文本的常见预处理步骤
这些步骤通常包括:
- 将文本作为字符串加载到内存中。
- 将字符串拆分为词元(如单词和字符)。
- 建立一个词表,将拆分的词元映射到数字索引。
- 将文本转换为数字索引序列,方便模型操作。
python
import collections
import re
from d2l import torch as d2l
#@save
d2l.DATA_HUB['time_machine'] = (d2l.DATA_URL + 'timemachine.txt',
'090b5e7e70c295757f55df93cb0a180b9691891a')
def read_time_machine(): #@save
"""将时间机器数据集加载到文本行的列表中"""
with open(d2l.download('time_machine'), 'r') as f:
lines = f.readlines()
return [re.sub('[^A-Za-z]+', ' ', line).strip().lower() for line in lines]#.strip() 移除字符串开头和结尾的空格
lines = read_time_machine()
print(f'# 文本总行数: {len(lines)}')
print(lines[0])
print(lines[10])
Downloading ../data\timemachine.txt from http://d2l-data.s3-accelerate.amazonaws.com/timemachine.txt...
# 文本总行数: 3221
the time machine by h g wells
twinkled and his usually pale face was flushed and animated there.sub(pattern, replacement, string)
\^A-Za-z+ 是一个正则表达式模式:
\^...表示"否定字符集",即匹配不在这个集合中的任意字符。
A-Za-z表示所有英文字母(大写和小写)。
所以 \^A-Za-z匹配任何非字母的字符(如数字、标点、空格、换行等)。
