最近在整理团队知识库。
一开始想法其实很朴素:我们已经有不少内部文档、项目记录、接口说明、会议纪要和经验总结,能不能把这些内容更好地共享给团队成员,甚至进一步给 Coding Agent 使用。
但真正开始做的时候,很快会发现这件事不是"把文档丢给 AI"这么简单。
知识库如果只是一个文件夹,最后大概率会变成另一个没人愿意翻的资料堆。
如果只是接一个大模型问答,也很容易遇到回答不稳定、上下文不完整、资料更新跟不上这些问题。
所以这段时间我专门补了一下相关方法论,主要是两个方向:
- 一个是大家更熟悉的 RAG
- 另一个是 Karpathy 提到的 LLM Wiki
这篇不是严格的论文解读,更像是一次阶段性学习记录。尽量用不那么技术化的方式,把我对这两件事的理解,以及后面可能会选择的一些工程化产品,整理一下。
为什么需要 RAG
RAG,全称是 Retrieval-Augmented Generation,通常翻译成"检索增强生成"。
我最早听到这个词,也是在大语言模型开始流行之后。
如果说得简单一点,RAG 解决的是这样一个问题:
大模型回答问题之前,能不能先去查一下资料。
我们平时直接使用大模型,它本质上是在依赖训练阶段形成的"记忆"和语言推理能力来回答问题。这个模式很强,但也有几个绕不开的问题。
第一个问题是,它可能会一本正经地胡说。
模型有时候会根据语言模式推一个看起来很像真的答案,但这个答案未必有依据。尤其是在一些具体业务、内部系统、历史项目上,它很容易把"像是这么回事"和"事实就是这样"混在一起。
第二个问题是,它不知道你的内部资料。
比如公司的产品文档、项目经验、接口说明、客户案例、内部流程,这些东西不会天然存在于模型里。就算模型能力再强,它也不可能凭空知道我们团队上个月才改过的一份设计文档。
第三个问题是,知识会过时。
公司制度会变,产品版本会变,项目进展会变,技术方案也会不断调整。模型训练时学到的东西,天然存在时间差。
RAG 的思路,就是在模型回答之前,先从知识库里检索一批相关资料,再把这些资料连同问题一起交给模型。
所以它更像是一个"会先翻资料,再回答问题的助手"。
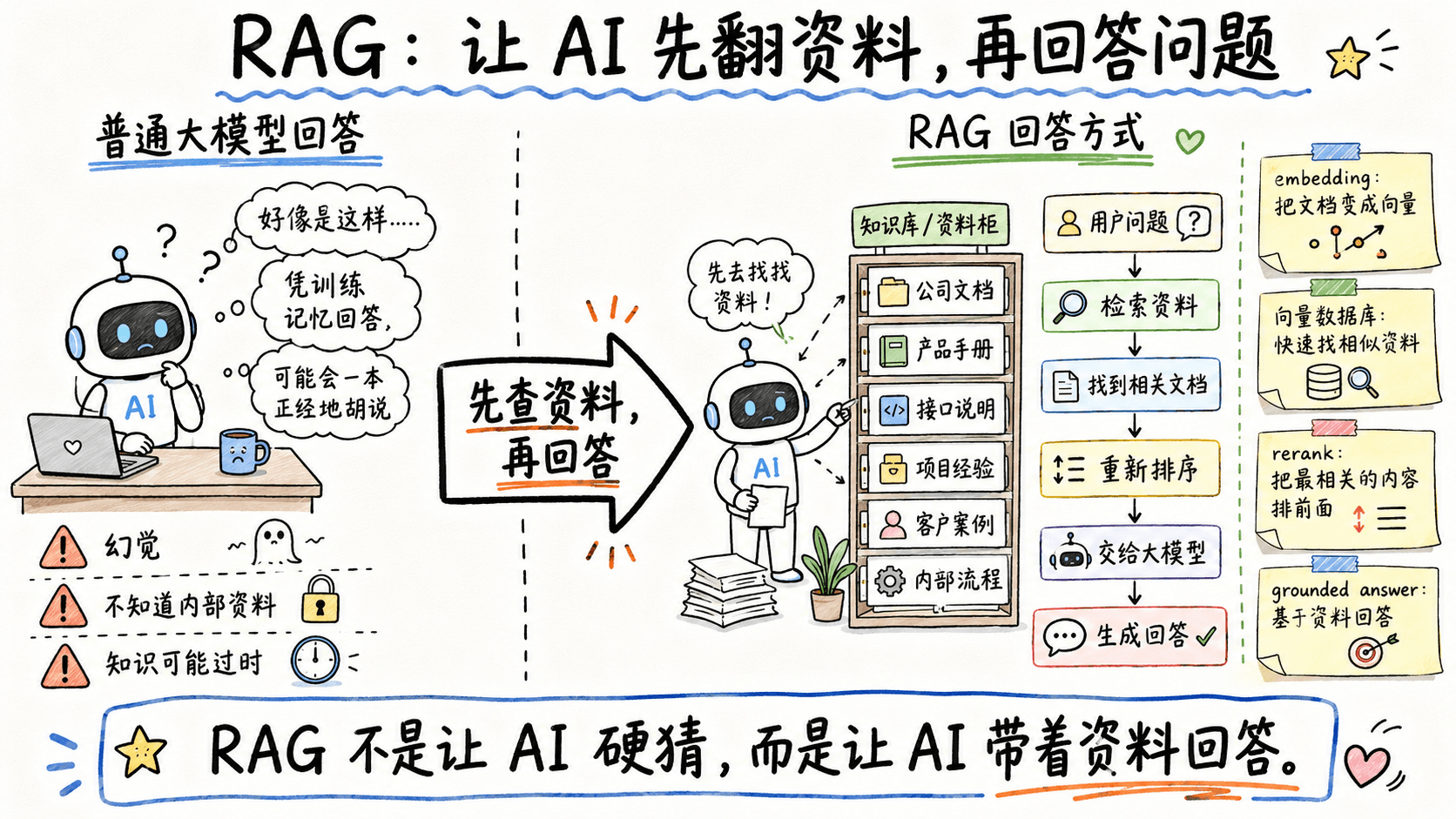
RAG 大概是怎么工作的
从工程上看,一个典型 RAG 流程大概会包含几步。
第一步是把文档切分。
因为一整篇文档直接丢给模型,既不现实,也不稳定。所以通常会先把文档按段落、标题、语义或者固定长度拆成很多小片段。
第二步是向量化,也就是常说的 embedding。
可以简单理解为:把文字转换成一组数字,让系统能够计算"这段话"和"这个问题"之间有多相关。
第三步是存入向量数据库。
这些向量化后的内容会被放到专门的数据库里,后面用户提问时,就可以快速找出最相近的文档片段。
第四步是检索和重排。
用户问一个问题后,系统先去知识库里搜相关内容。为了让结果更准,通常还会再做一层 rerank,也就是重新排序,把更可能有用的资料排到前面。
最后一步才是生成回答。
模型拿到用户问题和检索到的资料,再组织成自然语言回答。
