伪共享(False Sharing)是多线程编程中一个很容易被忽略,但在高并发场景下又可能非常致命的性能问题。
它最迷惑人的地方在于:从业务代码上看,多个线程并没有修改同一个变量,甚至每个线程都只操作属于自己的那份数据,理论上不应该发生竞争;但从 CPU 的视角看,这些变量可能刚好落在同一个缓存行里,于是一个线程修改自己的变量时,会导致其他 CPU 核心上的缓存行失效,最终引发大量无意义的缓存同步。
所以,伪共享不是"逻辑共享"导致的问题,而是"物理存储位置太近"导致的问题。
本文内容:
- 从现代处理器的缓存结构说起
- 缓存行为什么是 CPU 缓存的基本单位
- 什么是 CPU 缓存一致性
- 为什么缓存一致性会引出伪共享问题
- 用 Java 代码演示伪共享和缓存行填充
- 伪共享的常见解决方案
- 实际项目中该如何判断和取舍
CPU为什么需要缓存
在理解伪共享之前,我们要先理解一个基础问题:CPU 为什么需要缓存?
现代 CPU 的执行速度非常快,而内存相对 CPU 来说要慢很多。如果每一次读取变量、写入变量都直接访问主内存,那么 CPU 大部分时间都会浪费在等待内存数据返回上。为了缓解这个问题,CPU 和主内存之间会加入多级缓存,也就是我们常说的 L1、L2、L3 Cache。
一般来说,缓存层级可以简单理解为:
- L1 Cache:离 CPU 核心最近,速度最快,容量最小,通常每个核心独享
- L2 Cache:速度比 L1 慢一些,容量比 L1 大一些,很多处理器中也是每个核心独享
