前言
写这篇文章,其实是因为最近看到有些公众号在介绍 Kotlin 协程时,都推荐在 Repository 中这样写:
kotlin
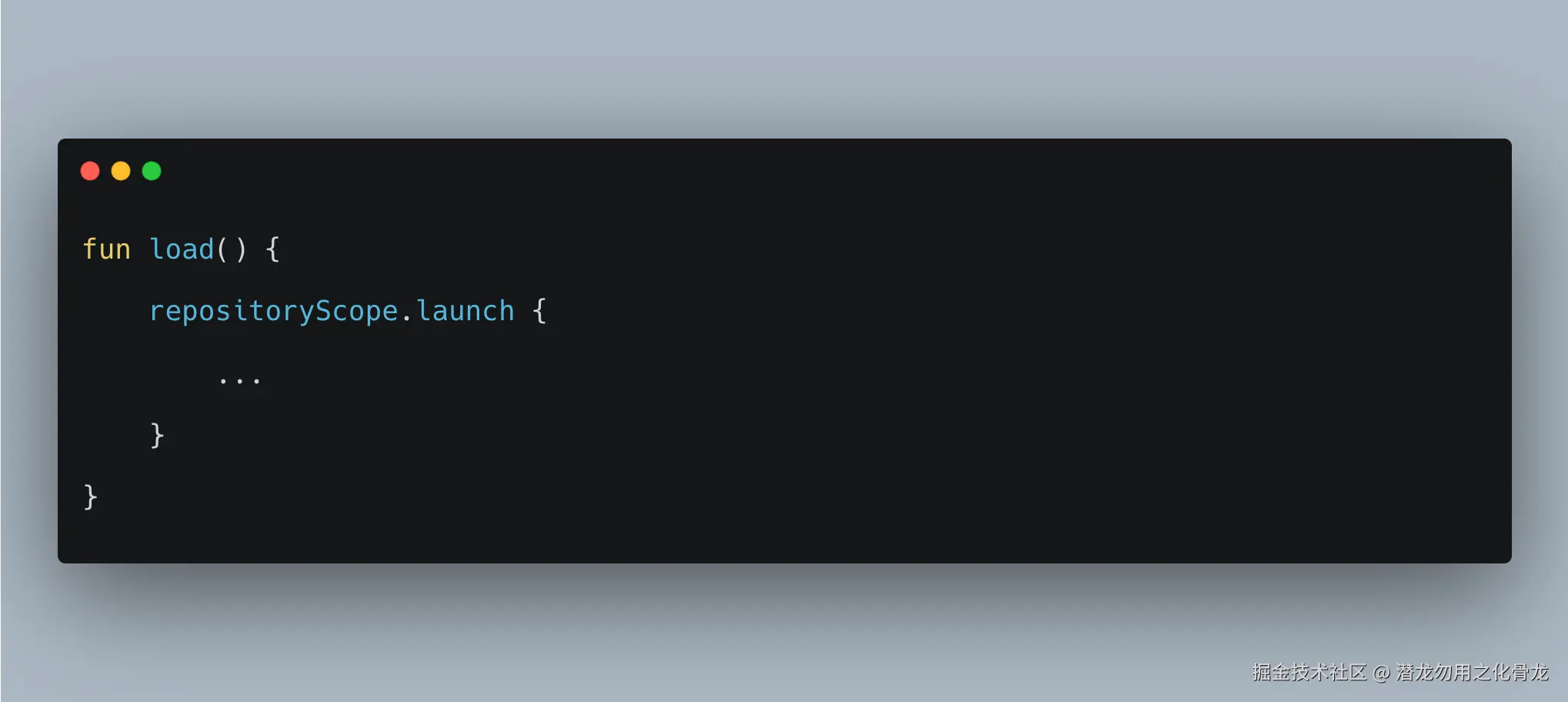
fun load() {
repositoryScope.launch {
// do something
}
}甚至把这种写法包装成一种"最佳实践",理由通常是:
- Repository 自己负责异步;
- 调用方不用
launch,调用更简单; - 避免阻塞主线程。
看到这样的文章越来越多,我实在忍不住了。
因为它真正改变的并不是"是否异步",而是任务的生命周期归属。
很多初学者会误以为:
耗时操作 = launch于是只要访问数据库、发起网络请求,就习惯性在 Repository 里偷偷 launch 一个新的协程。
但现代 Android 官方推荐的设计思想并不是这样。
对于绝大多数一次性数据操作,Repository 更应该暴露 suspend fun,由调用方决定在哪个 CoroutineScope 中启动协程。
因为:
suspend表达的是能力,而launch表达的是任务归属。
真正应该思考的问题从来不是"哪里写 launch 更方便",而是:
谁应该拥有这次任务的生命周期、取消权、完成时机以及异常边界?
这也是我写这篇文章最想讨论的问题。
一、先说结论:官方推荐背后的统一口径是什么?
如果把 Android 官方近几年的协程建议压缩成一句话,可以概括为:
Data / Domain 层对外暴露"挂起函数和 Flow",由调用方控制协程的创建、取消和生命周期。
也就是:
- 一次性操作 :暴露
suspend fun - 持续数据流 :暴露
Flow - 谁来启动协程 :通常是更上层,例如
ViewModel、UseCase 入口、WorkManager、应用级协调者
所以从职责上看:
- Repository 负责:定义数据语义
- 调用方负责:定义执行时机和生命周期
这就是为什么更推荐:
kotlin
suspend fun load()而不是:
kotlin
fun load() {
repositoryScope.launch { }
}二、这两个写法本质上到底差在哪?
