本文首发于 sg.yaoyuheng2001.me,转载请注明出处。
上一篇 eval 钉死了差距:固定模型、只变 harness,我的自建 agent 兑现了 Claude.ai 的 37% / 80% ≈ 46% ,而搜索精度一个人就占了将近一半的失败题。这篇兑现那个"P0 跑完之后"的 flag。
Part 1 · 教程:Claude.ai 搜索的 5 个工程优化
先说结论:Claude.ai 的搜索不是某个魔法引擎 ------它后端其实就是 Brave Search,第三方分析发现 Claude 的引用与 Brave 顶部结果重叠约 86.7%。它的"又快又准",是 5 个可拆解、可复刻的工程优化叠出来的。
先确立一个前提,后面每条都建立在它之上:claude.ai 用的是 Anthropic 的 server-side
web_search工具。调用方只声明 它,其余都在服务端:模型自行决定搜不搜、搜几次,整个多轮检索循环在 Anthropic 服务端、一次 HTTP 请求之内完成,结果加密内联回灌给模型,调用方无需 像普通 client tool 那样回tool_result。这个 "server tool" 的身份解释了下面几乎每一条优化,也是它与"自己用 client tool 搭 harness"的根本区别------后者必须把这个循环跨多次请求自行重建(Part 2 的主题)。
两种调用形态:同一个搜索,代码差一整个循环
ini
# A. server tool ------ 一次调用,多轮检索在服务端跑完
resp = client.messages.create(
model="claude-opus-4-...",
messages=[{"role":"user","content": q}],
tools=[{"type":"web_search_20250305","name":"web_search","max_uses":5}],
)
# resp 里已经是带引用的最终答案。你不写循环、不回 tool_result。
# (仅当 stop_reason=="pause_turn" 才把 content 原样回传、续一次)
python
# B. client tool ------ 循环和检索全得你自己写
messages = [{"role":"user","content": q}]
while True:
resp = client.messages.create(model=..., messages=messages, tools=[WEB_SEARCH])
messages.append({"role":"assistant","content": resp.content})
if resp.stop_reason != "tool_use":
break # 收敛,结束
results = []
for b in resp.content:
if b.type=="tool_use" and b.name=="web_search":
hits = do_search(b.input["query"]) # ← 你的搜索 API + 抓取 + 抽取
results.append({"type":"tool_result","tool_use_id":b.id,"content": hits})
messages.append({"role":"user","content": results}) # ← 回灌,再来一轮差别一眼可见:A 里没有循环 ------搜几次、怎么 refine、何时停,全在 Anthropic 服务端;B 里那个 while 循环、每轮的搜索执行、tool_result 回灌,全是你的代码。所以 server tool 自带的"内联内容、服务端循环、不限轮迭代",到了 client 侧都得一件件自己挣出来------这正是 Part 2 的工作。下图把这条结构差异并排画出来:
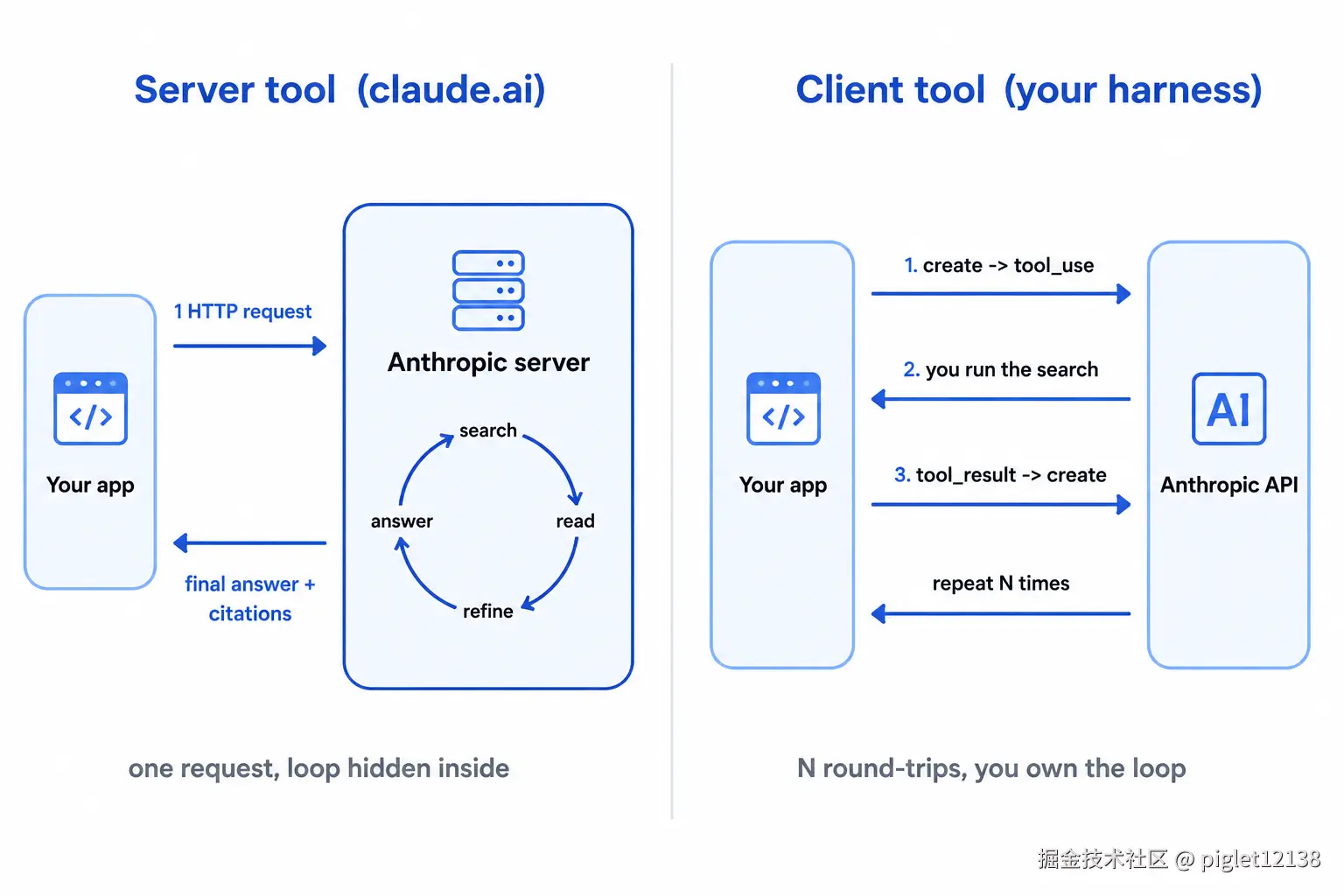 左:server tool,一次请求、循环藏在服务端;右:client tool,N 次往返、循环由你自己持有
