Docker 很厉害,Docker 很好用,是现代软件工程的杰作,在生产环境部署与 CI/CD 流程中占据着统治地位。但是,如果你今天使用 MacBook 构建本地 AI 应用和 RAG系统,还在用Docker Desktop 来部署的话,你会发现,它就是拖垮生产力的元凶。

本地AI开发的时候,刚在终端敲下 docker-compose up,MacBook 的风扇开始狂转,活动监视器里的内存压力瞬间飙红,随后在 VS Code 里编写代码微秒级卡顿。
本地 AI 开发,特别是涉及大型语言模型(LLM)和向量数据库的运行,需要对硬件算力进行极致的压榨。Docker 在 macOS 上基于虚拟机的架构,正在无形中消耗掉设备最宝贵的性能。
Docker 在 macOS 上的性能陷阱
要理解性能流失的原因,必须深入底层架构。而以下几个技术瓶颈是无法回避的客观事实。
内存分配的零和博弈
Apple Silicon(M 系列芯片)的技术壁垒在于"统一内存(Unified Memory)"架构。CPU 和 GPU 共享同一块高带宽内存池,本地运行 Llama 3 或 Mistral 等模型高度依赖这种机制来实现快速推理。

Docker 在 macOS 上并非原生运行,而是依托于一个隐形的 Linux 虚拟机(VM)。系统必须预先为这个虚拟机划定一块固定的内存边界(例如分配 16GB)。这种硬性隔离打破了统一内存的动态平衡。大模型在宿主机上运行时无法触及分配给 Docker 的内存;反之,如果为了给大模型留出空间而压缩 Docker 的内存配额,容器内的 PostgreSQL 或 Python 后端服务就会频繁触发 OOM(Out of Memory)崩溃。
GPU 调用的虚拟化损耗
在 Mac 上进行 AI 推理加速,必须通过 Apple 的 Metal 框架。
尽管 Docker Desktop 近年来在 GPU 直通方面做了诸多尝试,但让一个运行在 Linux 容器内的进程去无缝调用宿主机的 Metal API,中间的指令翻译和虚拟化层始终会产生性能损耗。实测数据表明,直接在 macOS 原生运行的推理引擎,其 Token 生成速度远超封装在 Docker 容器内的同类服务。
