AgiBot World Colosseo: A Large-scale Manipulation Platform for Scalable and Intelligent Embodied Systems
📄 arXiv: arXiv:2503.06669 | 🏷️ VLA模型 | ⭐ 评分: 8.5/10
🔑 论文笔记 VLA模型 机器人操作 数据集 具身智能 潜在动作 双臂操作 灵巧手 GO-1 AgiBot-World
文章目录
- [AgiBot World Colosseo: A Large-scale Manipulation Platform for Scalable and Intelligent Embodied Systems](#AgiBot World Colosseo: A Large-scale Manipulation Platform for Scalable and Intelligent Embodied Systems)
核心信息
- 论文ID:arXiv:2503.06669
- 作者:AgiBot-World Contributors (香港大学、AgiBot Inc.、上海创新研究院、上海AI Lab联合团队)
- 机构:The University of Hong Kong, AgiBot Inc., Shanghai Innovation Institute, Shanghai AI Lab
- 发布时间:2025-03-09
- 会议/期刊:IROS 2025 (camera-ready update July 2025)
- 链接 :arXiv | PDF
- 项目主页:https://agibot-world.com/
- 代码:https://github.com/OpenDriveLab/AgiBot-World
- 许可证:CC BY-NC-SA 4.0
摘要翻译
英文摘要
We explore how scalable robot data can address real-world challenges for generalized robotic manipulation. Introducing AgiBot World, a large-scale platform comprising over 1 million trajectories across 217 tasks in five deployment scenarios, we achieve an order-of-magnitude increase in data scale compared to existing datasets. Accelerated by a standardized collection pipeline with human-in-the-loop verification, AgiBot World guarantees high-quality and diverse data distribution. It is extensible from grippers to dexterous hands and visuo-tactile sensors for fine-grained skill acquisition. Building on top of data, we introduce Genie Operator-1 (GO-1), a novel generalist policy that leverages latent action representations to maximize data utilization, demonstrating predictable performance scaling with increased data volume. Policies pre-trained on our dataset achieve an average performance improvement of 30% over those trained on Open X-Embodiment, both in in-domain and out-of-distribution scenarios. GO-1 exhibits exceptional capability in real-world dexterous and long-horizon tasks, achieving over 60% success rate on complex tasks and outperforming prior RDT approach by 32%.
中文翻译
本文探索了可扩展的机器人数据如何解决通用机器人操作中的现实世界挑战。我们提出 AgiBot World------一个大规模平台,包含横跨五大部署场景、217项任务的超过100万条轨迹,相比现有数据集实现了数量级的规模提升。通过标准化采集流水线和人在环验证,AgiBot World 保证了高质量和多样性的数据分布。该平台可从夹爪扩展到灵巧手和视觉触觉传感器,以实现精细技能习得。在数据基础之上,我们提出 Genie Operator-1 (GO-1),一种利用潜在动作表征最大化数据利用率的通用策略,展现了随数据量增加的可预测性能扩展。在我们的数据集上预训练的策略相比在 Open X-Embodiment 上训练的策略,在域内和域外场景下均实现了平均30%的性能提升。GO-1 在现实世界灵巧操作和长时序任务中展现了卓越能力,在复杂任务上达到超过60%的成功率,超越先前 RDT 方法32%。
核心要点提炼
- 研究背景:机器人操作领域缺乏大规模、高质量、多样化的真实世界数据集,现有数据集局限于短时序桌面任务
- 研究动机:如何通过扩展真实世界机器人数据来解决通用操作的现实挑战
- 核心方法:构建全栈大规模平台(数据+模型+基准+生态),提出 ViLLA 框架利用潜在动作实现跨模态预训练
- 主要结果:数据集预训练策略比 OXE 提升30%,GO-1 超越 RDT 32%,复杂任务成功率超60%
- 研究意义:开源最大规模机器人操作数据集,推动通用具身智能发展
研究背景与动机
领域现状
机器人操作是具身智能的核心任务,但相比NLP和CV领域的大模型发展,机器人领域严重滞后。根本原因在于高质量数据采集困难------现有数据集存在碎片化、异构硬件、非标准化采集流程等问题,导致数据质量低、一致性差。
现有方法的局限性
- Open X-Embodiment (OXE):虽然聚合了140万条轨迹,但数据来自不同硬件平台,质量参差不齐,embodiment差异大,训练出的策略仅限于简单短时序任务,泛化能力弱
- DROID:通过众包采集多样化场景数据,但缺乏数据质量保证(无人在环验证),硬件受限(仅固定单臂机器人)
- 其他数据集(RoboNet, BridgeData, RT-1等):规模小、场景单一、技能覆盖有限,均未超出实验室桌面任务范畴
研究动机
实现通用机器人智能需要同时满足:数据规模与多样性的扩展、真实世界复杂性的捕获、标准化采集流水线保证质量、精心设计的真实世界任务。AgiBot World 正是为解决这些需求而构建。
研究问题
核心研究问题
如何通过扩展真实世界机器人数据来有效解决现实世界的操作复杂性?
具体而言:
- 如何构建大规模、高质量、多样化的机器人操作数据集?
- 如何利用异构数据源(人类视频+机器人数据)训练通用策略?
- 数据规模与策略性能之间是否存在可预测的扩展规律?
