作者:徐可甲
引子:Coding 变快了,组织为什么没跟上?
2026 年 5 月,Google Cloud DORA 团队发布了《ROI of AI-Assisted Software Development》。与前一年的《DORA Accelerate State of DevOps Report 2025》侧重个体采纳率不同,这份报告直接面向一个组织级问题:
"The question is no longer whether AI-assisted development works --- it's how to prove it to the business."
报告给出了一组模型数据:以一个 500 人工程团队为例,AI 工具年投入约 8.4M,预期回报11.6M,首年 ROI 约 39%。但这个收益并不是自动兑现的。DORA 明确指出,coding speed 的提升不会自动转化为组织产出:
"Initial gains in coding speed are promising, but they don't automatically translate to the bottom line."
报告引入了 J-Curve(先降后升曲线)概念来解释机制:团队在采纳 AI 工具的初期会经历一段生产力下降期 ------ 工作流适配、习惯切换、prompt 调优都是学习成本 ------ 只有度过这段谷底,并把回收的 capacity 重新投入减少 rework 而非直接削减人力,ROI 才会在曲线后段兑现。同时,DORA 延续了 2025 年报告的核心判断:
"AI is an amplifier, not a transformer. It magnifies strengths and dysfunctions."
数据显示 AI 在 greenfield 项目上可带来 35--40% 的效率增益,但在 legacy 代码上低于 10%。差异如此悬殊,意味着同一家公司内部不同团队的收益曲线可能完全不同。没有事件级度量能力的组织,连"自己的 J-Curve 走到了哪里"都无从判断。
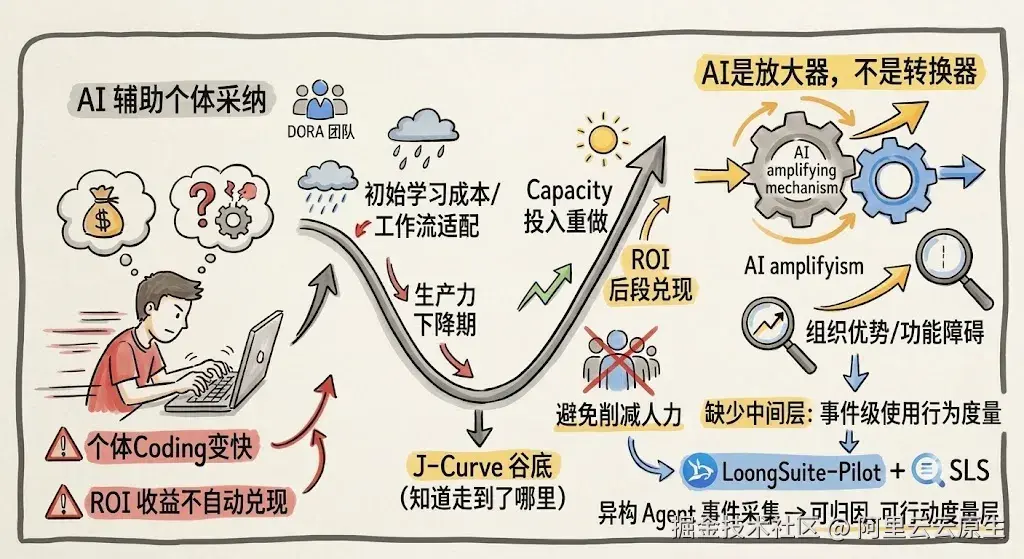
这正是当前多数研发组织的困境:手里只有两类数据 ------ 一类是个体自报的满意度问卷(主观、不可追溯),另一类是 CI/CD 流水线的聚合 KPI(告诉你 what,不解释 why)。真正缺的是中间那一层:事件级的、可下钻到 Agent / 模型 / Skill / 部门的 AI Coding 使用行为度量,让组织能精确回答"J-Curve 走到了哪里、哪些团队已经在曲线后段、哪些还在谷底"。
本文要介绍的 LoongSuite-Pilot × 阿里云日志服务 SLS 组合,正是这套度量层的工程落地:LoongSuite-Pilot 按 LoongSuite GenAI 语义规范(阿里云基于 OpenTelemetry GenAI semantic conventions 推出的扩展规范)统一采集异构 Agent 的事件流,SLS 看板把事件解释成可下钻、可归因、可行动的组织级度量。
数据接入层:从采集到 SLS 落地
在构建度量看板之前,首先要解决"数据从哪里来"的问题。
我们选择度量的不是"代码提交了多少行"或"PR 合并了多少个",而是 AI Coding Agent 的使用行为本身:谁用了什么 Agent、选了什么模型、消耗了多少 Token、调了哪些 Tool 和 Skill。
数据模型采用经典的事实表 + 维表分离设计,两张表通过 user.id 与 work_no 关联。事实表与维表分离,让度量层可以通过 JOIN 灵活叠加组织维度,而不需要在事件上报时嵌入组织信息。
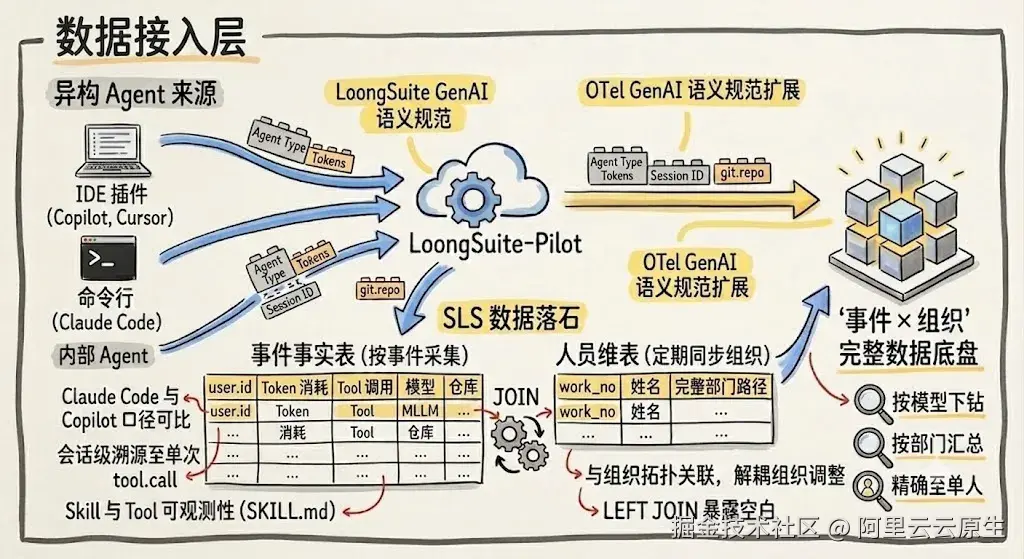
事件事实表:AI Coding Agent 行为日志
事实表是整张度量看板的核心数据源,每条记录对应一次 Agent 调用事件。核心字段包括:
- 用户标识:
user.id。 - 会话:
gen_ai.session.id。 - Agent / 供应商 / 模型:
gen_ai.agent.type、gen_ai.provider.name、gen_ai.request.model、gen_ai.response.model。 - Token 消耗:
gen_ai.usage.input_tokens、gen_ai.usage.output_tokens、gen_ai.usage.total_tokens。 - 工具调用:
gen_ai.tool.name、gen_ai.tool.call.arguments.file_path、event.name。 - 代码仓库:
git.repo、git.domain。
这些字段对齐 LoongSuite GenAI 语义规范。OTel GenAI semantic conventions 是业界公认的起点,但社区标准天然需要兼顾广泛适用性与长期稳定性,当前仍处于 Development 状态。而实际业务中 AI Agent 的调用链往往远比"单用户 × 单模型"复杂,一个请求可能跨越多个 Agent 的协同调用。
LoongSuite GenAI 语义规范正是在 OTel 社区标准基础上,结合大量实战场景沉淀而来的扩展规范,目前已正式开源,后续将逐步把优化能力贡献至社区上游。对齐这套规范带来的直接好处是:Claude Code、Copilot、Cursor、Qoder 以及各种内部 Agent 的上报口径天然一致,无需事后做字段对账。
这些事件通过 LoongSuite-Pilot 统一采集。LoongSuite-Pilot 不区分 Agent 来源和 IDE 形态,无论是命令行形态的 Claude Code,还是 IDE 插件形态的 Copilot / Cursor,都会落入同一张事实表。采集粒度是事件级的:每次 Agent 调用、每次 tool.call、每次 Token 消耗都作为独立事件上报,而不是按会话汇总后再上报。
事件级粒度带来三个工程价值:
第一,异构 Agent 可比性: 同一个 Token 在 Claude Code 与 Copilot 下的统计口径完全一致,做跨工具对比和汇总不需要任何口径转换。
第二,会话级溯源能力: 从 gen_ai.session.id 一直钻取到单次 tool.call,问题排查可以精确到"这个会话里第 3 次工具调用传了什么参数",而不是止步于"这个人上周 Token 高"。
第三,Skill 与 Tool 可观测性: gen_ai.tool.call.arguments.file_path 把工具调用关联到了具体的 SKILL.md 文件路径,让"团队沉淀的 Skill 有没有真的被用起来"变成了一个可量化的问题。
人员维表:组织关系映射
事件流解决的是"发生了什么",人员维表解决的是"谁在做",把事件中的用户标识映射到组织拓扑,让度量可以按部门、团队、人员下钻。维表定期同步到 SLS,核心字段是 work_no(工号)、show_name(姓名)、dept_name(完整部门路径,如 技术研发部-工程平台部-数据服务组)。
为什么必须把组织关系作为独立维表接入,而不是在事件上报时把部门信息一起打进事件?三个原因:
第一,解耦。 人员维表会随组织调整不断更新,而事件一旦上报就不应回溯修改,维表独立才能做到"按最新组织架构看历史数据"。
第二,LEFT JOIN 暴露空白。 维表中有但事件表中没有记录的员工,通过 LEFT JOIN + WHERE user_id IS NULL 就能直接列出"在册但未上报"的人,这份"在册但未上报"的名单往往比所有炫酷图表都更能推动落地。
第三,层级拆分一次完成。 把部门路径按层级拆成一级部门 / 二级部门 / 团队三层,所有下游图表只需 JOIN 维表即可获得完整组织维度,不需要每张图重复做拆分逻辑。
数据接入层回答的核心问题归结为三个:采什么(LoongSuite GenAI 语义事件)、怎么采(LoongSuite-Pilot 统一采集)、跟谁关联(人员维表)。三步完成后,SLS 里具备了"事件 × 组织"的完整数据底盘。
