分布式知识体系
一、分布式锁
 单机锁只能管住一个进程内的线程,比如
单机锁只能管住一个进程内的线程,比如 sync.Mutex、synchronized。一旦服务部署成多实例,请求可能打到不同机器,单机锁就不够了。
分布式锁要解决的是:多台机器、多个进程同时竞争同一份资源时,只允许一个执行者进入临界区。
典型场景:
- 定时任务多实例部署,只允许一个实例执行。
- 防止重复扣库存、重复发券、重复支付回调。
- 缓存重建时避免大量请求同时打到数据库。
- 分布式环境下保护某个共享资源。
分布式锁核心要求:
| 要求 | 说明 |
|---|---|
| 互斥性 | 同一时刻只能有一个客户端持有锁 |
| 防死锁 | 持锁方宕机后,锁最终能释放 |
| 可重入/续期 | 长任务需要考虑锁过期问题 |
| 安全释放 | 只能释放自己持有的锁 |
| 高可用 | 锁服务本身不能轻易成为单点 |
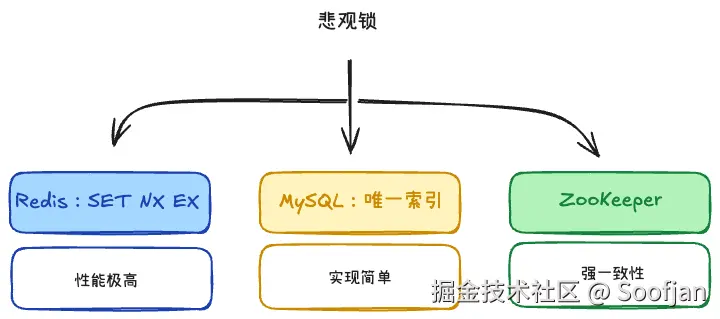
1. Redis 实现分布式锁
Redis 分布式锁最常见,性能高,实现简单,适合大多数业务互斥场景。
1.加锁
正确加锁方式应该是原子命令:
bash
SET lock:order:123 request-id NX EX 30含义:
| 参数 | 说明 |
|---|---|
lock:order:123 |
锁 key |
request-id |
锁持有者唯一标识 |
NX |
key 不存在时才设置,保证互斥 |
EX 30 |
30 秒过期,防止死锁 |
不要用下面这种分两步的方式:
bash
SETNX lock value
EXPIRE lock 30因为 SETNX 成功后,如果进程在 EXPIRE 前宕机,锁可能永远不释放。
2.解锁
解锁不能直接 DEL lock,因为可能误删别人的锁。
问题场景:
- A 获取锁,过期时间 30 秒。
- A 执行业务超过 30 秒,锁自动过期。
- B 获取到同一把锁。
- A 执行完直接
DEL lock,把 B 的锁删掉。
所以解锁要先判断 value 是否是自己的 request-id,再删除。这个判断和删除必须用 Lua 保证原子性:
lua
if redis.call("get", KEYS[1]) == ARGV[1] then
return redis.call("del", KEYS[1])
else
return 0
end一句话:加锁用 SET NX EX,解锁用 Lua 比对 value 后删除。
3.锁过期和续期
如果业务执行时间可能超过锁过期时间,有两种处理方式:
- 估算一个足够长的过期时间。
- 使用看门狗机制自动续期。
看门狗的思路是:持锁线程还活着,就周期性延长锁过期时间;业务结束后主动释放锁。
Redisson 的分布式锁就内置了类似机制。
4.Redis 锁的问题
Redis 锁不是没有风险,主要问题在高可用切换场景。
例如 Redis 主从架构:
- 客户端 A 在 master 上加锁成功。
- 锁还没同步到 slave。
- master 宕机,slave 被提升为新 master。
- 客户端 B 在新 master 上也加锁成功。
这时可能出现两个客户端同时认为自己持有锁。
所以 Redis 锁适合多数业务互斥场景,但如果是金融级强一致互斥,要更谨慎,可以考虑 ZooKeeper、etcd,或者从业务层做幂等和状态机兜底。
2. ZooKeeper / etcd 实现分布式锁
ZooKeeper 和 etcd 更偏强一致协调服务,适合对锁一致性要求更高的场景。
1.ZooKeeper 锁原理
常见做法是使用临时顺序节点:
text
/locks/order/lock-00000001
/locks/order/lock-00000002
/locks/order/lock-00000003加锁流程:
- 客户端在锁目录下创建临时顺序节点。
- 获取当前目录下所有节点并排序。
- 如果自己的节点序号最小,则获取锁成功。
- 如果不是最小节点,就监听自己前一个节点。
- 前一个节点删除后,再判断自己是否最小。
释放锁:
- 正常执行完删除自己的临时节点。
- 客户端宕机或会话断开,临时节点自动删除。
2.为什么监听前一个节点