- L3 Cache:速度再慢一些,但容量更大,通常多个核心共享
- 主内存:容量最大,但访问延迟远高于 CPU Cache
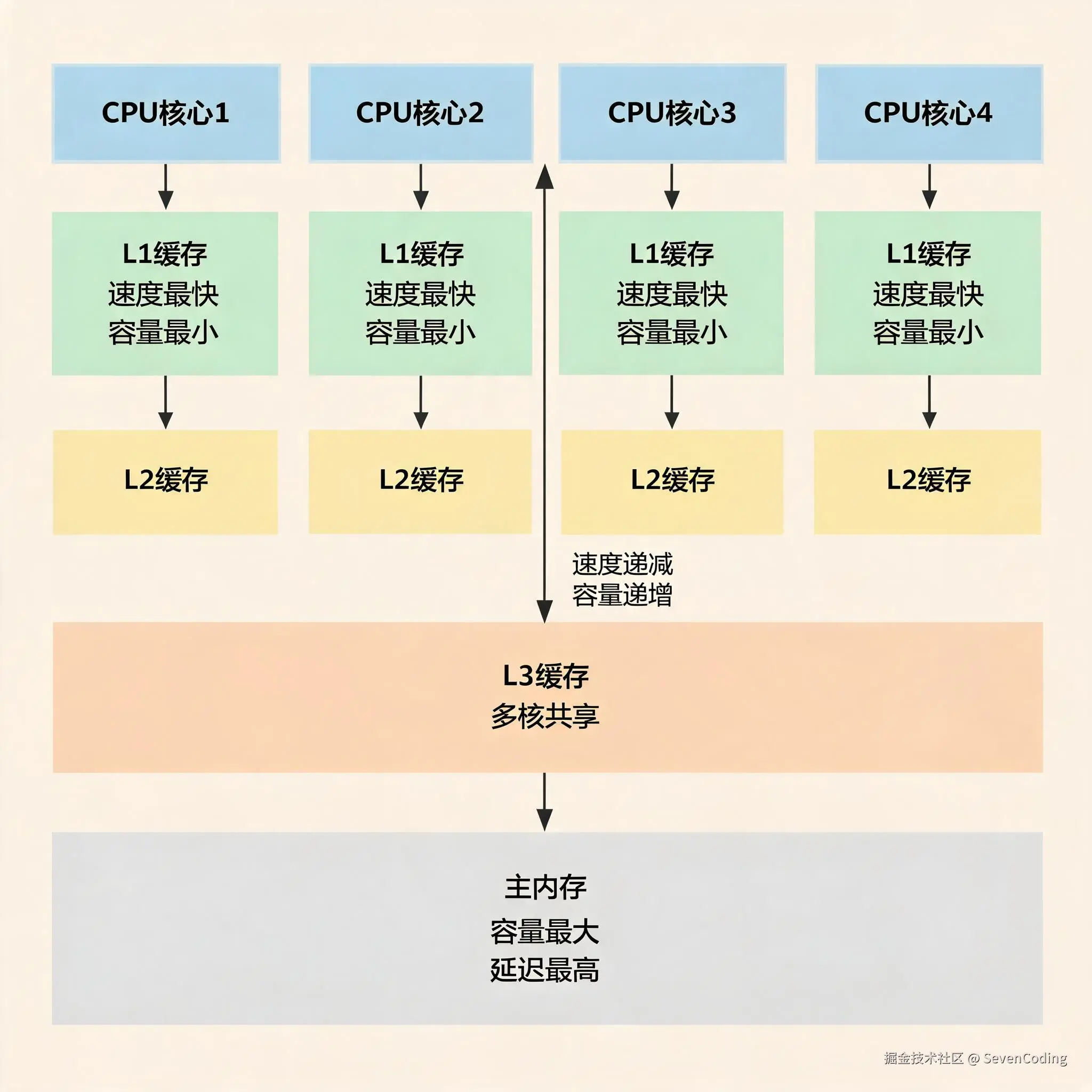
也就是说,一个变量并不是每次都从内存中直接读取。CPU 会尽量把最近访问过的数据放到缓存里,下次再访问相同数据或相邻数据时,就可以直接从缓存中拿到,速度会快很多。
这背后依赖两个很重要的局部性原理:
- 时间局部性:一个数据刚被访问过,后续很可能还会再次被访问
- 空间局部性:一个数据被访问时,它附近的数据也很可能会被访问
比如我们遍历一个数组:
java
for (int i = 0; i < arr.length; i++) {
sum += arr[i];
}CPU 读取 arr[0] 时,并不会只把 arr[0] 这几个字节加载到缓存里,而是会把它附近的一整块连续内存都加载进来。这样后续访问 arr[1]、arr[2] 时,大概率已经命中缓存,不需要再去主内存读取。
这个"一整块连续内存",就是接下来要讲的缓存行。
缓存行
在现代处理器中,缓存行(Cache Line)是 CPU Cache 和主内存之间进行数据交换的最小单位。主流 CPU 的缓存行大小通常是 64 字节。
注意这里的重点是"最小单位"。
假设有一个 long 类型变量,占 8 字节。当 CPU 需要读取这个 long 变量时,并不是只从主内存加载 8 字节,而是会把包含这个变量的一整个缓存行加载到 CPU Cache 中。如果缓存行大小是 64 字节,那么一次就会加载 64 字节。
