CLup是一款由中启乘数科技(杭州)有限公司自主研发的数据库统一管理平台,全称为"CLoud Unite Platform",中文名为"乘数云统一平台"。它聚焦于虚拟化IaaS层与数据库生态PaaS层的深度融合,是一款面向企业级场景的私有云平台。
简单来说,CLup将复杂的底层运维操作------如虚拟机的创建与管理、存储资源的动态分配、网络配置------与数据库的核心管理能力(高可用部署、故障自动切换、实时性能监控、自动备份恢复等)进行了整合封装,提供了一个开箱即用、可视化、自动化的运维管理界面。
CLup支持三种高可用架构的一键搭建:
-
流复制高可用集群:利用PostgreSQL自身的流复制技术,搭建一主多备的高可用集群。主库故障时,CLup自动将延迟最低的备库提升为主库,并将VIP漂移到新主库上;同时也支持手工一键完成主备库的角色互换(switchover)。
-
共享存储高可用集群:基于共享存储(如SAN)的两节点架构,切换时不会丢失数据,特别适合使用逻辑复制功能的场景,因为流复制集群切换后逻辑复制槽可能失效,而共享存储方案则不会。
-
负载均衡与读写分离:提供只读VIP,应用连接后自动在多台只读备库之间实现负载均衡。备库故障时自动从均衡器中移除,恢复后自动加入。
CLup官方网站:中启乘数科技(杭州)有限公司 - CLup产品
安装详解:CLup6.x产品手册:安装基础
一、纳管PostgreSQL数据库
该功能主要是为了把您在使用CLup之前已经有的PostgreSQL数据库纳入到CLup中集中管理。
在数据库列表界面中点导入数据库按钮,出现弹出框:

添加的时候会检查数据目录和端口是否正确。
- 数据库名称:方便用来标识数据库,可以是任何一个容易标识这个数据库的字符串。
- 所在主机:数据库所在的主机,只能选择运行clup-agent的主机。
- 数据库端口:数据库占用的端口。
- 数据目录:数据库数据所在目录。
- DB中的用户:此用户需要有数据库超级管理员的权限,默认是postgres。
- DB中的密码:用户的密码。
