计算机组成原理 | 虚拟存储器:从局部性原理到TLB加速的完整闭环
摘要/导语:
嗨!
上一期虽然说过了虚拟存储器的内容,但是我觉得效果不够好,所以今天用心打磨了一份极度硬核、深度解析的虚拟存储器全貌。
我们将彻底抛弃"虚拟内存就是用硬盘当内存"的肤浅认知,从局部性原理 的底层逻辑出发,深入剖析页式管理 的地址转换细节,并最终打通**TLB(快表)**如何拯救CPU性能的完整闭环。
这篇内容涵盖了从组织结构、地址映射、缺页中断处理到多级缓存协同工作的全流程。文末附带了页表大小计算公式和CPU完整访存路径分析,建议先点赞收藏,复习考研和期末时反复观看!
🚀 正文内容
🤔 第一部分:为什么要设计虚拟存储器?
存储系统设计的终极目标,是构建一个访问速度快 且存储容量大 的理想系统。虽然我们引入了 Cache 缓解了 CPU 与主存的速度不匹配问题,但主存的物理容量限制依然存在。
这时候,虚拟存储器(Virtual Memory)就登场了。它利用程序的局部性原理,通过"按需加载"的方式,解决了两个核心痛点:
-
打破容量限制:程序员编写程序时,不再受限于物理内存的大小。
-
提供独立空间:每个进程都有自己独立的地址空间,互不干扰,提高了安全性。