比如内存中有一段连续的数据:
text
| long a | long b | long c | long d | long e | long f | long g | long h |一个 long 占 8 字节,8 个 long 正好占 64 字节。假设它们刚好处在同一个缓存行里,那么 CPU 访问 a 时,实际上会把 a 到 h 这一整段数据都加载到缓存里。
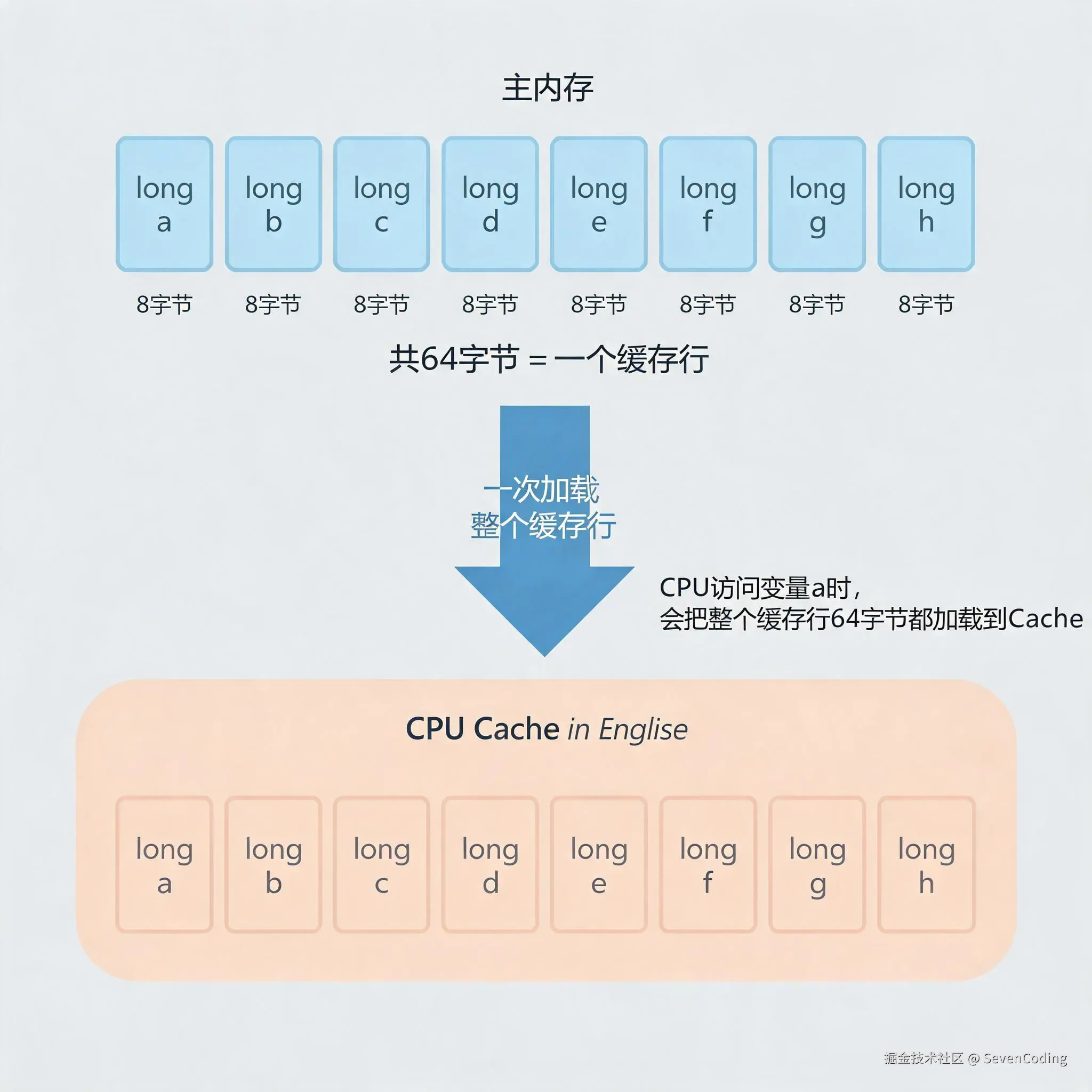
这样做大多数时候是有好处的。比如遍历数组时,CPU 预先加载相邻数据,可以显著提升访问效率。但凡事都有两面性:当多个线程在不同 CPU 核心上修改同一个缓存行里的不同变量时,问题就来了。
CPU缓存一致性是什么
现在考虑一个多核 CPU。每个核心都有自己的缓存,多个核心又共享同一块主内存。
如果只有读操作,一切都比较简单。多个核心都可以把同一份数据加载到各自的缓存里,大家读到的值一致即可。
但如果有写操作,问题就复杂了。
假设变量 x 的初始值为 1,线程 A 在 CPU Core 1 上运行,线程 B 在 CPU Core 2 上运行:
- Core 1 把
x = 1加载到自己的缓存中 - Core 2 也把
x = 1加载到自己的缓存中 - 线程 A 把
x修改为 2 - 线程 B 如果继续从自己的缓存中读取
x,是不是还会读到旧值 1?
