长输入短输出场景下的 SGLang 推理性能实测:前缀缓存、PD 分离配比与参数调优
我们产线上的推理请求,几乎是清一色的"长输入、短输出":几万 token 的资料或上下文喂进去,模型只吐回几百 token 的答案。RAG、长文档问答、代码库分析,本质上都是这个形状。
这种形状有个很要命的特点------算力几乎全砸在 prefill(读输入)上,decode(生成)反而很轻。再加上同一份长资料常常被很多请求反复问到,所以两个优化方向几乎写在脸上:
- 前缀缓存:相同的长前缀只算一次,后面的请求直接复用;
- PD 分离:把 prefill 和 decode 拆成两个独立服务,各自用最合适的资源,不互相抢。
道理人人都懂,但"到底配多少卡、开哪些参数、能省多少",得靠数据说话。这篇是一次把单服务 TP1~TP8、PD 全部 9 种配比都跑了一遍的完整复盘:模型 Qwen3.6-35B-A3B 的 GPTQ-int4 量化版(一个 GDN/Mamba 混合架构的 MoE),硬件 8×RTX 5090,框架 SGLang。
先把 PD 分离的结构摆出来:
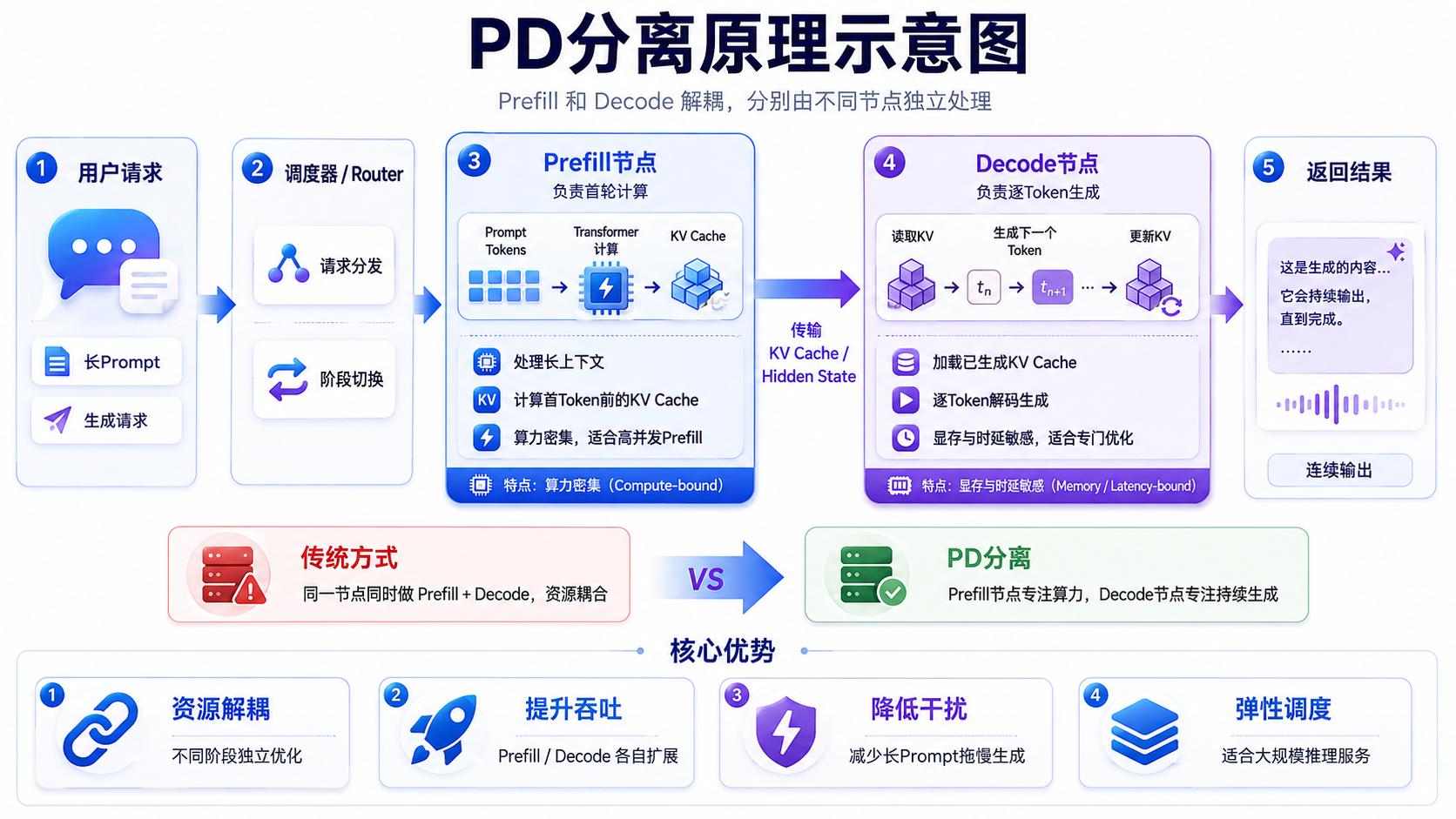
prefill 阶段要一次性处理几万 token 的输入,主要开销来自大规模矩阵乘法和 KV 计算,因此更偏算力密集;decode 阶段每次只生成一个 token,计算规模很小,但每一步都要反复读取历史 KV cache,尤其在长上下文下会大量消耗显存带宽,因此更偏访存密集。
一、前缀缓存的性能收益:并发越高,加速越明显
同一套配置,缓存开和关各跑一遍,并发从 1 扫到 32。
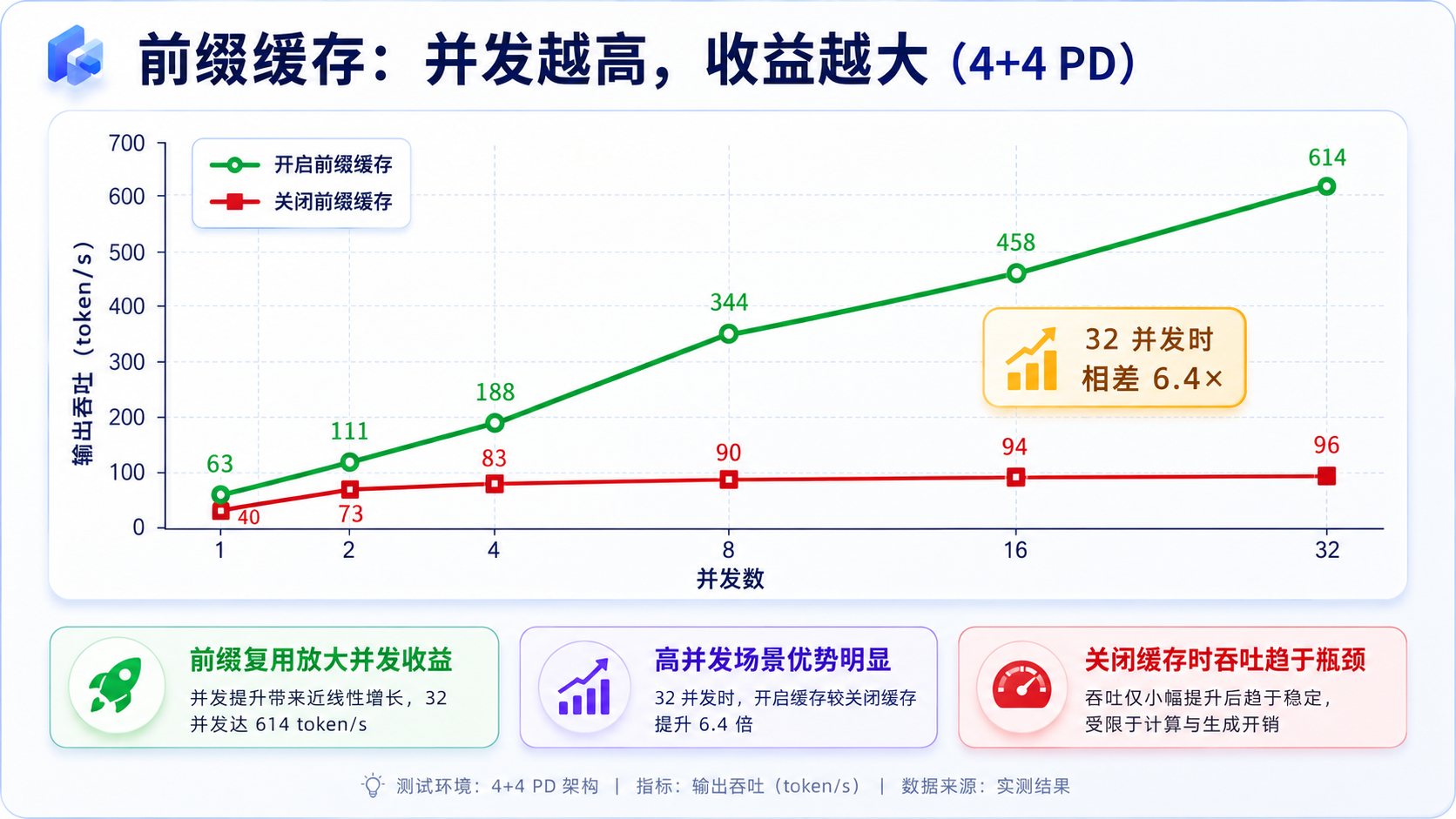
| 并发 | 关-吞吐 | 开-吞吐 | 吞吐提升 | 关-TTFT | 开-TTFT |
|---|---|---|---|---|---|
| 1 | 43 | 63 | +45% | 2.3s | 0.9s |
| 2 | 75 | 111 | +49% | 2.7s | 0.8s |
| 4 | 84 | 188 | +124% | 5.7s | 1.7s |
| 8 | 91 | 345 | +277% | 11.7s | 1.9s |
| 16 | 95 | 458 | +381% | 23.8s | 3.7s |
| 32 | 95 | 614 | +544% | 43.8s | 6.2s |
低并发时缓存只省四成多,单条请求本来也没什么可复用的。但并发一上去就指数级放大:到 32 并发,开缓存是关缓存的 6.4 倍,TTFT 从四五十秒砍到六七秒。
道理也简单:关缓存时每条请求都得把 4 万 token 重算一遍,prefill 端瞬间被灌死,吞吐死死卡在 95 tok/s 这条平线上,后面全在排队,延迟雪崩。开了缓存,4 万前缀全局只算一次,prefill 几乎白嫖,系统才扛得住继续往上加并发。