二、创建PostgreSQL单机数据库
在数据库列表界面中点创建数据库实例按钮,选择创建PostgreSQL实例,出现弹出框:
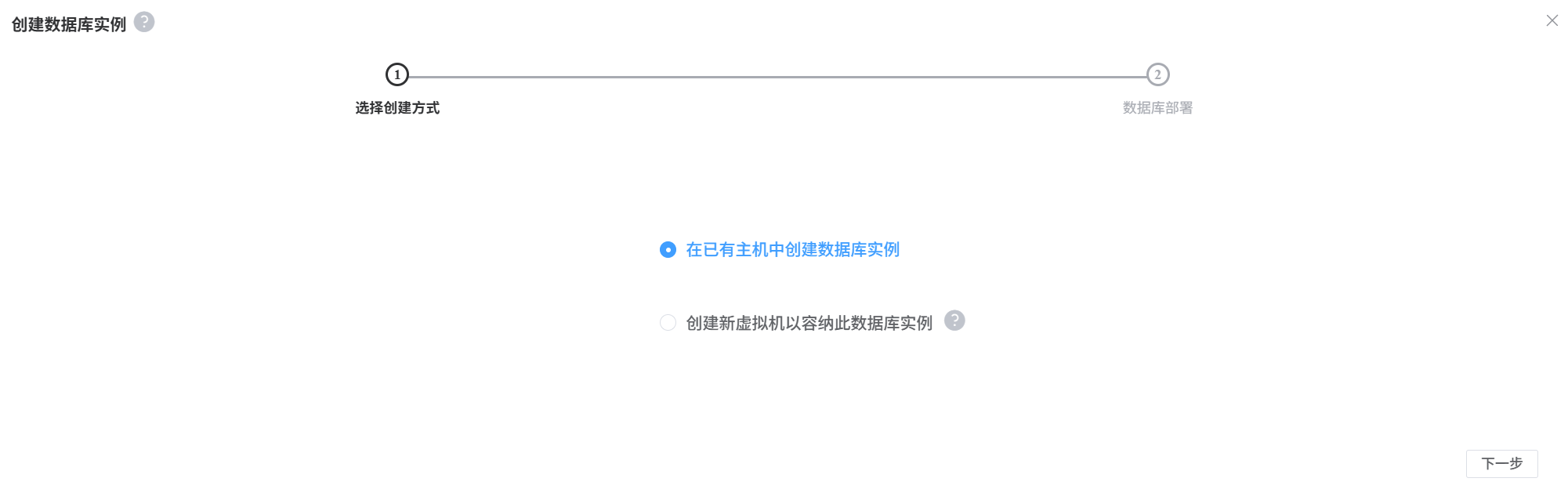
- 在已有主机中创建数据库实例:在已经安装运行clup-agent的主机上创建数据库实例
- 创建新虚拟机以容纳此数据库实例:先创建虚拟机,再在虚拟机中创建数据库实例。需要配置PaaS模板,PaaS类型必须选择PostgreSQL。
1. 在已有主机中创建数据库实例
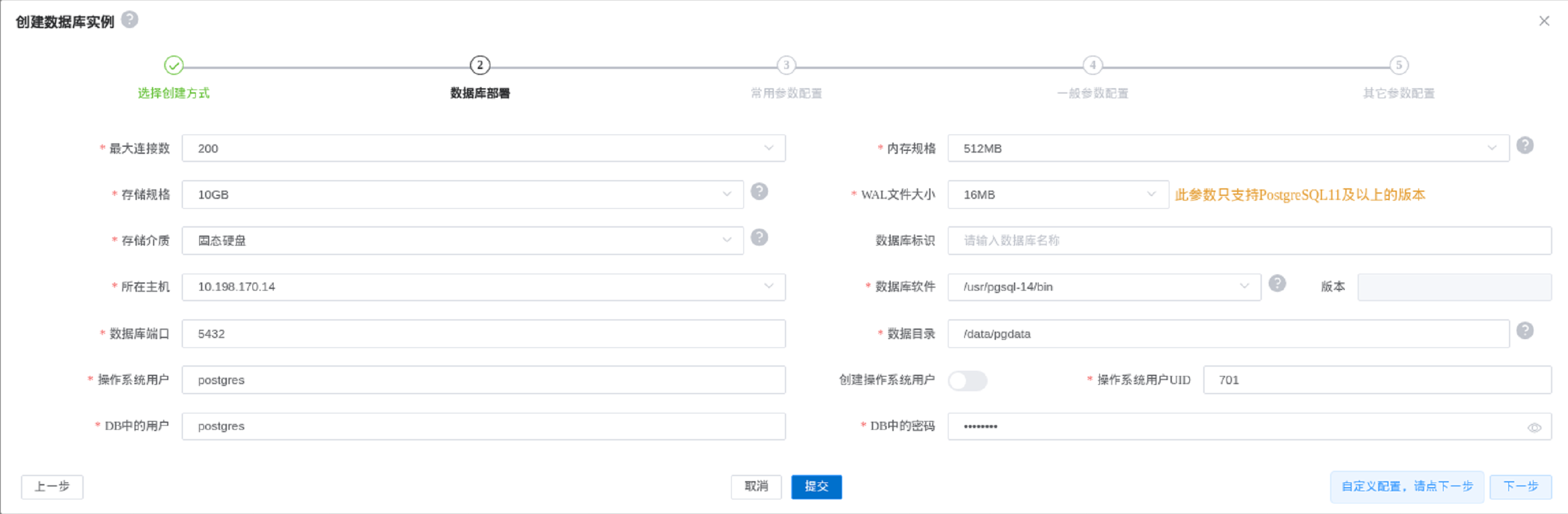
这个操作会创建一个新的数据库。
填写的各个项说明如下:
- 数据库标识:方便用来标识数据库,可以是任何一个容易标识这个数据库的字符串。
- 所在主机:数据库所在的主机,只能选择有运行clup-agent的主机
- 数据库软件:是一个不同类型和版本的数据库软件的目录列表,当选择中一个软件目录后,后面的版本字段会自动显示这个数据库软件的版本,如"10.6"、"11.12"等等。当这台机器安装了不同版本的PostgreSQL数据库并放在对应的目录中,就会自动出现在这个下拉框中,可以去
系统管理->CLUP参数设置->pg_bin_path_string配置好软件存放的路径,可以是多个路径,用英文逗号隔开,路径中可以使用*通配符。 - 数据库端口:数据库占用的端口。
- 数据目录:数据库数据所在目录,目录必须为空,目录不存在时会创建。
- 操作系统用户:指定数据库运行在哪个操作系统用于下,通常输入postgres。注意如果此用户不存在,后续的"创建操作系统"的选择框会亮起来,需要输入这个用户的UID,系统会自动创建这个用户。通常我们习惯把postgres用户的UID设置为701。
- DB中的HA用户:此用户需要有数据库超级管理员的权限,所以我们通常默认是postgres。
- DB中的HA密码:HA用户的密码。
2. 创建新虚拟机以容纳此数据库实例
