公共资源速递
6 个公共数据集:
- TACK 靶向嵌合体知识库数据集
* EAVSD 电商广告视频分镜数据集
-
Movie Feelings 电影情感特征数据集
-
OpenSAL360 全景视频显著性数据集
-
AI Student Impact AI 辅助学习影响数据集
-
Noisy Medical Document 含噪医疗文档图像数据集
6 个公共教程:
-
Galaxy-Deconv:星系图像反卷积
-
Gemma4 12B-it:图文音统一多模态模型
-
LongCat-Video-Avatar 1.5 视频化身系统
-
Sketch-RNN:矢量草图生成与潜在空间插值
-
Supertonic-3:轻量级本地多语言语音合成系统
-
AutoFigure:基于 LLM 的学术论文插图自动生成系统
访问官网立即使用: openbayes.com
公共数据集
1. TACK 靶向嵌合体知识库数据集
该数据集专为机器学习驱动的 PROTAC 降解活性预测任务构建,广泛应用于 PROTAC 降解活性预测、靶向蛋白降解(TPD)研究、人工智能辅助药物发现(AIDD)、计算机辅助药物设计(CADD)、药物虚拟筛选、多任务学习、分子性质预测、图神经网络研究以及机器学习基准测试等领域。
2. EAVSD 电商广告视频分镜数据集
该数据集包含 50,538 个产品样本,总计 401,351 张场景图,涵盖 8 个匿名化电商产品类别,每个样本包含 1 张参考图片、8 条英文场景提示词及对应生成的场景图。
