摘要:最近给我在维护的在线工具站补全了图片处理类工具链,从截图美化、AI抠图到图片压缩,全部支持浏览器端完成。这篇文章分享5个功能的实现方案、技术选型和踩坑记录,包含前端Canvas、WASM、SVG、色彩算法等具体细节。

写在前面
我在业余时间维护着一个在线工具站,之前主要做的是PDF转换、文档处理这类偏后端的工具。后来用户反馈里出现频率最高的词居然是"图片处理"------压缩、抠图、改尺寸、转格式。于是我花了一个多月,把图片处理这条线补全了。
这篇文章不是工具推荐,而是技术复盘。我会把5个功能的实现方案、当时做的技术选型、以及踩过的坑都摊开来讲。
一、截图美化:Canvas绘制的精度陷阱
需求与方案
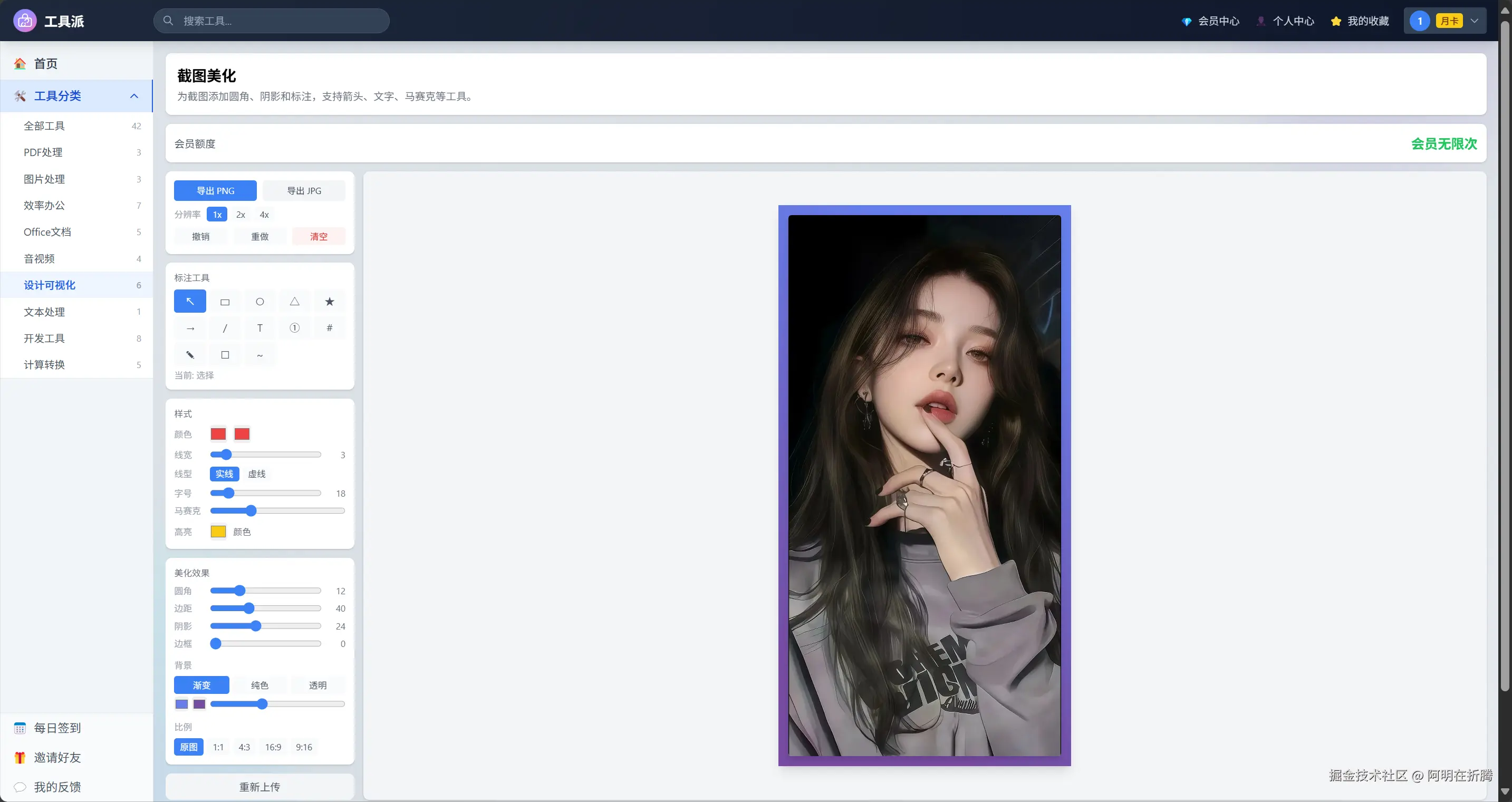
截图美化听起来简单:用户上传一张截图,给加个圆角、阴影,换个背景色,让截图看起来不那么" raw "。
我第一反应是用CSS------border-radius + box-shadow 套一个div就完事了。但很快发现不行:用户要的是导出成图片,而不是只在网页上好看。CSS渲染的效果无法直接保存为PNG。
所以方案换成了纯前端Canvas绘制。
核心代码
typescript
const beautifyScreenshot = (
img: HTMLImageElement,
options: {
radius: number;
shadowBlur: number;
shadowColor: string;
bgColor: string;
padding: number;
}
): Promise<Blob> => {
const canvas = document.createElement('canvas');
const ctx = canvas.getContext('2d')!;
// 画布尺寸 = 图片尺寸 + 内边距 + 阴影扩展
const expand = options.shadowBlur + options.padding;
canvas.width = img.width + expand * 2;
canvas.height = img.height + expand * 2;
// 填充背景
ctx.fillStyle = options.bgColor;
ctx.fillRect(0, 0, canvas.width, canvas.height);
// 设置阴影
ctx.shadowColor = options.shadowColor;
ctx.shadowBlur = options.shadowBlur;
ctx.shadowOffsetX = 0;
