2023 年那波 AI Agent 热潮,最迷人的地方不是"一个模型会做多少事",而是"一群模型能不能像团队一样工作"。
一个负责规划,一个负责写代码,一个负责检查结果,听起来像把公司搬进了提示词里。那一年,AutoGPT、BabyAGI、ChatDev 这类系统把"自主智能体"的气氛推得很高,但真正跑起来之后,问题也很快暴露------这些 Agent 往往不是在协作,而是在互相"传话"。
传话最怕什么?
最怕第一轮只是有点含糊,第二轮就开始走形,第三轮已经变成另一个项目。大模型的幻觉不再是单点错误,而会沿着多智能体链路一路扩散。
MetaGPT 就是在这个背景下出现的。
它不是让 Agent 聊得更热闹,而是让 Agent 像一个真正的软件团队那样交付。产品经理写 PRD,架构师做系统设计,项目经理拆任务,工程师写代码,QA 工程师设计测试。
一句大白话总结就是------把"群聊式智能体"改造成"流水线式智能体"。
放在今天回看,它最有价值的地方,不是又造了一个 Agent demo,而是把一个后来反复出现的问题提前说清楚了。
多智能体协作不能只靠"扮演角色",还必须遵守流程。
1. 2023年的Agent热潮,最缺的不是野心
单个大模型写代码时,最常见的问题是漏需求、写错接口、忘记边界条件。多智能体系统看起来能缓解这个问题,因为不同 Agent 可以分工合作。
但分工并不自动带来协作。
你可以想象一个真实办公室:产品经理说"做一个数据可视化工具",架构师听成"做一个图表组件",工程师又理解成"写一个 matplotlib 脚本"。每个人都在工作,但交付物之间对不上。
这就是论文里说的 cascading hallucinations------级联幻觉。它不是一个 Agent 突然胡说,而是一个小误差被下游 Agent 当成事实继续加工。
普通聊天式多智能体的危险就在这里。
自然语言很灵活,也很暧昧。Agent A 给 Agent B 发一段话,Agent B 再转述给 Agent C,中间没有结构化约束,也没有强制校验,信息就像一杯水在几个杯子之间倒来倒去。
倒到最后,水还在,但形状已经变了。
MetaGPT 当时给出的核心判断很直接:复杂任务需要的不只是"更多 Agent",而是更好的组织方式。
所以 MetaGPT 的切入点不是"让模型更聪明",而是"让聪明的模型按规矩交接"。
2. SOP 是 MetaGPT 的骨架,不是装饰
MetaGPT 最关键的设计,是把 Standard Operating Procedures,也就是 SOP,编码进多智能体协作流程。
SOP 这个词听起来有点企业管理味儿,但在这里非常关键。它的意思不是"写一堆流程文档给人看",而是把任务拆成可执行、可检查、可交接的步骤。
软件公司为什么需要 PRD?