方法概述
核心思想
AgiBot World 是一个全栈式机器人学习平台,由三部分组成:(1) 大规模高质量数据集,(2) 通用策略模型 GO-1,(3) 评估基准和开源生态。
方法框架
整体架构
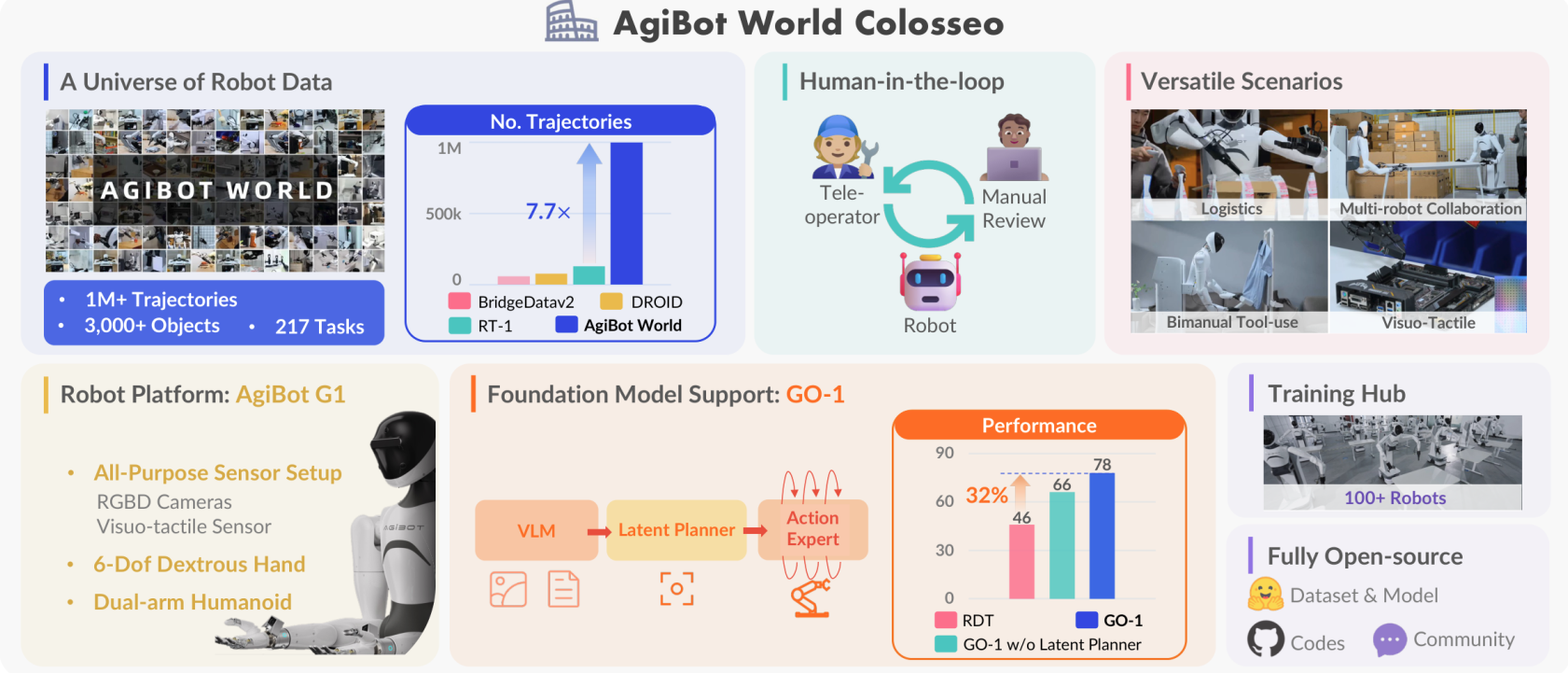
图1:AgiBot World Colosseo 平台概览。包含数据、模型、基准和生态四大模块,100台双臂人形机器人同时采集数据,GO-1 策略相比先前方法提升32%。
数据集:AgiBot World
硬件平台:AgiBot G1 人形机器人
- 双7自由度手臂 + 移动底盘 + 可调腰部
- 末端执行器可模块化切换:标准夹爪 / 6自由度灵巧手 / 视觉触觉传感器夹爪
- 8个摄像头:前视RGB-D + 3个鱼眼 + 双腕部 + 2个后视
- 30Hz 控制频率记录图像观测和本体感知状态
- 两种遥操作方式:VR头显控制 + 全身动捕控制
数据采集流水线:
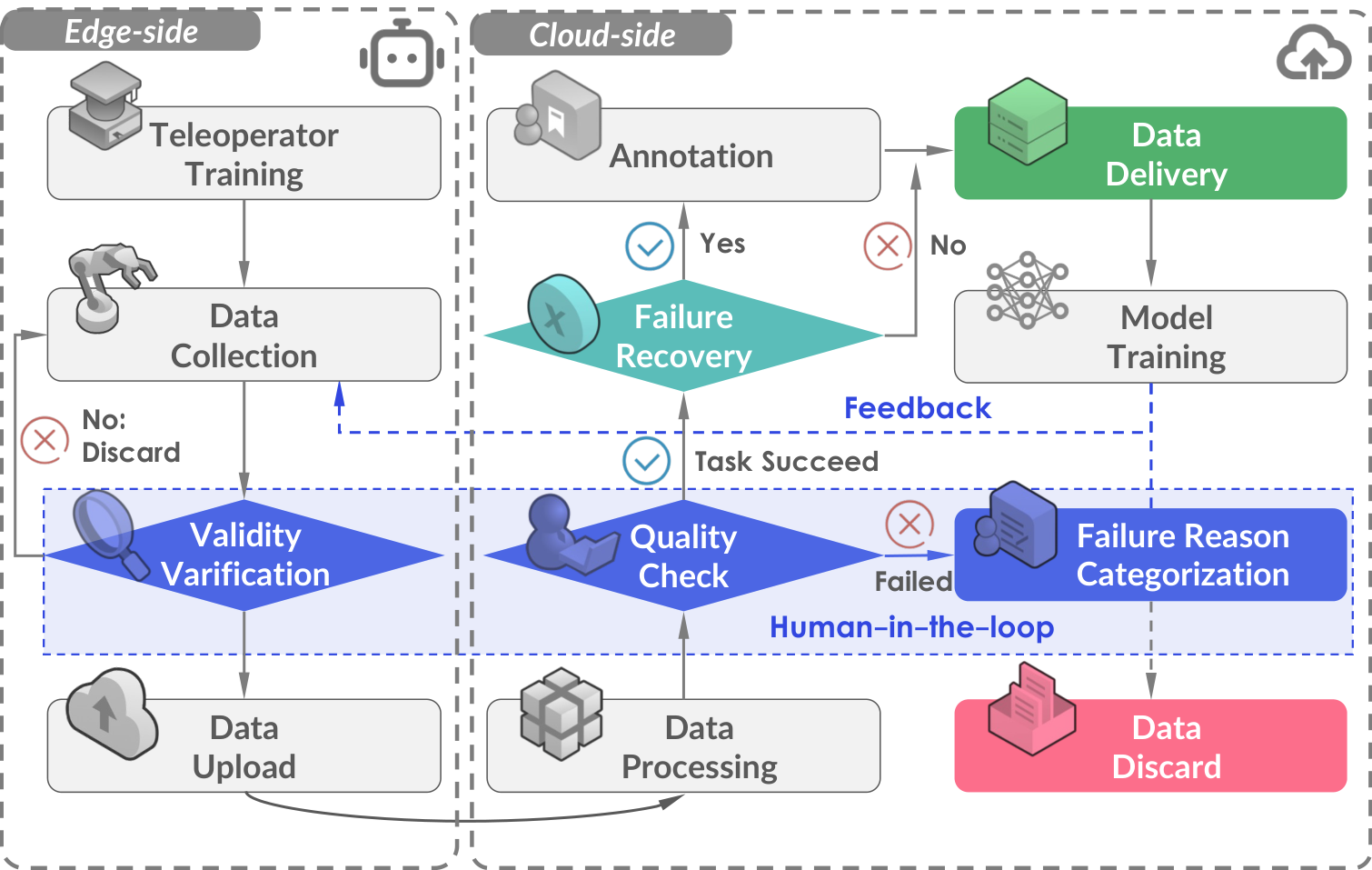
图2:数据采集流水线。采用人在环框架确保数据质量,包含详细标注和错误恢复行为。人工反馈不仅在采集后审查中起关键作用,还主动引导数据采集过程。
三个阶段:
- 预采集验证:验证任务可行性,建立采集标准
- 正式采集:熟练遥操作员按标准采集,本地验证数据完整性后上传云端
- 后处理:标注员验证是否符合标准,提供语言标注
关键创新:
- 错误恢复数据:保留操作失误但成功恢复的轨迹(约1%数据集),标注失败原因和时间戳,用于策略对齐和失败反思
- 人在环验证:迭代循环------采集少量演示→训练策略→部署评估→反馈改进采集流程
数据集统计:
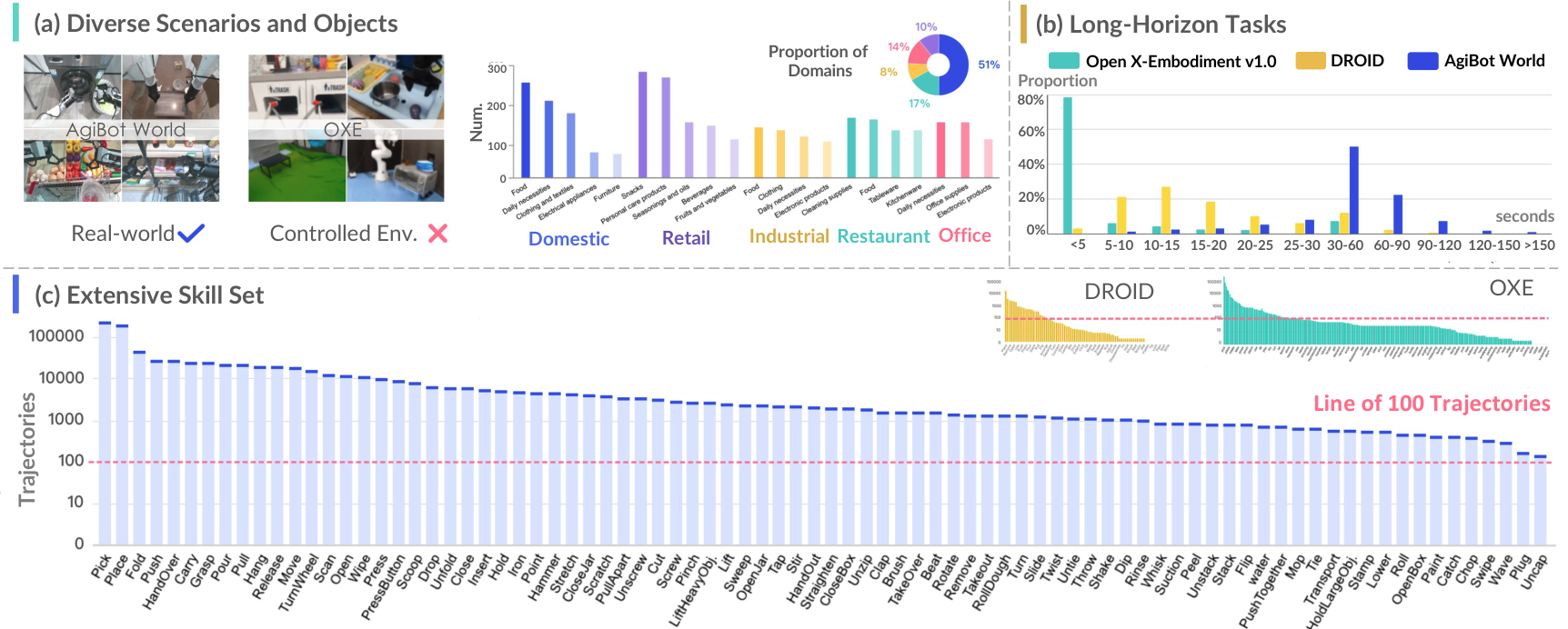
图3:数据集统计。(a) 覆盖五大领域和3000+物体类别。(b) 长时序任务为主(30-60秒),远超DROID(5-20秒)和OXE(<5秒)。© 87种原子技能,每种至少100条轨迹。
| 统计项 | 数值 |
