Harness Engineering(驭缰工程)
Harness Engineering(驭缰工程) 是 OpenAI 在 2026 年 2 月提出的工程范式:工程师不再写代码,而是设计环境、明确意图、构建反馈回路,让 AI 智能体可靠地完成工作。
「约束」(harness)一词已演变为一个简写,意指 AI 智能体中除模型本身之外的一切。
Agent = Model + Harness
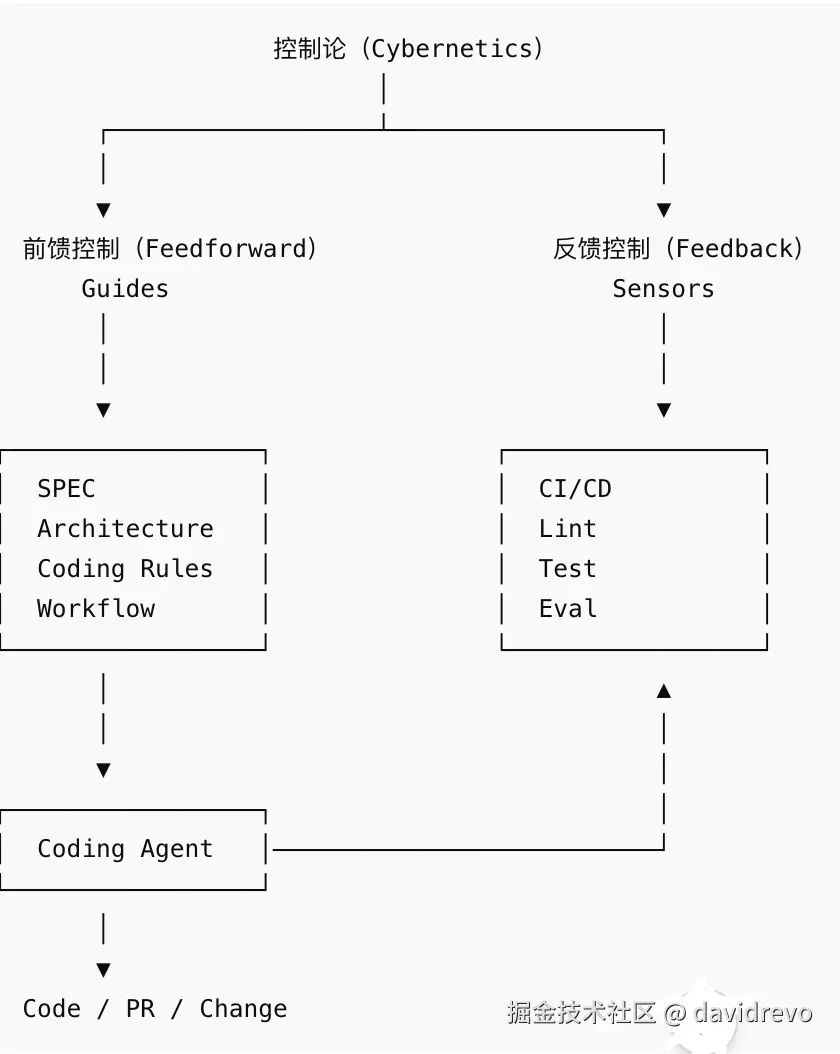
Harness Engineering(约束工程)是为 AI 编码智能体构建一套 "引导 + 反馈" 的控制系统,让智能体在更少人工监督下持续产生可信、高质量代码。Martin Fowler 团队认为:AI 编程的核心竞争力已经不再是模型本身,而是如何设计围绕模型运行的约束系统(Harness)。
未来 AI Coding 的重点将逐渐从:
Prompt Engineering
↓
Context Engineering
↓
Harness Engineering什么是 Harness(约束)
Harness 可以理解为:
- 规范
- 流程
- 工具链
- 检查机制
- 自动反馈系统
即:除了大模型本身之外,所有约束 AI 行为的东西。
例如:
- AGENTS.md
- Kiro Spec
- Claude Skills
- Cursor Rules
- MCP Server
- Linter
- Unit Test
- Architecture Test
- CI/CD Pipeline
- AI Code Review
都属于 Harness。
Harness 的两个核心组成
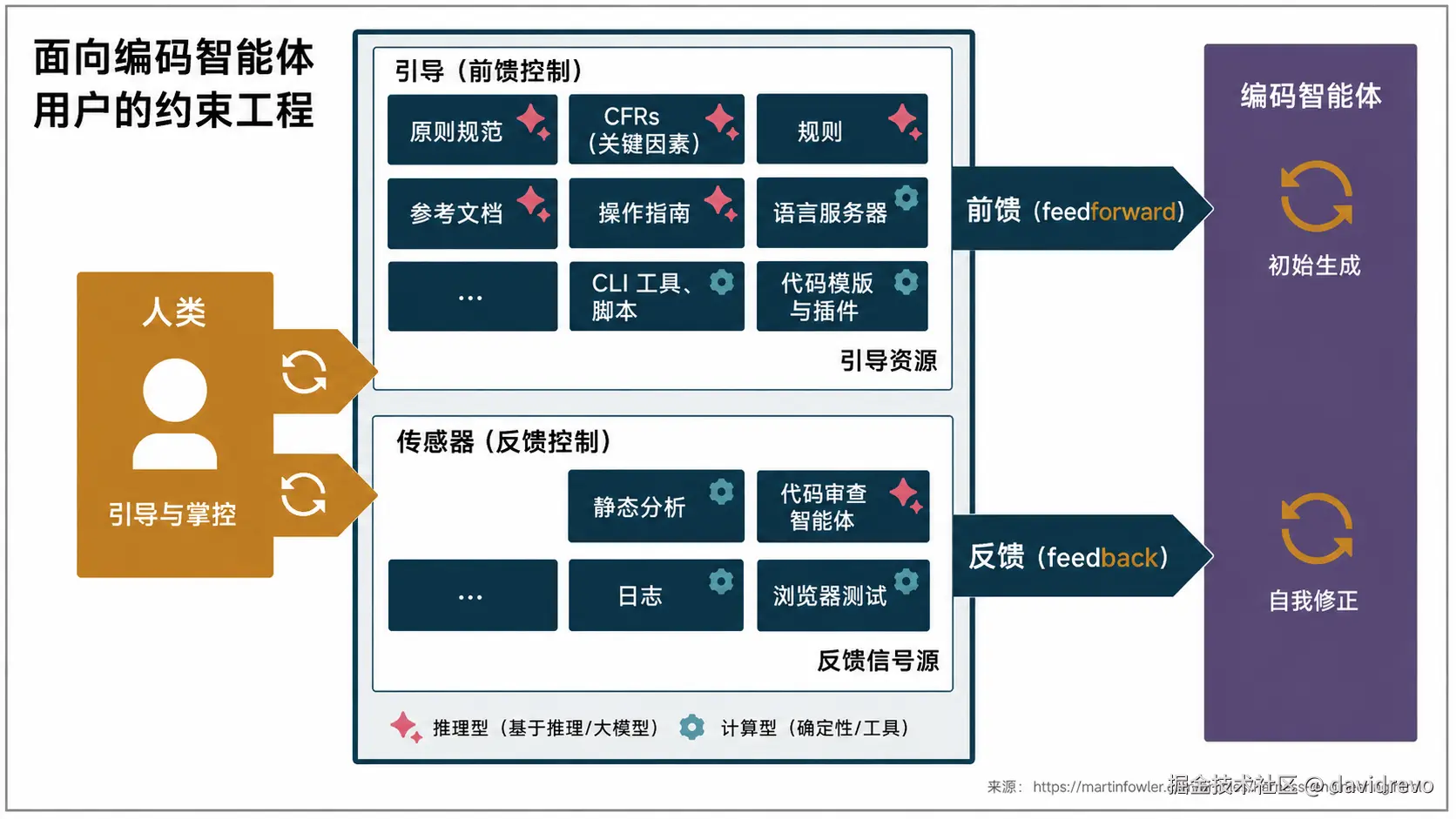
Feed Forward(前馈控制)
在 AI 写代码之前给予引导。
目的:
提高一次性生成正确代码的概率。
例如:
- Coding Rules
- AGENTS.md
- Spec 文档
- Architecture Guide
- Skills
典型流程:
需求
↓
Spec
↓
AI生成代码Feedback(反馈控制)
在 AI 写完代码之后自动检查。
目的:
让 AI 自己发现问题并修复。
例如:
- ESLint
- TypeScript
- Unit Test
- Mutation Test
- Architecture Test
- AI Code Review
流程:
AI生成代码
