Agent 系统的启动流程:从配置到运行时
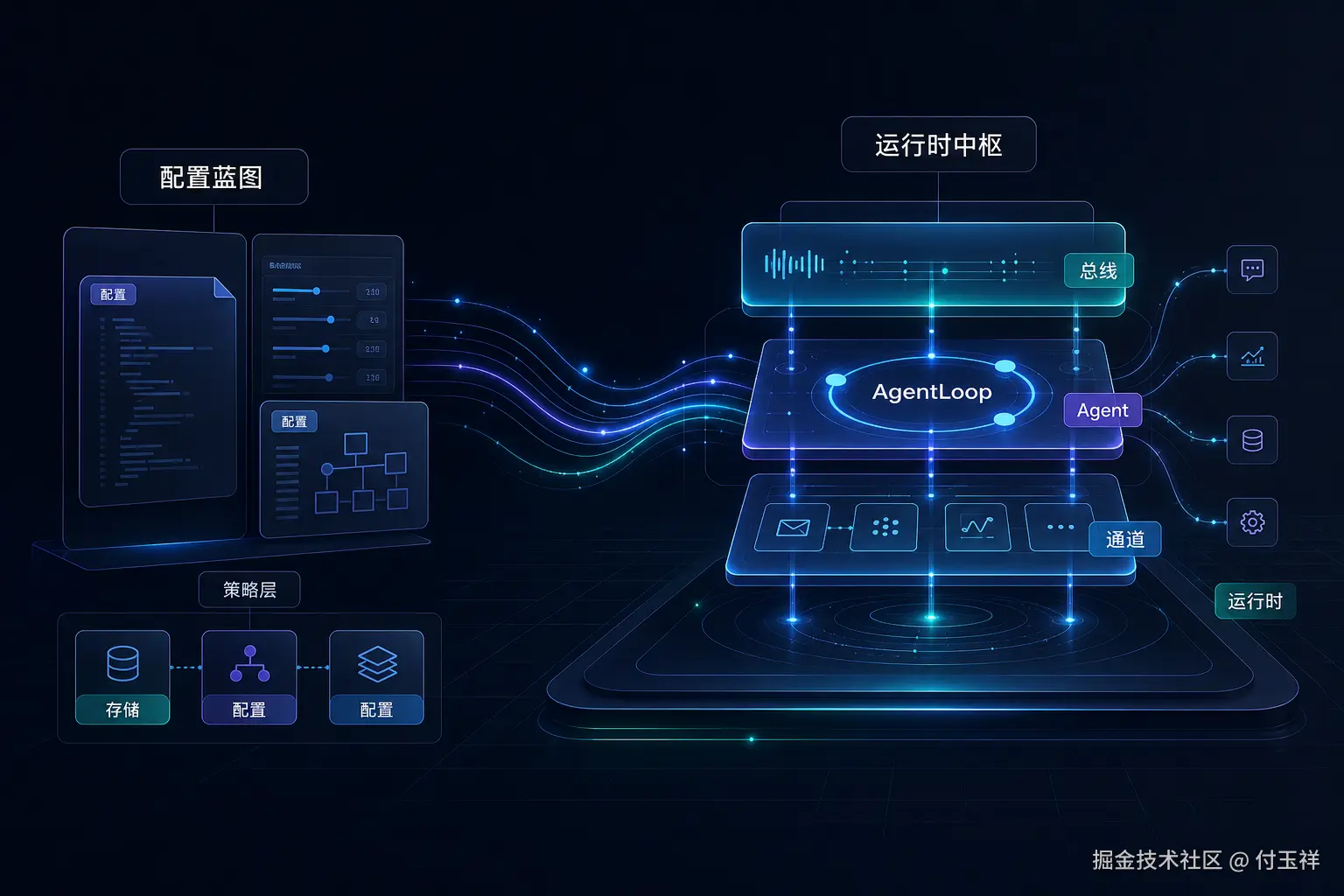
你可能遇到过这样的 Agent 问题:本地 CLI 能跑,换到 Gateway 就不稳定;同一段代码,在一台机器上能调用工具,在另一台机器上工具不可见;一次重启后,会话、任务和调度状态突然对不上。
这类问题表面是启动脚本细节,实际是系统边界没有被清楚装配。Agent 启动不是把进程拉起来,而是回答一个更底层的问题:这个 Agent 以什么身份、拥有什么能力、受哪些约束运行。
如果这个问题不清楚,工具不知道边界,状态不知道落点,通道不知道何时能接收外部消息,排障时也没人能说清"当前有效配置"到底是什么。
问题入口
普通服务的配置,多数是在描述运行参数:端口、数据库地址、日志级别。Agent 的配置更接近策略。它决定 provider 是否可用,CLI 或 Gateway 是否打开,工具 profile、执行器、网络策略、审批模式、memory 和 multi-agent 如何启用。
这些不是附属参数,而是能力边界。
源码提供可能性,配置决定当前这个 Agent 的现实能力。
用户执行 echo-agent run 只是触发启动。系统能否安全、稳定、可复现地运行,取决于启动阶段是否把配置策略装配成运行时对象图。
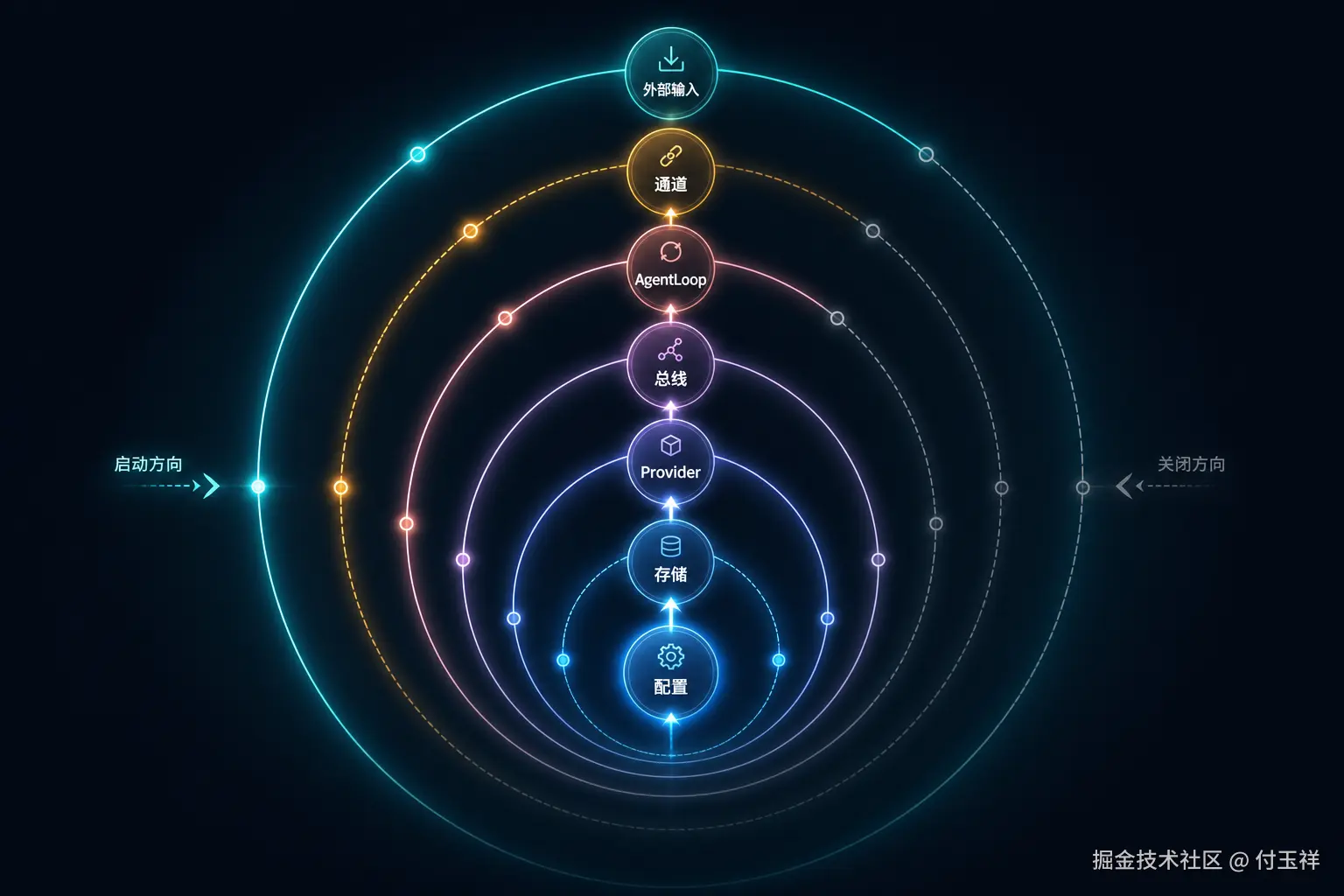
为了不停留在抽象层面,下面以 echo-agent 的实现为例。书稿中把启动链概括为:
config -> storage -> providers -> bus -> agent -> channels。这个顺序不是工程洁癖,而是依赖拓扑。
启动拓扑
启动流程最容易犯的错误,是把"对象创建成功"误解成"系统可以接收请求"。在 Agent 系统中,外部输入必须最后打开,因为通道一旦启动,真实用户、定时任务或外部平台就可能投递消息。
| 阶段 | 作用 | 顺序错误的风险 |
|---|---|---|
