覆盖索引
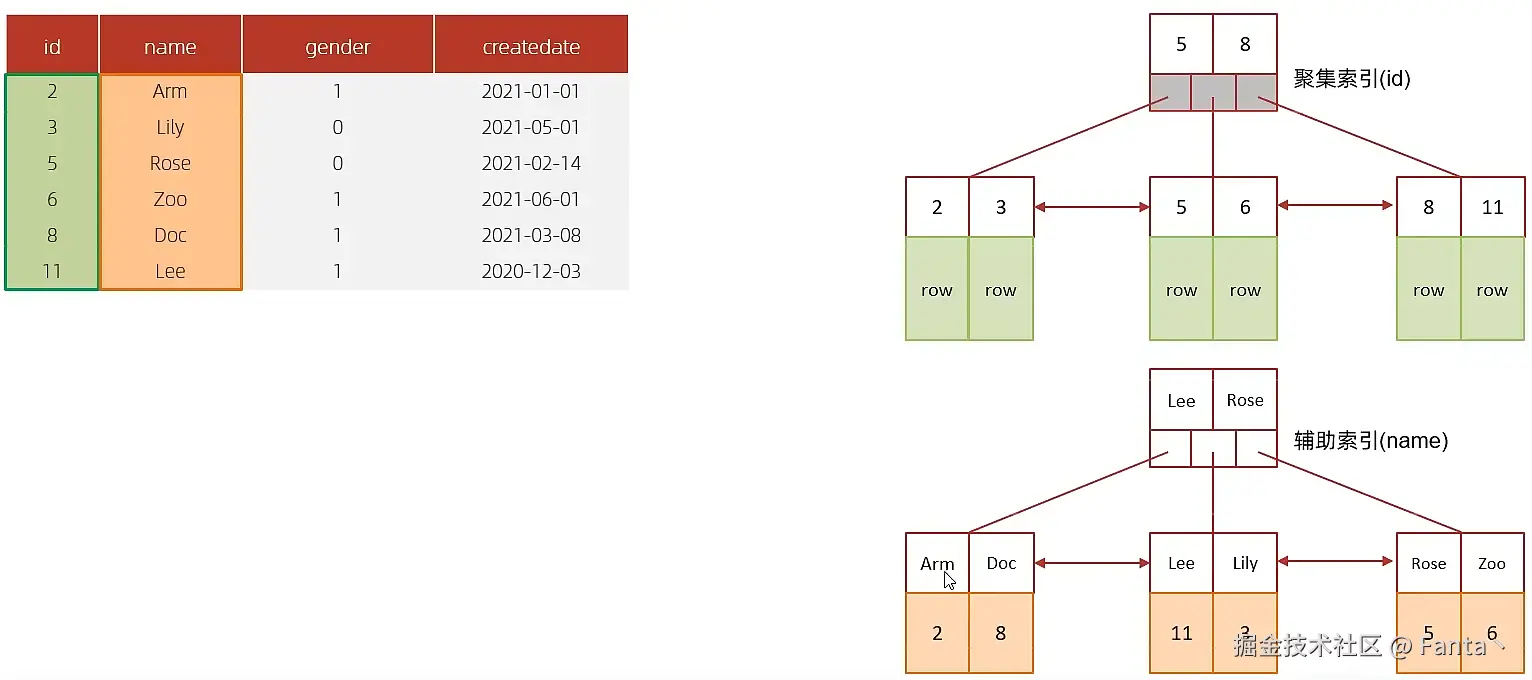
A.执行SQL : select * from tb_user where id = 2;
 根据id查询,直接走聚集索引查询,一次索引扫描,直接返回数据,性能高。
根据id查询,直接走聚集索引查询,一次索引扫描,直接返回数据,性能高。
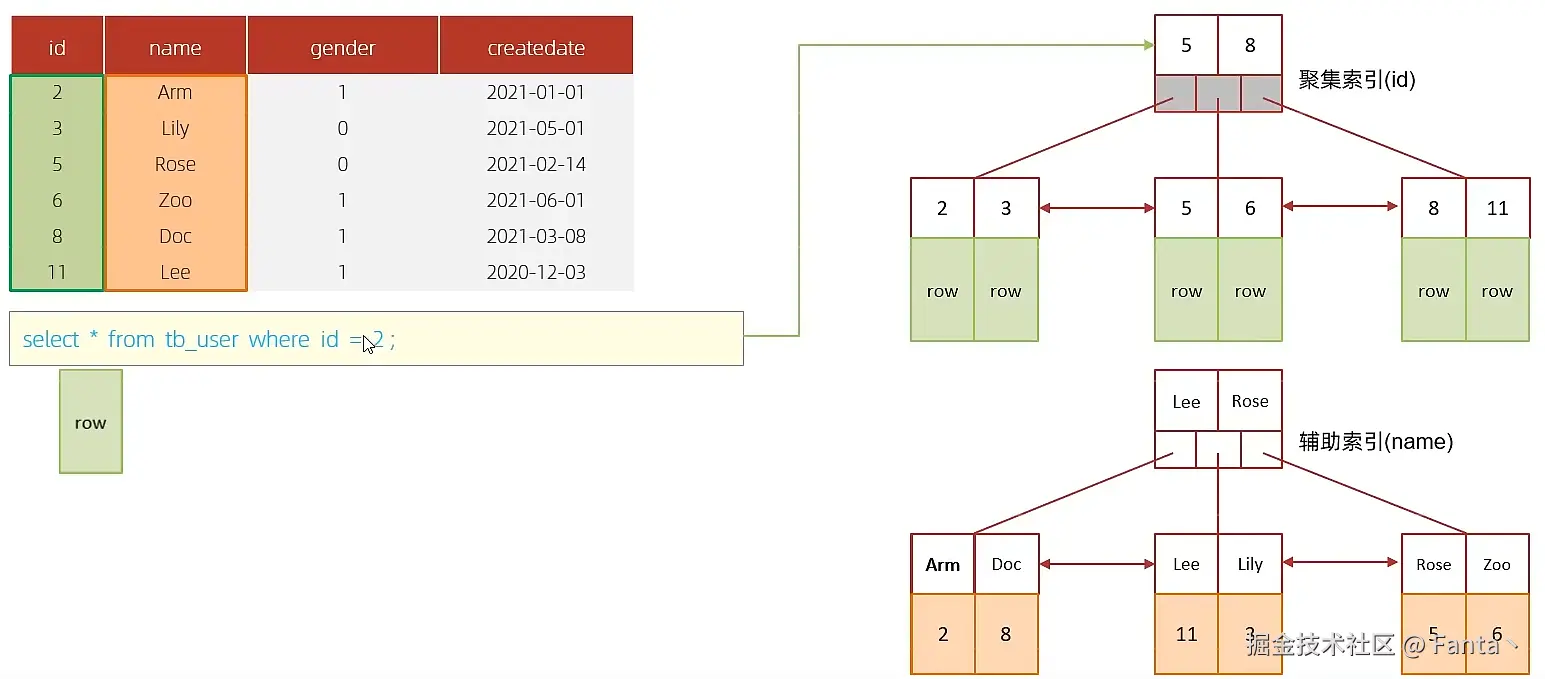
B.执行SQL:selet id,name from tb_user where name = 'Arm';
 虽然是根据name字段查询,查询二级索引,但是由于查询返回在字段为 id,name,在name的二级索引中,这两个值都是可以直接获取到的,因为覆盖索引,所以不需要回表查询,性能高。
虽然是根据name字段查询,查询二级索引,但是由于查询返回在字段为 id,name,在name的二级索引中,这两个值都是可以直接获取到的,因为覆盖索引,所以不需要回表查询,性能高。