因为工程师不能只靠一句"做个好用的产品"开工。PRD 要写用户故事、需求池、功能边界,架构设计要写文件列表、数据结构、接口定义,项目管理要把这些东西拆成可分配的任务。
MetaGPT 当时做的事,就是把这套人类软件工程流程搬进 Agent 系统。这里最适合先看论文的总览图,因为它不是在展示某个模块,而是在展示 MetaGPT 的基本世界观:软件开发不是一场群聊,而是一条有角色、有交付物、有顺序的生产线。
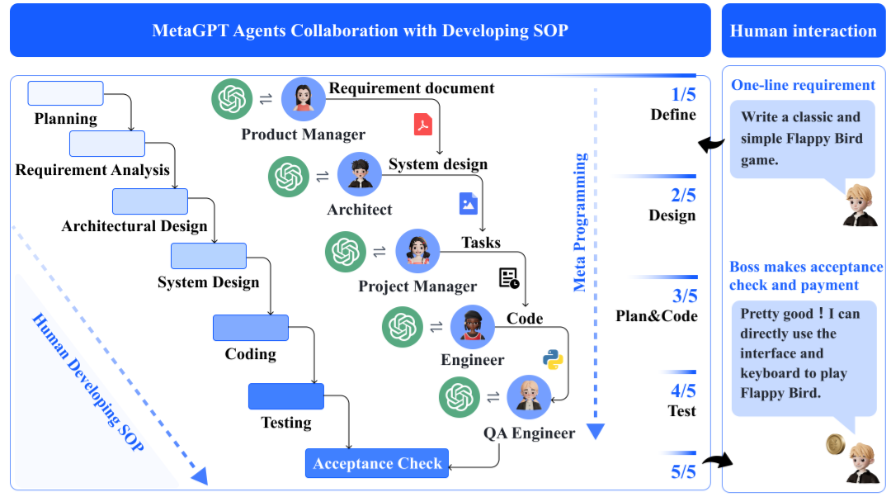
图1
图1:它把真实软件团队的 SOP 和 MetaGPT 的多 Agent 流程放在一起对照。
这张图的关键不在"角色很多",而在"交付物标准化"。
旧式多智能体更像开会:大家轮流发表意见,最后期待某个 Agent 把讨论揉成结果。MetaGPT 更像生产线:每个岗位只做自己该做的事,并把产物整理成下一个岗位能直接使用的格式。
这意味着什么?意味着协作不再依赖 Agent 的临场理解,而依赖流程本身减少歧义。意味着中间产物不再是随口一段话,而是 PRD、系统设计、接口说明、测试用例这些工程文档。意味着错误更容易暴露在交接处,而不是一路潜伏到最终代码里。
这也是 MetaGPT 和早期"角色扮演式 Agent"的根本区别。
角色扮演给 Agent 一个身份,SOP 给 Agent 一套工序。前者让模型知道"我是谁",后者让模型知道"我该交付什么"。
差别很大。
3. 五个角色,把软件公司压缩进一个 Agent 系统
MetaGPT 在软件开发任务里定义了五个核心角色:Product Manager、Architect、Project Manager、Engineer 和 QA Engineer。
这套分工不是为了热闹。
它解决的是复杂任务里最常见的"职责混杂"问题。让一个模型同时想需求、做架构、写代码、测代码,本质上就像让一个人同时当客户、设计师、工人和质检员。
当然不是不能做。
但越复杂,越容易顾此失彼。
在 MetaGPT 的流程里,Product Manager 先分析用户需求,生成 PRD。这个 PRD 包括 User Stories 和 Requirement Pool,作用是把一句自然语言需求拆成更稳定的功能描述。
Architect 接过 PRD 后,把需求转成系统设计。这里会出现 File Lists、Data Structures、Interface Definitions 这类更贴近工程实现的产物。
Project Manager 再把系统设计拆成任务。Engineer 根据任务实现类和函数。QA Engineer 最后生成测试用例,用来约束代码质量。