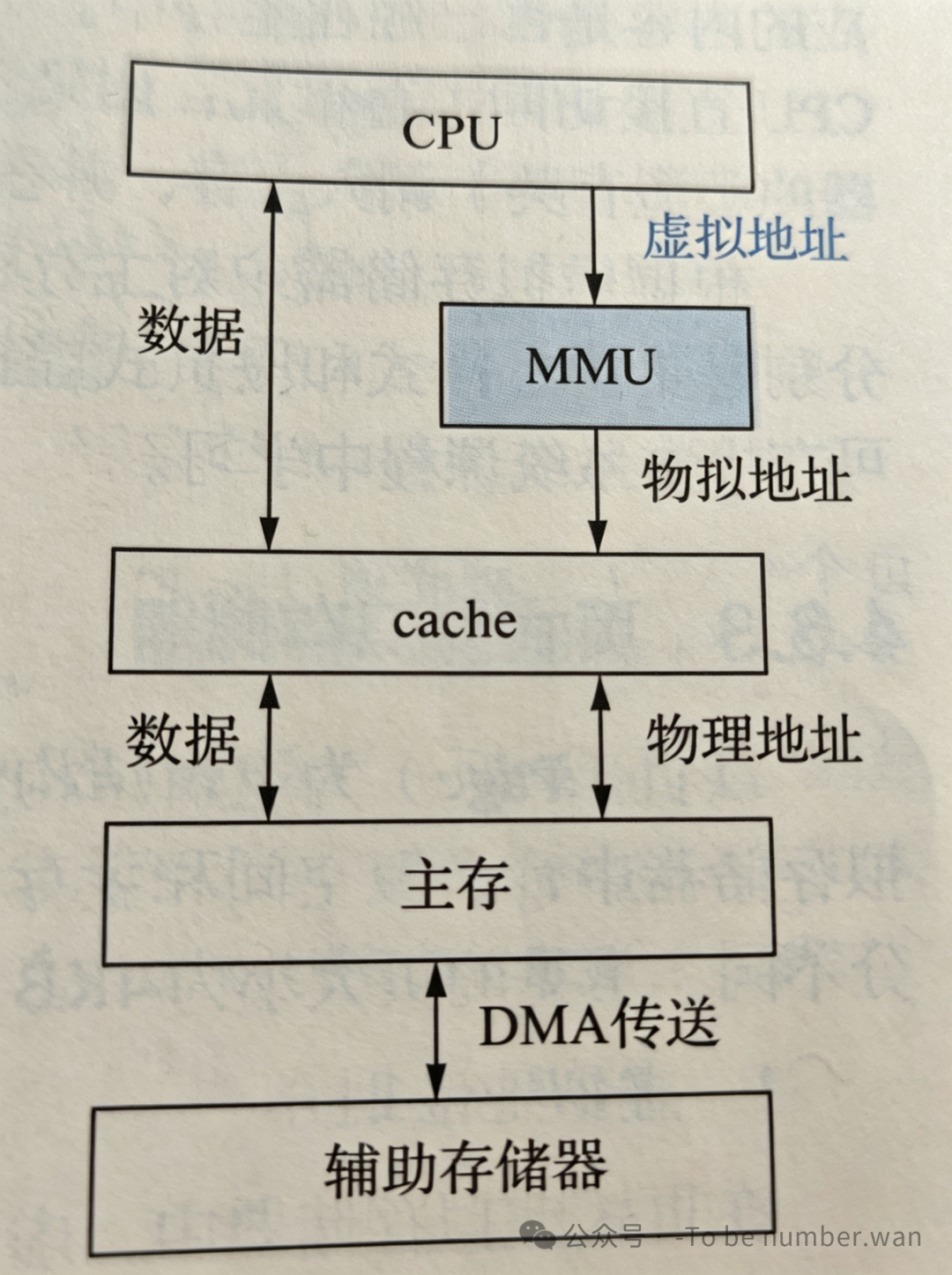
虚拟存储器的典型组织结构 虚拟存储器不仅仅是软件的概念,它是软件(操作系统) 与**硬件(MMU、缺页中断机构)**的深度结合。
-
登记:程序加载时,并不直接全部装入主存,而是在其相对应的虚拟地址转换表中登记其磁盘地址。
-
执行与缺页 :程序执行时,若发现所需数据不在主存(缺页),则触发缺页异常。
-
调入:操作系统介入,将磁盘中对应的数据页调入主存,并更新映射表。
-
继续:程序恢复执行。
💡 深度思考:缺页中断会影响效率吗?
确实,磁盘调入数据和进程上下文切换会产生巨大的时间开销。但现代计算机通过多级缓存 、预调页技术 以及高效的页面置换算法 等技术,将缺页率降低到了极低的水平,从而在保证大容量的同时,将性能损失控制在可接受范围内。
🧭 第二部分:地址映射与变换------虚拟世界的导航仪
虚拟存储器涉及三个不同的地址空间:
-
虚拟地址空间(程序员眼中的)
-
主存地址空间(物理的)
-
辅存地址空间(磁盘的)
地址映射与变换流程是虚拟存储器的核心灵魂:
-
CPU 发出虚拟地址。