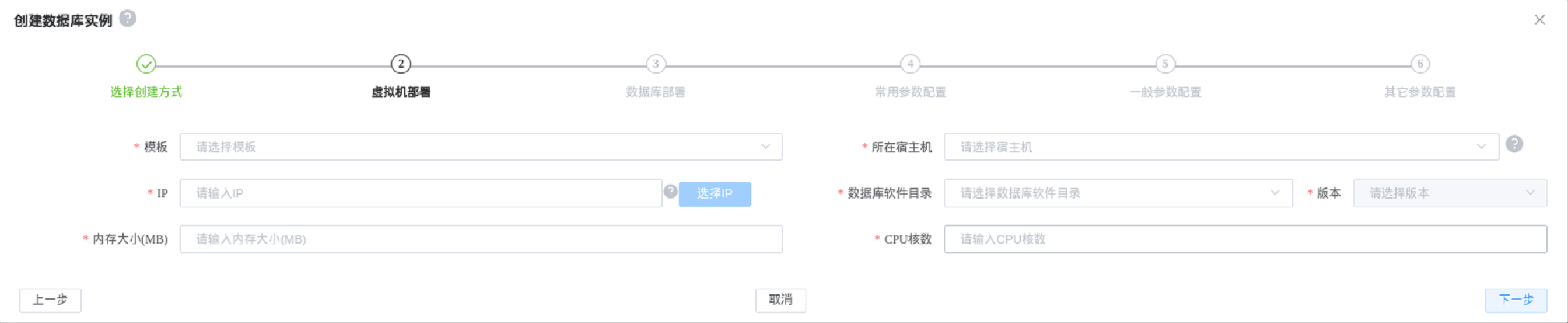
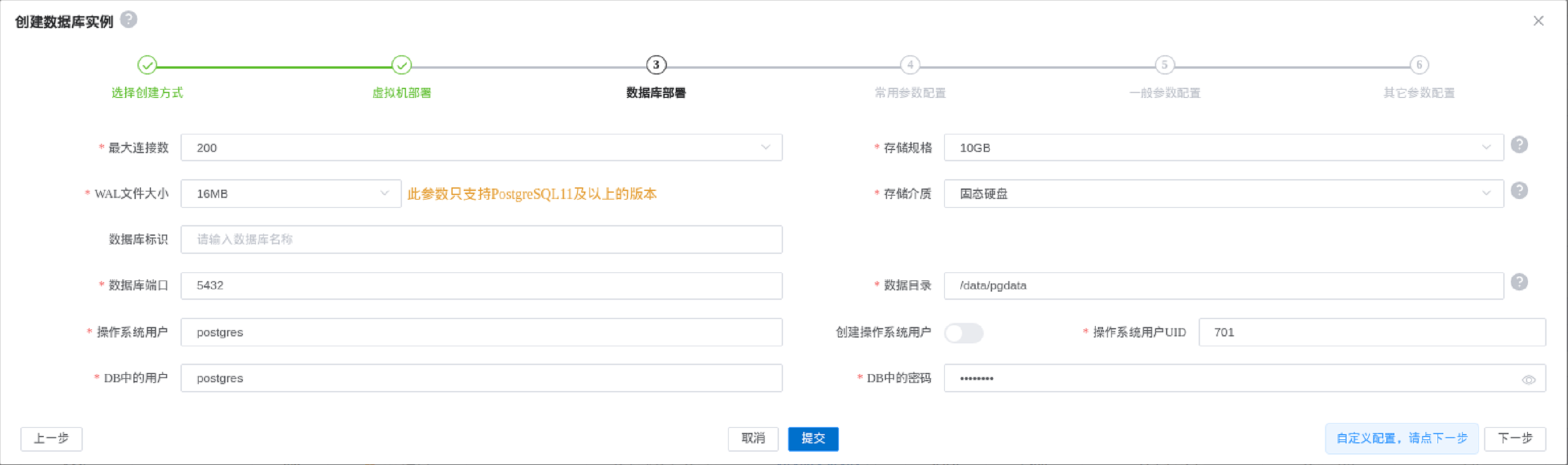
这个操作会先创建一个虚拟机,在虚拟机中安装clup-agent,最后创建一个新的数据库。
填写的各个项说明如下:
- 模板:这里选择的就是之前配置好的PaaS模板,模板的PaaS类型必须是PostgreSQL类型。
- 所在宿主机:虚拟机模板所在的宿主机。
- IP:虚拟机的IP地址,当虚拟机是多网卡时,第一个IP必须为主IP,作为安装clup-agent的IP。
- 数据库软件:是一个不同类型和版本的数据库软件的目录列表,需要配置好PaaS参数中的数据库软件bin目录。
- 内存大小:分配给虚拟机的内存大小,单位(MB)。
- CPU核数:分配给虚拟机的CPU核数,单位(个)。
- 数据库标识:方便用来标识数据库,可以是任何一个容易标识这个数据库的字符串。
- 数据库端口:数据库占用的端口。
- 数据目录:数据库数据所在目录,目录必须为空,目录不存在时会创建。
- 操作系统用户:指定数据库运行在哪个操作系统用于下,通常输入postgres。通常我们习惯把postgres用户的UID设置为701。
- DB中的HA用户:此用户需要有数据库超级管理员的权限,所以我们通常默认是postgres。
- DB中的HA密码:HA用户的密码。
请确保填写的参数没有问题,创建数据库过程需要花一些时间,这个创建过程是一个异步的,会在后台创建,页面会显示数据库的状态是正在创建中,可以到PaaS平台->日志管理 查看相关创建过程日志。
从第二个步开始,都是在设置数据库的一些配置,我们程序提供了这些配置项的默认值,可以根据实际情况进行修改。其中默认会加载pg_stat_statements和pg_store_plans两个插件,即把这两个插件配置到数据库参数shared_preload_libraries中,请根据实际情况修改,默认至少需要保留pg_stat_statements,以便于后续监控中可以启用TopSQL功能,如果没有装此插件,将不能使用TopSQL的功能。