为了避免不同核心看到的数据互相矛盾,CPU 需要一套机制来维护缓存之间的数据一致性,这就是 CPU 缓存一致性。
常见的一致性协议是 MESI,它把缓存行的状态大致分为下面几类:
| 状态 | 含义 |
|---|---|
| Modified | 当前缓存行被本核心修改过,数据和主内存不一致,其他核心没有有效副本 |
| Exclusive | 当前缓存行只被本核心持有,数据和主内存一致 |
| Shared | 当前缓存行可能被多个核心持有,数据和主内存一致 |
| Invalid | 当前缓存行已经失效,不能继续使用 |
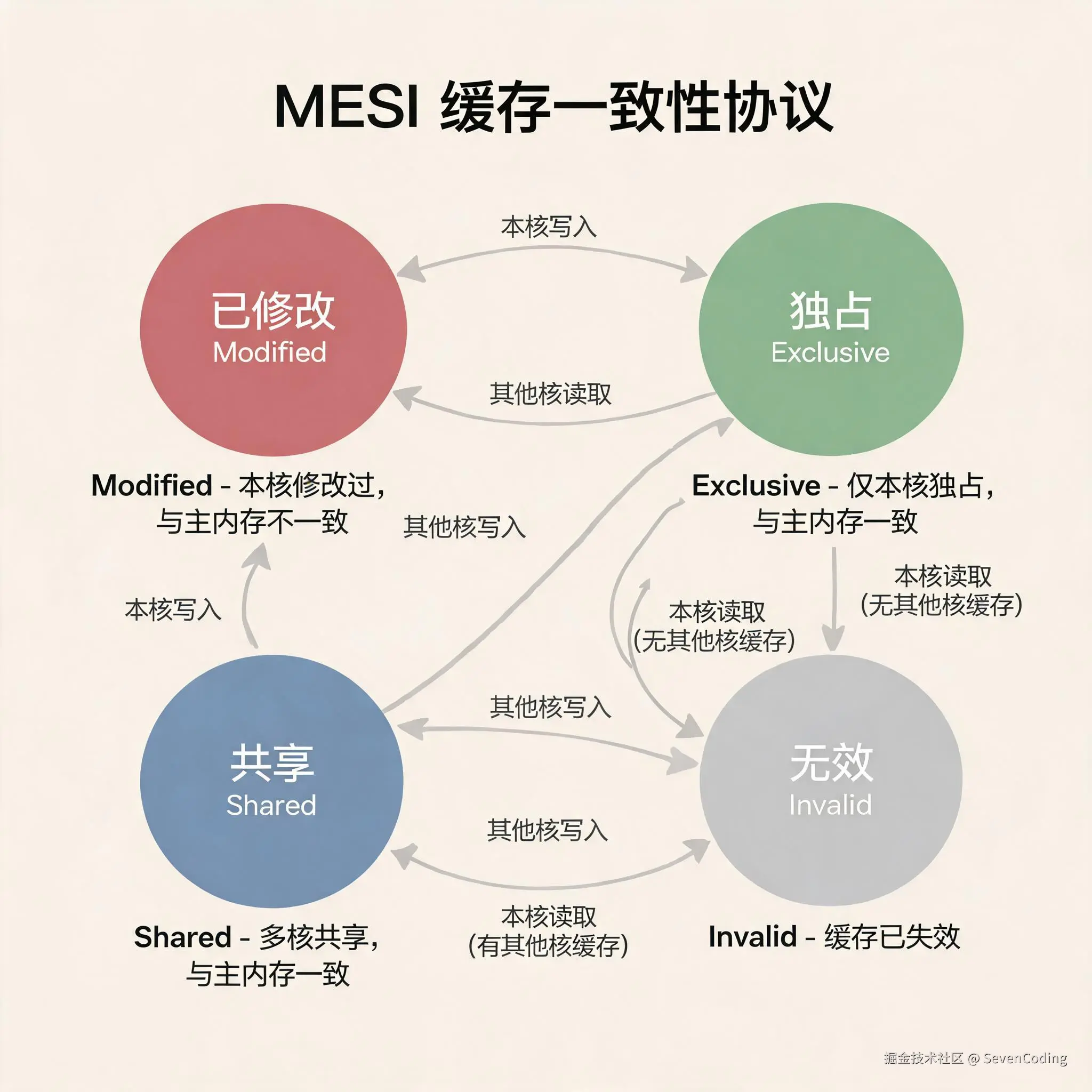
这里不需要把 MESI 的所有细节背下来,我们只要抓住一个关键点:CPU 维护一致性的单位不是某个 Java 字段,也不是某个 C 语言变量,而是缓存行。
也就是说,只要某个核心修改了一个缓存行中的任意一个字节,其他核心中同一个缓存行的副本就可能被标记为失效。
这句话就是理解伪共享的关键。
从缓存一致性到伪共享
现在我们构造一个场景。
有两个线程,分别运行在两个 CPU 核心上:
- 线程 A 只修改变量
a - 线程 B 只修改变量
b - 从业务逻辑上看,
a和b是两个完全不同的变量 - 但从内存布局上看,
a和b刚好落在同一个缓存行中
它可能长这样:
text
同一个缓存行(64字节)
+---------------------------------------------------------------+
| a | b | 其他数据 |
+---------------------------------------------------------------+
^ ^
线程A 线程B此时会发生什么?