↓
自动检测
↓
发现问题
↓
AI修复
↓
重新检测约束工程的黄金公式
作者提出:
diff
高质量AI编码
=
前馈控制
+
反馈控制缺一不可。
只有前馈:
规则很多
但没人验证只有反馈:
不断修Bug
不断犯同样错误两类控制手段
计算型(Computational)
传统软件工程工具。测试、linter、类型检查器、结构分析。运行时间在毫秒到秒级;结果是可靠的。
特点:
- 快
- 便宜
- 准确
- 确定性
推理型(Reasoning)
利用 LLM 进行语义判断。语义分析、AI 代码审查、「LLM 作为裁判」。通常由 GPU 或 NPU 运行。更慢、更昂贵;结果更具非确定性。
特点:
- 慢
- 贵
- 非确定性
| 场景 | 方向 | 计算型/推理型 | 示例实现 |
|---|---|---|---|
| 编码规范 | 前馈 | 推理型 | AGENTS.md, Skills |
| 新项目启动说明 | 前馈 | 两者兼具 | 包含说明和启动脚本的 Skill |
| 代码改造 | 前馈 | 计算型 | 可访问 OpenRewrite recipes 的工具 |
| 结构测试 | 反馈 | 计算型 | 运行 ArchUnit 测试的 pre-commit hook |
| 审查说明 | 反馈 | 推理型 | Skills |
Steering Loop(引导循环)
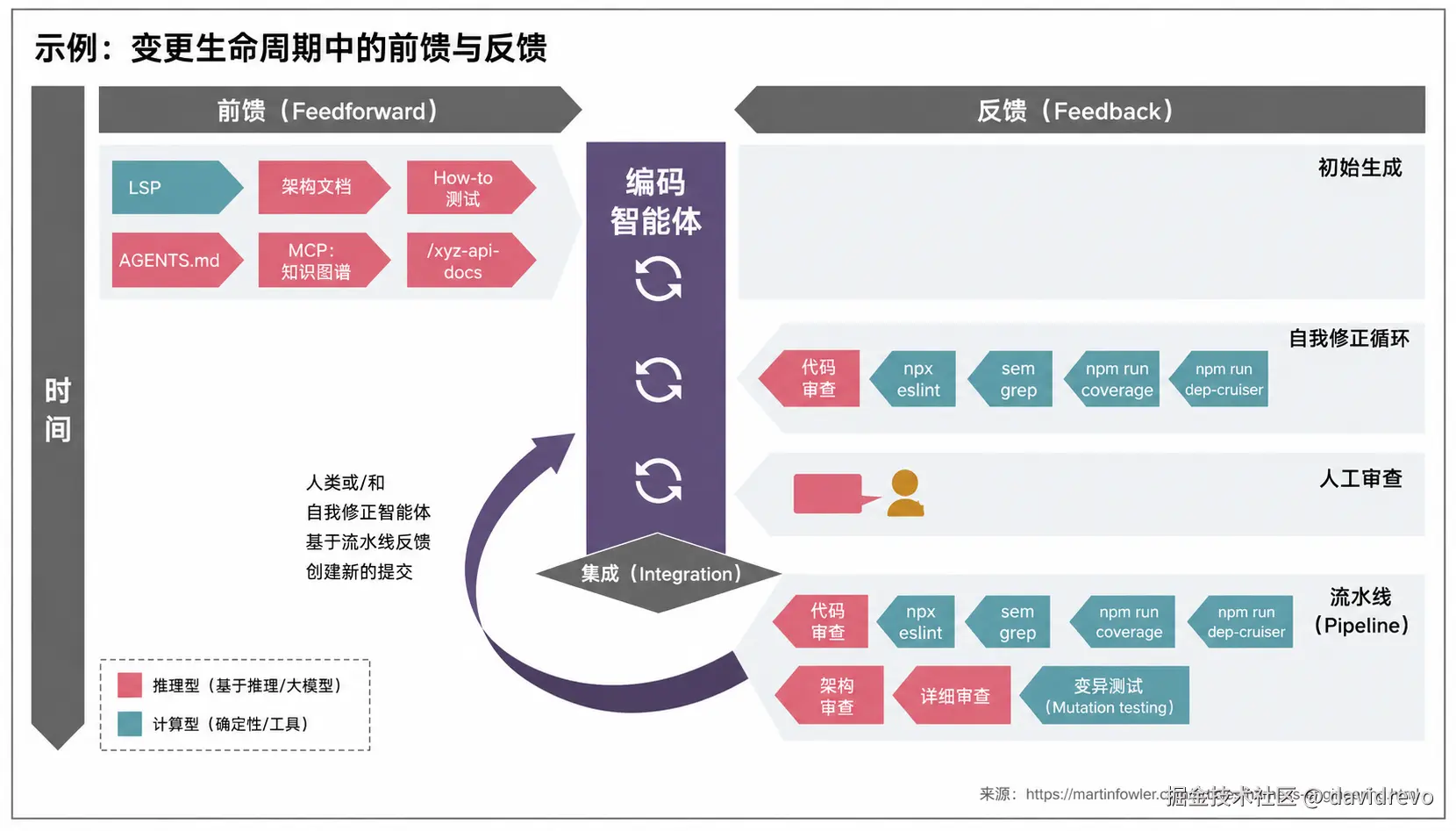
在这个模型中,人类的职责是持续"调优控制系统(harness)"来引导 AI agent 行为。
当某类问题反复出现时,就不只是修 bug,而是要:
- 优化 前置控制(feedforward)
- 优化 反馈机制(feedback)
目标是:
让同类问题在未来更不容易发生,甚至被直接预防。
在 steering loop 里,AI 不只是写代码,还可以帮助改进开发规则体系,例如:
- 生成结构化测试(structural tests)
- 从错误模式中提炼规则
- 自动生成静态检查工具(custom linters)
- 从代码库"考古"中总结开发规范(how-to guides)
👉 本质:AI 用来优化"约束系统",而不是只产出代码
Harness Engineering = Context Engineering 2.0
Martin Fowler 团队认为:
ini
Context Engineering
=
给AI上下文
Harness Engineering