+表示前面的字符出现一次或多次,即连续的非字母字符会被当作一个整体匹配。
第二个参数 ' ' 是替换内容,这里是一个空格。
第三个参数 line 是要处理的原始字符串。
因此,整句的作用是:将字符串 line中所有连续的非字母字符(包括多个连续的非字母字符)都替换成一个空格。
例如:
输入 "Hello, World! 123"→ 输出 "Hello World "(注意末尾可能有一个空格)
然后你后面还用了 .strip()去掉首尾空格,.lower()转成小写,最终得到纯英文单词组成的干净文本。
词元化:
python
def tokenize(lines, token='word'): #@save
"""将文本行拆分为单词或字符词元"""
if token == 'word':
return [line.split() for line in lines]
elif token == 'char':
return [list(line) for line in lines]
else:
print('错误:未知词元类型:' + token)
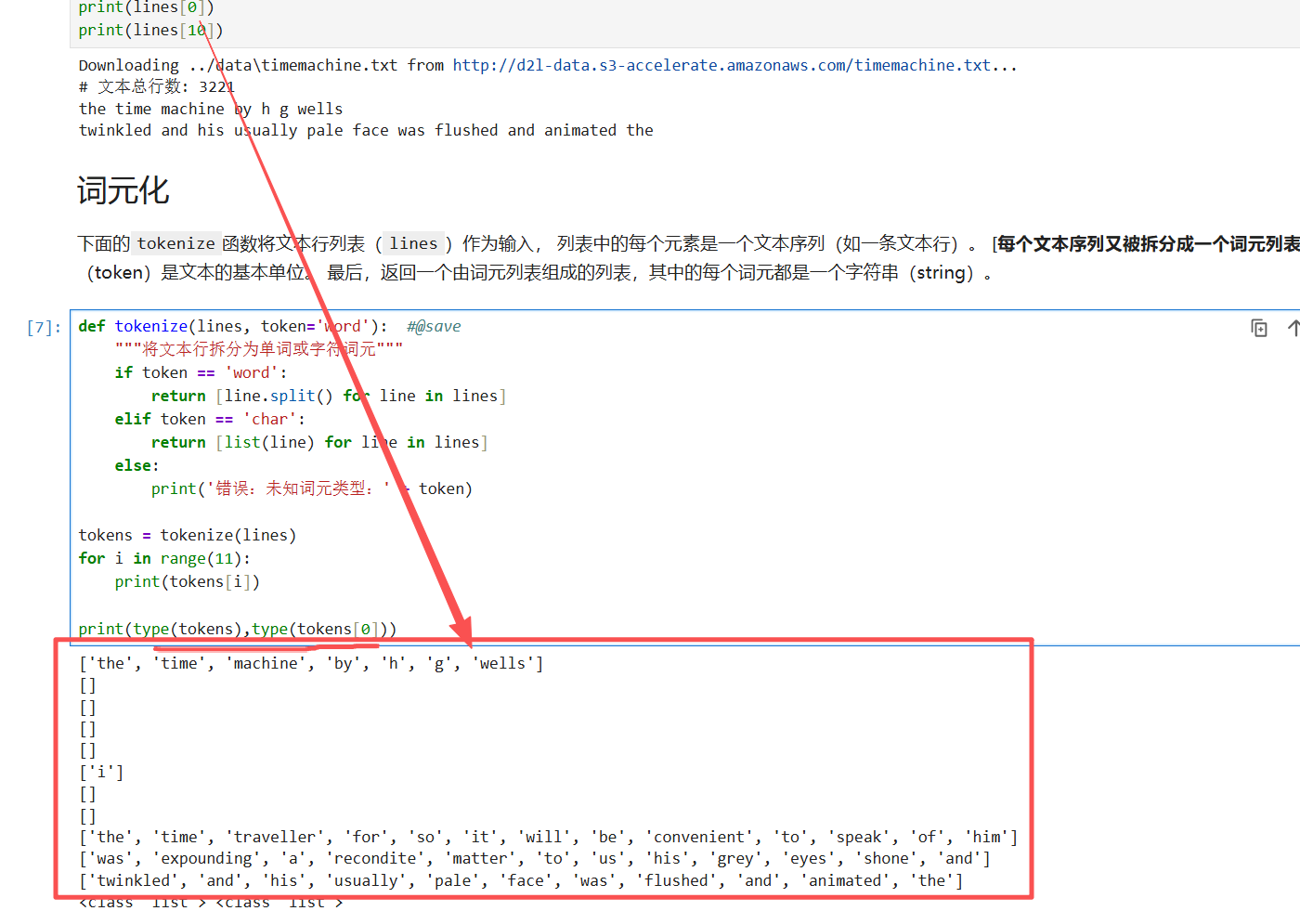
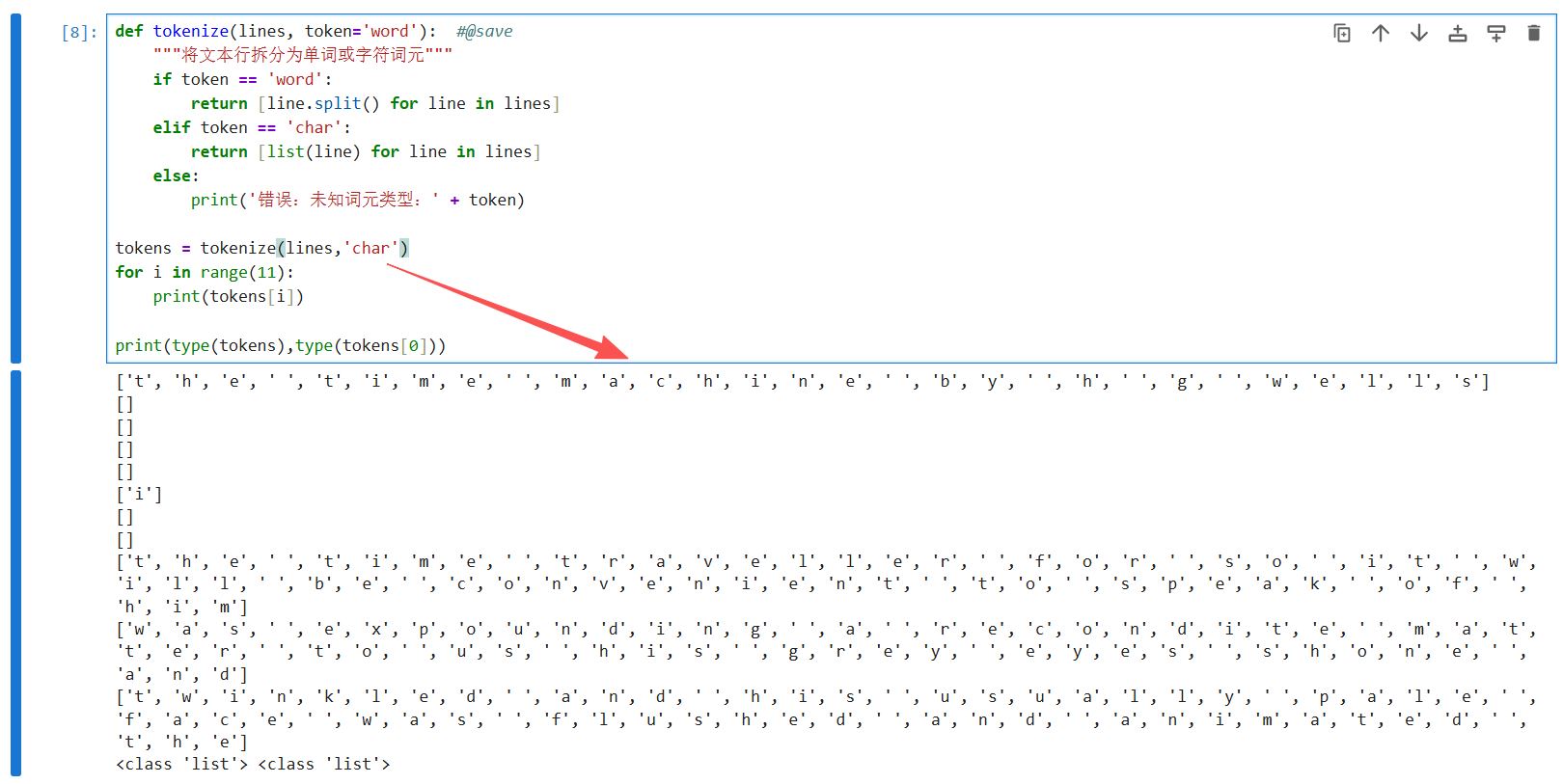
tokens = tokenize(lines)
for i in range(11):
print(tokens[i])
print(type(tokens)) # <class 'list'>
print(type(tokens[0])) # <class 'list'> (因为 tokens[0] 也是一个列表)
print(type(tokens[0][0])) # <class 'str'>最终 tokens是一个二维列表:外层是行索引,内层是该行的词元列表(单词或字符)
word和 char的主要区别在于词元化的粒度不同:
token='word':使用 line.split(),将每行文本按空白字符(空格、制表符等) 分割成一个个单词(词元)。