这个过程听起来不复杂,但真正落地时会遇到很多细节问题:
- 文档怎么切,太碎会丢上下文,太长又会影响召回
- 向量模型怎么选,不同语言和场景效果差异很大
- 检索结果怎么排序,不能只靠相似度
- 权限怎么控制,不能谁都查到所有内部资料
- 资料怎么更新,不能新文档进来后知识库还是旧的
所以 RAG 看起来是"问答增强",但工程上其实是一整套知识检索和内容治理系统。
现在它被广泛用在 AI 客服、企业知识问答、内部文档助手这些场景里。对于团队知识库来说,它确实是一个很自然的起点。
但 RAG 不是全部
不过只靠 RAG,也会有一些问题。
最典型的是:RAG 更像是"问题来了,再去资料里查"。
这本身没问题,但如果原始资料本来就很散,结构也很乱,检索出来的内容就不一定好用。
比如我们经常会遇到这种情况:
- 同一个概念在不同文档里有多个叫法
- 项目背景散在会议纪要、需求文档和聊天记录里
- 某个技术方案改过几轮,但旧资料没有标记废弃
- FAQ 写在一篇长文下面,很难被准确召回
- 关键经验只存在某个人的总结里,没有进入体系
这时候即使接了 RAG,也只能在"混乱的资料堆"里尽量找答案。
它能缓解问题,但不一定能真正解决知识库长期维护的问题。
这也是我最近对 LLM Wiki 感兴趣的原因。
什么是 LLM Wiki
LLM Wiki 是 Karpathy 提到的一种知识库管理方法论。
原文可以看这里:Karpathy/llm-wiki。
我自己的理解是:
RAG 更关注怎么从资料中检索答案,LLM Wiki 更关注怎么把资料整理成一个可持续更新的知识体系。
也就是说,它不是等用户问问题时才去临时找材料,而是提前借助 LLM,把分散资料整理成一个 Wiki。
这个 Wiki 不是传统意义上靠人工一篇篇维护的百科,而是由 AI 帮忙读取资料、提炼重点、合并重复内容、建立页面和关联,再持续更新。
如果用更简单的话说:
RAG 像是"来问题了,我去仓库里帮你找几份资料"。
LLM Wiki 像是"我先把仓库整理成一个资料室,以后找东西就更有秩序"。
两者并不冲突,甚至可以结合起来。
LLM Wiki 的核心流程
LLM Wiki 的流程可以粗略拆成四步。
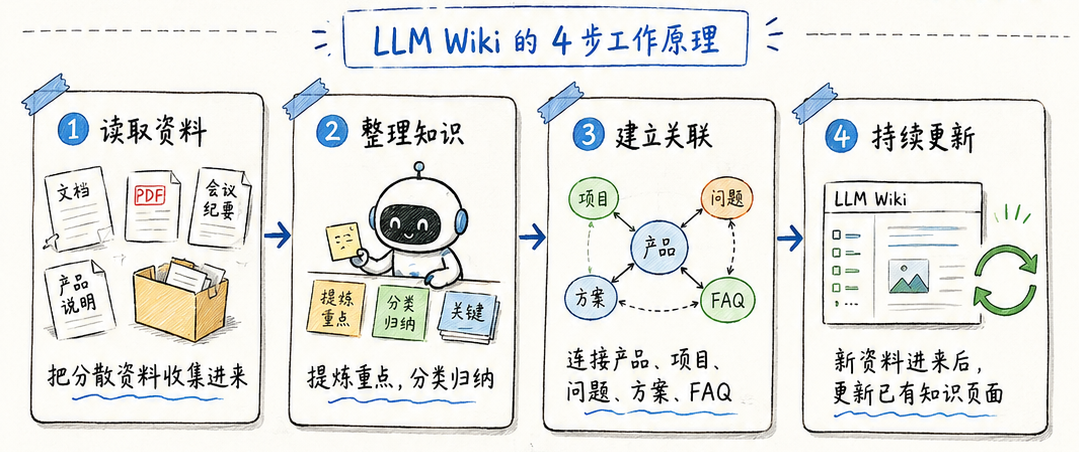
1. 读取资料
第一步还是读取原始资料。
这些资料可能来自:
- 产品文档
- 会议纪要
- 项目复盘
- 接口说明
- FAQ
- 代码仓库里的 README
- 甚至是聊天记录和工单
这一步和 RAG 很像,都是先让系统能接触到资料本身。
2. 整理知识
区别从这里开始变明显。
LLM Wiki 不只是把文档切块后存起来,而是会尝试提炼出结构化内容。
比如:
- 这个产品是什么
- 解决什么问题
- 有哪些核心模块
- 和哪些系统有关
- 之前做过哪些方案
- 当前版本有哪些限制
- 常见问题是什么
这些内容最终会变成 Wiki 页面,而不是一堆孤立的片段。
3. 建立关联
Wiki 真正有价值的地方,不只是页面本身,而是页面之间的关系。
比如:
- 某个产品依赖哪些服务
