深入理解CUDA NVCC编译系统:从PTX到二进制,从离线到即时
作为CUDA开发者,我们每天都在使用nvcc命令编译代码,但你是否真正理解它背后发生了什么?为什么同样的代码在不同GPU上运行速度不同?为什么有时程序启动会有明显延迟?本文将带你深入CUDA编译系统的核心,从编译流程到PTX与二进制文件,从兼容性到优化技巧,全面解析NVCC的工作原理。
一、NVCC是什么?不只是一个编译器
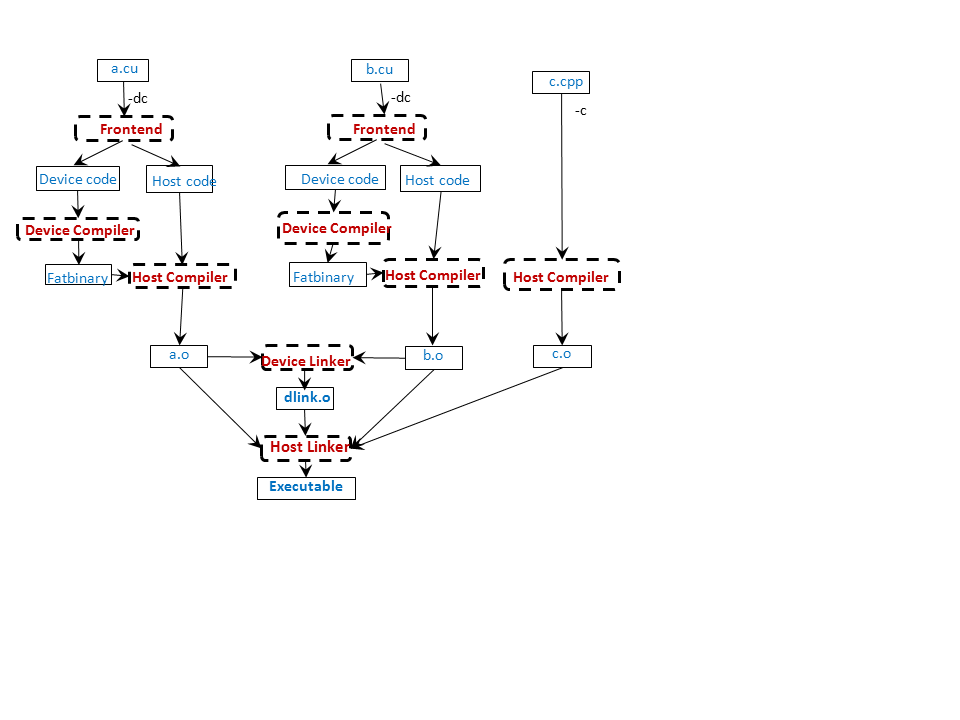
首先需要明确一个重要概念:NVCC不是一个单一的编译器,而是一个编译器驱动程序(Compiler Driver) 。它的核心作用是协调整个CUDA编译流程,将混合了CPU代码和GPU代码的.cu源文件拆分开来,分别调用不同的编译器进行处理,最后将结果链接成一个完整的可执行文件。
一个典型的CUDA源文件包含两部分:
- 主机代码(Host Code):运行在CPU上的标准C/C++代码
- 设备代码(Device Code) :运行在GPU上的CUDA内核函数(使用
__global__、__device__等修饰符)
NVCC的基本职责就是将这两部分代码分离并分别编译,最终让它们能够协同工作。
二、完整的NVCC编译工作流程
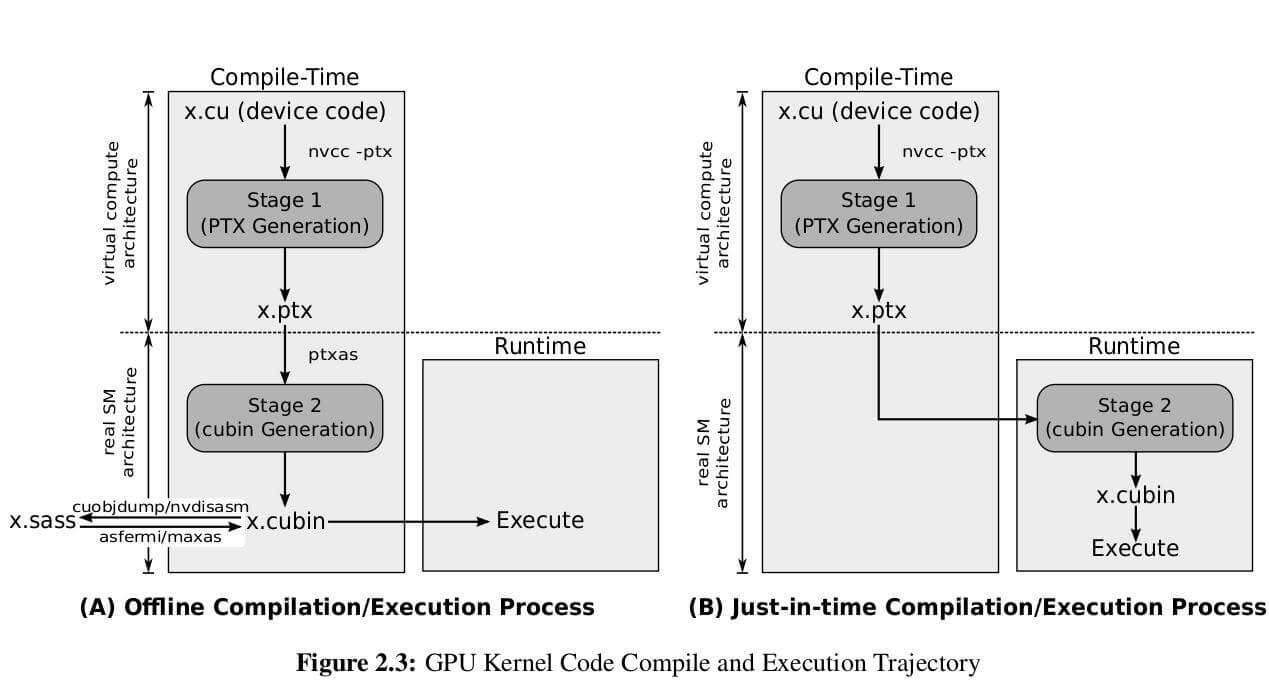
CUDA编译系统采用了两级编译模型:离线编译(Offline Compilation)和即时编译(Just-In-Time Compilation)。这种设计在性能和兼容性之间取得了很好的平衡。
2.1 离线编译(Offline Compilation)
离线编译是指在开发阶段完成的编译过程,它将源代码转换为可以直接在GPU上执行的形式。整个过程分为以下几个关键步骤:
-
代码分离阶段 :NVCC首先解析
.cu源文件,将主机代码和设备代码分离开来。- 分离:NVCC 根据语法规则(如 global 、device 等关键字)将代码分为:
- 设备代码:将在 GPU 上执行的函数。
- 主机代码:将在 CPU 上执行的普通 C/C++ 代码。
- 分离:NVCC 根据语法规则(如 global 、device 等关键字)将代码分为:
-
设备代码前端编译 :设备代码被编译为PTX (Parallel Thread Execution)中间表示。PTX是一种与硬件无关的虚拟指令集架构(ISA),它定义了GPU的编程模型和指令集,但不针对任何特定的GPU硬件。
-
设备代码后端编译 :PTX代码通过
ptxas工具进一步编译为Cubin (CUDA Binary )文件,其中包含了针对特定GPU架构的SASS (Streaming Multiprocessor Assembly)二进制指令。SASS是GPU硬件真正执行的机器码。 -
嵌入宿主可执行文件:生成的 PTX 和 CUBIN 会以静态数据的形式被放入一个"胖二进制"文件中,最终被链接到 CPU 端的目标文件里(支持运行时动态选择或通过 JIT 编译)。
-
主机代码编译 :主机代码被传递给系统的C/C++编译器(如GCC、Clang或MSVC)进行编译。同时,NVCC会将源代码中的
<<<...>>>内核启动语法替换为对CUDA运行时库的函数调用。 -
链接阶段 :将编译后的主机目标文件、设备Cubin文件以及CUDA运行时库链接在一起,生成最终的可执行文件。
-
设备链接 :CPU 链接器(如 ld 或 link.exe)只能处理 CPU 端的符号链接,完全不了解 GPU 的虚拟地址空间、线程模型、内存架构。无法重定位 GPU 函数之间的调用地址,无法解析跨文件的 device 变量引用,无法合并多个 .cu 文件的设备代码段。因此调用专用 GPU 链接器提取不同设备代码段,解析跨文件的引用关系,将多个设备代码段合并成一个统一的设备镜像,最终生成一个完整的、可执行的 GPU 程序映像。