ctx.shadowOffsetY = options.shadowBlur / 2;
// 绘制圆角矩形路径,再填充图片
const x = expand;
const y = expand;
const w = img.width;
const h = img.height;
const r = options.radius;
ctx.beginPath();
ctx.moveTo(x + r, y);
ctx.lineTo(x + w - r, y);
ctx.quadraticCurveTo(x + w, y, x + w, y + r);
ctx.lineTo(x + w, y + h - r);
ctx.quadraticCurveTo(x + w, y + h, x + w - r, y + h);
ctx.lineTo(x + r, y + h);
ctx.quadraticCurveTo(x, y + h, x, y + h - r);
ctx.lineTo(x, y + r);
ctx.quadraticCurveTo(x, y, x + r, y);
ctx.closePath();
ctx.clip();
ctx.drawImage(img, x, y, w, h);
return new Promise(resolve => canvas.toBlob(blob => resolve(blob!), 'image/png'));
};踩坑:高清屏的DPI问题
这个函数在普通屏幕上没问题,但在MacBook Retina屏上导出的图片会模糊。原因是Canvas的绘制像素比和屏幕物理像素比不一致。
修复方案:根据window.devicePixelRatio缩放Canvas:
typescript
const dpr = window.devicePixelRatio || 1;
canvas.width = (img.width + expand * 2) * dpr;
canvas.height = (img.height + expand * 2) * dpr;
canvas.style.width = `${img.width + expand * 2}px`;
canvas.style.height = `${img.height + expand * 2}px`;
ctx.scale(dpr, dpr);不加这一行,Retina屏上的截图导出后文字边缘全是锯齿。
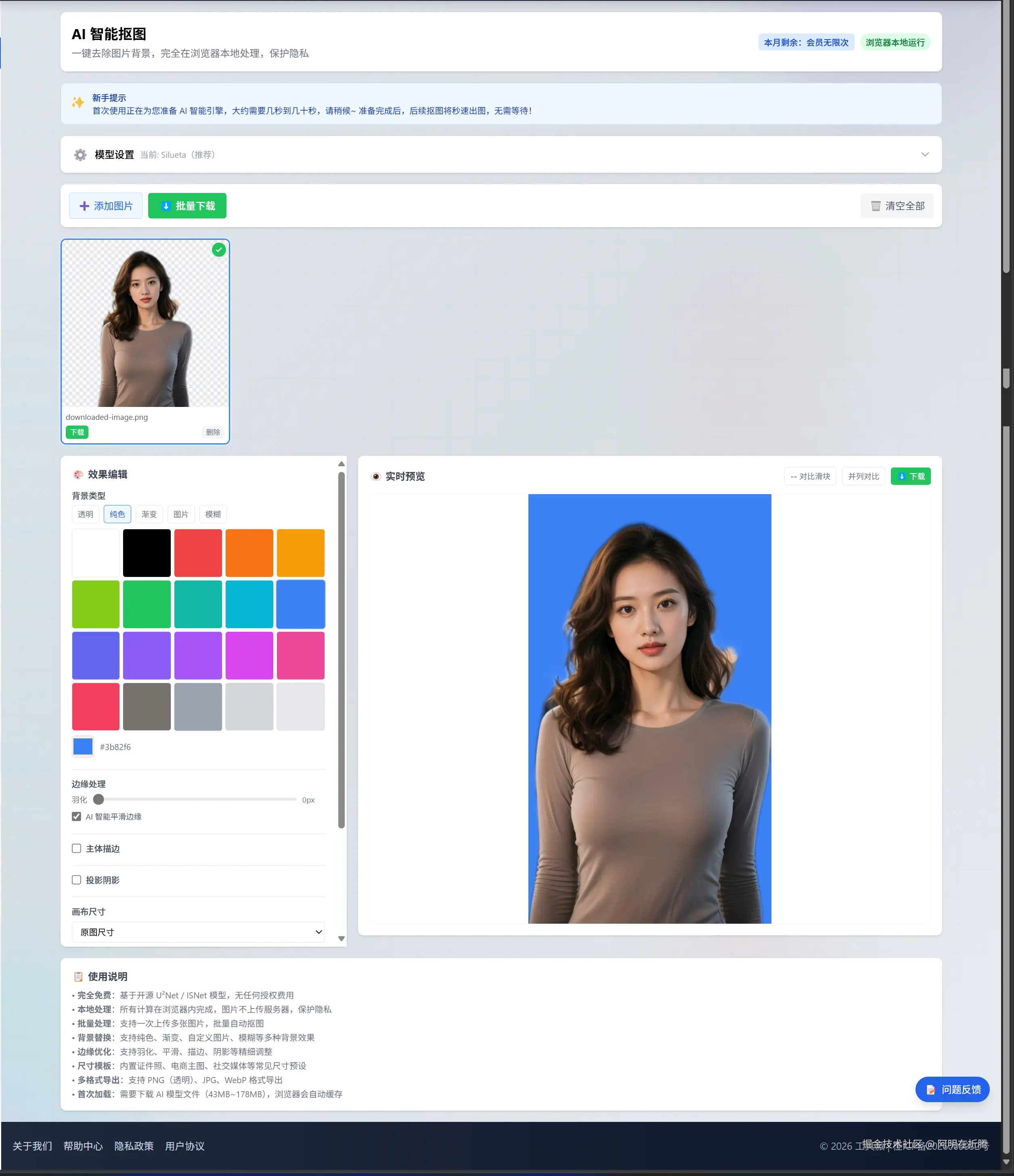
二、AI智能抠图:前端WASM vs 后端API的取舍
技术选型