|---|---|
| 轨迹数 | 1,001,552 |
| 总时长 | 2,976.4小时 |
| 任务数 | 217 |
| 技能数 | 87 |
| 场景数 | 106 |
| 场景面积 | 4,000+ 平方米 |
| 物体数 | 3,000+ |
| 机器人数 | 100 |
| 领域 | 5个(家庭、零售、工业、餐饮、办公) |
模型:GO-1 (Genie Operator-1)
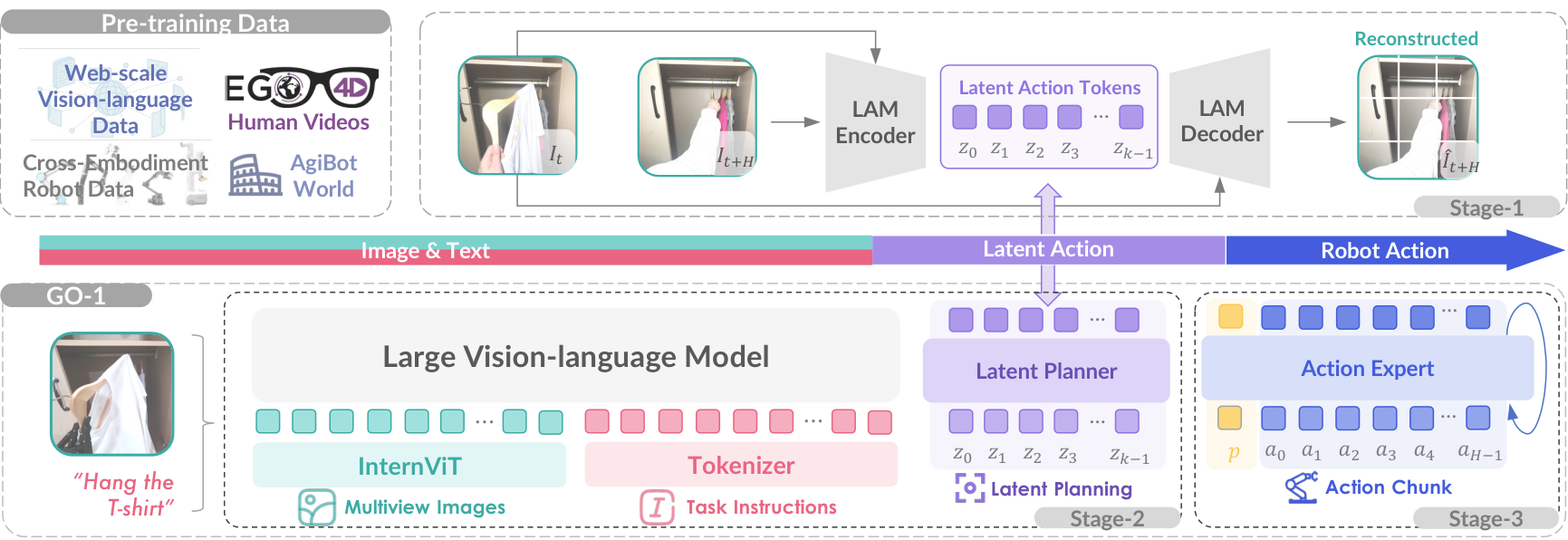
图4:GO-1 架构------Vision-Language-Latent-Action (ViLLA) 框架。潜在动作模型(LAM)从网络规模视频学习通用动作表征,量化为离散潜在动作token;潜在规划器通过潜在动作预测进行时序推理,桥接图像文本输入和机器人动作。
三阶段训练:
模块1:潜在动作模型 (LAM)
- 功能:从连续图像帧中提取潜在动作表征
- 输入 :连续帧 { I t , I t + H } \{I_t, I_{t+H}\} {It,It+H}
- 输出 :离散潜在动作token z t = z t 0 , . . . , z t k − 1 z_t = z_t\^0, ..., z_t\^{k-1} zt=zt0,...,ztk−1, k = 4 k=4 k=4
- 关键技术 :逆动力学编码器 I ( z t ∣ I t , I t + H ) \mathbf{I}(z_t | I_t, I_{t+H}) I(zt∣It,It+H) + 正动力学解码器 F ( I t + H ∣ I t , z t ) \mathbf{F}(I_{t+H} | I_t, z_t) F(It+H∣It,zt)
- 训练数据:网络规模异构数据(Ego4D人类视频)
- 量化 :VQ-VAE目标,码本大小 ∣ C ∣ |C| ∣C∣
- 架构:编码器使用时空Transformer + 因果时序mask;解码器使用空间Transformer
模块2:潜在规划器 (Latent Planner)
