从需求说起
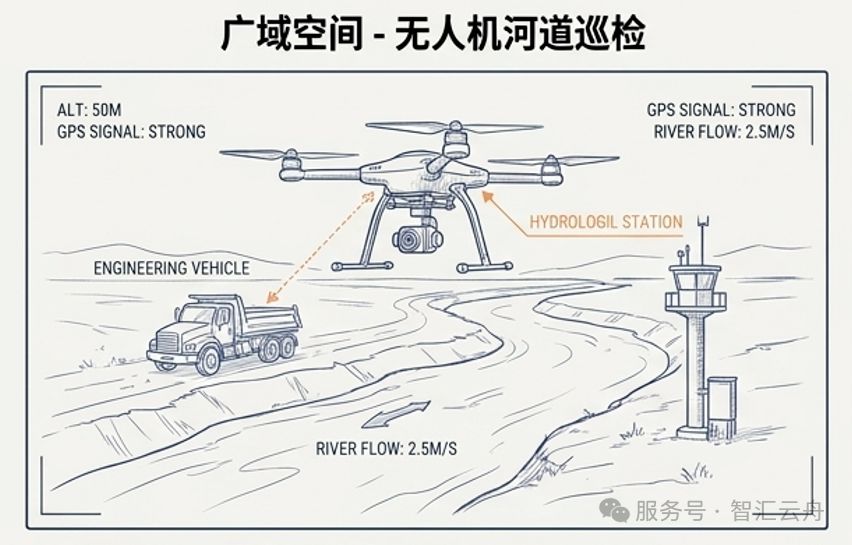
在执行某次无人机河道巡检保障任务的时候,用户指着无人机的视频画面,想搞清楚正在作业的工程车距离刚才看到的水文站有多远。我们结合现场情况快速判断:无人机已飞离四分钟左右,根据飞行速度,飞行里程大概三四公里,再结合画面中工程车距离当前位置大约500米,于是给出了一个不到5KM的人脑评估结果。
很快,更多巡检中的问题接踵而来,而智汇云舟也一直在紧密的配合着巡检工作。但刚才那个问题仍在心头挥之不去:我们是否可以用视频完成定位与测量工作。
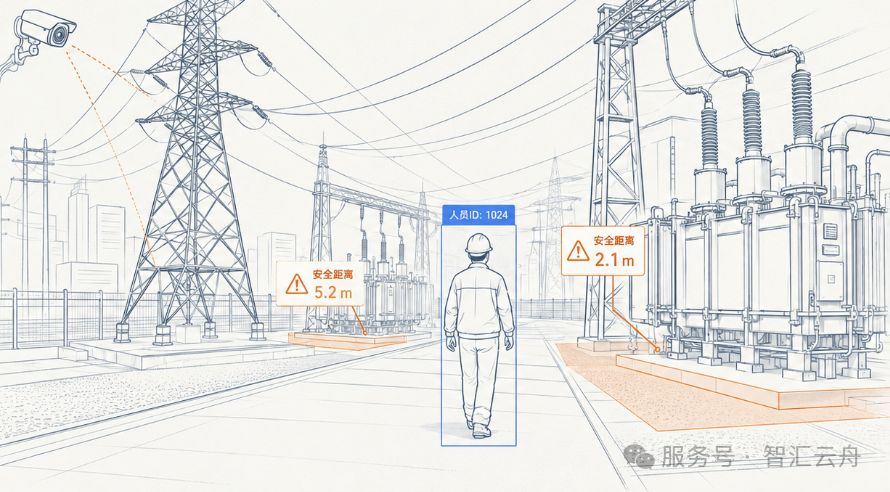
再后来,又在一个完全不同的场景里,我们遇到了同样类似的问题。这一次是电力场站。
在变电站场景中,尤其是高压、特高压变电站,人员进场是一件非常严肃、非常危险的工作。工作要严格依据"作业票"规定的区域和流程完成作业。即便如此,事故依然难以杜绝。为了精确且实时掌握人员的位置、运动轨迹,避免误入危险区域,用户尝试了很多种方案。
最容易被想到的是携带定位设备,然而在高压高磁环境中,甚至发生过定位装置自燃现象,该类方案于是作罢。那么能否基于现场的摄像机,在不使用其他定位辅助的情况下实现基于视频的作业人员定位和行为监测成了新的思考方向。在这之后,用户和我们不约而同的想到了视频孪生引擎下的位置智能。
这一次,需求和技术刚好不期而遇。
位置智能的一次科普
先给个接近官方的定义吧,位置智能是一种以3D视频孪生引擎为基础,面向真实物理世界所提供的一系列空间计算服**务。**所以,LI位置智能不是一个单点功能,而是一系列服务的集合。为了便于理解,我们仅以上面两个案例需求为例,来解释一下位置智能。
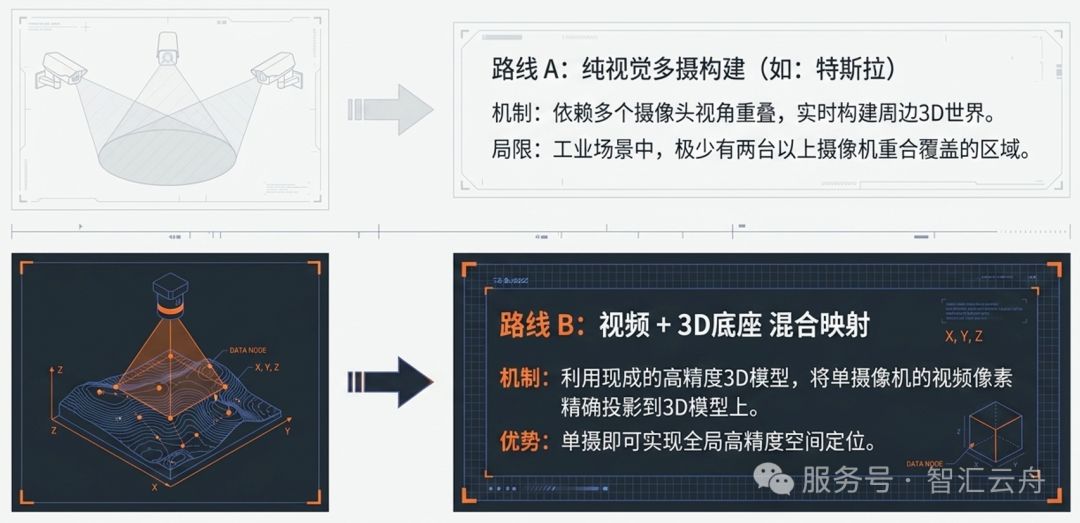
上面的需求其实都共同指向了同一种感知手段------视频。而然,这里存在一个物理悖论,视频的本质只是一系列连续的照片,视频是平面的,它没有深度信息,又该如何定位。幸好,智汇云舟深耕自主可控 3D 引擎领域多年,我们可以向引擎要深度、要位置、要距离。
不同于特斯拉使用多个摄像机来构建车辆周边3D世界的技术方案,云舟采用了视频+3D模型的混合方案。因为在我们的应用场景里,一方面几乎没有两个以上摄像机重合覆盖的区域,另一方面我们却可以获得高精度的3D模型。