-
整体链接:由 CPU 链接器执行,将编译后的主机目标文件、完整的设备Cubin文件以及CUDA运行时库链接在一起,生成最终的可执行文件。
-
2.2 即时编译(JIT Compilation)
即时编译是指在程序运行时完成的编译过程。当程序在一个没有对应Cubin文件的GPU上运行时,CUDA驱动会自动将嵌入在可执行文件中的PTX代码编译为当前GPU架构的SASS指令。
JIT编译的优点:
- 向前兼容性:可以在编译时不存在的新GPU架构上运行程序
- 持续优化:可以受益于新驱动带来的编译器改进
- 动态生成代码:可以在运行时根据输入数据生成最优的内核代码
JIT编译的缺点:
- 启动延迟:首次运行内核时会有明显的编译延迟
- 运行时内存占用:需要在内存中保存PTX代码和编译结果
重要区别 :离线编译使用ptxas工具生成SASS,而JIT编译由GPU驱动程序内部完成,不需要安装CUDA Toolkit。
三、PTX文件与二进制文件详解
3.1 PTX:虚拟指令集架构
PTX是CUDA的中间表示语言,它是一种低级的、类似汇编的语言,但具有很强的抽象性,不依赖于任何特定的GPU硬件。
PTX的特点:
- 与硬件无关:同一份PTX代码可以在任何支持对应计算能力的GPU上运行
- 向前兼容:为旧架构生成的PTX可以在新架构上运行(但反之不行)
- 可移植性:是CUDA程序跨代兼容的基础
- 人类可读 :可以通过
nvcc -ptx命令生成并查看PTX代码
生成PTX文件的命令:
bash
nvcc -ptx mykernel.cu -o mykernel.ptx演示:
cpp
__global__ void vectorAdd(const float* a, const float* b, float* c, int n) {
// 获取当前线程的全局索引
int index = blockIdx.x * blockDim.x + threadIdx.x;
// 确保索引在有效范围内
if (index < n) {
c[index] = a[index] + b[index];
}
}编译后的 ptx 汇编
asm
//
// Generated by NVIDIA NVVM Compiler
//
// Compiler Build ID: CL-34097967
// Cuda compilation tools, release 12.4, V12.4.131
// Based on NVVM 7.0.1
//
.version 8.4
.target sm_52
.address_size 64
// .globl _Z9vectorAddPKfS0_Pfi
.visible .entry _Z9vectorAddPKfS0_Pfi(
.param .u64 _Z9vectorAddPKfS0_Pfi_param_0,
.param .u64 _Z9vectorAddPKfS0_Pfi_param_1,
.param .u64 _Z9vectorAddPKfS0_Pfi_param_2,
.param .u32 _Z9vectorAddPKfS0_Pfi_param_3
)
{
.reg .pred %p<2>;
.reg .f32 %f<4>;
.reg .b32 %r<6>;
.reg .b64 %rd<11>;
ld.param.u64 %rd1, [_Z9vectorAddPKfS0_Pfi_param_0];