因为前面已经用 re.sub('\^A-Za-z+', ' ', line)把所有非字母字符替换成了空格,所以此时每行只有连续的英文字母和空格,split()会返回一个由单词组成的列表。
例如:"the time machine"→ 'the', 'time', 'machine'
token='char':使用 list(line),直接将字符串转换为字符列表,每个字符(包括空格)都是一个独立的词元。
例如:"the time"→ 't','h','e',' ','t','i','m','e'
-
单词级词元化常用于大多数自然语言处理任务(如文本分类、翻译)。
-
字符级词元化用于处理拼写错误、罕见词或某些序列建模场景(如字符级 RNN)。
两种处理方式区别:
line = "the time machine by h g wells"
words = line.split()
print(words) # 'the', 'time', 'machine', 'by', 'h', 'g', 'wells'
-
它自动识别连续的空格,并忽略开头和结尾的空格。
-
每个单词成为一个独立的字符串元素。
list()是一个内置函数,可以将任何可迭代对象(如字符串、元组、集合等)转换为一个列表。当参数是字符串时,它会将字符串中的每个字符(包括空格、标点)作为列表的一个元素。
line = "the time machine by h g wells"
chars = list(line)
print(chars)
输出:'t', 'h', 'e', ' ', 't', 'i', 'm', 'e', ' ', 'm', 'a', 'c', 'h', 'i', 'n', 'e', ' ', 'b', 'y', ' ', 'h', ' ', 'g', ' ', 'w', 'e', 'l', 'l', 's'
在列表推导式中 :[list(line) for line in lines]是一种简写形式,等价于:
result = []
for line in lines:
result.append(list(line))- 它遍历
lines中的每一行,对每一行执行list(line),然后把结果收集到一个新列表result中。
2. range(11)是什么意思?
