类实例执行过程:
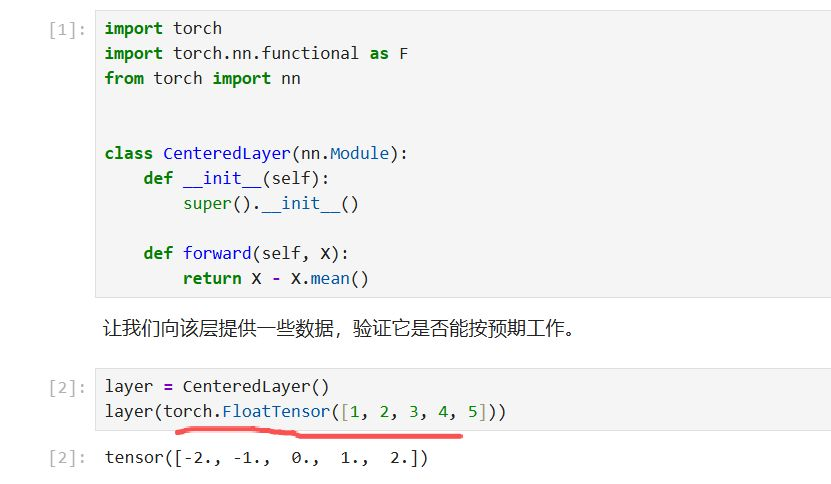

init函数只是针对构建类实例时候是否需要传参数
forward函数原理:
forward函数不是直接自动执行的。 它是一个被调用的函数,而不是自动执行的脚本。
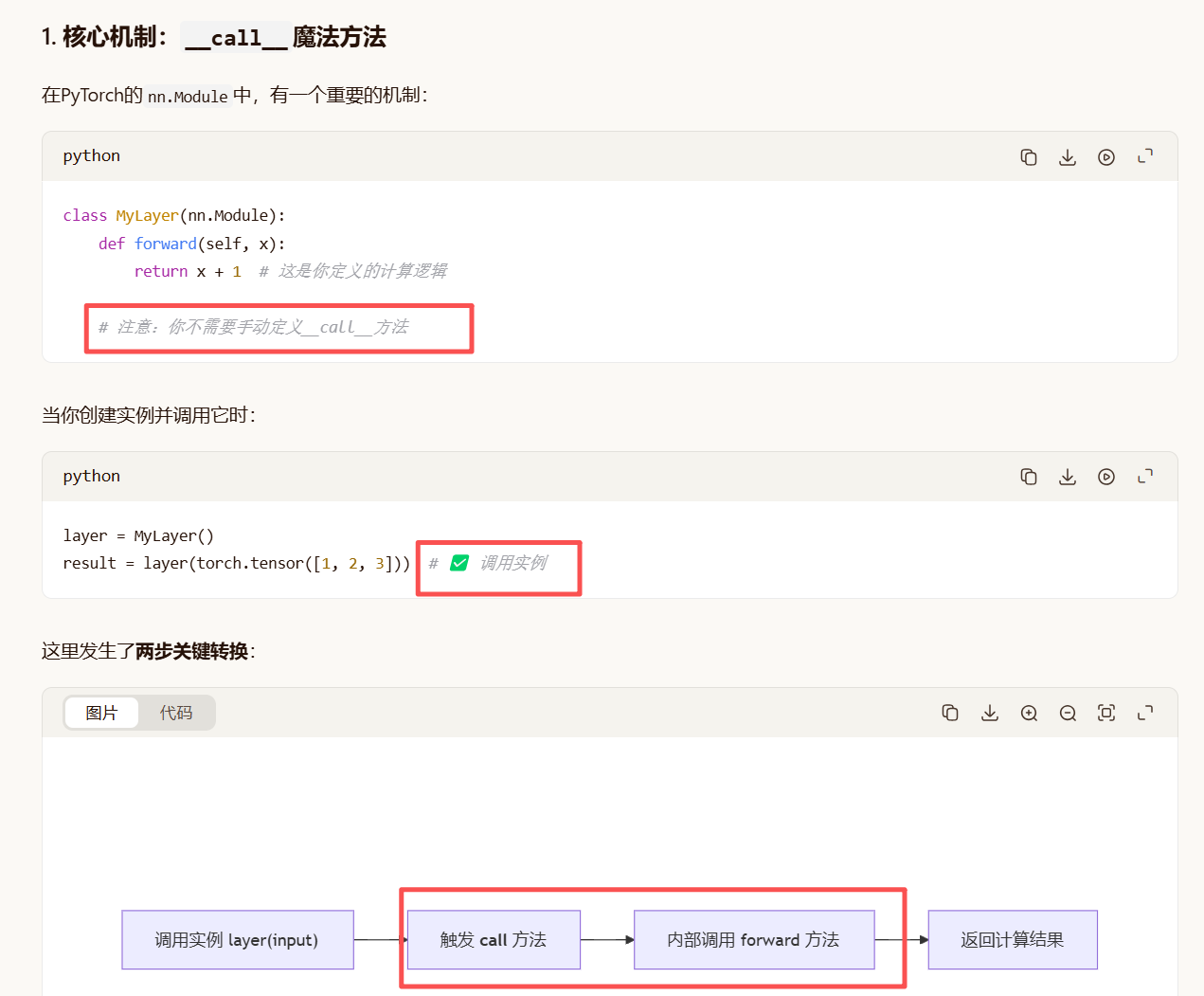
关键点:
-
你没有直接调用
forward方法 -
你调用的是实例本身(
layer()) -
PyTorch在父类
nn.Module中定义了__call__方法 -
这个
__call__方法内部会调用你的forward方法
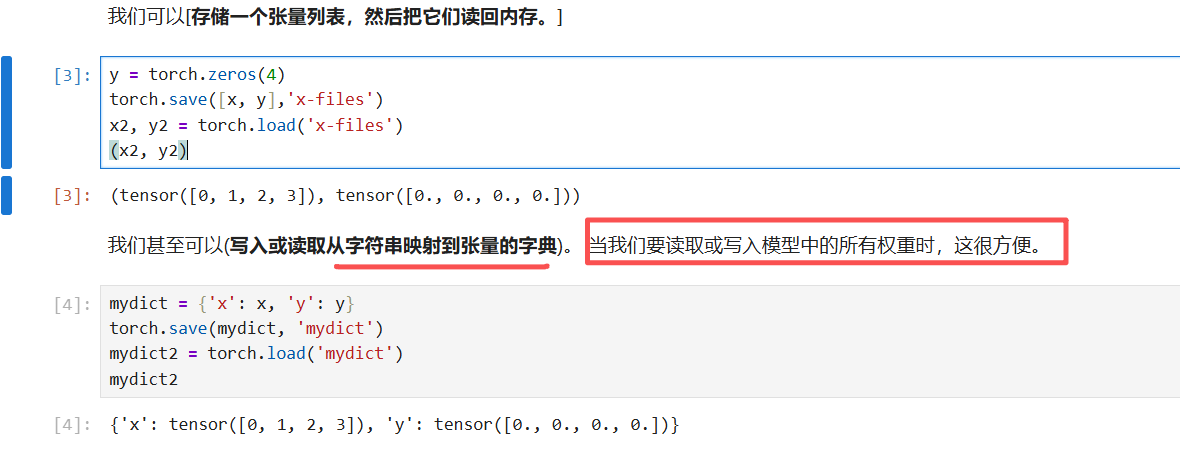
读写文件(重点):
加载和保存张量:
python
import torch
from torch import nn
from torch.nn import functional as F
x = torch.arange(4)
torch.save(x, 'x-file')
x2 = torch.load('x-file')存在当前目录:
结果