度量层:从公共 CTE 到可决策的 AI Coding Agent 度量看板
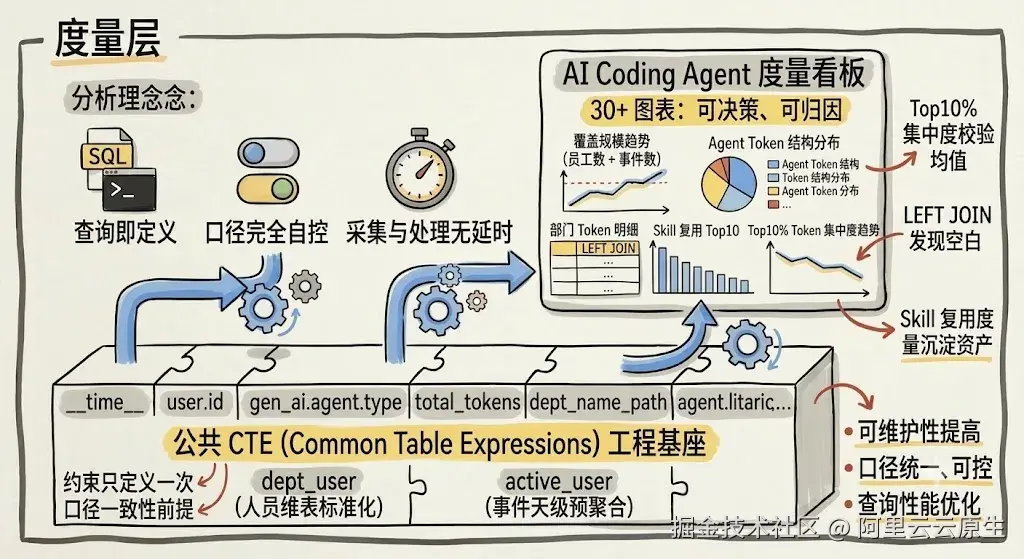
为什么选择 SLS 大盘做分析层?
有了数据底盘之后,下一步是选择分析载体。我们直接在 SLS 看板上用 SQL 构建整张度量大盘。选择这条路径的核心原因是灵活性。AI Coding 度量是一个口径高度因团队而异、需求快速迭代的场景,分析层必须给使用者足够的自由度。
第一,查询即定义。 SLS 看板的每张图表背后就是一条 SQL,需求变了改 SQL 即刻生效,不需要等待产品侧发版或做配置化支持。
第二,口径完全自控。 "什么算活跃用户""部门怎么拆""覆盖率分母取在册还是全员" ------ 这些口径选择因组织而异,没有标准答案,SLS SQL 让每个团队可以按自身业务特点灵活定义:你的组织按三级部门拆,我的按项目组拆;你的活跃定义是"过去 7 天有事件",我的是"过去 30 天且 Token > 1000"。这些差异在 SQL 层一行 WHERE 子句就能表达。
第三,采集与分析同平台。 事件落到 SLS 立即可以被查询,没有额外的 ETL 链路、没有 T+1 延迟。比如刚接入一个新 Agent,上线后几分钟就能在看板上确认数据是否正常流入,验证闭环极短。
灵活性确立之后,接下来的问题是:30+ 图表如何保持口径一致?
公共 CTE:报表的工程骨架
灵活性解决了"能不能改"的问题,但一张有 30+ 图表的看板如果每张图各写各的 SQL,口径不一致和维护成本会迅速失控。因此工程核心在于分析层次的设计:从口径定义、到预聚合、到维度递进、再到具体图表,每一层都为下一层服务。
整张看板的所有图表共享同一组公共 CTE(Common Table Expressions)。这不是 SQL 技巧,而是整张报表能做到"口径一致、可维护、性能可控"的工程前提。
CTE 1:dept_user(人员维表标准化)
sql
WITH dept_user AS (
SELECT
work_no,
show_name,
COALESCE(SPLIT_PART(dept_name, '-', 1), '') AS dept_name_1, -- 一级部门,如"技术研发部"
COALESCE(SPLIT_PART(dept_name, '-', 2), '') AS dept_name_2, -- 二级部门,如"工程平台部"
COALESCE(SPLIT_PART(dept_name, '-', 3), '') AS dept_name_3 -- 团队,如"数据服务组"
FROM <dept-logstore>
GROUP BY work_no, show_name, dept_name
)这段 CTE 的核心是把完整部门路径(如 技术研发部-工程平台部-数据服务组)拆成三级层次结构(一级部门 / 二级部门 / 团队)。"统计范围"这一口径约束只在此处定义一次,所有下游图表通过 JOIN 自动继承。
CTE 2:active_user(事件预聚合)
sql
active_user AS (
SELECT
date_trunc('day', __time__) AS t,
"user.id" AS user_id,
coalesce(nullif("gen_ai.agent.type", 'null'), 'unknown') AS agent_type,
coalesce(nullif("gen_ai.provider.name", 'null'), 'unknown') AS provider,
coalesce(nullif("gen_ai.request.model", 'null'),
nullif("gen_ai.response.model", 'null'), 'unknown') AS model,
sum(coalesce("gen_ai.usage.input_tokens", 0)) AS input_tokens,