AI抠图是我这次投入调研时间最多的功能。核心矛盾在于:效果好的模型太大,体积小的模型效果差。
我调研了两条路线:
| 方案 | 实现方式 | 优点 | 缺点 |
|---|---|---|---|
| 前端WASM | 浏览器加载ONNX模型,本地推理 | 隐私性好、无服务器成本 | 模型体积大(20MB+)、低端设备卡、首次加载慢 |
| 后端API | 服务端调用AI服务或自研模型 | 效果稳定、不受客户端性能限制 | 有服务器成本、用户担心隐私上传 |
最终方案
我采用的是混合策略:
- 优先走前端WASM方案,用
@imgly/background-removal这类已经封装好的库。它底层是WebAssembly跑ONNX Runtime,模型会按需加载。 - 如果用户设备性能不足(通过检测内存和CPU核心数判断),或者浏览器不支持WASM,自动降级到后端Python方案。
踩坑:模型加载的UX
最大的坑不是技术,是用户体验。模型首次加载要下载20多MB,如果用户点了抠图按钮后没有任何反馈,他会以为页面卡死了。
我的处理方式:
- 页面加载时预加载模型(不阻塞主流程)
- 用户点击抠图后,显示"AI模型加载中(约5秒)"的进度提示
- 加载完成后缓存到IndexedDB,下次不再下载
typescript
// 预加载模型,不阻塞交互
const preloadModel = async () => {
if ('storage' in navigator && 'estimate' in navigator.storage) {
const estimate = await navigator.storage.estimate();
// 如果设备存储紧张,跳过预加载
if (estimate.quota && estimate.usage && estimate.usage / estimate.quota > 0.8) {
return;
}
}
// 静默预加载
removeBackground.preload().catch(() => {});
};
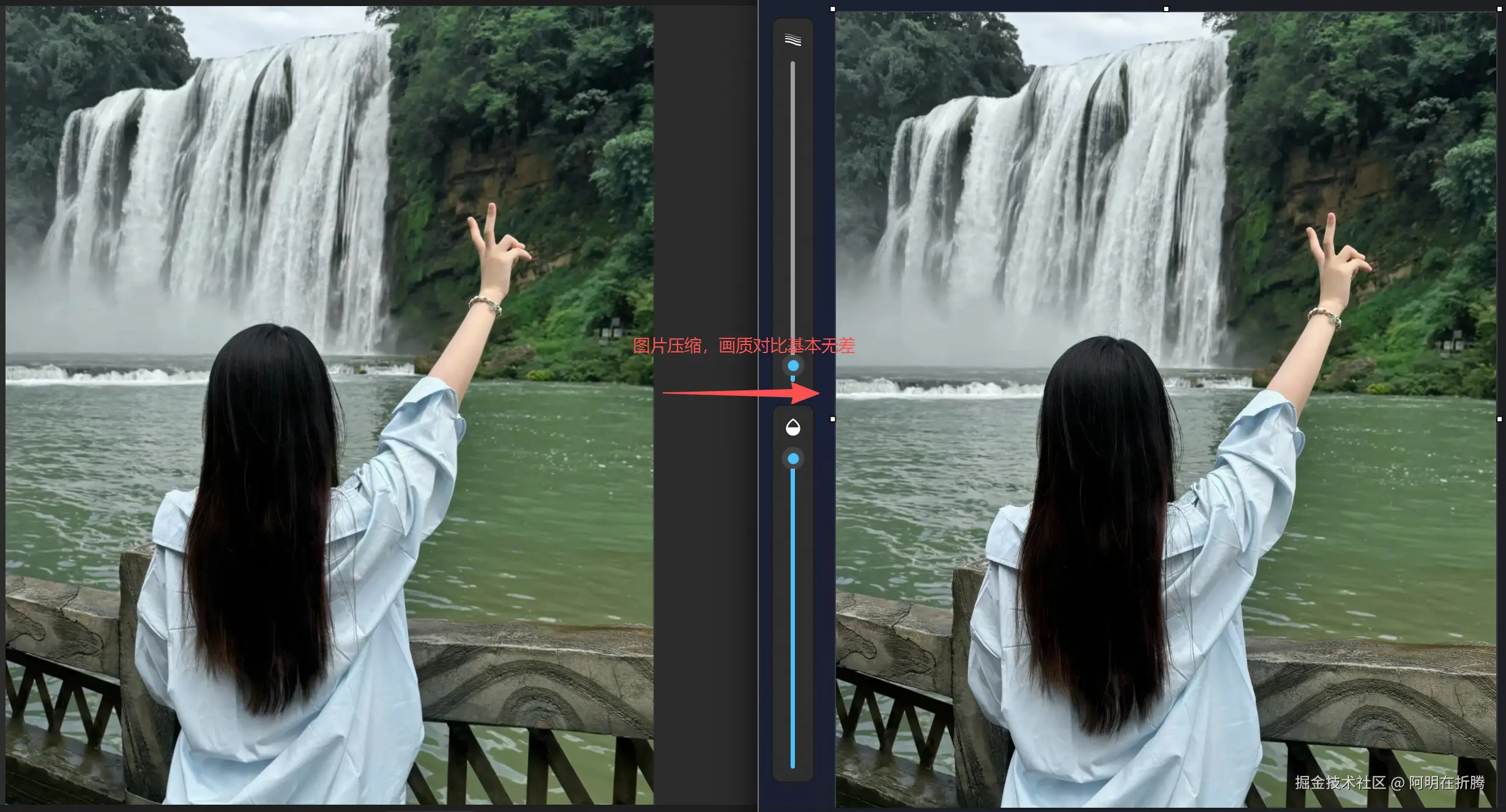
三、图片压缩:Canvas toBlob的边界
前端压缩方案
图片压缩是高频需求,我最先尝试的是纯前端方案------用Canvas的toBlob API:
typescript
const compressImage = (file: File, quality: number): Promise<Blob> => {
return new Promise((resolve, reject) => {
const img = new Image();