| config | 决定工作区、模型、通道、工具、安全策略 | 后续组件不知道边界 |
| storage | 初始化会话、任务、记忆、调度、日志等状态落点 | 第一条消息可能无法保存 |
| providers | 准备模型 provider 和 ModelRouter |
推理阶段缺少模型选择 |
| bus | 建立通道与 Agent 的消息桥 | 通道消息无处投递 |
| agent | 创建 AgentLoop,注入依赖 |
外部消息进入没有消费者的系统 |
| channels | 打开 CLI、Gateway、Webhook 等入口 | 半初始化状态下接收真实请求 |
关键设计在于:AgentLoop 接收已经构造好的依赖,而不是自己解析命令行、寻找配置文件、初始化数据库、枚举通道。启动逻辑留在入口层,核心循环只处理事件。
简化后的装配过程大致是:
ini
async def bootstrap(config_path, overrides):
config = load_config(config_path, overrides)
ws = resolve_workspace(config.workspace)
storage = await init_storage(ws, config.storage.database_path)
bus = await start_bus()
provider = create_provider_or_stub(config.models)
agent = AgentLoop(bus=bus, config=config, provider=provider, storage=storage)
await agent.start()
await ChannelManager(config.channels, bus).start_all()这段代码的重点不是类名,而是控制顺序:内部基础设施先就绪,外部输入最后开放。
关闭顺序则反过来:先停 Gateway、health、scheduler,再停 channels、agent、bus,最后关闭 storage。先停外部输入,再让内部收尾,才能避免"通道还在收消息,但 Agent 或存储已经关闭"的半失败状态。