-
MMU(内存管理单元) 查找虚拟地址与物理地址的对应关系。
-
判断内容是否在主存内:
-
在(命中):转换为物理地址,访问主存。
-
不在(缺失):触发缺页中断,调入页面,更新 MMU 信息。
-
📄 第三部分:页式虚拟存储器------最主流的实现方式
在众多虚拟存储器实现方式中,页式虚拟存储器 是目前最常见、最核心的结构。它将虚拟地址空间和物理地址空间划分为固定大小的块,分别称为页 和物理块(或页框)。

1. 地址划分与页表机制 在页式管理中,虚拟地址被划分为两部分:虚页号 (VPN) 和 页内偏移 。物理地址则由 物理块号 (PPN) 和 页内偏移 组成。
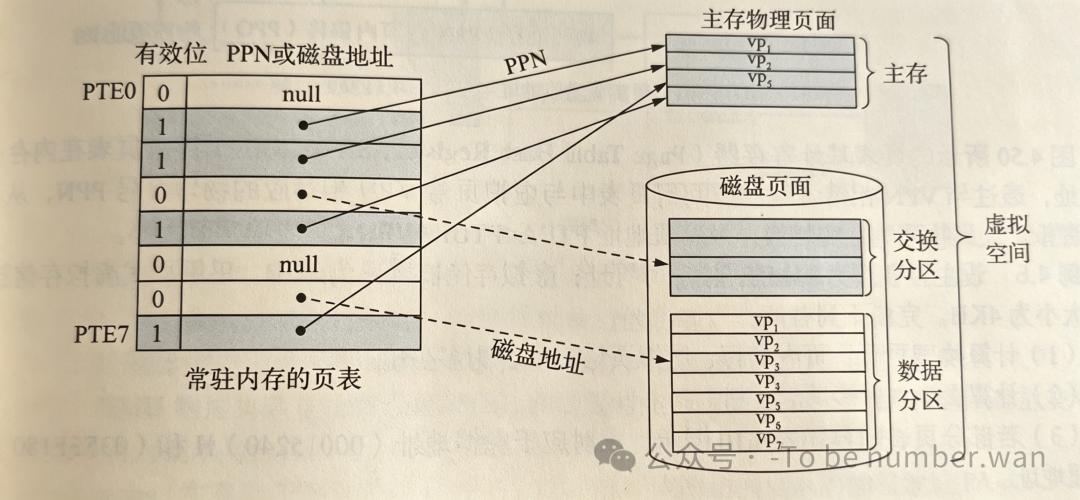
-
页表:这是虚拟地址到物理地址转换的"地图"。
它记录了虚拟页号对应的物理块号,以及有效位、修改位等控制信息。
-
页表项 (PTE):页表中的每一个条目。
计算题考点预警: 假设虚拟地址空间为2^32 ,页大小为 4KB ,则页表项数目为2^20 。如果每个页表项占 4B,整个页表大小将达到 4MB。
2. 地址转换流程图解利用虚拟页号实现地址转换的过程如下:
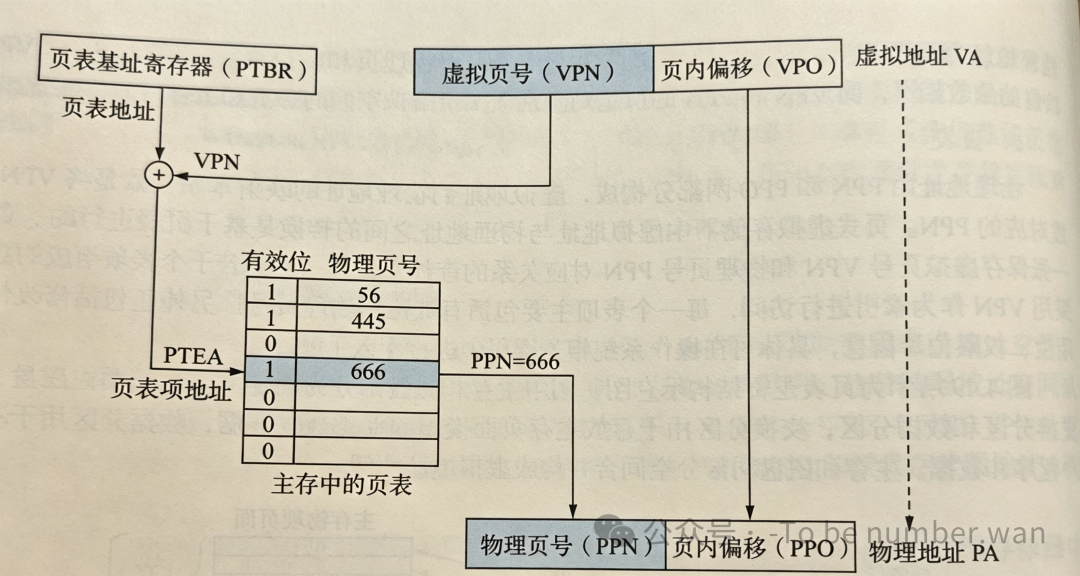
-
拆分:CPU 发出虚拟地址,MMU 将其拆分为虚页号和页内偏移。
-
查表:利用虚页号作为索引,查找页表,获取对应的页表项。
-
拼接:从页表项中取出物理块号,与页内偏移拼接,形成物理地址。
3. 页式虚拟存储器的完整访问流程
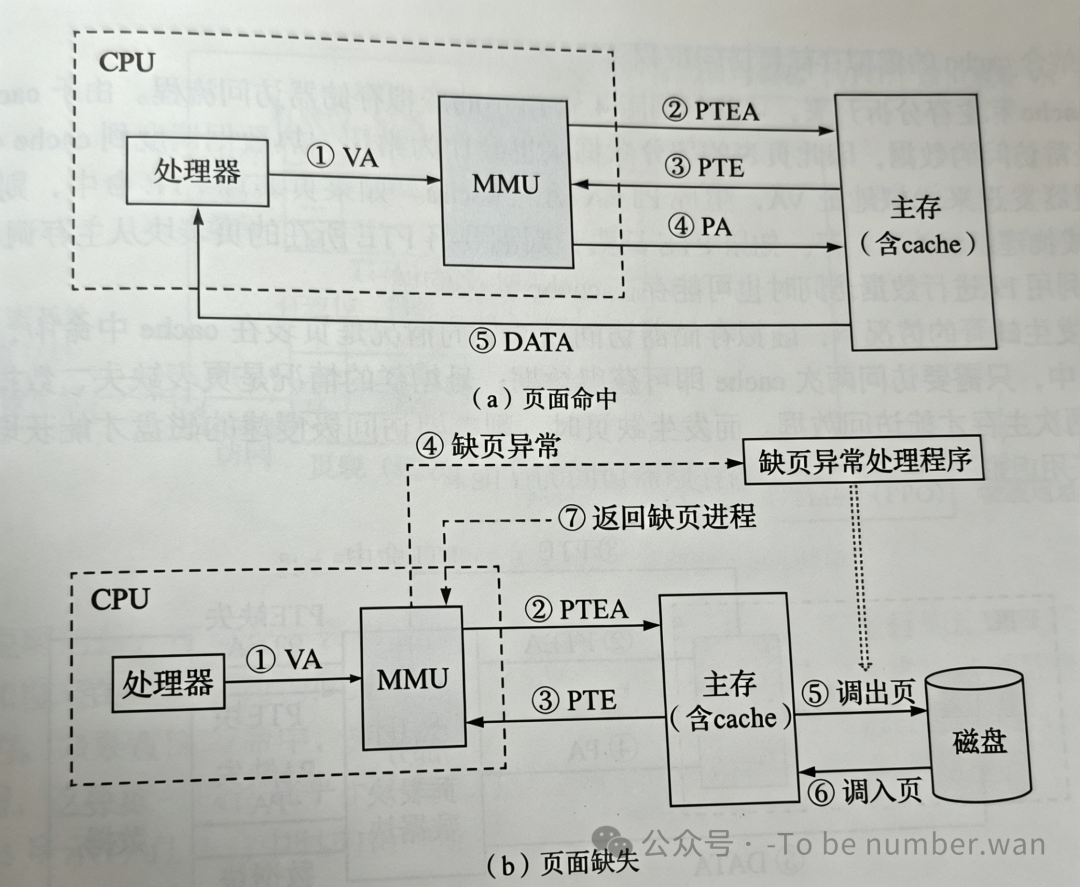
(a)页面命中时这是最理想的情况,流程如下:
-
处理器生成虚拟地址,传给 MMU。
-
MMU 利用页表基址寄存器和虚页号生成页表项地址,访问页表。
-
页表项返回,有效位为 1。
-
MMU 构造物理地址,访问主存/CPU Cache,获取数据。
**(b)页面不命中时(缺页异常)**这是最糟糕的情况,涉及磁盘 I/O:
-
处理器生成虚拟地址,传给 MMU。
-
MMU 访问页表,发现有效位为 0。
-
触发缺页异常,CPU 转入操作系统内核处理。
-
置换决策:如果主存页满,根据替换算法(如 LRU)确定换出页。若换出页被修改过(Dirty Bit=1),则需写回磁盘。
-
调入新页:从磁盘读取所需页到主存。