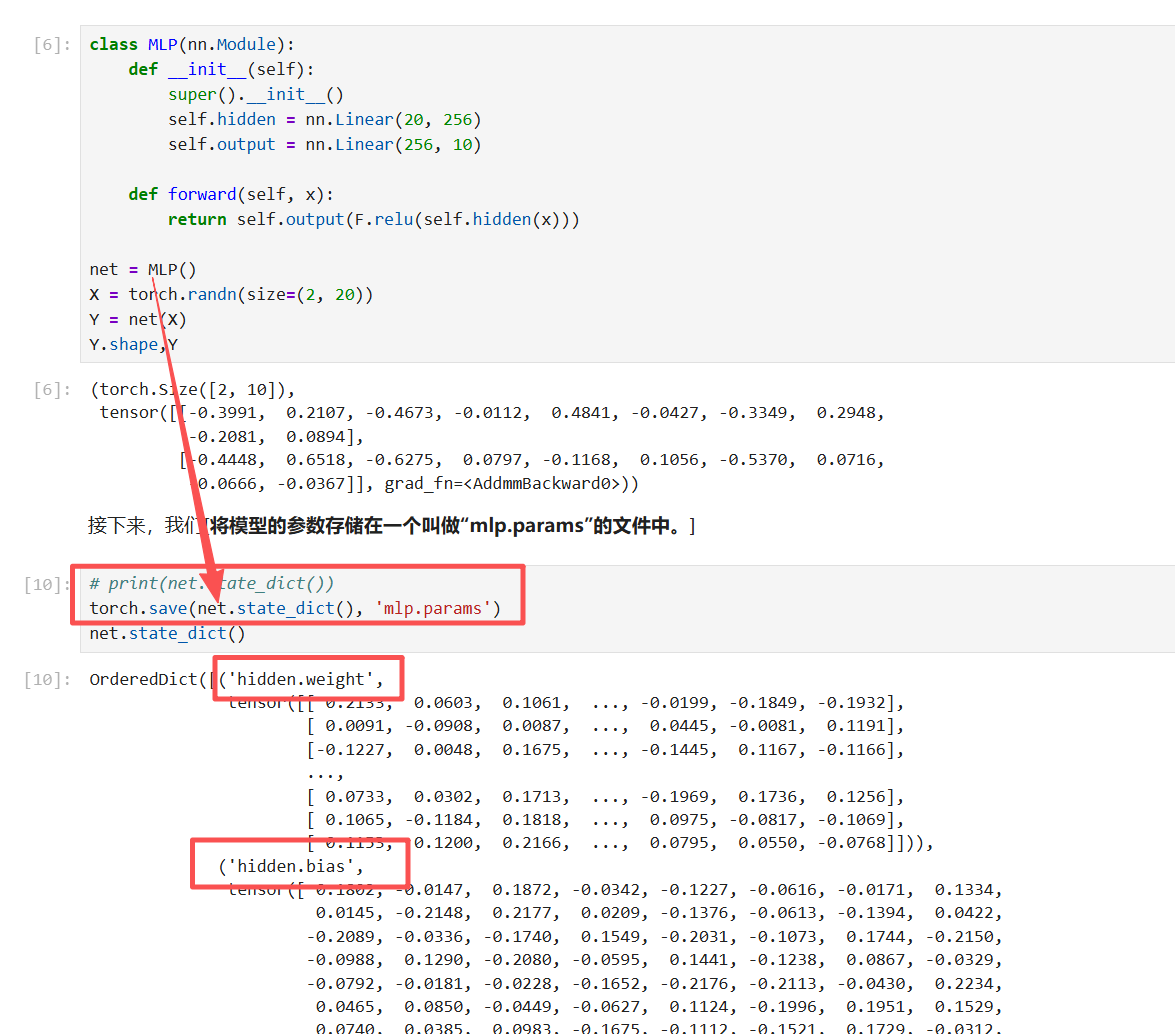
保存模型参数:(常用)
恢复模型(常用)
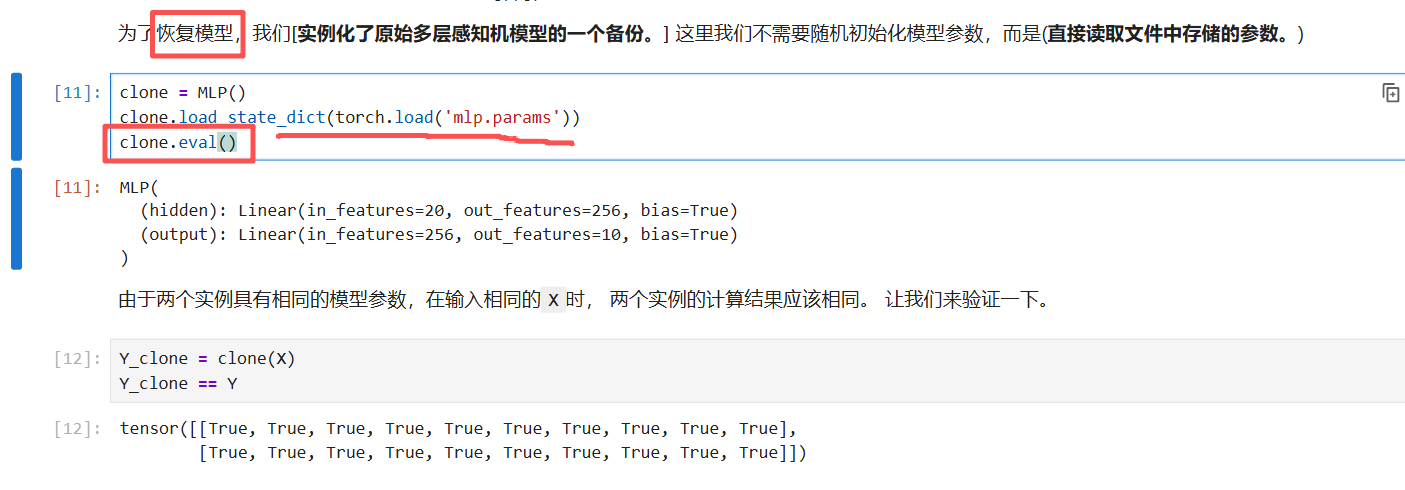
clone = MLP() # 第1步:创建空白模型
clone.load_state_dict(torch.load('mlp.params')) # 第2步:加载训练好的参数 现在clone拥有了和训练时完全一样的权重,但模式还是训练模式
clone.eval() # 第3步:切换到评估模式
评估模式和训练模式区别:


eval模式下结果不会变的
| 特性 | train 模式 (.train()) |
eval 模式 (.eval()) |
|---|---|---|
| 用途 | 训练模型 | 测试/推理/验证模型 |
| 随机性 | 有(Dropout 随机丢弃) | 无(确定性输出) |
| 统计量 | 实时计算并更新 | 使用训练时累积的固定值 |
| 结果一致性 | 同一输入可能输出不同 | 同一输入总是输出相同 |
| 内存占用 | 较大(需存储梯度) | 较小(可配合 torch.no_grad()) |