看起来只是少写一个 launch,但它们表达的是两种完全不同的架构语义。
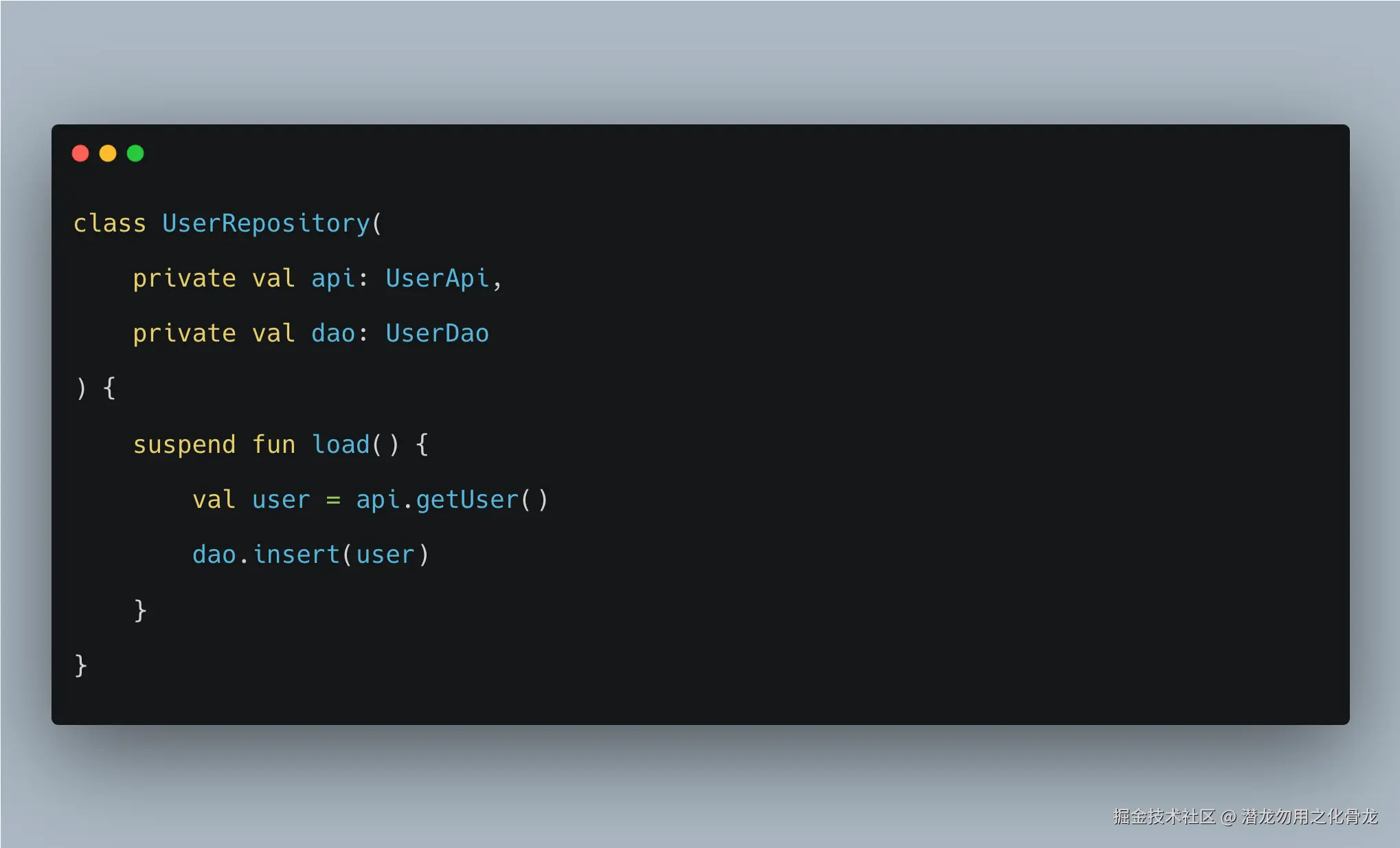
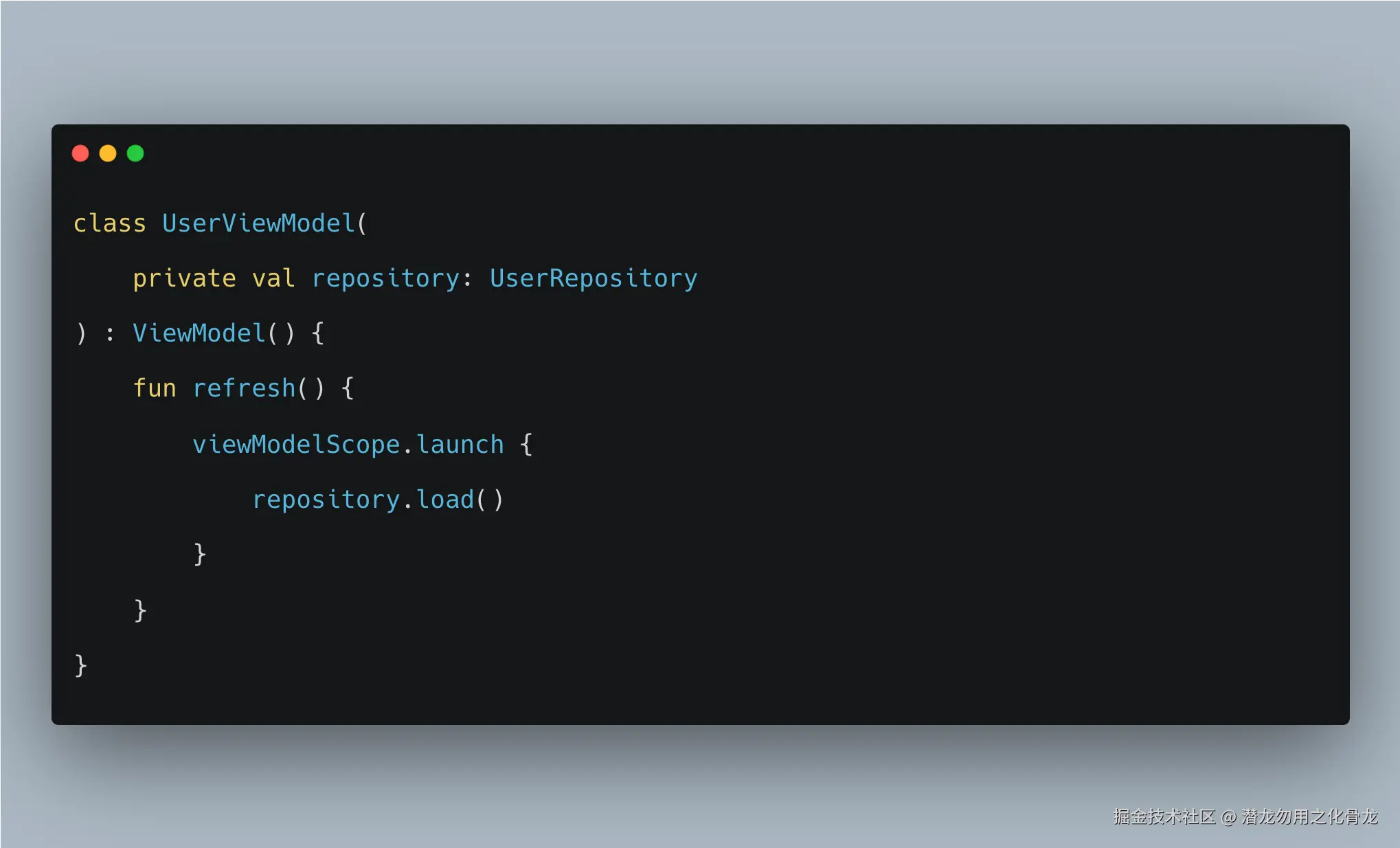
写法 A:suspend fun load()
调用方:
这个设计表示:
- Repository 只描述"这件事怎么做"
- ViewModel 决定"什么时候做"
- 任务归
viewModelScope管 - 页面销毁时,任务可以自动取消
- 异常能沿调用链自然传播
这是结构化并发的典型写法。