C.执行SQL:selet id,name,gender from tb_user where name = 'Arm';
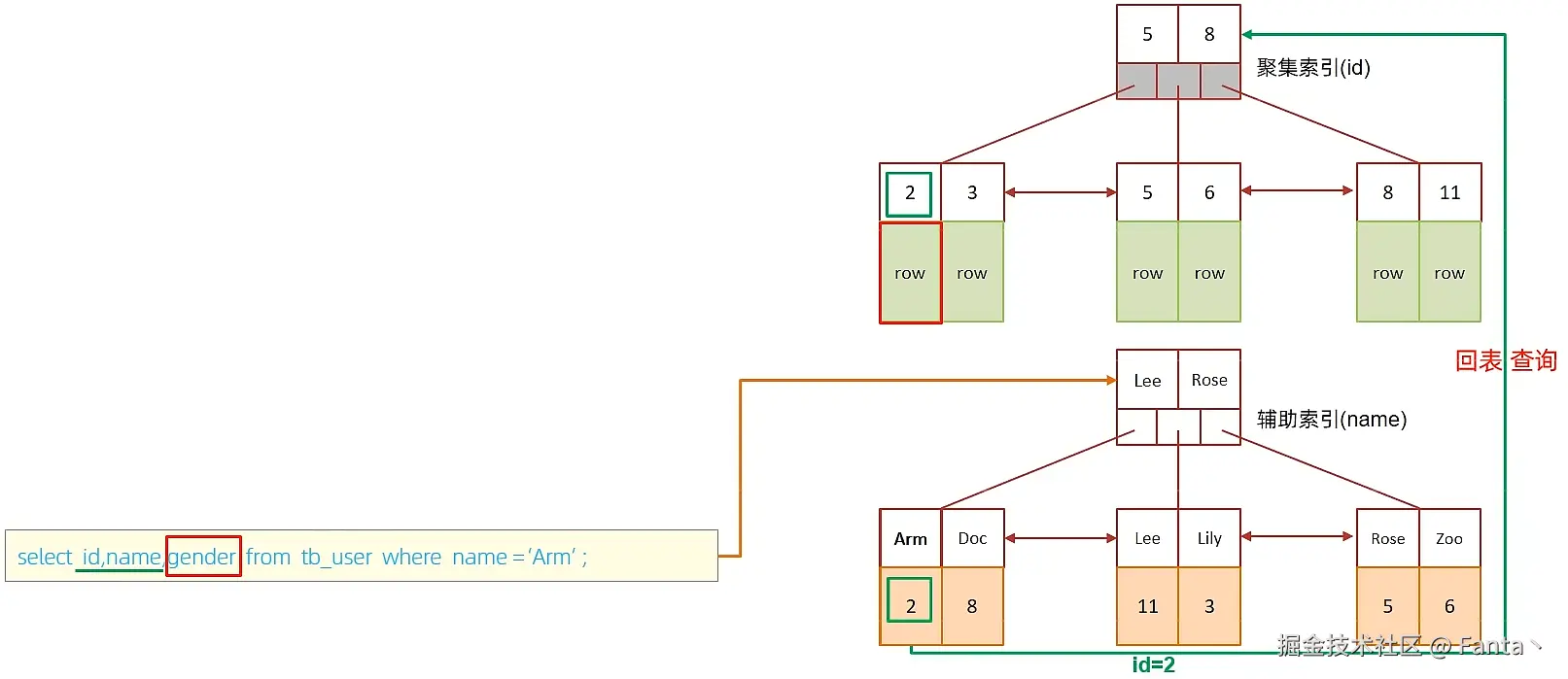 由于在name的二级索引中,不包含gender,所以,需要两次索引扫描,也就是需要回表查询,性能相对较差一点。
由于在name的二级索引中,不包含gender,所以,需要两次索引扫描,也就是需要回表查询,性能相对较差一点。
前缀索引
当字段类型为字符串(varchar,text,longtext等)时,有时候需要索引很长的字符串,这会让索引变得很大,查询时,浪费大量的磁盘IO, 影响查询效率。此时可以只将字符串的一部分前缀,建立索引,这样可以大大节约索引空间,从而提高索引效率。
1). 语法 create index idx_xxxx on table_name(column(n));
