总体介绍
SHAP(SHapley Additive exPlanations)是一种基于博弈论的模型可解释性方法,用来量化 "每个特征对预测结果的贡献大小",既能做全局特征重要性,也能对单个样本做精细化归因。
一、核心思想
把模型预测看成一场 "合作博弈":
- 特征 = 玩家
- 模型输出(预测值)= 总收益
- SHAP 值 = 每个玩家应得的公平贡献
公式(加性归因):

- SHAP>0:把预测往高推(正贡献)
- SHAP<0:把预测往低拉(负贡献)
- 所有 SHAP 之和 = 预测值 − 基准值
医疗例子(脓毒症风险预测):
- 基准风险:0.30
- 乳酸 = 4.2 → SHAP=+0.25(高乳酸推高风险)
- 尿量正常 → SHAP=−0.08(尿量好拉低风险)
- 最终风险:0.30+0.25−0.08=0.47
二、能解决什么问题(为什么用 SHAP)
- 黑盒模型解释:XGBoost、LightGBM、NN 等复杂模型,不再 "只给结果不给理由"。
- 全局特征重要性:哪些变量整体驱动脓毒症 / 病原体预测(如乳酸、SOFA、体温)。
- 单样本归因:为什么这个患者被评为高风险?每一项指标各影响多少。
- 特征交互与非线性:能看到 "乳酸升高时,SOFA 的影响变大" 这类交互效应。
- 模型 Debug:发现异常样本、特征漂移、标注错误。
三、常用 SHAP 图(论文里最常见)
1)Summary Plot(全局重要性 + 分布)
- 纵坐标:特征(从上到下重要性递减)
- 横坐标:SHAP 值(正负 = 贡献方向)
- 颜色:特征值大小(如红色 = 高乳酸,蓝色 = 低乳酸)
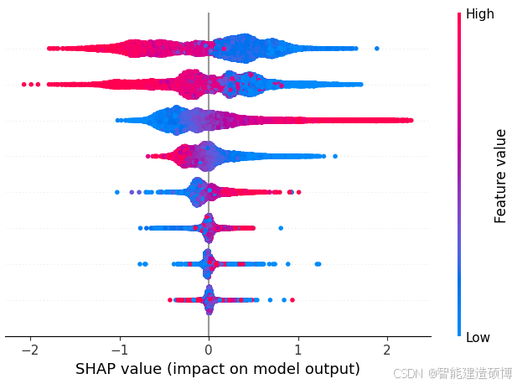
解读:乳酸是最重要特征;高乳酸推高风险,低乳酸拉低风险。
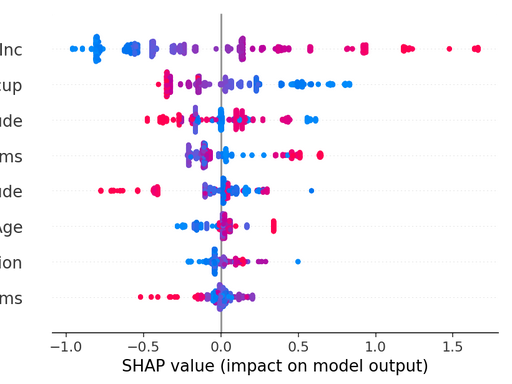
2)Dependence Plot(单个特征与输出关系)
- X 轴:特征值(如乳酸)
- Y 轴:SHAP 值
- 散点:每个样本
解读:乳酸 > 2 后,SHAP 值快速上升(非线性效应)SHAP。
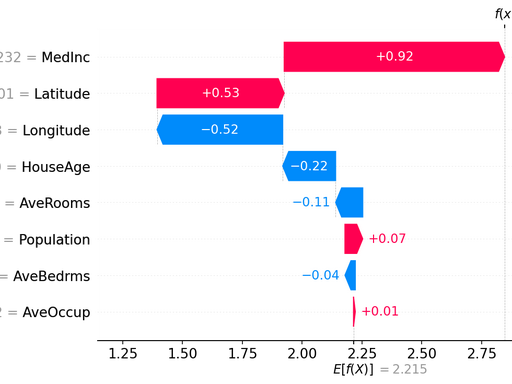
3)Force Plot(单样本归因,最直观)
- 基准值 → 各特征贡献(红推高、蓝拉低) → 最终预测
解读:该患者因 "乳酸高 + SOFA 高" 被推到高风险SHAP。
4)Bar Plot(全局重要性排序)
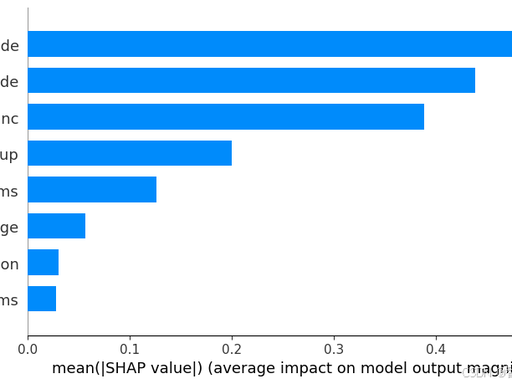
解读:直接看 top 特征,适合论文结果图。
实际操作
由于害怕污染当前LLM环境,新建一个conda虚拟环境进行shap分析
conda create -n shap_analysis \
python=3.11 \
numpy=1.26 \
pandas=2.2 \
scikit-learn \
xgboost=1.7.6 \
matplotlib \
-c conda-forge
conda activate shap_analysis
pip install shap==0.48.0一、基础概念类(必问,所有人都会被问到)
这类问题考察你有没有真正理解 SHAP 是什么,不会深挖公式,侧重通俗解释。
1. 简单介绍一下什么是 SHAP?