左:server tool,一次请求、循环藏在服务端;右:client tool,N 次往返、循环由你自己持有
1. 内容随结果"内联"返回------不再单独抓页
原理:调一次 web_search,每条结果里已经附带了约 500 词、按查询挑选的正文片段。一次搜索就同时拿到了相关正文,无需再抓页、也无需再调一个模型去抽取。
这 500 词从哪来?答案落在"它后端是 Brave"这件事上。Brave Search API 本身就做索引侧的段落选择 :每条结果除主摘要 description,还会返回 最多 5 条 extra_snippets------按查询实时挑出的相关摘录。实测一条结果的 description(~250 字符) + 4--5 条 extra_snippets(~1300 字符) 正好凑到 ~500 词。证据是:同一个 URL、换一个查询,返回的片段就不同 ------这正是搜索索引做 snippet 的本质(索引里存着全文,每次按关键词邻近度抽取当前查询相关的片段)。所以"内联内容"不是整页、也不靠额外的抽取模型,就是 Brave 索引选好的若干片段,Anthropic 透传过来而已。
示例:一次带搜索工具的请求
bash
POST /v1/messages
{
"model": "claude-opus-4-...",
"tools": [{ "type": "web_search_20250305",
"name": "web_search", "max_uses": 5 }],
"messages": [{ "role": "user", "content": "苏格兰 2021 高地群岛 保守党得票" }]
}返回的 content\[\] 是一串有序的 block(都在同一个 assistant turn 里)
json
[
{ "type": "text", "text": "我来查一下......" }, // ① 宣告要搜
{ "type": "server_tool_use", // ② 实际查询(server tool)
"id": "srvtoolu_01WYG...", // 注意 srvtoolu_ 前缀
"name": "web_search", "input": { "query": "..." } },
{ "type": "web_search_tool_result", // ③ 结果,紧跟在②后面
"tool_use_id": "srvtoolu_01WYG...",
"content": [{ "type": "web_search_result",
"url": "https://en.wikipedia.org/...",
"title": "2021 Scottish Parliament election",
"encrypted_content": "EqgfCiB...", // ↓ ~500词正文,索引侧已选段
"page_age": "..." }] },
{ "type": "text", "text": "保守党在...", // ④ 带引用的最终答
"citations": [{ "type": "web_search_result_location",
"url": "...", "cited_text": "...(≤150字符)...",
"encrypted_index": "Eo8BC... " }] }
]这串 block 里有两点对自建 harness 很关键。第一,它是 server_tool_use(srvtoolu_ 前缀),不是普通 client tool,结果由服务端回灌,你不必回 tool_result。第二,encrypted_content(在结果里)和 encrypted_index(在引用里)用于 Anthropic 跨轮管理上下文与引用;多轮对话里要把整个 assistant turn 原样塞回 messages,不能抽出纯文本再拼回去,否则后续轮次的引用会断。