文件同步的 I/O 瓶颈
RAG 应用开发涉及大量的文件处理。开发者需要频繁读取本地的 PDF 集合、Markdown 文档库或代码仓库,将其拆分并转化为向量(Embedding)。
将 macOS 的文件系统挂载到 Docker 容器内部,即使启用了 VirtioFS 等实验性加速特性,在应对数以万计的细碎文件并发读取时,I/O 吞吐量依然会呈现断崖式下跌。一段在本地原生 Python 环境中只需几百毫秒即可完成的文档加载脚本,在容器内往往需要阻塞数秒。
繁杂的网络与端口映射
构建一个完整的 AI Agent 系统,微服务架构是常态。开发者通常需要维护运行在 5432 端口的向量数据库、运行在 3000 端口的前端框架、监听 8000 端口的 API 后端,还要与本地 11434 端口的大模型接口进行通信。

在 Docker 的桥接网络、宿主机的 Localhost 之间不断配置端口映射,处理跨域请求拦截(CORS),以及为本地 HTTPS 调试签发 SSL 证书,这些繁杂的运维工作严重干扰了业务逻辑的开发进度。
范式转移:重返纯原生架构
打破上述瓶颈的唯一途径是改变基础设施架构。与其在一个臃肿的 Linux 沙盒中不断寻找优化补丁,不如直接回归 macOS 的物理硬件。
现代开发栈中的核心组件,包括 Python、Node.js、PostgreSQL 以及各类 AI 推理库,均提供了基于 ARM64 架构优化的 macOS 原生二进制版本。剥离虚拟化层,让代码直接运行在物理机上,成为本地 AI 开发的新共识。
原生开发环境的重构
为了彻底消除虚拟化带来的性能税,本地开发环境需要一次彻底的重构。ServBay 正是在这种需求下脱颖而出的 macOS 原生开发基础设施。它摒弃了容器化思路,直接提供物理机级别的原生性能。
100% 物理机原生性能
ServBay 内部没有任何 Linux 虚拟机。它采用纯原生编译的底层环境,服务进程直接由 macOS 内核调度,直接与 Apple Silicon 交互。由于去除了资源预留机制,系统的统一内存得以被大模型和后端服务按需动态分配,彻底解决了风扇狂转和系统卡顿的问题。