sum(coalesce("gen_ai.usage.output_tokens", 0)) AS output_tokens,
sum(coalesce("gen_ai.usage.total_tokens", 0)) AS total_tokens,
count(1) AS events
FROM <events-logstore>
GROUP BY t, user_id, agent_type, provider, model
)这段 CTE 按 天 × 用户 × Agent × 供应商 × 模型 五维预聚合,产出 Token 和事件数。预聚合的关键收益在于:绝大多数图表直接复用 active_user JOIN dept_user,不需要每张图重复写聚合逻辑。
两表 JOIN 约定
css
FROM dept_user d
JOIN active_user a ON d.work_no = a.user_idCTE 层的设计质量决定了整张大盘的三个基本面:口径一致性(约束只定义一次)、可维护性(改一处 CTE,所有图表自动生效)、查询性能(预聚合减少了下游 SQL 的扫描量)。后面展开的 8 个 Section,绝大多数直接复用 CTE 作为数据源;少数需要更细粒度的图表(如 Skill 路径提取、仓库维度聚合)则退回原始事件表单独查询------但即便如此,人员维表的 JOIN 逻辑仍然复用 dept_user,保持口径一致。
分析维度递进
度量看板的 8 个 Section 不是随意堆砌的图表,而是按分析层次递进设计的:
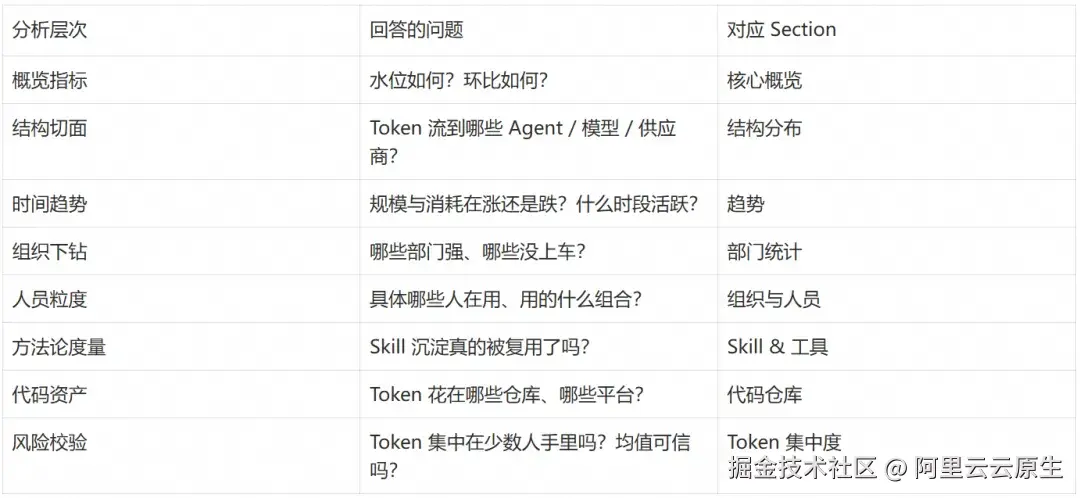
从"整体感知"到"结构拆解"再到"风险校验",每一层都在为更细粒度的分析提供上下文。
以下截图中的数据均为模拟数据,用于说明报表结构和分析逻辑,不代表真实业务数据。
Section 1:核心概览
顶部一组对比卡片是整张大盘的"水位计":使用员工数、总 Token、会话数、Agent 事件数、人均 Token、未上报员工数,每张都带"较上周同期"环比。这些卡片把"用了多少"这个问题从个人感知推到组织层面------现在有多少人已经在用、整体用量本周比上周是涨是跌。
环比异常的卡片就是下钻入口:哪个指标掉了,就去对应 Section 找原因,让管理者的决策有据可循而不是凭直觉。

要让环比数字可靠,环比计算需要绕过一个坑:compare() 与跨表 CTE JOIN 不兼容、会直接报错,因此改为手动分窗:
vbnet
time_base AS (
SELECT max(__time__) AS t_max FROM <事件表>
),
cur_agg AS (
SELECT "user.id" AS user_id, count(*) AS events
FROM <事件表>
WHERE __time__ >= (SELECT t_max - 604800 FROM time_base)
GROUP BY "user.id"
),
prev_agg AS (
SELECT "user.id" AS user_id, count(*) AS events
FROM <事件表>
WHERE __time__ >= (SELECT t_max - 1209600 FROM time_base)
AND __time__ < (SELECT t_max - 604800 FROM time_base)
GROUP BY "user.id"
)
-- 分别 JOIN dept_user 聚合后计算环比
SELECT
cur.cnt AS "当前值",
CASE WHEN prev.cnt > 0
THEN round((1.0 * cur.cnt / prev.cnt - 1) * 100, 2)
END AS "较上周(%)"
FROM cur, prevSQL 更长,但在"CTE + JOIN"架构下是唯一稳定的写法。
Section 2:结构分布