有一点容易误会:encrypted_content 对开发者是黑盒,对 Claude 不是。按社区逆向,调用方没有公钥、没有客户端解密,只能把它原样回传,无从查看内容;而抓取、加密、解密都在 Anthropic 服务端完成,模型照常用里面的正文作答、生成引用(官方文档也是这么描述的)。加密更多是出于商业与合规考虑:避免把 Claude API 当作免费爬虫,并尊重内容方"只用于 AI 上下文、不原样转发"的授权。所以在 claude.ai 这类全程服务端的产品里,搜索这一步就把相关片段一并交给了模型。
插曲:同一个引擎,Claude Code 走了相反的路
同样是 Anthropic、同样的 Brave 后端,命令行里的 Claude Code 却把内联片段丢掉了。对 Claude Code 网页工具的逆向显示,它拆成了两个工具、两条管线。
Claude Code 的 WebSearch:只留标题和链接,正文被丢弃
json
// 同样的 web_search_result,但 Claude Code 只取这两个字段:
{ "title": "2021 Scottish Parliament election",
"url": "https://en.wikipedia.org/wiki/..." }
// page_age、encrypted_content(那 500 词正文)------ 直接扔掉想要正文,得显式再调一次 WebFetch(自己重抓 + 自己提炼)
scss
WebFetch(url, prompt)
→ 抓 HTML → Turndown 转 Markdown → 截到 ~100KB
→ 用一个小模型(Haiku)按 prompt 把这页"读"成一段答案
→ 返回的是这段答案,不是原始网页为什么放着现成的 500 词内联片段不用、偏要重抓一遍?逆向作者给的解读是:这是一次刻意的工程取舍 ------CLI 里 agent 要长时间自主跑,把"搜索"和"读取"拆开能缩小注入面 (搜索结果只剩标题链接,不会把一大段不可信网页正文直接灌进主上下文)、更省版权风险 (默认不大段复述原文)、也让每一步的成本和行为更可预测。代价是慢、是多一跳------但 CLI 场景换来的是可控。
同一个引擎、两套内容管线,正好框住了一个工程取舍:*把正文随搜索内联端上来(claude.ai,快),还是搜完再选择性重抓(Claude Code,稳)。*两条路各有代价,也各有适用场景------Part 2 会看到,自建 harness 若不小心,容易落进两者里最差的组合:既要单独重抓(慢),又把不可信正文整段塞进上下文(脏)。
2. 整个检索循环在服务端、一次请求内跑完
**原理:**这是 "server tool" 身份最值钱的地方。你一次请求发出去,多轮检索的 agentic loop 全在服务端跑 :Claude 判断要搜 → 生成 query → Anthropic 执行 Brave → 结果回灌 → 还不够就拿上一轮结果 refine 下一轮、再搜 → 直到信息够了或撞 max_uses → 吐出带引用的答案。**这中间没有一次回到你这儿。**你通常一个 HTTP 请求就拿到完整答案。
ini
你的一次请求
└─[服务端] 搜 → 读 → refine → 再搜 → ... → 带引用作答 // 多轮全在里面
stop_reason = "end_turn" // 正常:一次拿全
stop_reason = "pause_turn" // 仅当这轮太长被切断 → 原样回传接力client tool 复刻不了这条。用 client tool 时,模型每决定搜一次,就要把 tool_use 流回客户端、客户端执行搜索、再开 一次新的 /v1/messages 请求 把结果送回去------服务端一个请求内做完的 7--11 次搜索,在客户端是 7--11 个公网往返 + 每轮重新 prefill。这是结构性差异:官方把整个循环关在服务端,客户端只能把它摊开成多次请求。这也正是为什么下面 #4 的缓存对自建 harness 是关键、对 server tool 却无关紧要。
3. "代码过滤"而不是"再叫一个模型"
原理:结果太多时,它的动态过滤 是让模型写一段代码、在沙箱里跑一遍 来筛/排/抽,只把代码输出送进上下文。确定性、token 便宜,零额外模型往返 。这其实对应工具的两个版本:基础版 web_search_20250305 没有动态过滤;新版 web_search_20260209 才有,而它内部依赖 code execution 来跑这段过滤逻辑(代价:默认不符合 ZDR 零数据保留,要 ZDR 得退回基础版)。