-
更新页表:修改页表项,将有效位设为 Abstract,填入新的物理块号。
-
重新执行:缺页处理程序返回,重新执行导致缺页的那条指令。
⚡️ 第四部分:结合 Cache 的虚拟存储器访问流程
在不发生缺页的情况下,虚拟存储器的访问性能也大不相同。
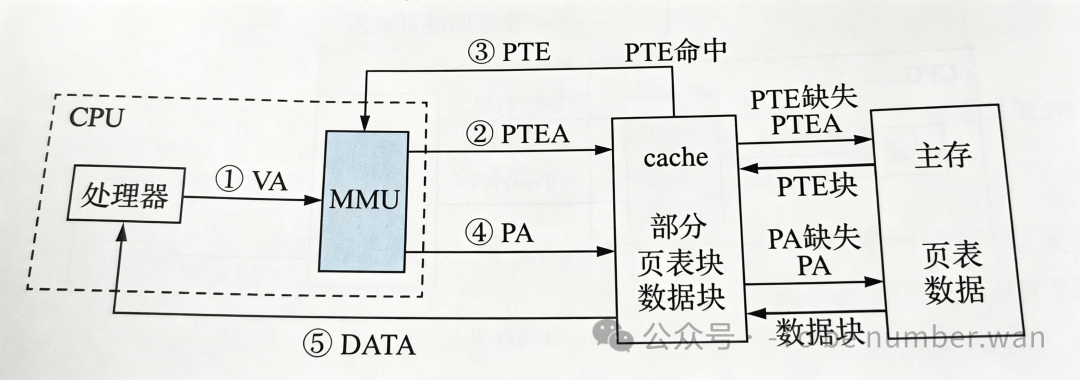
-
最优情况:页表在 Cache 当中命中,数据也在 Cache 当中命中。只需要访问两次 Cache 即可获得数据。
-
最差情况:页表缺失,数据也缺失。需要访问两次主存,缺页时还需要访问速度极慢的磁盘。
由此可知,虽然虚拟存储器解决了容量问题,但页表查询成为了新的性能瓶颈。
🚀 第五部分:利用 TLB 加速地址转换
为了解决页表查询带来的性能损耗,我们引入了TLB(Translation Lookaside Buffer) ,也叫快表。
快表与慢表的博弈
-
TLB(快表):位于 MMU 内部,速度极快,容量小。用于缓存最近使用过的页表项。
-
页表(慢表):位于主存中,速度慢,容量大。
核心逻辑 :在包含快慢表的系统中,进行地址转换时,会同时查询快慢表。如果快表命中,则直接终止慢表的查询。