=
给AI控制系统关系:
Harness
⊂
Context Engineering约束工程其实是上下文工程的高级阶段。
三大约束方向
① 可维护性约束
目标:
代码质量例如:
- 重复代码检测
- 复杂度检测
- 测试覆盖率
- 风格检查
这是目前最成熟的方向。
② 架构适配约束
目标:
架构一致性例如:
- 分层架构
- DDD
- Clean Architecture
- 微服务边界
典型工具:
vbnet
ArchUnit
Custom Linter
AI Architecture Review③ 行为约束
目标:
业务功能正确这是最困难的问题。
因为:
测试通过
≠
业务正确目前 AI Coding 最大短板仍然是:
无法保证真正理解业务需求。
AI Coding 最大挑战已经改变
过去:
模型能力不足现在:
模型能力足够强未来挑战:
如何控制AI引用 OpenAI 团队实践:
最困难的问题已经变成设计环境、反馈循环和控制系统。
对国内研发团队的意义
对于企业 AI 编程落地,真正需要建设的是:
第一层:前馈
编码规范
技术方案
架构规范
AGENTS.md
Spec模板第二层:反馈
css
ESLint
Type Check
Unit Test
SonarQube
Code Review Agent第三层:治理
Prompt管理
Skill管理
MCP管理
Agent管理
质量监控Harness Templates(控制模板 / 编码约束模板)
在很多大型企业里,大部分系统其实都属于少数几种"标准服务形态",大概覆盖 80% 的需求,例如:
-
📦 提供 API 的业务服务(CRUD Service)
-
🔄 事件驱动处理服务(Event Processor)
-
📊 数据看板 / Dashboard 服务
👉 这些已经存在"服务模板(service templates)"
在成熟工程组织中,这些结构通常已经被标准化。
👉 未来演进:Harness Template(AI控制模板)
这些服务模板可能进一步升级为:
Harness Template = 服务结构 + AI Agent 约束系统
它不仅是代码模板,还包括:
-
📐 架构规范(structure definition)
-
🧭 开发指南(guides)
-
🧪 自动化检测器(sensors)
-
🔒 约束 AI coding agent 的行为规则
👉 本质作用:
用"模板 + 规则 + 传感器"把 AI coding agent 限制在某种架构范式内