ld.param.u64 %rd2, [_Z9vectorAddPKfS0_Pfi_param_1];
ld.param.u64 %rd3, [_Z9vectorAddPKfS0_Pfi_param_2];
ld.param.u32 %r2, [_Z9vectorAddPKfS0_Pfi_param_3];
mov.u32 %r3, %ctaid.x;
mov.u32 %r4, %ntid.x;
mov.u32 %r5, %tid.x;
mad.lo.s32 %r1, %r3, %r4, %r5;
setp.ge.s32 %p1, %r1, %r2;
@%p1 bra $L__BB0_2;
cvta.to.global.u64 %rd4, %rd1;
mul.wide.s32 %rd5, %r1, 4;
add.s64 %rd6, %rd4, %rd5;
cvta.to.global.u64 %rd7, %rd2;
add.s64 %rd8, %rd7, %rd5;
ld.global.f32 %f1, [%rd8];
ld.global.f32 %f2, [%rd6];
add.f32 %f3, %f2, %f1;
cvta.to.global.u64 %rd9, %rd3;
add.s64 %rd10, %rd9, %rd5;
st.global.f32 [%rd10], %f3;
$L__BB0_2:
ret;
}3.2 Cubin与SASS:硬件特定二进制
Cubin文件是包含SASS指令的二进制文件,SASS是GPU硬件直接执行的机器码。
Cubin/SASS的特点:
- 与硬件相关:每个Cubin文件只针对特定的GPU架构(如sm_86、sm_90)
- 执行效率高:已经针对特定硬件进行了优化
- 无运行时开销:可以直接加载执行,无需额外编译
- 不可移植:不能在不同架构的GPU上运行
生成Cubin文件的命令:
bash
nvcc -cubin mykernel.cu -o mykernel.cubin -arch=sm_863.3 Fatbin:多目标容器
为了让一个可执行文件能够在多种GPU架构上运行,NVCC引入了Fatbin (Fat Binary)机制。Fatbin是一个容器,可以包含多个不同架构的Cubin文件和一个PTX文件。
当程序运行时,CUDA运行时会自动选择最适合当前GPU的代码:
- 如果有与当前GPU架构完全匹配的Cubin文件,直接使用它
- 如果没有,就寻找最接近的兼容Cubin文件
- 如果连兼容的Cubin文件都没有,就使用PTX代码进行JIT编译
四、CUDA兼容性:计算能力与目标架构
兼容性是CUDA开发中最容易出错的地方之一。要理解兼容性,首先需要了解计算能力 (Compute Capability)的概念。
4.1 计算能力(Compute Capability)
计算能力是NVIDIA为其GPU架构定义的版本号,格式为X.Y,其中:
X是主版本号,表示GPU的架构代际(如7代表Volta,8代表Ampere,9代表Blackwell)Y是次版本号,表示同一代架构中的改进版本
常见的计算能力与对应架构:
| 计算能力 | 架构名称 | 代表GPU |
|---|---|---|
| 7.0 | Volta | V100 |
| 7.5 | Turing | RTX 20系列 |
| 8.0 | Ampere | A100 |
| 8.6 | Ampere | RTX 30系列 |
| 9.0 | Blackwell | H100, RTX 40系列 |
| 10.0 | Blackwell | B100, RTX 50系列 |
4.2 二进制兼容性(Cubin兼容性)