如果所有客户端都监听最小节点,最小节点释放时会唤醒大量客户端,形成惊群。
监听前一个节点可以做到链式唤醒:
text
lock-01 释放 -> 唤醒 lock-02
lock-02 释放 -> 唤醒 lock-03这样更有序,也更节省资源。
3.数据库实现分布式锁
数据库也可以实现分布式锁,常见方式有唯一索引和悲观锁。
1.唯一索引加锁
建一张锁表:
sql
CREATE TABLE distributed_lock (
lock_name VARCHAR(128) PRIMARY KEY,
owner VARCHAR(128),
expire_at DATETIME
);如果插入成功,说明拿到锁;如果主键冲突,说明锁已被别人持有。
2.数据库锁的特点
优点:
- 依赖少,如果系统本来就有数据库,实现方便。
- 可以利用数据库事务和唯一约束。
- 对一致性要求比 Redis 更直观。
缺点:
- 性能不如 Redis。
- 高并发下数据库压力大。
- 需要处理过期锁、死锁、事务超时等问题。
数据库锁适合并发量不高、依赖简单、业务更看重一致性的场景。
二、分布式 ID
 单机自增 ID 在单库单表里很好用,但系统分布式后会遇到问题:
单机自增 ID 在单库单表里很好用,但系统分布式后会遇到问题:
- 分库分表后,不同库的自增 ID 可能冲突。
- 多服务并发生成 ID,需要全局唯一。
- 订单号、消息 ID、链路追踪 ID 等需要跨系统流转。
- 有些场景还要求趋势递增,方便数据库索引和排序。
分布式 ID 常见要求:
| 要求 | 说明 |
|---|---|
| 全局唯一 | 不同机器生成的 ID 不能重复 |
| 高性能 | 生成 ID 不能成为系统瓶颈 |
| 趋势递增 | 对数据库 B+Tree 索引更友好 |
| 高可用 | ID 服务故障不能影响全站 |
| 可解析 | 最好能看出时间、机器号等信息 |
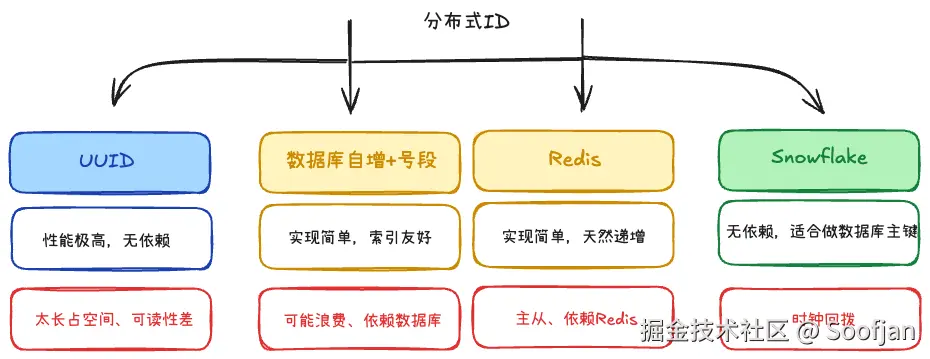
1.UUID
UUID 最简单,应用本地直接生成,不依赖中心服务。
text
550e8400-e29b-41d4-a716-446655440000优点:
- 本地生成,性能高。
- 不依赖数据库、Redis 或 ID 服务。
- 全局唯一概率极高。
缺点:
- 太长,占用存储空间大。
- 无序,作为数据库主键会导致索引频繁分裂。
- 可读性差,不方便排查。
UUID 适合日志追踪、请求 ID、幂等 token,不太适合做核心业务表的自增主键。
2. 数据库自增和号段模式
1.数据库自增
最简单方式是用数据库自增主键:
sql
id BIGINT AUTO_INCREMENT PRIMARY KEY优点是简单、递增、容易理解。
缺点是分库分表后不好保证全局唯一,而且强依赖数据库,性能和可用性都受数据库影响。
2.号段模式
号段模式是数据库自增的增强版。ID 服务每次从数据库申请一段 ID,缓存到本地慢慢发。
例如数据库记录当前最大值:
text
biz_tag = order
max_id = 100000
step = 1000ID 服务申请一次号段后,拿到:
text
100001 ~ 101000后续 1000 个 ID 都可以在内存里生成,不用每次访问数据库。
优点:
- 性能比每次查数据库高很多。
- ID 趋势递增,对数据库索引友好。
- 可以按业务隔离号段,比如订单、用户、消息分别分配。
缺点:
- ID 服务重启可能浪费一部分号段。
- 数据库仍是号段分配的核心依赖。
- 需要处理双 buffer、提前加载、数据库故障兜底。
典型方案:美团 Leaf 号段模式。
3.Snowflake 雪花算法
Snowflake 是 Twitter 提出的分布式 ID 生成方案,核心思想是把一个 64 位整数拆成几段:
text
0 | timestamp | machine-id | sequence常见结构:
| 部分 | 作用 |
|---|---|
| 符号位 | 固定为 0,保证正数 |
| 时间戳 | 当前时间减去自定义起始时间 |
| 机器 ID | 标识是哪台机器生成的 |
| 序列号 | 同一毫秒内自增 |
示意:
text
1ms 内:
machine-01 生成 sequence 0,1,2,3...