- 某个项目使用了哪些方案
- 某个问题在哪几个版本里出现过
- 某个接口影响了哪些业务流程
- 某个技术决策和哪些历史背景有关
这些关联一旦建立起来,知识库就不再只是"能搜索",而是开始有了结构。
对人来说,这有助于快速理解背景。
对 Agent 来说,这也很重要,因为它需要的不只是某个答案,而是一组可以支撑推理的上下文。
4. 持续更新
这一点我觉得尤其关键。
很多团队知识库失败,不是因为一开始没人写,而是因为后面没人维护。
新资料不断产生,旧资料没人归档,页面没人更新,最后大家还是回到问人、翻聊天记录、找历史文档。
LLM Wiki 的理想状态是:新资料进入系统后,不是简单追加一堆新文档,而是更新已有页面。
比如一次新的项目复盘进来,它应该能识别:
- 哪些内容是新增信息
- 哪些内容修正了旧结论
- 哪些内容应该进入 FAQ
- 哪些内容应该关联到某个产品或模块
- 哪些旧内容可能已经过期
如果能做到这一步,知识库才有机会变成一个长期演进的系统,而不是一次性的资料整理项目。
RAG 和 LLM Wiki 的关系
我现在更倾向于把它们看成两个层次。
RAG 是回答层。
它解决的是:用户问问题时,怎么从知识库里找到最相关的资料,并让模型基于资料回答。
LLM Wiki 是治理层。
它解决的是:团队资料怎么被整理、归档、关联、更新,最终沉淀成一个更适合人和 AI 使用的知识体系。
如果只有 RAG,可能会变成"对着一堆乱资料做搜索"。
如果只有 Wiki,没有好的检索和问答能力,使用门槛又会偏高。
所以更理想的状态,可能是两者结合:
- 用 LLM Wiki 把知识整理成结构化体系
- 用 RAG 在体系之上做检索和问答
- 再把结果提供给人,也提供给 Coding Agent
这样知识库就不只是"人查资料"的地方,也可以变成 Agent 工作时的上下文来源。
几个值得看的工程化产品
方法论之外,真正要落地,还是得看工程产品。
我最近主要关注了几个开源项目,后面团队知识库也可能会从这些里面选型或组合使用。
RAGFlow
RAGFlow 是一个偏完整产品形态的 RAG 引擎。
它比较适合用来做企业知识库问答,因为很多基础能力已经被产品化了,比如文档解析、知识库管理、问答界面、工作流等。
如果团队希望快速搭一个可用的知识问答系统,而不是从底层框架开始拼,RAGFlow 这种产品形态会比较友好。
但它也意味着系统复杂度会更高一些。部署、维护、权限、数据接入这些问题都需要认真评估。
LightRAG
LightRAG 更偏轻量,也更适合用来理解 RAG 和图谱增强检索的关系。
传统 RAG 很容易只停留在"文本片段相似度检索"上,而 LightRAG 这类方案会更强调知识之间的关联。
这对团队知识库很重要。
因为内部知识经常不是单点答案,而是"产品、项目、模块、问题、方案、负责人、历史决策"之间的一张网。
如果只做文本相似度,很多时候会查到相关片段,但不一定能串出完整背景。
LlamaIndex
LlamaIndex 更像是一个 AI 数据编排框架。
它不只是 RAG 产品,而是提供了一套把外部数据接入 LLM 应用的工具链。