所以对长输入这种场景,缓存压根不是"要不要优化"的问题,是"服务能不能用"的问题。后面的实验,缓存全程开着。
二、单服务的吞吐天花板:张量并行的扩展性
在聊 PD 之前,得先知道"老老实实堆卡的单服务"能跑到什么程度,这是基准线。
这里先踩一个硬约束:这个模型有 16 个注意力头 ,张量并行(TP)的卡数必须能整除 16。所以 TP3、TP5、TP6、TP7 直接启动失败 (报 not divisible),能用的单服务只有 TP1 / 2 / 4 / 8。
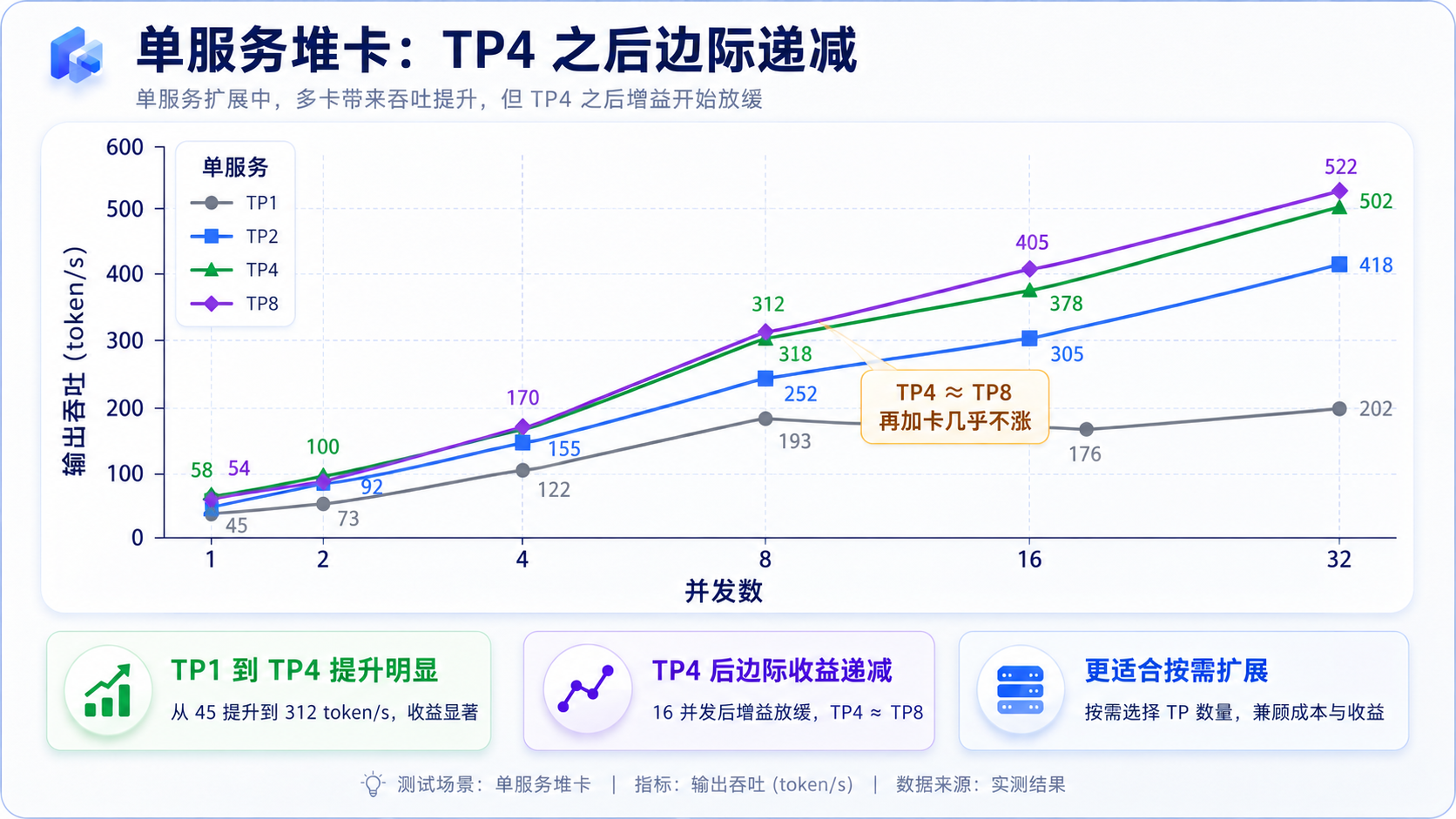
每格是「吞吐 / TTFT」
| 并发 | TP1 | TP2 | TP4 | TP8 |
|---|---|---|---|---|
| 1 | 47 / 1.7s | 57 / 1.1s | 61 / 0.8s | 53 / 1.0s |
| 2 | 74 / 2.4s | 94 / 1.5s | 103 / 1.1s | 93 / 1.4s |
| 4 | 123 / 3.1s | 155 / 2.2s | 174 / 1.7s | 172 / 1.6s |
| 8 | 194 / 4.4s | 253 / 3.0s | 314 / 2.2s | 310 / 2.1s |
| 16 | 176 / 11.1s | 307 / 5.5s | 379 / 3.1s | 406 / 4.1s |
| 32 | 203 / 20.3s | 418 / 6.5s | 504 / 5.7s | 522 / 5.6s |
两个点值得记一下。一是 TP1 单卡早早就饱和了,16 并发吞吐见顶(~200 tok/s),再加并发只堆延迟。二是 TP4 往上边际严重递减:TP4 是 504、TP8 是 522,多用一倍的卡只换来 4% 的吞吐;低并发时 TP8 甚至还不如 TP4。
为什么 TP8 堆不动?这里有个绕不开的硬件原因------5090 没有 NVLink 。nvidia-smi topo 一看,8 张卡之间全是 PCIe 桥(PXB),没有一条 NVLink。而张量并行(TP)有个特点:每一层、每次前向,都要在所有 TP 卡之间做一次 all-reduce 同步。TP8 就是 8 张卡每层同步一次,全挤在 PCIe 那点带宽上,卡越多同步越贵,把多出来的算力收益全吃掉了。要是换成带 NVLink 的数据中心卡(H100 那种 600GB/s 的片间互联),TP8 能 scale 得好得多。
所以在我们这种消费级、没 NVLink 的机器上,单服务这条路,4 张卡基本就到头了,再堆纯属浪费。
三、PD 配比全景:对称与非对称的性能差异
PD 分离要决定 prefill 几张卡、decode 几张卡。我把 P、D ∈ {1,2,4} 且总卡数 ≤8 的 9 种配比全跑了一遍。结果非常戏剧性:
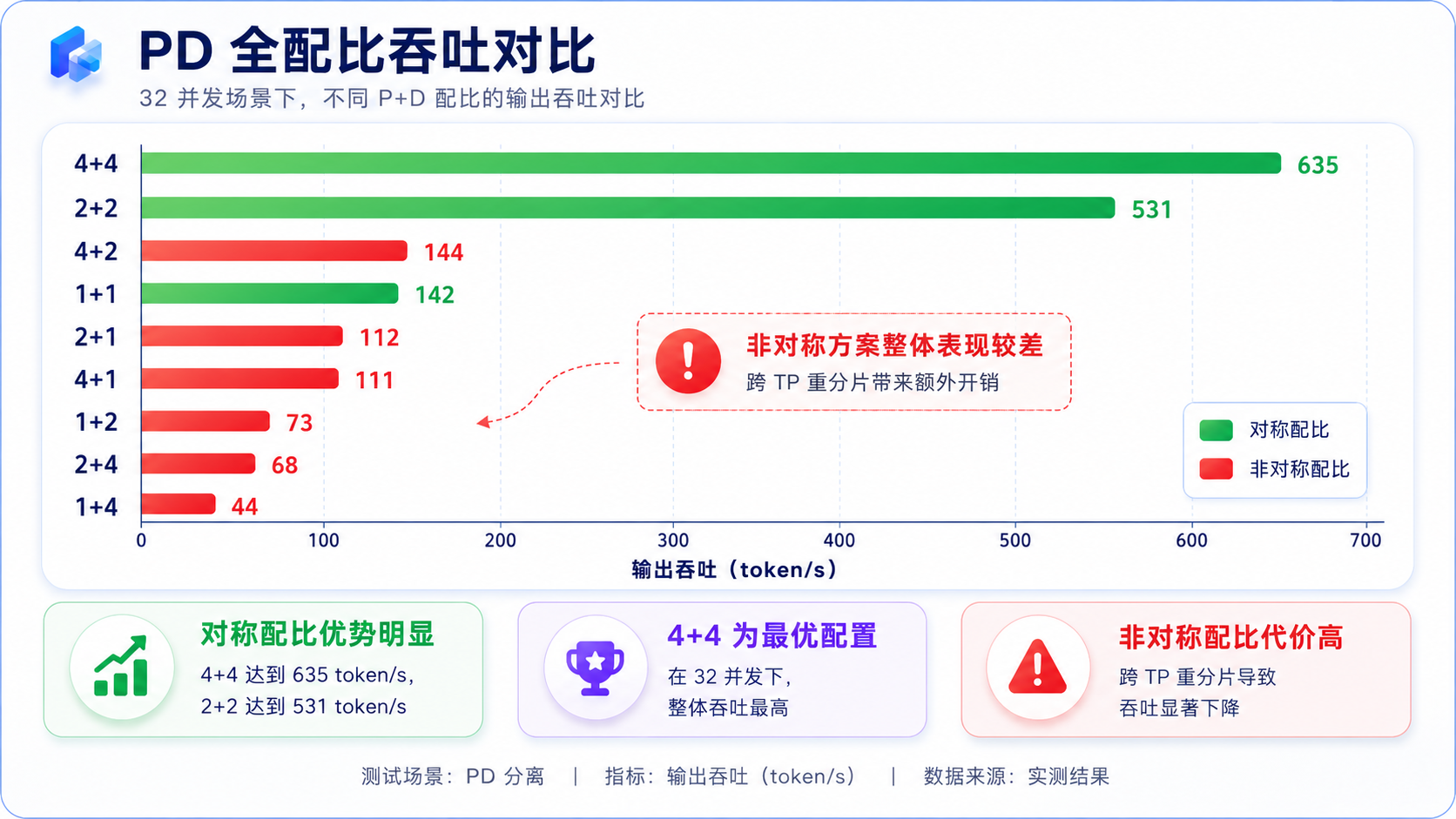
输出吞吐(tok/s),从 1 并发扫到 32,最后一列是 32 并发的首 token 延迟:
| 类型 | 配比 | c1 | c2 | c4 | c8 | c16 | c32 | c32-TTFT |
|---|---|---|---|---|---|---|---|---|
| 对称 | 4+4 | 63 | 111 | 188 | 346 | 469 | 635 | 6.0s |
| 对称 | 2+2 | 59 | 103 | 162 | 304 | 369 | 531 | 7.0s |
| 对称 | 1+1 | 48 | 84 | 110 | 134 | 134 | 142 | 29s |
| 非对称 | 4+2 | 29 | 69 | 99 | 114 | 125 | 144 | 30s |
| 非对称 | 2+1 | 28 | 70 | 89 | 104 | 105 | 112 | 38s |
| 非对称 | 4+1 | 28 | 71 | 85 | 99 | 106 | 111 | 38s |
| 非对称 | 1+2 | 24 | 50 | 52 | 64 | 69 | 73 | 59s |
| 非对称 | 2+4 | 24 | 43 | 52 | 65 | 63 | 68 | 64s |
| 非对称 | 1+4 | 18 | 31 | 41 | 42 | 36 | 44 | 100s |
所有非对称配比(prefill 和 decode 卡数不等的)全部崩盘,吞吐只有 44~144,而对称的 4+4 是 635------差距高达 4 到 14 倍。TTFT 那边更夸张:4+2 的 TTFT 是 30 秒、1+4 高达 100 秒,而 4+4 才 6 秒。
为什么非对称这么惨?翻日志找到了根因。SGLang 自己打了条警告:"非 MLA 模型用不同的 TP 大小,性能没保证" 。比如 4+2,是 prefill 按 4 路切 KV、decode 按 2 路切,两边切法不一致,KV 传过去之前要做一次 4→2 的重新分片。这个重分片走 PCIe(消费级卡没 NVLink),又慢又容易串行,大批请求堵在传输环节,decode 干等,吞吐和延迟一起崩。
对称配比(2→2、4→4)两边切法一致,KV 一一对应直接拷贝,没有重分片这道工序,所以顺。
所以记住一条就行:SGLang 的 PD 分离,prefill 和 decode 的 TP 必须相等,能用的就 1+1 / 2+2 / 4+4 这三种。任何不对称配比都会踩到跨 TP 重分片的慢路径,直接腰斩甚至骨折。
四、同卡数横评:PD 相对单服务的吞吐优势
光看"4+4 比 2+2 快"没意义,那是因为卡多。真正该问的是:同样的卡数,我该开单服务,还是拆成 PD?