三张饼图分别按 agent_type、model、provider 切 Token 占比,回答的是组织层面的资源配置问题:哪个 Agent 在挑大梁、Token 集中在一家供应商还是分散在多家、团队主力模型是什么。答案直接决定工具是否需要收敛、供应商如何集采、成本怎么归集。
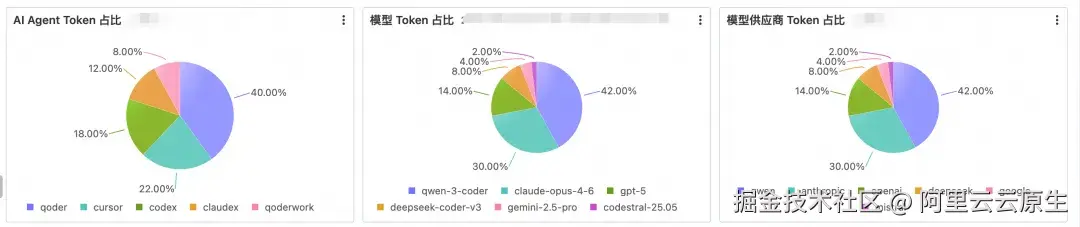
这些决策所需的数据,得益于 CTE 基座变得非常轻量:三张图都跑在 dept_user JOIN active_user 上,仅 GROUP BY 字段不同:
vbnet
SELECT
a.agent_type AS "AI Agent",
sum(a.total_tokens) AS "总Token"
FROM dept_user d
JOIN active_user a ON d.work_no = a.user_id
GROUP BY a.agent_type
ORDER BY "总Token" DESC预聚合让每张图表只需关心自己的 GROUP BY 维度,model、provider 版本只是换一个字段。
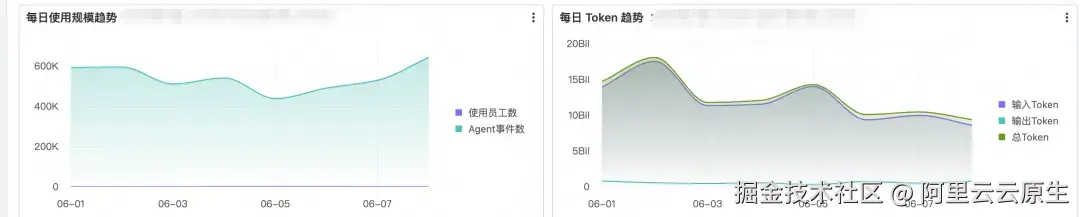
Section 3:趋势
趋势图把"现状"延伸为"走向":覆盖规模趋势(员工数 + 事件数双线)、Token 消耗趋势(input / output / total 三线)、各 Agent 的事件与 Token 走势(按 agent_type 分组),以及 Token 使用时段分布。
AI 工具的使用规模是在稳步增长还是一波推广后回落、特定 Agent 是日益重要还是逐渐被替代,这些判断只能从趋势中来。时段分布则给出工作节奏的侧写------如果 Token 集中在凌晨,说明 AI 自动化任务的占比在提高,这与工作时段内人工交互驱动的使用是两种完全不同的模式,管理动作也不同。

多数折线图直接复用 active_user 的天粒度 GROUP BY a.t 即可,但时段分布是个例外,active_user 已经 date_trunc('day', __time__),小时维度被丢掉了。要还原小时分布,必须绕过 CTE,另起一个 hourly_user 独立聚合:
vbnet
hourly_user AS (
SELECT
date_format(__time__, '%H:00') AS h,
"user.id" AS user_id,
sum(coalesce("gen_ai.usage.total_tokens", 0)) AS total_tokens
FROM <事件表>
GROUP BY h, user_id
)
SELECT a.h AS t, sum(a.total_tokens) AS "tokens"
FROM dept_user d
JOIN hourly_user a ON d.work_no = a.user_id
GROUP BY a.h
ORDER BY t这是"下游图表需要比 CTE 更细粒度"时的典型回退路径。
Section 4:部门统计
部门统计把视角从个体切到团队。部门 Token 明细表(部门、总人数、使用人数、覆盖率%、事件数、输入/输出/总 Token、人均 Token)配"未正常上传统计数据的员工列表",再叠 Top10 水平柱图分别按总 Token、覆盖率、人均 Token 排序。
三个维度指向三种不同的行动:规模低的需要推广,覆盖率低的需要从"个别尝鲜"推进到"团队标配",人均低的可能需要优化工具配置或改进使用方式。
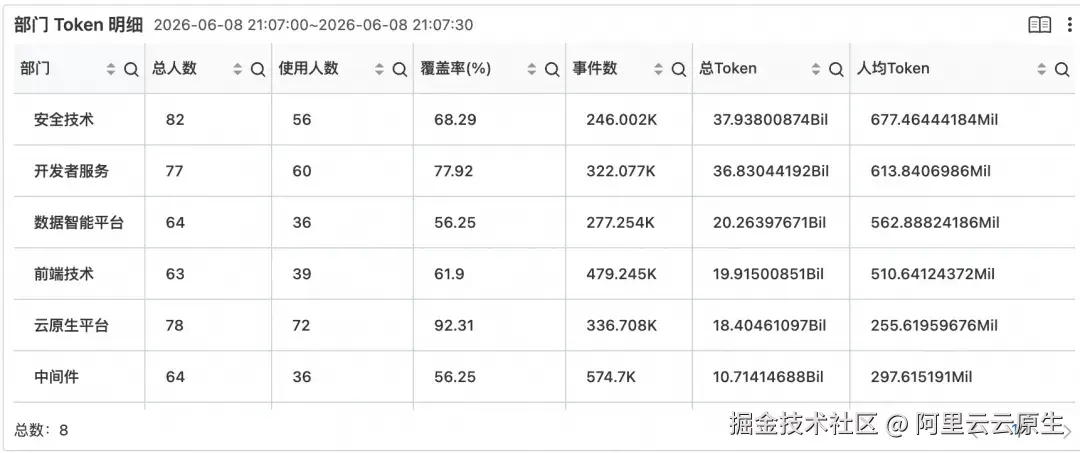
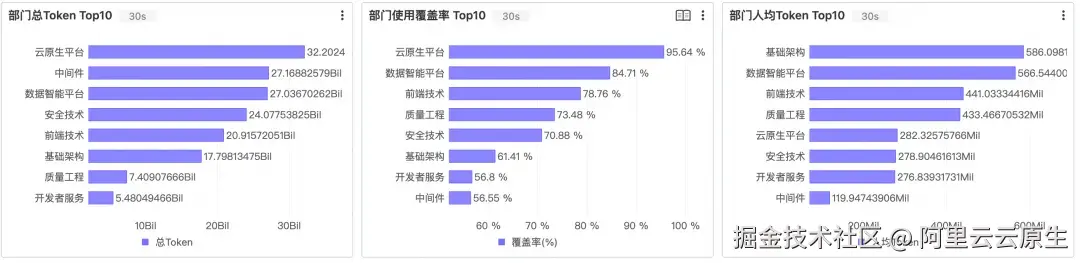
要让这些排名有意义,"使用人数为 0"的部门不能被过滤掉,它们恰恰是推广的目标。因此明细表用 LEFT JOIN 而非 INNER JOIN:
vbnet
SELECT
d.dept_name_2 AS "部门",
approx_distinct(d.work_no) AS "总人数",
approx_distinct(a.user_id) AS "使用人数",
round(100.0 * approx_distinct(a.user_id) / nullif(approx_distinct(d.work_no), 0), 2) AS "覆盖率(%)",
sum(a.total_tokens) AS "总Token",
round(1.0 * sum(a.total_tokens) / nullif(approx_distinct(a.user_id), 0), 2) AS "人均Token"
FROM dept_user d
LEFT JOIN active_user a ON d.work_no = a.user_id
GROUP BY d.dept_name_2
ORDER BY "总Token" DESCLEFT JOIN 让"使用人数为 0"的部门保留在表里,不会被 INNER JOIN 静默过滤;"未上报"列表则是同一份 JOIN 加 WHERE a.user_id IS NULL。一个 JOIN 同时支撑了"规模排名"和"空白发现"两类输出,后者往往比前者更能推动组织行动。
Section 5:组织与人员
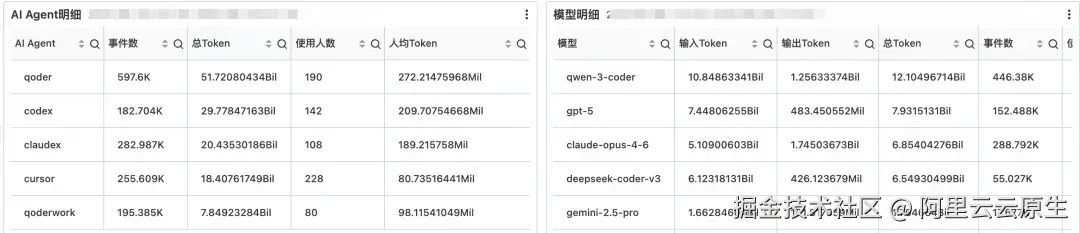
这一节从"部门"穿透到"个人":员工 Token 明细(姓名 / 工号 / 团队 / Token / 事件数 / 使用过的 Agent 与模型)、AI Agent 明细(按 agent_type 聚合的 Token 与员工数)、模型明细(按 model 聚合)。
"具体谁在用、用什么组合、用了多深"是团队负责人做一对一辅导和工具推荐的事实基础;AI Agent / 模型明细则把个体行为聚合为工具画像,反哺工具选型和最佳实践沉淀。
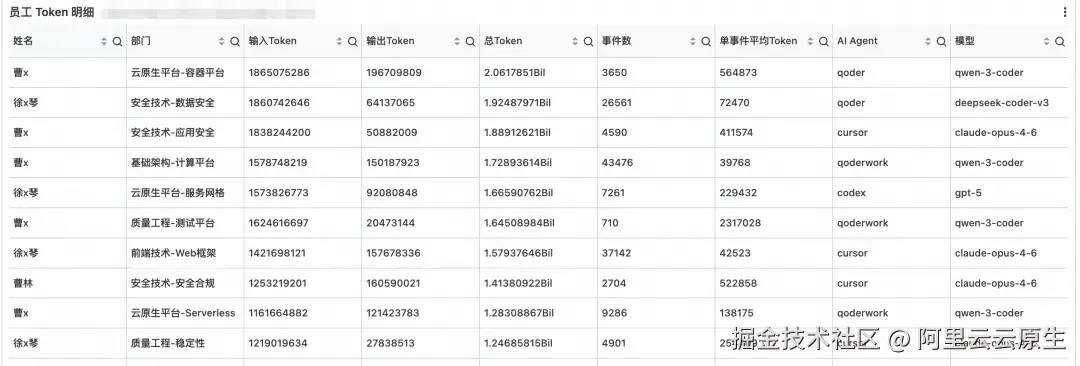
既然要看"一个人用了哪些 Agent / 模型",就需要把多值聚合成可读字段。常见写法用 array_agg(DISTINCT ...) 即可,但要让周报对比不产生噪声,必须再套一层 array_sort 保证输出顺序稳定。少了这一步,导出的 CSV 在两次 Diff 之间会因数组元素顺序随机抖动产生大量噪声。
sql
SELECT
d.show_name AS "姓名",
d.work_no AS "工号",
d.dept_name_2 AS "团队",
sum(a.total_tokens) AS "总Token",
sum(a.events) AS "事件数",
round(1.0 * sum(a.total_tokens) / nullif(sum(a.events), 0), 2) AS "单事件平均Token",
array_join(array_sort(array_agg(DISTINCT a.agent_type)), ', ') AS "AI Agent",
array_join(array_sort(array_agg(DISTINCT a.model)), ', ') AS "模型"
FROM dept_user d
JOIN active_user a ON d.work_no = a.user_id
GROUP BY d.show_name, d.work_no, d.dept_name_2
ORDER BY "总Token" DESCSection 6:Skill & 工具
Skill 调用次数、Skill 使用人数、Tool 调用次数三个 Top10 柱图构成了整张大盘里最具特色的一段。调用次数看单个 Skill 被使用的强度,使用人数看它在团队中的传播广度------两个数同时高的 Skill 才是真正沉淀为组织资产的方法论;只有调用次数高、使用人数低的,仍停留在个人探索阶段。
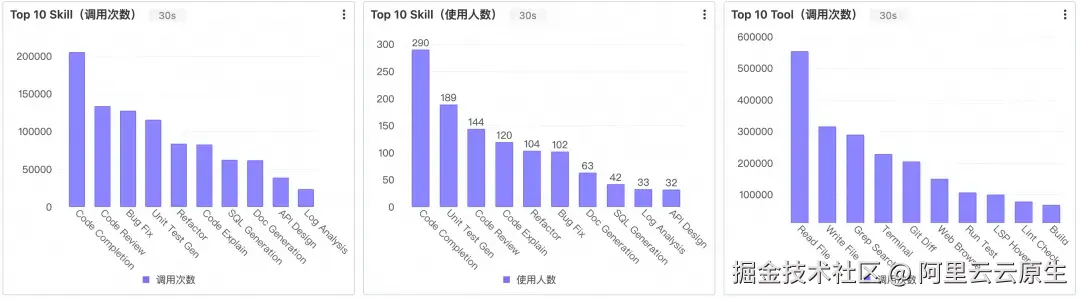