- 线程 A 修改
a,Core 1 获得这个缓存行的写权限 - Core 2 上相同缓存行的副本被标记为 Invalid
- 线程 B 修改
b,发现自己的缓存行失效,只能重新加载并获得写权限 - Core 1 上相同缓存行的副本又被标记为 Invalid
- 线程 A 下一次修改
a,又要重新加载这个缓存行
两个线程明明没有修改同一个变量,却在缓存行层面互相"打扰"。这种因为不同变量共享同一个缓存行而导致的无意义缓存失效,就是伪共享。
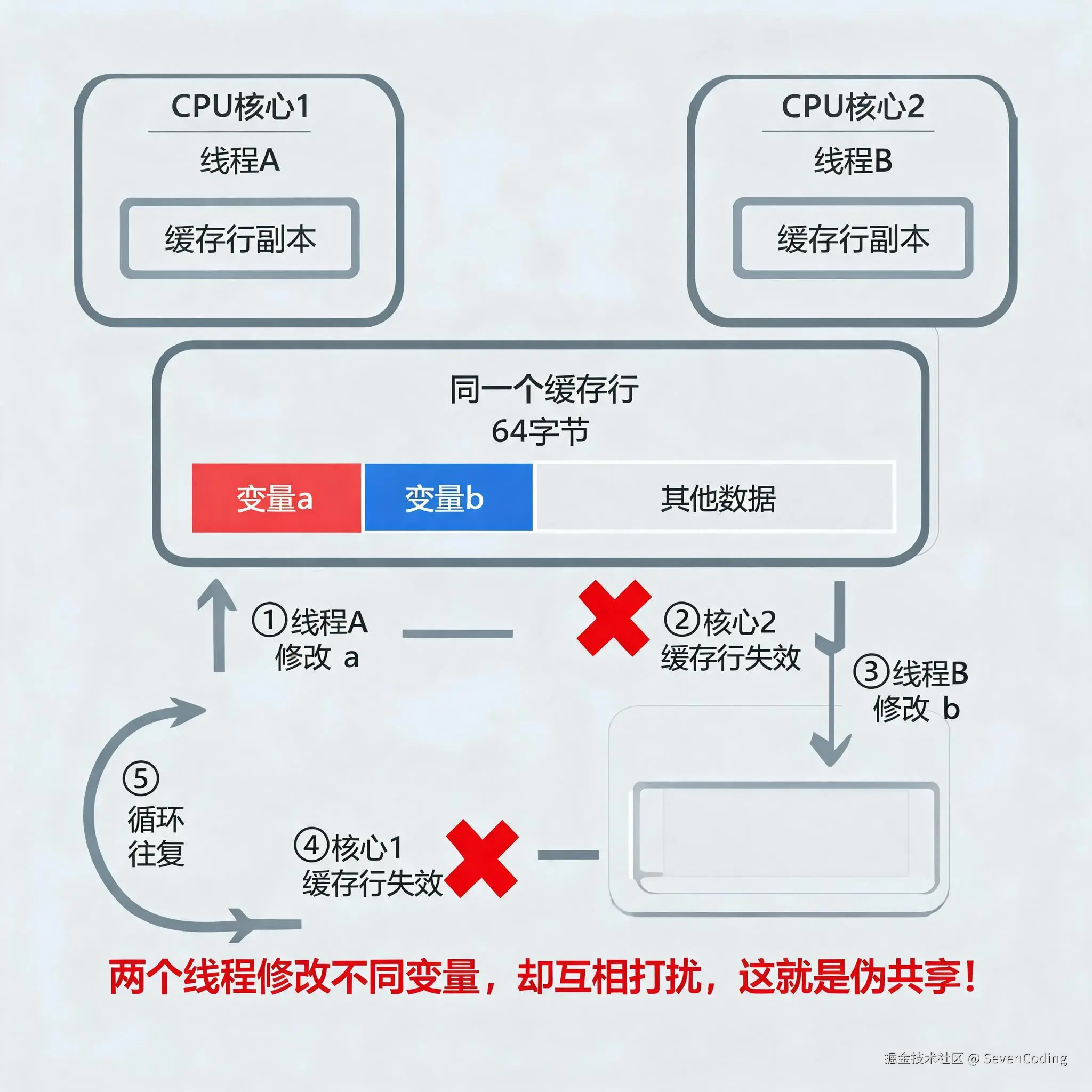
它之所以叫"伪共享",是因为从程序语义上看没有共享冲突,但从 CPU 缓存行的角度看,它们确实共享了同一个缓存行。
伪共享为什么会影响性能
伪共享带来的性能损耗,主要来自下面几个方面。
第一,缓存行频繁失效。
一个线程刚把数据加载到自己的缓存里,另一个线程一写,当前线程的缓存行就失效了。下一次再访问时,不能直接使用本地缓存,只能重新拉取。
第二,缓存一致性通信增加。
多核 CPU 为了维护缓存一致性,需要在核心之间传递失效、同步、所有权转移等消息。如果多个核心不断争夺同一个缓存行,核心间通信成本会变得很高。
第三,CPU 流水线可能被迫等待。
CPU 执行指令很快,但一旦等待缓存行重新加载或等待写权限,就会出现停顿。对于高频循环、计数器、队列游标这类代码来说,这种停顿会被放大得非常明显。
第四,代码层面很难一眼看出来。
锁竞争、CAS 失败、阻塞等待通常比较容易从代码或监控里看到,但伪共享隐藏在内存布局中。代码上看起来每个线程都只操作自己的字段,甚至没有锁,也没有共享写同一个变量,但性能就是上不去。
Java中的伪共享示例
下面用一个常见例子来模拟伪共享。我们准备一个数组,数组里有多个对象,每个线程只修改自己对应对象中的 value 字段。
先看不做填充的版本:
java
public class FalseSharingExample implements Runnable {
public static final int NUM_THREADS = 4;
public static final long ITERATIONS = 500_000_000L;
private static PlainValue[] values;
private final int arrayIndex;
public FalseSharingExample(int arrayIndex) {
this.arrayIndex = arrayIndex;
}
public static void main(String[] args) throws InterruptedException {
values = new PlainValue[NUM_THREADS];
for (int i = 0; i < values.length; i++) {
values[i] = new PlainValue();
}
Thread[] threads = new Thread[NUM_THREADS];
long start = System.nanoTime();
for (int i = 0; i < threads.length; i++) {
threads[i] = new Thread(new FalseSharingExample(i));
}
for (Thread thread : threads) {
thread.start();
}
for (Thread thread : threads) {
thread.join();
}
System.out.println("Duration = " + (System.nanoTime() - start));
}
@Override
public void run() {
long i = ITERATIONS + 1;
while (0 != --i) {
values[arrayIndex].value = i;
}
}
public static class PlainValue {
public volatile long value = 0L;
}
}这里每个线程操作的是不同的 PlainValue 对象,看起来不存在共享写同一个变量的问题。但由于多个对象在堆上可能分配得比较接近,这些 value 字段仍然可能落在同一个缓存行,最终出现伪共享。