img.onload = () => {
const canvas = document.createElement('canvas');
canvas.width = img.width;
canvas.height = img.height;
const ctx = canvas.getContext('2d')!;
ctx.drawImage(img, 0, 0);
canvas.toBlob(
blob => blob ? resolve(blob) : reject(new Error('压缩失败')),
'image/jpeg',
quality // 0 ~ 1
);
};
img.src = URL.createObjectURL(file);
});
};发现的问题
这个方案有几个隐蔽的坑:
1. PNG转JPEG时透明背景变黑
如果原图是PNG且有透明通道,drawImage到Canvas后再导出JPEG,透明部分会变成黑色。用户上传一个Logo,压完出来个黑底,体验很差。
修复:压缩前检测图片格式,如果是PNG且有透明通道,要么保持PNG格式压缩,要么在Canvas底层先填充白色背景再绘制。
2. 压缩比不够高
toBlob的quality参数只能控制JPEG质量,无法调整编码方式。对于一些已经高度优化的图片(比如从相机导出的JPEG),前端再压一遍效果微乎其微。
3. 大图片导致浏览器卡顿
如果用户上传了一张iPhone拍的4MB照片(3024×4032),Canvas需要占用约48MB内存。在移动端浏览器上,这很容易触发内存限制导致页面崩溃。
后端补充方案
对于大图和需要高压缩比的场景,我加了一个后端Python方案,用Pillow处理:
python
from PIL import Image
import io
def compress_image(input_bytes, quality=75, max_dimension=1920):
img = Image.open(io.BytesIO(input_bytes))
# 如果图片尺寸过大,先缩小
if max(img.width, img.height) > max_dimension:
ratio = max_dimension / max(img.width, img.height)
new_size = (int(img.width * ratio), int(img.height * ratio))
img = img.resize(new_size, Image.Resampling.LANCZOS)
output = io.BytesIO()
