传统聊天机器人是单轮问答:用户提问,系统回答,流程结束。Agent不同------它具备执行循环:给定目标后,系统自主迭代执行,观察中间结果,调整策略,直到达标或触发终止条件。
构建Agent系统要回答一个核心问题:如何让LLM驱动的系统循环执行、管理状态、调用工具、处理错误,并在合适时机停止?
本文从执行循环出发,构建Skill系统、MCP集成、Memory机制、Sub-agent协作,完成Agent架构的关键模块。
第一章 核心架构与执行循环
1.1 执行循环
Agent的三步迭代:观察-思考-行动。
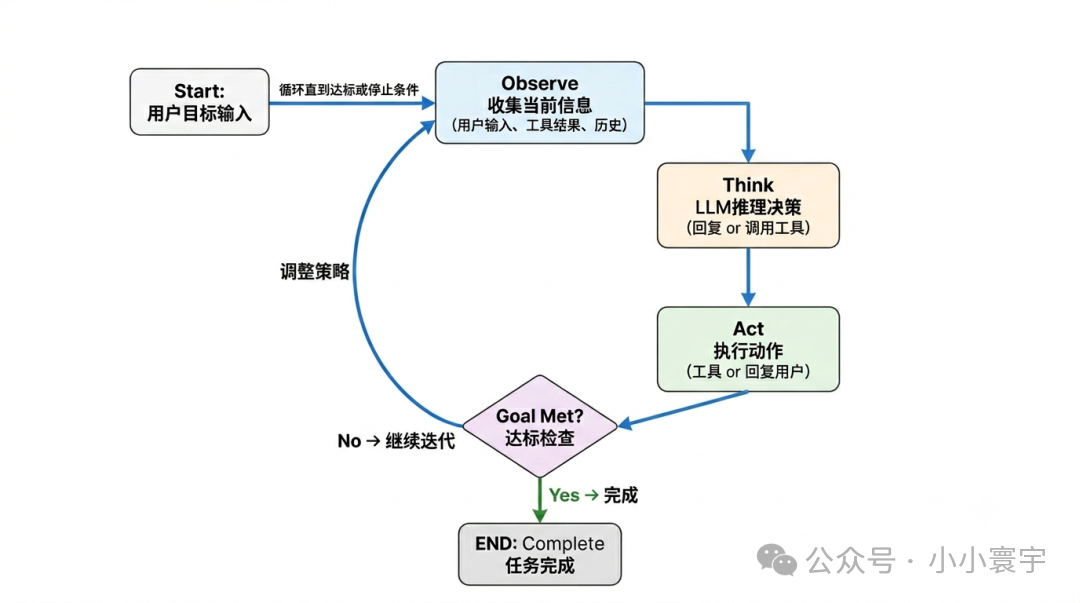
每次迭代的三步:
- • Observe:收集当前信息(用户输入、工具结果、历史消息)
- • Think:LLM推理,决策下一步行动(回复用户 or 调用工具)
- • Act:执行工具或生成回复
1.2 架构分层设计
Agent系统分层架构:
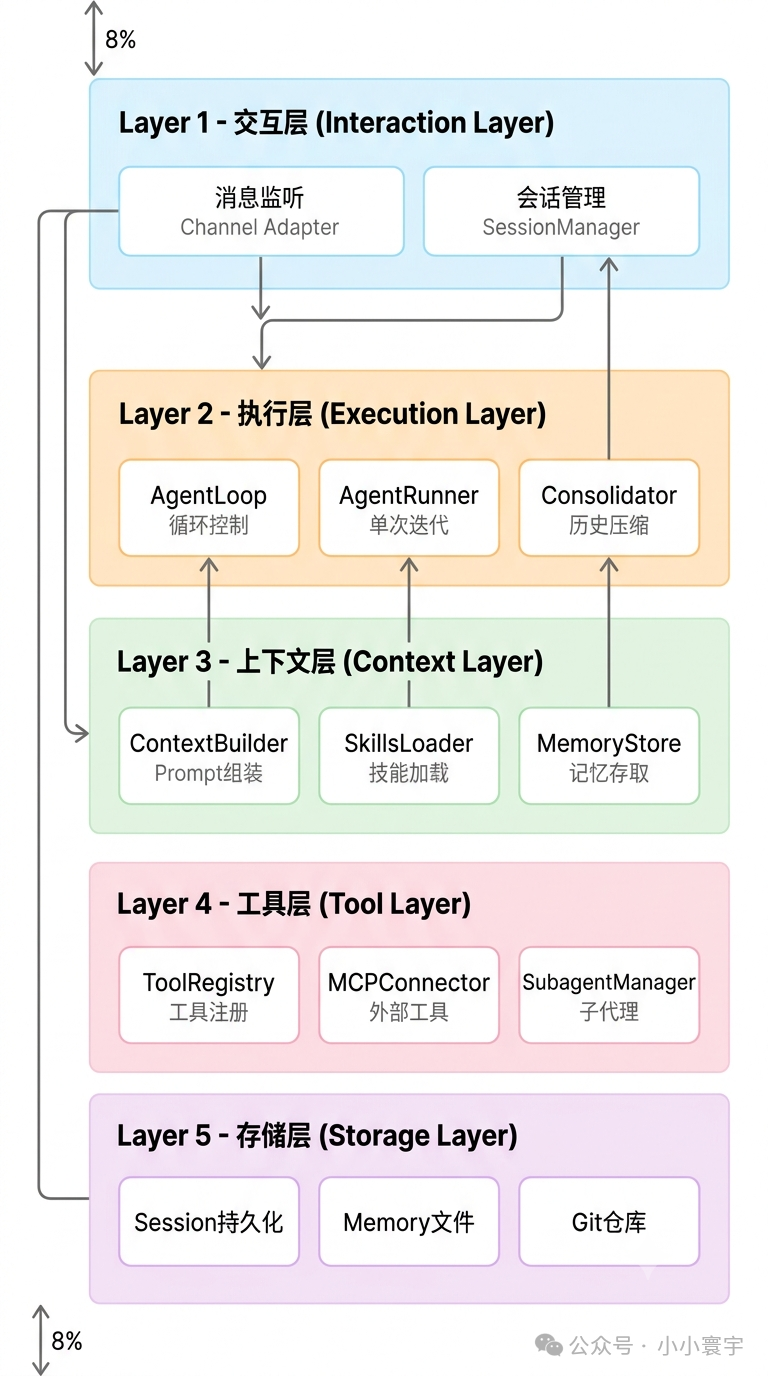
1.3 组件职责
AgentLoop(循环控制器):
- • 路由用户消息到对应Session
- • 调用AgentRunner执行迭代
- • 判断终止条件(完成/最大步数/错误)
- • 触发历史压缩
AgentRunner(单次执行器):
- • 构建Prompt
- • 调用LLM推理
- • 解析响应(文本回复或工具调用)
- • 执行工具并返回结果
为什么要分离?
- • Runner可被Dream等子系统复用
- • 可独立测试单次执行逻辑
- • Loop专注流程控制,Runner专注执行细节
1.4 Session管理
每个对话对应一个Session对象,存储对话历史、运行时状态、压缩检查点。
并发控制 :同一Session的请求必须串行执行(通过session_locks实现),避免消息顺序错乱。
mid-turn消息注入 :Sub-agent结果等系统消息需要在对话进行中插入,使用pending_queue实现。AgentLoop每次迭代前检查队列,将pending消息加入当前对话。
1.5 工具调用
Agent通过工具与外部交互。工具注册到ToolRegistry,LLM根据schema决策调用哪个工具。
工具定义示例:
bash
@tool_parameters(
tool_parameters_schema(
path=StringSchema("File path to read"),
required=["path"]
)
)
class ReadFileTool(Tool):
async def execute(self, path: str) -> str:
"""读取文件内容"""
return Path(path).read_text()
def schema(self) -> dict:
return {