不过要得到这些排名,首先得从文件路径中还原 Skill 名,这本身就是这个 Section 最核心的 SQL 逻辑。SKILL.md 在历史目录结构下花样很多(skills/<name>/SKILL.md、skills/<name>/v1.2/SKILL.md、.qoderwork/<name>.skill.md),提取规则如下:
sql
SELECT skill_name AS "Skill", count(1) AS "调用次数"
FROM (
SELECT
CASE
-- 候选是版本号 → 向上再取一段目录名
WHEN regexp_like(regexp_extract(path, '/([^/]+)/[^/]+$', 1), '^v?[0-9]+\.[0-9]+')
THEN regexp_extract(path, '/([^/]+)/v?[0-9][^/]*/[^/]+$', 1)
-- 候选是容器目录名 → 从文件名提取,去掉后缀
WHEN lower(regexp_extract(path, '/([^/]+)/[^/]+$', 1))
IN ('skills','skill','.claude','agents','resources','.qoderwork','docs')
THEN regexp_replace(regexp_extract(path, '/([^/]+)$', 1), '(?i)(\.skill)?\.md$', '')
-- 默认:取倒数第二段目录名
ELSE regexp_extract(path, '/([^/]+)/[^/]+$', 1)
END AS skill_name
FROM <事件表> t
JOIN dept_user d ON t."user.id" = d.work_no
WHERE regexp_like(t."gen_ai.tool.call.arguments.file_path",
'(?i)(/SKILL\.md|/[^/]+\.skill\.md)$')
)
WHERE skill_name IS NOT NULL AND skill_name <> '' AND upper(skill_name) <> 'SKILL'
GROUP BY skill_name
ORDER BY "调用次数" DESC LIMIT 10整段绕过 active_user、直接 JOIN 原始事件表,因为 gen_ai.tool.call.arguments.file_path 不在 CTE 里。
Section 7:代码仓库
如果说 Skill 回答了"方法论有没有复用",仓库回答的是"AI 辅助编码的投入到底流向了哪些代码资产"。Repo Token Top10 横向柱图和 Git Domain Token 占比饼图给出两个维度:Token 是集中流向核心业务仓库,还是散落在实验性项目;主要消耗在内部 GitLab(受控资产)还是外部 GitHub(边界外代码)。
这两个分布直接服务于"AI 投入是否与组织战略对齐"的判断。
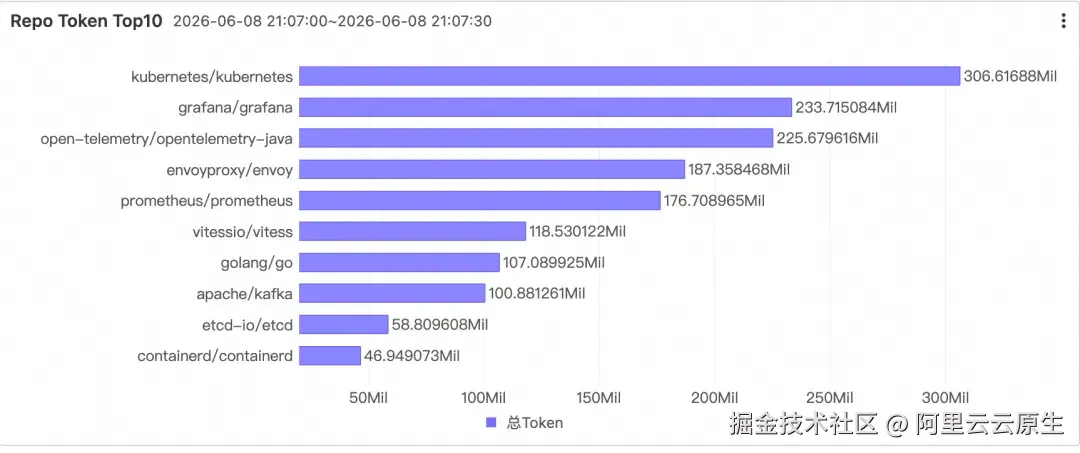
要支撑这个视角,需要解决一个架构取舍:git.repo 与 git.domain 不能进入 active_user CTE。把仓库加进 GROUP BY,CTE 行数会从"人 × 天"膨胀到"人 × 天 × 仓库",反而拖慢全部下游图表。所以这里退回到原始事件表单独聚合:
sql
SELECT
coalesce(nullif(t."git.repo", ''), 'unknown') AS "仓库",
sum(coalesce(t."gen_ai.usage.total_tokens", 0)) AS "总Token"
FROM <事件表> t
JOIN dept_user d ON t."user.id" = d.work_no
WHERE t."git.repo" IS NOT NULL AND t."git.repo" != ''
GROUP BY "仓库"
ORDER BY "总Token" DESC LIMIT 10这是"哪些维度该进 CTE、哪些该让出"的一个范例:通用预聚合不是越宽越好。