三种典型"服务拓扑(topologies)"

举例三类常见系统:
1、数据看板(Data Dashboard)
- Node.js
- 前端 + API + 数据展示
- 强结构化查询
2、CRUD 业务服务
- JVM / Java 系统
- 标准增删改查服务
- 企业后台核心系统
3、事件处理系统(Event Processor)
-
Golang
-
Kafka / stream processing
-
异步数据处理
👉 每种 topology 都可以有自己的:
-
代码结构
-
技术栈
-
约束规则
-
AI agent harness
约束即产品(Spec as Product)
核心思想
当编码智能体能从规范生成实现时,可分发的产品形态从"代码"反转为"规范"。
软件交付的传统形态是"代码 + 文档" ------使用者拿到的是已编译的实现,文档只是辅助理解。Spec as Product 的反转 :使用者拿到的是约束、目标与工作流的形式化描述,自己用编码智能体生成符合本地环境的实现。
OpenAI Symphony 是当前最干净的范式样本:仓库主体只是 SPEC.md + WORKFLOW.md,参考实现(Elixir)的地位明确为"参考",社区被鼓励自己拿规范跑一份。OpenAI Symphony 是 OpenAI 在 2026 年开源的一个 Coding Agent 编排(Orchestration)框架/规范,用于管理大量 AI 编码代理协同开发。
简单理解:
Codex = 程序员
Harness = 开发规范
Symphony = 项目经理 + 调度系统
Symphony 解决什么问题?
在使用多个 AI Coding Agent 时,开发者很快会遇到:
- 同时开 3~5 个 Agent 已经很难管理
- 不停切换上下文
- 不知道哪个任务完成了
- Agent 卡住了没人发现
- PR、测试、Review 流程混乱
OpenAI 在内部实践中发现,真正的瓶颈已经不是模型能力,而是 Agent 管理和调度。
Symphony 的核心思想
把项目管理工具变成 AI Agent 控制中心。
例如:
bash
Linear
├── Issue #101
├── Issue #102
├── Issue #103Symphony 会自动:
less
Issue #101 → Agent A
Issue #102 → Agent B
Issue #103 → Agent C每个任务都有独立 Agent、独立工作区。