- 功能:实现具身无关的长时序规划
- 输入 :多视角图像 ( I t h , I t l , I t r ) (I_t^h, I_t^l, I_t^r) (Ith,Itl,Itr) + 语言指令 l l l
- 输出 :潜在动作token P ( z t ∣ I t h , I t l , I t r , l ) \mathbf{P}(z_t | I_t^h, I_t^l, I_t^r, l) P(zt∣Ith,Itl,Itr,l)
- 关键技术:InternVL2.5-2B 作为VLM骨干,24层Transformer
- 监督 :LAM编码器生成的伪标签 z t : = I ( I t h , I t + H h ) z_t := \mathbf{I}(I_t^h, I_{t+H}^h) zt:=I(Ith,It+Hh)
- 优势:潜在动作空间远小于离散化低层动作空间,高效适配VLM到机器人策略
模块3:动作专家 (Action Expert)
- 功能:高频灵巧操作控制
- 输入 :多视角图像 + 本体感知状态 p t p_t pt + 语言指令
- 输出 :低层动作chunk A t = a t , a t + 1 , . . . , a t + H A_t = a_t, a_{t+1}, ..., a_{t+H} At=at,at+1,...,at+H, H = 30 H=30 H=30
- 关键技术:扩散目标建模连续动作分布,迭代去噪生成控制信号
- 推理流程 :VLM→潜在规划器预测 k k k个潜在动作token→动作专家条件去噪→最终控制信号
\\mathbf{P}(z_t \| I_t\^h, I_t\^l, I_t\^r, l) \\rightarrow \\mathbf{A}(A_t \| I_t\^h, I_t\^l, I_t\^r, p_t, l)
实验结果
实验目标
验证三个核心问题:(1) AgiBot World 数据集是否提升策略学习?(2) GO-1 是否是更强的通用策略?(3) 性能是否随数据规模可预测扩展?