Cubin文件的兼容性遵循主版本号相同,次版本号向后兼容的原则:
- 一个为计算能力
X.Y生成的Cubin文件可以在任何计算能力为X.Z(Z ≥ Y)的GPU上运行 - 但不能在计算能力为
X.Z(Z < Y)或W.X(W ≠ X)的GPU上运行
例如:
- sm_80的Cubin可以在sm_80、sm_86、sm_89的GPU上运行
- sm_86的Cubin不能在sm_80的GPU上运行
- sm_80的Cubin不能在sm_90的GPU上运行
4.3 PTX兼容性
PTX代码的兼容性遵循向前兼容,不向后兼容的原则:
- 为计算能力
X.Y生成的PTX代码可以在任何计算能力≥X.Y的GPU上运行 - 但不能在计算能力<
X.Y的GPU上运行
4.4 如何正确指定目标架构
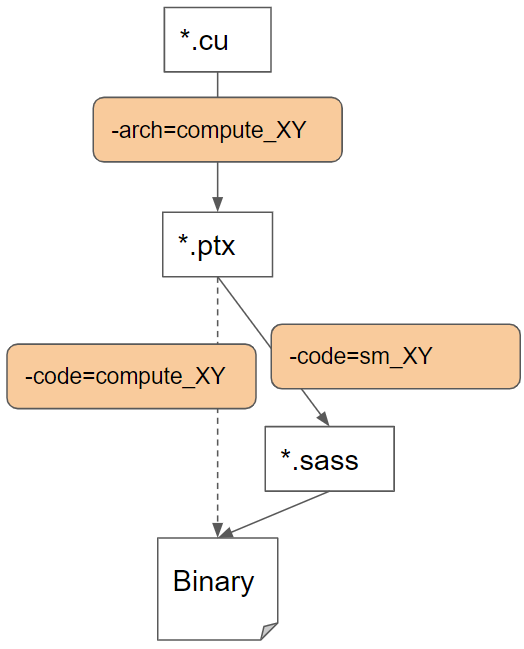
NVCC提供了两种主要方式来指定目标架构:-arch和-gencode。
1. -arch=sm_XX
这是最常用的简化选项,它等价于:
bash
-gencode=arch=compute_XX,code=sm_XX
-gencode=arch=compute_XX,code=compute_XX它会生成针对sm_XX架构的Cubin文件和针对compute_XX的PTX文件,这样程序可以在sm_XX及以上架构的GPU上运行。
2. -gencode选项
-gencode选项提供了更精细的控制,允许我们为多个架构生成代码。它的语法是:
bash
-gencode=arch=compute_XX,code=YY其中:
arch=compute_XX指定前端编译的PTX版本code=YY指定后端编译的目标,可以是sm_XX(生成Cubin)或compute_XX(生成PTX)
推荐的多架构编译命令(支持从Pascal到Blackwell的所有主流GPU):
bash
nvcc -gencode=arch=compute_60,code=sm_60 \
-gencode=arch=compute_61,code=sm_61 \
-gencode=arch=compute_70,code=sm_70 \
-gencode=arch=compute_75,code=sm_75 \
-gencode=arch=compute_80,code=sm_80 \
-gencode=arch=compute_86,code=sm_86 \
-gencode=arch=compute_90,code=sm_90 \
-gencode=arch=compute_100,code=sm_100 \
-gencode=arch=compute_100,code=compute_100 \
-O2 -o myapp myapp.cu这个命令会为每个架构生成对应的Cubin文件,并为最新的compute_100生成PTX文件,确保程序可以在未来的GPU上运行。
五、NVCC编译优化方法
NVCC提供了丰富的优化选项,可以从主机代码、设备代码和链接过程三个层面进行优化。
5.1 主机代码优化
主机代码的优化由系统的C/C++编译器负责,NVCC通过-O选项将优化级别传递给主机编译器:
bash
nvcc -O2 -o myapp myapp.cu # 主机代码使用O2优化
nvcc -O3 -o myapp myapp.cu # 主机代码使用O3优化5.2 设备代码优化
设备代码的优化由NVCC的设备编译器负责,有几个重要的优化选项:
1. 快速数学库:
bash
nvcc -use_fast_math -o myapp myapp.cu启用快速数学库,牺牲一定的精度换取更高的性能。它会将一些标准数学函数替换为更快的硬件实现版本。