回答 : SHAP 全称是沙普利加性解释,是基于博弈论的模型可解释性方法。核心思路是把模型的预测结果,公平地拆分到每一个输入特征上,量化每个特征对最终预测的贡献大小和方向。 简单来说,它以全体样本的平均预测值作为基准值,每个特征都会产生一个 SHAP 值:SHAP 为正代表该特征拉高预测结果,为负代表拉低结果,所有特征 SHAP 值相加,就等于单样本预测值与基准值的差值。我在脓毒症预测、病原体分类项目中,用它解释模型决策逻辑。
2. SHAP 值的正负分别代表什么含义?结合你的项目举例
回答: 以我做的脓毒症风险二分类为例,模型输出是患病概率。
- SHAP 值 > 0:该特征提升患病风险,比如高乳酸、高 SOFA 评分,会让模型判定风险更高;
- SHAP 值 < 0:该特征降低患病风险,比如尿量正常、体温正常,会拉低患病概率。
3. 你为什么选择用 SHAP,而不是传统的特征重要性?
回答 : 传统方法(比如 XGBoost 的增益、基尼系数)只能得到特征重要性排序 ,有两个明显缺陷:一是没有贡献方向 ,不知道特征是正向还是负向影响结果;二是无法做单样本解释,只能看全局。 而 SHAP 不仅能做全局特征排序,还能分析单个样本的决策原因,同时体现特征影响的方向、非线性关系,对于医疗这种高风险场景,可解释性更强,也更符合临床分析的需求。
4. 你在项目里用 SHAP 做了哪些分析?画了哪些图?各自作用是什么?
(结合你的任务 1 / 任务 4 作答,高频题) 回答模板(适配你的脓毒症项目): 我主要做了四类可视化分析:
- Summary 图 :全局特征重要性图,一方面排序找出对脓毒症预警、病原体预测最关键的临床指标,另一方面通过颜色分布,看出特征取值和 SHAP 值的关联;
- 依赖图 (Dependence Plot):分析单个特征和模型输出的非线性关系,比如观察乳酸浓度达到多少后,患病风险会显著上升;
- 力图 (Force Plot):针对单个患者样本做归因,直观展示该患者为什么被模型判定为高风险 / 某类病原体,逐条拆解指标贡献;
- 多分类任务中,我还会针对每个类别单独计算 SHAP,区分不同病原体对应的关键特征差异。
二、原理 & 理论类(中等难度,考察基本功,学过可解释性必问)
面试官会试探你是不是只会调包,不懂底层逻辑,重点掌握核心公理、来源、基础公式。
1. SHAP 的理论来源是什么?沙普利值的核心思想?
回答 : SHAP 基于博弈论中的沙普利值 。把整个模型预测看作一场多人合作博弈,每一个特征都是参与者,最终预测结果是总收益。沙普利值的规则是:每个参与者的收益,等于它在所有合作组合下的边际贡献平均值,保证分配公平,这也是 SHAP 解释结果具备一致性、公平性的原因。
2. SHAP 满足哪些公理(性质)?常考 3 个即可
不用背复杂名词,用通俗语言说: 回答: 它主要满足几个关键性质,也是它优于其他解释方法的原因:
- 加性性:最终预测 = 基准值 + 所有特征 SHAP 值之和,结果可拆解、可追溯;
- 一致性:如果一个特征对模型的影响变大,它的 SHAP 值也一定会变大,不会出现矛盾;
- 缺失性:完全不起作用的特征,SHAP 值一定为 0;
- 还有对称性:作用完全相同的两个特征,SHAP 值相等。
面试说前 3 个就足够。
3. 基准值(expected value)是什么?