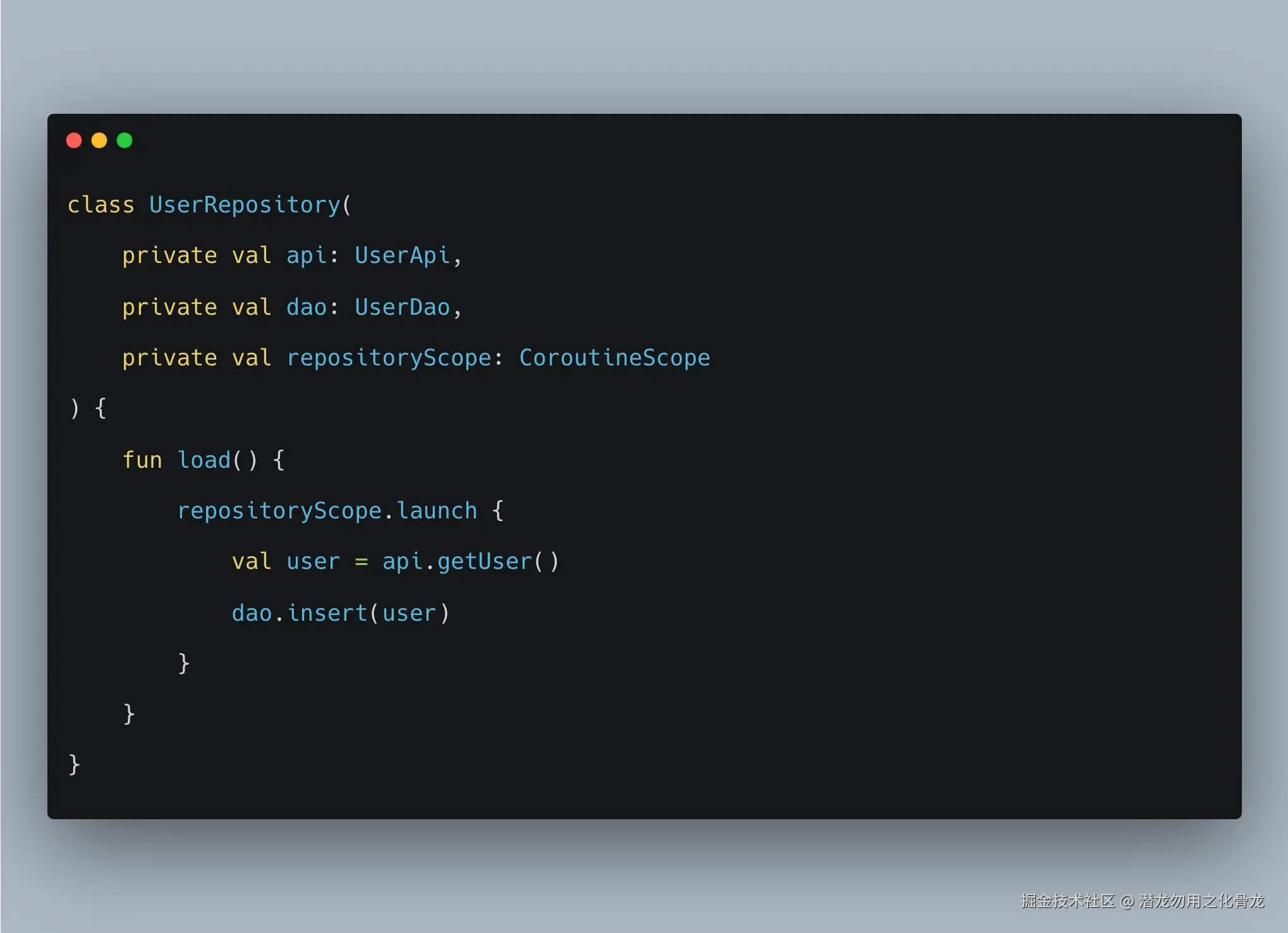
写法 B:Repository 内部 launch
调用方:
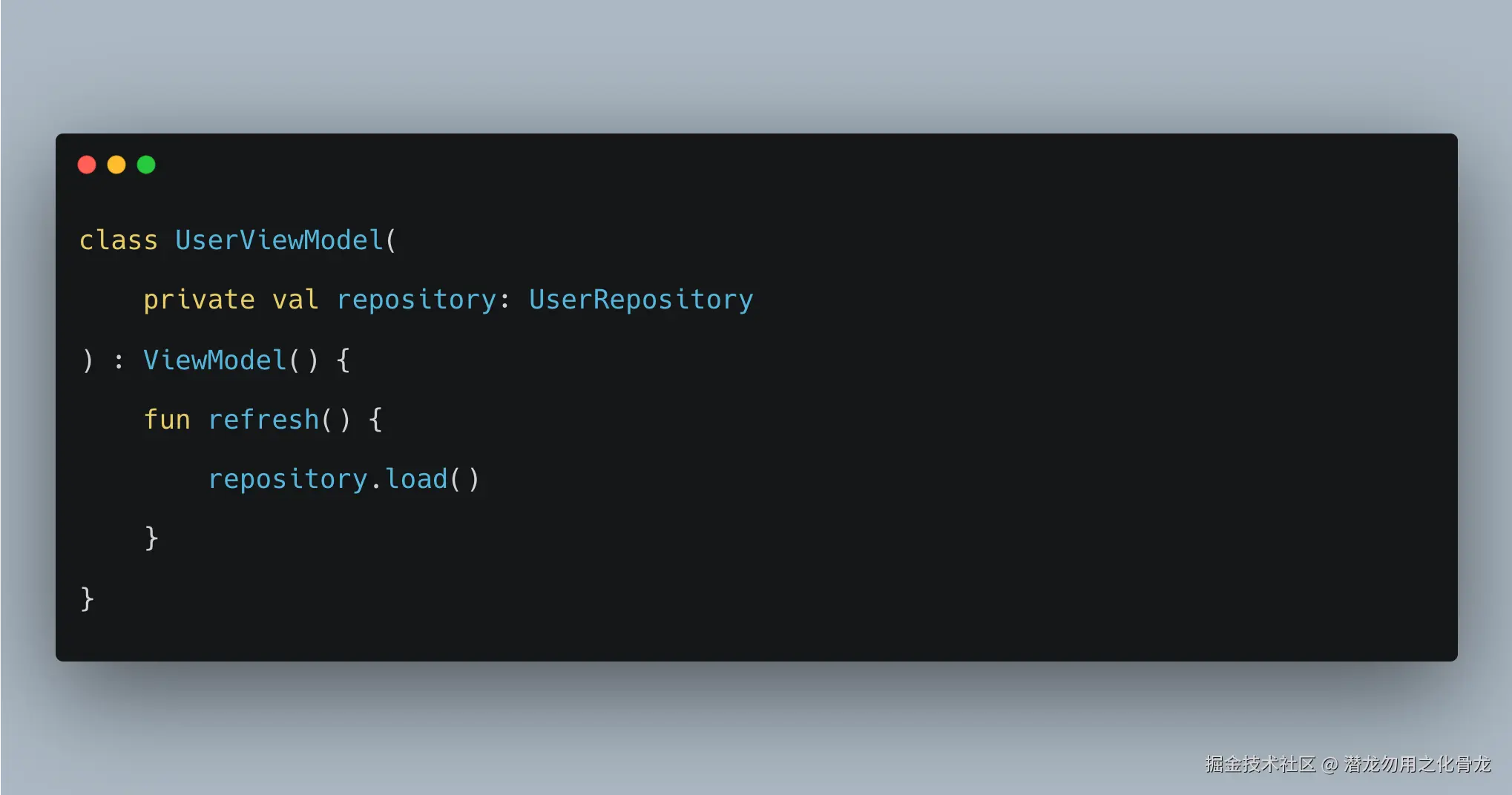
这个设计实际上表示:
- ViewModel 只是"发了个命令"
- 真正的协程生命周期不再归 ViewModel 管
- 调用方不知道任务什么时候结束
- 调用方也不知道异常会怎么处理
- 页面销毁后,这个任务可能还继续跑
所以,区别不是"谁写 launch 更方便",而是:
谁拥有这次异步任务的控制权。
三、为什么 suspend fun 更符合现代 Android 架构?