2. 快速编译模式:
bash
nvcc -Ofc=max -o myapp myapp.cu # 最快编译速度,禁用大部分优化
nvcc -Ofc=mid -o myapp myapp.cu # 平衡编译时间和运行性能
nvcc -Ofc=min -o myapp myapp.cu # 最小影响,只禁用最耗时的优化-Ofc(Fast Compile)选项控制设备代码的编译速度与运行性能之间的权衡。
3. 最大寄存器数限制:
bash
nvcc -maxrregcount=64 -o myapp myapp.cu限制每个线程使用的最大寄存器数。减少寄存器使用可以增加每个SM上可以同时运行的线程块数,但可能会导致更多的寄存器溢出到本地内存。
4. 设备链接时优化:
bash
nvcc -dlto -o myapp myapp.cu启用设备链接时优化(Device Link Time Optimization),可以跨多个目标文件进行设备代码优化,显著提高性能。
5.3 常用优化参数汇总
| 参数 | 作用 |
|---|---|
-O2/-O3 |
主机代码优化级别 |
-use_fast_math |
启用快速数学库 |
-dlto |
设备链接时优化 |
-maxrregcount=N |
限制每个线程的最大寄存器数 |
-lineinfo |
生成设备代码的行号信息,用于性能分析 |
-std=c++17 |
指定C++标准版本(CUDA 11+支持C++17,CUDA 12+支持C++20) |
--extended-lambda |
启用设备端lambda支持 |
--expt-relaxed-constexpr |
放宽设备端constexpr函数的限制 |
六、实战示例:完整的编译与CMake配置
6.1 基本编译命令
编译单个文件为可执行文件:
bash
nvcc -o hello hello.cu编译为目标文件:
bash
nvcc -c hello.cu -o hello.o链接多个目标文件:
bash
nvcc -o myapp main.o kernel1.o kernel2.o生成调试版本:
bash
nvcc -g -G -o myapp_debug myapp.cu-g生成主机代码的调试信息,-G生成设备代码的调试信息。
6.2 CMake配置示例
对于大型项目,推荐使用CMake进行构建。以下是一个完整的CUDA项目CMakeLists.txt示例:
cmake
cmake_minimum_required(VERSION 3.18)
project(cuda_demo LANGUAGES CXX CUDA)
# 设置C++标准
set(CMAKE_CXX_STANDARD 17)
set(CMAKE_CXX_STANDARD_REQUIRED ON)
# 设置CUDA标准
set(CMAKE_CUDA_STANDARD 17)
set(CMAKE_CUDA_STANDARD_REQUIRED ON)
# 查找CUDA包
find_package(CUDAToolkit REQUIRED)
# 添加可执行文件
add_executable(cuda_demo
main.cpp
kernel.cu
)
# 设置目标架构(支持从Ampere到Blackwell)
set_target_properties(cuda_demo PROPERTIES
CUDA_ARCHITECTURES "80;86;90;100"
)
# 启用设备链接时优化
target_compile_options(cuda_demo PRIVATE
$<$<COMPILE_LANGUAGE:CUDA>:-dlto>