"name": "read_file",
"description": "Read file contents",
"parameters": {
"type": "object",
"properties": {
"path": {"type": "string", "description": "File path"}
},
"required": ["path"]
}
}1.6 终止条件与错误恢复
四种终止原因:
| 终止原因 | 触发条件 |
|---|---|
| completed | LLM返回文本回复,无工具调用 |
| max_iterations | 达到步数上限(默认100步) |
| error | LLM调用失败或工具执行不可恢复错误 |
| ask_user | LLM请求用户确认或澄清 |
断点续传:工具调用失败时,Agent可能已执行多步操作。系统在每次迭代后保存checkpoint到Session.metadata,下次会话从失败点恢复。
1.7 设计原则
声明式架构
传统聊天机器人硬编码if-else流程树。Agent系统改为声明式:
- • 声明能力(注册工具)
- • 声明知识(编写Skill文档)
- • 声明约束(配置Memory规则)
LLM根据目标自主组合工具,无需预设流程。
渐进式上下文加载
System Prompt包含多层信息,全部加载会耗尽token(一个典型Agent的工具定义可能占用5-10k tokens)。分层加载:
- • Layer 1、2:始终加载(~1k tokens)
- • Layer 3:LLM自主决定是否读取(通过read_file工具)
- • Layer 4:保留最近N条,超出则压缩为摘要
单一职责分离
每个组件职责单一:
| 组件 | 职责 | 不负责 |
|---|---|---|
| AgentLoop | 循环控制、会话序列化 | 单次执行细节 |
| AgentRunner | 单次迭代执行 | 上下文构建、消息路由 |
| ContextBuilder | Prompt组装 | 执行逻辑 |
| MemoryStore | 文件I/O | 数据分析 |
优势:独立测试、易于替换、降低耦合。
第二章 Skill系统
Tool定义了"能做什么",但如何做好需要Skill。
2.1 Tool的局限
Agent通过Tool与外部交互。一个Tool是可执行的Python类,例如:
bash
class ReadFileTool(Tool):
"""读取文件内容"""
async def execute(self, path: str) -> str:
return Path(path).read_text()Tool定义了"能做什么":读文件、写文件、执行命令、搜索代码。
但Tool无法教会Agent方法论:
- • 什么场景下用grep而不是glob?