配置合并
配置系统看似只是读 YAML,实际承担三件事:定义默认行为、允许覆盖、做结构校验。
echo-agent 的 load_config 合并顺序很明确:packaged default.yaml -> user config file -> ECHO_AGENT_ environment variables -> CLI/runtime overrides -> Config(**data)。
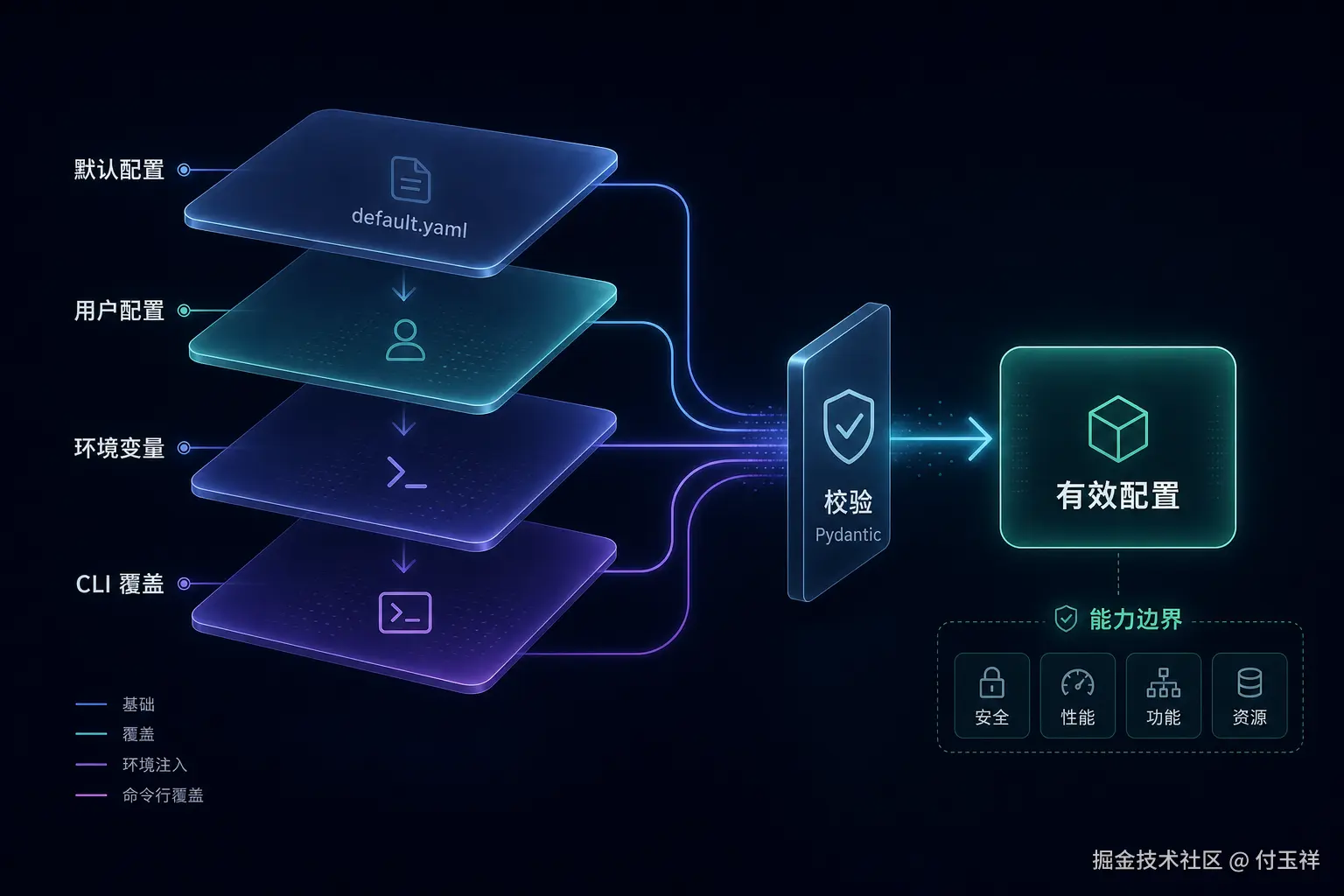
越靠后的来源优先级越高。default.yaml 提供基线,用户配置表达部署意图,环境变量适合平台注入,CLI overrides 适合一次性调整。
这里必须用 deep merge。用户只想把 Gateway 端口改成 9100,不应该被迫重写整段 gateway 配置。局部字段覆盖,其余字段继承默认值,这是配置可维护性的基础。所有来源合并后,最后都会进入 Config(**data),由 Pydantic 做结构校验。
环境变量采用 ECHO_AGENT_ 前缀,并用双下划线表达嵌套层级。例如 ECHO_AGENT_GATEWAY__PORT=9100 会被转换成嵌套配置,再交给 Pydantic 做类型转换和校验。
默认值
阅读配置时,一个常见误区是只看 schema.py 的字段默认值,然后以为那就是系统实际默认行为。echo-agent 先加载打包的 default.yaml,再构造 Config(**data)。只要 default.yaml 写了某个字段,它就会覆盖 schema 类上的默认值。
三个层次要分开看:schema.py 代表类型级默认值和合法取值,回答"字段是什么类型";default.yaml 代表产品级默认配置,回答"默认安装后系统怎样运行";合并后的 Config 才代表当前有效配置,回答"当前 Agent 实际拥有什么能力"。