)
# 链接CUDA运行时库
target_link_libraries(cuda_demo PRIVATE
CUDA::cudart
)
# 发布版本优化
if(CMAKE_BUILD_TYPE STREQUAL "Release")
target_compile_options(cuda_demo PRIVATE
$<$<COMPILE_LANGUAGE:CUDA>:-O3;-use_fast_math>
)
endif()6.3 实战:手动编译链接一个向量加法程序并进行验证
cuda源文件如下
cpp
#include <iostream>
#include <cuda_runtime.h>
// 检查CUDA错误的宏
#define CHECK_CUDA_ERROR(call) \
do { \
cudaError_t error = call; \
if (error != cudaSuccess) { \
std::cerr << "CUDA error in " << __FILE__ << " at line " << __LINE__ << ": " \
<< cudaGetErrorString(error) << std::endl; \
exit(EXIT_FAILURE); \
} \
} while(0)
// CUDA核函数:向量加法
// 在GPU上执行,每个线程处理一个元素
__global__ void vectorAdd(const float* a, const float* b, float* c, int n) {
// 获取当前线程的全局索引
int index = blockIdx.x * blockDim.x + threadIdx.x;
// 确保索引在有效范围内
if (index < n) {
c[index] = a[index] + b[index];
}
}
// CPU版本的向量加法(用于验证结果)
void vectorAddCPU(const float* a, const float* b, float* c, int n) {
for (int i = 0; i < n; i++) {
c[i] = a[i] + b[i];
}
}
int main() {
// 设置向量大小
int n = 1000000;
size_t bytes = n * sizeof(float);
std::cout << "向量大小: " << n << " 个元素" << std::endl;
std::cout << "内存大小: " << bytes / (1024 * 1024) << " MB" << std::endl;
// 1. 分配主机内存
float* h_a = new float[n];
float* h_b = new float[n];
float* h_c = new float[n];
float* h_c_cpu = new float[n];
// 2. 初始化主机数据
for (int i = 0; i < n; i++) {
h_a[i] = static_cast<float>(i);
h_b[i] = static_cast<float>(i * 2);
}
// 3. 分配设备内存
float *d_a, *d_b, *d_c;
CHECK_CUDA_ERROR(cudaMalloc(&d_a, bytes));
CHECK_CUDA_ERROR(cudaMalloc(&d_b, bytes));
CHECK_CUDA_ERROR(cudaMalloc(&d_c, bytes));
// 4. 将数据从主机复制到设备