- • 调试时应该先复现问题还是先看日志?
- • 重构时如何保证不破坏现有功能?
这些"如何做好"的知识,需要Skill。
2.2 Skill vs Tool
Tool定义"能做什么"(可执行操作),Skill定义"如何做好"(方法论知识)。
| 维度 | Tool | Skill |
|---|---|---|
| 形式 | Python类 | Markdown文件 |
| 扩展方式 | 编写代码、注册、发布版本 | 添加.md文件即可 |
| 示例 | read_file工具 | "调试方法论"文档 |
核心优势 :用户无需编码,在workspace/skills/目录创建SKILL.md即可注入领域知识。
Skill教Agent在什么场景下、如何组合使用Tool。两者互补。
2.3 Skill文件结构
Skill是带YAML frontmatter的Markdown文件:
bash
---
name: debug
description: Guide for systematic debugging
metadata:
agent:
requires:
bins: [grep, git]
---
# 调试方法论
## 步骤1:复现问题
确保可以稳定复现bug...
## 步骤2:分析日志
使用grep搜索错误模式...元数据字段:
- •
requires.bins:依赖的CLI工具(启动时检查可用性) - •
requires.env:依赖的环境变量 - •
always:是否常驻注入
2.4 渐进式加载机制
Skill分为三层加载,避免一次注入所有内容:
层次1:目录扫描 (启动时)遍历skills/目录,收集所有SKILL.md文件路径。
层次2:摘要注入(每轮对话)将Skill的name和description组装为简短清单,注入System Prompt:
bash
Available Skills:
- weather --- Get weather forecasts
- debug --- Systematic debugging guide
- git-workflow --- Branch management best practices层次3:完整内容 (按需读取)LLM看到摘要后,决定是否需要完整内容,自主调用read_file读取特定Skill文件。
2.5 Workspace vs Builtin
Skill有两个来源,优先级不同:
Builtin Skills(内置,随代码发布)
- • 位置:
agent/skills/*/SKILL.md(或项目内置路径) - • 示例:weather、debug、skill-creator
- • 性质:通用能力,适合大多数项目
Workspace Skills(项目级,用户自定义)
- • 位置:
workspace/skills/*/SKILL.md - • 示例:项目特定的代码规范、部署流程、团队最佳实践
- • 性质:项目知识,覆盖builtin同名Skill
- • 核心特性:用户无需修改Agent代码,只需创建Markdown文件即可注入自定义知识
覆盖机制:Workspace skill优先级高于builtin,允许项目定制。
第三章 MCP集成
Skill可零代码扩展知识,但Tool不行------新增可执行能力需编码。MCP解决了这个问题。
3.1 为什么需要MCP
Skill可以零代码扩展知识(添加.md文件即可),但Tool不行------新增可执行能力通常需要编码。
MCP(Model Context Protocol)解决了这个问题:通过标准化协议,Agent可动态接入外部服务(GitHub、Slack、数据库),无需修改Agent源码。
3.2 MCP架构
Agent通过MCP协议与MCP Server通信,Server负责暴露工具schema、执行调用、返回结果。类比插件架构:Agent是宿主,MCP Server是插件。
3.3 三种能力统一为Tool接口
MCP定义三种能力,Agent视角统一为Tool:
| 类型 | 行为 | 示例 |
|---|---|---|
| Tool | 执行操作,有副作用 | 创建Issue、执行SQL |
| Resource | 读取数据,无副作用 | 文件内容、日志 |
| Prompt | 返回文本模板 | Bug报告模板 |
3.4 连接与错误处理
Agent启动时连接MCP Server并注册工具schema,后续调用复用连接。
传输协议支持:
- • stdio:Server作为子进程,通过标准输入输出通信
- • sse:Server-Sent Events单向流
- • streamableHttp:双向HTTP流
命名规则 :mcp_{server_name}_{tool_name},避免冲突。例如Server "github"的Tool "create_issue" → mcp_github_create_issue。
错误处理:
| 错误类型 | 处理策略 |
|---|---|
| 临时错误(网络、超时) | 指数退避重试(1s→2s→4s) |
| 永久错误(权限、参数错误) | 修改参数或更换方案 |
| 连接断开 | 标记重连,下次调用恢复 |