如果不选择pg_store_plans,将在TopSQL的功能中不能查看SQL的历史执行计划。当使用虚拟机创建实例时,无法探测软件包中插件是否存在,所以当填写的插件不存在时,会在创建过程中自动将该插件剔除。
三、PostgreSQL实例管理
1. 修改数据库配置
1.1 修改数据库参数
此功能主要是修改PostgreSQL数据库配置文件postgresql.conf或postgresql.auto.conf中的配置。注意此处仅仅是修改文件中的配置参数,并不会使用让这些参数生效,如果想生效,还需要手动点击reload 数据库的命令或重启数据库后才会生效。
点更多按钮弹出菜单,然后在菜单中点修改数据库配置:
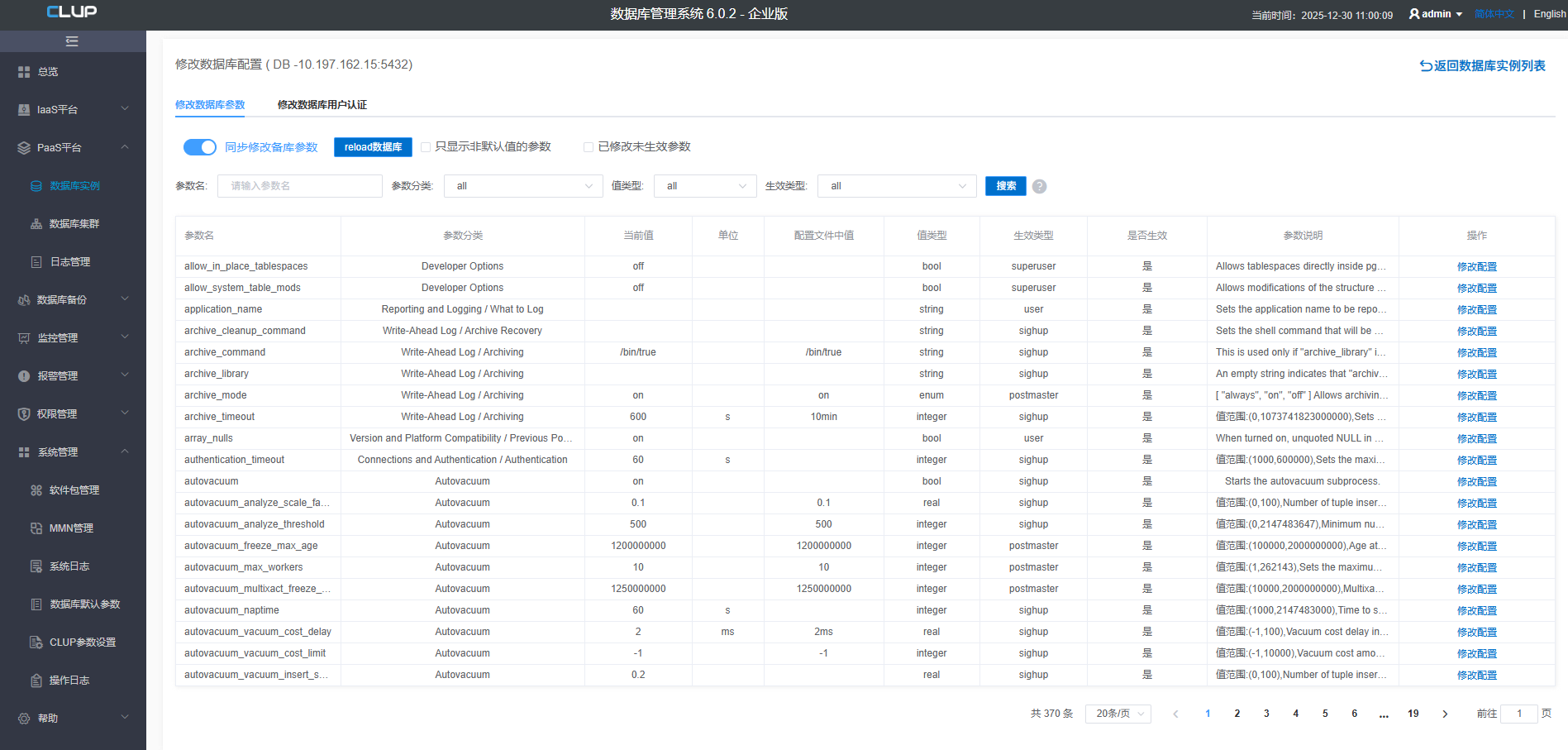
上图中有一个选项"同步修改备库参数",意思时把修改的参数同时应用到备库上。有三个参数'max_connections', 'max_worker_processes', 'max_prepared_transactions',PostgreSQL要求备库设置的值不能小于主库,否则修改后重启备库将无法启动,所以即使没有勾中选项"同步修改备库参数",CLup也会智能的保证备库设置的参数不会小于主库,保证不会因为修改参数而导致备库无法启动的严重故障。
点击页面修改配置按钮即可修改对应参数的配置值,修改完是否生效在页面的【是否生效】列可以看到。
一些参数说明:
- Listen_address:通常配置为"*",表示数据库在本地的所有IP地址上监听。一般保持不变就可以了。
- max_connections: 数据库接受的最大连接数,由于修改此值需要重启数据库,通常我们设置一个较大的值,比如2000。
- superuser_reserved_connection: 保证默认的10即可。
- max_worker_processes: 保持默认的256即可。
