但信息进来了只是个良好开端,后续的挑战是:Agent 只要跑得足够久,上下文一定会膨胀。对话历史、tool 返回、错误日志、代码 diff、测试结果,会一轮一轮堆起来。到了某个时刻,系统必须压缩历史,否则不是撞上 context limit,就是让模型淹在旧信息里。
核心不是"压缩文本",而是怎么让 Agent 在长任务里持续保留判断所需的证据、决策和失败经验。
语义压缩模式:
- 第一层先清理冗长 tool output,比如日志全文、API 返回、查询结果。
- 第二层把旧对话合并成任务状态,比如用户意图、已做改动、已做决策、下一步。
- 第三层才是更激进的历史摘要,只有在 context 压力很大时才触发。
每一层都接住上一层的输出,越往后越短,也越容易丢细节。所以语义压缩不是一次 summarize,而是一条逐级压缩链。
什么时候该用语义压缩?
只要 Agent 进入长任务,就应该考虑。比如:
会话超过 20-30 轮
context 占用超过 60%-70%
tool 结果开始大量堆积
日志、测试输出、代码 diff 明显膨胀
Agent 开始重复问、重复查、重复试
这时候不压,Agent 会撞上 context limit;乱压,Agent 会忘掉关键证据。真正好的压缩,是让 Agent 在长 session 里继续保持清醒。
但有一类内容不能被普通摘要吞掉,那就是错误信息。错误堆栈、失败测试、异常日志、关键数字、文件路径、行号,这些不是普通背景材料,而是 Agent 的反馈回路。它不能被压成一句模糊结论。短错误栈可以原文保留。长错误栈可以保留异常类型、关键数字、文件路径、行号、首尾几段和原始日志 handle。已经失败过的方案,也要进入工作记忆锚点(anchor),告诉 Agent 这条路不要再走。
Claude Code 的自动压缩:
主张更早触发,比如在 60% 到 70% 左右主动压缩。这么做看似浪费窗口,但它背后的逻辑是,不要等 Agent 变笨之后再压,而是在它还清醒的时候整理历史。Claude Code 的设计给我的工程启发是:短任务可以晚压,长会话、高风险任务应该早压。压缩的目标不是把窗口塞满,而是维持推理质量。
Factory 的锚定式迭代摘要:
Factory(也是一家 AI Coding 公司)提出重点不是"要不要压",而是"压完之后历史怎么持续演化"。普通摘要每次都重新总结历史,容易像复印件反复复印一样逐步丢细节。Factory 的做法是维护一个持续更新的 anchor。每次有新对话、新改动、新工具结果,不是重写完整摘要,而是把新信息合并进已有 anchor。对比一下摘要和 anchor:
摘要 -> 摘要的摘要 -> 摘要的摘要的摘要 (越来越模糊)
摘要0-> 摘要1-> 摘要2 (anchor仍然清晰)
OpenHands 的可配置压缩器:
Agent 历史里有两类信息:Action 和 Observation。Action 是 Agent 做过什么,比如读文件、调接口、执行命令;Observation 是外部世界返回了什么,比如日志全文、API 响应、测试输出。很多工程场景里,Agent 后续不一定需要保留所有 Observation 原文,但必须记住自己做过哪些 Action。ObservationMasking 的做法就是把早期 Observation 替换成占位符,但保留 Action。这相当于告诉 Agent:你不需要记住每一屏输出,但必须记住自己走过哪些路。如果你的 Agent token 主要花在日志、SQL 查询结果、API 响应、测试输出上,而后续推理更依赖"做过哪些动作、得出哪些结论",那 ObservationMasking 往往比通用 LLM summarization 更稳,既省 token,也减少语义漂移。