第四章 Memory系统
4.1 为什么需要Memory
Session.messages解决了当前对话的上下文,但无法跨对话保留:用户偏好、项目约束、交互经验在每次新会话中重复讲解,效率低下。
需要三层记忆架构:短期对话历史、中期对话摘要、长期项目知识。
4.2 三层记忆架构
| 层次 | 存储 | 时效 | 内容 |
|---|---|---|---|
| 短期 | Session.messages | 单次对话 | 问答历史、工具调用记录 |
| 中期 | history.jsonl | 数周~数月 | 对话摘要、关键决策 |
| 长期 | memory.md | 永久 | 项目约束、固化知识 |
4.3 文件存储结构
bash
workspace/
├── memory/
│ ├── memory.md # 长期记忆(注入System Prompt)
│ ├── history.jsonl # 对话历史(append-only)
│ └── .cursor # 自增计数器
├── soul.md # Agent角色定义
└── user.md # 用户画像memory.md示例:
bash
## 项目约束
- 使用 Python 3.11 特性
- 遵循 Google Python Style Guide
## 用户偏好
- 回答简洁4.4 Consolidator:历史压缩
消息历史平均每次对话增长15-50条,最终超出context window(如120k tokens)。Consolidator在prompt token占用超过75%时压缩旧消息。
压缩策略:
- • 在用户回合边界切割(保持对话完整性)
- • LLM将50条消息压缩为~500 tokens摘要
- • 写入history.jsonl,移除Session中的原始消息
4.5 Dream:知识提取
Consolidator释放了空间,但没有提取长期知识。Dream是后台进程,定期分析history.jsonl,更新memory.md。
两阶段设计:
- • Phase 1:分析生成建议(单次LLM调用,快速)
- • Phase 2:执行文件编辑(多轮工具调用,成本高)
Git集成:长期记忆纳入版本控制,Dream完成后自动commit。
4.6 上下文注入顺序
构建System Prompt时的优先级:
第五章 Sub-agent机制
5.1 为什么需要Sub-agent
单线程AgentLoop带来三个问题:
Sub-agent是完整的AgentLoop实例,在后台独立执行任务。
5.2 Sub-agent是完整的AgentLoop
Sub-agent不是简单的工具调用,而是完整的执行循环。它拥有:
- • 临时messages(仅task描述,不持久化)
- • 独立ToolRegistry(不含spawn和message工具)
- • 精简System Prompt(聚焦task)
- • 独立FileStates缓存
主Agent vs Sub-agent对比:
| 维度 | 主Agent | Sub-agent |
|---|---|---|
| Session | 持久化 | 临时(不持久化) |
| 工具集 | 完整+spawn+message | 完整但不含spawn和message |
| System Prompt | 完整上下文 | 精简版 |
| 用户交互 | 直接交互 | 不能直接联系用户 |
禁止的工具:
- • spawn:防止递归创建孙Agent
- • message:必须通过主Agent转发消息
5.3 Spawn工具
主Agent通过spawn工具启动Sub-agent:
bash
# 主Agent注册spawn工具
self.tools.register(SpawnTool(manager=self.subagents))spawn schema:
bash
{
"name": "spawn",
"description": "Spawn a subagent for background task execution",
"parameters": {
"task": {"type": "string", "description": "Task description"},
"label": {"type": "string", "description": "Short label"}
}
}执行流程:主Agent调用spawn后立即返回,可继续处理其他请求。Sub-agent在后台执行完整循环(read→edit→read→edit...),完成后通过MessageBus将结果注入主Agent的pending_queue。
5.4 Sub-agent的独立组件
独立ToolRegistry:注册核心工具(read、write、edit、glob、grep),但不包含spawn和message。
独立FileStates缓存:避免与主Agent冲突。
临时messages:仅包含task描述和system prompt,迭代消息不持久化。
优势:Sub-agent的消息历史不污染主Agent的Session,节省token。
5.5 为什么必须是完整AgentLoop?