# PNG用quantize减少颜色数,JPEG用quality参数
if img.format == 'PNG':
if img.mode in ('RGBA', 'LA', 'P'):
img = img.convert('RGB')
img.save(output, format='JPEG', quality=quality, optimize=True)
else:
img.save(output, format=img.format or 'JPEG', quality=quality, optimize=True)
return output.getvalue()前端策略是:小于1MB的图片走Canvas压缩,大于1MB或者压缩后效果不理想的,走后端处理。用户无感知,前端自动判断。
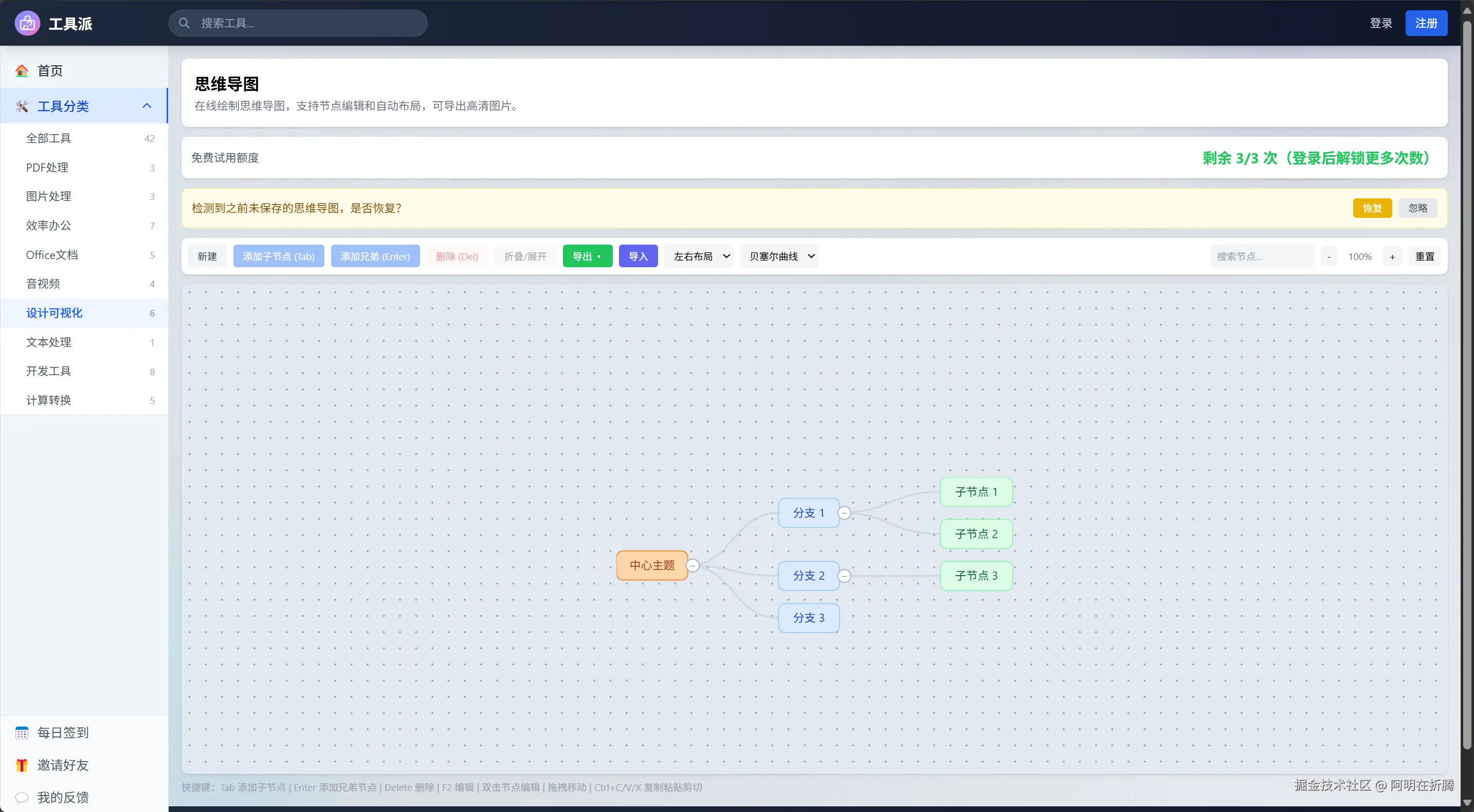
四、思维导图:SVG比Canvas更适合交互式绘图
为什么选SVG
思维导图和流程图的实现,我最初考虑的是Canvas(性能好想得美),但很快转向了SVG。原因很实际:
- 事件处理 :SVG的每个元素(节点、连线)都是DOM节点,可以直接绑定
click、drag事件。Canvas需要自己做碰撞检测,坐标转换非常复杂。 - 文本渲染 :SVG的
<text>标签自动处理字体、换行、对齐。Canvas的fillText在中文换行和度量上很弱。 - 缩放与导出:SVG是矢量格式,缩放不会模糊,导出成PNG也只需要序列化成字符串后交给Canvas绘制。
树形布局算法
思维导图最核心的不是绘图,是自动布局。我实现了一个简单的树形布局:
typescript
interface TreeNode {
id: string;
text: string;
children: TreeNode[];
x?: number;
y?: number;
width?: number;
height?: number;
}
// 计算每个节点的尺寸(基于文本内容)
const measureNode = (node: TreeNode): { w: number; h: number } => {
// 实际实现中基于DOM测量
return { w: node.text.length * 14 + 24, h: 36 };
};
// 简单的层序布局
const layoutTree = (root: TreeNode): void => {
const levelHeight = 80;
const siblingGap = 20;
const traverse = (node: TreeNode, level: number, startX: number): number => {