示例:开启代码执行后,模型自己写过滤代码
ini
# Claude 在 code_execution 工具里生成并运行:
results = load_search_results()
hits = [r for r in results
if "Highlands and Islands" in r["text"]
and any(y in r["text"] for y in ("2021","2016"))]
print(hits[:3]) # 只有这几条进上下文这套"让模型写代码来编排/过滤工具结果",Anthropic 官方叫 programmatic tool calling。它和"再叫一个 LLM 去读去筛"是两个量级:后者是一次完整推理往返(几百 ms~数秒),前者只是跑一段确定性脚本(毫秒级)。这条区别在 Part 2 会反复出现------用模型做本该用代码做的过滤,是最常见的延迟来源之一。
4. Prompt Caching:缓存稳定前缀,长 prompt 延迟最高降 85%
官方数据是延迟最高降 85%、成本降 90% ,一个 10 万 token 的例子从 11.5s 降到 2.4s 。但"缓存"究竟缓存了什么、cache_control 又在标什么,值得从底层讲清楚------它直接决定了多轮 agent 的成本与延迟。
第一步:为什么 prompt 能被缓存------KV cache
Transformer 读每个 token 时,注意力层会为它算三个向量:Query(我在找什么)、Key(我含什么)、Value(我携带什么信息)。关键性质是因果性 :某个位置的 Key/Value 只依赖它前面的 token ,一旦算出来就永远不变 。所以这些 K/V 张量完全可以存下来复用,而且不影响输出质量 (因为位置 i 的注意力本就只看 i 之前)。这堆存下来的 K/V,就是 KV cache。不缓存的话,每次请求都要把整段前缀的 K/V 从头算一遍------纯属浪费。
第二步:cache_control 在标什么
原生 KV cache 只在一次 生成内复用。Prompt caching 把它跨请求复用 :把前缀的 K/V 张量留在推理服务器的显存里,用 token 序列的哈希 做索引。下次请求来,服务器哈希你的前缀、命中就直接取那批张量、跳过重算。而 cache_control: {type:"ephemeral"} 就是你打的一个**"断点标记"------告诉服务器"到这个 block 为止的前缀是稳定的,请缓存它"。Anthropic 要你显式**打这个断点(OpenAI 是自动的)。
scss
请求 = [ tools ][ system ][ 历史消息 ][ 这一轮新增 ]
└─── cache_control 缓存到这(稳定前缀) ───┘
// 第 1 轮:建缓存(cache_creation_input_tokens)
// 第 2+ 轮:前缀命中,直接读(cache_read_input_tokens,便宜 ~10×)
// ※ 历史若"只追加不改写",断点可往后滚,连历史也一起缓存示例:在 system 和最后一个 tool 上打断点
json
{
"system": [{ "type": "text", "text": "<长系统提示>",
"cache_control": { "type": "ephemeral" } }],
"tools": [ ...,
{ "name": "web_search", ...,
"cache_control": { "type": "ephemeral" } } ] // 缓存整个 tools 块
}关键纪律:命中按前缀哈希精确匹配,任何字节变动------空格、JSON key 顺序、工具定义------都会从变动处往后 整段 miss**。需要厘清的是:纪律不是"别缓存工具结果",而是 "别改写前缀"。历史只要 只追加、不回头改**,累计的搜索结果就能持续命中缓存(甚至可以把断点滚到最后一条消息,把整段历史也缓存住)。真正打碎缓存的是"每轮回头重写/压缩历史"------比如把工具结果有损拍平成摘要再塞回、或用 compaction 函数每轮重新截断旧消息,都会让前缀字节不断变化。"Don't Break the Cache"(arXiv 2601.06007) 量化了这点:边界控制得当能改善 TTFT 13--31%,乱缓存反而增延迟。