如果你的模型包含Dropout、BatchNorm等特殊层 ,不要eval()会导致推理结果不一致、不准确
BatchNorm是另一个需要eval()的重要原因:
python
import torch
import torch.nn as nn
import numpy as np
# 创建一个只有BatchNorm的网络
class BNOnlyNet(nn.Module):
def __init__(self):
super().__init__()
self.bn = nn.BatchNorm2d(1) # 只有BatchNorm,没有Dropout
def forward(self, x):
return self.bn(x)
# 创建两个相同的网络
net1 = BNOnlyNet()
net2 = BNOnlyNet()
# 让它们有相同的初始参数
net2.load_state_dict(net1.state_dict())
# 固定输入
x = torch.randn(2, 1, 3, 3) # 批次大小=2,通道=1,3x3
print("输入数据形状:", x.shape)
print("输入数据:\n", x)
print()
# 1. 不调用eval() - 训练模式
print("=== 训练模式(不调用eval)===")
print("但BatchNorm没有随机性,所以每次结果相同")
net1.train() # 训练模式
for i in range(3):
with torch.no_grad():
output = net1(x)
print(f"第{i+1}次输出的前2个值: {output[0, 0, 0, 0]:.4f}, {output[0, 0, 0, 1]:.4f}")
print()
# 2. 调用eval() - 评估模式
print("=== 评估模式(调用eval)===")
net2.eval() # 评估模式
for i in range(3):
with torch.no_grad():
output = net2(x)
print(f"第{i+1}次输出的前2个值: {output[0, 0, 0, 0]:.4f}, {output[0, 0, 0, 1]:.4f}")
因为用了不同的统计量,所以归一化的结果不同,最终输出也就不同了!