1. 调用方才能决定生命周期
在 Android 里,不同层的生命周期完全不同:
Fragment/Activity生命周期短ViewModel生命周期通常跟页面绑定- 应用级对象生命周期更长
WorkManager甚至希望任务在进程重启后继续
同一个 Repository,可能被很多不同调用方使用。
如果 Repository 自己偷偷 launch,它就等于假设:
"这份任务的生命周期由我来定。"
但这就是问题所在。
更合理的方式是让调用方决定:

这样:
- 页面不在了,可以取消
- 页面重试,可以重新发起
- 调用方可以决定串行、并行、限流、超时
- 生命周期跟 UI / 业务动作边界一致
这正是结构化并发要解决的问题。
2. suspend 天然支持结构化并发
suspend fun 最大的价值不是"异步",而是:
它把异步操作保留在当前调用链里。
例如:
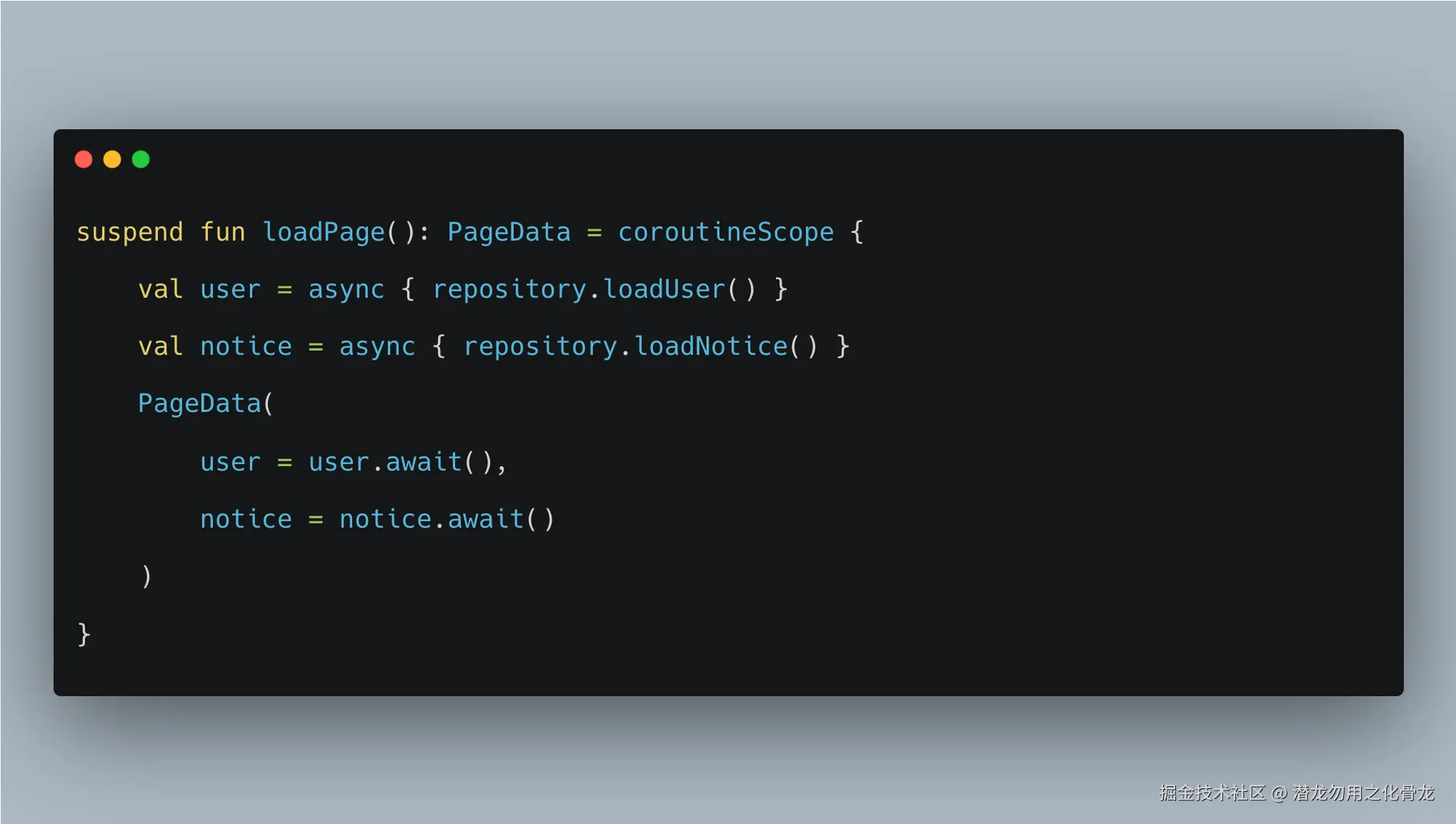
这里 repository.loadUser() 和 repository.loadNotice() 都是可组合的。
因为它们是 suspend fun,所以我们可以:
- 用
coroutineScope做并发组合 - 用
supervisorScope控制失败隔离 - 用
withTimeout控制超时 - 用
retry、runCatching、Result包装错误策略
但如果 Repository 内部直接 launch,那这些组合能力会明显变差。因为你已经拿不到这个任务的完成时机了。
3. launch 会让完成时机变得模糊
suspend 版本:

调用方很清楚:

内部 launch 版本:
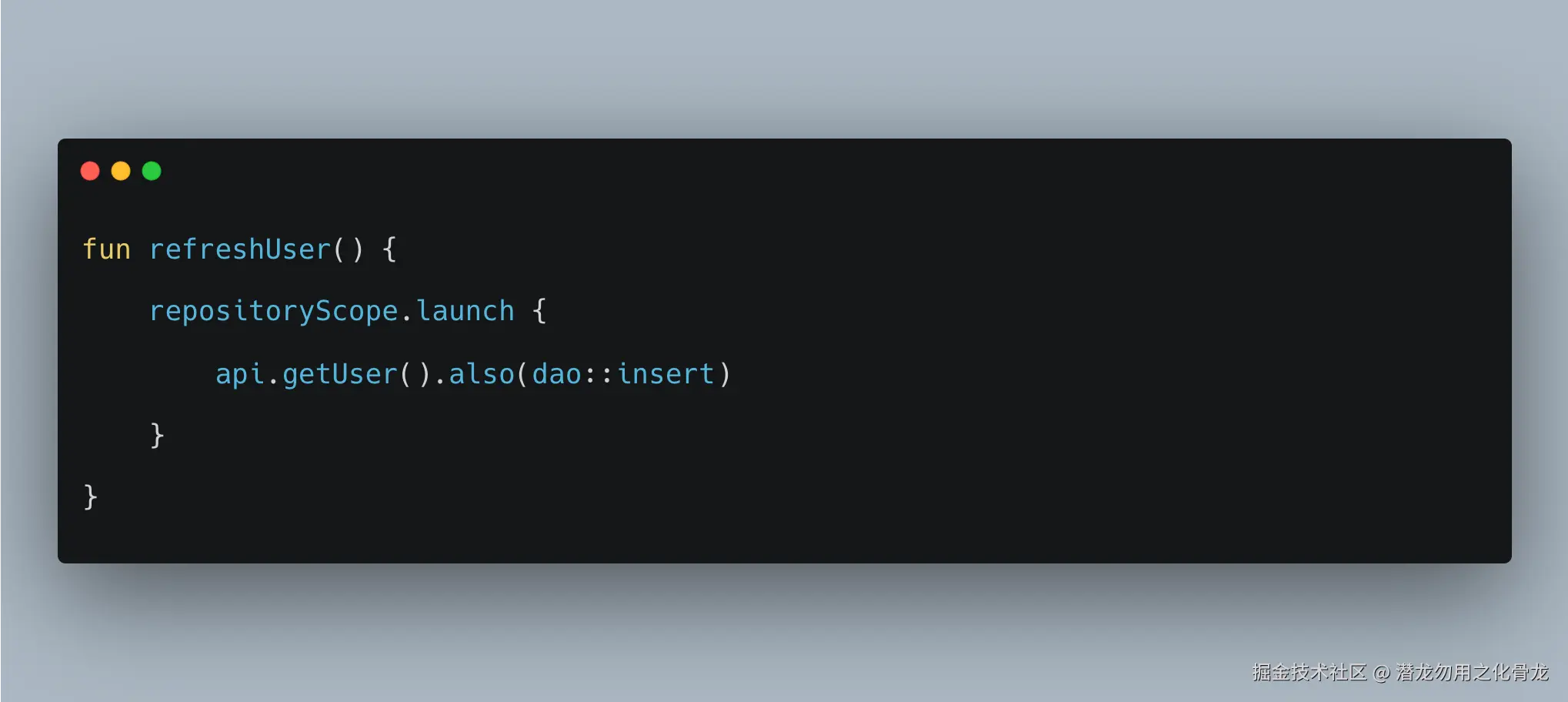
调用方:

于是你就会开始补各种东西:回调、事件通知、额外状态流、手写完成监听......