把同卡数的两种方案摆一起(都取 32 并发):
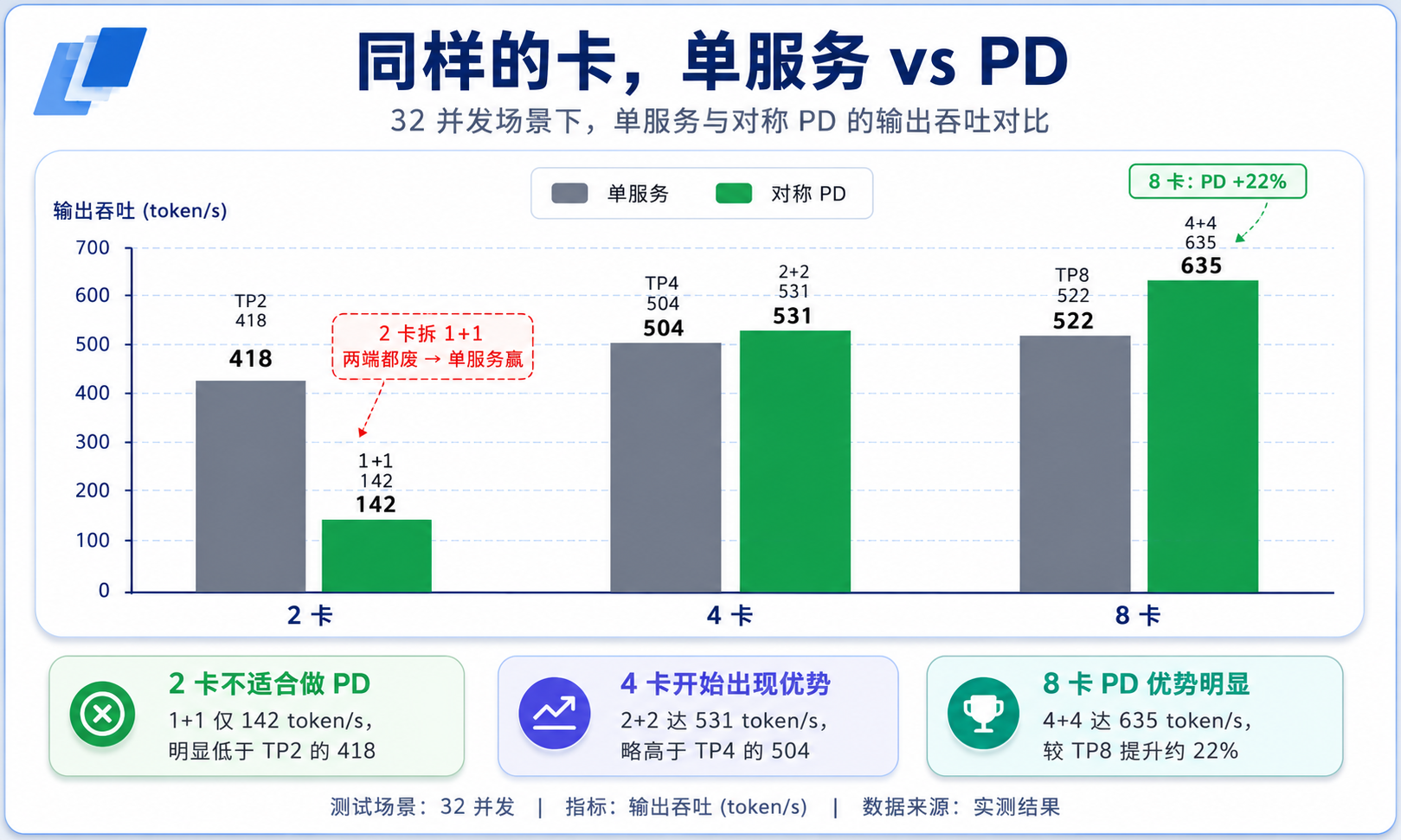
每格是「吞吐 / TTFT」(都取 32 并发):
| 卡数 | 单服务 | 对称 PD | 吞吐结论 |
|---|---|---|---|
| 2 卡 | TP2 = 418 / 6.5s | 1+1 = 142 / 29s | 单服务大胜 |
| 4 卡 | TP4 = 504 / 5.7s | 2+2 = 531 / 7.0s | PD 小胜 +5% |
| 8 卡 | TP8 = 522 / 5.6s | 4+4 = 635 / 6.0s | PD 胜 +22% |
(顺带提一句:4 卡、8 卡这两档,单服务的 TTFT 反而还略低一点点------PD 多了一跳 KV 传输。PD 赢在吞吐和后面要讲的解码延迟,不在首 token。)
这张表得多看两眼。
2 卡千万别拆。把 2 张卡拆成 1+1,prefill 和 decode 各自只剩 1 张卡,两端都被削成残废,吞吐 142,连 TP2 单服务 418 的零头都不到------PD 是有临界质量的,每一侧至少得 2 张卡才玩得转。4 卡算及格线,2+2 略微反超 TP4。到 8 卡,4+4 比 TP8 高 22%。
8 卡这个反超,跟上一节的 NVLink 问题是同一回事。4+4 其实是两个 TP4 的服务:每一侧只做 4 路 all-reduce,而不是 TP8 的 8 路;两侧之间只有"每请求一次"的 KV 批量传输,而不是每层都同步。换句话说,PD 把"每层全卡同步"这个 PCIe 大头给绕开了,只在该传的时候传一次。在没 NVLink 的机器上,这个通信模式上的便宜,比那 22% 数字本身更值钱。
所以规律其实挺简单:卡少(≤2)老老实实单服务,卡多(≥4)拆成对称 PD,而且卡越多 PD 越划算。这正好对上我们产线"长输入要堆卡"的需求------同样是堆卡,PD 更能把卡转化成吞吐。
五、吞吐之外:解码延迟、稳定性与成本权衡
看到这儿你可能会犯嘀咕:单服务吞吐也不差------2 卡 TP2 性价比还最高,就算到 8 卡,4+4 也才比 TP8 领先 22%。为这点提升搞 PD 这一整套,值吗?