如果图1讲的是"为什么需要 SOP",那图2讲的就是"这条 SOP 到底怎么跑起来"。放在角色分工这一节,它能帮读者把五个角色的先后关系一次看清楚。
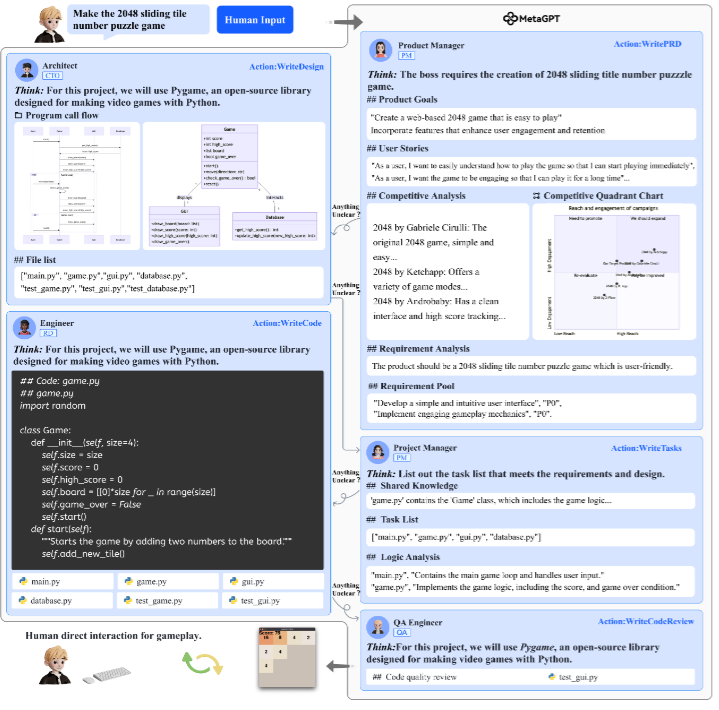
图2
图2:用户输入先进入产品经理,随后经过架构师、项目经理、工程师和 QA 工程师,最终形成完整软件输出。
你会发现,这里没有哪个 Agent 被神化。
MetaGPT 的聪明之处,是让每个 Agent 的输入和输出都被流程固定住。产品经理不能随便写几句感想,架构师不能只说"建议模块化",工程师也不能绕开接口定义自由发挥。
这就像做菜。
普通 Agent 系统是几个人围着厨房聊天:"你觉得加点盐怎么样?""我觉得可以更香。""那我发挥一下。"MetaGPT 则先写菜单,再备菜,再分工炒菜,最后试吃。
同样是多个人参与,组织方式完全不同。
更关键的是,论文并没有只停留在概念层面。消融实验显示,只用 Engineer 一个角色时,可执行性得分只有 1.0,人工修订次数是 10 次;加入 Product Manager 后,可执行性提升到 2.0,修订降到 6.5 次;当 Engineer、Product Manager、Architect、Project Manager 四个角色都加入时,可执行性达到 4.0,修订次数降到 2.5 次。
这里可以插入一张表,但不是为了堆数字,而是为了回答一个很具体的问题:角色到底有没有用?

表1
表1:它展示角色消融实验:只保留 Engineer 时可执行性最低,逐步加入 Product Manager、Architect、Project Manager 后,可执行性和人工修订次数明显改善。
这说明角色不是锦上添花,而是复杂协作里的结构性约束。
没有角色,Agent 只是"能干活"。有了角色,Agent 才开始"按工种干活"。
4. 结构化通信,让 Agent 少说废话
多智能体系统还有一个老问题:通信太自由。
自由听起来很好,但在工程任务里,自由往往意味着不稳定。一个 Agent 用散文式语言描述需求,另一个 Agent 用自己的理解补完细节,第三个 Agent 又把补完的部分当成原始需求。
这就是"电话游戏"。
MetaGPT 的通信协议把这个问题拆成两层:结构化通信接口,以及发布-订阅机制。
先说结构化通信接口。它要求不同角色按照固定 schema 输出内容。schema 可以理解成"表单格式"------你不能想写什么就写什么,而要把信息放进指定栏目。
为什么这很重要?
