文档数据库:
文档数据库的典型代表是MongoDB和CouchDB.文档数据库普遍采用JSON格式来存储数据.而不是采用僵硬的行和列结构.其好处是可以解决关系型数据库表结构扩展不方便的问题.以及可以存储和读写任何格式的数据.文档数据库与键值存储系统很类似.只不过存储的内容是文档信息.文档数据库具有很好的可扩展性.
适用场景:
数据量大.且数据增长很快的业务场景.
数据字段定义不明确.且字段在不断变化 无法统一的场景.比如商品参数信息存储.电子设备商品参数有内存大小 电池容量等.服装商品参数有尺码 面料等.
不适用场景:
需要支持事务.文档数据库无法保证在一个事务中修改多个文档的原子性.
需要支持复杂查询.例如.join语句.
列式数据库:
列式数据库的典型代表是BigTable HBase等.关系型数据库按照行来存储数据.所以它被称为行式数据库.而列式数据库按照列来存储数据.
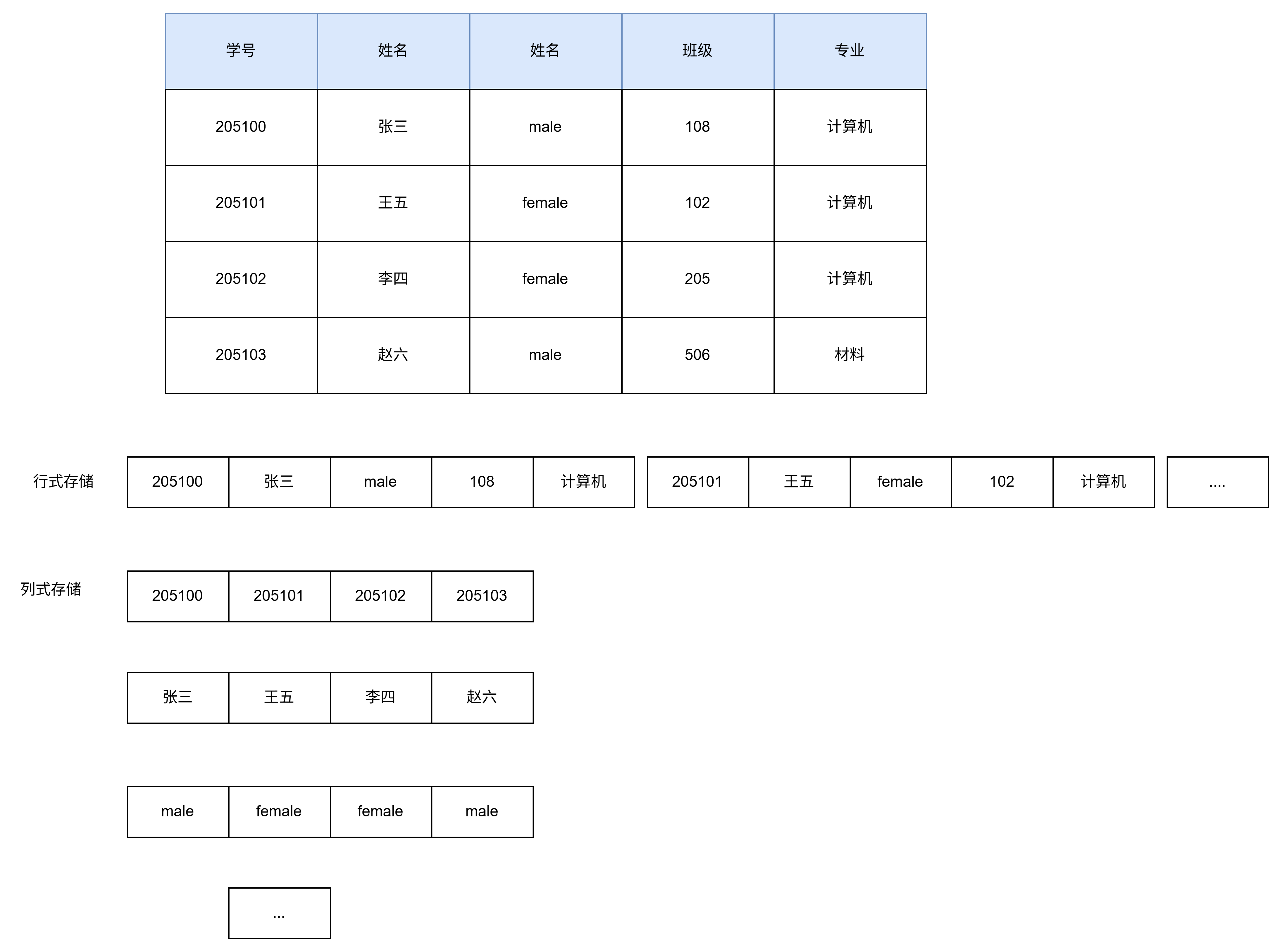
列式数据库将每一列的数据组织在一起.这样做有什么好处呢.假设现在要统计各专业的学生人数.如果使用行式数据库.那么首先需要将所有行的数据读取到内存.然后对专业列进行GroupBy操作得到结果.虽然只关注专业一列.但是其他列也参与了数据读取.磁盘I/O次数较多.而如果使用列式数据库.那么只需要将专业列数据读取到内存.磁盘I/O数大大减少.提高了查询效率.