**为什么这对"搜索"尤其重要:**搜索结果正文一旦进了上下文,会在后续每一轮继续按 input token 计 (因为它还留在messages里)------这是长对话成本悄悄上涨的主因。所以"缓存累计的搜索历史"并非锦上添花:不缓存时,跑到第 12 轮,前 11 轮的搜索正文每一轮都在重新计费、重新 prefill;缓存住,它们近乎免费。能否负担多轮检索,往往就取决于此。
想深入:这套机制的学术脉络
这不是 Anthropic 独家黑科技,而是一条清晰的研究线:Prompt Cache(arXiv 2311.04934)最早提出"模块化注意力复用",把可复用的 prompt 片段预算好 K/V;SGLang 的 RadixAttention(arXiv 2312.07104)用一棵 radix 树自动发现并跨请求复用共享前缀(vLLM 的 PagedAttention 则在显存分块层面做这件事);到 KVFlow(arXiv 2507.07400),研究对象已经正是多 agent / agentic workflow 的前缀缓存 ------和我们这种"每轮重复 system+tools、反复多轮调工具"的场景严丝合缝。有句话很到位:"前缀缓存是这串优化里唯一一个'上下文越长越省'的。"
验证它是否生效也简单:看响应里的 cache_creation_input_tokens(写入缓存)与 cache_read_input_tokens(从缓存读),命中率 = read / (read + creation)。缓存生效时,靠后轮次的非缓存 input token 会从上千掉到个位数。另外存进显存的是张量、不是文本,所以原始 prompt 不会以文本形式留存。
5. 搜索后"选择性抓取",不是每次都抓一堆
原理: 官方建议 search → selective retrieve:简单事实题 1--3 次搜索即可,用 max_uses 给搜索次数兜底,避免一上来就 fetch 一大批、把上下文撑爆。注意它和优化 #1 是一对------因为内联片段已经够用,大多数时候根本不需要"深抓"那一步,深抓是例外不是默认。
示例:给搜索次数设上限
json
"tools": [{ "type": "web_search_20250305",
"name": "web_search",
"max_uses": 3 }] // 延迟敏感场景:3 次封顶把 Claude.ai 的搜索链复原
5 个优化拆完,现在把它们拼回去,看一次完整搜索的原貌------从你按下回车,到它给出带引用的答案,中间到底发生了什么:
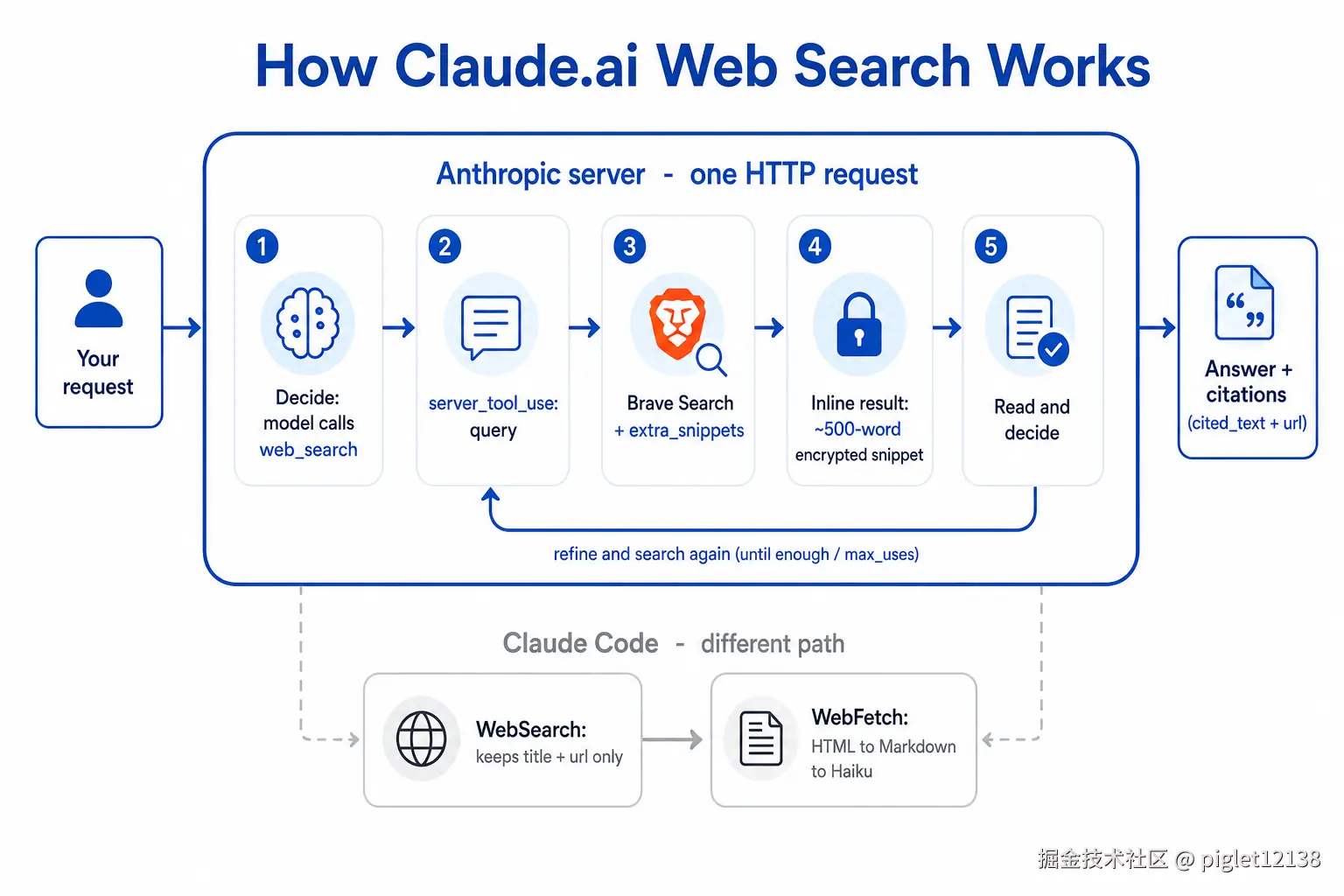 一次 Claude.ai 搜索:检索循环整个关在"服务端·一次请求"的方框内(含 refine 回环);下方灰色支线是 Claude Code 的另一套内容管线
一次 Claude.ai 搜索:检索循环整个关在"服务端·一次请求"的方框内(含 refine 回环);下方灰色支线是 Claude Code 的另一套内容管线
- 决策 :模型判断这题需要实时信息,自主生成一个
web_search工具调用(带 query)。 - 缓存命中 :请求的
tools + system前缀已缓存(优化 #4),这一步几乎不花 prefill 时间。 - 服务端搜索 :在 Anthropic 基础设施内打 Brave(优化 #2,无客户端往返);Brave 索引侧把每条结果的
description+extra_snippets(约 500 词相关片段)打包进encrypted_content、随结果内联返回(优化 #1)------搜索这一步就把"该读的段落"端上来了。 - 代码过滤(按需):结果多时,模型写一段代码把结果筛到几条,只把输出送进上下文(优化 #3,零额外模型往返)。
- 读 & 决定 :模型直接读内联正文;信息够就作答,不够才选择性