回答 : 基准值是所有样本在模型上的平均预测值,可以理解为 "无任何特征信息时,模型的默认预测结果"。所有特征的 SHAP 值,都是相对于这个基准值计算的。
4. 为什么说 SHAP 是全局 + 局部兼顾的解释方法?
回答:
- 局部解释:针对某一个样本,拆解每个特征的贡献,回答 "这个样本为什么得到这个预测结果";
- 全局解释:统计所有样本的 SHAP 值,可以得到整体的特征重要性、特征分布规律,回答 "整个模型最依赖哪些特征"。 大部分传统方法只能做全局,部分 LIME 这类方法侧重局部,而 SHAP 两者都能实现。
5. 简单说下 SHAP 的计算思路?(不用写公式)
回答 : 精确计算沙普利值需要遍历特征所有组合,计算量极大。实际工程中一般用近似采样:随机屏蔽部分特征,对比 "有该特征" 和 "无该特征" 的预测差异,多次采样取平均,最终得到该特征的 SHAP 值。
三、实操 & 项目落地类(最高频!结合你的代码 / 项目提问,重中之重)
面试官最喜欢结合你实际做的内容 提问,考察动手能力、踩坑经验,一定要结合你的脓毒症、多分类任务回答。
1. 你用的是哪个 SHAP 解释器?为什么选它?(树模型 / 深度学习通用区分)
场景 1:你用了 XGBoost/LightGBM(树模型,你的基线模型) 回答 : 我用的是 TreeExplainer。因为我的基线模型是树模型,这个解释器是专门为树模型优化的,计算速度极快,而且是精确计算,不需要采样近似,结果更稳定。
场景 2:你用了 LLM / 神经网络 回答 : 针对大模型、神经网络,我使用 KernelExplainer 通用解释器,它不限制模型结构,适用于所有黑盒模型;缺点是依赖采样,样本量大的时候计算会比较慢。
2. 计算 SHAP 时遇到过什么问题?怎么解决的?(考察排坑能力)
整理项目中真实高频问题,选 1-2 个作答:
问题 1:样本量大,计算速度慢
回答: 医疗数据集样本量较大,直接全量计算耗时很久。我的解决办法:一是树模型优先用 TreeExplainer 提速;二是对大模型 / 通用模型,适当减少采样次数,或者抽取部分代表性样本做可视化分析。
问题 2:多分类任务(你的 Task4 病原体预测)SHAP 如何处理?
回答 : 多分类任务中,SHAP 会为每一个类别单独输出一组 SHAP 值。我在病原体 8 分类任务里,分别查看每个菌种对应的特征贡献,比如区分革兰氏阳性菌、阴性菌各自依赖哪些临床指标,以此分析不同病原体的模型决策差异。
问题 3:特征取值极端、异常值干扰 SHAP 可视化
回答: 部分临床指标存在极端异常值,会让散点图分布混乱。我做了简单的截断处理,或者单独标注异常样本,保证可视化结果可读。
3. 在你的医疗任务中,SHAP 分析得出了哪些有价值的结论?(核心项目亮点)
分两个任务准备,直接背诵
(1)Task1 脓毒症早期预测(二分类)
回答 : 通过 SHAP 分析,我们验证了临床常识:乳酸、SOFA 评分、心率是模型早期预警最核心的特征。同时依赖图发现,乳酸存在明显阈值效应,当数值超过临床临界值后,SHAP 值快速上升,模型会显著判定为高风险,和临床诊断经验相吻合,也证明模型学到了有效医学规律,而非噪声。
(2)Task4 病原体多分类
回答: 多分类 SHAP 结果显示,不同病原体对应的关键特征有明显区分:比如白细胞、C 反应蛋白对革兰氏阴性菌预测贡献更大;部分体温、用药特征对真菌、肠球菌区分度更高。这也帮助我们理解模型是依靠哪些临床指标区分不同病原体的。
4. 你用 SHAP 做分析,最终服务于什么目的?(拔高,体现项目思考)
回答 : 一方面是模型解释 ,把黑盒模型的决策逻辑可视化,提升模型可信度,这在医疗 AI 中尤为重要;另一方面是模型迭代,通过 SHAP 发现低贡献、冗余特征,辅助特征筛选,精简模型;同时也能反向验证模型是否符合临床知识,排查模型是否学到虚假关联。
四、对比辨析类(中等偏难,区分度题)