range(11)生成整数序列:0, 1, 2, ..., 10,共 11 个数。
所以 for i in range(11)会执行 11 次循环,依次打印 tokens[0], tokens[1], ..., tokens[10]。
词表:
构建一个字典,通常也叫做词表(vocabulary), 用来将字符串类型的词元映射到从开始的数字索引中 ]。 我们先将训练集中的所有文档合并在一起,对它们的唯一词元进行统计, 得到的统计结果称之为语料(corpus)。 然后根据每个唯一词元的出现频率,为其分配一个数字索引。 很少出现的词元通常被移除,这可以降低复杂性。
另外,语料库中不存在或已删除 的任何词元都将映射到一个特定的未知词元**"<unk>"** 。 我们可以选择增加一个列表,用于保存那些被保留的词元, 例如:填充词元("<pad>"); 序列开始词元("<bos>"); 序列结束词元("<eos>")。
python
import collections
def count_corpus(tokens): #@save
"""统计词元的频率"""
# 如果tokens是空列表或者第一个元素是列表(即二维列表),则需要展平
if len(tokens) == 0 or isinstance(tokens[0], list):
# 使用双重循环列表推导式将二维列表展平为一维列表
# 外层for line in tokens遍历每一行,内层for token in line遍历行内每个词元
tokens = [token for line in tokens for token in line]
# collections.Counter返回一个字典,键为词元,值为出现次数
return collections.Counter(tokens)
class Vocab: #@save
"""文本词表"""
def __init__(self, tokens=None, min_freq=0, reserved_tokens=None):
#min_freq的意思是 "最小词频阈值"(Minimum Frequency)。设置它的主要目的是为了过滤掉罕见词(生僻字/词)。
# 如果未提供tokens,初始化为空列表
if tokens is None:
tokens = []
# 如果未提供reserved_tokens,初始化为空列表
if reserved_tokens is None:
reserved_tokens = []
# 统计词频并排序(按频率降序)
counter = count_corpus(tokens)
# counter.items()返回(key, value)对,sorted按value(频率)降序排列
self._token_freqs = sorted(counter.items(), key=lambda x: x[1], reverse=True)
# 初始化索引到词元的列表:索引0固定为<unk>(未知词元),然后追加预留词元
self.idx_to_token = ['<unk>'] + reserved_tokens
# 根据idx_to_token建立词元到索引的映射字典
self.token_to_idx = {token: idx for idx, token in enumerate(self.idx_to_token)}