因为 Agent 真正需要的不是更多聊天,而是更少误解。架构师要看的不是产品经理的灵感散文,而是需求列表、用户故事、功能边界。工程师要看的不是架构师的泛泛建议,而是文件结构、数据结构和接口定义。
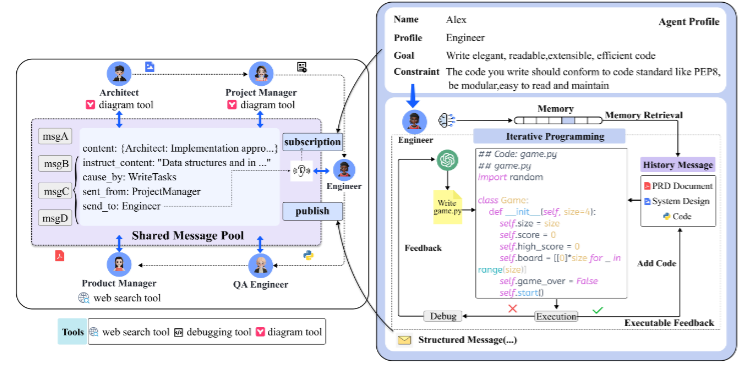
图3
图3左侧:左侧展示通信协议:Agent 把结构化消息发布到 shared message pool,并根据角色订阅相关信息。
共享消息池是第二个关键设计。
旧方案常见的是一对一对话。产品经理问架构师,架构师问工程师,工程师再问项目经理。Agent 越多,通信拓扑越乱,就像一个没有群文档的项目团队,所有信息都散落在私聊里。
MetaGPT 让所有结构化消息进入一个全局 message pool。每个 Agent 可以发布自己的产物,也可以从池子里读取需要的信息。
但如果所有信息都推给所有 Agent,又会出现信息过载。
所以 MetaGPT 引入 publish-subscribe,也就是发布-订阅机制。每个 Agent 根据自己的角色订阅相关信息。Architect 主要关注 PRD,Engineer 主要关注任务和设计,QA Engineer 关注代码和测试目标。
一句大白话总结就是------不是所有人都进同一个大群狂刷消息,而是每个人订阅自己工作所需的频道。
这个设计现在看起来很朴素,也很工程。但在 2023 年那波 Agent 叙事里,它恰好补上了最容易被忽略的一环。
它说明 MetaGPT 没有把"多智能体"理解成"多轮聊天",而是理解成"信息在组织结构里的流动"。真正的协作不是说得多,而是该知道的人在该知道的时候拿到该知道的信息。
这才是系统设计。
5. 可执行反馈,把"自我反思"拉回现实
代码生成最残酷的一点是:看起来对,不等于能跑。
大模型很擅长写出"像代码的代码"。变量名合理,注释漂亮,结构完整,但一运行就可能缺包、接口不匹配、路径写错、类名对不上。
所以只让另一个 Agent 做 code review,仍然不够。
因为审查者也是大模型,也可能被同样的幻觉骗过去。一个不会真正运行的审查流程,很容易变成"看上去挺专业"的二次幻觉。
MetaGPT 的可执行反馈机制,就是把代码放进现实里撞一下。刚才图3左侧讲的是"消息怎么流动",现在可以把视线移到同一张图的右侧------它展示的是代码如何在执行、报错、修复之间循环。
具体流程很直接:Engineer 根据 PRD 和系统设计生成初始代码,然后运行代码和测试。如果通过,就继续后续任务;如果失败,就读取历史执行与调试记忆,对照 PRD、系统设计和代码文件进行修复。这个循环最多重试 3 次。
这里的重点不是"反思",而是"可执行"。
反思是模型自己说"我可能哪里错了"。可执行反馈是系统告诉它"这里真的错了"。前者像自我检讨,后者像编译器和测试框架把错误拍在桌上。
两者的力度完全不同。
论文给出的消融结果也很清楚:加入可执行反馈后,MetaGPT 在 HumanEval 上带来 4.2% 的提升,在 MBPP 上带来 5.4% 的提升。在 SoftwareDev 里,可执行性从 3.67 提升到 3.75,人工修订成本从 2.25 降到 0.83。
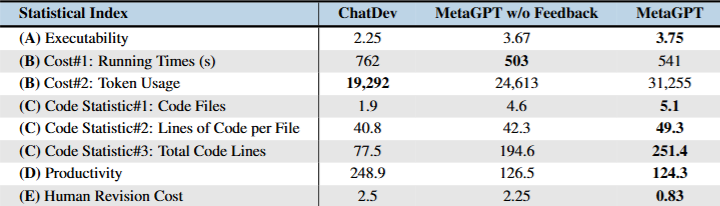
表2