面试官喜欢横向对比,考察你知识面广度。
1. SHAP 和 LIME 有什么区别?
回答: 两者都是主流可解释性方法,核心区别:
- 理论基础:SHAP 基于博弈论沙普利值,理论严谨,结果具备公平、一致等数学性质;LIME 是局部线性近似,启发式方法,理论基础较弱;
- 解释范围 :SHAP 天然支持全局 + 局部解释;LIME 主打单样本局部解释,全局解释效果差;
- 稳定性:LIME 依赖随机采样,多次运行结果可能不一致;SHAP 结果更稳定;
- 速度:小样本下 LIME 更快,树模型专用 SHAP 速度也非常快。
2. SHAP 和模型自带特征重要性(XGB/GBDT)对比?
前面基础题有简略版,这里拓展: 回答:
- 传统特征重要性只看特征对整体损失的降低程度 ,只有排序,无方向、无单样本解释;
- SHAP 能明确特征是正向 / 负向影响,支持单样本归因,还能分析非线性、特征交互;
- 两者可以互补:先用传统重要性快速粗筛特征,再用 SHAP 做深度解读。
3. 线性模型需要用 SHAP 吗?
回答: 线性模型本身系数就代表特征权重和方向,理论上系数就是最简解释。但如果特征之间存在相关性,系数解读会有偏差;这种场景下,SHAP 依然可以用来做更公平的归因。一般线性模型很少额外用 SHAP,复杂黑盒模型才是它的主要应用场景。
五、拔高拓展题(学霸 / 学硕面试、导师深挖,酌情准备)
1. 什么是交互 SHAP?(高阶)
回答 : 普通 SHAP 只计算单个特征的独立贡献,交互 SHAP 可以量化两个特征组合在一起产生的额外影响。比如在我的项目中,"高乳酸 + 高心率" 组合,两者共同作用对风险的影响,大于各自单独影响之和,这就是特征交互效应。
2. SHAP 有什么局限性?
回答:
- 精确计算沙普利值复杂度很高,大模型、高维数据下计算成本大,大多只能用近似采样;
- 对高度相关的特征,SHAP 值会被分摊,解读难度上升;
- 它是事后解释方法,无法从训练阶段约束模型,只能解释已训练好的模型。
3. 针对时序数据 / 大模型,SHAP 有什么适配难点?(你有 LLM 任务,必看)
回答 : 对于大语言模型、时序医疗数据,特征维度极高,逐特征计算 SHAP 开销巨大。行业内一般会结合特征降维、分块采样来优化,也会结合模型结构做定制化解释器。
六、面试应答小技巧(加分项)
- 紧扣你的项目 :所有问题优先结合脓毒症、病原体预测、LLM / 树模型作答,不要空谈理论;
- 分层作答:基础题通俗讲(面向临床 / 入门视角),原理题简单提理论(证明你懂底层);
- 主动引导亮点:问到收获时,主动说 "SHAP 让模型解释贴合临床知识",这是医疗 AI 项目最大加分点;
- 不会就坦诚:遇到高阶题(如公式、复杂变种),可以说:"这个变种我暂时没有深入研究,目前主要用基础 SHAP 完成项目解释,后续计划继续学习"。
快速背诵清单(临场突击)
- 核心定义:博弈论沙普利值,拆分特征贡献,正负代表影响方向,兼顾全局 + 局部;
- 选型:树模型用 TreeExplainer(快、精确),黑盒 / 大模型用 KernelExplainer;
- 图表:Summary(重要性)、依赖图(非线性)、Force 图(单样本归因);
- 项目结论:关键临床指标符合医学常识,发现特征阈值效应;
- 对比:优于传统特征重要性(有方向、可单样本),比 LIME 理论更严谨、结果更稳定。