# 遍历排序后的词频列表(已按频率从高到低)
for token, freq in self._token_freqs:
# 如果当前词元频率小于min_freq,由于列表已排序,后续频率只会更低,直接跳出
if freq < min_freq:
break
# 如果该词元还未添加到词表中(即不在token_to_idx中)
if token not in self.token_to_idx:
# 将词元追加到idx_to_token末尾,索引为当前列表长度减1
self.idx_to_token.append(token)
self.token_to_idx[token] = len(self.idx_to_token) - 1
def __len__(self):
"""返回词表大小(词元总数)"""
return len(self.idx_to_token)
def __getitem__(self, tokens):
"""将词元(或词元列表)转换为索引"""
# 如果输入不是列表或元组(即单个词元)
if not isinstance(tokens, (list, tuple)):
# 尝试在token_to_idx中查找,找不到则返回self.unk(即0,对应<unk>)
return self.token_to_idx.get(tokens, self.unk)
# 如果输入是列表或元组,递归地对每个元素调用__getitem__,返回索引列表
return [self.__getitem__(token) for token in tokens]
def to_tokens(self, indices):
"""将索引(或索引列表)转换为词元"""
# 如果输入不是列表或元组(即单个索引)
if not isinstance(indices, (list, tuple)):
# 直接从idx_to_token中取对应位置的词元
return self.idx_to_token[indices]
# 如果输入是列表或元组,返回词元列表
return [self.idx_to_token[index] for index in indices]
@property
def unk(self):
"""未知词元的索引固定为0"""
return 0
@property
def token_freqs(self):
"""返回词频列表(按频率降序排列)"""
return self._token_freqs索引建立的核心机制
Vocab类使用两个数据结构协同工作:
-
列表
self.idx_to_token:存储所有词元,列表的下标就是该词元的索引。 -
字典
self.token_to_idx:存储每个词元对应的索引,用于快速查找。
索引的分配过程完全由这两个结构的同步更新来保证唯一性。
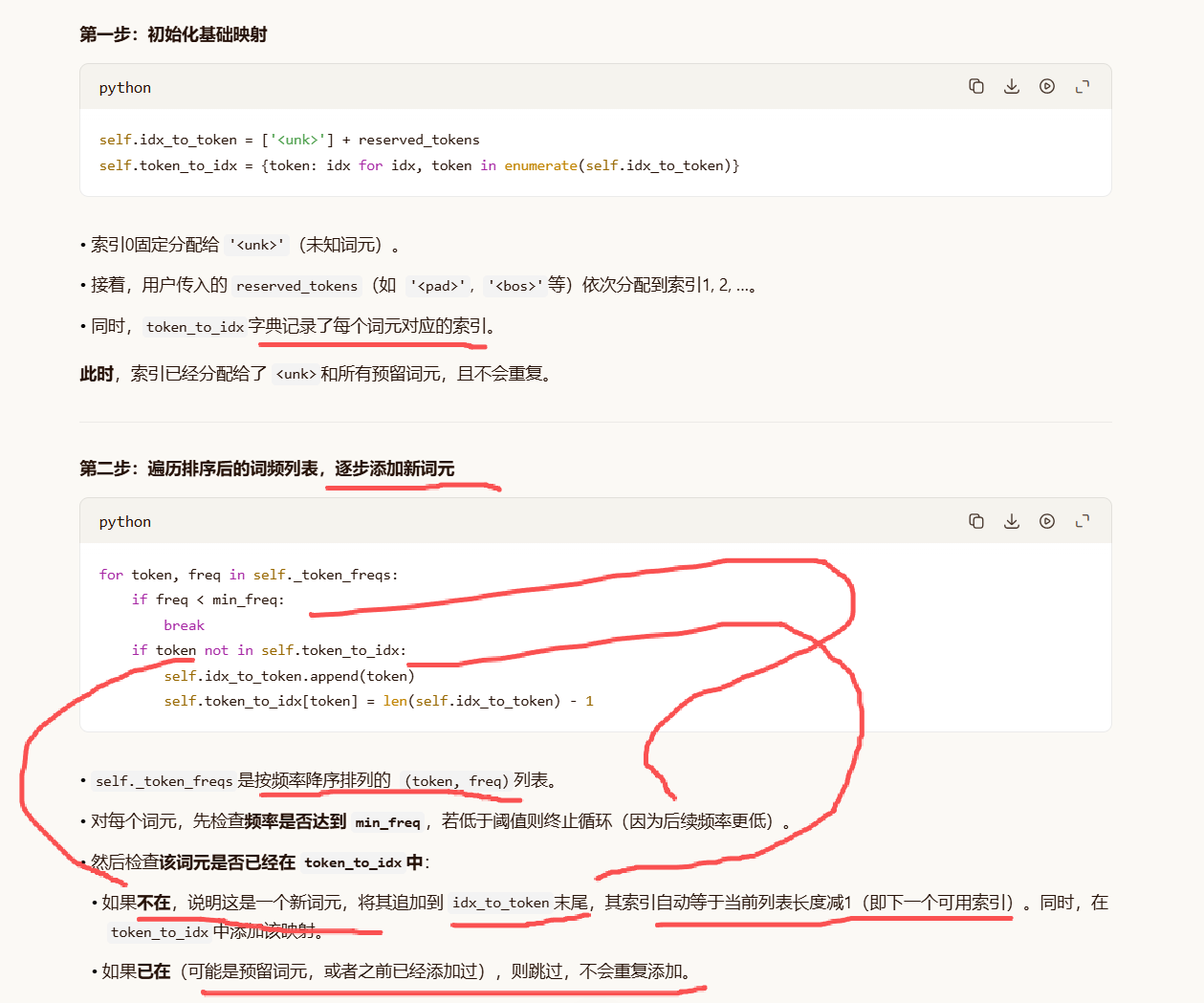
预留词元已预先占用索引 :在遍历词频列表之前,<unk>和预留词元已经占据了索引0,1,...,后续添加的新词元从下一个空闲索引开始,不会覆盖它们。

当多个词元出现频率相同时,它们的索引分配顺序取决于 sorted函数的稳定性 和 Counter的迭代顺序。
关键点
-
sorted是稳定排序在 Python 中,
sorted采用稳定排序算法(Timsort),这意味着当比较键(此处为频率)相等时,元素的相对顺序保持不变。也就是说,如果两个词元频率相同,它们在