而这些问题,本来 suspend fun 天然就已经解决了。
Repository 内部
launch并没有减少复杂度,只是把时序复杂度藏起来了。
4. 异常传播会被打断
suspend fun 的一个重要优点是:
异常可以沿调用链自然上传。
例如:
 这条链路是很自然的:Repository 抛错 → ViewModel 捕获 → UI 决定如何展示。
这条链路是很自然的:Repository 抛错 → ViewModel 捕获 → UI 决定如何展示。
但如果 Repository 自己 launch,异常处理就变成一个问题:是 Repository 自己吃掉?还是打日志?还是发事件通知?还是依赖 CoroutineExceptionHandler 更致命的是 如果上层try catch 其实是包不住的。
错误边界开始变得不透明,而不透明往往就是可维护性开始下滑的地方。
5. 取消能力会被削弱
如果调用链保持结构化:
那当 viewModelScope 被取消时,repository.load() 会跟着取消。
但如果 Repository 使用自己的 repositoryScope,那调用方取消了自己,也不一定能取消 Repository 内部那个任务。
这会带来几个常见问题:
- 页面没了,网络还在跑
- 请求结果回来了,但页面已经销毁
- 多次点击触发多个后台任务,难以收敛
四、很多人把 withContext 和 launch 搞混了
这是整篇文章里一个非常关键的点,值得单独拿出来说。
很多开发者把:
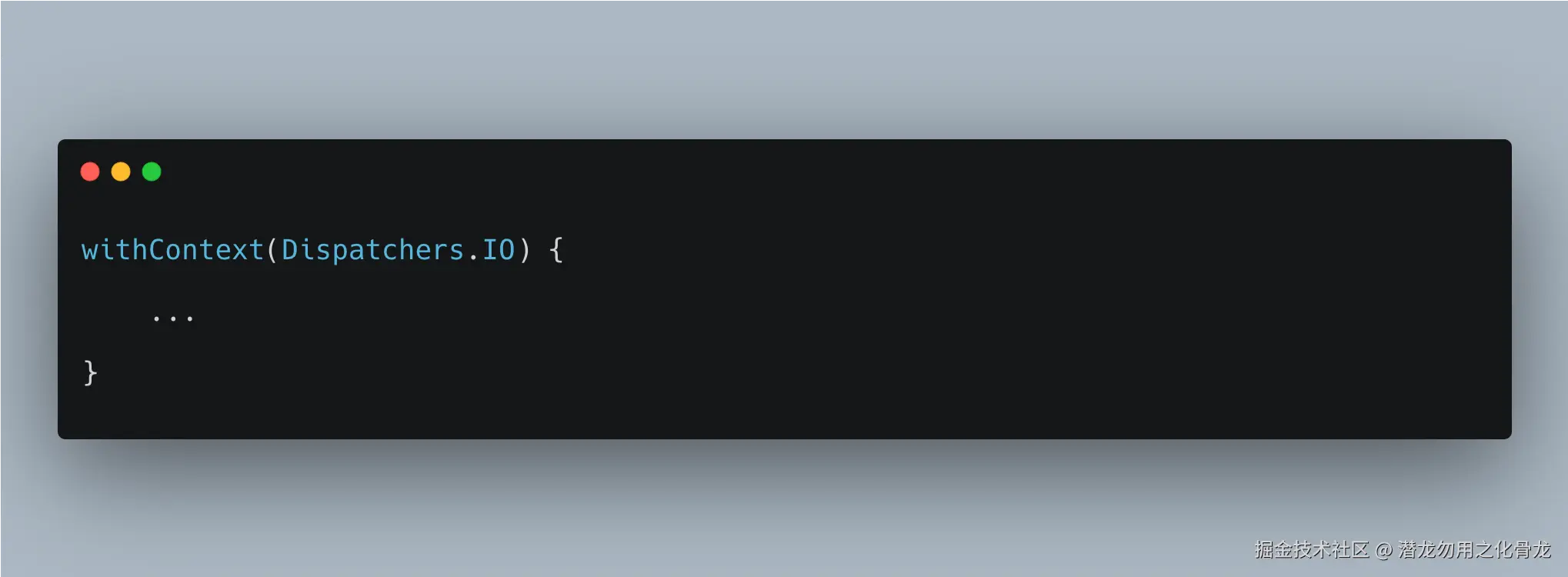
和:

认为是差不多的东西------"反正都是把耗时操作放到后台跑"。
实际上,它们解决的是完全不同的问题。
很多开发者真正想表达的是:
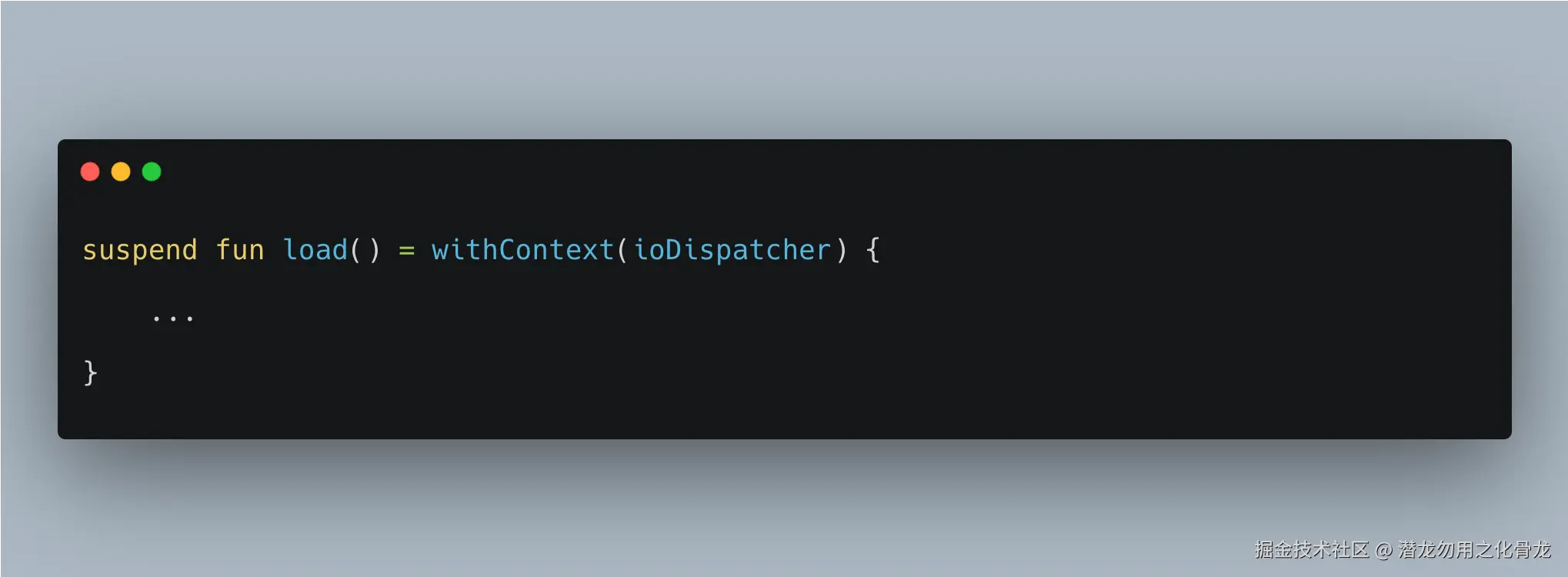