(组相联时虚地址划分)
基于 TLB 的虚拟地址到物理地址的转换
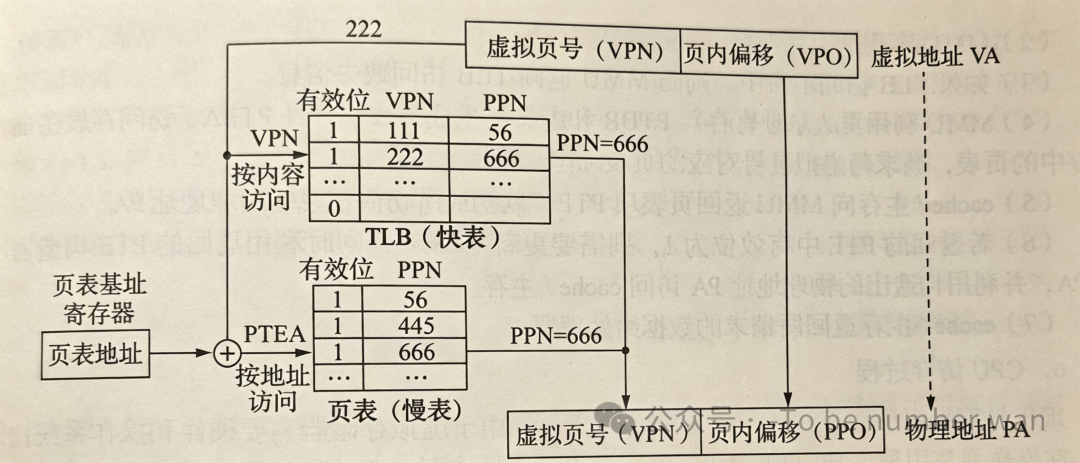
TLB 根据 MMU 发过来的 VPN(虚页号)进行内容访问,读出对应的物理页号。
TLB 命中的访问流程
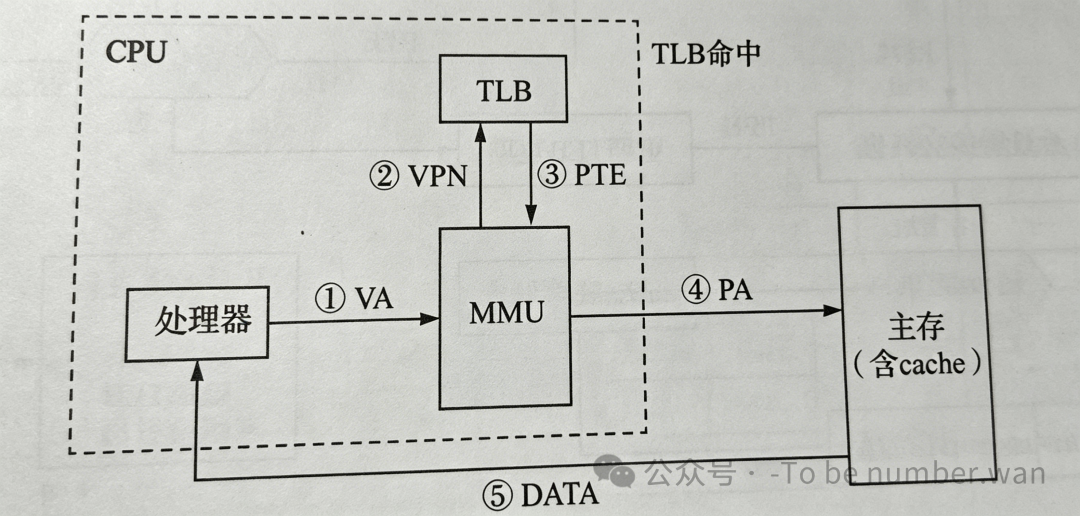
-
处理器生成虚拟地址,传给 MMU。
-
MMU 利用虚页号 VPN 查询 TLB。
-
页表项在 TLB 中且有效位为 1,返回对应的 PPN。
-
MMU 构造物理地址,访问 Cache/主存。
-
返回数据。
TLB 不命中的访问流程
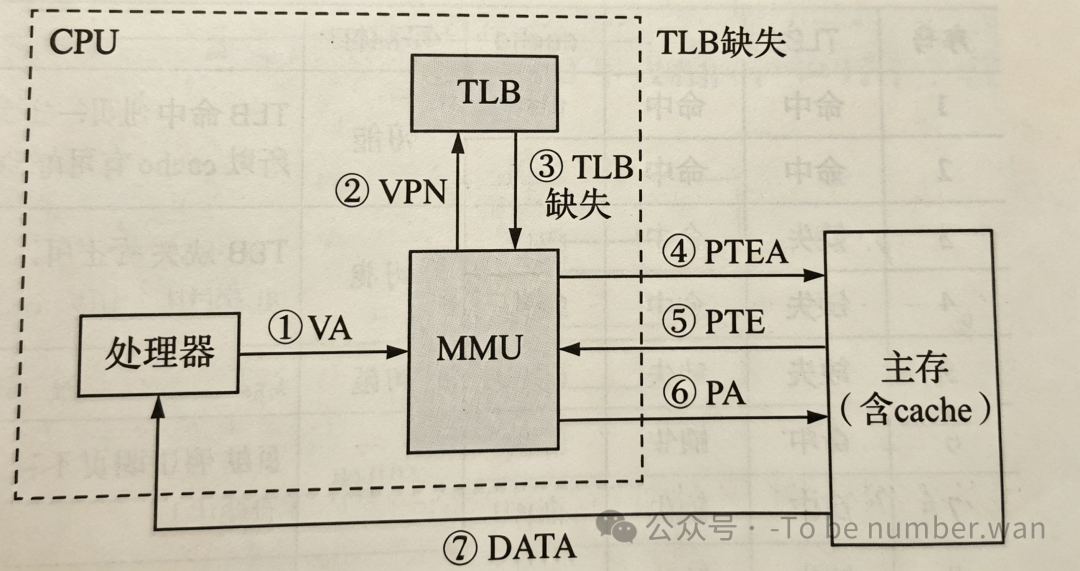
-
处理器生成虚拟地址,传给 MMU。
-
MMU 查询 TLB,未命中。
-
MMU 转向查询主存中的页表(慢表)。
-
获取页表项,构造物理地址,访问数据。
-
更新 TLB:将本次查询到的页表项加载到 TLB 中,以备后用。
利用TLB可以在几乎不降低主存访问效率的情况下访问虚拟存储器
快表访问速度快,为什么还需要慢表?