只盯吞吐的话,这质疑有道理。但产线要的不光是吞吐,还有延迟稳不稳、长尾抖不抖、过载扛不扛得住------而这几样恰恰是 PD 的强项。
同卡数对比:吞吐咬得很紧,延迟天差地别
先做最公平的对比:同样的卡数,单服务和对称 PD 各跑一遍,看解码延迟(TPOT)随并发怎么走。
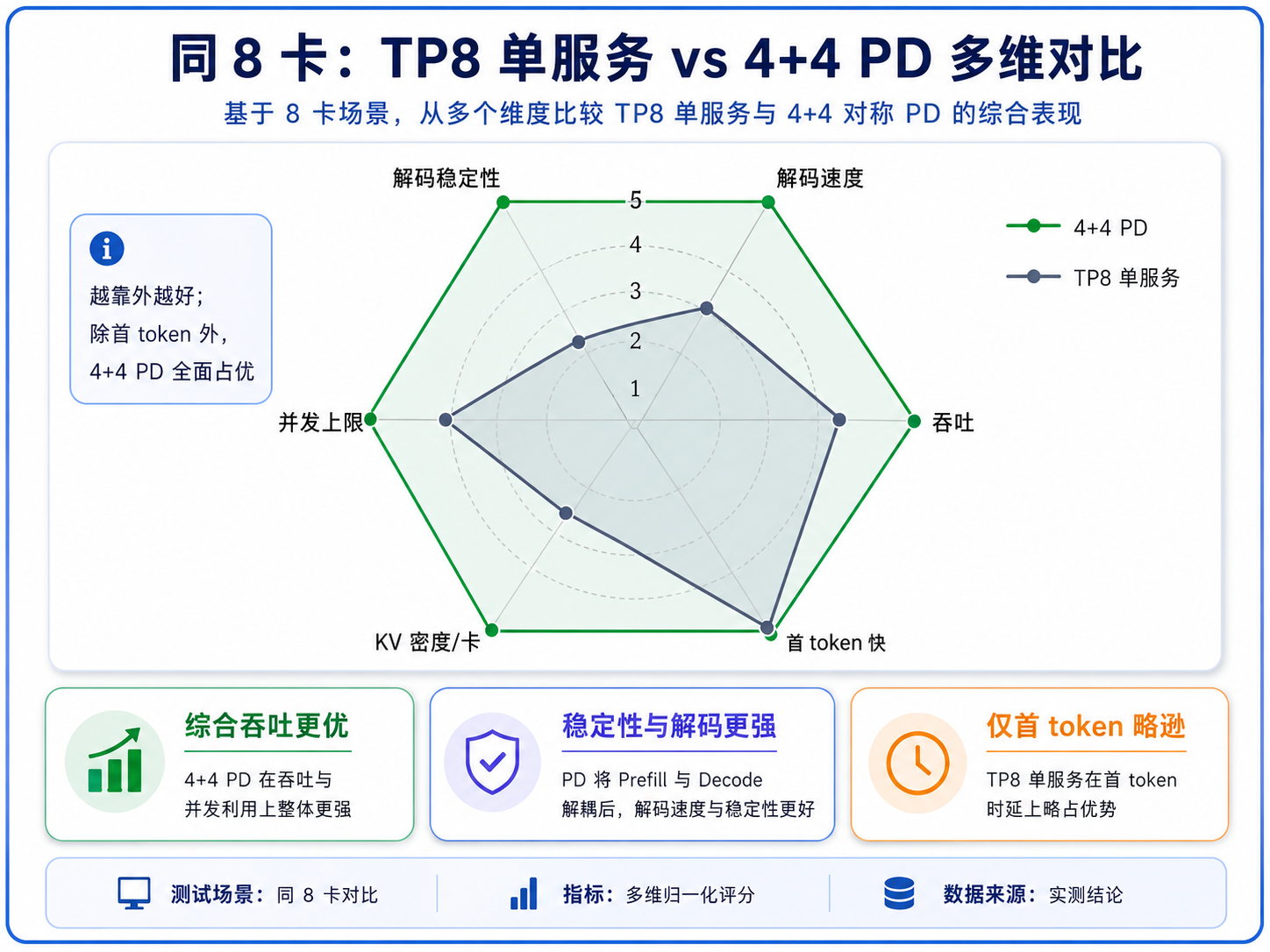
把 32 并发那一档拎出来列个表:
| 卡数 | 配置 | 吞吐 | 解码延迟 TPOT | 长尾 P99-TPOT |
|---|---|---|---|---|
| 4 卡 | TP4 单服务 | 504 | 22ms | 34ms |
| 4 卡 | 2+2 PD | 531 | 13ms | 18ms |
| 8 卡 | TP8 单服务 | 522 | 22ms | 42ms |
| 8 卡 | 4+4 PD | 635 | 11ms | 18ms |
吞吐上 PD 只是小赢,但解码延迟差出一大截:单服务的 TPOT 随并发一路爬升,到 32 并发涨到 22ms;PD 却全程压在 ~12ms 纹丝不动。长尾更夸张------单服务的 P99 抖到 34~42ms,PD 稳在 18ms。
为什么会这样?单服务里 prefill 和 decode 挤在同一个前向循环,每当一个 4 万 token 的大 prefill 块在跑,正在解码的请求就得干等它算完才能吐下一个字,TPOT 就一卡一卡地抖。PD 把 decode 拆到独立的卡上,永远不被 prefill 打断,所以解码丝滑、可预测。对流式输出、有 P99 SLA 的服务,这个差别基本是决定性的:用户看到的是匀速吐字,不是一卡一顿。
其实不止解码延迟。把 8 卡这组在几个维度上整体过一遍:除了首 token 延迟(PD 多一跳 KV 传输略逊),4+4 在解码速度、稳定性、并发上限、单卡 KV 密度上都占优------后两项(并发上限、KV 密度)下一节的压力测试还会专门讲。
成本视角:加卡到底买回了什么
PD 不是白来的,它要花更多卡。把 TP2、2+2、4+4 这条"加卡阶梯"摆出来算笔账:
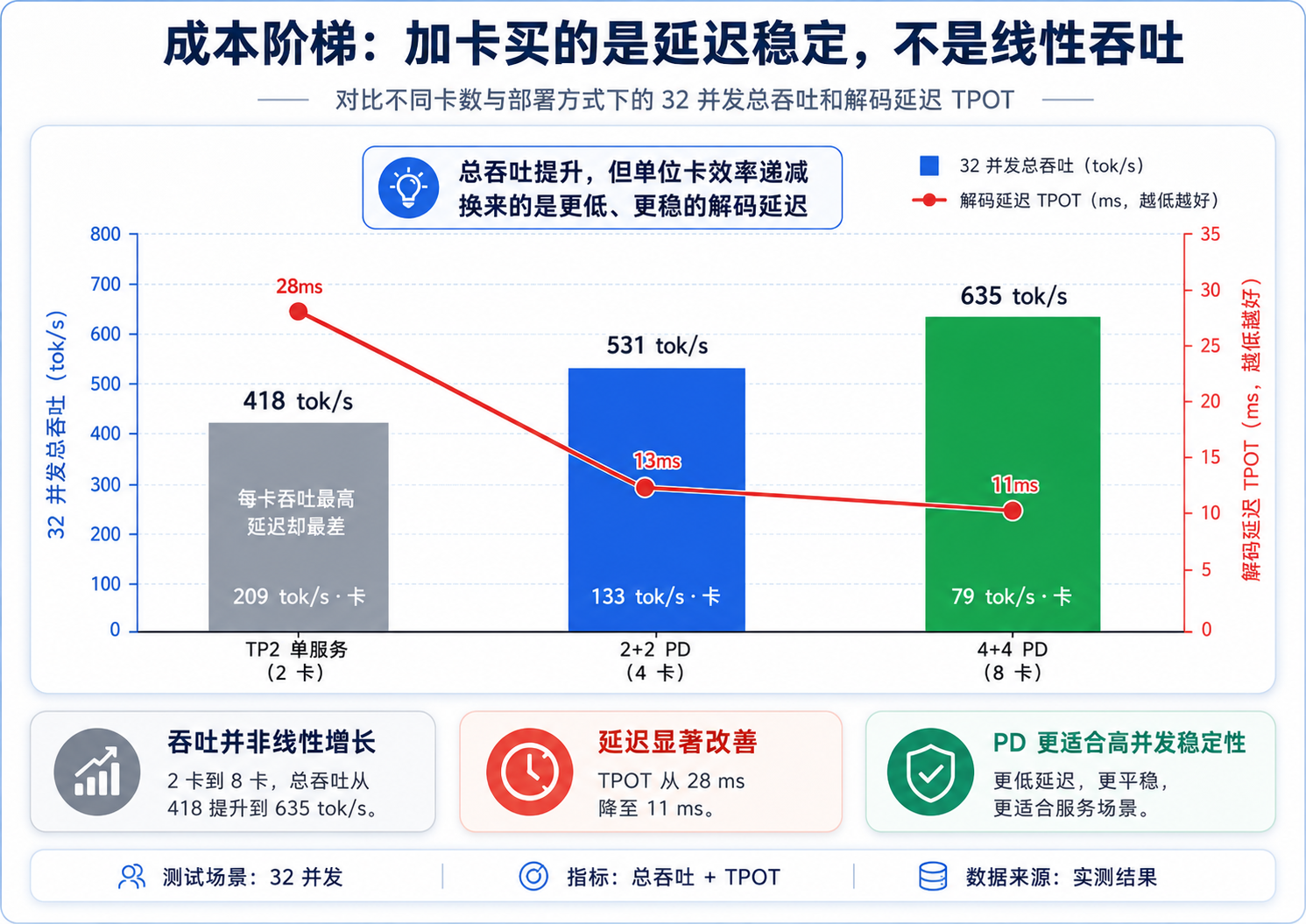
| 配置 | 卡数 | 总吞吐 | 每卡吞吐 | TPOT |
|---|---|---|---|---|
| TP2 单服务 | 2 | 418 | 209 | 28ms |
| 2+2 PD | 4 | 531 | 133 | 13ms |
| 4+4 PD | 8 | 635 | 79 | 11ms |
有意思的是,每卡吞吐最高的恰恰是最便宜的 TP2(209 tok/s 每卡),加卡反而越加越"亏":2+2 掉到 133,4+4 只剩 79。也就是说,如果你的考核口径就是"每张卡榨出多少吞吐",TP2 单服务才是最优解,PD 在这个口径上是吃亏的。
但加卡买回来的,是延迟和稳定性:TPOT 从 28ms 一路压到 11ms 并稳住,长尾从 53ms 收到 18ms,外加下一节会讲的"过载不雪崩"。所以这笔账怎么算,全看你的服务有没有延迟 SLA------没有,TP2 最省;有,这卡就花得值。
还有几个不太好量化、但很实在的好处
- 故障隔离:prefill 和 decode 是两个独立进程,一端崩了不会带崩另一端,也能分别重启、灰度;