如果要自己构建更灵活的知识库系统,比如接入不同数据源、设计自己的索引方式、组合多种检索策略,LlamaIndex 会更适合作为底层框架。
它的优点是灵活,缺点也是灵活。
对小团队来说,如果目标只是快速做出一个可用知识库,直接从 LlamaIndex 开始可能会偏重。但如果后面要做更深的定制,它是绕不开的参考对象。
GraphRAG
GraphRAG 是微软开源的一个方向,核心思路是把知识图谱引入 RAG。
它适合处理那种关系比较复杂、需要全局理解的问题。
比如你不是只想问"某个接口怎么用",而是想问:
- 这个项目为什么当初这么设计
- 哪些模块受这个方案影响
- 某类问题过去出现过几次
- 某个产品线的技术债主要集中在哪里
这类问题光靠局部片段检索,往往很难回答好。
GraphRAG 的价值就在于,它试图先抽取实体和关系,再基于图结构做更高层次的总结和推理。
当然,它的工程复杂度也会更高。不是所有团队一上来都需要 GraphRAG,但它代表了一个很值得关注的方向。
LLM Wiki
LLM Wiki 这类项目更贴近前面提到的 Wiki 化思路。
它关注的不是单次问答效果,而是怎么把资料整理成更长期可维护的页面。
从团队知识库角度看,我觉得这个方向很有价值。
因为我们真正缺的,往往不是"再多一个聊天入口",而是让已有知识从散落状态进入可维护状态。
如果一个系统能持续把会议纪要、项目文档、问题复盘整理成 Wiki 页面,再让 RAG 或 Agent 基于这些页面工作,那知识库的质量会比直接喂原始文档好很多。
我现在的倾向
如果只是做一个演示,RAG 很快就能出效果。
上传文档,提问,模型回答,看起来已经像一个知识库助手。
但如果目标是团队长期使用,我觉得不能只看第一周效果。
真正要评估的是:
- 新资料进来后,能不能被及时纳入
- 旧内容过期后,能不能被识别和修正
- 同一个概念能不能合并,而不是散在十篇文档里
- 权限边界能不能处理清楚
- Agent 使用时,能不能拿到稳定、干净、可追溯的上下文
所以我的初步判断是:
短期可以用 RAG 产品快速跑通问答,长期还是要往 LLM Wiki 或知识图谱化方向演进。
这不是为了追概念,而是因为团队知识本身就是持续变化的。
如果只做检索,不做治理,知识库迟早会重新变乱。
如果只做整理,不接问答和 Agent,又很难融入日常工作流。
最后
这次学习下来,我最大的感受是:
AI 时代的知识库,不应该只是一个"能被搜索的文档仓库",而应该是一个能持续整理、更新、关联,并能被人和 Agent 共同使用的知识系统。
RAG 解决的是"怎么查"。
LLM Wiki 解决的是"怎么沉淀"。
工程化产品解决的是"怎么真的跑起来"。
接下来如果团队要落地,我会更倾向于先从一个小范围场景开始,比如某个产品线、某个项目组,或者一组高频 FAQ。
先不要一上来追求全量覆盖。
因为知识库这件事,最怕的不是规模小,而是没人用、没人维护、没人相信它。
先让它在一个真实场景里回答得准、更新得动、能帮大家少问几次重复问题,这件事就已经很有价值了。