3. Movie Feelings 电影情感特征数据集
该数据集包含 1,500 部具有代表性且具有文化影响力的电影,时间跨度为 1920 年至 2024 年,覆盖怀疑、恐惧、平静、厌恶、团结、欣喜等 50 种情感状态。
4. OpenSAL360 全景视频显著性数据集
OpenSAL360 是目前最大规模的全方位视频显著性数据集,旨在支持视觉注意力、显著性预测以及多模态视频分析的研究。该数据集广泛应用于全景视频理解、视觉注意力建模、显著性预测算法评估、多模态感知研究以及 VR / AR 交互系统设计等多个研究与工程领域。
5. AI Student Impact AI 辅助学习影响数据集
该数据集包含 50,000 名学生样本,共 16 个结构化特征字段,覆盖学生的学术背景、AI 使用行为、学习行为、机构背景、心理健康状态、应用场景等数据。
6. Noisy Medical Document 含噪医疗文档图像数据集
Noisy Medical Document 是一个面向 OCR 与医疗文档理解任务的噪声增强医疗文档图像数据集,旨在模拟真实医疗场景中扫描文档所面临的复杂噪声干扰问题,提升 OCR 模型与文档理解模型在真实环境下的鲁棒性与泛化能力。该数据集包含 1,000 张高保真合成医疗文档图像,其中医院账单 500 张、出院小结 500 张,并配套提供完整的 JSON 结构化标注数据。
公共教程
1. Galaxy-Deconv:星系图像反卷积