列式数据库有很高的存储空间利用率.对于列数据类型是有限枚举(比如性别 专业)的情况.列式数据库可以通过字典将数据压缩.
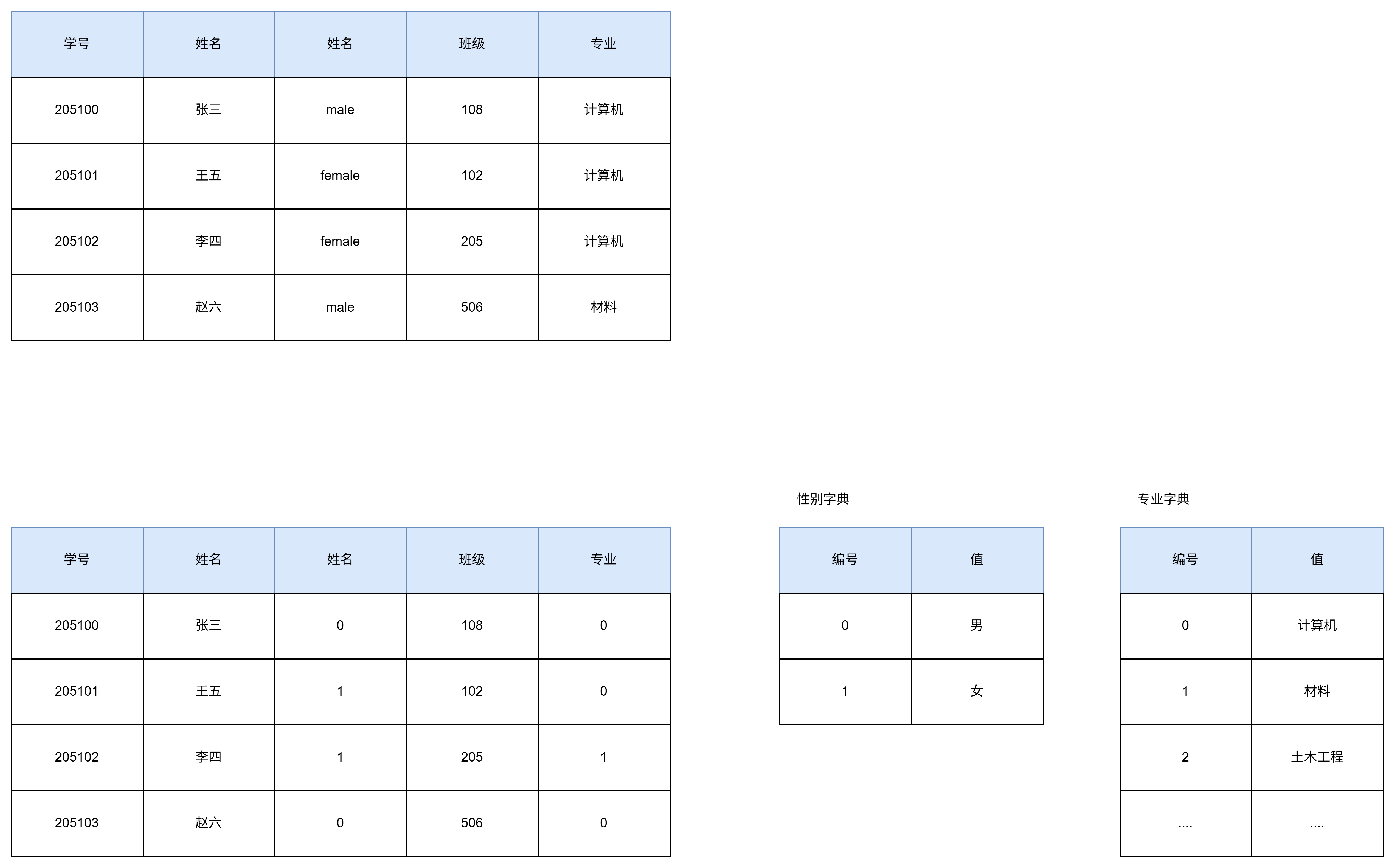
从图中可以看出.性别字典 专业字典分别使用了数字编号来代表原来的字符串.原始数据经过压缩后字符串变为数字.提高了存储空间利用率/且数据量越大.存储空间利用率越高.
