Bleve:Go 生态里的全文检索库
Bleve 是面向 Go 的全文检索与索引库:在进程内维护倒排索引,用熟悉的 Index / Search API 完成文档入库与查询。默认索引实现是 Scorch(段式存储 + 后台持久化与合并),适合单机或中小规模、希望少运维组件的场景;需要跨机分片、集群联邦时,一般会转向 Elasticsearch/OpenSearch 等独立搜索服务。
下文以 bleve v2.5.5 源码路径为参照(与 go/pkg/mod 中版本一致),说明一条文档从 API 到落盘的调用链,以及读源码时该看哪些文件。
从 API 到索引实现
 当你写下
当你写下
go
type Page struct {
Path string `json:"path"`
Title string `json:"title"`
Content string `json:"content"`
}
index.Index("doc-1", &Page{Path: "/a/b", Content: "hello bleve"})
// 或
index.Index("doc-1", map[string]interface{}{"path": "/a/b", "content": "hello bleve"})对外类型是 bleve.Index。打开或创建索引后:
- 单条写入 :
Index(id, data)先按 mapping 把data变成内部的document.Document,再交给底层index.Index的Update。 - 批量写入 :
Batch(b)把Batch里的操作交给底层Batch,通常比逐条Index吞吐更好。
go
type Document struct {
// 文档唯一标识
id string `json:"id"`
// 普通字段:mapping 展开后的各类 Field(文本/日期/geo 等),AddField 默认进此切片
Fields []Field `json:"fields"`
// 合成字段(如 _all),与 Fields 分开存放,遍历走 VisitComposite
CompositeFields []*CompositeField
...
}可以用这个来理解:
json
{
"path": "/docs/go/bleve",
"title": "Bleve 入门",
"content": "Bleve 是 Go 的全文检索库"
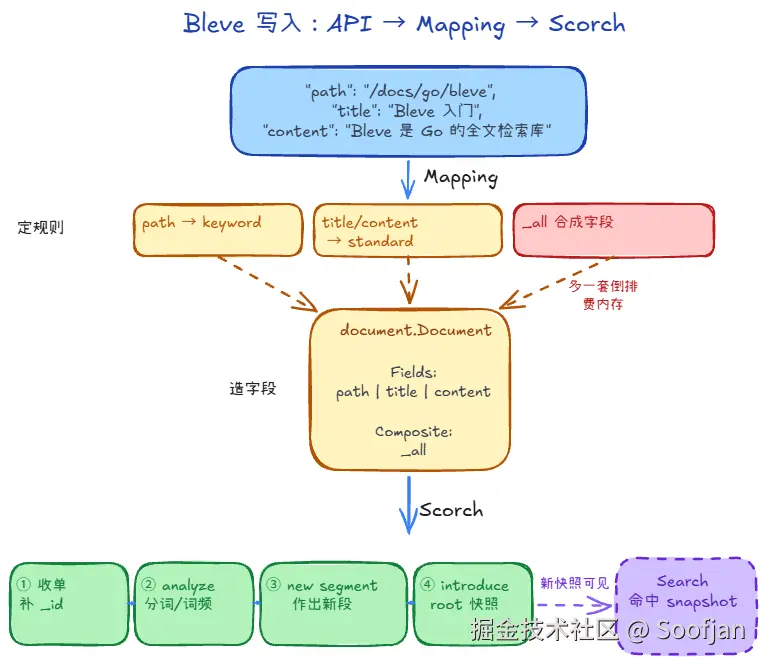
}假设 mapping 里:
- title、content 是普通可检索文本字段
- 开了 _all(把多个字段拼成一个合成字段)
那在 document.Document 里大概会变成:
- Fields:path、title、content
- 每个都是独立字段,后面可按字段名精确查,比如只搜 title:Bleve
- CompositeFields:_all
- 把 title 和 content 的词合起来,支持不指定字段的全文搜,比如直接搜 Bleve,title和content包含的话都会被搜到
- 虽然方便,但把数据"又建一套(或多套)倒排结构",即消耗了CPU,又占了内存
Mapping:字段如何进索引
还是用上面的例子:我们给 path 配了字段规则(keyword 分词器),并把它挂到一个 DocumentMapping 上;那 Mapping 这层可以理解成两步:
-
先定规则(
mapping/index.go)- 先决定这条数据走哪套
DocumentMapping - 命中明确配置的字段规则(比如
path走keyword分词器) - 没单独写规则的字段,再回退到默认 analyzer、默认日期解析
_all决定要不要做一个「把多个字段合起来搜」的合成字段- 动态字段开关(
IndexDynamic/StoreDynamic/DocValuesDynamic)决定:遇到没声明过的字段,要不要自动建索引、存原文、建 doc values- title、content:如果没显式配置,会走 dynamic mapping
- 先决定这条数据走哪套
-
再造字段(
mapping/document.go/mapping/field.go)- 把这个 JSON/结构体转换成一个
document.Document对象 - 把每个值变成具体的
Field(文本、日期、地理等) - 套用字段规则:例如
path用keyword(整串匹配,不拆词) - 给每个字段打上选项:要不要分词、要不要存盘、要不要 doc values
- 把这个 JSON/结构体转换成一个
DocumentMapping 它定义的是这类文档里每个字段怎么处理,比如:
- 字段是否建立索引
- 用哪个 analyzer 分词:默认 analyzer 通常是 standard
- 是否存原文(store):默认不存
- 是否建 doc values(排序/聚合常用):默认不建
- 是否参与 _all:默认参与
所以排错时通常是这样:
- 搜不到:先看 mapping/analyzer 是否把字段正确建成可检索字段
- 索引太大:先看是否多开了 store、doc values,或者动态字段收得太松
Scorch:Batch 主流程(分析 → 新段 → 引入)
可以把 Scorch 理解成「索引写入流水线」:上游把字段都准备好了,它负责高效落到索引里。
核心流程在 index/scorch/scorch.go 的 Scorch.Batch,按你这个文档场景可理解为:
-
先收单(收这批写入请求)
- 统计这批是新增还是删除
- 给文档补
_id字段(内部检索和去重要用)
-
并发分析(analyze)
- 文档进入
analysisQueue - 对可索引字段做分词、词频、位置信息计算
- 如果开了
_all,还会把词项再 compose 到 composite 字段
- 文档进入
-
做出新段(new segment)
s.segPlugin.New(analysisResults)把这批分析结果做成一个内存段- 这个段里已经是可查询的倒排结构雏形
-
把新段接入当前索引视图
prepareSegment会算旧段里哪些文档要作废(obsolete 位图)- 把引入任务发到
introductions队列 - 等这次引入应用到 root(新快照可见)
- 默认配置下还会等持久化回调后再返回
mapping 决定"字段怎么建",Scorch 决定"这些字段怎么批量写进段并变成可查询数据"。
段:为什么要这么设计
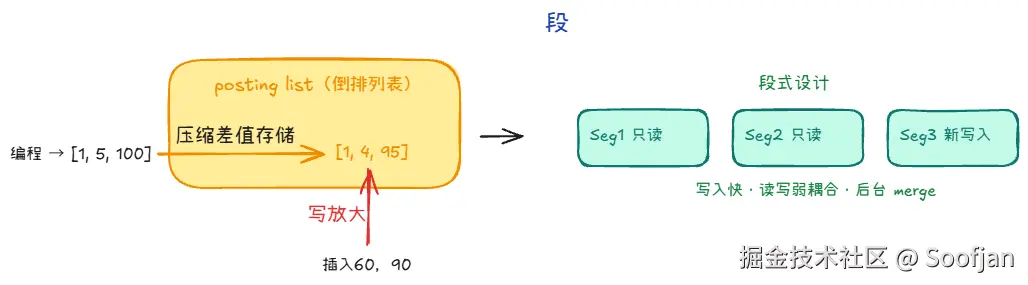 可以把「段」理解成:一小批文档对应的一份倒排索引快照。
可以把「段」理解成:一小批文档对应的一份倒排索引快照。
先看问题:为什么不能直接改老索引?