CHECK_CUDA_ERROR(cudaMemcpy(d_a, h_a, bytes, cudaMemcpyHostToDevice));
CHECK_CUDA_ERROR(cudaMemcpy(d_b, h_b, bytes, cudaMemcpyHostToDevice));
// 5. 配置内核启动参数
int threadsPerBlock = 256;
int blocksPerGrid = (n + threadsPerBlock - 1) / threadsPerBlock;
std::cout << "线程块数量: " << blocksPerGrid << std::endl;
std::cout << "每块线程数: " << threadsPerBlock << std::endl;
// 6. 启动CUDA内核(在GPU上执行)
vectorAdd<<<blocksPerGrid, threadsPerBlock>>>(d_a, d_b, d_c, n);
// 等待GPU完成并检查错误
CHECK_CUDA_ERROR(cudaDeviceSynchronize());
CHECK_CUDA_ERROR(cudaGetLastError());
// 7. 将结果从设备复制回主机
CHECK_CUDA_ERROR(cudaMemcpy(h_c, d_c, bytes, cudaMemcpyDeviceToHost));
// 8. CPU验证(可选)
vectorAddCPU(h_a, h_b, h_c_cpu, n);
// 9. 验证结果(检查前10个元素)
bool correct = true;
std::cout << "\n前10个结果验证:" << std::endl;
for (int i = 0; i < std::min(10, n); i++) {
std::cout << "索引 " << i << ": " << h_a[i] << " + " << h_b[i]
<< " = " << h_c[i] << " (期望: " << h_c_cpu[i] << ")" << std::endl;
if (std::abs(h_c[i] - h_c_cpu[i]) > 1e-5) {
correct = false;
}
}
if (correct) {
std::cout << "\n✓ 结果验证成功!GPU计算正确。" << std::endl;
} else {
std::cout << "\n✗ 结果验证失败!" << std::endl;
}
// 10. 清理内存
delete[] h_a;
delete[] h_b;
delete[] h_c;
delete[] h_c_cpu;
CHECK_CUDA_ERROR(cudaFree(d_a));
CHECK_CUDA_ERROR(cudaFree(d_b));
CHECK_CUDA_ERROR(cudaFree(d_c));
// 11. 重置设备
CHECK_CUDA_ERROR(cudaDeviceReset());
return 0;
}
bash
# 步骤1: 分离主机和设备代码
nvcc -cuda vector_add.cu -o vector_add_host.cpp
# 步骤2:前端编译,生成设备 PTX 中间码
nvcc -ptx -arch=sm_70 vector_add.cu -o vector_add_device.ptx
# 步骤3: 后端编译,PTX 编译为 CUBIN
nvcc -cubin -arch=sm_70 vector_add_device.ptx -o vector_add_device.cubin