-
BatchNorm在训练模式下结果也是稳定的 - 相同输入得到相同输出
-
但训练模式和评估模式的结果不同 - 因为用了不同的统计量
这就是统计量不同的地方:
-
训练模式统计量 :每次前向传播时,计算当前批次的均值和方差
-
评估模式统计量 :使用训练过程中累积的running_mean 和running_var
-
训练时:
(x - batch_mean) / √(batch_var + ε) -
评估时:
(x - running_mean) / √(running_var + ε)

小结:
训练要随机,预测要稳定;
训练用 train,预测用 eval。
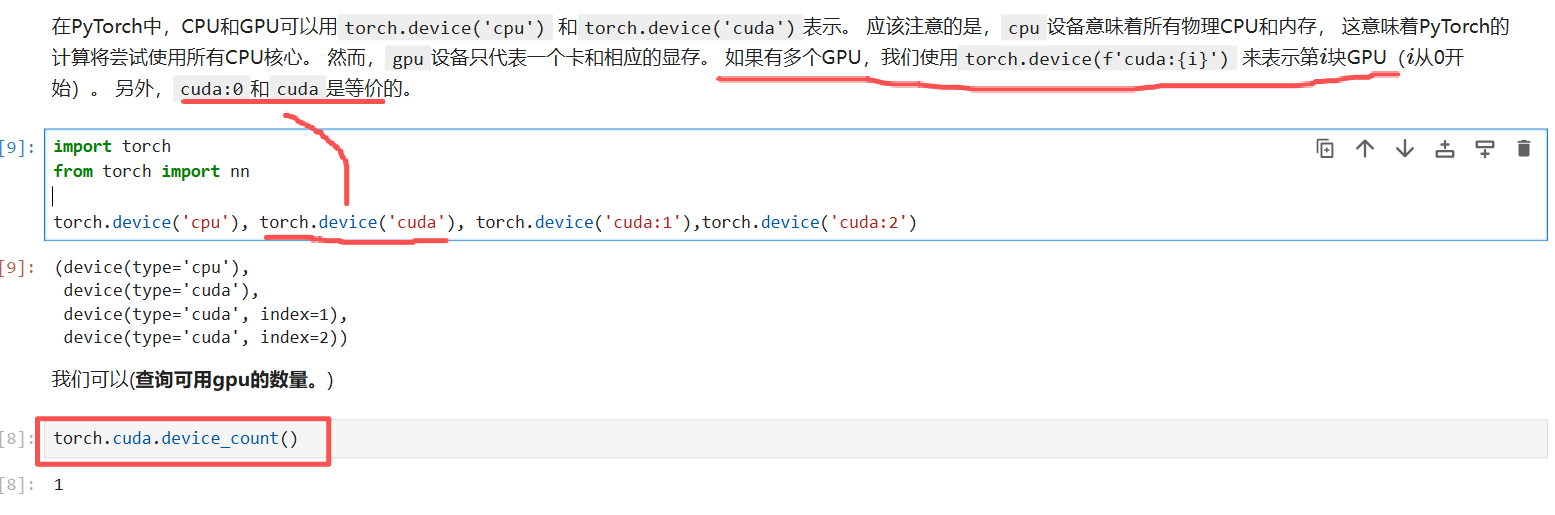
使用gpu:(重点)
查看cpu/可用的gpu数目:

查看张量所在设备:

需要注意的是,无论何时我们要对多个项进行操作, 它们都必须在同一个设备上。 例如,如果我们对两个张量求和, 我们需要确保两个张量都位于同一个设备上, 否则框架将不知道在哪里存储结果,甚至不知道在哪里执行计算
def try_gpu(i=0): #@save
"""如果存在,则返回gpu(i),否则返回cpu()"""
if torch.cuda.device_count() >= i + 1:
return torch.device(f'cuda:{i}')
return torch.device('cpu')
Y = torch.rand(2, 3, device=try_gpu(1))
存在第二个gpu上
演示不同设备的张量如何运算:需要复制一份