const size = measureNode(node);
node.width = size.w;
node.height = size.h;
if (!node.children || node.children.length === 0) {
node.x = startX;
node.y = level * levelHeight;
return startX + size.w + siblingGap;
}
let childX = startX;
for (const child of node.children) {
childX = traverse(child, level + 1, childX);
}
// 父节点水平居中于子节点群
const firstChild = node.children[0];
const lastChild = node.children[node.children.length - 1];
node.x = (firstChild.x! + lastChild.x! + lastChild.width!) / 2 - size.w / 2;
node.y = level * levelHeight;
return childX;
};
traverse(root, 0, 0);
};这个算法非常基础,对于复杂的思维导图(比如节点很多、层级很深)会不够用。后续我可能会引入更成熟的布局库,但对于目前80%的使用场景已经够了。
踩坑:中文输入与快捷键冲突
思维导图需要支持快捷键(Tab新建子节点、Enter新建兄弟节点、Delete删除)。但用户在编辑节点文本时,如果用的是中文输入法,Tab和Enter会被输入法拦截,导致快捷键不生效或者误触发。
解决方案:监听compositionstart和compositionend事件,在输入法编辑期间屏蔽快捷键。
typescript
let isComposing = false;
input.addEventListener('compositionstart', () => { isComposing = true; });
input.addEventListener('compositionend', () => { isComposing = false; });
window.addEventListener('keydown', (e) => {
if (isComposing) return; // 输入法编辑中,不处理快捷键
if (e.key === 'Tab') {
e.preventDefault();
addChildNode();
}
// ...
