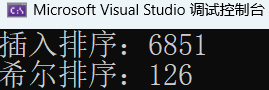
随机生成 100000 个数据,分别使用插入排序和希尔排序进行排序,看看耗时:
void TestOP()
{
srand((unsigned)time(NULL));
int N = 100000;
int* a1 = (int*)malloc(sizeof(int) * N);
int* a2 = (int*)malloc(sizeof(int) * N);
for (int i = 0; i < N; i++)
{
a1[i] = rand() + i;
a2[i] = a1[i];
}
int begin1 = clock();
InsertSort(a1, N);
int end1 = clock();
int begin2 = clock();
ShellSort(a2, N);
int end2 = clock();
printf("插入排序:%d\n", end1 - begin1);
printf("希尔排序:%d\n", end2 - begin2);
}运行一下:

单位是毫秒。我们把数据量增加到 1000000 再试试:
上面两次测试均是在Debug下测试的。
5 · 总结
插入排序是希尔排序的基础算法,通过逐个将元素插入到已排序部分的正确位置来完成排序,最适合小规模或基本有序的数据。
希尔排序本质是对插入排序的改进。通过将数据按特定间隔(称为增量序列)分组,并对每组进行插入排序,逐步缩小间隔直至为 1。
希尔排序是插入排序在分治思想下的优化:通过动态分组增量,减少小范围无效比较,平衡了排序过程中的局部性与全局性。两者体现了从基础算法到高级改进的典型演进逻辑。
以上内容如有错误或不准确之处,欢迎指出,或者你有更好的想法,也欢迎交流。