结果却写成了:
withContext 只是切换执行上下文
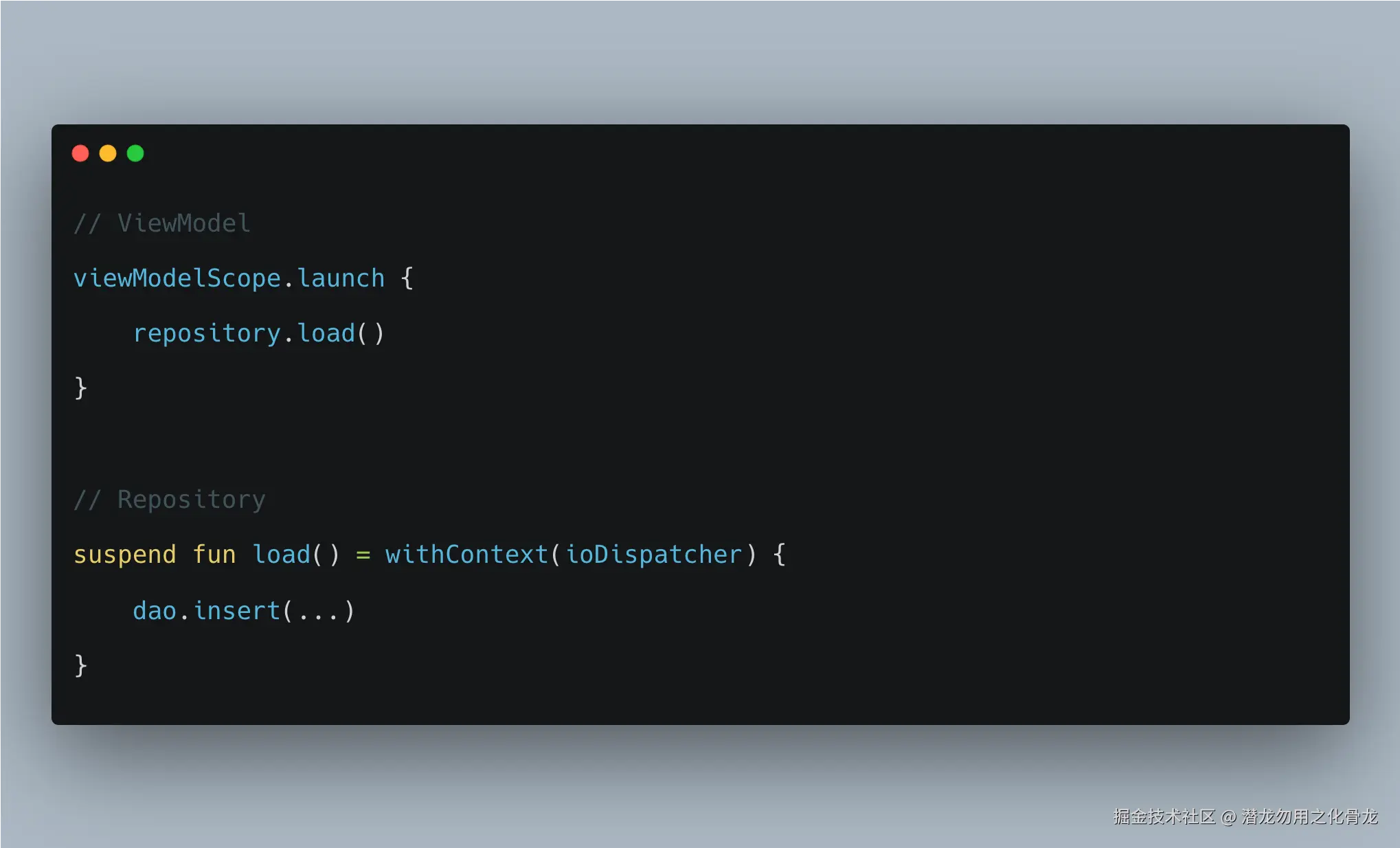
这里虽然线程可能从 Main 切到了 IO,但整个任务仍然属于同一个协程。也就是说:
- 生命周期没有变
- 取消关系没有变
- 异常传播没有变
withContext 只是临时切换了执行环境,并没有创建新的任务。整个调用链仍然保持结构化并发。
launch 则会创建新的协程
如果改成:
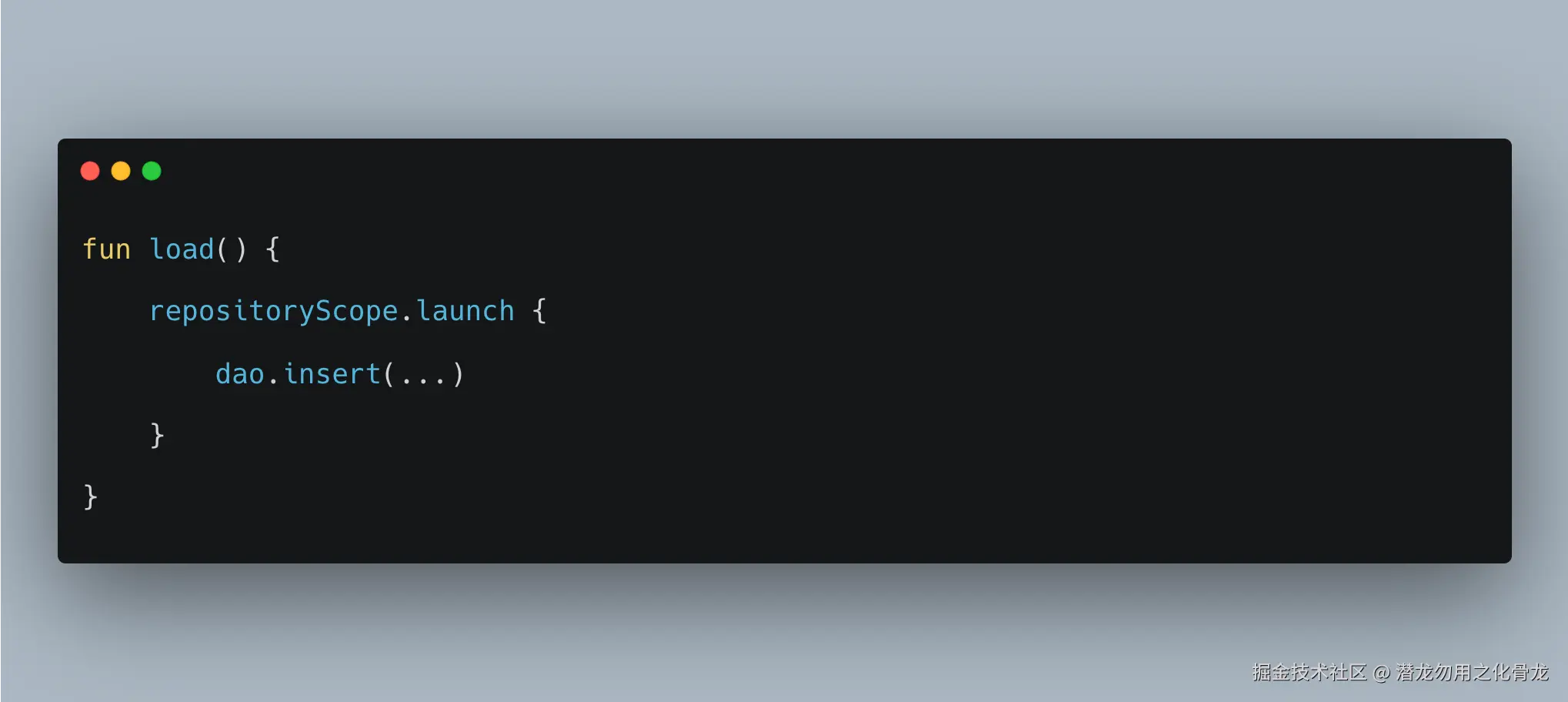
情况就完全不同了。Repository 已经主动创建了一个新的 Job,这意味着:
- 生命周期发生了变化
- 取消关系发生了变化
- 异常传播关系也发生了变化
调用方取消自己的协程,并不一定能够取消 Repository 内部那个新的任务。调用方也无法天然知道它什么时候完成。
withContext改变的是执行线程;launch改变的是任务归属。
很多公众号把这两者混为一谈,这是导致 Repository 滥用 launch 的重要原因之一。
真正需要线程切换时,优先考虑 withContext;真正需要创建一个拥有独立生命周期的新任务时,再考虑 launch。
五、Repository 内部 launch 最大的问题:职责越界
直觉上觉得自己只是"封装了一下异步"。但本质上,你已经额外承担了这些职责:
- 决定协程在哪个
Scope里跑 - 决定任务是否可取消
- 决定异常由谁处理
- 决定任务能否并发重入
- 决定调用方如何感知完成
这些其实都不是普通 Repository 的核心职责。普通 Repository 更像:
- 数据访问抽象
- 本地 / 远端组合
- 查询与写入语义封装
而不是:
- 后台任务调度器
- 生命周期托管器
- 任务状态协调中心
六、那 launch 应该放在哪里?