- 资源可分级:可以给 prefill、decode 设不同的优先级、超时,甚至放到不同规格的机器上;
- 过载不雪崩:decode 永远有富余,流量打爆时只是上游排队变长,而不是像单服务那样撞硬墙、整体崩------这点第七节用压力测试细说。
六、CUDA graph:容易被忽视的解码加速开关
插一段血泪教训。中途发现另一套脚本跑同样 workload,吞吐是我的整整 5 倍。扒了半天配置,差别只有一个: CUDA graph的开启。
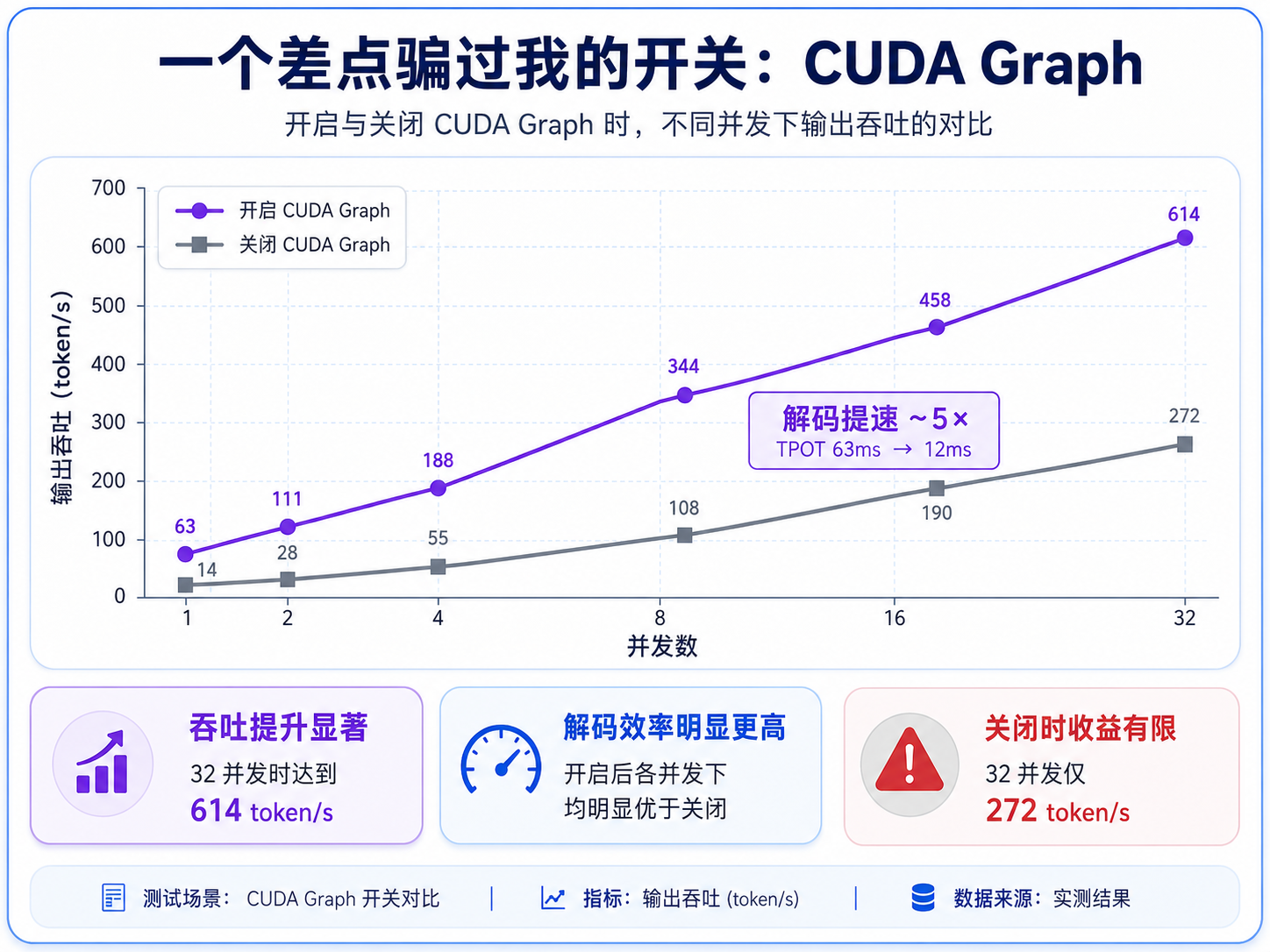
我为什么关?前期调别的量化格式时撞过 CUDA graph 捕获崩溃,出于防御就全程加了 --disable-cuda-graph。结果这个 int4 模型捕获得好好的,3 秒就完事,纯属过度保守。
CUDA graph 把解码的内核调用序列固化下来,消掉每步的 kernel launch 开销。对这个解码本来就快的 MoE,效果立竿见影:每 token 延迟从 63ms 掉到 12ms,解码快 5 倍,吞吐随之 5 倍。
两层教训:一是 CUDA graph 务必开 ,关掉等于白白慢 5 倍,这是单点收益最大的开关;二是绝对值会被这种全局开关整体拉偏,但相对排名稳如老狗------我前面所有配比对比因为统一关了 graph,结论(对称最优、非对称崩盘、缓存 6 倍)一个没错,只是绝对数字整体低了 5 倍,重跑后排名分毫未变。控制变量做实验,就是这点好处。
七、高并发压力测试:并发上限与排队行为
性能数字之外,PD 在结构上还有一层硬优势。把并发往死里灌(64 / 128 / 256),盯着"正在跑的请求数"和"排队数":
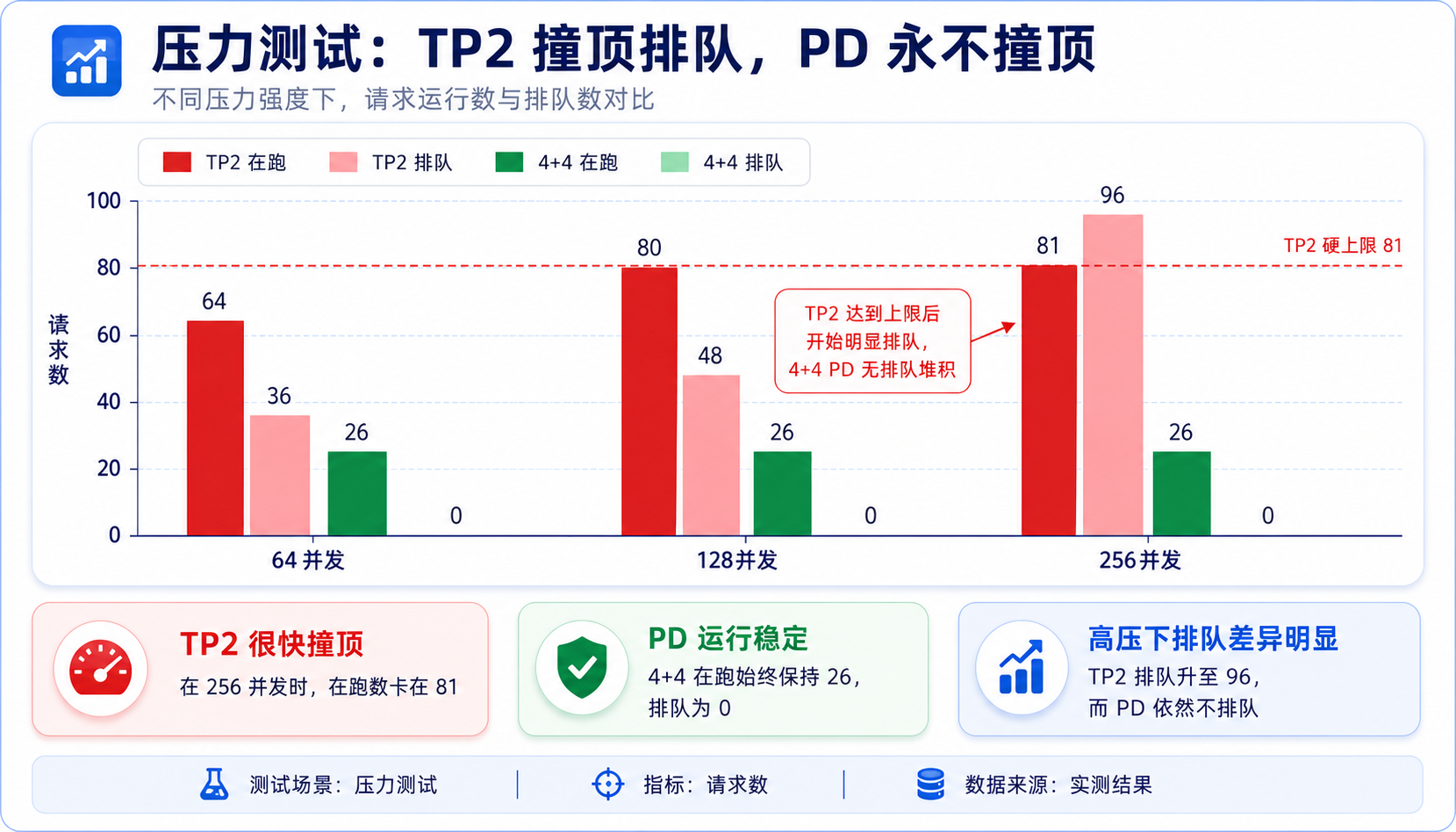
TP2 单服务很干脆 :不管灌多少,同时在跑的请求死死卡在 81,多出来的全堆进队列。256 并发时 81 个在跑、近 200 个排队,TTFT 飙到 47 秒。
这个 81 怎么来的?这模型的并发不光看显存,还看 Mamba 的状态槽 (每个并发请求占一份递归状态)。单服务要同时干 prefill 和 decode、还得给缓存留 ping-pong 缓冲,每个请求占 3 个槽,243 ÷ 3 = 81。
PD 这边完全是另一幅景象:不管灌 64 还是 256,decode 端"正在解码"的数量一直稳在 20 多个,排队 0,抢占 0。
256 个请求,decode 里怎么才 26 个?这是排队论的常识------一个工位里此刻有几个在处理 = 流入速度 × 每个处理多久,和你总共发了多少无关。decode 一个请求 2.4 秒就跑完走人,上游 prefill 又喂得慢,两者一乘,decode 里永远只积着 20 多个,远够不着容量上限。那 256 个请求大部分堆在 prefill 门口排队。
所以"PD 不撞顶"的准确含义是:decode 引擎永远有富余,不堵、不抢占,瓶颈被挪到了上游的 prefill。它没消除等待,但这个"挪"很值钱------decode 不被 prefill 抢,延迟稳;没有硬墙,吞吐能靠加 prefill 卡继续顶;decode 端也永远不会撞顶把算了一半的请求踢掉重来。单服务则是 prefill 和 decode 焊死在一个池子里,一灌满就整体雪崩。
这才是 PD 在高并发下真正的护城河:不是峰值快那么一点,是过载了也不崩。