适用场景:
有海量数据插入.但是数据修改极少的场景.比如用户行为收集.
数据分析场景.比如针对少数几列做离线数据统计工作.
不适用场景:
数据高频删除 修改的场景.即不适合直接服务于在线用户.
需要支持事务的场景.
全文搜索数据库:
全文搜素数据库的典型代表是Elasticsearch.关系型数据库在应对全文搜索场景时.只能通过Like语句进行模糊查询.而Like语句会扫描全量数据.效率非常低下.全文搜索数据的出现就是为了解决关系型数据库不支持高效全文搜索的问题.其基本原理是建立单词到文档的索引关系作为倒排索引.
倒排索引维护这每个关键词在哪些文档中出现过的文档列表.在进行全文搜索时.根据搜素关键词就可以直接获取到相关文档信息.文档列表既可以保存文档ID.也可以记录关键词在每个文档中出现的频率和位置.
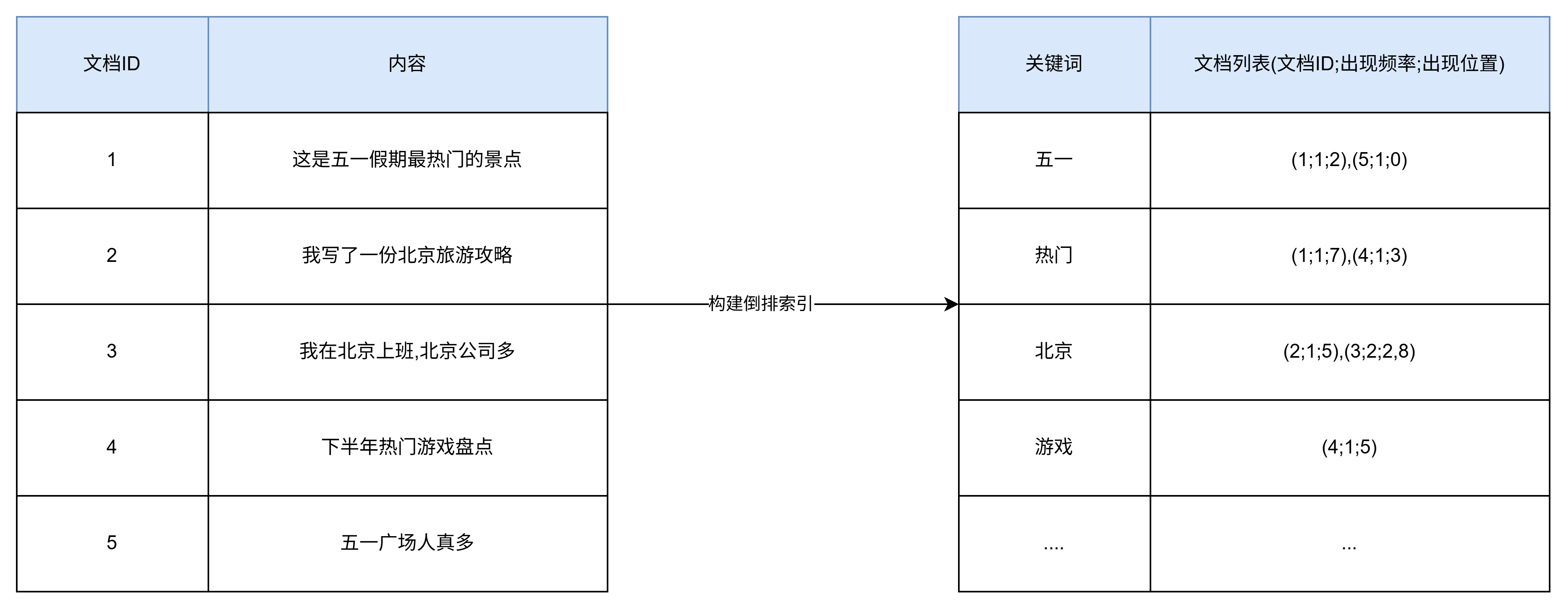
倒排索引非常适合根据关键词查询文档内容.所以在各种搜索场景中得到了广泛应用.
适用场景:
关键词搜素.如搜索引擎.
海量数据的复杂查询.
数据统计和数据聚合.
不适用场景:
高频更新数据的场景.在全文搜素数据库中.修改数据实际上是删除旧数据和创建新数据两步操作.
需要支持事务的场景.
图数据库:
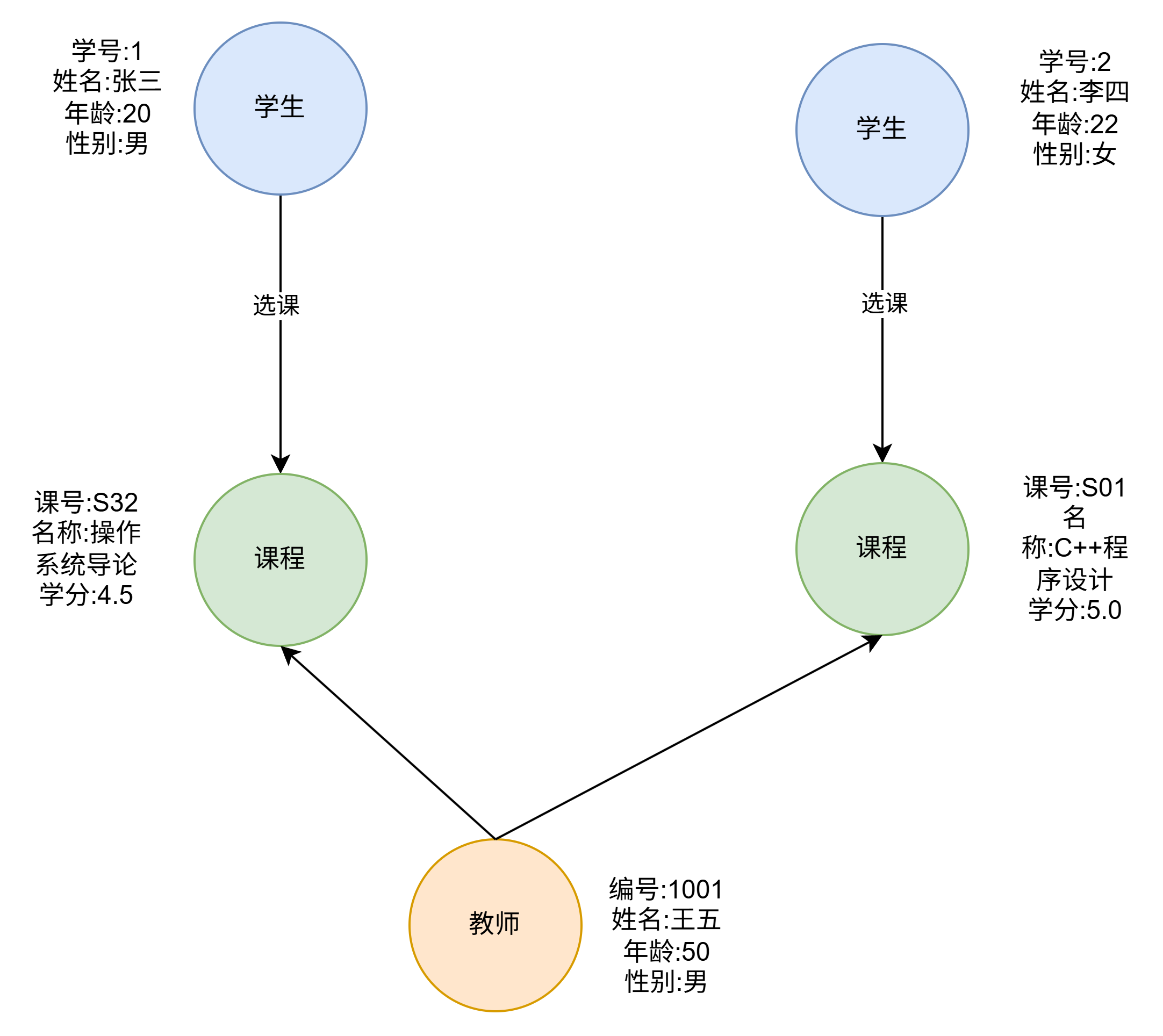
主要的开源项目有Neo4j Titan等.图数据指的并不是存储图片的数据库.而是以图这种数据结构存储数据的数据库.图由两个元素组成.节点和关系.其中.节点表示一个实体(人 商品等事物).关系表示两个节点之间的关联关系.关系在图数据库中占首要地位.它非常适合强调关系 需要复杂关系查询和分析的业务场景.比如社交网络 知识图谱等.
上述几种NoSQL数据库.虽然分别解决了关系型数据库无法实现高效处理的一些问题.但是也近乎丧失了关系数据库的强一致性 事务支持等特性.结合关系数据库及NoSQL数据库两者优点的数据库产生了.即NewSQL数据库.较为知名的项目包括Google Spanner TiDB CockroachDB等.
NewSQL底层依然采用了NoSQL存储数据.确切的说.NewSQL使用了分布式键值存储系统存储数据.而且在此基础上进行了很多革新.
键值存储系统采用了LSM Tree模型构建.可以大幅提升写数据性能.
放弃了NoSQL的主从复制模式.而是以更小粒度的数据分片作为高可用单位.主从分片之间通过Paxos或Raft等分布式共识算法进行数据复制.
采用分布式事务实现键值存储系统的事务能力.
NewSQL既保留了NoSQL可扩展性强的优势.又在此基础上提供了类似于关系型数据库的事务能力.换言之.NewSQL的本质就是在传统的关系型数据库上集成了NoSQL强大的扩展性.NewSQL的思想很好.作为数据库的后起之秀.正在进入越来越多的应用场景.但是目前NewSQL依然是小众产品.它在高并发 事务性上的表现还需要更多的表现.短期内难以完全替代关系型数据库和NoSQL数据库.
RPC服务:
一般来说.一个业务场景的核心逻辑都在RPC服务场景中实现的.强调的是服务于后台系统内部.所谓的微服务主要指的就是RPC服务.而HTTP服务强调的是与用户请求的交互.它做的主要工作一般比较简单.比如校验用户请求 打包响应数据.而用户请求真正的处理逻辑会被HTTP服务通过RPC请求交给RPC服务来执行.HTTP服务更像是业务服务层的网关.RPC对服务后台内部暴露RPC协议.而HTTP服务对后台外部暴露HTTP.
RPC的目标就是屏蔽网络编程的细节.能够像调用本地方法一样调用远程方法.让开发者更专注于业务逻辑本身.