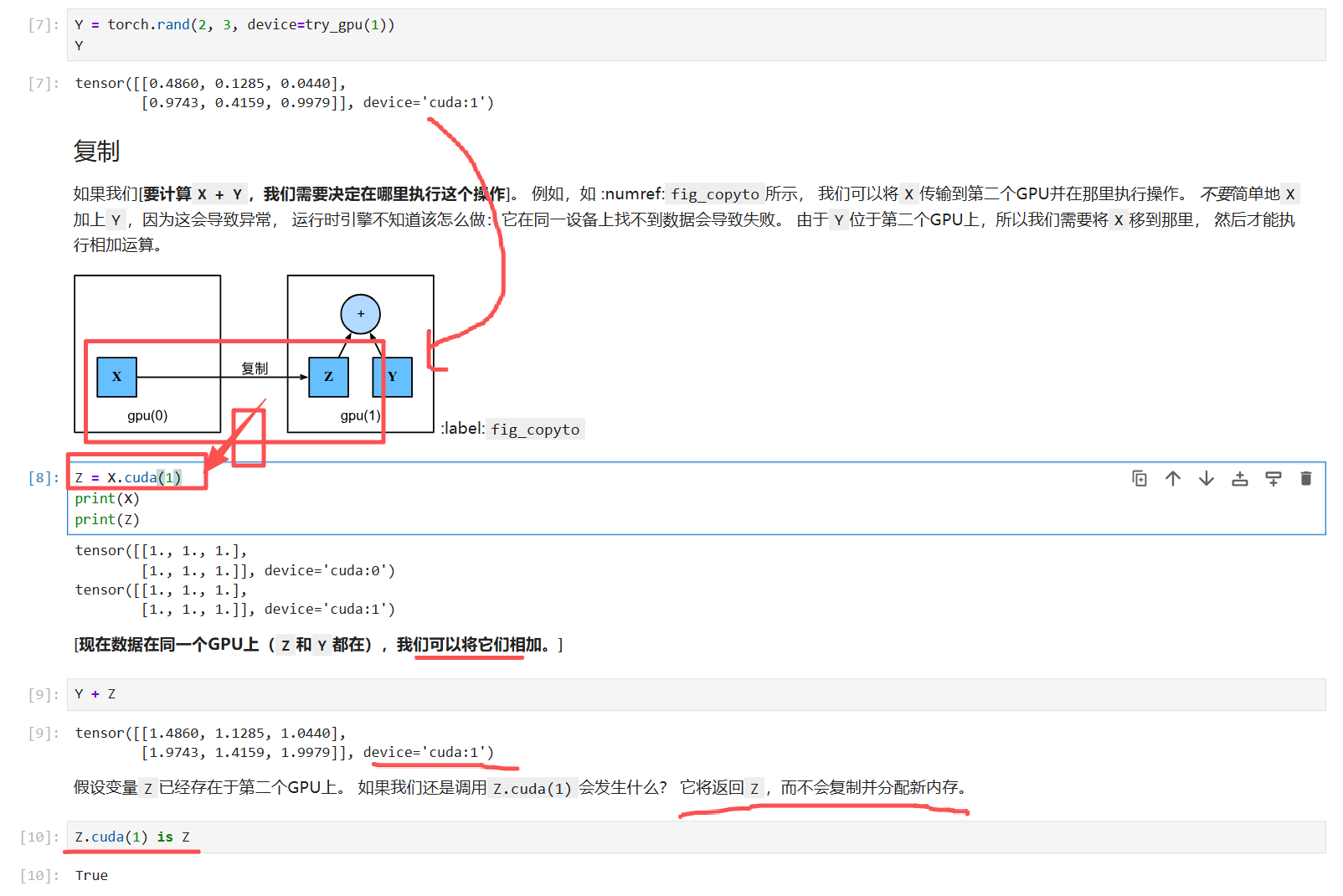
关于 Z.cuda(1) is Z这个表达式,它的结果是取决于 Z 的当前设备位置的。让我详细解释一下:
核心原理
PyTorch 的张量操作方法遵循"原地操作原则":
-
如果张量已经 在目标设备上,
.cuda()会返回原张量本身 (原地操作,is为True) -
如果张量不在 目标设备上,
.cuda()会创建新的张量副本 (返回新对象,is为False)
.cuda(xx)就是复制/返回一份
拓展:如何知道一个东西有啥方法属性(重要)
1 print(type(xx))
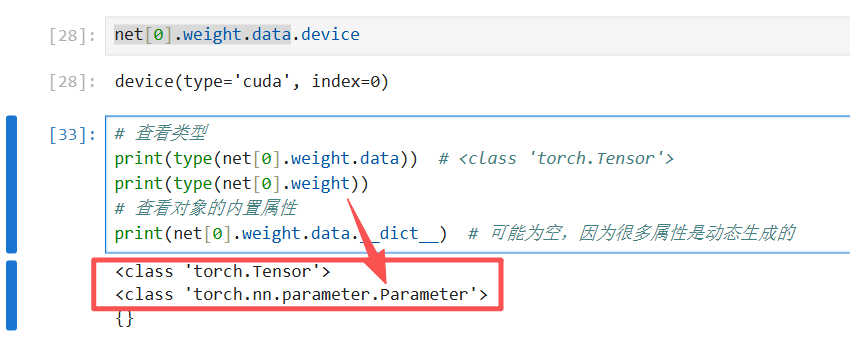
2 暴力print该东西print(dir(xx))
对于 PyTorch 张量,最常用的属性包括:
| 属性 | 说明 | 示例 |
|---|---|---|
.device |
张量所在的设备 | device(type='cuda', index=0) |
.dtype |
数据类型 | torch.float32 |
.shape或 .size() |
形状/尺寸 | torch.Size([64, 3, 3, 3]) |
.ndim |
维度数量 | 4 |
.requires_grad |
是否需要梯度 | True/False |
.grad |
梯度值 | 通常为 None或张量 |
.is_cuda |
是否在 GPU 上 | True/False |
.is_leaf |
是否是计算图的叶节点 | True/False |