counter.items()中的原始出现顺序决定了谁先谁后。 -
Counter的顺序Python 3.7+ 中字典(包括
Counter)保持插入顺序。count_corpus函数中,Counter(tokens)会按照词元第一次出现的时间顺序记录。因此,频率相同的词元会按照它们在原始语料中首次出现的先后顺序进入排序后的列表。
python
def load_corpus_time_machine(max_tokens=-1): #@save
"""
返回时光机器数据集的词元索引列表和词表
参数:
max_tokens (int): 最大词元数量,-1表示使用全部
返回:
corpus (list): 一维整数列表,每个元素是字符对应的索引
vocab (Vocab): 词表对象,包含字符到索引的映射
"""
# 1. 读取原始文本行(已预处理为小写、去除非字母字符)
lines = read_time_machine()
# 2. 将文本行按字符级别分词,得到二维列表 tokens
# tokens[i] 是第 i 行的字符列表,如 ['t','h','e',' ','t','i','m','e',...]
tokens = tokenize(lines, 'char')
# 3. 基于所有字符构建词表 Vocab
# 自动统计每个字符的频率,分配索引(0为<unk>,其余按频率降序)
vocab = Vocab(tokens)
# 4. 将二维 tokens 展平为一维 corpus,并将每个字符转换为索引
# 双重循环:外层遍历每一行,内层遍历行内的每个字符
# vocab[token] 调用 __getitem__ 返回字符对应的索引
corpus = [vocab[token] for line in tokens for token in line]
# 5. 如果指定了 max_tokens(正数),截取前 max_tokens 个词元
if max_tokens > 0:
corpus = corpus[:max_tokens]
# 6. 返回词元索引列表和词表对象
return corpus, vocab
# 调用函数,使用全部数据(max_tokens=-1 默认)
corpus, vocab = load_corpus_time_machine()
# 打印结果:
# len(corpus):总字符数(展平后的长度)
# len(vocab):词表大小(包含<unk>在内的不同字符种类数)
print(len(corpus), len(vocab))
(170580, 28)
len(corpus) = 170580:整个《时间机器》文本的总字符数(包括空格)。
len(vocab) = 28:词表中不同的字符种类数(26个小写字母 + 空格 + <unk>)。corpus是一个一维整数列表,例如 12, 15, 18, ...,每个数字对应一个字符的索引。
vocab是 Vocab类的实例,可以通过 vocab.token_to_idx查看字符到索引的映射,通过 vocab.idx_to_token查看索引到字符的映射。
len(corpus)是整个《时光机器》文本去掉非字母字符后的总字符数。
len(vocab)是词表大小,通常包括 <unk>、空格和所有出现过的字母(a-z)等。