:快表容量小,慢表容量大,二者互补关系,快表可能发生TLB缺失,即未命中
🏁 第六部分:CPU 的一次完整虚存访问操作
最后,我们把 Cache、TLB、主存、磁盘串联起来,看 CPU 访问虚拟内存的完整路径。
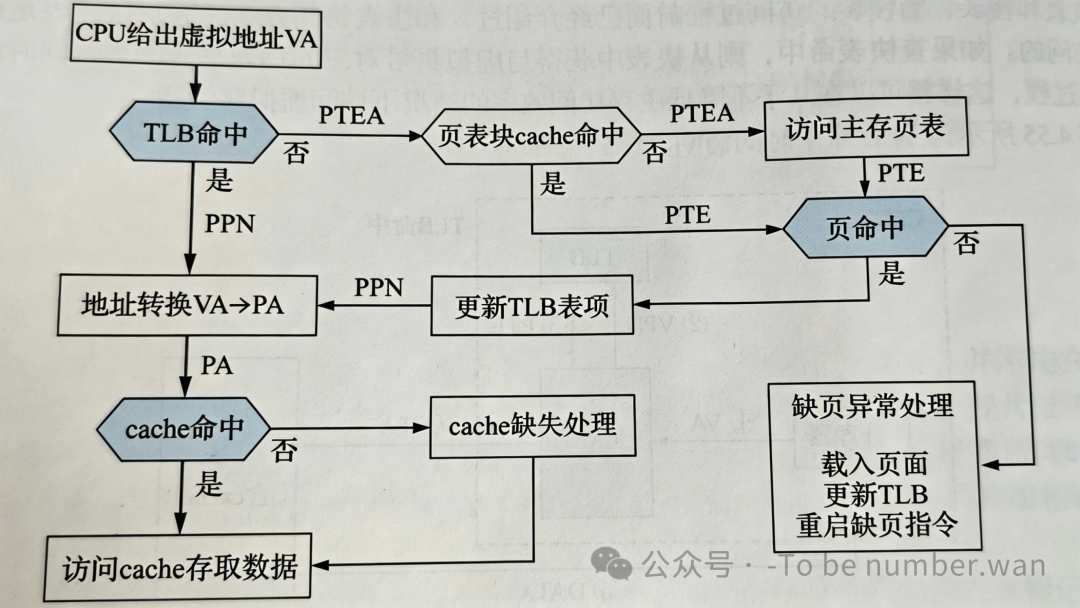
左侧(TLB 命中 + Cache 命中)为最短路径,即性能最优的情况。
右侧(TLB 缺失 + Cache 缺失 + 缺页)为最长路径,涉及磁盘访问,性能最差。
通过这张图,我们可以清晰地看到,现代计算机是如何通过"局部性原理"和"多级缓存机制",在几乎不降低主存访问效率的情况下,实现了巨大的虚拟地址空间。
📝 总结与考点回顾
-
虚拟存储器的本质:是主存-辅存层次的逻辑扩展,利用局部性原理实现大容量、独立的地址空间。
-
页式管理:核心是页表,将虚拟页号映射到物理块号。
-
缺页中断:是性能杀手,也是系统调入数据的契机。
-
TLB 的作用:作为页表项的高速缓存,解决了二次访存问题,是现代计算机性能的守护神。