嗯,我承认这个标题有点夸张了。当你把不用 AI 写代码的人排除掉之后,确实有可能出现一种情况:Token 使用量更少的人,反而生产效率更高。我讲一个故事,你们可能就开始有点理解了。
一个真实的故事
在软件发展的早期,也就是 60 年代到 80 年代,曾经流行过一个公式:LOC,全称 Lines of Code per Man-Month。
text
Productivity = LOC / MM简单来说,就是按程序员写出的代码行数来衡量工作效率。今天听起来很荒谬,但在那个时代,这确实是一种被广泛使用的指标。然后它引发了一些很有趣的现象。比如程序员宁愿自己手搓代码,也不愿意导入公共库,因为导入库不会增加代码行数。
Bill Gates 曾经说过一句很经典的话(他真的说过):
text
用代码行数衡量软件开发进度,就像用飞机重量衡量造飞机进度一样。如果把 LOC 换算成 TOC(Tokens of Code),放到今天,其实就是用 Token 消耗量来衡量一个人的工作效率。
上下文的困境
看到这里,你可能会觉得:"嗯,这个类比我也能想到。但用了 Token 说明用了 AI,而 AI 确实比人写代码快啊。"真的吗?接下来我要说的是一些很多老板并不知道的事情。首先,我们现在说的 AI 并不是真的 AGI,而是 LLM。很多人天天在用 LLM,但其实并不理解它的工作原理。
你有没有对 LLM 的"记忆能力"感到困惑过?为什么我用一个 Chat App 和 LLM 聊天,它会记住我?为什么我在一个聊天窗口里说过的事情,换一个聊天窗口它就不记得了?LLM 究竟怎么判断要记住多少事情?LLM 真的有记忆吗?
上下文困境
LLM 记忆原理
这件事情的原理其实非常简单。一个纯 LLM 模型是完全没有记忆的。对它来说,每一次请求都是全新的开始。那为什么我们用 Chat App 的时候,它看起来又认识我们呢?因为 Chat App 自己把你和模型之间的对话保存了下来,然后在每次提问时重新拼接进 Prompt 里。换句话说,它手搓了一个记忆系统。
哪怕你只是对 AI 说一句简单的"你好",在 App 内部实际上也可能会被拼接成这样:
"你是一个名叫 XX 的 AI 助手。用户的名字叫 XXXXX。他喜欢 blah blah blah。你现在根据他说的信息进行回复。以下是用户输入:你好。"
所以模型知道你是谁,也知道你的偏好。没有魔法,就是这么简单。
Session 记忆
那为什么我们在一个 Chat 里聊过的事情,换一个 Chat 模型就不记得了呢?在 LLM 应用领域里,Chat 更专业的叫法其实是 Session。因为记忆系统通常分成两个层级:
- App 级别记忆
- Session 级别记忆
Session 级别记录的内容更细,但它并不是全局共享的。听到这里,你可能会想:"那为什么不把所有事情都记住呢?"答案很简单,因为 LLM 可以接受的上下文长度是有限的。如果你尝试让它记住所有事情,那么上下文很快就会爆掉。所以 Session 的存在是必要的。
但新的问题又来了。即便分了 Session,当一个 Session 持续很长时间后,上下文依然会变得越来越长。那该怎么办?