machine-02 生成 sequence 0,1,2,3...只要机器 ID 不冲突,同一毫秒内序列号不溢出,ID 就不会重复。
优点:
- 本地生成,不依赖数据库。
- 性能高。
- 生成的是整数,适合做数据库主键。
- 大体按时间趋势递增。
缺点:
- 依赖机器时钟,时钟回拨可能导致重复。
- 需要分配和管理机器 ID。
- 单机同一毫秒序列号有上限。
1.时钟回拨怎么处理
常见处理方式:
- 小幅回拨:等待时间追上来。
- 大幅回拨:拒绝生成 ID,报警处理。
- 使用备用 workerId 或时钟序列位。
- 通过 NTP 管理机器时间,避免频繁回拨。
面试要点:Snowflake 的核心风险是时钟回拨和机器 ID 冲突。
4.Redis 生成 ID
Redis 可以用 INCR 生成全局递增 ID:
bash
INCR id:order为了避免单 key 过大,也可以按日期分 key:
bash
INCR id:order:20260607生成订单号时可以组合:
text
日期 + 自增序列
202606070000001优点:
- 实现简单。
- 天然递增。
- 性能较高。
缺点:
- 强依赖 Redis。
- Redis 持久化和主从切换要处理好,否则可能丢失或回退。
- 超高并发下单 key 可能成为热点。
适合中小规模业务、订单号、流水号等场景。
5.方案对比
| 方案 | 优点 | 缺点 | 适合场景 |
|---|---|---|---|
| UUID | 本地生成、简单、无中心依赖 | 长、无序、索引不友好 | 请求 ID、日志追踪 |
| 数据库自增 | 简单、递增 | 分库分表困难、依赖数据库 | 单库单表 |
| 号段模式 | 趋势递增、性能高 | 实现复杂、依赖数据库分配号段 | 业务主键、订单 ID |
| Snowflake | 本地生成、高性能、整数趋势递增 | 时钟回拨、机器 ID 管理 | 高并发业务主键 |
| Redis INCR | 简单、递增、性能较好 | 依赖 Redis、可能热点 | 流水号、订单号 |
选择建议:
- 只是请求追踪:用 UUID。
- 单库单表:数据库自增足够。
- 高并发业务主键:优先 Snowflake 或号段模式。
- 需要严格递增流水号:可以用 Redis INCR 或数据库号段。
- 分库分表主键:不要直接依赖单库自增。
三、总结
分布式锁:
text
分布式锁常见实现有 Redis、ZooKeeper/etcd、数据库。
Redis 锁性能好,通常用 SET key value NX EX 加锁,
用 Lua 判断 value 后删除,避免误删别人的锁。
ZooKeeper/etcd 一致性更强,常用临时顺序节点或租约机制,
适合强一致协调场景。
数据库锁实现简单,但性能一般,适合并发不高的业务。分布式 ID :
text
分布式 ID 要保证全局唯一,最好高性能、趋势递增。
UUID 简单但无序;数据库自增不适合分库分表;
号段模式通过批量申请 ID 提升性能;
Snowflake 通过时间戳、机器 ID、序列号组合生成 64 位整数,
性能高但要处理时钟回拨和机器 ID 冲突;
Redis INCR 简单递增,但依赖 Redis,可用于流水号。