数据集
评估任务
| 任务 | 类型 | 描述 |
|---|---|---|
| Restock Bag | 工具使用 | 从推车取零食放超市货架 |
| Table Bussing | 清理 | 清理桌面杂物入垃圾桶 |
| Pour Water | 精细操作 | 抓壶柄、提壶倒水入杯 |
| Restock Beverage | 语言跟随 | 取瓶装饮料放指定货架位置 |
| Fold Shorts | 可变形物体 | 将短裤对折两次 |
| Wipe Table | 工具使用 | 用海绵擦拭水渍 |
每个任务设计2个未见场景,覆盖位置泛化、视觉干扰和语言泛化。
实验设置
基线方法
- RDT-1B:基于扩散Transformer的通用策略,先验最强开源通用策略
- π 0 \pi_0 π0:使用预训练VLM骨干和流匹配动作专家的策略
- GO-1 w/o Latent Planner:去掉潜在规划器的消融基线
评估指标
归一化任务完成分数:每个任务/场景/方法10次rollout平均,完全成功1.0分,部分成功给部分分。
主要结果
AgiBot World vs OXE 数据集对比
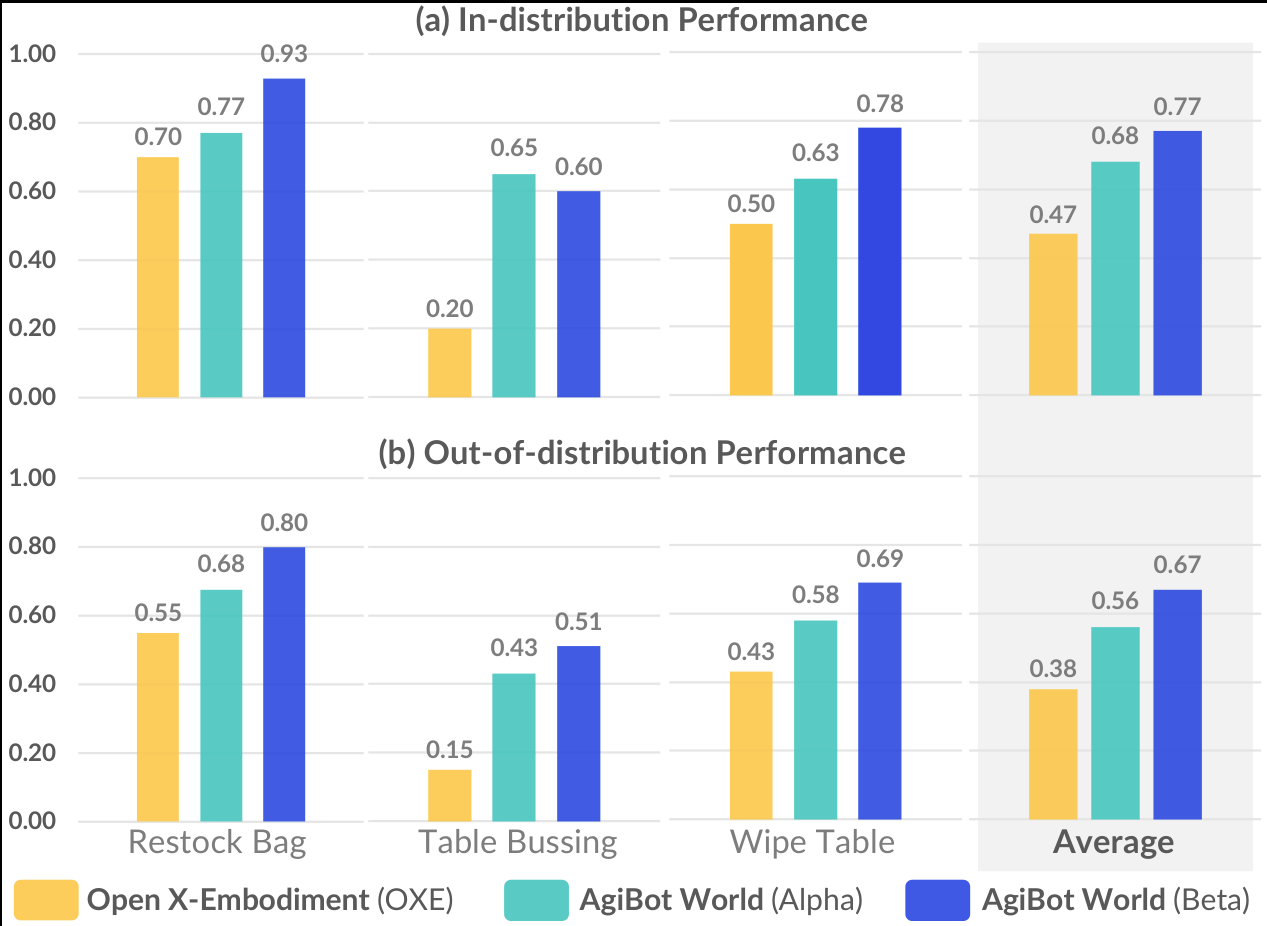
图5:在 AgiBot World 数据集上预训练的策略显著优于 OXE,域内(0.77 vs 0.47)和域外(0.67 vs 0.38)均大幅领先。仅用 alpha 子集(1/10数据量)也优于 OXE。
| 数据源 | 域内成功率 | 域外成功率 | 平均提升 |
|---|---|---|---|
| OXE | 0.47 | 0.38 | -- |
| AgiBot World alpha (236h) | >0.47 | >0.38 | +18% |
| AgiBot World beta | 0.77 | 0.67 | +30% |
注:alpha 子集仅含约14%轨迹(236小时 vs OXE ~2000小时),但性能更优,凸显数据质量的重要性。
GO-1 模型对比
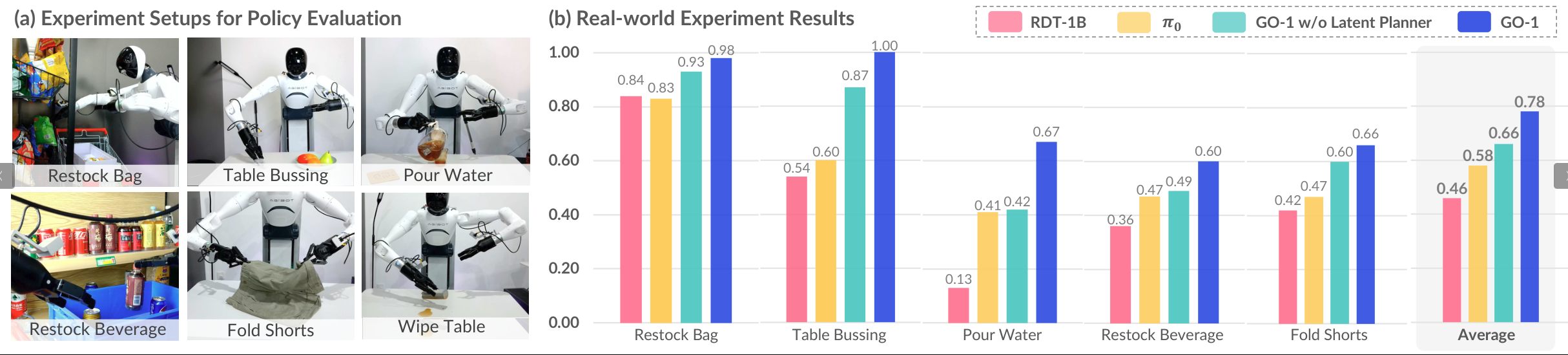
图6:GO-1 在所有任务上大幅超越 RDT-1B 和无潜在规划器基线。潜在规划器在复杂任务(如"Fold Shorts")上提升显著,在"Restock Beverage"上极大提升泛化能力。
GO-1 相比 RDT 平均提升32%,潜在规划器带来平均0.12的任务完成分数提升。在"Pour Water"(需对物体位置鲁棒)和"Restock Beverage"(需指令跟随)上优势尤为突出。
数据扩展规律
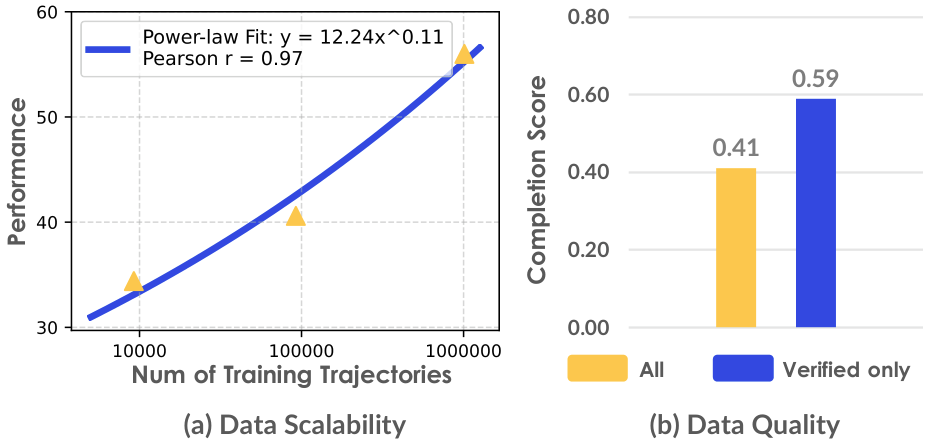
图7:(a) 策略性能与数据量呈现可预测的幂律扩展关系(Pearson r = 0.97 r=0.97 r=0.97),从9.2k到1M轨迹。 (b) 人工验证数据虽少但质量高,比未验证数据提升0.18完成分数。
消融实验
数据质量影响
- 人工验证数据(528条轨迹) vs 未验证数据(482条轨迹)
- 结论:数据量更大不一定更好,高质量人工验证数据带来0.18完成分数提升
潜在规划器消融
- 去除潜在规划器后,复杂任务(如折叠短裤)性能显著下降
- 语言跟随任务(如补货指定饮料)泛化能力大幅削弱
深度分析
研究价值评估
理论贡献
-
贡献1 :首次在机器人操作领域验证了数据规模与策略性能的幂律扩展关系( r = 0.97 r=0.97 r=0.97)
- 创新点:从9.2k到1M轨迹的连续验证
- 学术价值:为大规模数据采集提供理论支撑
- 影响范围:机器人学习、具身智能
-
贡献2:提出 ViLLA 框架,通过潜在动作表征桥接VLM和机器人控制