- shared_preload_libraries: 配置一些常用的插件。CLup要求要把pg_stat_statements配置上去,如果没有配置上,会导致后续的数据库监控中的TopSQL的功能不正常。通常还需要把pg_store_plans插件也配置上去,这个插件可以看运行过的SQL的历史执行计划。
- archive_mode:保持默认的on即可。
- archive_command:如果不使用归档,默认的命令可以不改。如果想使用归档,请配置相应的命令,如"cp %p /data/archives/%f",注意修改此命令时需要确保命令可以执行成功,否则会导致WAL堆积。
- shared_buffers:通常配置为机器内存的四分之一或更低一些。
- work_mem: 通常保持默认值4MB就可以了。如果经常要排序或hash join的数据量超过了4MB,可以调的大一些,这样更多的数据在内存中处理性能会好一些。但配置太大的值,当同时有多个SQL运行时,可能会消耗太多的内存,导致内存不足。
- maintenance_work_mem:一般保持默认值就可以了。
- rand_page_cost:如果数据库使用的是SSD,保持默认值即可,如果是机械硬盘,可以改大一些,比如4。
- max_wal_senders:保持默认的64即可。
- wal_keep_segments:这是PostgreSQL12版本及之前使用的参数,如果后面要为此数据库搭建备库,为了防止备库与主库延迟过大导致流复制失效,则需要设置一个比较大的值,这里是2048,当WAL文件大小是16M时,大于时保留32G的WAL日志。如果是比较小的数据库,也可以设置的小一些。通常设置为数据库大小的5%~10%的大小,具体取决于主库WAL的生成速度。
- wal_keep_size:这是PostgreSQL13版本及之后,使用此参数控制主库保留更多的WAL日志,以防止备库失效。如果后面要为此数据库搭建备库,为了防止备库与主库延迟过大导致流复制失效,则需要设置一个比较大的值,如设置为32GB, 如果是比较小的数据库,也可以设置的小一些。通常设置为数据库大小的5%~10%的大小,具体取决于主库WAL的生成速度。