});
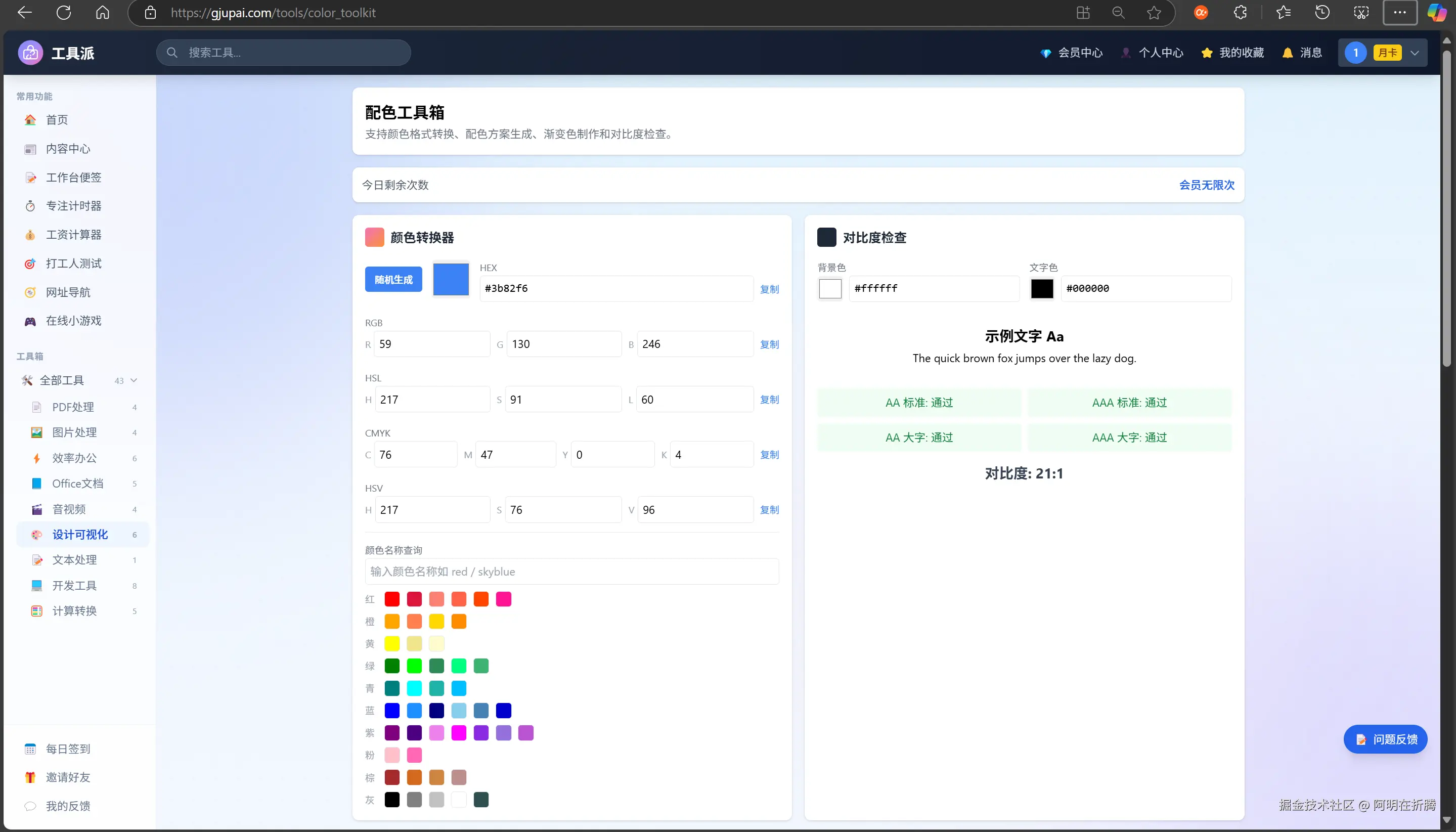
五、配色工具箱:HSL色彩空间的工程化应用
为什么用HSL而不是RGB
配色工具的核心是根据一个主色生成整套配色方案(互补色、近似色、三色搭配)。这个需求在RGB色彩空间里很难做,因为RGB是面向设备的,人类无法直观感知"把红色旋转180度"是什么意思。
HSL(色相、饱和度、亮度)更适合这个场景,因为:
- H(Hue):色相环上的角度,0°~360°。互补色就是相差180°,近似色就是±30°。
- S(Saturation):饱和度,0%~100%。
- L(Lightness):亮度,0%~100%。
RGB与HSL的互转
typescript
// RGB转HSL
const rgbToHsl = (r: number, g: number, b: number): [number, number, number] => {
r /= 255; g /= 255; b /= 255;
const max = Math.max(r, g, b), min = Math.min(r, g, b);
let h = 0, s = 0, l = (max + min) / 2;
if (max !== min) {
const d = max - min;
s = l > 0.5 ? d / (2 - max - min) : d / (max + min);
switch (max) {
case r: h = (g - b) / d + (g < b ? 6 : 0); break;
case g: h = (b - r) / d + 2; break;
case b: h = (r - g) / d + 4; break;
}
h /= 6;
}
return [h * 360, s * 100, l * 100];
};
// HSL转RGB
const hslToRgb = (h: number, s: number, l: number): [number, number, number] => {
h /= 360; s /= 100; l /= 100;
let r: number, g: number, b: number;
if (s === 0) {
r = g = b = l;
} else {
const hue2rgb = (p: number, q: number, t: number) => {
if (t < 0) t += 1;
if (t > 1) t -= 1;
if (t < 1/6) return p + (q - p) * 6 * t;
if (t < 1/2) return q;
if (t < 2/3) return p + (q - p) * (2/3 - t) * 6;
return p;