一键部署 AI 基础设施(附安装指南)
摆脱冗长复杂的 docker-compose.yml 文件。RAG 开发高度依赖支持向量检索的数据库,ServBay 提供了开箱即用的原生环境。
安装与配置步骤:
- 前往 ServBay 官网下载最新的 macOS 安装包(.dmg 文件),将应用拖拽至应用程序文件夹即可完成基础安装。

- 打开 ServBay 控制面板,在「软件包」选项卡中找到 PostgreSQL。系统提供从 11 到 16 的多个大版本,点击绿色按钮安装,它会自动下载并配置原生基于 ARM64 编译的数据库。
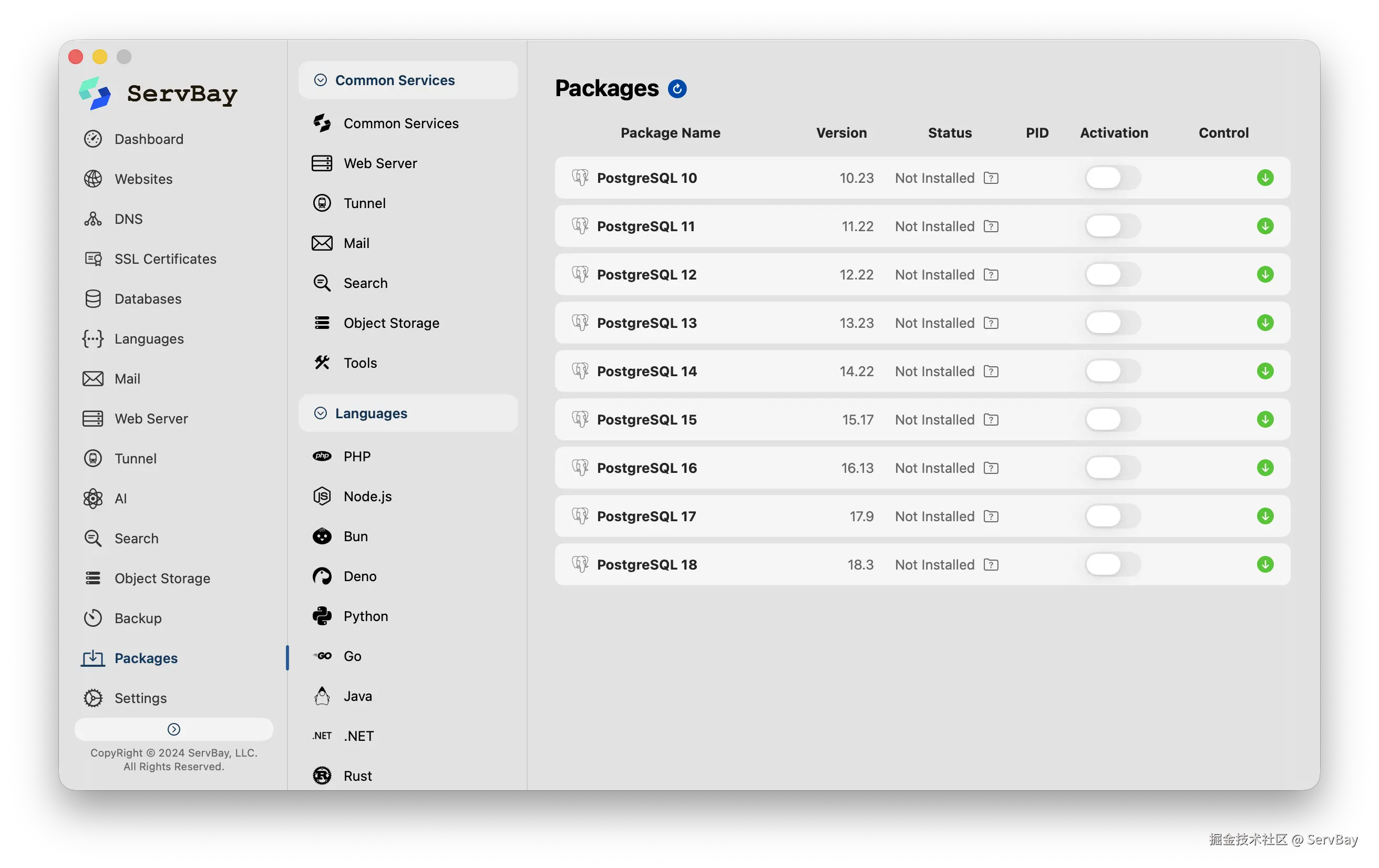
-
启用 pgvector 插件。ServBay 底层已预置编译好的 pgvector 扩展包。开发者使用 SQL 客户端连接本地数据库后,直接执行
CREATE EXTENSION vector;即可开启向量检索能力,免去了处理 C 语言编译依赖的繁琐步骤。 -
ServBay 提供了对 Node.js 以及 Python 等多语言环境的底层支持,自动处理全局路径映射,避免与 macOS 系统自带的环境产生版本冲突。
极简的网络与 SSL 调试
前后端分离开发与 AI 接口联调时,HTTPS 环境不可或缺。ServBay 内置了本地 DNS 路由和自动信任的 SSL 证书机制。开发者可以直接使用自定义的本地域名(如 my-ai-app.test)进行访问,彻底告别浏览器证书警告和本地跨域报错。
无缝对接本地大模型环境
原生环境最大的优势在于进程间的低延迟通信。配合本地大模型运行工具,整个链路将变得异常顺畅。
Ollama 原生安装与联动示例:
原生环境的优势在于进程间的低延迟通信。ServBay 已经将 Ollama 深度集成到软件内部。开发者无需切换到终端执行命令行,直接在 ServBay 的「软件包」找到 Ollama 并点击一键安装ollama,系统便会自动配置并拉起原生进程。
服务就绪后默认监听本地 11434 端口。此时在 ServBay 托管的 Python 后端代码里直接发起网络请求,数据无需穿透任何虚拟化网络层,延迟降到最低。
