很多 Java 开发者写过无数次 try-catch-finally,也知道异常会打印一串调用栈。但如果继续往下问:catch 在字节码里长什么样?finally 为什么"总会执行"?javap 输出里的 any 到底是什么?为什么异常对象的创建成本比普通对象高?这些问题就开始触到 JVM 的实现层了。
这篇文章想讲清楚一件事:Java 异常不是简单的错误提示,而是 JVM 支持的一套非正常控制流转移机制。
一、异常体系:checked 和 unchecked 到底检查什么?
Java 里的异常处理由两个动作组成:抛出异常 和捕获异常。抛出异常可以是应用程序主动做的,例如:
java
throw new RuntimeException("something wrong");也可以是 JVM 在执行字节码时被迫做的,例如数组下标非法时自动抛出 ArrayIndexOutOfBoundsException。从执行路径上看,异常会让程序从"正常路径"切换到"异常路径"。所以异常不能只理解成日志或者错误消息,日志只是结果,真正重要的是:程序控制流已经被改道了。
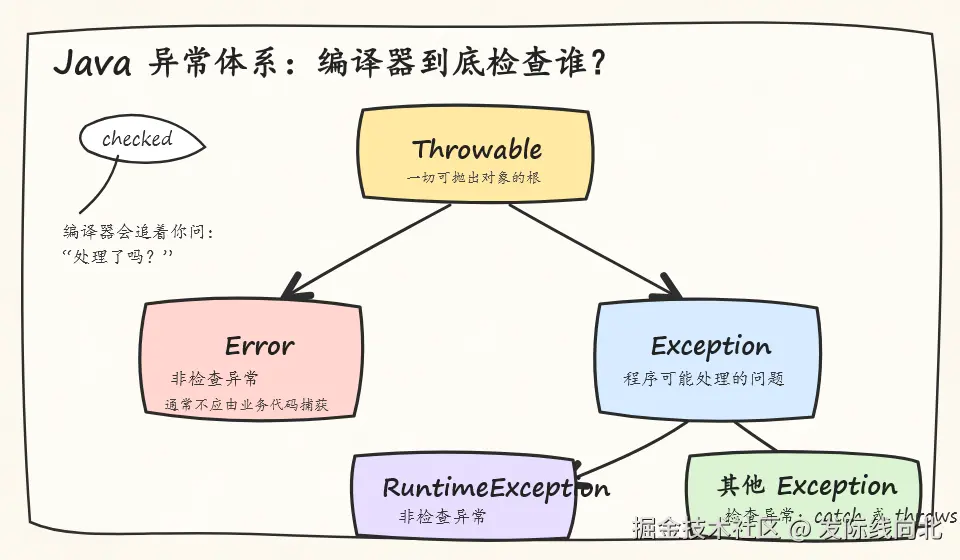
Java 中所有可抛出的对象都继承自 Throwable。它下面有两个重要分支:Error 和 Exception。Error 通常表示程序不应该捕获的问题;Exception 表示程序可能需要处理的问题;而 RuntimeException 是 Exception 的特殊子类,通常表示运行时才能暴露的程序错误或业务异常。
Java 又把异常分为 checked 和 unchecked:Error、RuntimeException 及其子类属于 unchecked exception;除 RuntimeException 外的其他 Exception 属于 checked exception。所谓 checked,不是说异常只在编译期发生,而是指编译器会检查你有没有显式处理它 。例如 IOException 要么 catch,要么在方法签名上 throws;但 NullPointerException、IllegalArgumentException 这类异常,编译器不会强制你提前处理。
二、栈轨迹:为什么异常对象比普通对象更贵?
很多人说"异常性能差",但这句话太粗。更准确地说,异常的成本主要来自两个方面:
- 第一,异常对象构造时可能生成栈轨迹;
- 第二,异常发生后 JVM 需要沿异常表和调用栈寻找处理器。
当我们写:
java
throw new RuntimeException("boom");JVM 不只是分配一个对象。构造异常实例时,通常会收集当前线程的 Java 调用栈,把类名、方法名、文件名、行号等调试信息记录下来,最终形成我们熟悉的 at Demo.dao(Demo.java:18) 这类输出。
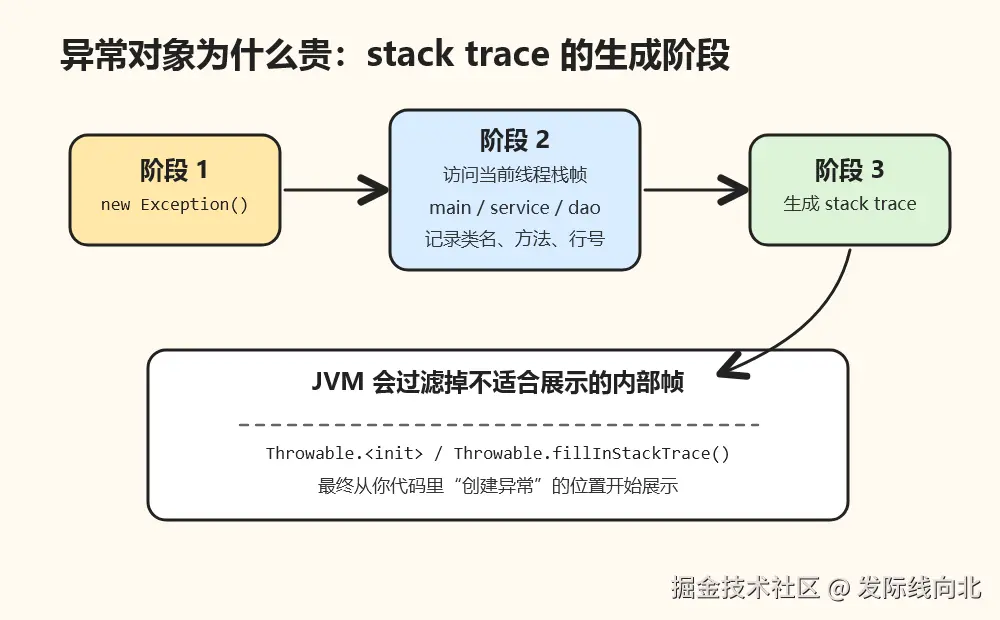
生成 stack trace 需要访问当前线程的栈帧,因此不是零成本。JVM 还会隐藏一些对开发者没帮助的内部帧,例如异常构造器本身、Throwable.fillInStackTrace(),以及一些不可见的运行时辅助方法,让栈轨迹直接从你真正创建异常的位置开始。
也正因为 stack trace 记录的是"异常对象被创建的位置",所以缓存异常实例然后反复抛出通常不推荐:日志会指向缓存对象创建处,而不是每次真正抛出的代码行。换句话说,异常适合表达"不正常路径",不适合替代高频普通分支判断。
三、异常表:JVM 捕获异常的核心机制
try-catch 在源码里看起来像一段普通结构化语句,但编译成字节码后,JVM 依靠的是每个方法携带的异常表 。异常表里的每一行都代表一个异常处理器,通常包含 from、to、target 和 type 四类信息。
from/to 表示监控哪一段字节码范围,target 表示捕获成功后跳到哪条字节码开始执行,type 表示这个处理器能捕获哪种异常。也就是说,catch 的底层不是在每条语句后面塞一堆 if,而是 JVM 在异常发生时,根据当前字节码位置和异常类型去查表。
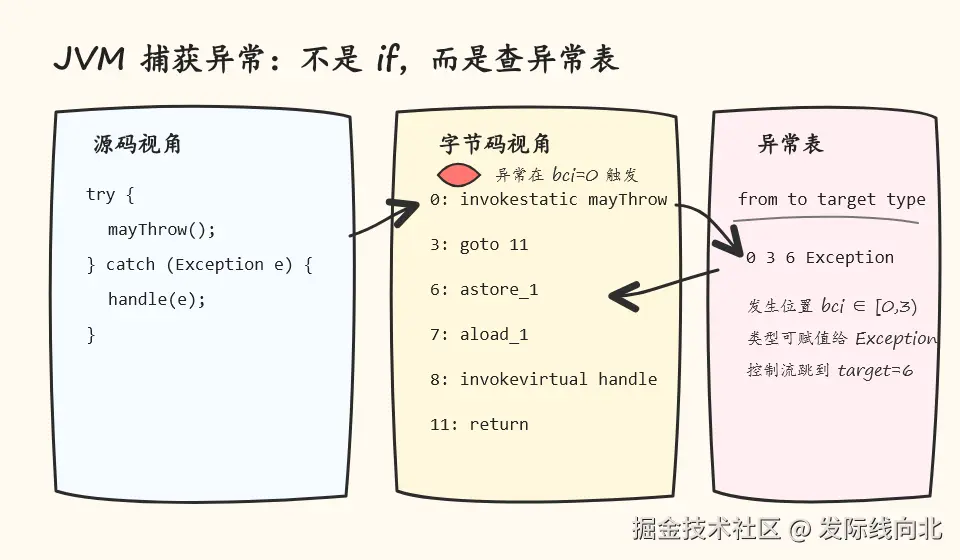
假设源码是这样:
java
public static void main(String[] args) {
try {
mayThrowException();
} catch (Exception e) {
e.printStackTrace();
}
}概念上,它可能对应这样的字节码和异常表:
text
0: invokestatic mayThrowException
3: goto 11
6: astore_1
7: aload_1
8: invokevirtual Exception.printStackTrace
11: return
Exception table:
from to target type
0 3 6 java/lang/Exception如果 mayThrowException() 在 bci 为 0 的位置触发异常,JVM 会先判断异常发生位置是否落在 [from, to) 监控范围内,再判断抛出的异常类型是否能被 type 指定的异常处理器接住。如果匹配,就把控制流跳转到 target,也就是 catch 逻辑的起始位置。如果当前方法找不到匹配项,JVM 会弹出当前方法的栈帧,到调用者方法里继续查。
这里有个容易混淆的点:checked exception 只存在于 Java 源码和编译检查层面,异常表并不是"列出这个方法可能抛出的所有异常",它记录的是这个方法里有哪些捕获处理器。
四、finally、any 与 Java 7:异常路径上的清理和保真
finally 的语义是:无论正常完成,还是发生异常,都要尽量执行清理逻辑。源码里 finally 只有一份,但从编译结果看,它更像是被复制到了多个控制流出口:try 正常结束时执行一份,catch 正常结束时执行一份,异常路径上还会有一份作为兜底处理。 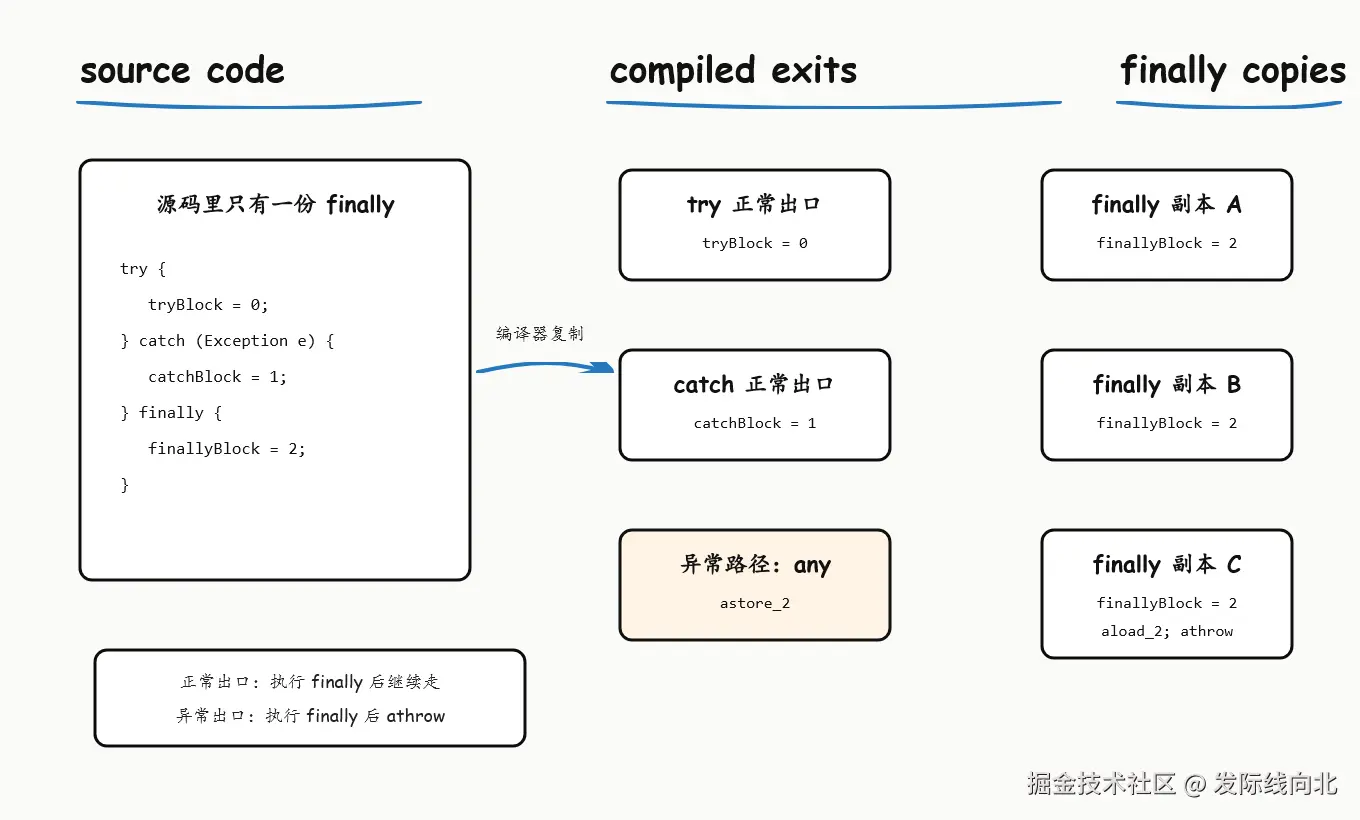
这个兜底处理器在 javap 输出里经常能看到 any。它不是 Java 源码关键字,而是字节码工具对"捕获任意可抛出异常"的表示。换句话说,any 的作用通常不是为了真正"处理"业务异常,而是为了先把异常拦一下,执行复制出来的 finally 代码,然后再把原异常重新抛出去。
这套机制解释了很多 finally 的坑。例如:
java
try {
throw new RuntimeException("try");
} finally {
throw new RuntimeException("finally");
}最后外部看到的通常是 "finally" 这个异常,"try" 那个异常会被覆盖。类似地,如果 finally 里写 return,也可能吞掉前面正在传播的异常。所以实践上要记住:finally 适合做简单、可靠的清理,不适合写复杂业务逻辑,更不适合随便 return 或 throw。
如果是资源关闭场景,Java 7 之后更推荐使用 try-with-resources:
java
try (Resource r0 = new Resource("r0");
Resource r1 = new Resource("r1")) {
throw new RuntimeException("main error");
}try-with-resources 的价值不只是少写 close()。它还会配合 suppressed exception 保留异常信息:如果主逻辑抛出 "main error",资源关闭时又抛出 "close r1"、"close r0",最终主异常仍然是主异常,而关闭资源时产生的异常会作为 suppressed exception 挂到主异常下面。
text
RuntimeException: main error
Suppressed: RuntimeException: close r1
Suppressed: RuntimeException: close r0这样主异常不会被资源关闭异常覆盖,排查问题时信息也更完整。Java 7 还支持 multi-catch,例如 catch (IOException | SQLException e)。源码层面是一个 catch,底层可以生成多个异常表条目,最终指向同一段处理逻辑。
总结
Java 异常机制的核心,是 JVM 通过异常表完成控制流跳转;catch 对应异常表里的处理器,finally 通常通过复制代码和 any 兜底处理器保证执行,try-with-resources 则在此基础上用 suppressed exception 保留资源关闭时的附属异常。理解这些底层机制后,我们就能更准确地判断异常的成本、边界和语义:异常不是普通分支,而是程序进入非正常路径时的结构化表达。