在搜索引擎里,数据是按「词 -> 文档列表」存的(倒排),不是按"行记录"存的。
比如:
编程->[1, 5, 100, ...]健身->[2, 5, 88, ...]
如果新文档(比如 2001)也包含「编程」,你不是在文件末尾追加一行,而是要把 2001 插进 编程 的 posting list。
而 posting list 为了查询快通常要保持有序、连续编码。中间频繁插入会触发大量重写,写放大非常严重。
所以搜索引擎采用「段」:
- 旧段只读,不改历史
- 新数据写成新段(先内存,后持久化)
- 查询时同时查多段再合并结果
这样做的核心收益:
- 写入快:避免频繁重写大文件
- 并发友好:读旧快照,写新段,互不强阻塞
- 可维护:后台再 merge 小段,逐步整理成大段
Persister 与 Merge:何时刷盘、额外内存从哪来
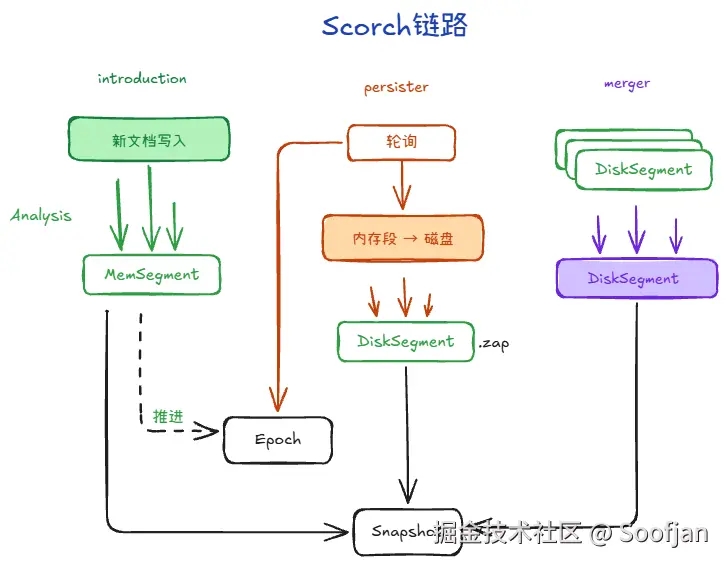
-
index/scorch/persister.go:像「落盘线程」。新段先在内存里引入,persister 再按策略把段和元信息写到磁盘,并推进 epoch/root。它和前台查询快照解耦,避免读写互相卡死。
-
index/scorch/merge.go:像「后台整理线程」。运行一段时间后会有很多小段,merge 会把它们合成更大的段,减少查询时要扫的段数;代价是会额外吃 CPU、磁盘 IO,以及一段时间内的内存。
可以把它理解成三条并发链路:引入新段(introduction)→ 持久化(persist)→ 后台合并(merge) 。
查询看到的是某个 snapshot;旧文件能不能删,由 epoch + 引用计数一起决定。
MemoryUsed():官方如何估算内存
仍在 index/scorch/scorch.go :Scorch.MemoryUsed() 把下列部分加总(概念上):
- 当前 root 快照 的
Size()。 - Persister 正在处理的快照 (若 epoch 与当前不一致,加上
persistSnapshotSize)。 - Merger 正在处理的快照 (同理加
mergeSnapshotSize)。 - 新段缓冲区 的增减:
newSegBufBytesAdded - newSegBufBytesRemoved。 - 分析阶段 暂存的字节:
analysisBytesAdded - analysisBytesRemoved。
因此它不是操作系统层面的 RSS,而是 与索引实现相关的、可解释的组成部分;做容量规划或对比配置时很有用。
内存占用飙升的常见原因
_all开启:会为合成字段再维护一套倒排结构- 文档内容太长:分词后 token 数暴涨,词频/位置信息更大
- 单次 batch 太大:分析缓冲和新段缓冲同时抬高峰值
- 动态字段过多:字段集合不收敛,索引结构持续膨胀
- merge/persist 叠加期:会短时多持有快照和中间数据