为什么 value 要加 volatile?
这里的 volatile 不是为了制造伪共享,而是为了避免 JIT 编译器把循环中的写操作优化掉。因为这个例子本身没有复杂业务,只是不断写变量,如果不加 volatile,基准测试结果可能失真。
使用缓存行填充解决
一个直接的思路是:既然问题来自多个热点变量落在同一个缓存行,那就让每个热点变量尽量独占一个缓存行。
可以通过填充字段来实现:
java
public class FalseSharingPaddingExample implements Runnable {
public static final int NUM_THREADS = 4;
public static final long ITERATIONS = 500_000_000L;
private static PaddingValue[] values;
private final int arrayIndex;
public FalseSharingPaddingExample(int arrayIndex) {
this.arrayIndex = arrayIndex;
}
public static void main(String[] args) throws InterruptedException {
values = new PaddingValue[NUM_THREADS];
for (int i = 0; i < values.length; i++) {
values[i] = new PaddingValue();
}
Thread[] threads = new Thread[NUM_THREADS];
long start = System.nanoTime();
for (int i = 0; i < threads.length; i++) {
threads[i] = new Thread(new FalseSharingPaddingExample(i));
}
for (Thread thread : threads) {
thread.start();
}
for (Thread thread : threads) {
thread.join();
}
System.out.println("Duration = " + (System.nanoTime() - start));
}
@Override
public void run() {
long i = ITERATIONS + 1;
while (0 != --i) {
values[arrayIndex].value = i;
}
}
public static class PaddingValue {
protected long p1, p2, p3, p4, p5, p6, p7;
public volatile long value = 0L;
protected long p9, p10, p11, p12, p13, p14, p15;
}
}一个 long 占 8 字节,7 个 long 就是 56 字节。value 本身占 8 字节,前后各填充 56 字节,可以让 value 周围隔出足够大的空间,降低不同对象中的热点字段落在同一个缓存行的概率。

这个思路并不复杂:
- 原来多个线程修改的热点字段可能挤在同一个缓存行中
- 现在通过无意义字段把热点字段隔开
- 每个线程修改自己的
value时,不容易影响其他线程的缓存行
不过需要注意,Java 对象在内存中的真实布局还会受到对象头、字段重排、压缩指针、JVM 实现等因素影响,所以手工填充并不是一种绝对精确的方式。它是利用空间换时间,在很多高性能框架中都能看到类似思想。
使用@Contended解决
从 Java 8 开始,JDK 提供了 @Contended 注解,可以用来减少伪共享。
示例:
java
import jdk.internal.vm.annotation.Contended;
public class ContendedExample {
@Contended
public volatile long value;
}不过这个注解有几个注意点。
首先,@Contended 在 JDK 内部使用较多,比如一些高性能并发类会用它隔离热点字段。
其次,如果我们在自己的业务代码中使用它,通常需要加 JVM 参数:
shell
-XX:-RestrictContended否则对于非 JDK 内部类,这个注解可能不会生效。
另外,在 JDK 9 之后,@Contended 所在包涉及模块访问限制。如果直接使用 jdk.internal.vm.annotation.Contended,还可能需要额外的编译或运行参数。因此在普通业务项目中,不建议一上来就依赖它。更常见的做法是:只有当已经定位到伪共享确实是瓶颈时,再考虑使用 @Contended 或者手工填充。
更换数据结构
除了填充字段,还有一种更工程化的思路:从数据结构设计上减少多个线程对相邻热点数据的写入。
比如有一个全局计数器:
java
public class Counter {
private final AtomicLong count = new AtomicLong();
public void increment() {
count.incrementAndGet();
}
}如果很多线程同时更新同一个 AtomicLong,这里的问题已经不只是伪共享了,而是真共享。所有线程都在竞争同一个变量,CAS 会不断失败,缓存行也会在多个核心之间来回转移。
这时可以使用分段思想,把一个计数器拆成多个槽:
java
public class StripedCounter {
private final LongAdder counter = new LongAdder();
public void increment() {
counter.increment();
}
public long sum() {
return counter.sum();
}
}LongAdder 的核心思想就是在竞争激烈时,把更新分散到多个 Cell 上,最后求和时再汇总。这既减少了对单个变量的竞争,也会通过内部填充等方式降低伪共享带来的影响。
所以在实际项目里,如果只是做高并发计数,不一定要自己手写填充类,优先考虑 JDK 已经提供的并发工具,比如:
LongAdderLongAccumulatorConcurrentHashMap- Disruptor 这类成熟高性能队列框架
这些工具背后已经考虑了大量并发性能细节,通常比自己随手写一个数组加 CAS 更可靠。
什么时候容易出现伪共享
伪共享并不是所有并发程序都会遇到。它通常出现在下面这些场景中:
- 多个线程频繁写不同变量
- 这些变量在内存中相邻
- 写入频率非常高,比如循环计数、状态位、队列游标
- 变量属于性能关键路径
- 程序运行在多核机器上,并且线程确实并行执行
典型例子包括:
- 高性能队列中的生产者、消费者游标
- 多线程统计中的分片计数器
- RingBuffer 中的序号字段
- 批量任务中每个工作线程维护的进度字段
- 自研并发组件中的状态数组
反过来说,如果一个变量一天只改几次,或者代码本身主要瓶颈在数据库、网络、磁盘 IO 上,那么伪共享通常不是你应该优先关注的问题。优化要看瓶颈在哪里,不能因为伪共享听起来高级,就到处加填充字段。
如何判断是不是伪共享
伪共享的排查一般不靠肉眼猜,而是结合压测和性能分析。
可以从以下几个方向入手。
第一,看代码模式。
如果你发现多个线程分别更新数组中相邻元素,或者分别更新多个对象中位置相近的 volatile long、AtomicLong、状态字段,那么就可以怀疑是否存在伪共享。
第二,做对比实验。
可以保留原始版本,再写一个填充版本,在相同机器、相同线程数、相同参数下进行多轮测试。如果填充后性能明显提升,说明伪共享很可能是重要原因之一。
第三,使用更严谨的基准测试工具。
Java 中推荐使用 JMH,而不是简单地用 System.nanoTime() 跑一次就下结论。因为 JVM 有 JIT 编译、逃逸分析、锁消除、死代码消除、分层编译等优化,普通 main 方法很容易测出误导性的结果。
一个简单的 JMH 思路是:
- 准备未填充的数据结构
- 准备填充后的数据结构
- 固定线程数进行多轮写入测试
- 对比吞吐量和平均耗时
第四,结合硬件性能计数器。
在 Linux 环境下,可以使用 perf 等工具观察缓存未命中、缓存一致性相关事件。不过这类工具需要一定硬件和系统知识,普通业务开发中不一定会用到。很多时候,通过代码模式和对比压测已经能定位大方向。
解决伪共享的常见方案
总结下来,解决伪共享通常有以下几类方式。
填充字段