上下文压缩
于是人们想出了一个办法:压缩上下文。这个过程其实非常朴素,就是把大量历史内容总结成几句摘要。毕竟大部分记忆并没有那么重要。
这件事情放在聊天记录上通常没有什么问题,但放到写代码场景里问题就比较大了。你可能曾经明确告诉模型"不要这样做",结果很多轮对话之后,它突然又开始干同样的蠢事。原因往往不是模型故意犯傻,而是你触发了上下文压缩,那些它认为不重要的细节,被压缩过程丢掉了。
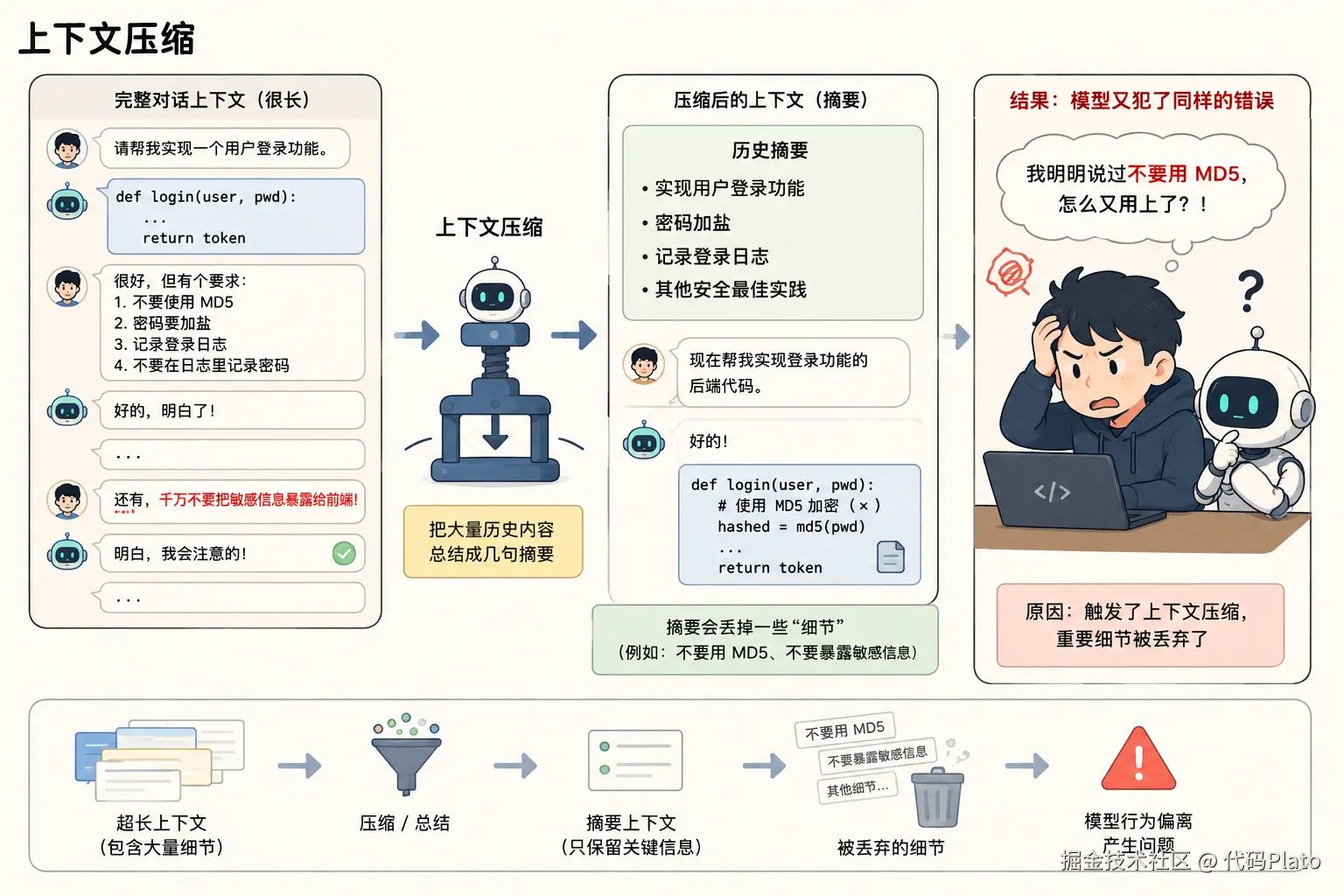
注意力稀释
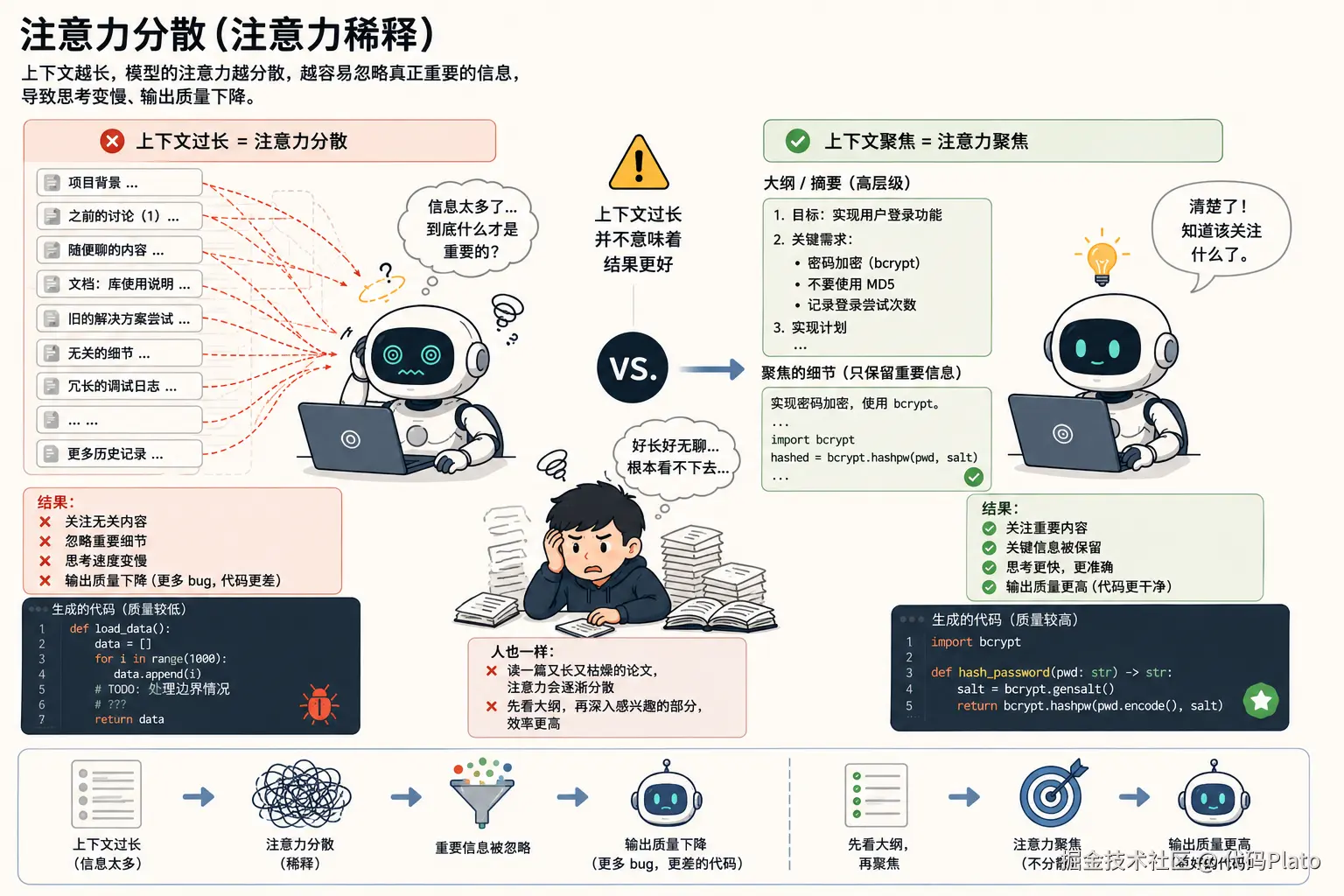
当上下文过长的时候,问题还不仅仅是达到上限,更大的问题是注意力稀释。上下文越长,模型需要关注的信息就越多,于是它可能开始关注一些无关紧要的内容,同时忽略真正重要的信息。
这其实和人很像。如果你在阅读一篇又长又枯燥的论文,你的注意力往往会逐渐分散,到最后甚至不知道论文到底在讲什么。很多时候,还不如先看一份大纲,再针对自己感兴趣的部分深入阅读。模型也存在类似的问题,这就是所谓的 Attention Dilution(注意力稀释)。因此,一个超长上下文并不会让模型工作得更好,很多时候,它反而会产出质量更差的代码。
Tokenmaxxing 排行榜的问题
我用的是 Claude 的包月套餐。有一次我让模型总结 10 个并不算长的 Markdown 文档,结果居然遇到了"达到 1M 上下文上限"的错误。系统提示我必须购买 API Token,才能继续使用超过 1M 的上下文。我当时非常震惊,因为那 10 个文档按字数加起来,肯定远远不到 1M。天知道 Claude 客户端到底给我塞了多少前置上下文。