Section 8:Token 集中度
集中度是对前面所有"总量"指标最直接的校验。当 Section 1 的"人均 Token"看起来很漂亮时,必须追问------是全员普惠,还是头部少数人撑起来的均值。如果 Top10% 的人占了 70% 以上 Token,那么即使总量很大,组织仍停留在"少数人的个人生产力"阶段。
数值卡片(Top10% / Top20% Token 占比)、人群分层柱图(Top10% / 10--20% / 后 80% 三个桶)、每日集中度趋势线,合起来回答"集中度在变好还是恶化"。集中度持续下降,才意味着 AI Coding 正在从个人扩散为组织的共同能力。
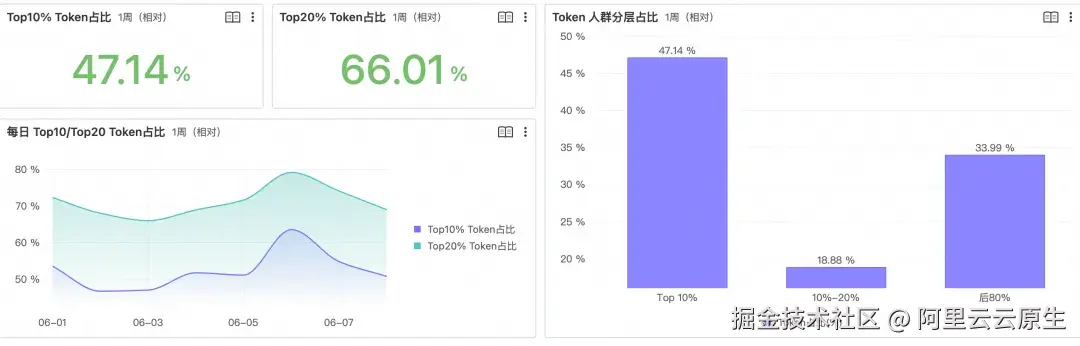
实现这个判断的关键是用 window function 排名后按百分位切桶:
sql
user_token AS (
SELECT a.user_id, sum(a.total_tokens) AS total_tokens
FROM dept_user d
JOIN active_user a ON d.work_no = a.user_id
GROUP BY a.user_id
HAVING total_tokens > 0
),
ranked AS (
SELECT user_id, total_tokens,
row_number() OVER (ORDER BY total_tokens DESC) AS rn,
count(*) OVER () AS user_count,
sum(total_tokens) OVER () AS all_tokens
FROM user_token
)
SELECT
round(100.0 * sum(CASE WHEN rn <= cast(ceil(user_count * 0.1) AS bigint)
THEN total_tokens ELSE 0 END)
/ max(all_tokens), 2) AS "Top10% Token占比"
FROM ranked每日趋势版本只多一个 PARTITION BY t,把"全局排名"变成"每天排名"。cast(ceil(user_count * 0.1) AS bigint) 保证了即使总人数不整除也能正确取到前 10% 的边界。
结语
本文给出的回答是一条三层递进的路径:
第一层:统一语义采集。 LoongSuite GenAI 语义规范解决了"用什么口径记录"的问题,LoongSuite-Pilot 解决了"从异构 Agent 中采出来"的问题。无论 Claude Code、Copilot 还是 Cursor,事件按同一套字段结构落入 SLS,跨工具可比、跨时间可追溯。
第二层:灵活分析。 SLS 大盘以 SQL 为唯一定义语言,口径完全自控、秒级可查。公共 CTE 作为工程基座,保证了 30+ 图表的口径一致性和可维护性。从概览到结构、从趋势到人员、从 Skill 复用到代码仓库再到 Token 集中度,8 个 Section 按分析层次递进,每一层都在为更细粒度的判断提供上下文。
第三层:组织可行动。 人员维表通过 LEFT JOIN 暴露"在册但未上报"的空白,集中度看板校验"人均指标是否被头部个体撑起来"。这些不是好看的数字,而是可以直接转化为行动的信号。
AI 是放大器。度量层的价值,就是让组织看清它在放大的究竟是什么,然后决定下一步往哪里走。
相关链接:
1 DORA: ROI of AI-Assisted Software Development --- Google Cloud
cloud.google.com/resources/c...
2 ROI of AI-Assisted Software Development report --- DORA.dev
3 LoongSuite GenAI 语义规范 --- GitHub
4 OpenTelemetry GenAI semantic conventions --- OpenTelemetry