表2:SoftwareDev 上,ChatDev 的可执行性是 2.25,MetaGPT 无反馈版本是 3.67,完整 MetaGPT 是 3.75;人工修订成本分别是 2.5、2.25 和 0.83。
这说明可执行反馈不是"多一个检查环节",而是把多智能体系统从文本世界拉回工程世界。
只要代码需要运行,现实就是最硬的裁判。
6. 实验结果:MetaGPT 赢在工程完整性
一句话概括实验结论:在论文设定的评测里,MetaGPT 不只是代码题上分数更高,在真实软件开发任务里也更像一个能交付的系统。
论文用了三类评测。
第一类是 HumanEval,包含 164 个手写编程任务。第二类是 MBPP,包含 427 个 Python 任务。第三类是团队自建的 SoftwareDev,包含 70 个代表性软件开发任务,覆盖小游戏、图像处理算法、数据可视化等场景。
HumanEval 和 MBPP 更像算法题考场。
SoftwareDev 更像真实外包需求。它不只看代码对不对,还看能不能运行、花多少时间、用了多少 token、生成多少代码、需要人类修几次。
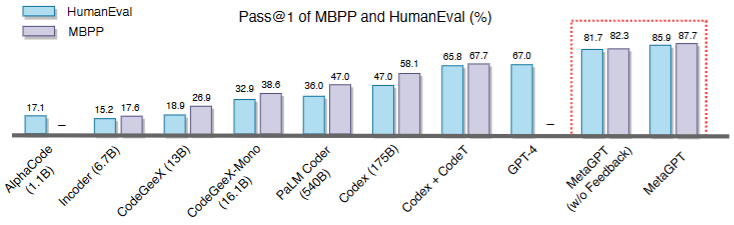
图4
图4:它展示 MetaGPT 在 HumanEval 和 MBPP 上的单次 Pass 率,MetaGPT 分别达到 85.9% 和 87.7%。
数字本身已经不错,但更有信息量的是 SoftwareDev。
在这个评测里,ChatDev 的可执行性是 2.25,MetaGPT 是 3.75,满分是 4。ChatDev 平均运行时间是 762 秒,MetaGPT 是 541 秒;ChatDev 平均总代码行数是 77.5,MetaGPT 是 251.4;ChatDev 每行代码消耗 248.9 token,MetaGPT 是 124.3 token。
这里有个很有意思的细节。
MetaGPT 总 token 用量更高,达到 31,255,而 ChatDev 是 19,292。乍看之下,MetaGPT 更贵。但如果按每行代码消耗计算,MetaGPT 反而更高效。
这就像装修。
一个团队只花了很少材料,但最后交付一个半成品;另一个团队材料用得多一些,却交付了更完整的房子。单看材料费会误判,必须看最终可用面积。
如果图4说明"分数能打",Table 1 说明的就是"真实软件开发任务里能不能交付"。这张表值得放在 SoftwareDev 讨论之后,因为它能把可执行性、运行时间、token、代码行数和人工修订成本放在同一张图景里。
表2
表2:它比较 ChatDev、MetaGPT w/o Feedback 和完整 MetaGPT 在 SoftwareDev 上的统计结果,尤其适合支撑"MetaGPT 赢在工程完整性"这个判断。
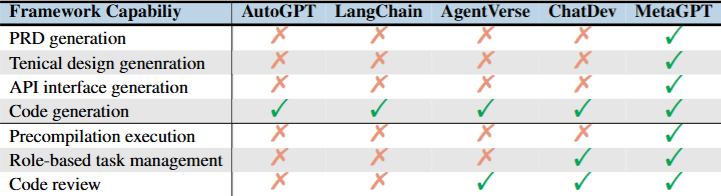
表3
表3:它比较 AutoGPT、LangChain、AgentVerse、ChatDev 和 MetaGPT 的能力,MetaGPT 覆盖 PRD 生成、技术设计生成、API 接口生成、代码生成、预编译执行、基于角色的任务管理和代码审查。
这个表的含义很直接:MetaGPT 当时的优势不是某个单点功能,而是完整软件工程链路。
AutoGPT、LangChain 更偏通用工具调用。AgentVerse 有多智能体协作。ChatDev 有角色和代码审查。但 MetaGPT 把 PRD、技术设计、API 接口、预编译执行这些环节都接进来了。
它不是在某个点上"更聪明"。
它是在整个流程上"更像团队"。
7. MetaGPT 的定位:不是更大模型,而是更硬组织
把 MetaGPT 放进 2023 年前后的多智能体研究版图里,它的位置很清楚。
第一条路线,是单 Agent 加工具。比如让一个模型调用搜索、执行代码、读文件、写文件。这条路线的优势是简单,链路短,出问题容易定位。但缺陷也明显------复杂任务会把规划、执行、检查全压在一个上下文里,模型很快开始丢细节。
第二条路线,是多 Agent 自由讨论。多个角色互相提建议,靠对话形成答案。优势是灵活,能模拟头脑风暴;缺陷是通信松散,信息容易漂移,幻觉会沿着对话链条扩散。
第三条路线,是角色扮演式开发团队。比如让不同 Agent 扮演 CEO、CTO、程序员、测试员。优势是分工感更强;缺陷是如果没有结构化交付物和严格流程,角色只是提示词里的身份标签。
单 Agent 太挤,自由讨论太飘,浅层角色扮演太软。
MetaGPT 的定位正是在这三者之间找一个新平衡:保留多角色分工,但用 SOP 固定流程;保留自然语言能力,但用结构化文档约束交接;保留自我修复能力,但用可执行反馈提供现实校验。
这也是它最值得关注的地方。
很多人谈 Agent,会自然走向"更自主""更开放""更像人"。MetaGPT 在当时反而给了一个相反方向的提醒:越复杂的任务,越需要制度化约束。
人类公司不是因为每个人都自由发挥才强大。
公司强在流程、角色、交接、复盘和责任边界。AI Agent 要进入复杂任务,也绕不开这些东西。
当然,站在今天看,MetaGPT 也不是终点。
论文自己的限制部分提到,系统侧仍面临上下文高效使用、减少幻觉等深层挑战;在人类用户侧,需求表达不清依然会影响最终结果。它还涉及就业、透明度、隐私和数据安全等伦理问题。
这些限制并不削弱 MetaGPT 的历史价值。
它们反而说明,多智能体系统一旦从玩具演示走向真实生产,就必须面对工程、组织和社会层面的复杂性。
8. 从 Agent 到组织,MetaGPT留下的问题还没过时
MetaGPT 的核心贡献,可以用一句话概括:它把多智能体协作从"对话问题"改写成了"组织问题"。
这个转向放在今天看,仍然重要。
过去我们总想让模型变得更强,能理解更多上下文,能自己规划更多步骤,能一次性生成更完整的代码。MetaGPT 提醒我们,复杂工作不一定只靠更强的个体完成,也可以靠更好的协作结构完成。
沿着这个思路,后来的系统仍然绕不开三个方向。
第一,SOP 会从软件开发扩展到更多专业领域。法律、科研、金融分析、数据科学,本质上都有自己的工作流和交付标准。
第二,多智能体系统会更重视中间产物。不是只看最后答案,而是看需求文档、推理记录、接口说明、测试结果这些"过程资产"。
第三,可执行反馈会变得更普遍。代码可以运行,数据分析可以复算,网页可以截图检查,机器人可以在仿真环境里试错。Agent 越要进入现实,反馈就越不能只停在语言层面。
MetaGPT 给出的不是一个万能答案,而是一条很硬的路线:让 AI 不只会说、不只会想,还要会交接、会执行、会被检查。
如果说早期 Agent 是"会聊天的员工",MetaGPT 展示的就是"会按流程交付的团队"为什么重要。