- 创新点:将潜在动作作为中间表征,实现web-scale预训练到机器人策略的高效迁移
- 学术价值:解决了异构数据源(人类视频+机器人数据)联合训练的关键问题
- 影响范围:VLA模型、机器人基础模型
实际应用价值
-
应用场景1:家庭服务机器人
- 适用性:数据集覆盖大量家庭场景(厨房、卧室、客厅等)
- 优势:长时序任务、双臂协作能力
- 潜在影响:推动家用机器人从实验室走向实际部署
-
应用场景2:工业与零售自动化
- 适用性:数据集包含工业和零售场景的1:1复刻环境
- 优势:标准化采集流程保证数据质量
- 潜在影响:降低工业场景机器人部署的数据门槛
领域影响
- 短期影响:成为最大规模开源机器人操作数据集,推动社区研究
- 中期影响:ViLLA框架可能成为VLA模型的新范式
- 长期影响:验证了数据扩展规律,为机器人基础模型发展指明方向
- 潜在变革:从单任务策略学习到通用操作智能的范式转变
方法优势详解
优势1:全栈式平台设计
- 描述:数据+模型+基准+生态的完整闭环
- 技术基础:4000平方米场地、100台机器人、标准化流水线
- 实验验证:人在环验证流程持续提升数据质量
- 对比分析:OXE仅聚合数据,DROID仅众包采集,均无完整生态
优势2:潜在动作规划
- 描述:通过LAM学习通用动作表征,潜在规划器实现长时序推理
- 技术基础:VQ-VAE量化+VLM骨干(InternVL2.5-2B)+扩散动作专家
- 实验验证:复杂任务平均提升0.12完成分数
- 对比分析:直接预测低层动作的方法(如OpenVLA)动作空间大、效率低
优势3:数据质量保证
- 描述:人在环验证+错误恢复数据+详细标注
- 技术基础:三阶段采集流水线+迭代反馈机制
- 实验验证:验证数据比未验证数据提升0.18完成分数
- 对比分析:众包数据(如DROID)缺乏质量保证
局限性分析
局限1:仅限真实世界评估
- 描述:所有评估均在真实世界进行,缺少仿真环境
- 表现:评估成本高、不可复现
- 原因:仿真环境尚未开发完成
- 影响:限制了社区对方法的可复现验证
- 可能的解决方案:论文提到正在开发仿真环境
局限2:单一硬件平台
- 描述:数据采集仅使用 AgiBot G1 一种机器人
- 表现:跨embodiment泛化能力未验证
- 原因:标准化采集需要统一硬件
- 影响:策略迁移到其他机器人平台的可行性未知
- 可能的解决方案:引入更多embodiment类型的数据
局限3:领域覆盖有限
- 描述:五大领域虽多,但未覆盖医疗、农业、建筑等
- 表现:策略在这些领域的适用性未验证
- 原因:场地和成本限制
- 影响:限制了通用性声明
- 可能的解决方案:社区协作扩展更多场景
适用性与场景分析
适用场景
-
场景1:双臂协作操作
- 适用原因:数据集以双臂任务为核心设计
- 预期效果:显著优于单臂数据训练的策略
- 注意事项:需要双臂机器人平台
-
场景2:长时序复杂任务
- 适用原因:轨迹平均30秒,最长超2分钟,潜在规划器支持长时序推理
- 预期效果:复杂任务成功率超60%
- 注意事项:任务设计需分解为可标注的子步骤
不适用场景
- 场景1 :单臂桌面简单任务
- 不适用原因:数据集面向复杂任务,简单任务用更小数据集即可
- 替代方案:BridgeData V2 或 RT-1 数据集
与相关论文对比
对比论文选择依据
选择同样面向大规模机器人数据集和通用策略的代表性工作进行对比。
Open X-Embodiment - Padalkar et al., 2023
方法对比
| 对比维度 | OXE | AgiBot World |
|---|---|---|
| 核心思想 | 聚合已有数据集 | 从零构建标准化数据 |
| 数据规模 | 1.4M轨迹 | 1M+轨迹 |