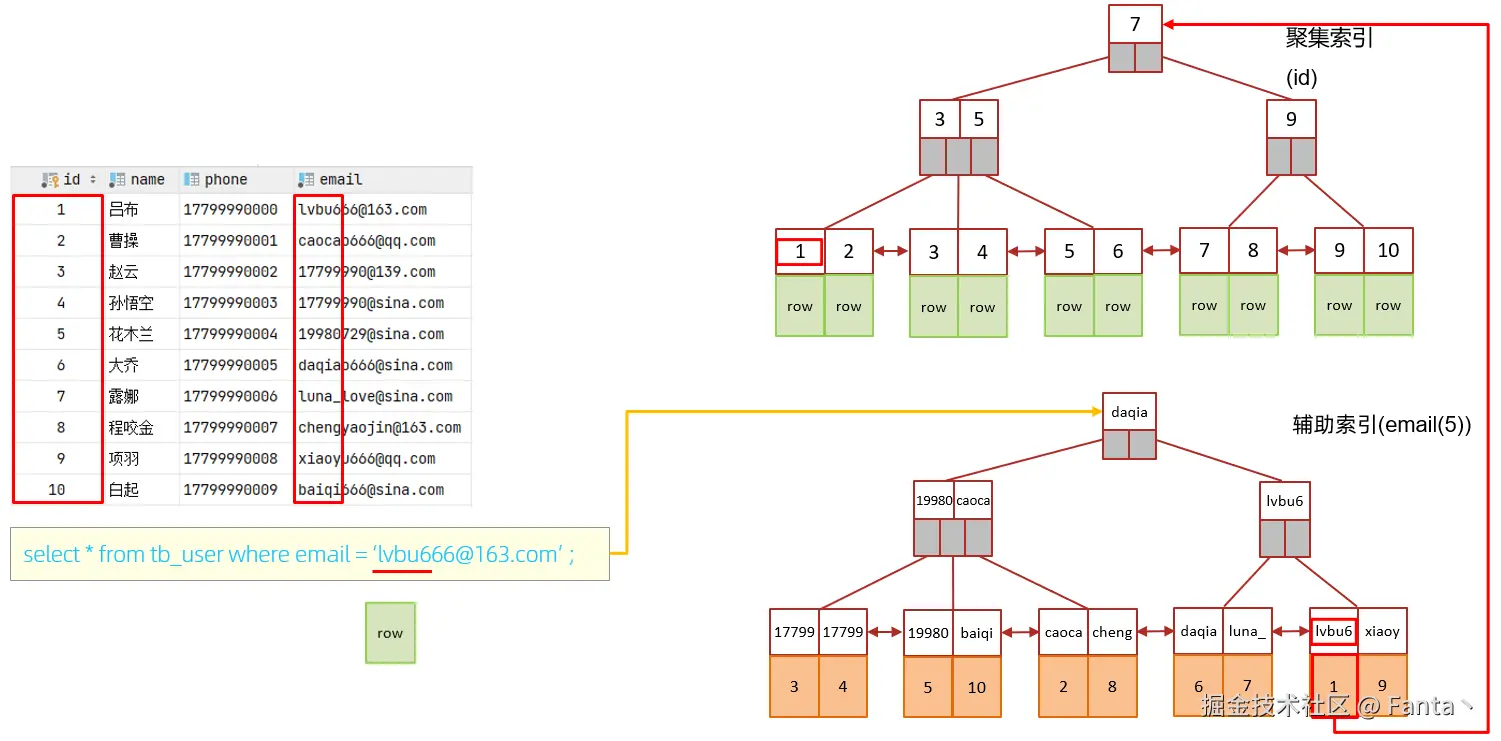
示例:为tb_user表的email字段,建立长度为5的前缀索引。
csharp
create index idx_email_5 on tb_user (email (5));idx_email_5的 Sbu_part 是5
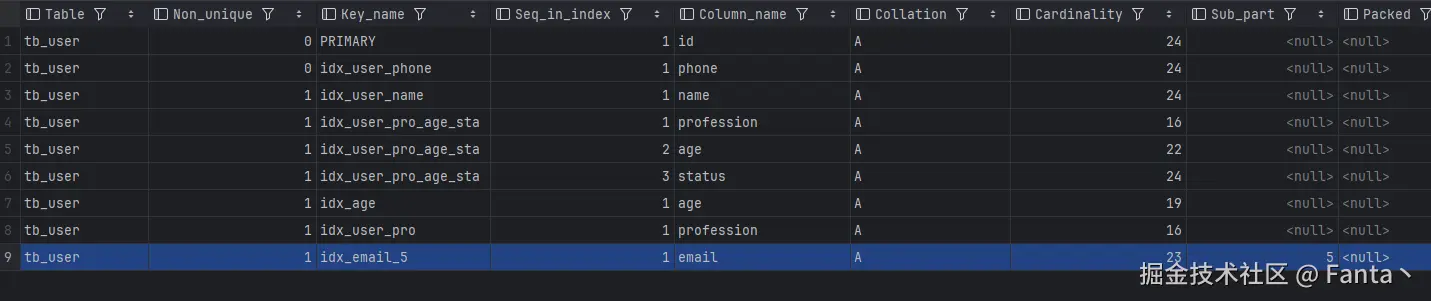
2). 前缀长度
可以根据索引的选择性来决定,而选择性是指不重复的索引值(基数)和数据表的记录总数的比值,索引选择性越高则查询效率越高, 唯一索引的选择性是1,这是最好的索引选择性,性能也是最好的。
sql
-- 去重之后的email数量 / 数据总量
select count (distinct email) / count (*) from tb_user ;
select count (distinct substring (email ,1 ,5)) / count (*) from tb_user ;3). 前缀索引的查询流程
索引设计原则 1). 针对于数据量较大,且查询比较频繁的表建立索引。
2). 针对于常作为查询条件(where)、排序(order by)、分组(group by)操作的字段建立索引。
3). 尽量选择区分度高的列作为索引,尽量建立唯一索引,区分度越高,使用索引的效率越高。
4). 如果是字符串类型的字段,字段的长度较长,可以针对于字段的特点,建立前缀索引。
5). 尽量使用联合索引,减少单列索引,查询时,联合索引很多时候可以覆盖索引,节省存储空间,避免回表,提高查询效率。
6). 要控制索引的数量,索引并不是多多益善,索引越多,维护索引结构的代价也就越大,会影响增删改的效率。
7). 如果索引列不能存储NULL值,请在创建表时使用NOT NULL约束它。当优化器知道每列是否包含 NULL值时,它可以更好地确定哪个索引最有效地用于查询。