这三个合在一起,就能提炼出压缩的三条工程原则:
-
自动:必须自动化,否则长 session 迟早撞墙(师承 Claude Code)。
-
演化:不要每次重写历史,而要维护持续演化的 anchor(师承 Factory)。
-
分治:不能只有一种算法,而要根据 Action、Observation、Error、Decision 的不同性质分层处理(师承 OpenHands)。
所以,生产级压缩处理,写个 prompt 要求 Agent"把前面对话总结一下"远远不够。它应该是在合适的时间触发,用稳定 anchor 保存任务状态,对不同类型信息采取不同压缩策略,并保护错误证据、关键数字、文件路径、已做决策和已排除方案。
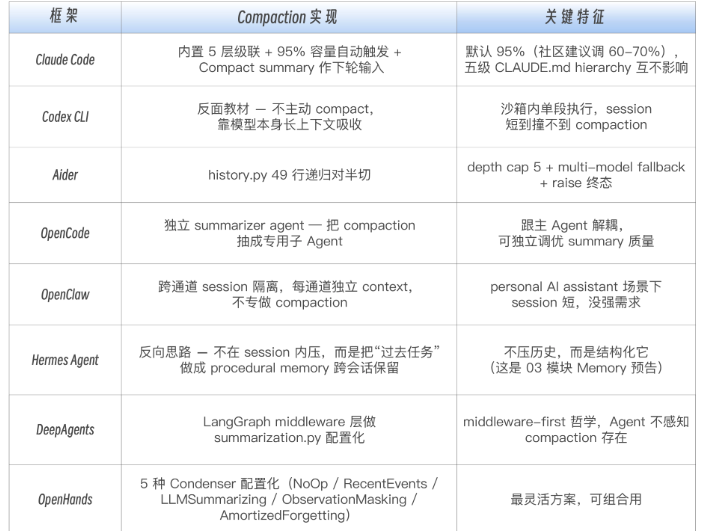
把几家主流 harness 放在一起看,会发现 Compaction 没有标准答案,只有不同取舍
-
第一,Compaction 是取舍。Claude Code 简单,OpenHands 灵活,Aider 透明,OpenCode 解耦,但没有一个方案在所有场景都最优。
-
第二,不做 Compaction 也是一种选择,但只适合短任务。任务一长,Agent 就容易忘记自己做过什么、排除过什么、为什么走到当前这一步。
-
第三,Compaction 和 Memory 要分清。Compaction 管当前 session 怎么续命;Memory 管跨 session 的经验怎么沉淀。前者解决窗口压力,后者解决长期记忆。
所以生产系统不要问"哪家方案最好",而要问:我的 Agent 会话有多长?工具输出有多大?错误密度有多高?翻车成本有多大?短问答可以轻量处理;长调试必须有 anchor;大量日志适合 ObservationMasking;跨会话复用经验,就该进入 Memory 设计。
工业级实现:可观测 Compaction 的最小骨架:
工业级 Compaction 的最小实现可以拆成三个对象:Turn、Anchor和CompactionEvent。
1、对象Turn 表示一轮对话、工具调用或工具返回。这里最关键的是 is_error。错误堆栈、失败测试、异常日志不能按普通文本压缩,因为它们是 Agent 的反馈回路。
@dataclass
class Turn:
role: str
content: str
tokens: int
is_error: bool = False
对象 Anchor 是压缩后的工作记忆。它应该稳定回答五个问题:用户要什么、我做过什么、我决定了什么、我排除了什么、下一步做什么。其中 excluded_approaches 最重要。很多长会话 Agent 反复试错,不是因为不会推理,而是忘了哪些方案已经失败。
@dataclass
class CompactionAnchor:
intent: str = ""
changes_made: liststr = field(default_factory=list)
decisions_taken: liststr = field(default_factory=list)
excluded_approaches: liststr = field(default_factory=list)
next_steps: liststr = field(default_factory=list)
对象 CompactionEvent 记录每一次压缩,应该通过这个对象把压缩前后信息和完整的 Log 日志相对应。没有这个对象,压缩就变成黑盒,Agent 后面变蠢了,你也不知道它是在哪一次压缩里丢了信息。