一个很实用的经验是:
launch放在边界层;suspend留在可组合的业务能力层。
1. ViewModel
kotlin
fun refresh() {
viewModelScope.launch {
repository.load()
}
}适用于页面按钮点击、首次加载、下拉刷新、页面生命周期触发的任务。
2. UseCase / Interactor 入口
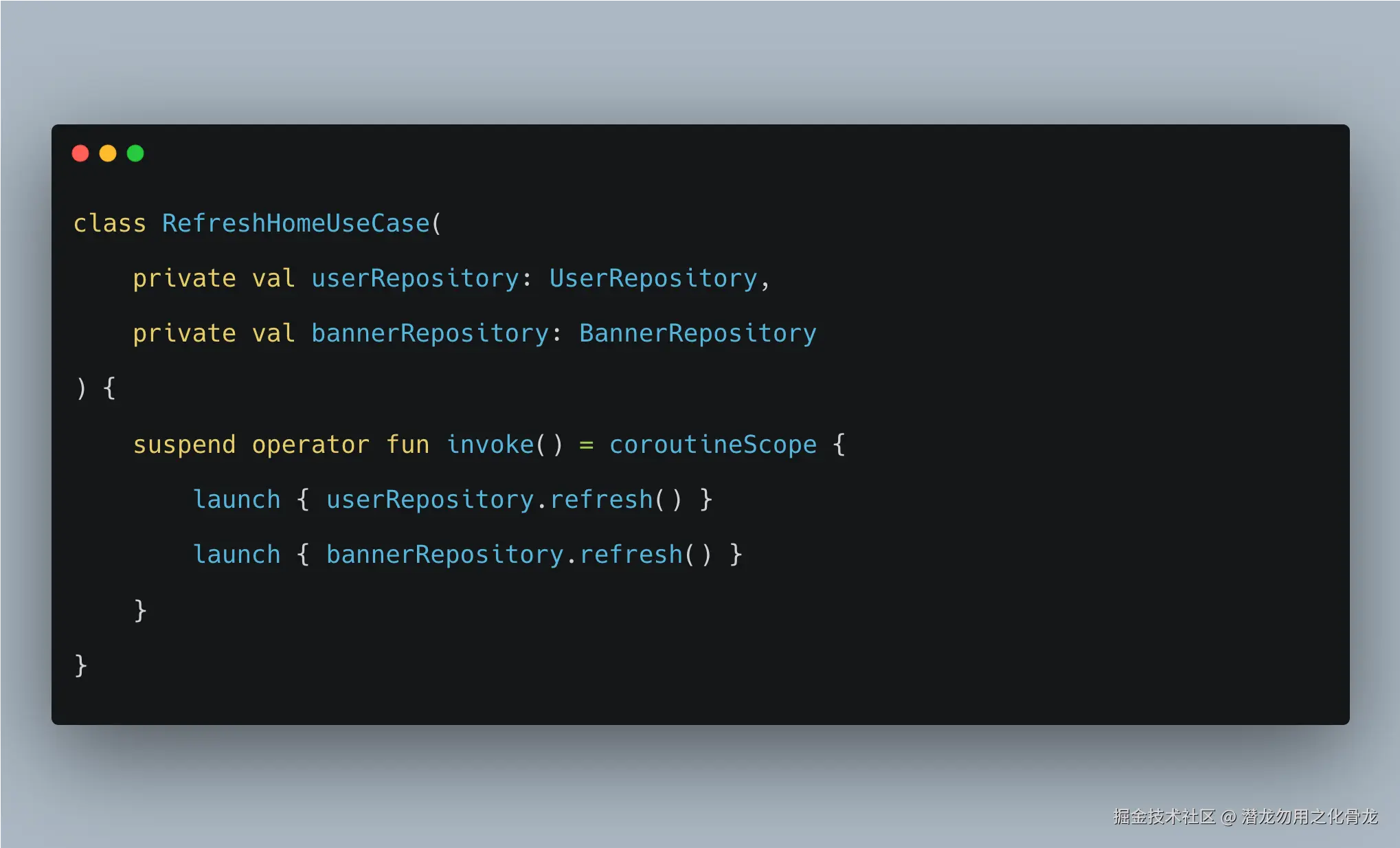
这里 launch 是合理的,因为 UseCase 正在定义一个更高层的业务执行过程。
3. WorkManager / 应用级任务协调者
如果任务天然就应该脱离页面生命周期存在(日志上传、离线同步、大文件下载、数据迁移),那么它本来就不该绑定到 viewModelScope,而应该放在 WorkManager 或 application scope 等组件中。
七、Repository 就绝对不能创建协程吗?