基于AI能力,云舟实现了摄像机的自动化标定,解决了摄像机的像素精确投影到3D模型上,实现了像素坐标到空间坐标的映射关系,画面中的任意一个像素都有一个唯一的经度、纬度、高度坐标与之对应。所以,当画面中出现一个人的时候,我们利用AI检测算法把人员所在像素计算出来,并通过LI位置智能服务计算出人员的空间坐标位置、方向、速度。从而实现了基于单画面的视觉定位、测量。上面案例中的需求也就自然解决了。
需求来临时的突然涌现,而是厚积薄发后的自然发生
其实,我们并不是一开始就想着要做位置智能。
最初的最初,我们是在做3D视频可视化平台,其定语是视频+可视化。为了让视频的3D可视化容量更大,算法支持更友好,智汇云舟在十年前自主研发出孪舟引擎。在数字孪生颜值即正义的初级阶段,我们顶着压力没有去卷效果,而是始终在研究如何把面向视频的引擎做好,如何把面向视频的重建算法做好。
打造一款面向视频孪生的自主可控3D引擎,业界没有参考,把和视频相关的接入、解码、渲染、AI计算等服务融入引擎的各个层级没有先例。历史上还没有一个3D引擎将视频置于如此重要的位置。
同样,做视频的空间重建算法也经历了几代技术的迭代。有些算法利于可视化而不利于计算,有些算法计算友好却又逊于可视化效果。直到我们引入了预训练大模型,我们突然发现算法在各方面都到达了一个优秀的平衡。而此时我们距离LI位置智能只有一步之遥。原来过往的所有努力和积累下的数据资源,都在大模型被激活的那一刻获得了应有的肯定。
位置智能只是开始,空间智能正在路上
如果说之前我们的平台大部分功能是面向人,为人提供可视化服务,那么**位置智能是首个面向非人类用户,面向AI和智能体的一组服务。**它不直接提供可视化界面,而是提供空间计算结果,它输出的是一组数据结构,这更适合AI去阅读和理解,而不是人类。这个变化某种程度上也代表了云舟产品哲学的一次升级。
从可视到可计算,从位置智能到空间智能,从服务于人到服务于AI。位置智能回答了空间中目标在哪里的问题,而空间智能将解决空间理解的问题。依托孪舟引擎这款自主可控 3D 引擎,位置智能,只是正在书写的空间智能巨著的第一篇序章。
做AI友好型的空间智能产品,我们已经在路上。