怎样拿到排行榜的高名次
回到文章主题。当一个人想冲 Tokenmaxxing 排行榜的时候,他会怎么做?其实很简单:不停加载大文档,或者不断提出特别宽泛的问题。这样模型的上下文一定会疯狂增长,上下文增长之后,Token 消耗自然也会跟着暴涨。
但最大的问题其实并不是 Token 费用。当上下文越来越长时:
- 模型思考速度会明显下降;
- 注意力分散导致代码质量下降;
- 上下文压缩导致最佳实践逐渐丢失;
- 模型开始重复犯同样的错误。
代码质量下降之后,Bug 数量增加;Bug 增加之后,又要消耗更多 Token 去修复。于是形成一个对员工有利、对公司有害的循环:
上下文越来越长 → Token 越来越多 → 代码越来越差 → Bug 越来越多 → Token 消耗继续增加。
怎样拿到排行榜的低名次
我现在几乎 100% 的代码都是 Claude Code 生成的。但这并不意味着:
- 我写代码特别快;
- 我不知道 Claude Code 在写什么。
恰恰相反,和很多 AI 编程用户相比,我的速度甚至算比较慢的。
我曾经把一个使用 Streamlit 作为前端的 Python 项目,重构成了"Python 后端 + React 前端"的架构。如果让 Claude Code 一次性完成,大概十几分钟就能跑出来,但我花了三天。