Galaxy-Deconv 是由清华大学与 Northwestern University 发布的星系图像反卷积项目,该项目面向弱引力透镜观测中的星系图像复原问题,使用展开式 Plug-and-Play ADMM 方法对受点扩散函数(PSF)模糊与噪声影响的星系图像进行反卷积。
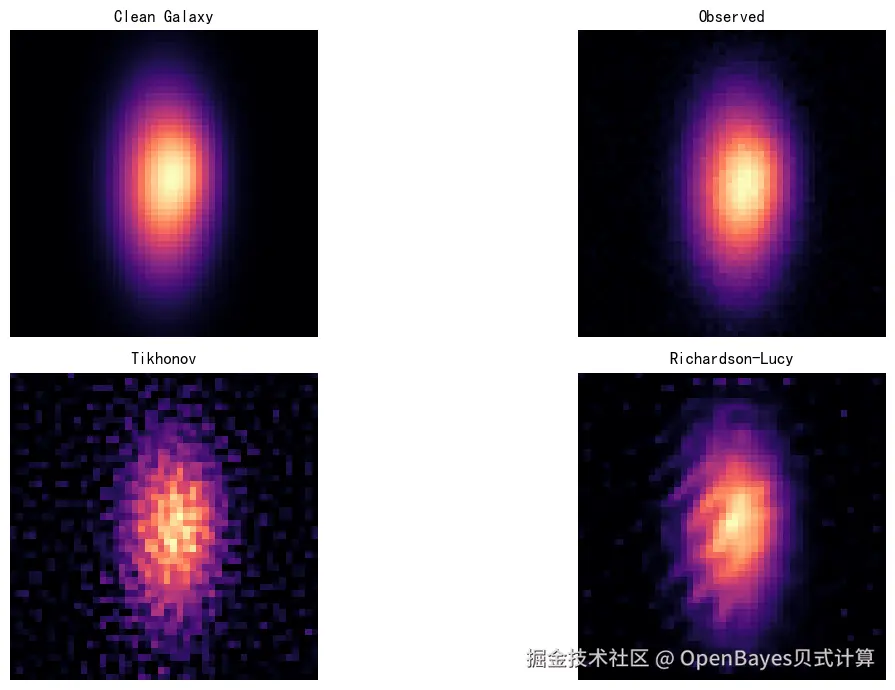
可视化结果
2. Gemma4 12B-it:图文音统一多模态模型
Gemma 4 12B-it 是 Google DeepMind 发布的 Gemma 4 系列统一多模态模型,采用 encoder-free 架构,将图像和音频直接投影到 LLM 的嵌入空间中,无需独立的编码器即可处理文本、图像和音频三种模态,在 12B 参数量级实现了强大的推理、编码和多模态理解能力。
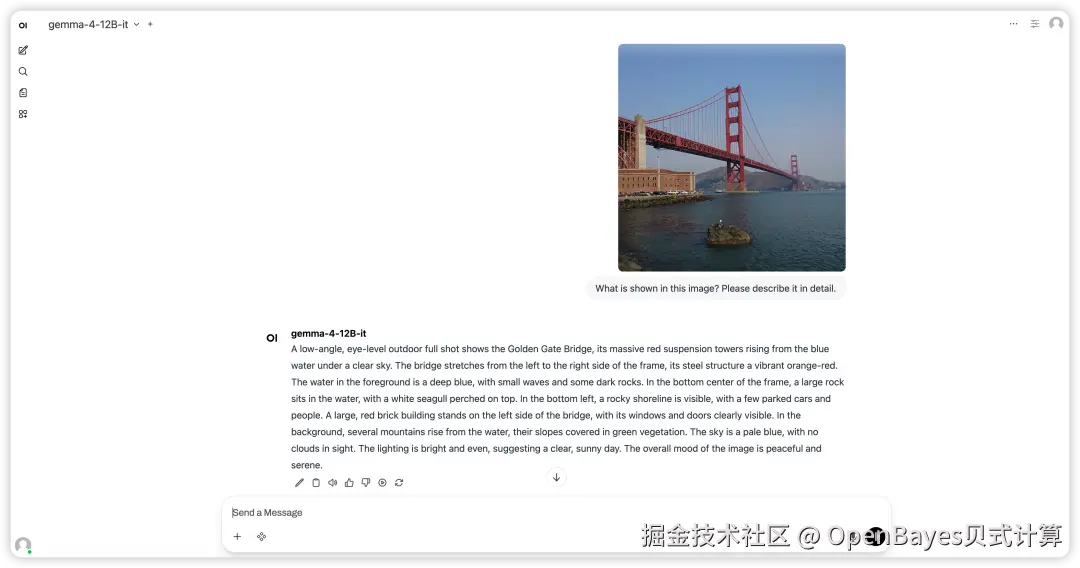
项目示例
3. LongCat-Video-Avatar 1.5 视频化身系统
LongCat-Video-Avatar 1.5 由美团 LongCat 团队于 2026 年 5 月发布,是一款全新升级的开源音频驱动视频生成(AI2V)框架。仅需一张静态参考图和一段驱动音频,即可生成高度逼真、口型完美同步的动态化身视频,且能够轻松应对复杂的真实世界场景以及动漫、动物等风格化领域。
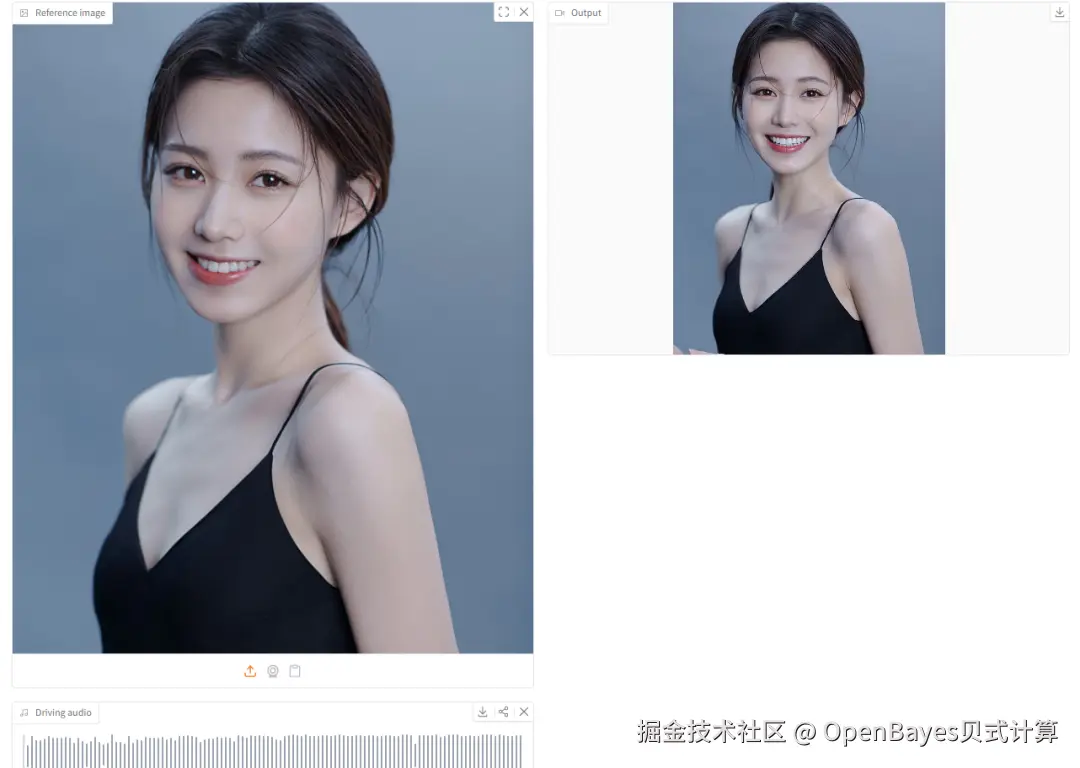
项目示例
4. Sketch-RNN:矢量草图生成与潜在空间插值