# 步骤4: G++编译主机代码
g++-11 -c -I$CONDA_PREFIX/include -D__CUDACC__ vector_add_host.cpp -o vector_add_host.o
# 步骤5: 设备代码封装到对象文件
nvcc -c -arch=sm_70 -dc vector_add.cu -o vector_add_device.o
# 步骤6: 最终链接
# 设备链接
nvcc -dlink -arch=sm_70 vector_add_device.o -o vector_add_dlink.o
# 整体链接
nvcc vector_add_host.cpp vector_add_dlink.o -o final_program
# 运行
./final_program结果
ubuntu@ubuntu:~/MyProject/MyCuda$ ./final_program
向量大小: 1000000 个元素
内存大小: 3 MB
线程块数量: 3907
每块线程数: 256
前10个结果验证:
索引 0: 0 + 0 = 0 (期望: 0)
索引 1: 1 + 2 = 3 (期望: 3)
索引 2: 2 + 4 = 6 (期望: 6)
索引 3: 3 + 6 = 9 (期望: 9)
索引 4: 4 + 8 = 12 (期望: 12)
索引 5: 5 + 10 = 15 (期望: 15)
索引 6: 6 + 12 = 18 (期望: 18)
索引 7: 7 + 14 = 21 (期望: 21)
索引 8: 8 + 16 = 24 (期望: 24)
索引 9: 9 + 18 = 27 (期望: 27)七、常见问题与最佳实践
7.1 为什么我的程序在新GPU上运行很慢?
这通常是因为程序没有为新GPU架构生成对应的Cubin文件,只能通过JIT编译PTX代码运行。JIT编译生成的代码质量通常不如离线编译,而且无法使用新架构的高级特性(如Tensor Core)。
解决方法 :在编译时为新架构添加对应的-gencode选项。
7.2 如何减少程序启动时间?
JIT编译是程序启动延迟的主要原因之一。以下是一些减少启动时间的方法:
- 为所有目标GPU架构生成对应的Cubin文件
- 使用CUDA的JIT缓存机制(默认启用,缓存位于
~/.nv/ComputeCache) - 提前进行JIT编译(可以在程序启动时预编译所有内核)
7.3 最佳实践总结
- 总是包含一个PTX目标 :在编译命令的最后添加
-gencode=arch=compute_XX,code=compute_XX,确保程序可以在未来的GPU上运行。 - 为常用架构生成Cubin:为你的用户最可能使用的GPU架构生成对应的Cubin文件,避免JIT编译延迟。
- 启用设备链接时优化 :
-dlto选项可以显著提高跨文件的设备代码性能。 - 使用最新的CUDA Toolkit:每个新版本的CUDA Toolkit都会带来编译器改进和新架构支持。
- 避免过度使用
-use_fast_math:只有在精度要求不高的情况下才使用,否则可能导致计算错误。
八、总结
NVCC编译系统是CUDA编程的核心,理解它的工作原理对于编写高性能、高兼容性的CUDA程序至关重要。本文详细讲解了:
- NVCC作为编译器驱动的角色和基本工作流程
- 离线编译与即时编译的区别和优缺点
- PTX与Cubin/SASS的本质和各自的特点
- CUDA兼容性规则和正确指定目标架构的方法
- 常用的编译优化选项和最佳实践
通过合理配置NVCC编译选项,我们可以在性能和兼容性之间取得最佳平衡,让我们的CUDA程序在各种GPU上都能发挥出最佳性能。