};
const q = l < 0.5 ? l * (1 + s) : l + s - l * s;
const p = 2 * l - q;
r = hue2rgb(p, q, h + 1/3);
g = hue2rgb(p, q, h);
b = hue2rgb(p, q, h - 1/3);
}
return [Math.round(r * 255), Math.round(g * 255), Math.round(b * 255)];
};生成配色方案
有了互转函数,生成配色方案就很简单了:
typescript
const generatePalette = (baseHex: string) => {
const rgb = hexToRgb(baseHex);
const [h, s, l] = rgbToHsl(rgb.r, rgb.g, rgb.b);
return {
complementary: hslToRgb((h + 180) % 360, s, l), // 互补色
analogous1: hslToRgb((h + 30) % 360, s, l), // 近似色1
analogous2: hslToRgb((h - 30 + 360) % 360, s, l), // 近似色2
triadic1: hslToRgb((h + 120) % 360, s, l), // 三色1
triadic2: hslToRgb((h + 240) % 360, s, l), // 三色2
light: hslToRgb(h, s, Math.min(l + 20, 95)), // 亮色变体
dark: hslToRgb(h, s, Math.max(l - 20, 10)), // 暗色变体
};
};渐变色生成
渐变生成器的需求是:给定两个颜色,生成一段平滑过渡的CSS渐变。难点在于等距采样------人眼对颜色的感知是非线性的,简单的RGB线性插值在某些色相区间会出现"发灰"的过渡带。
我的做法是:在HSL空间做插值,而不是RGB空间。这样色相的过渡会更自然。
写在最后
这五个功能的实现难度参差不齐:
- 截图美化:纯前端Canvas,核心难点是DPI适配,开发成本最低
- AI抠图:技术选型花时间最多,WASM方案用户体验需要精细打磨
- 图片压缩:前后端两套方案,前端负责轻量快速,后端负责大文件深度压缩
- 思维导图:SVG+自动布局,核心工作量在交互逻辑而非渲染
- 配色工具:纯算法,没有复杂交互,但色彩理论的工程化需要仔细验证
如果让我重新做一遍,我会在AI抠图上更早地引入后端降级方案。前端WASM虽然酷,但国内用户的网络环境和设备性能差异太大,纯前端方案覆盖面有限。
文中提到的这些功能都已经集成在我维护的在线工具站里,站名叫工具派,感兴趣的话可以去体验下。如果你也在做类似的功能,欢迎评论区交流实现细节。