web_fetch深读某个 URL(优化 #5,深抓是例外不是默认)。 - 多轮迭代(全在服务端) :3--5 步是个循环------不够就拿上一轮结果 refine、再搜,整个 7--11 次的检索都在这一个请求内、服务端跑完 ,中间不回到客户端;正常以
end_turn收尾,只有这轮太长被切断才返回pause_turn让你原样回传接力。 - 带引用作答 :输出里每个来自网页的论断都挂
cited_text + url(不计入 token),可回溯。
同一条链,Claude Code 在第 3--5 步岔开:WebSearch 只取 title/url、把内联正文丢掉;要正文时显式 WebFetch(抓 HTML → Turndown → Haiku 提炼)。多一跳、更慢,换来更小的注入面和更可控的成本------这是 CLI 自主长跑的取舍。
**"又快又准"拆开就是:**快 = 不走 「搜索 → 抓取 → 再调模型抽取」这条慢路(内联 #1 + 代码过滤 #3 + 缓存 #4 让多轮变便宜);准 = 索引侧按查询选段 + 代码过滤 + 不限轮的选择性深抓(#1 #3 #5)。用 client tool 自建 harness,则要把上面这条服务端链路在客户端逐步重建------下面 Part 2 用延迟、token、逐题 pass/fail,逐个验证每一步到底值多少。
Part 2 · 实验报告:把检索管线重写到 Claude.ai 的形状
实验设置
**对象:**自建 harness(agent-research 的 runner,与生产 claude-ai-harness 同族)。
**控制变量:**模型固定(同一上游),只改检索/抓取/上下文管线。
**数据集:**GAIA + FRAMES 中 30 道"裸模型答不对"的题,全量跑。
判分:
contains------模型最终FINAL ANSWER是否包含标准答案(大小写不敏感)。**基线:**裸模型 0 / 30、原 harness(B)11 / 30(37%)、Claude.ai(C)24 / 30(80%)。
**成色声明:**上游(luckyapi)并非 vanilla Anthropic,temperature 0 也不完全复现,单跑是点估计、不是定论(这也是下面 frames_241 时好时坏的根因)。
过去的架构
原 harness 是最朴素的**「搜索 → 抓取 → 字符截断」三段式**,每一层都在丢信息:
- **检索:**主力 Serper,只拿 snippet------没有正文,必须再单独抓页。
- **抓取:**一次
web_search自动抓 top-3 页,且裸 fetch 不渲染 JS,常被反爬挡。 - **摄入:**抓到正文后按字符位置硬截断
slice(0, 6000)进上下文------query 无关,答案若在第 6000 字之后会被静默切掉(一个隐藏 bug)。 - **上下文:**仅在 >30k token 时用 Haiku 压缩历史(也 query 无关),每轮把历史重写一遍、打碎可缓存前缀。
- **循环:**上限 8 轮。
三个致命点:搜不到正文、抓取脆、答案被位置截断;多跳题往往撑不到收敛。
目前的架构
照着 Part 1 拆出的 5 条优化,把每一层都换成**「检索式、零额外生成、可缓存」**的形状:
| 层 | 过去 | 现在 |
|---|---|---|
| 检索 | Serper,只 snippet | Brave 主力 + extra_snippets(内联 ~500 词);9 级兜底链 |
| 抓取 | 每搜抓 top-3 | 内联优先:snippet 够富不抓;否则只选择性抓 top-1 |
| 抽取 | slice(6000) 位置截断 |
Exa /contents highlights(embedding 选段,逐字原文,无 LLM 往返) |
| 上下文 | 每轮重写历史摘要 | 只追加 + 给 system/tools 打 cache_control |
| 循环 | 8 轮 | 16 轮 + 多跳规划提示 + 网络重试 |
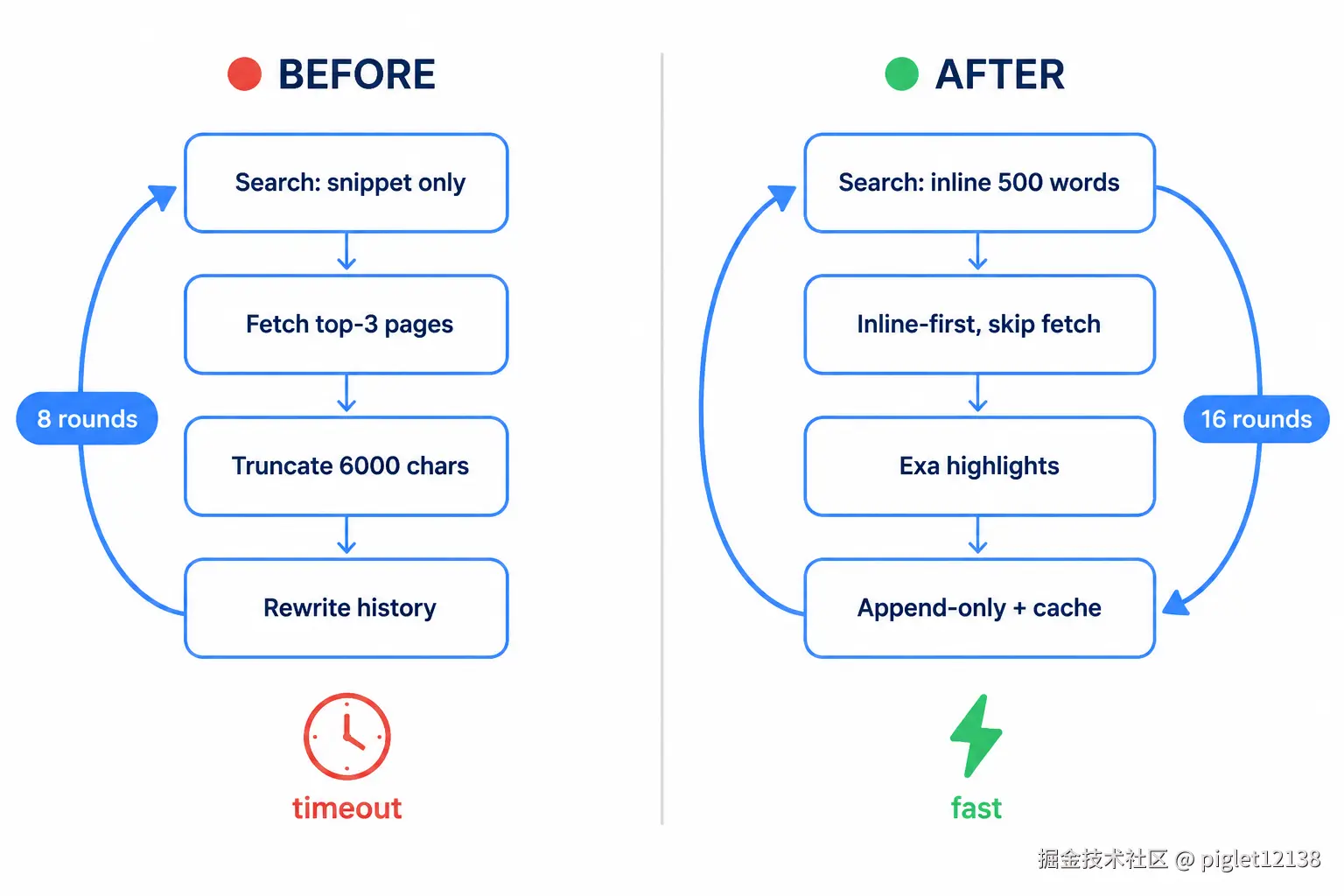 同一条检索管线逐层重写:左边每层丢信息、撑不到多轮就超时;右边内联优先 + 缓存,16 轮也跑得动