- max_wal_size:通常设置为1GB至几十GB,控制产生checkpoint的频度,写的WAL的日志量超过 max_wal_size的1/3~1/2时,就会发生一次checkpoint。具体是多数还取决于参数checkpoint_completion_target。
- min_wal_size:通常保持默认值即可。
- checkoint_timeout: 通常保持默认5分钟即可。当然也可以适当调大,如15分钟。"一般参数"和"其它参数"Tab页中的配置项如果没有特殊要求保持默认即可。
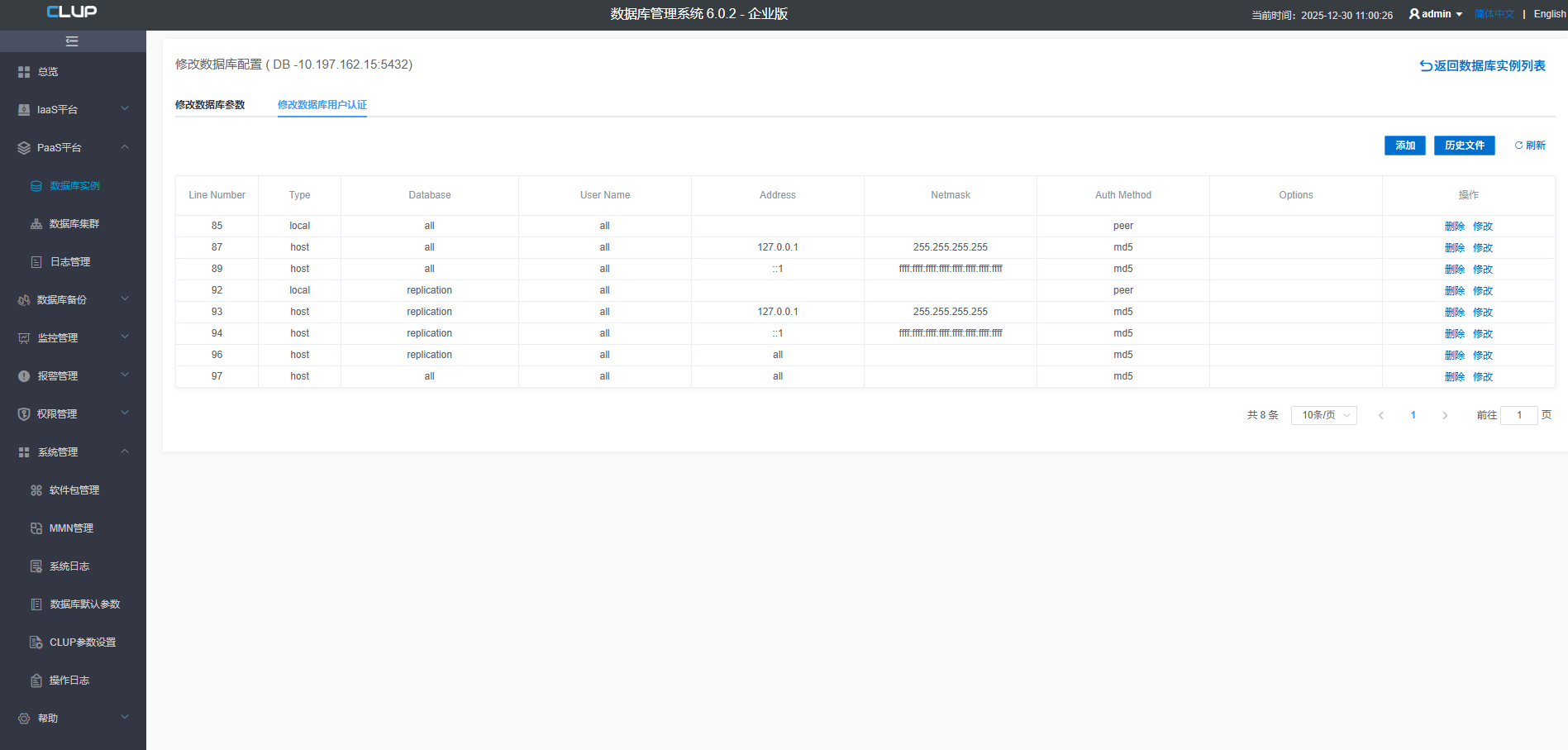
1.2 修改数据库认证
此功能主要是修改PostgreSQL数据库配置文件pg_hba.conf中的配置。注意此处仅仅是修改文件中的配置、删除一条配置、增加一条配置,并不会使用让这些参数生效,如果想生效,还需要在修改的同时选择reload才会生效。
2. 获得SQL的执行计划
点更多按钮弹出菜单,然后在菜单中点查询计划:
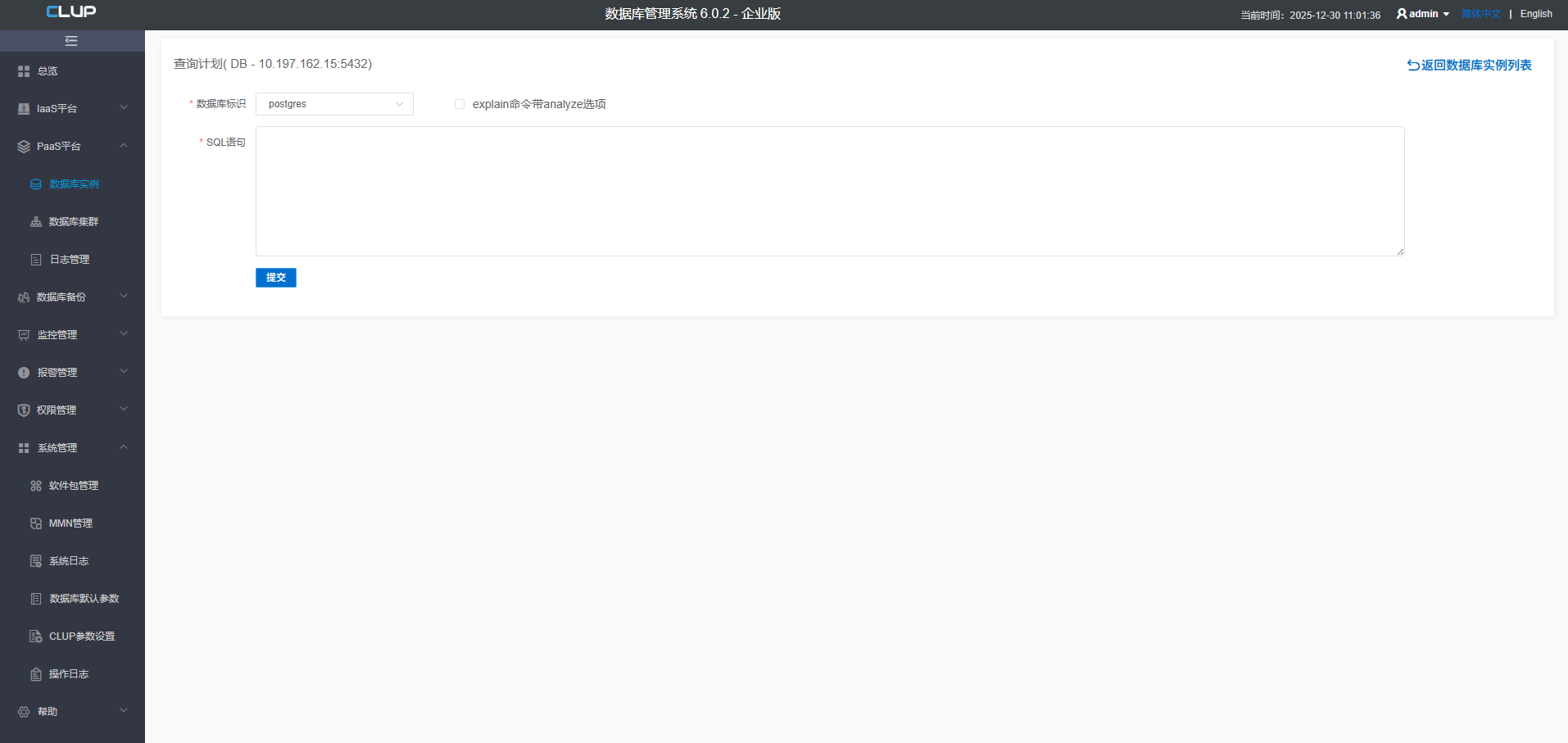
上图中,可以选择在那个database中执行这个SQL,"analyze"选项可以选择"true"或"false",选择true,是用"explain analyze SQL"的方式获得SQL的执行计划,即真实执行这台SQL,选择"fasle",是用"explain SQL"获得执行计划。
3. WEB界面中psql登录数据库
点更多按钮弹出菜单,然后在菜单中点psql,浏览器会弹出一个新的窗口:

4. 搭建备库
这个功能会为当前选择的数据库搭建一个新的备库。CLup可以从一个主库搭建备库,也可以从一个备库搭建另一个备库。
点更多按钮弹出菜单,然后在菜单中点搭备库,然后弹出一个搭建备库的框。搭备库过程可能会比较慢,搭建时间要看数据库大小,所以这是一个异步的功能。