Sketch-RNN 是由 Google Brain 团队于 2017 年发布的矢量草图序列生成模型。该方法面向由笔画位移和落笔状态组成的手绘草图数据,能够学习草图的连续潜在表示,并生成新的矢量草图序列。Sketch-RNN 采用编码器-解码器结构,将输入草图映射到潜在空间,再通过循环神经网络解码器逐步生成笔画。
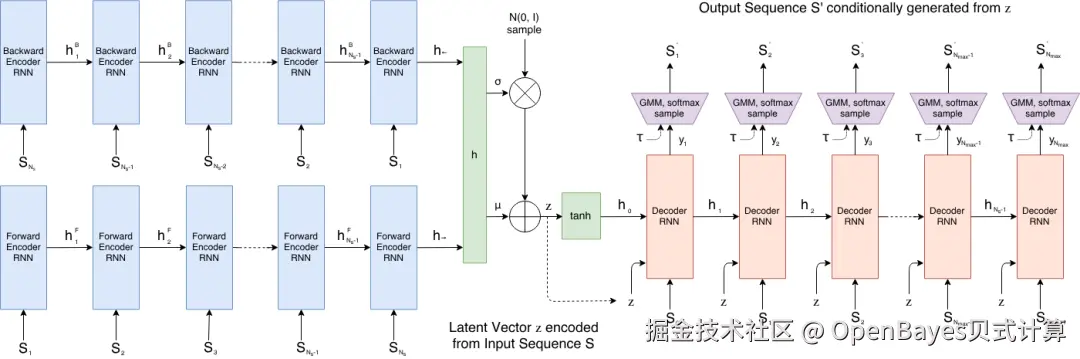
Sketch-RNN 的整体结构
5. Supertonic-3:轻量级本地多语言语音合成系统
Supertonic-3 由 Supertone 团队于 2026 年 4 月发布,是面向本地、离线和端侧场景的轻量级多语言文本转语音模型。该模型的核心价值在于用较小的模型体积覆盖多语言本地语音合成场景。相比依赖云端 API 的在线 TTS 服务,Supertonic-3 更适合在本地环境中完成可控、可复现的语音生成;相比体积更大的开源 TTS 模型,它又更便于快速启动与边缘端部署。
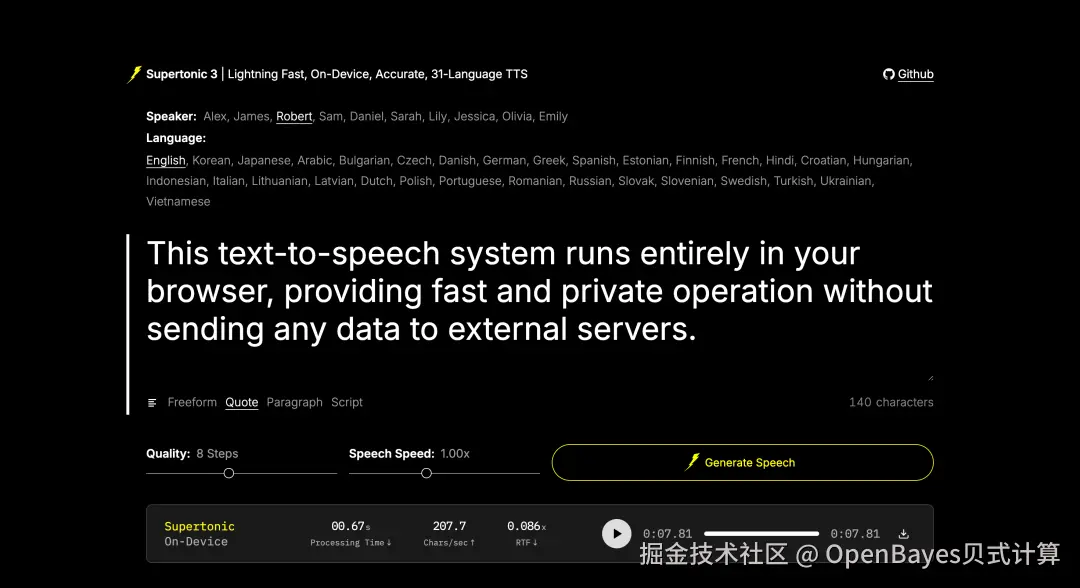
项目示例
6. AutoFigure:基于 LLM 的学术论文插图自动生成系统
AutoFigure 是西湖大学 ResearAI 团队开发的智能学术插图生成系统,发表于 ICLR 2026。该系统利用大型语言模型通过迭代优化机制,从文本描述或研究论文中自动生成达到出版标准的高质量科学插图,支持 SVG 矢量图和 mxGraph XML 两种输出格式。
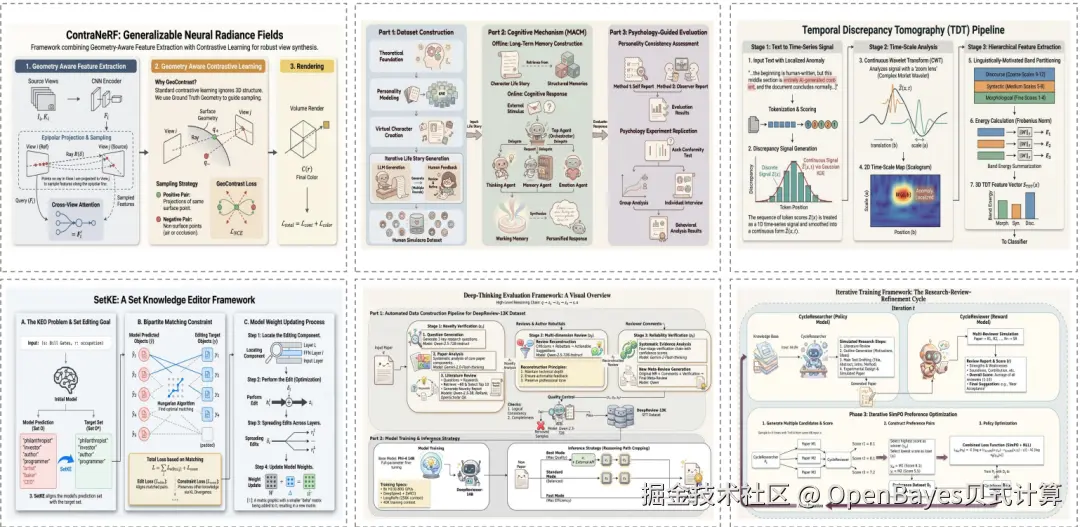
AutoFigure 生成复杂科学插图方面的通用性