| 硬件统一性 | 22种不同机器人 | 1种标准化机器人 |
| 质量保证 | 无 | 人在环验证 |
| 任务复杂度 | 短时序桌面任务 | 长时序真实世界任务 |
性能对比
| 指标 | OXE | AgiBot World | 提升 |
|---|---|---|---|
| 域内成功率 | 0.47 | 0.77 | +64% |
| 域外成功率 | 0.38 | 0.67 | +76% |
关系分析
- 关系类型:改进
- 本文改进:统一硬件+标准化流水线+质量保证+真实世界场景
- 优势:数据质量和一致性远优于聚合数据集
- 劣势:embodiment多样性不足
- 互补性:OXE的跨embodiment特性与AgiBot World的质量优势互补
RDT-1B - Liu et al., 2024
方法对比
| 对比维度 | RDT | GO-1 |
|---|---|---|
| 核心思想 | 扩散Transformer+多机器人预训练 | ViLLA框架+潜在动作+VLM |
| 动作预测 | 扩散模型直接预测 | 潜在规划器+扩散动作专家 |
| 预训练数据 | 异构多机器人数据 | Web视频+机器人数据 |
| 规划能力 | 无显式规划 | 潜在动作时序推理 |
关系分析
- 关系类型:改进
- 本文改进:引入潜在动作规划层,实现长时序推理
- 优势:GO-1在复杂任务上超越RDT 32%
π₀ - Black et al., 2024
关系分析
- 关系类型:对比
- 本文改进:潜在动作表征使web视频预训练更高效
- 优势:显式的时序规划能力
- 劣势:π₀在灵巧手任务上经验丰富,但未开源
对比总结
AgiBot World 的核心优势在于"质量优于数量"------即使是alpha子集(1/10数据量)也优于OXE全量。GO-1通过ViLLA框架将VLM的知识有效迁移到机器人控制,在长时序和泛化能力上显著超越RDT和π₀。
技术路线定位
所属技术路线
本文属于VLA/具身智能基础模型技术路线,核心特点是:
- 特点1:大规模高质量数据驱动策略学习
- 特点2:视觉-语言-动作的多模态对齐
- 特点3:从web知识到机器人控制的迁移学习
技术路线发展历程
RT-1 (2022) → RT-2 (2023) → Octo (2024) → RDT (2024) → π₀ (2024) → GO-1 (2025)
↓ ↓ ↓ ↓ ↓ ↓
130k轨迹 VLM增强 开源通用 扩散策略 流匹配 潜在动作
简单任务 语义理解 策略 双臂预训练 灵巧操作 长时序规划本文在技术路线中的位置
- 承上:继承了RDT的扩散策略框架、π₀的VLM+动作专家架构、LAPA的潜在动作思想
- 启下:验证了数据扩展幂律规律、开创了ViLLA框架范式
- 关键节点:首个将潜在动作规划与VLM有效结合并验证扩展规律的工作
具体子方向
本文主要关注大规模数据驱动+潜在动作规划的通用操作策略,该子方向的研究重点是:
- 重点1:如何在异构数据源(人类视频+机器人数据)上联合训练
- 重点2:潜在动作空间如何桥接高层推理和低层控制
未来工作建议
作者建议的未来工作
-
建议1:开发仿真环境
- 可行性:正在进行中
- 价值:实现快速可复现评估
- 难度:中等(需与真实世界对齐)
-
建议2:社区协作扩展生态
- 可行性:已开源数据集和工具
- 价值:推动领域整体发展
- 难度:低(基础设施已就绪)
基于分析的未来方向
-
方向1:跨embodiment迁移
- 动机:当前仅支持单一机器人平台
- 可能的方法:潜在动作空间的embodiment条件化
- 预期成果:策略可迁移到不同机器人
- 挑战:不同硬件的动力学差异
-
方向2:仿真到真实的桥接
- 动机:真实世界评估成本高、不可复现