页面提交之后会显示搭建的备库状态是在创建中,可以到数据库管理-日志查看查看搭建过程日志,日志的最后显示success表示搭建成功
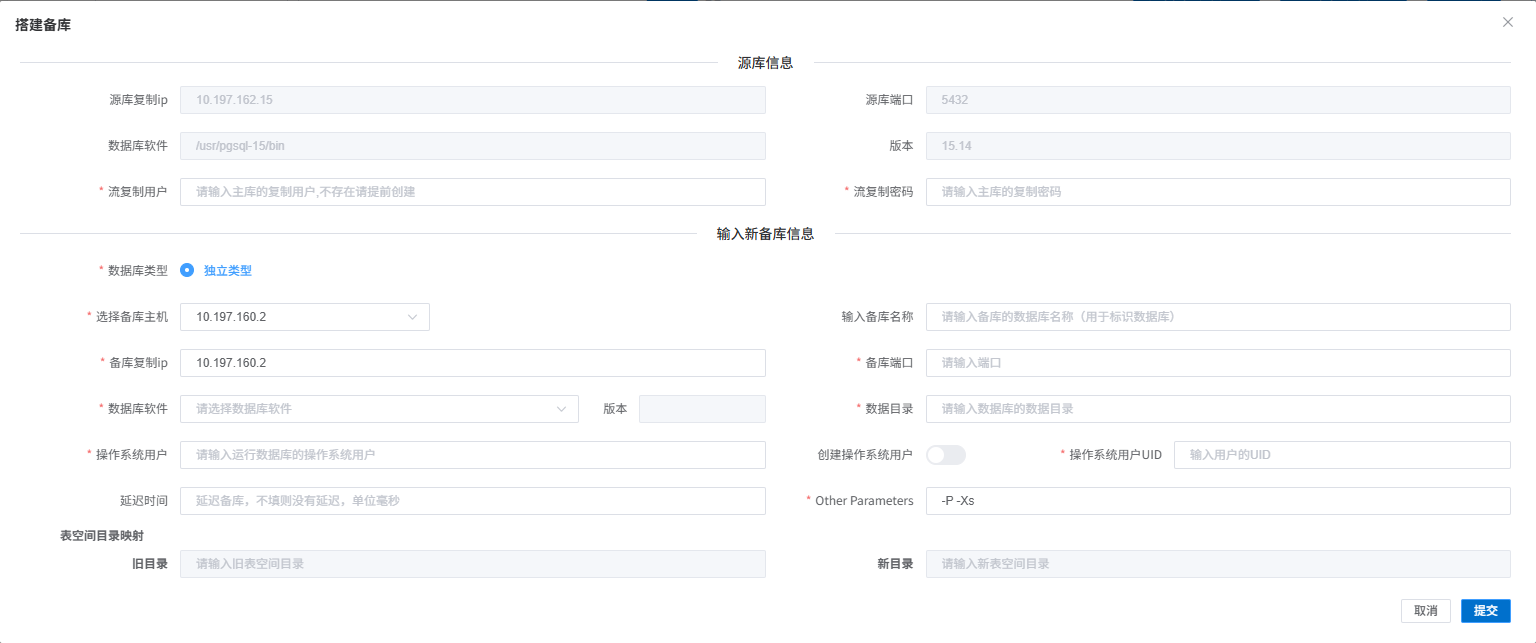
- 源复制ip:要搭建的备库的流复制的上级库的IP
- 源端口:要搭建的备库的流复制的上级库的IP
- 源库数据库软件及版本:后面选择备库的软件及版本时需要选择与此处相同版本的数据库软件
- 流复制用户:流复制用户,如果源库已配置,则会禁止修改
- 流复制密码:源库的流复制用户密码,如果源库已配置,则会禁止修改
- 备库主机: 选择在哪台主机上建这个备库。下拉列表是运行了clup-agent的主机列表
- 备库名称: 用于标识数据库
- 备库复制ip:填写新建的备库复制IP,如果没有为流复制分布单独的网络,则填写主机的IP
- 备库端口:备库的数据库端口,默认同主库端口一样,不能修改
- 数据库软件及版本:需要选择与源库相同版本的数据库软件,选择后会自动获得版本信息
- 数据目录:备库数据存放目录,目录不存在会自动创建
- 操作系统用户:备库运行在哪个操作系统用户。如果没有此操作系统用户,需要输入后面的操作系统用户的UID,系统会自动创建此用户
- 延迟时间:用以延时搭建备库,单位毫秒,默认无延迟
- other_param:系统使用pg_basebackup搭建备库时需要带的一些附带参数,默认-P -Xs。
点击提交后开始自动创建备库,同时弹出一个框显示创建备库过程的日志:
5. 切换上级库
在一主多备的环境中,每个备库不一定都要从主库接收流复制数据,也可以从另一个备库接收流复制数据,我们可以修改某一个备库,让其从另外一个库接收流复制数据。
点更多按钮弹出菜单,然后在菜单中点切换上级库,就可以修改当前备库的上级库。注意如果当前备库在HA集群中,需要先将HA集群离线后才可以操作。弹出一个对话框:
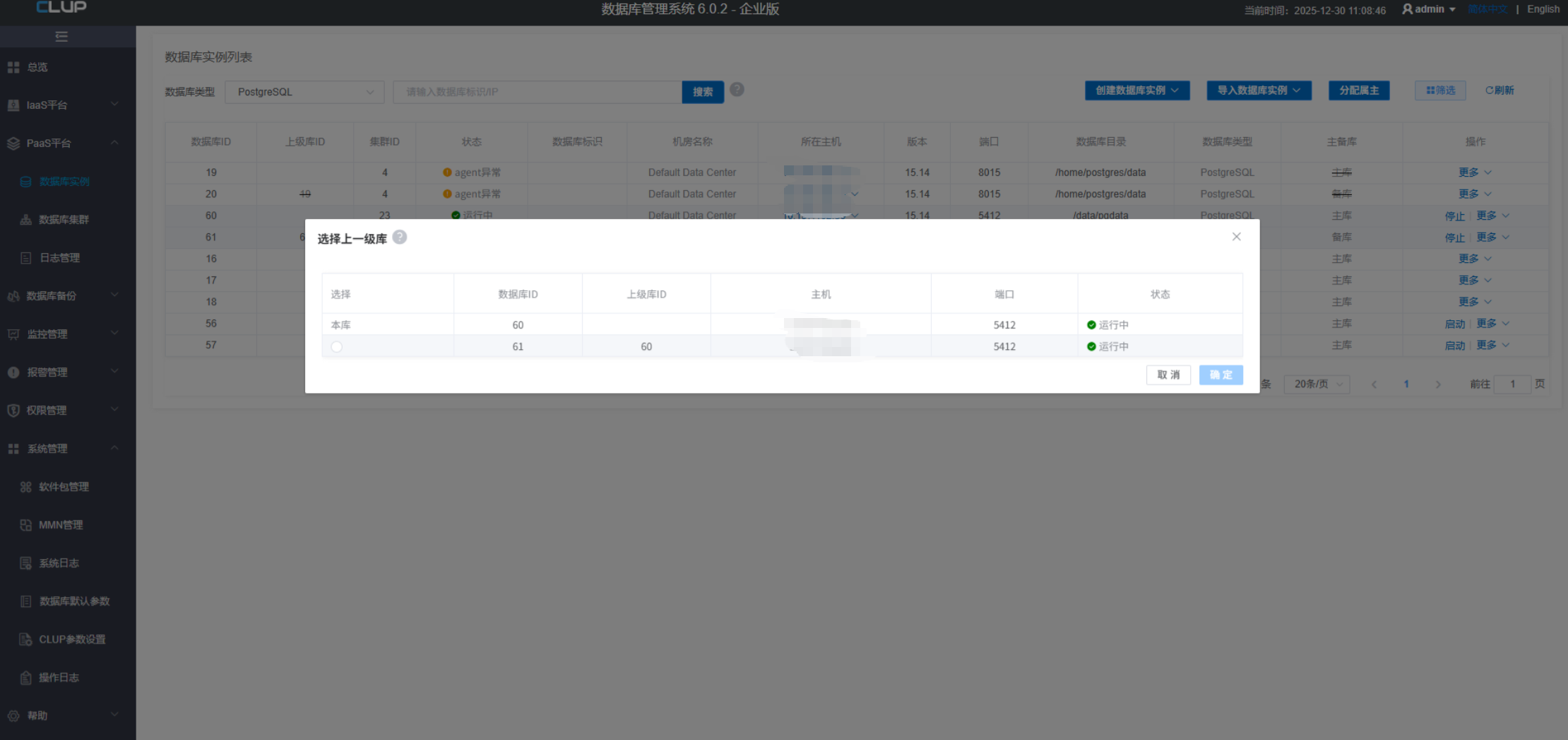