书稿中特别指出几个差异:ToolsConfig.profile 在 schema 中默认是 coding,但 default.yaml 写的是 full;schema 中执行器默认是 sandbox、网络策略默认是 deny,但 default.yaml 写的是 local 和 allow。
审批配置也要分清。schema 中 require_approval 默认包含 exec、execute_code、process、cronjob、skill_install、skill_manage;而 default.yaml 显式列出的 requireApproval 只有 cronjob、skill_install、skill_manage。这不表示执行类工具完全无约束。当前路径还有 ApprovalGate、风险分级、静态 guard、工具策略、执行器策略和 smart approval 等多层机制。
判断默认行为时,看
default.yaml;判断最终行为时,看合并后的Config。
默认姿态
当前 default.yaml 体现了 echo-agent 的默认产品姿态:个人 CLI 优先,能力较完整,风险靠审批和边界治理。
security.profile 是 personal_cli,说明默认假设运行在用户自己的机器或私有环境;CLI 默认开启,Gateway 默认关闭,说明第一入口是本地终端;tools.profile 是 full,defaultExecutor 是 local,networkPolicy 是 allow,说明默认能力偏完整,适合本地项目读写、命令执行和联网查资料;approval.mode 是 smart,说明 EXEC 级风险会由 LLM 预审,必要时升级人工审批;memory、knowledge、multiAgent 默认开启,说明它不是无状态聊天程序。
这些默认值不是中性的。它们表达了框架作者对"第一次启动应该是什么体验"的判断。个人 CLI 场景下,这组默认值可以提升可用性;但如果部署成公开 Gateway,就必须重新审查认证、工具 profile、网络策略、审批模式、执行器类型、日志和 trace。