python
import requests
response = requests.post('http://127.0.0.1:11434/api/generate', json={
"model": "llama3",
"prompt": "解析这篇文档的摘要",
"stream": False
})
print(response.json()['response'])性能基准:数据对比
客观的基准测试能最直观地反映架构差异带来的性能鸿沟。以下是常规 RAG 开发环境(PostgreSQL + Python Backend + Node Frontend)在两套架构下的表现。
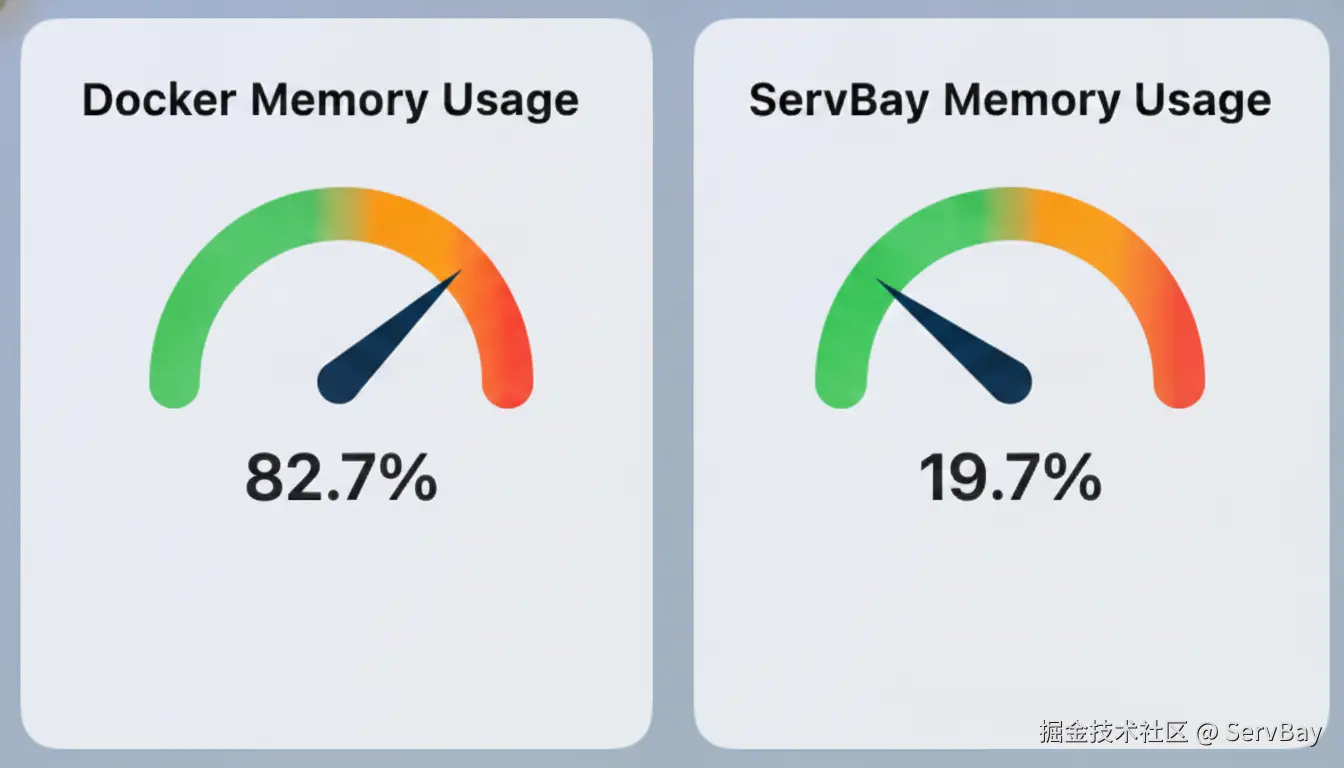
内存 占用对比
| 环境架构 | 空载常驻内存 | 峰值内存分配策略 |
|---|---|---|
| Docker Desktop | 3.5 GB - 4.2 GB | 固化分配,易导致系统 Swap |
| ServBay (原生) | < 150 MB | 按需动态调用统一内存 |
启动与就绪时间
| 环境架构 | 冷启动耗时 | I/O 密集型任务耗时 (加载1000份PDF) |
|---|---|---|
| Docker Compose | 12 - 18 秒 (需启动 VM 及容器) | 14.5 秒 (受限于虚拟文件系统) |
| ServBay (原生) | < 2 秒 (系统级进程拉起) | 3.2 秒 (原生 APFS 满速读取) |
让云计算归云,让本地归本地
技术栈的选择应当服务于具体的场景。Docker 依然是构建标准云原生应用、执行 CI/CD 流水线以及服务器部署的绝对标准。但在代码编写和本地调试阶段,特别是在需要压榨每一滴算力给大模型推理的 AI 时代,继续固守基于虚拟机的本地开发模式已经不再合时宜。
轻量、极速、无损的原生环境是提升开发者体验的必经之路。不要让高昂的 M 系列芯片算力浪费在维持虚拟机的运转上。拥抱 ServBay 等原生开发工具,重构本地 AI 开发工作流,将硬件的真实性能全盘释放。