原因有两个。第一,其中很多技术我自己也不熟悉。有了 Claude Code 之后,我敢使用以前没有接触过的技术栈,而不用担心项目彻底失控或者时间线无限拉长。我可以一边开发,一边学习。第二,我把任务拆得非常细。我会逐行阅读它生成的代码,不断重构,不断调整规则,再让 Claude Code 记住这些新的最佳实践。除此之外,我还使用了很多别的方法。这些方法太多了,不可能在一篇文章里全部讲完,我会在后续文章里慢慢展开。
最终,我写出了一个代码相当简洁、相当优雅的项目。虽然用了三天时间,但我有信心它在未来很长一段时间里的 Bug 数量都会比较低。更重要的是,如果没有模型帮忙,其中很多技术我根本不会,我可能需要一个月才能完成。从一个月缩短到三天,我已经非常满意了。
随着我使用 Claude Code 经验的积累,我从最开始每周都把 Weekly Usage 用满,到现在一周只使用大约 25%。我敢说,我做出来的东西,可能超过很多人花 1000 美元 API 费用才能做出来的成果。这还没有计算未来因为 Bug 减少而节省下来的维护成本。
那么如果放到 Tokenmaxxing 排行榜里,我能排第几名呢?我猜大概是倒数吧。
结论
当然,这并不能说明排行榜前几名的人一定是在投机。但它至少说明了一件事:Token 使用量并不能衡量生产效率,甚至有可能损害公司的工程文化。
更长的上下文会让模型思考得更久,有时候甚至长达几十分钟。我还听说过一些案例,一个问题能让模型连续工作几个小时。而在如此低效率的情况下,它最终产出的代码质量却未必更高。
你以为自己节省了时间,实际上只是把维护成本预支到了未来。在你发现这些问题之前,它已经开始损害你的产品质量,损害用户对产品的信任。和这些长期成本相比,浪费掉的 Token 钱反而是最不严重的问题。