会调用工具只说明系统有行动接口。生产级标准更硬:是否有 tool call trace,是否区分只读、低风险写、高风险写,是否有审批节点,是否有失败重试与回滚,是否有任务状态持久化和评估回归,是否能解释每次行动依据。
路径与隔离
配置不只决定开关,还决定状态放在哪里。_bootstrap 对 workspace 的解析处理了一个常见问题:相对路径到底相对于谁。
规则很具体:~ 展开为用户 home,绝对路径保持不变;如果 CLI override 显式指定 workspace,相对路径基于当前工作目录;如果配置文件存在,配置中的相对 workspace 基于配置文件所在目录;否则基于当前工作目录。
存储路径进一步基于 workspace,例如 SQLiteBackend(ws / config.storage.database_path)。默认情况下,数据库会落到类似 ~/.echo-agent/data/echo_agent.db 的位置。用户也可以为不同项目指定不同 workspace,让会话、任务、记忆、知识索引、调度文件和日志彼此隔离。
配置字段命名还有一层转换。Python 代码使用 snake_case,例如 config.execution.network_policy;YAML 可以写 camelCase,例如 networkPolicy: "allow"。读源码和写配置时要分清这两套命名。
运行时状态
启动的本质,是把静态配置变成运行时对象图。只有启动之后,provider 被创建,工具被发现,执行器被绑定,消息总线开始运行,通道开始接收消息,AgentLoop 获得存储、模型、会话和工具引用,配置中的能力才进入执行态。
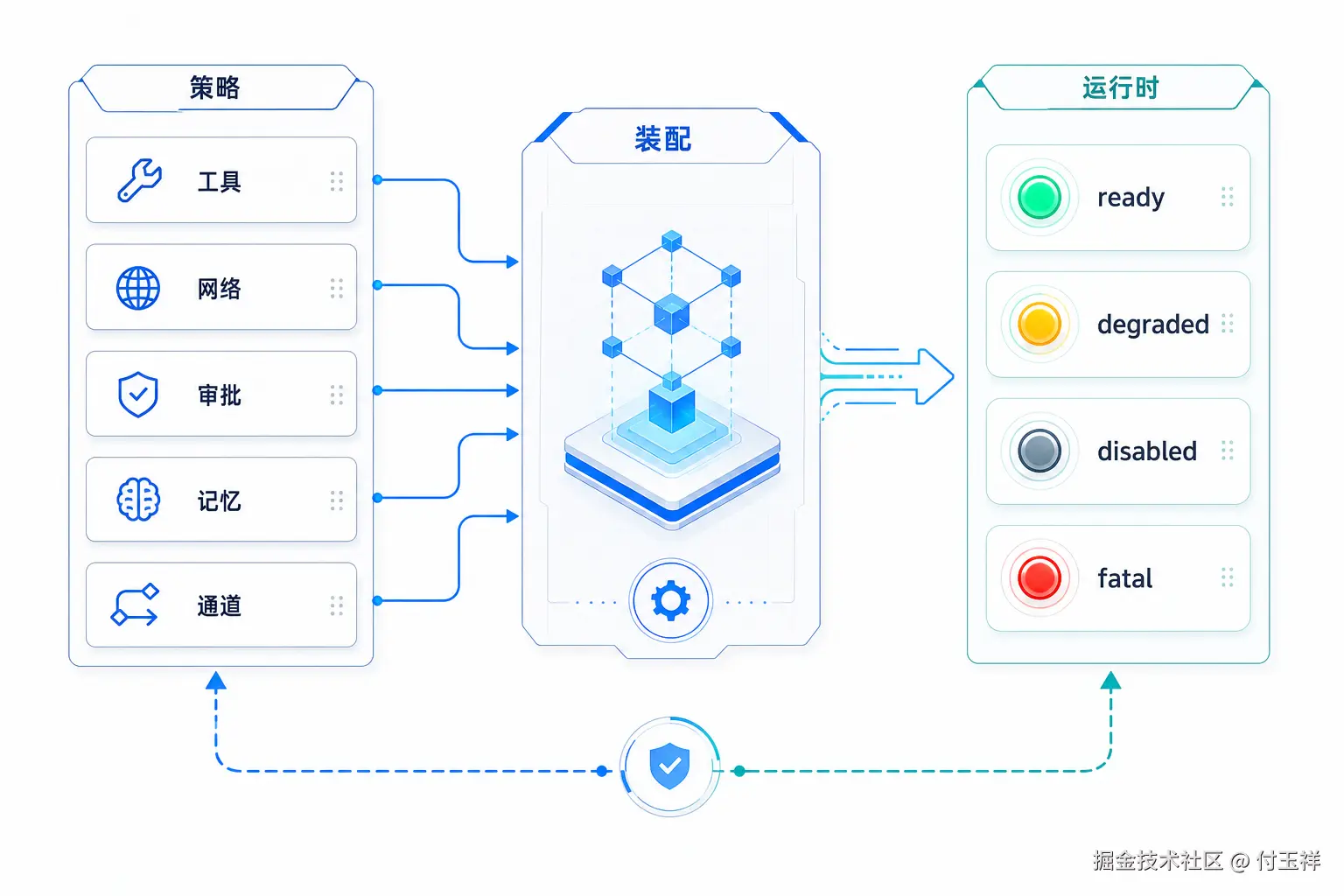
这也是为什么配置错误应该尽量在启动阶段暴露。Agent 配错工具和权限,可能导致错误行动;配错 workspace,可能读写错误项目;配错 Gateway auth,可能把内部 Agent 暴露给未知用户。