Agent 会:
- 读取任务
- 编码
- 运行测试
- 修复错误
- 提交 PR
- 等待人工 Review
整个过程自动运行。
Symphony 架构
css
Human
│
▼
Project Board
(Linear/GitHub)
│
▼
Symphony
Agent Orchestrator
│
┌───────────┼───────────┐
▼ ▼ ▼
Agent A Agent B Agent C
│ │ │
▼ ▼ ▼
Workspace Workspace Workspace
│ │ │
└────── Git Repo ──────┘三个支撑结构
SPEC.md:定义问题,不定义实现
SPEC.md 描述三件事:
- 要解决的问题("对每一个打开的任务,保证都有一个智能体在自己的工作区中运行")
- 目标解法的形态(控制平面、状态机映射、生命周期保证)
- 取舍的边界(什么不在范围内)
刻意不写:使用什么语言、什么库、什么部署方式。这些是实现问题,留给本地智能体决定。
WORKFLOW.md:把隐式人类流程显式化
许多团队的 "开发流程"是部落知识------只有资深成员知道 issue 进 In Progress 之前要先 checkout 仓库、PR 提交后要附演示视频、Review 状态前要附自我反思。这些步骤过去靠文化传承,从未文档化。
Symphony 把这些步骤压进 WORKFLOW.md ,由编排器保证智能体每一步都执行。当文化必须显式化才能被智能体执行时,团队规范也被迫从口头传承升级为可审计文本。
多语言验证:用实现差异反向打磨规范
OpenAI 的工程师让 Codex 用 Elixir、TypeScript、Go、Rust、Java、Python 各自实现一遍 SPEC.md,然后用实现差异定位规范歧义:哪一段被不同语言的智能体理解成了不同的东西,那段规范就有问题。
这是 spec engineering 的"压力测试"环节,把"规范是否清晰"从主观判断变成了可重复实验。
Martin Fowler --- 控制论的双向延伸
Fowler 的 Guides×Sensors 框架 提供了前馈+反馈的二维分类。Spec as Product 是把"前馈"维度(Guides)抽出来作为可独立分发的工件------SPEC 是给智能体的最高层 Guide,WORKFLOW 是过程性 Guide。反馈维度(Sensors,CI/lint/eval)通常仍由本地实现。