- 可能的方法:基于AgiBot World场景构建数字孪生
- 预期成果:快速策略评估和迭代
- 挑战:仿真与现实的对齐精度
-
方向3:多机器人协作
- 动机:数据集已包含协作任务,但策略层面尚未专门优化
- 可能的方法:多智能体潜在动作规划
- 预期成果:多机器人协同完成复杂任务
- 挑战:通信延迟和协调策略
改进建议
-
改进1:增加embodiment多样性
- 当前问题:单一机器人平台限制跨体泛化
- 改进方案:采集多种机器人的数据,使用embodiment token条件化
- 预期效果:提升跨体泛化能力
-
改进2:引入在线学习机制
- 当前问题:策略部署后无法自适应
- 改进方案:利用错误恢复数据进行在线微调
- 预期效果:策略在实际使用中持续改进
我的综合评价
价值评分
总体评分
8.5/10 - 机器人操作数据集和通用策略领域的重要工作,数据规模和质量均创新高
分项评分
| 评分维度 | 分数 | 评分理由 |
|---|---|---|
| 创新性 | 8/10 | ViLLA框架和潜在动作规划有新意,但整体思路仍在VLA路线内 |
| 技术质量 | 8/10 | 三阶段训练设计合理,实验全面,但部分细节(如码本大小 |
| 实验充分性 | 9/10 | 真实世界6任务评估、数据扩展规律验证、质量消融实验,覆盖全面 |
| 写作质量 | 8/10 | 结构清晰,但部分表格和公式可更详细 |
| 实用性 | 9/10 | 开源数据集和模型,CC BY-NC-SA许可,社区可直接使用 |
重点关注
值得关注的技术点
- 潜在动作模型(LAM)从人类视频学习通用动作表征的设计
- 潜在规划器与动作专家的双专家协作机制
- 人在环数据质量验证流程
- 幂律扩展规律的验证( r = 0.97 r=0.97 r=0.97)
需要深入理解的部分
- VQ-VAE码本大小 ∣ C ∣ |C| ∣C∣和token数 k = 4 k=4 k=4的选择依据
- 潜在动作空间与低层动作空间的维度关系
- 三阶段训练的具体训练细节和超参数
我的笔记
%% 用户可以在这里添加个人阅读笔记 %%
相关论文
直接相关
- Open X-Embodiment - 数据集对比基线
- RDT-1B - 模型对比基线
- π₀ - 模型对比基线
- LAPA - 潜在动作思想的来源
背景相关
- DROID - 众包机器人数据集
- Octo - 开源通用策略
- OpenVLA - VLA模型
- InternVL2.5 - GO-1的VLM骨干
后续工作
- 仿真环境开发
- 跨embodiment迁移
外部资源
- 项目主页:https://agibot-world.com/
- GitHub仓库:https://github.com/OpenDriveLab/AgiBot-World
- 数据集许可:CC BY-NC-SA 4.0
💡 关键启示
高质量数据比大规模低质量数据更重要------AgiBot World alpha(1/10数据量)就超越了OXE全量,数据质量和标准化采集流程是通用机器人策略成功的关键。
⚠️ 注意事项
- 所有评估仅在真实世界进行,无可复现的仿真基准
- 仅支持单一机器人平台(AgiBot G1),跨体泛化未验证
- 许可证为 CC BY-NC-SA 4.0,商业使用受限
📌 推荐指数
⭐⭐⭐⭐⭐ 强烈推荐!这是目前最大规模的开源机器人操作数据集,ViLLA框架为VLA模型发展提供了新范式。
📝 本文为论文深度解读笔记,基于对原论文的系统性分析和思考撰写。
🏷️ 相关标签:论文笔记 VLA模型 机器人操作 数据集 具身智能 潜在动作 双臂操作 灵巧手 GO-1 AgiBot-World
💬 欢迎在评论区讨论交流!如果觉得有帮助,请点赞收藏~