八、参数调优:逐项消融实验
确定 4+4 是最优配比后,系统地扫了一圈参数,一个一个改、跟基线对照。
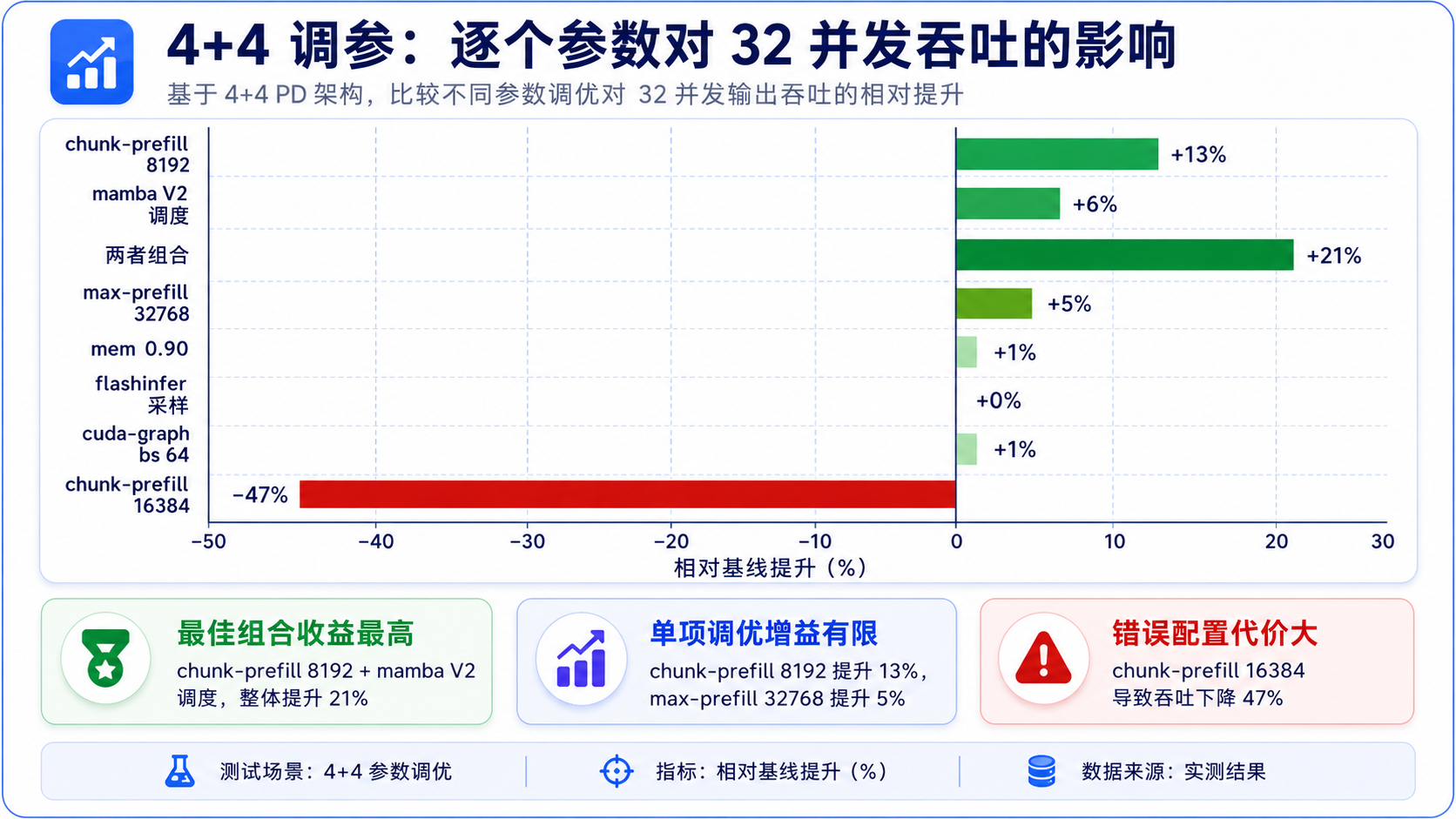
下面是 4+4、32 并发下逐个参数的结果(基线吞吐 622、TTFT 6.2s),真正有用的其实就两个:
| 参数 | 改动 | 吞吐 (提升) | TTFT | 结论 |
|---|---|---|---|---|
| 基线 | --- | 622 | 6.2s | --- |
| chunked-prefill-size | 2048 → 8192 | 701 (+13%) | 5.4s | ✅ 最有效 |
| mamba-scheduler-strategy | 默认 → extra_buffer | 662 (+6%) | 5.3s | ✅ 有效 |
| 两者组合 | --- | 751 (+21%) | 4.9s | ✅✅ 叠加 |
| max-prefill-tokens | 16384 → 32768 | 653 (+5%) | 5.7s | ⚪ 几乎无效 |
| mem-fraction 0.90 | 0.85 → 0.90 | 626 (±0) | 6.1s | ⚪ 噪声 |
| flashinfer 采样 | pytorch → flashinfer | 619 (±0) | 6.1s | ⚪ 噪声 |
| cuda-graph-max-bs | 32 → 64 | 625 (±0) | 6.0s | ⚪ 噪声 |
| chunked-prefill-size | → 16384 | 330 (−47%) | 11.9s | ❌ 过犹不及 |
| page-size | 1 → 16 | 启动崩溃 | --- | ❌ 不支持 |
chunked-prefill-size 调到 8192 直击 prefill 瓶颈,+13~15%;但别贪心调到 16384 ,会暴跌四成多。mamba-scheduler-strategy extra_buffer 换更聪明的调度,稳定 +6~8%。两个一起上,合计 +20% 吞吐。
剩下那一堆基本是噪声。还有两个直接劝退:page-size 改 16 会崩(混合 Mamba 模型把它锁死成 1),16384 分块更是负优化。说白了,这模型真正能拧的就两三个旋钮,剩下的别浪费时间。
九、生产环境落地配置建议
对"长输入短输出 + 高并发"场景,推荐 4+4 对称 PD,关键启动参数:
--attention-backend triton --sampling-backend pytorch
--cuda-graph-max-bs 32 # CUDA graph 必开(默认即开,别手贱关掉)
--mem-fraction-static 0.85
--context-length 65536
--chunked-prefill-size 8192 # 有效:+13~15%,别超过这个值
--mamba-scheduler-strategy extra_buffer # 有效:+6~8%
# 前缀缓存默认开启,务必保留一张决策速查表:
| 你的诉求 | 该怎么做 |
|---|---|
| 长前缀被反复问 | 前缀缓存必开,高并发能到 6 倍吞吐 |
| 只有 2 张卡、只看吞吐 | 用单服务 TP2,别拆 1+1 |