选择为此备库选择一个新的上级库,点确定即可以完成此备库的上级库的切换。
选择一个数据库作为他的上一级主库,当前节点的所有子节点关系不变。
如果选择的上级库是他的子节点,就会将当前数据库单独分离出来作为选择的上级主库的备库,之前的子节点跟在之前的上一级节点上。
如果将一个主库的上级库指向一个备库,会在此备库会变成新主库。
例子:
- 如果所选的上级库在当前库的子节点中,所选库会作为当前库上级库的备库,其他的字节点关系不变:A(主库)--->B(当前库)--->C(所选上级库) 操作后关系变成:A--->C--->B
- 如果当前库是主库,会将所选的库作为新的主库,旧的主库作为新的主库的备库,其他的上下级关系不变:A(主库也是当前库)--->B--->C(所选库) 操作后关系变成: C(主库)---> A --->B
6. 激活备库
该功能会将一个备库激活为主库。点更多按钮弹出菜单,然后在菜单中点激活既可以完成备库的激活操作。如果备库是在一个HA集群中,则会弹出一个对话框:

激活这个备库,会导致这个备库和它的所有子节点都脱离HA集群,这些节点在后面的HA集群中将看不到。
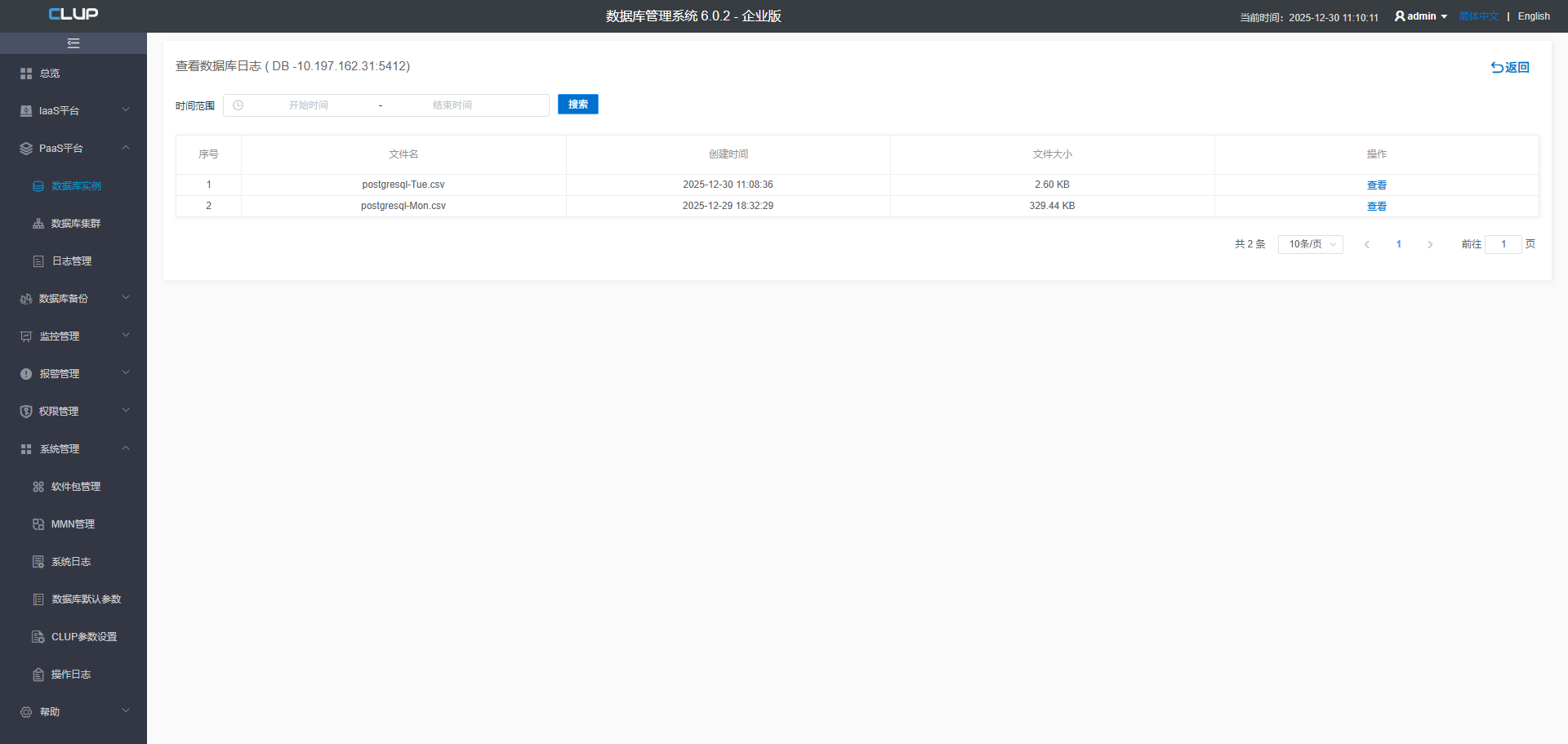
7. 查看数据库日志
该功能可以查看该数据库实例的所有日志,日志文件按照时间顺序倒序排列,还可以通过时间范围查找文件。查看日志文件内容,可以选择查看的日志文件大小,默认2KB。
8. 详情
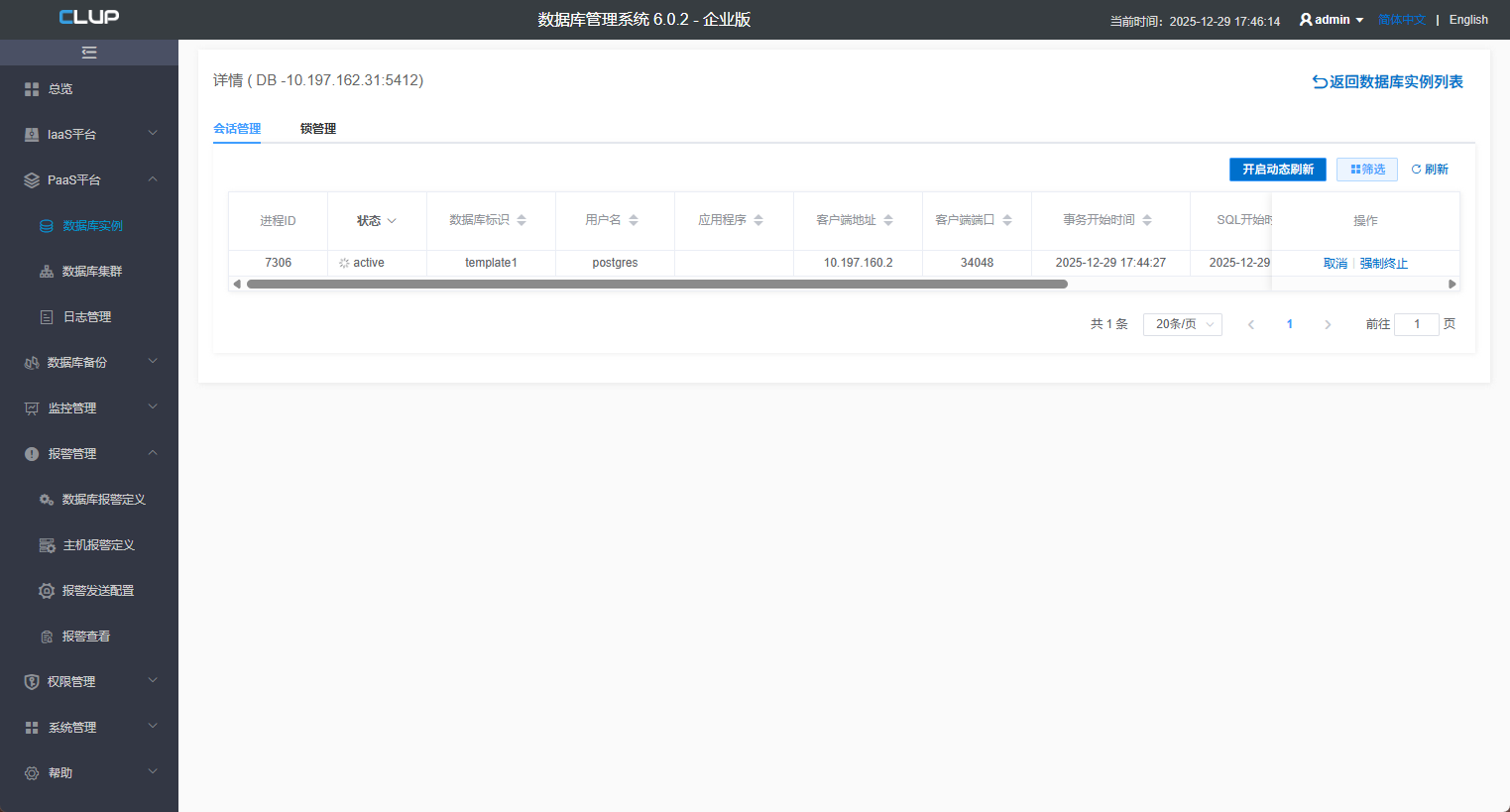
8.1 会话管理
该页面对数据库的连接(即session)进行管理,列表中可以查看各个连接的进程ID、状态、数据库名、用户名、应用程序、客户端地址、客户端端口、事务开始时间、SQL开始时间、等待事件、运行SQL、进程类型。 然后根据需求可以对进程取消 和强制终止 :
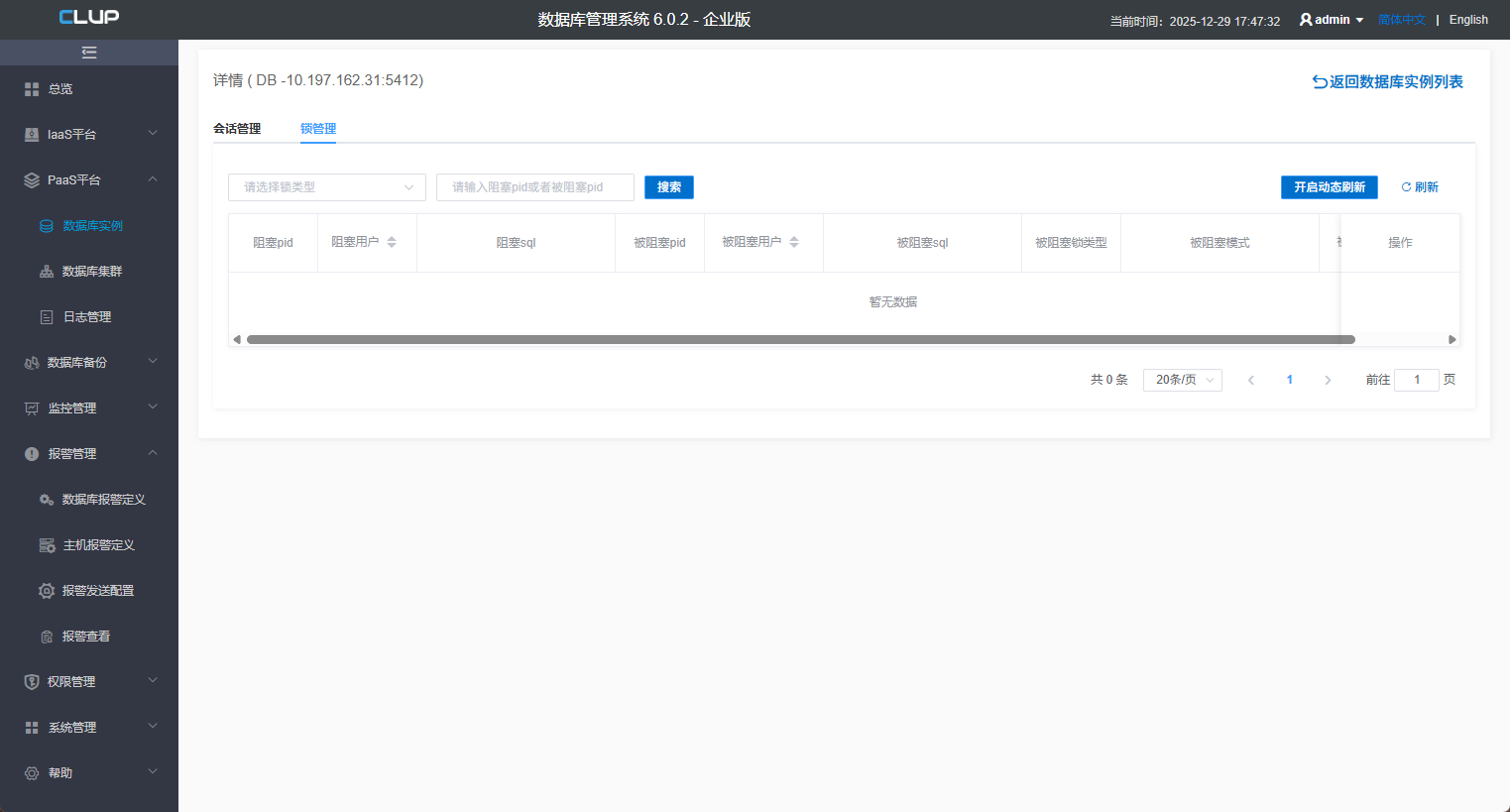
8.2 锁管理
锁管理页面,可以在这个页面看到数据库被阻塞的sql,也可以直接将sql结束掉: