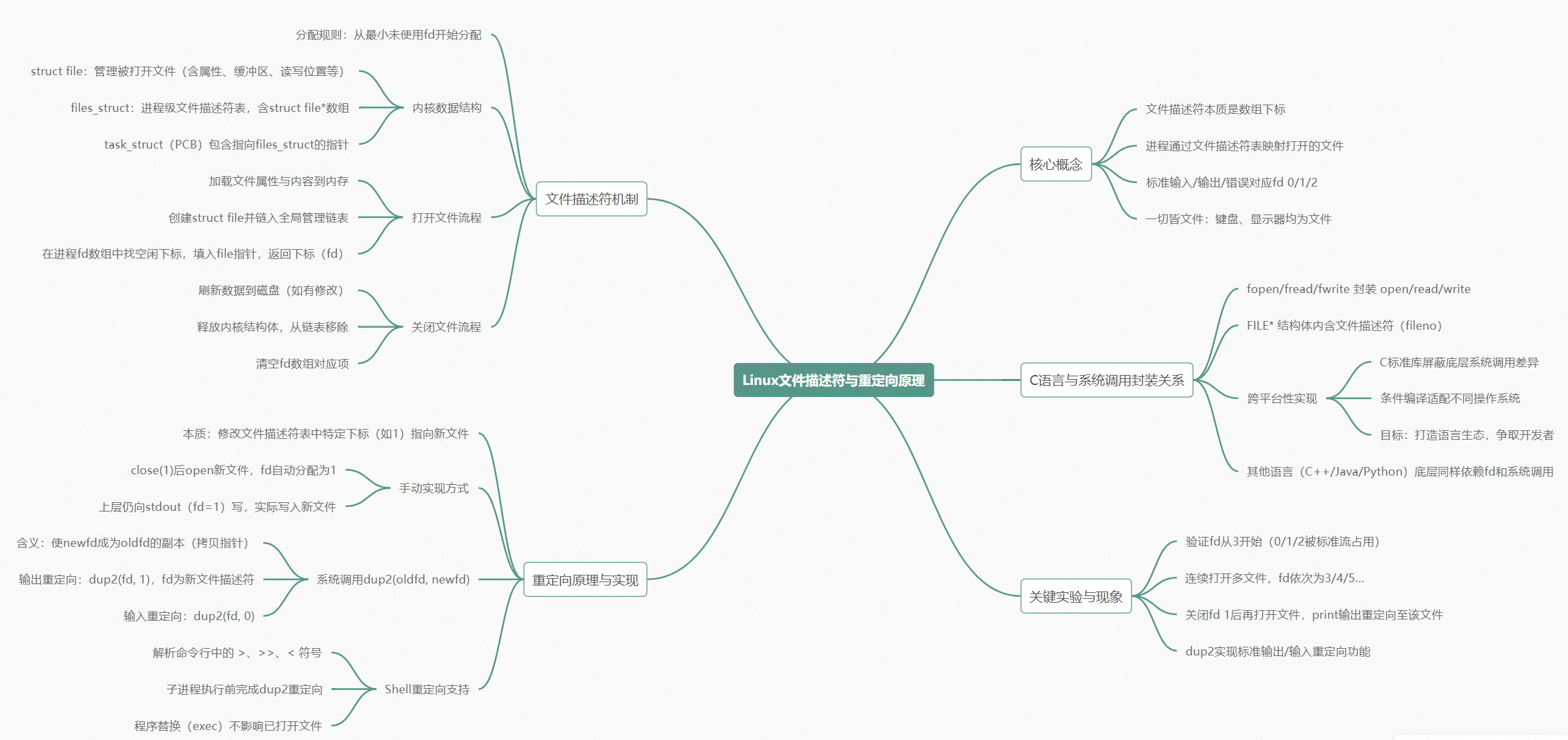
文件描述符------从内核数据结构到重定向,一次彻底搞懂
为什么 open 返回的文件描述符总是从 3 开始?0、1、2 去哪了?"文件描述符的本质是数组下标"这句话到底是什么意思?
这篇文章来回答这些问题。我们从课堂上的一个小实验出发,一路挖到内核源码,最后在自己写的 mini shell 里实现重定向。
一个实验:打印 fd,然后开始问问题
写一段最简单的代码,打开一个文件,然后把它返回的那个整数------文件描述符------打印出来:
c
int fd = open("log.txt", O_WRONLY | O_CREAT | O_TRUNC, 0666);
printf("fd: %d\n", fd);
close(fd);编译运行。输出:
fd: 33。如果我再打开三个文件 log_a、log_b、log_c:
c
int fda = open("log_a", O_WRONLY | O_CREAT | O_TRUNC, 0666);
int fdb = open("log_b", O_WRONLY | O_CREAT | O_TRUNC, 0666);
int fdc = open("log_c", O_WRONLY | O_CREAT | O_TRUNC, 0666);
printf("fda: %d, fdb: %d, fdc: %d\n", fda, fdb, fdc);输出:
fda: 3, fdb: 4, fdc: 5看到这三个数字,四个问题立刻跳出来:
- 为什么从 3 开始? 0、1、2 去哪了?
- 为什么是连续的? 3、4、5,不是 3、7、11。
- 为什么一个整数就能表示一个文件? 凭什么往
write(3, ...)里传个 3,数据就能写到正确的文件里? - 文件描述符的本质到底是什么?
一个一个来。
0、1、2 去哪了------标准输入、标准输出、标准错误
你学 C 语言的第一天就听过:任何一个程序运行时,默认会打开三个"流"------stdin、stdout、stderr。当时老师说:"你记住就行。"
现在我们来证明它。stdin、stdout、stderr 都是 FILE* 类型的。而上一篇文章我们已经说了,FILE 是一个结构体,它在底层必然封装了文件描述符------因为操作系统只认文件描述符 。你不封装 fd,你的 fwrite 就写不进去。
那这个 fd 藏在哪?在 FILE 结构体里有一个字段叫 _fileno。
c
printf("stdin->_fileno: %d\n", stdin->_fileno);
printf("stdout->_fileno: %d\n", stdout->_fileno);
printf("stderr->_fileno: %d\n", stderr->_fileno);运行:
stdin->_fileno: 0
stdout->_fileno: 1
stderr->_fileno: 2答案出来了。0 被标准输入占了,1 被标准输出占了,2 被标准错误占了。 你再打开新文件,只能从 3 开始。
Linux 下一切皆文件------键盘是文件,显示器也是文件。进程启动时,操作系统帮你把键盘和显示器这两个"文件"也打开了,分别分配了 fd 0 和 fd 1(显示器还被分配了两次------stdout 和 stderr 各占一个)。
所以第二个问题也顺带回答了:3、4、5 是连续的,因为它就是数组下标。进程内部维护了一个数组(文件描述符表),新打开的文件按顺序填入第一个空闲的位置。
命名不等于理解。"标准输入"这四个字让你觉得它跟普通文件有什么本质不同。换个问法------"进程启动时,操作系统帮你打开了键盘文件,分配了 fd 0,然后 C 库把它封装成一个叫 stdin 的 FILE 结构体"------这才是真正发生的事情。就这么回事。
在内核里,到底发生了什么
前面说的"文件描述符就是数组下标"------你得亲眼看到内核里的这个数组,才算真的信了。
第一步:task_struct 里有一个 files 指针
每个进程在内核里有一个 task_struct,也就是我们常说的 PCB。在这个结构体里,有一个字段叫 files,类型是 struct files_struct *------指向一个"文件描述符表"。
在 Linux 内核源码里(随便哪个版本,这部分改动不大),你翻 task_struct 的定义,会看到类似这样的东西:
c
struct task_struct {
// ... 调度信息、内存信息、pid、父进程指针 ...
struct files_struct *files; // 打开的文件信息
// ...
};第二步:files_struct 里有一个 fd_array
追进去看 struct files_struct:
c
struct files_struct {
// ...
struct file __rcu *fd_array[NR_OPEN_DEFAULT]; // 文件指针数组
// ...
};看到了吗?一个数组,元素类型是 struct file *。 这个数组就是文件描述符表的物理实现。NR_OPEN_DEFAULT 通常是 64(桌面系统)或更大(服务器可达 600 万+,通过动态扩展实现)。
第三步:struct file 就是被打开的文件对象
数组里的每个指针指向一个 struct file。这个结构体在内核里就代表一个被打开的文件。它的成员包括:
- 文件标志位 (你调用
open时传的那些O_WRONLY | O_CREAT | O_TRUNC,就保存在这里) - 当前读写位置 (
f_pos------就是上篇文章说的那个"数组下标",ftell返回的就是它) - 文件的 uid/gid
- 引用计数
- 文件操作表 (一个函数指针表,指向
read、write、lseek等具体实现------这也是"一切皆文件"的基石,后面会讲) - 文件的属性数据 (通过
address_space间接关联到 inode 的元数据) - 文件的缓冲区 (
address_space维护的 page tree,保存从磁盘预加载的数据)
c
struct file {
// ...
struct path f_path; // 文件在目录树中的位置
const struct file_operations *f_op; // 操作表
atomic_long_t f_count; // 引用计数
unsigned int f_flags; // 打开标志位
fmode_t f_mode; // 读写模式
loff_t f_pos; // 当前读写位置
struct address_space *f_mapping; // 缓冲区
// ...
};这就是上篇文章说的"文件 = 内容 + 属性"在内核里的具体体现。属性有,内容缓冲区也有。
把这些串起来
进程 (task_struct)
└─ files → files_struct
└─ fd_array[0] → struct file (键盘/stdin)
└─ fd_array[1] → struct file (显示器/stdout)
└─ fd_array[2] → struct file (显示器/stderr)
└─ fd_array[3] → struct file (log.txt)
└─ fd_array[4] → struct file (log_a)
└─ ...现在 open("log.txt", ...) 到底做了什么,就完全清楚了:
- 内核在磁盘上找到
log.txt,把它的属性和内容(部分或全部)加载到内存 - 内核创建一个
struct file来管理这个被打开的文件,把它链入全局的文件链表 - 内核找到当前进程的
files_struct,在fd_array里找到第一个空闲位置(此时 0、1、2 已占,所以是位置 3) - 把新创建的
struct file的地址填入fd_array[3] - 把下标 3 返回给用户------这就是文件描述符
read(3, buf, size) 做了什么:
- 内核拿到当前进程的
task_struct - 找到
files->fd_array[3] - 访问那个
struct file,从它的缓冲区(或触发磁盘读取)把数据拷到用户传进来的buf里
close(3) 做了什么:
- 刷新缓冲区数据到磁盘(如果有未写入的数据)
- 把
struct file从全局文件链表中移除并释放 - 把
fd_array[3]置空
文件描述符的本质就是数组下标。 它之所以能表示一个文件,不是因为它本身有什么魔力,而是因为它指向的那个 struct file 里包含了文件的全部信息。
文件描述符的分配规则------一个无意间触发重定向的实验
知道了"fd 就是数组下标",分配规则就是顺理成章的事:从最小的、没有被使用的下标开始分配。
我们来验证一下。把 0 号关掉,再打开新文件:
c
close(0); // 关掉标准输入
int fda = open("log_a", O_WRONLY | O_CREAT | O_TRUNC, 0666);
int fdb = open("log_b", O_WRONLY | O_CREAT | O_TRUNC, 0666);
printf("fda: %d, fdb: %d\n", fda, fdb);输出:
fda: 0, fdb: 30 被关了,最小的空闲位置就是 0,所以 fda 拿了 0。接着 1、2 还占着,所以 fdb 拿了 3。如果连 2 也关掉:
c
close(0);
close(2);
// 打开三个文件...
// 输出: fda: 0, fdb: 2, fdc: 3很自然。一切符合"最小空闲下标"的规则。
现在来做那个"意外"的实验。关掉 1,再打开新文件。
c
close(1); // 关掉标准输出!
int fd = open("log_a", O_WRONLY | O_CREAT | O_TRUNC, 0666);
printf("hello printf\n"); // 本来应该打印到屏幕
fprintf(stdout, "hello fprintf\n"); // 本来也应该打印到屏幕编译运行。屏幕上一片空白。打开 log_a,里面赫然写着:
hello printf
hello fprintf发生了什么?你刚刚实现了一次重定向。 而且是在完全无意识的情况下。
逻辑是这样的:
- 进程启动时,
fd_array[1]指向显示器文件 close(1)把fd_array[1]清空了open("log_a", ...)发现最小空闲下标是 1,于是把log_a的struct file地址填入fd_array[1]- 上层代码完全不知道内核偷偷做了什么------
printf和fprintf(stdout, ...)依然天真地往stdout写 stdout这个FILE结构体里封装的是_fileno = 1- 所以数据顺着 fd 1 写到了
fd_array[1]指向的文件------也就是log_a
重定向的本质就是把文件描述符表里某个下标指向的内容换掉。 上层代码只认下标,不关心下标背后指向的是什么文件。
dup2------正式的重定向系统调用
上面用 close(1) + open 的方式虽然也能实现重定向,但太蹩脚了------你得先关再开,而且前提是正好能分配到那个下标。实际场景里,标准输出(fd 1)根本就没被关掉。
更好的做法是:文件已经打开了,我们有两个 fd。比如 fd 1 指向显示器,fd 3 指向 log.txt。把 fd 3 里存的 struct file* 拷贝到 fd 1 里,覆盖掉 fd 1 原来指向显示器的指针。 这就叫重定向。
系统调用 dup2 就是干这个的:
c
int fd = open("log.txt", O_WRONLY | O_CREAT | O_TRUNC, 0666);
dup2(fd, 1); // 把 fd 的内容拷贝到 1 里面
// 现在 fd 1 也指向 log.txt 了
printf("这条消息会写进 log.txt\n");dup2(oldfd, newfd) 的语义:让 newfd 成为 oldfd 的一份拷贝。 两个文件描述符最终指向同一个 struct file。
这个名字起得有点反直觉。"dup2(fd, 1) 是把 fd 拷到 1 里"------但参数名里 newfd 是第二个参数,它要变成 oldfd(第一个参数)的拷贝。记住一句话:两个 fd 最后都变成 oldfd 的内容。 你要把新文件的 fd(比如 3)拷到标准输出(1)里,那就是 dup2(fd, 1)。
用 dup2 实现三种重定向,清晰明了:
c
// 输出重定向(>):把标准输出重定向到文件
int fd = open("log.txt", O_WRONLY | O_CREAT | O_TRUNC, 0666);
dup2(fd, 1);
// 追加重定向(>>):同理,只是打开模式改成追加
int fd = open("log.txt", O_WRONLY | O_CREAT | O_APPEND, 0666);
dup2(fd, 1);
// 输入重定向(<):把标准输入重定向到文件
int fd = open("log.txt", O_RDONLY);
dup2(fd, 0);三种重定向,唯一的区别就是打开文件时的选项:O_TRUNC vs O_APPEND,O_WRONLY vs O_RDONLY。dup2 的逻辑完全一样。就这么回事。
程序替换不会影响文件描述符表
有了重定向的原理,在 shell 里实现它还差最后一个认知:程序替换(exec 系列函数)不会影响进程已打开的文件。
exec 替换的是进程的代码和数据,但 task_struct 里的 files 指针不受影响。你重定向好了 fd 1 指向一个文件,然后 exec 成 ls------ls 往 stdout 写的时候,数据照样写进那个文件。
这就是为什么 shell 实现重定向的流程是:
- fork 出子进程
- 在子进程里,根据重定向类型打开文件、调
dup2 - exec 替换成目标命令
第 2 步和第 3 步之间,你会看到典型的 if (redir_type == OUT_REDIR) { fd = open(...); dup2(fd, 1); } ------然后 exec。子进程被替换后,文件描述符表纹丝不动。
C 语言为什么要封装系统调用?------不是技术问题,是生态问题
末了聊一个更大的话题。你知道了 fopen 封装了 open,fwrite 封装了 write,FILE 封装了 fd。那问题来了:为什么 C 语言要费这么大劲做封装? 直接让程序员用系统调用不好吗?
答案是跨平台性。
Linux 有 Linux 的系统调用,Windows 有 Windows 的系统调用。如果 C 语言不封装,程序员写代码时就得这样:
c
#ifdef __linux__
int fd = open("file.txt", O_WRONLY | O_CREAT, 0666);
write(fd, buf, len);
close(fd);
#elif _WIN32
HANDLE h = CreateFile("file.txt", GENERIC_WRITE, ...);
WriteFile(h, buf, len, ...);
CloseHandle(h);
#endif每换一个平台就重写一遍。C 标准库的做法是:把所有平台的文件操作都用同一套接口封装好 (fopen、fclose、fread、fwrite),然后用条件编译在不同平台上编译出不同版本的库。程序员只需要学一套接口,代码就能跨平台。
但跨平台性本身不是目的。跨平台性的本质是在打造语言的生态。
如果一个语言只支持 Linux,Windows 上几千万程序员就不会用它。如果它只支持 Windows,Linux 上几百万程序员也不会用它。开发者做技术选型时,如果不知道自己的产品将来要跑在哪个平台,一定会选跨平台的语言。不支持跨平台的语言,用户量会被锁死,最终被淘汰。
汇编语言为什么被 C 替代?x86 的汇编和 ARM 的汇编语法不一样,汇编不做跨平台抽象。C 做了,所以 C 活下来了。C++ 每三四年才发布一个新特性------为什么这么慢?因为它每加一个新特性,需要让所有平台都支持,代码要写很多份。
所以你在 Python、Java、Go 里看到的文件操作------不管上层语法多不一样,底层全都一样:最终都会被解释器/虚拟机翻译成系统调用 + 文件描述符。因为这些语言的解释器和虚拟机本身,就是用 C/C++ 写的。
命名不等于理解。"跨平台性"四个字,多数人说到这就停了。再往下追问一句------"语言为什么要争着跨平台?"------答案不是技术上的,是生态上的:它在争取每一个平台背后的开发者。
把重定向写进 mini shell------核心思路
有了上面所有认知,在 mini shell 里加重定向就是水到渠成的事。核心流程:
- 解析重定向符号 :拿到命令字符串
"ls > log.txt",识别出>,把字符串在>的位置截断(用\0覆盖>),左边是命令"ls",右边是文件名"log.txt" - 记录重定向类型和文件名 :
redir_type = OUT_REDIR,filename = "log.txt" - fork 子进程后,exec 之前 :根据
redir_type打开文件、调dup2
c
// 在子进程里,exec 之前
if (redir_type == IN_REDIR) {
int fd = open(filename, O_RDONLY);
dup2(fd, 0);
} else if (redir_type == OUT_REDIR) {
int fd = open(filename, O_WRONLY | O_CREAT | O_TRUNC, 0666);
dup2(fd, 1);
} else if (redir_type == APPEND_REDIR) {
int fd = open(filename, O_WRONLY | O_CREAT | O_APPEND, 0666);
dup2(fd, 1);
}
// 然后 exec解析字符串的细节:遍历命令字符串,遇到 > 判断下一个字符是不是也是 >(区分 >> 追加和 > 输出),遇到 < 判断输入重定向。截断后需要跳过文件名左侧的空格(用 isspace 循环跳过,或写一个宏 do { while (isspace(*p)) p++; } while(0))。
我们从中学到了什么
这篇文章的核心就一句话:文件描述符的本质是数组下标,它指向内核中的 struct file,而 struct file 包含了文件的属性、内容缓冲区和操作表。
从这个核心出发:
- 0、1、2 分别对应 stdin、stdout、stderr------进程启动时操作系统帮你打开的
- 新文件的 fd 从 3 开始连续分配------因为它是数组,找的是最小空闲下标
dup2(oldfd, newfd)把文件描述符表里的指针做了拷贝------这就是重定向的底层实现- 程序替换不影响文件描述符表------所以 shell 可以"先重定向,再 exec"
- C 语言封装系统调用是为了跨平台------而跨平台的本质是打造生态,争取开发者
还有一个细节:如果你在重定向之后 close(fd) 了,但程序退出前缓冲区没刷新,数据可能丢了------这和缓冲区的刷新策略有关。这个问题我们放到下一篇文章专门讲。
本文从一个打印 fd 数字的小实验出发,让学生看到 0/1/2 的来源,再逐层挖到内核数据结构,最后现场把重定向功能写进 mini shell------用代码证明了"你理解的东西,必须能写出来"。