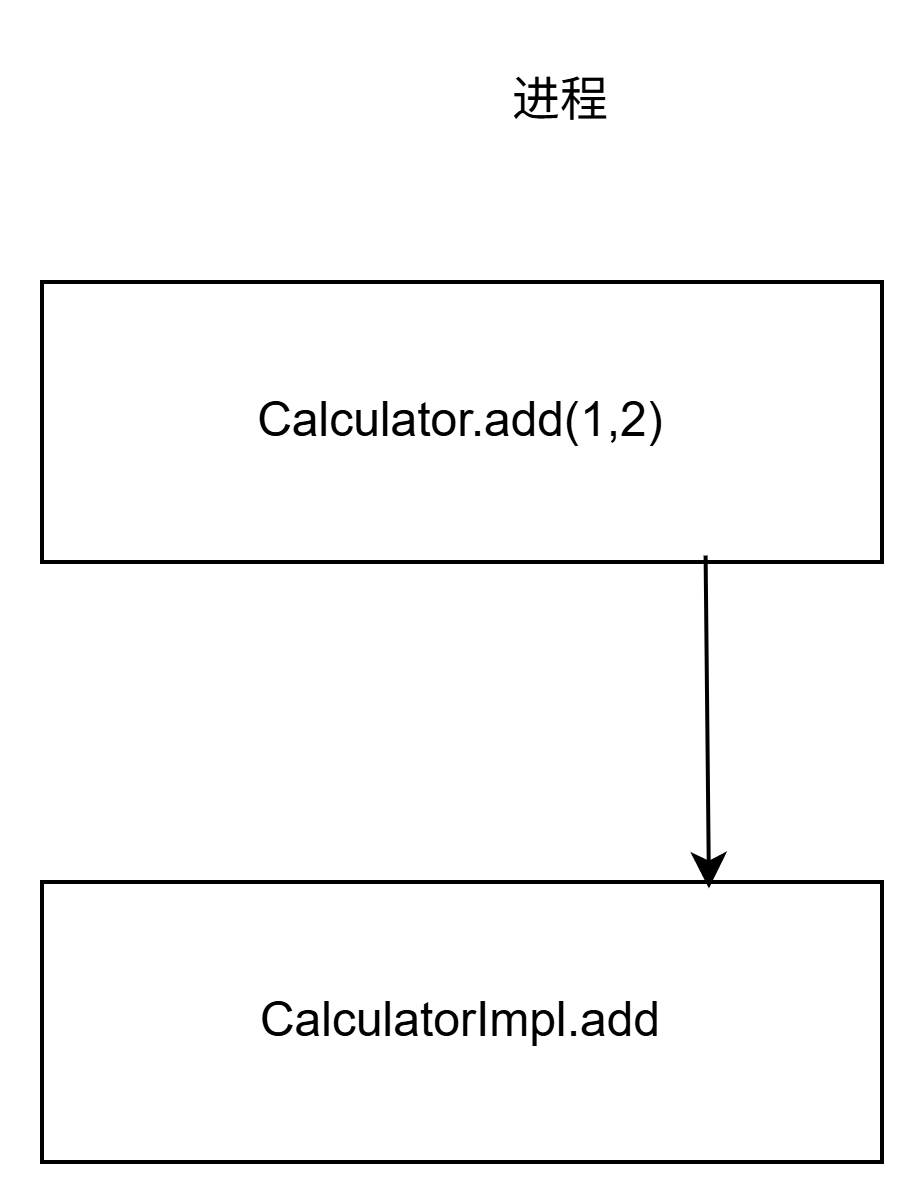
如图所示.在一个单体应用.假设有一个Calculator接口以及这个接口的实现类.那么调用add方法执行相加运算可以直接调用.这是因为CalcuatorImpl实现类和Calculator接口在一个进程中.这种形式可以直接本地调用.
现在将单体应用改为分布式应用.接口调用和实现分别在两个服务中.服务1中只有接口没有实现类.只能通过网络调用.服务2可以作为一台TCP服务器.服务1向其发送请求并接受响应.当它收到指定的数据包时调用add方法并将运算结果回传.服务2也可以作为一台HTTP服务器.对外提供Restful API.服务1发起HTTP请求调用此Restful API获取运算结果.
服务1发起远程调用来执行服务2的add方法.这样做已经很接近RPC了.不过每次服务1调用add方法的时候.都不得不编写一大段TCP或HTTP收发请求的代码.RPC框架通过代理模式将网络通信屏蔽.服务调用者仅需要本地过程调用一样调用一个RPC方法就能执行远程的方法.
RPC实质上就是调用方将调用方法和参数发送到被调用方.被调用方处理后将结果返回给调用方的过程.由于RPC底层实际上是网络通信.所以这里主要包括两个方面的工作.
方法的输入参数 输出参数都是对象.这些对象和二进制数据都可以相互转化.这个过程被称为序列化.
被调用方收到数据包.需要知道指定的方法名是什么.以及输入参数在数据包中的起始位置等.于是需要根据我们约定的协议格式对数据包解码.二进制数据与数据包可以互相转化.这个过程称为编解码.
调用方先将输入参数序列化.再将其编码为所约定的协议格式的数据包.然后通过网络发送给调用方.被调用方先将数据包解码.得到指定的方法名和序列化的输入参数.然后将输入参数反序列化.执行方法.最后通过与调用方调用相同的流程将结果返回给调用方.完整的RPC通信流程如图所示.
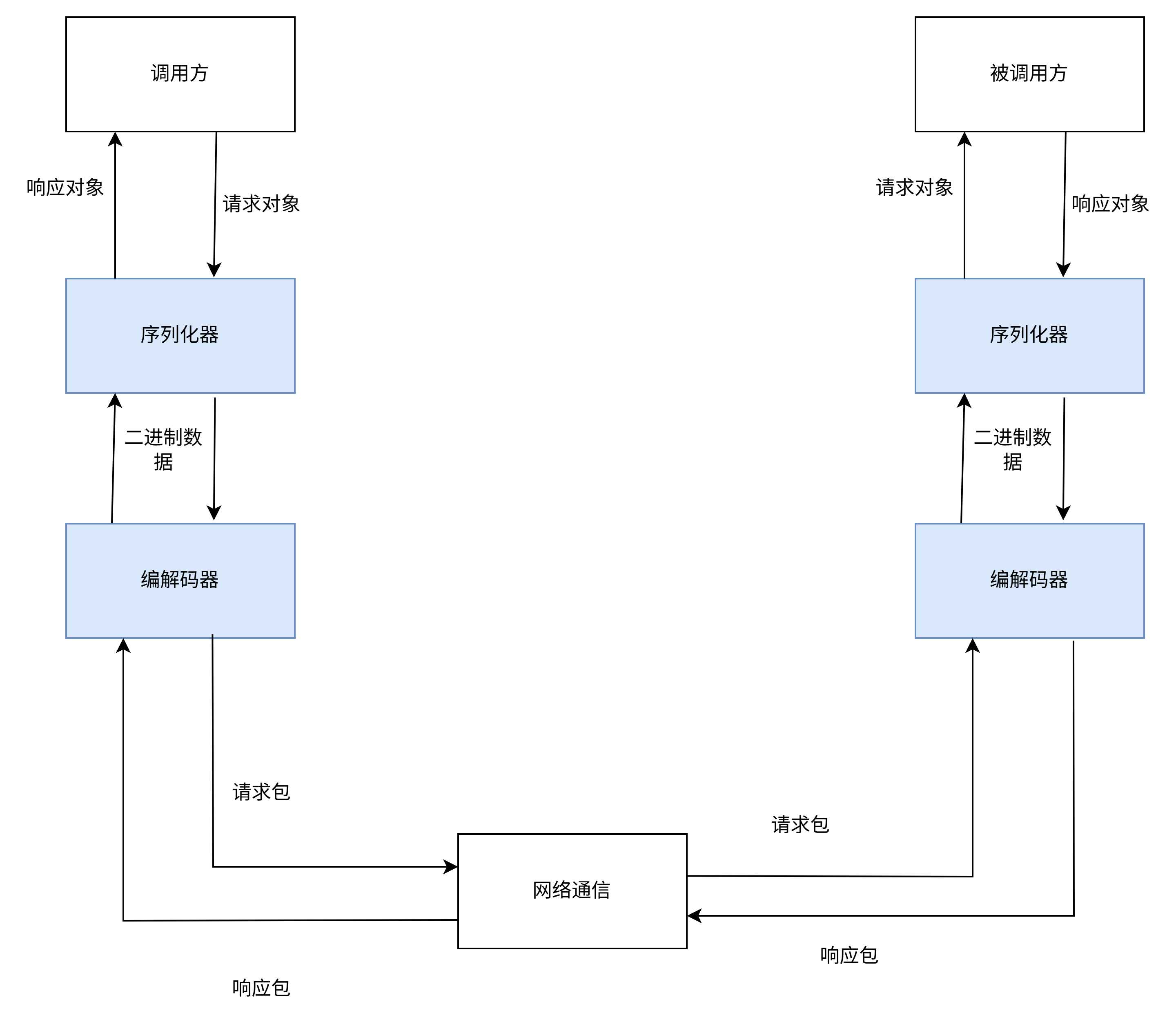
由于RPC通信流程相对固定.gRPC Thrift等RPC框架都可以利用所约定的协议定义文件生成脚手架代码.使用者只需要将具体的方法处理代码完成后就能实现RPC通信了.
从上述介绍可以看出.RPC是一种用于屏蔽远程过程调用的设计.它与HTTP不是对立的.因为两者不是一个层面的概念.RPC底层的网络通信可以使用TCP实现(Thrift).也可以使用HTTP实现(如gRPC).其本身并无限制.将业务服务层拆分为HTTP服务和RPC服务.更像强调的是前者服务于后台外部.后者服务于后台内部.即后台服务之间的通信使用RPC形式.所谓RPC协议只是表示RPC网络调用形式.而RPC服务的意思是该服务是基于gRPC Thrift或其他RPC框架生成的.后台内部可以通过RPC形式与其通信.
语雀地址https://www.yuque.com/itbosunmianyi/xg8vfe?
《Go.》 密码:xbkk 欢迎大家访问.提意见.