但早失败不等于所有可选能力出错都直接退出。生产系统更需要区分 ready、disabled、degraded 和 fatal:已装配的能力可以进入上下文,未开启的能力不暴露,部分不可用的能力进入 status、health 和日志,不能安全运行的情况才应该在启动阶段失败。
echo-agent 的 provider stub 是温和失败的例子。如果用户没有配置 provider,系统可以启动,并明确告诉用户"没有配置模型",而不是等到第一次请求时抛出底层异常。
同理,工具 readiness、MCP 降级、health check 和 status 命令,都是在把"配置写了什么"和"系统实际能做什么"对齐。不可用工具不应进入模型上下文,不可用 provider 不应进入路由候选。
成熟 Agent 不只读取配置,还要持续校验配置与运行时状态是否一致。
小结
本篇只讲一个点:Agent 的启动流程,不是脚手架细节,而是系统从"声明式策略"进入"可执行运行时"的过程。
配置决定能力边界,合并规则决定控制权层级,workspace 决定状态隔离,启动顺序决定依赖拓扑,health/status 决定配置与现实是否一致。echo-agent 在这里不是定义 Agent 的依据,而是工程案例:它通过 _bootstrap() 把配置、存储、provider、消息总线、核心循环和外部通道装配成一个可运行、可检查、可关闭的系统。
理解启动流程,后面再看存储、会话、记忆和任务调度,就不会把它们当成零散功能。配置决定状态放在哪里,启动把状态系统接入运行时,而下一步要解决的,就是这些状态如何在进程重启、长任务和多轮协作中可靠保存。
(全篇完)
本文为 echo-agent 设计笔记系列第 03 篇。项目源码已开源至 GitHub。如果你对工业级 Agent 的工程落地感兴趣,欢迎加入技术交流群(QQ群号:47572014)参与日常讨论。下一篇我们将探讨 《给 Agent 加一个可恢复的状态层》,敬请期待。