同一条检索管线逐层重写:左边每层丢信息、撑不到多轮就超时;右边内联优先 + 缓存,16 轮也跑得动
改进了哪些
压成四条真正改变行为的动作(其余调参省略):
- **内联优先(最大提速):**让相关正文随搜索结果一起回来,能不抓页就不抓------把每搜默认的"3 抓 + 3 次模型抽取"降到常见 0 次。
- **抽取用检索、不用生成:**把"读到正确那一段"交给 Exa highlights(语义选段),不再每抓一页调一次 Haiku。
- **缓存稳定前缀 + 历史只追加:**system+tools 缓存住、消息只追加,去掉每轮重写历史的 hack------多轮迭代不再每轮全量重算。
- **修掉位置截断 bug:**query 感知抽取替掉
slice(6000),"答案在第 6000 字后被切掉"的静默失败消失。
支撑第 2 条的受控测量(同 URL、同 query,唯一变量是 Exa
contents参数):summary:{query}在 Exa 侧跑生成式 LLM = 3284ms ;highlights:{query}是 embedding 选段、返回逐字原文 = 613ms(快 5.4×) 。教训:抽取要的是"检索式逐字摘录",不是再叫一个模型生成摘要------这正是 Claude.ai 内联片段的本质。Exa Search/Contents API
实验表现
全部改动叠满(temperature 0、16 轮),对 30 题全量跑一遍,对照基线:
| harness(模型固定不变) | 30 题通过 | 相对位置 |
|---|---|---|
| 裸模型(无工具) | 0 / 30 | 地板 |
| 原自建 harness(B) | 11 / 30 · 37% | 起点 |
| 本文重构后(v3) | 20 / 30 · 67% | +30 点 |
| Claude.ai(C) | 24 / 30 · 80% | 天花板 |
37% → 67%,把对 Claude.ai 的差距从 43 点压到 13 点、吃掉约 ⅔。
更关键的是用时------这是过去架构"准了却超时"的死穴。补上每组的时间 / 轮次 / 检索行为:
| 组 | 题数 | 均用时 | 中位用时 | 均轮数 | 均搜索 | 均抓取 | 纯 inline |
|---|---|---|---|---|---|---|---|
| PASS | 20 | 54s | 35s | 4.4 | 2.2 | 2.4 | 89% |
| FAIL | 10 | 93s | 40s | 8.0 | 3.4 | 3.9 | 65% |
PASS 题几搜即中(中位 35s、2.2 搜),又准又省;全 30 题平均 67s/题。FAIL 题反而搜得更多、跑得更久仍失败(均 3.4 搜 / 8 轮)------卡点不在"搜不到"。
把范围收紧到第一次实验(原 B harness,8 轮上限)就答对的 8 道题(v3 这 8 道也全 PASS),做纯用时对照:
| 任务 | 第一次(B) | 现在(v3) | 用时变化 |
|---|---|---|---|
| gaia_016 | 32s | 7s | 快 4.5× |
| gaia_150 | 37s | 22s | 更快 |
| gaia_096 | 37s | 35s | 持平 |
| gaia_052 | 56s | 57s | 持平 |
| gaia_136 | 16s | 25s | 略慢 |
| gaia_158 | 16s | 33s | 略慢 |
| gaia_059 | 12s | 31s | 略慢 |
| gaia_153 | 41s | 79s | 更慢 |
| 8 题汇总(都 PASS) | 均 31s · 中位 34.5s | 均 36s · 中位 32s | 同一量级 |
3 道更快、5 道略慢,均值 31s→36s、中位 34.5s→32s------基本同一量级 (均值被 gaia_153 一题拉高)。结论:重构在硬题上多拿的正确率,没有拖慢原本就能解的题。
分析改进来源
整体数会骗人------67% 也可能"碰巧"。把逐轮日志拆开,每条改动都在机制层面留下了可量化的证据。先看现在每一次搜索实际怎么走:
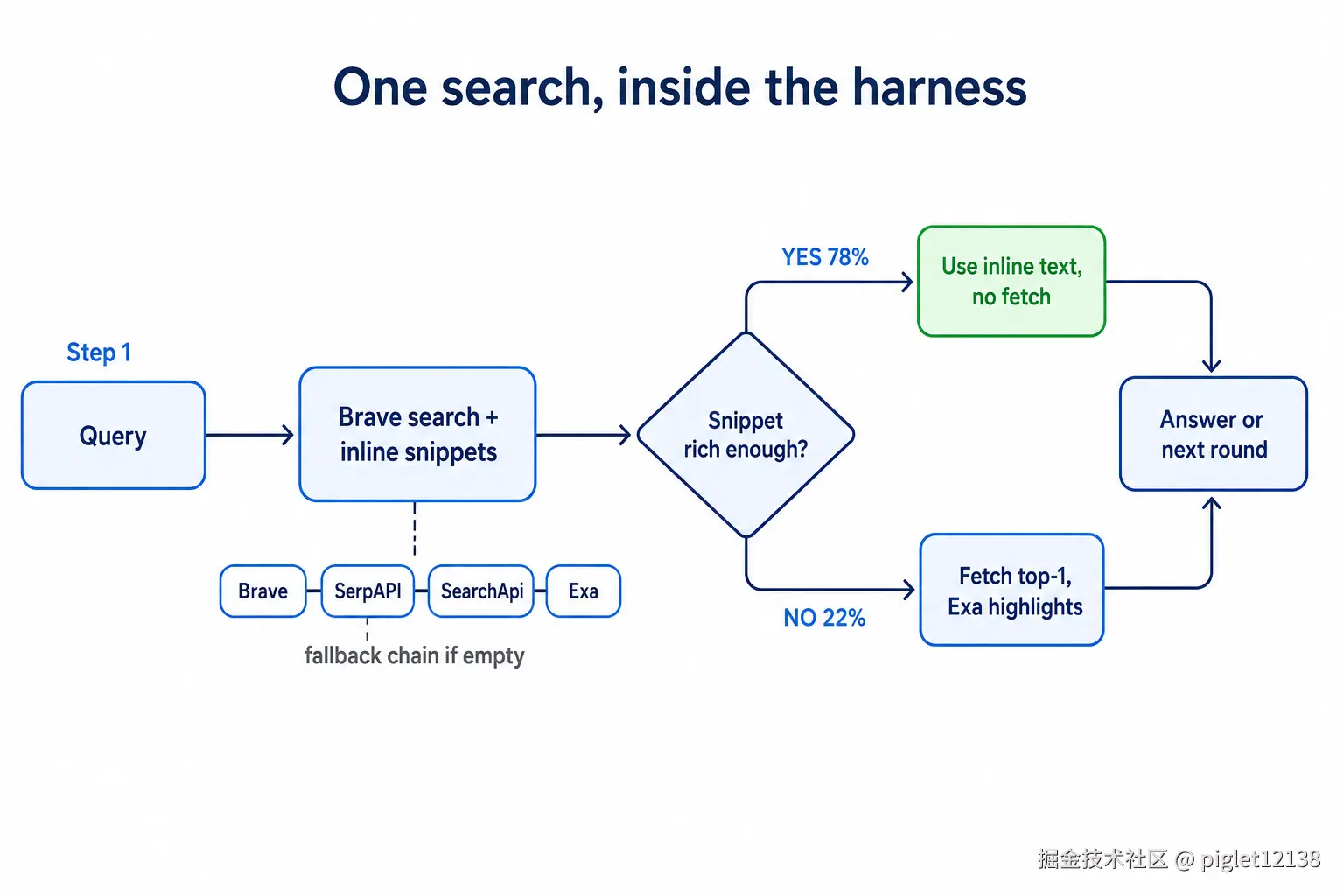
78% 的搜索靠内联片段直接答、零抓取;不够富才抓 top-1 + Exa 选段。兜底链只在 Brave 返空时接力
每条优化都在日志里留下指纹:
- **内联优先 → 速度:**78 次搜索里 61 次(78%)零抓取(PASS 题 89%)------这是用时从"超时"回到"几十秒"的主因。
- **兜底链 → 覆盖:**67 次纯 Brave、11 次落兜底、每次都恢复到 ≥3 结果(0 瘦果);1 次打满 4 层(Brave→SerpAPI→SearchApi→Exa),Exa 救回 9 条、直接换来 gaia_008 一道 PASS。
- **highlights → 又快又准:**87 次抓取 100% 由 Exa
/contents命中、零 LLM 往返,逐字保真。(鲁棒抓取链 Jina/Firecrawl 一次没触发:休眠保险,这轮没拿到它的鲁棒性证据。) - **缓存 → 撑住多轮:**靠后轮非缓存 input 掉到个位数 token(gaia_001 跑 11 轮,后段每轮 ~7--44 token)------多轮在算力上不再贵,这是能"跑完"而非超时的底座。
**一句话归因:**速度来自不走「搜 → 抓 → 生成式抽取」这条慢路 (内联 + highlights + 缓存);覆盖来自 Brave 内联片段 + 兜底链补稀缺结果。
剩下 10 道失败已基本不在搜索 / 抓取管线 ,拆成三类、只有一类是检索精度问题:① 判断墙 (gaia_110 / 014 / 128 跑满 15 轮,读到正文却选错实体);② 检索精度墙 (仅 gaia_029:niche 事实没被索引,13 次换词、10 次被迫转抓仍未锁定);③ 触发纪律(frames_543 / 647 搜 1 次就答、frames_562 干脆 0 搜------没搜够就开口)。
诚实的边界:frames_241 这类多跳题 PASS 是不稳定的 ~⅓ (专跑 4 遍 1/4,head-to-head 也 FAIL 过),根因是上游非 vanilla、temperature 0 都不复现。所以升级把瓶颈从"基建 / 轮数"挪到了"多跳推理选实体 + 上游确定性",不是"攻克"。
结论与可迁移原则
这轮实验把瓶颈从"基建"推进到了"判断" :搜得准、抓得到、轮次便宜------都用数据验证做到了;剩下两道差的是多跳推理里选对实体的能力,那是下一座山(更强的规划/自我验证),不再是搜索管线的事。五条可迁移原则:
- 内容内联优先:能让检索 API 直接返回查询相关内容(Exa highlights / Tavily),就别"搜→抓→再调模型抽"。
- 抽取用检索,不用生成:语义高亮(embedding 选段)比"叫模型写摘要"快一个量级(实测 613ms vs 3284ms),且逐字保真。
- 缓存稳定前缀、历史只追加:system+tools 缓存住,别每轮重写历史------这是"负担得起多轮"的前提(实测靠后轮 input token 降到个位数)。
- 位置截断是隐形 bug:按字符切正文会静默丢答案,要按查询相关性留。
- 护城河要认:服务端 co-location 和"边生成边执行"复刻不了,但它们不是速度大头------内联、缓存、代码过滤才是,这三样都能自己做。
Yao Yuheng / 姚钰珩
NTU Data Science 硕士。专注:AI Agent 系统工程、Eval 驱动开发、LLM 应用。
本文首发于 sg.yaoyuheng2001.me,转载请注明出处。
Blog · GitHub · 掘金 · Substack · RSS
相关链接:上一篇:用 30 道题量化我和 Claude.ai 的差距 · 白皮书:Agent Harness 工程化方法论 · GitHub 仓库
权威来源: Claude Web Search · Web Fetch · Parallel Tool Use · Prompt Caching · Advanced Tool Use · "Don't Break the Cache"(arXiv) · Claude Code Web Tools 逆向 · Exa API