原因1:复杂任务需要推理示例:"分析代码库性能瓶颈并提出优化方案"
Sub-agent执行流程:
- • 迭代1-5:grep + read分析瓶颈
- • 迭代6-10:exec运行性能测试
- • 迭代11-15:综合结果推理方案
- • final:生成报告
不同task需要不同的工具组合,需LLM动态决策,无法预编码。
原因2:错误恢复工具失败时需要推理替代方案:文件A权限不足→尝试文件B;exec失败→read日志分析→调整参数重试。简单脚本无法处理。
5.6 并发控制与错误处理
并发上限:默认max_concurrent_subagents=5,防止资源耗尽。超过上限时spawn返回拒绝消息。
错误分类处理:
| 错误类型 | Sub-agent行为 | 通知主Agent |
|---|---|---|
| tool_error | 工具执行失败 | "部分完成:3步成功,第4步失败" |
| error | LLM调用失败 | "执行失败:API超时" |
| max_iterations | 达到100步上限 | "达到步数限制,部分完成" |
| completed | 正常完成 | "任务完成:..." |
级联清理:主Agent的Session被清理时,所有Sub-agent级联取消。
第六章 总结
6.1 六大核心能力
| 能力 | 解决的问题 | 核心组件 |
|---|---|---|
| 执行循环 | 自主迭代执行目标 | AgentLoop、AgentRunner |
| 工具生态 | 与外部世界交互 | ToolRegistry、MCPConnector |
| 知识注入 | 教会Agent方法论 | SkillsLoader |
| 记忆系统 | 跨对话学习 | MemoryStore、Dream |
| 任务分解 | 并发执行复杂任务 | SubagentManager |
| 状态管理 | 持久化与断点续传 | Session、Git集成 |
6.2 Chatbot vs Agent
| 维度 | Chatbot | Agent |
|---|---|---|
| 决策机制 | 规则引擎(if-else) | LLM推理 |
| 能力边界 | 预定义模板 | 动态工具调用 |
| 知识来源 | 硬编码 | Skill+Memory持续学习 |
| 执行模式 | 单轮对话 | 多轮迭代+工具执行 |
质变:从被动响应到主动执行。
6.3 设计权衡
Session集中 vs Memory分布式
- • Session需要强一致性(消息顺序不能乱)
- • Memory需要人工可读可编辑(文件格式友好)
同步工具 vs 异步Sub-agent
- • 同步工具:行为可预测,易于错误处理
- • 异步Sub-agent:避免长时间阻塞,提升响应性
功能丰富 vs 约束安全
- • Sub-agent权限最小化,主Agent可控开放
- • 防御性设计,降低误操作影响范围
6.4 当前局限与未来方向
局限:
- • 工具固化:新增工具需编码,未实现自动创造
- • 完全依赖LLM:推理质量受限于模型能力
- • 记忆被动:Dream依赖定时触发,未实现事件驱动
方向1:自主工具生成Agent分析需求→生成Tool代码→自我注册→使用
方向2:Neuro-symbolic融合LLM处理模糊决策+规则引擎处理确定逻辑=可解释Agent
方向3:Multi-agent协作对等Agent协作(前端专家+后端专家+数据库专家),而非主从模式。
6.5 工程实践建议
从最小闭环开始先跑通:用户输入→LLM推理→工具调用→返回结果。验证假设后再添加Memory、Skill、Sub-agent。
Token预算先行规划token分配:
- • System Prompt固定开销:~1k tokens
- • Memory注入:~2k tokens
- • 工具定义:~5k tokens
- • 历史消息:滑动窗口
LLM降级策略
- • 主模型失败→切换备用模型
- • LLM不可用→启用规则引擎
- • 关键工具失败→保存checkpoint,人工介入
可观测性优先
- • 每次LLM调用的prompt/response日志
- • 工具调用参数与结果
- • Token消耗统计
- • 错误追踪与告警
6.6 结语
构建Agent系统不是技术堆砌,而是设计实践:
- • 简洁原则:能用简单循环,不引入状态机框架
- • 渐进原则:先跑通最小闭环,再扩展能力
- • 显式原则:让状态可见、决策可解释
- • 人本原则:Agent服务于人,Human-in-the-loop是安全网
Agent的目标不是AGI,而是可靠的智能助手:在人类监督下,自动化执行复杂任务,放大工程师的生产力。
---
文章首发于 「小小寰宇」