也不是。这里要区分两件事。
情况 1:一次性操作,对外应该暴露 suspend
Repository 内部可以使用 withContext、coroutineScope、supervisorScope、async 等在当前调用链内部组织子任务:
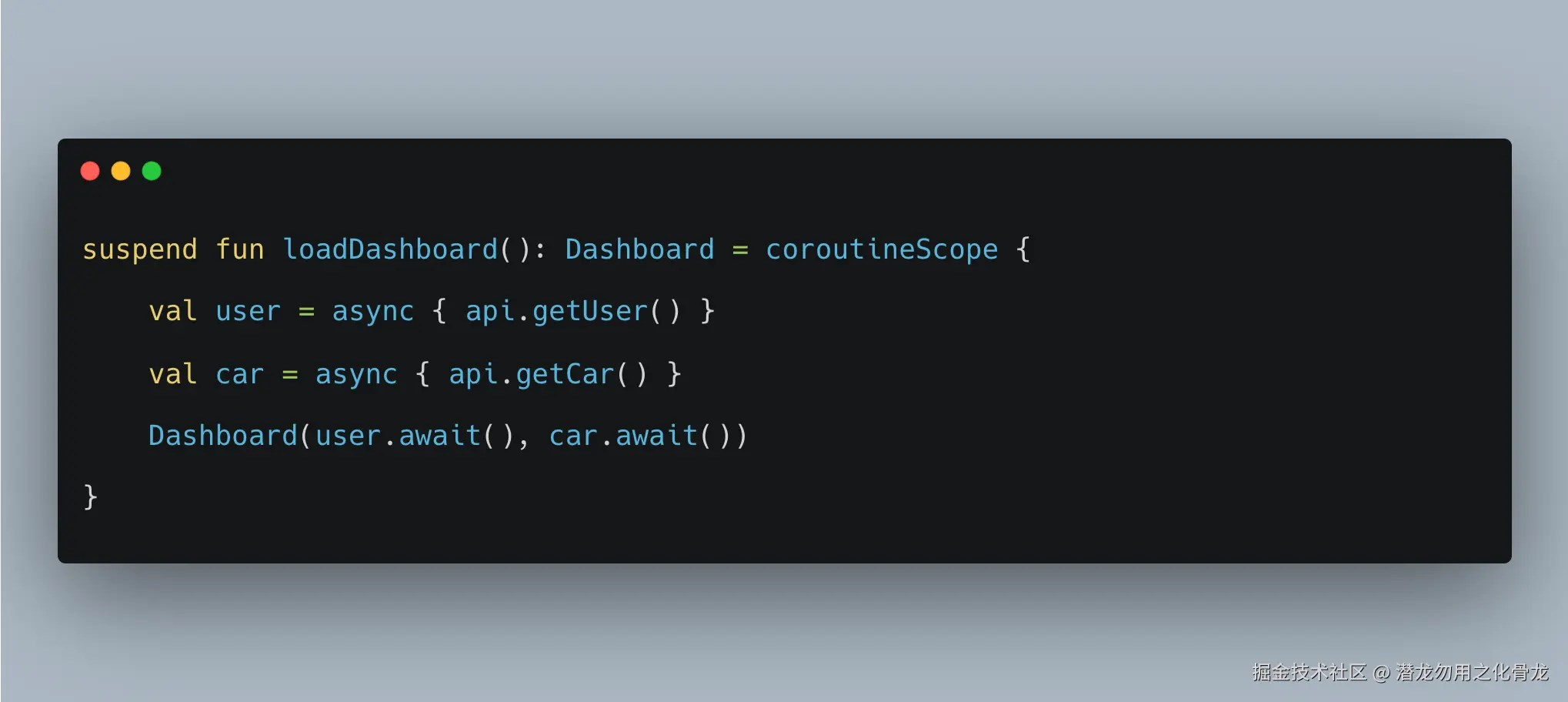
这里 Repository 是在"当前调用链内部组织子任务",而不是偷偷创建一个脱离调用方的顶层任务。这两者差别非常大。
情况 2:任务必须比调用方活得更久
这才是 Repository 内部启动协程可能合理的场景,例如用户点击"收藏",希望即使离开页面也尽量完成写入。
这时更准确的设计是:
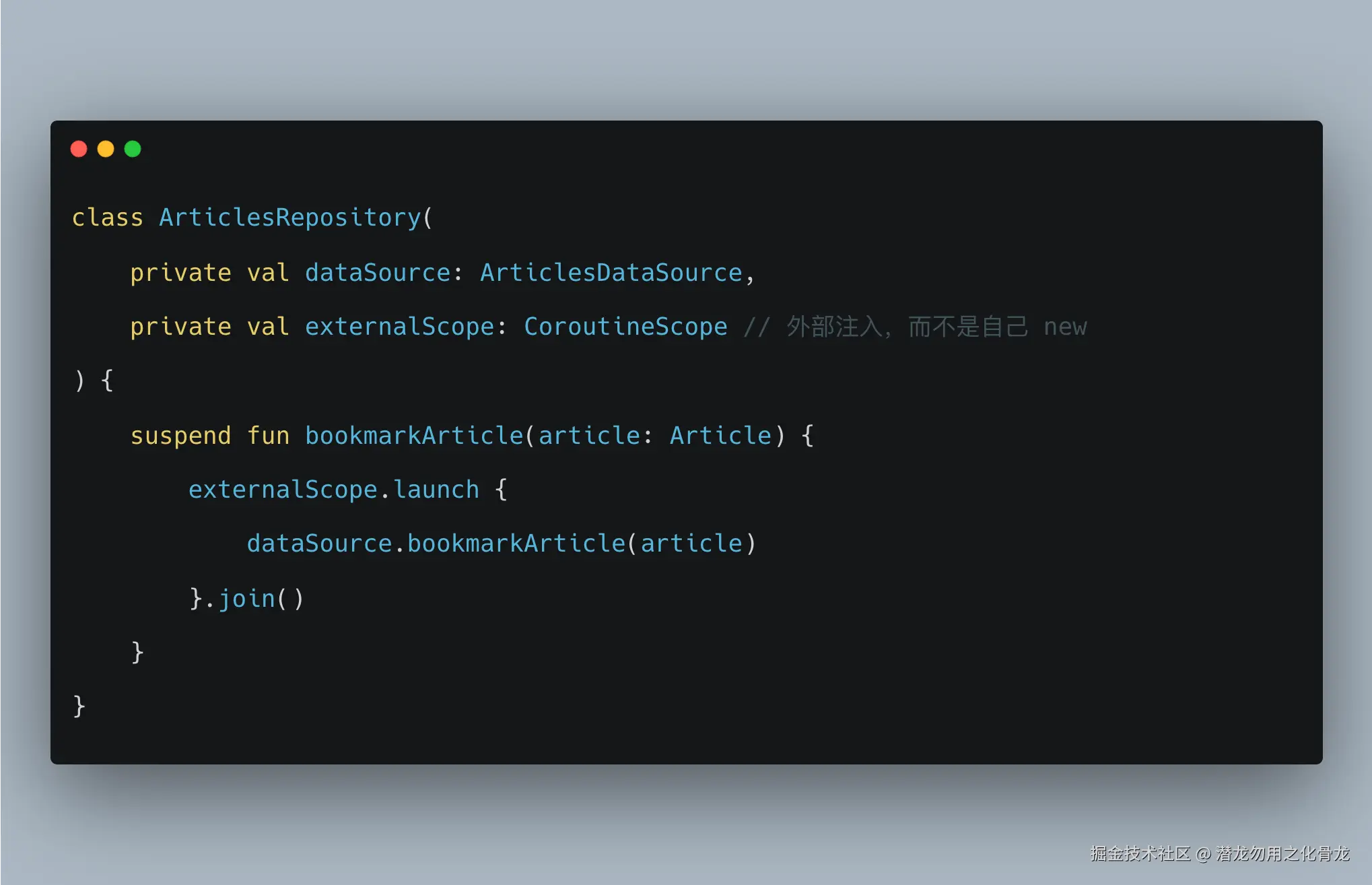
重点不是"终于可以在 Repository 里 launch 了",而是:
- 这是特例,不是默认模式
- 任务为什么需要更长生命周期,是被明确设计过的
- 作用域来自外部注入,而不是 Repository 随便 new 一个
能在 Repository 内部启动协程,不代表"默认就该这么写";它只适合那些明确需要脱离调用方生命周期的工作。
八、团队里可以直接落地的判断规则
在代码评审时纠结 Repository 要不要自己 launch,可以直接问 4 个问题:
问题 1:这是一次性操作,还是持续数据源?
一次性操作 → 优先 suspend fun;持续数据源 → 优先 Flow。
问题 2:谁最适合决定它的生命周期?
页面相关 → ViewModel;业务动作入口 → UseCase;脱离页面的后台任务 → WorkManager / application scope。如果答案不是 Repository,那 Repository 就不该默认自己 launch。
问题 3:调用方需不需要知道它何时完成、是否失败?
只要答案是"需要",那内部 launch 通常就不是好主意。一旦内部 launch,完成与失败边界就会立刻变模糊。
问题 4:这个任务是否必须活得比调用方更久?
不需要 → suspend fun;需要 → 才考虑外部注入长生命周期 scope 或后台任务框架。
九、比较稳的团队约定
- Repository 对一次性操作默认暴露
suspend fun - Repository 对持续数据默认暴露
Flow - 协程的启动通常由 ViewModel / UseCase / WorkManager 决定
- Repository 内部可以用
coroutineScope/withContext组织实现,但不要默认偷开顶层launch - 只有当任务明确需要脱离调用方生命周期时,才考虑注入外部长生命周期
Scope
这样做的好处:生命周期归属清晰、取消语义清晰、异常传播清晰、完成时机清晰、分层职责更稳定。
十、总结
现代 Android 推荐 Repository 暴露
suspend fun,不是因为launch不能用,而是因为一次性数据操作的生命周期,默认应该由调用方而不是 Repository 来控制。