这是最直接的方式,通过增加无意义字段,让热点变量尽量分布在不同缓存行中。
优点是简单直接,适合自己实现高性能组件时使用。
缺点是浪费内存,并且和 JVM 对象布局有关,不够优雅。
使用@Contended
@Contended 可以让 JVM 帮我们做隔离,语义上比手写 p1、p2 这类字段更清晰。
优点是表达明确,避免手工填充代码污染业务含义。
缺点是需要 JVM 参数支持,而且在不同 JDK 版本下使用方式可能有差异。
拆分热点字段
如果一个对象里有多个字段分别由不同线程频繁写入,可以考虑把它们拆到不同对象中,让内存布局更容易隔离。
比如原来是:
java
public class TaskState {
volatile long producerIndex;
volatile long consumerIndex;
}可以根据实际情况拆成:
java
public class ProducerState {
volatile long producerIndex;
}
public class ConsumerState {
volatile long consumerIndex;
}当然,这不是说所有字段都应该拆。只有当这些字段确实分别被不同线程高频写入,并且已经成为性能瓶颈时,拆分才有意义。
使用成熟并发类
如果需求是计数、累加、并发映射、任务队列,优先使用成熟类库。比如 LongAdder 就比单个 AtomicLong 更适合高并发累加场景。
这类工具的价值在于,它们不只解决伪共享,还会综合处理 CAS 竞争、扩容、内存可见性、并发安全等一系列问题。
减少共享写
从更高层看,最好的优化往往不是"让共享更快",而是"减少共享"。
比如:
- 每个线程先写本地变量,最后统一汇总
- 每个线程维护自己的分片数据
- 批量更新,减少高频写共享状态
- 使用消息传递代替多个线程同时改状态
这种方式通常比单纯填充字段更符合工程设计,也更容易长期维护。
伪共享和真共享的区别
这里顺便区分一下伪共享和真共享。
真共享是多个线程确实在读写同一个变量。比如多个线程同时更新同一个 AtomicLong,这是真正的数据竞争或同步竞争。
伪共享是多个线程读写不同变量,但这些变量落在同一个缓存行中,导致缓存行层面发生竞争。
可以这样理解:
| 类型 | 线程是否操作同一个变量 | 是否竞争同一个缓存行 | 例子 |
|---|---|---|---|
| 真共享 | 是 | 是 | 多线程更新同一个计数器 |
| 伪共享 | 否 | 是 | 多线程更新相邻的多个计数器 |
| 无共享 | 否 | 否 | 每个线程更新独立缓存行中的变量 |
真共享通常需要从算法或数据结构上减少同一个变量的竞争。伪共享则更多是内存布局问题,可以通过填充、隔离、拆分字段来优化。
一个容易误解的点
很多人第一次学习伪共享时,会以为"只要多个线程操作不同对象,就不会有伪共享"。这个理解是不准确的。
Java 中的对象虽然是不同对象,但对象最终还是分配在堆内存里。如果多个小对象分配得比较连续,它们的热点字段仍然可能位于相邻位置,甚至落在同一个缓存行里。
还有人会认为"加了 volatile 才会有伪共享"。这也不准确。
伪共享的根因是缓存行共享,而不是 volatile。只是 volatile 字段通常更容易出现在并发状态同步中,而且写 volatile 会带来内存可见性和有序性约束,更容易暴露缓存一致性成本。所以很多演示伪共享的例子都会使用 volatile long。
总结
伪共享的本质是:多个线程虽然操作的是不同变量,但这些变量落在同一个缓存行中。由于 CPU 缓存一致性以缓存行为单位工作,一个线程修改其中一个变量时,会导致其他核心中同一个缓存行的副本失效,最终造成大量无意义的缓存同步和缓存重新加载。
理解伪共享,要抓住三点:
- CPU Cache 不是按变量加载数据,而是按缓存行加载数据
- 缓存一致性不是按字段维护状态,而是按缓存行维护状态
- 多线程高频写不同变量时,如果变量落在同一个缓存行,就可能互相影响
解决伪共享时,也不要一上来就盲目填充。更合理的顺序是:先确认性能瓶颈,再通过压测或 JMH 做对比,最后根据场景选择填充字段、@Contended、拆分数据结构、使用 LongAdder 或减少共享写。
对于普通业务系统来说,伪共享不一定是最优先的问题;但对于高性能队列、并发计数器、任务调度器、内存型中间件这类场景,它往往就是影响吞吐量的关键细节。