| 有 4 张及以上 | 用对称 PD(2+2 / 4+4),卡越多越划算 |
| 对延迟稳定性 / P99 有 SLA | 用 PD,解码 TPOT 低一半、长尾紧 2~3 倍 |
| 选 PD 配比 | 只用对称的,非对称配比吞吐腰斩到骨折 |
| 千万别做 | 非对称配比、关 CUDA graph、page-size 调大、TP 取 3/5/6/7 |
| 想再榨一点 | chunked-prefill-size 调 8192 + mamba 调度换 V2,再 +20% |
| 担心高并发崩 | 用 PD,decode 解耦后永不撞顶 |
十、讨论与展望:NVLink 互联的潜在影响
这篇所有数都是在没 NVLink 的 5090 上跑的,前面也反复提到,跨卡通信全靠 PCIe。那很自然有人会问:换上带 NVLink 的卡(H200、B300 那种),结论会不会被推翻?
老实说我也很想知道,但手头暂时没那条件,只能先从原理上掰扯几句,算给以后挖个坑。
关键是,NVLink 是给单服务和 PD 两边同时提速的,不是只帮一边:
- 对单服务,它直接治的就是大 TP 的痛点。每层那个 8 路 all-reduce,在 NVLink 上是几百 GB/s,不再是 PCIe 那点可怜带宽。所以 TP8 大概率能重新 scale 起来,单服务吞吐会往上窜一截。
- 对 PD,它能加速 prefill→decode 的那次 KV 传输(前面看到长输出、高并发时,这一跳本身会变成瓶颈)。更有意思的是,那个把所有非对称配比打趴下的"跨 TP 重分片",大头也是 PCIe 慢------上了 NVLink,4+2、2+4 这些配比说不定就活过来了,"只能对称"这条铁律,可能就松动了。
所以这是个两边都受益的事,谁涨得更多、最优配比会不会变,光靠想是想不明白的,得真跑。我的直觉(也就是个直觉):单服务在纯吞吐上会追上来不少,毕竟 NVLink 最直接修的就是它的 all-reduce 短板;但 PD 那几个结构性好处------解码延迟稳、不撞顶、故障隔离------是跟互联无关的,该有还是有。
要是以后能摸到一台 H200 或者 B300,我打算把这整套矩阵原样再跑一遍:单服务的 TP scale、PD 的全配比、对称非对称,一个不落重测,到时候再写一篇对照的。手上有这条件的同行,也欢迎拿去跑,结论咱们对一对。
结语
这一圈跑下来,印象最深的是:一堆"看着就该更好"的东西,实测要么没用、要么直接骨折------非对称配比、16k 分块、TP8 堆卡、各种花哨参数,一个没幸免。真正管用的反而就那么几下:缓存打开、配比对称、CUDA graph 别手贱关掉、prefill 分块调到 8192。
调性能这活儿基本就这样,拍脑袋只能定个大方向,最后还得拿数字说话。而最值钱的数字,往往是那些跟你直觉拧着来的------比如同样 8 张卡,配比选对没选对,吞吐能差 14 倍。这种东西,不跑一遍你永远不知道。
实测环境:SGLang 0.5.12 + torch 2.9.1+cu128 + sgl_kernel 0.3.21,8×RTX 5090(CUDA 12.8 驱动),模型 Qwen3.6-35B-A3B-GPTQ-Int4。workload 为 4 万 token 共享前缀 + 200 token 问题 + 200 token 输出。文中所有数字均为真机实测。