目录
注意事项:sessionid 与挑战初始化
本题代码中的 sessionid 需要替换为你自己登录 SpiderDemo 后 浏览器 Cookie 中的值。不同用户、不同登录会话的 sessionid 都不一样,并且可能会过期;示例代码里的 paste-your-sessionid-here 只是占位内容,实际测试时不能直接照抄。
另外,SpiderDemo 题目在浏览器提交答案后,会清理当前会话里的挑战状态。此时如果不刷新页面、不重新进入题目初始化流程,直接用 Python 请求数据接口,可能会返回 404、need_init 或 请先初始化 之类的提示。浏览器中 Ctrl + F5 强制刷新可以解决,本质上就是重新触发页面和挑战状态初始化;代码里也可以在正式请求接口前,先访问题目页或初始化接口,确保当前 sessionid 对应的挑战状态已经准备好。
一、分析
今天继续挑战 SpiderDemo:第1题------请求头检测挑战。这个题目容易被误判为 "控制台检测",但更准确地说,它校验的是请求行为:DevTools 的 Disable cache 会改变请求头;而脚本请求如果和浏览器请求表现不一致,也需要继续排查底层请求特征差异。
老规矩,按下 F12 打开 浏览器调试工具,切换到 Network 面板,选择下方的 Fetch/XHR 选项。接着点击页面上的页码,切换不同页的数据。此时可以观察到,翻页请求可能会变红并返回 400。这个现象第一眼很容易被理解成打开 控制台就会被检测,但先不要急着下结论,需要继续对比正常请求和异常请求的差异。
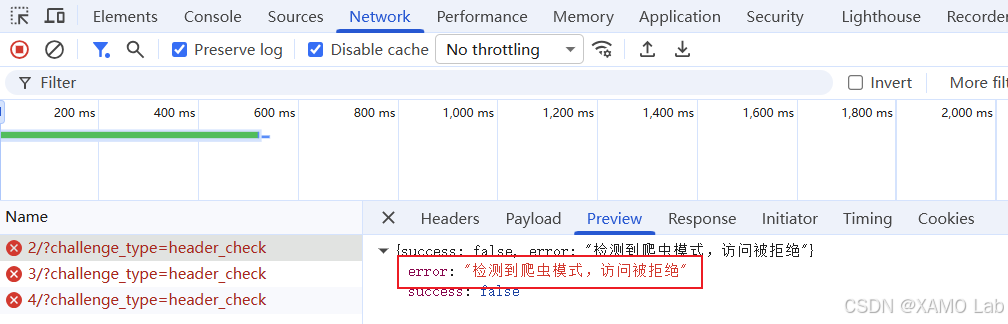
返回内容提示存在请求校验,但这里不应该直接理解成网站在检测 控制台本身。更稳妥的做法是先绕开 DevTools 的影响,用 SunnyNet、Fiddler、Charles 等抓包工具观察一次未打开 DevTools 时的正常请求,再和打开 DevTools 后的异常请求做对比。这样可以先判断问题到底来自 JS 反调试、请求头变化,还是更底层的请求特征差异。
关闭浏览器开发者工具,重新刷新页面,点击页码翻页,查看 SunnyNet 是否能抓到正常的请求包。实际测试发现,不打开 DevTools 时翻页请求可以正常返回,说明问题不一定来自控制台被打开这个动作本身。
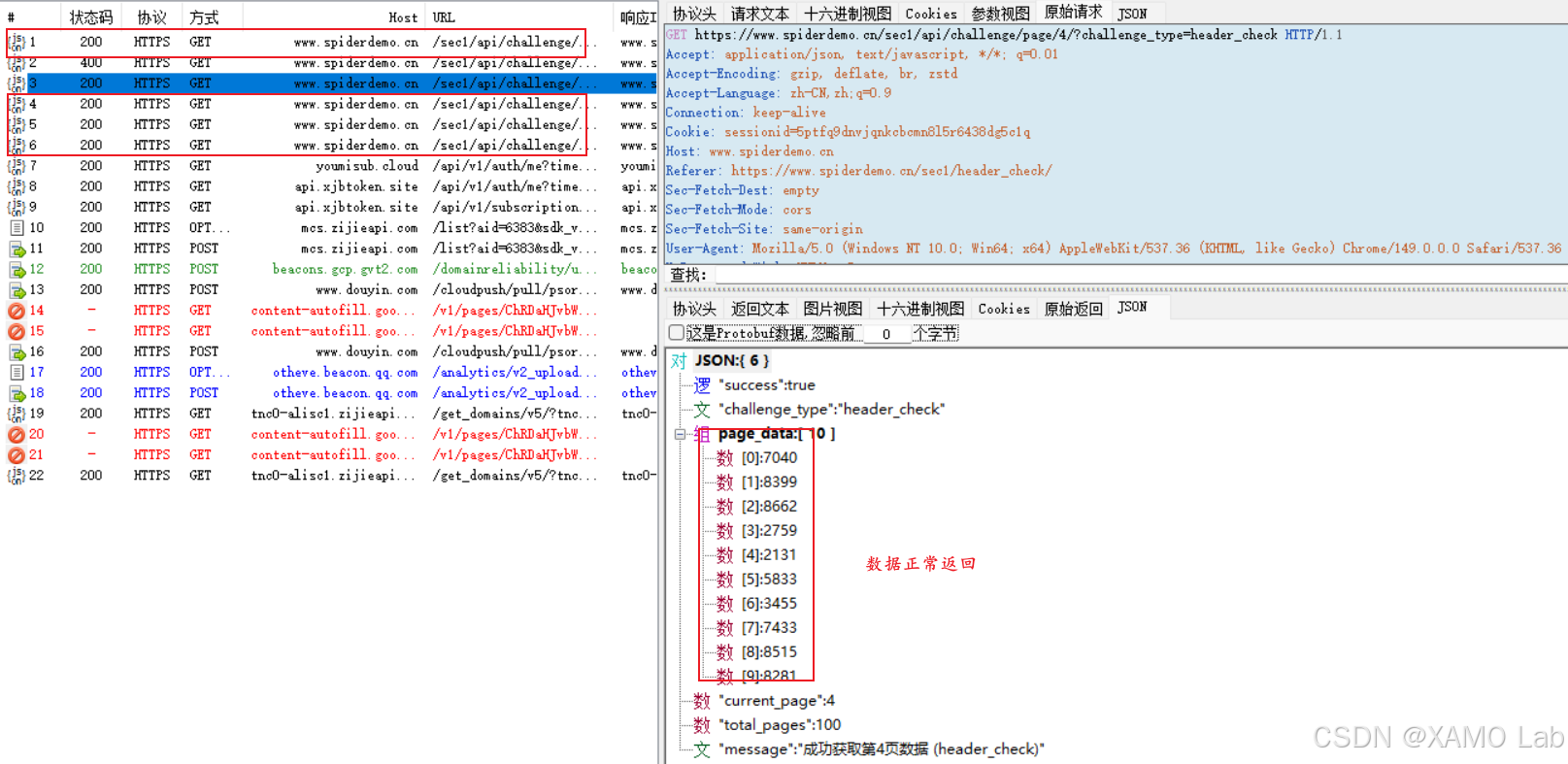
其实到这里已经可以直接分析正常请求了。但为了把原因讲清楚,我们继续对比正常请求和异常请求。重新打开浏览器开发者工具,翻页通过 SunnyNet 对比后发现,异常请求里多了两项缓存控制头:Pragma: no-cache 和 Cache-Control: no-cache。这两个字段并不是控制台打开的直接标记,而是 Chrome DevTools Network 面板中 Disable cache 选项带来的请求行为变化。
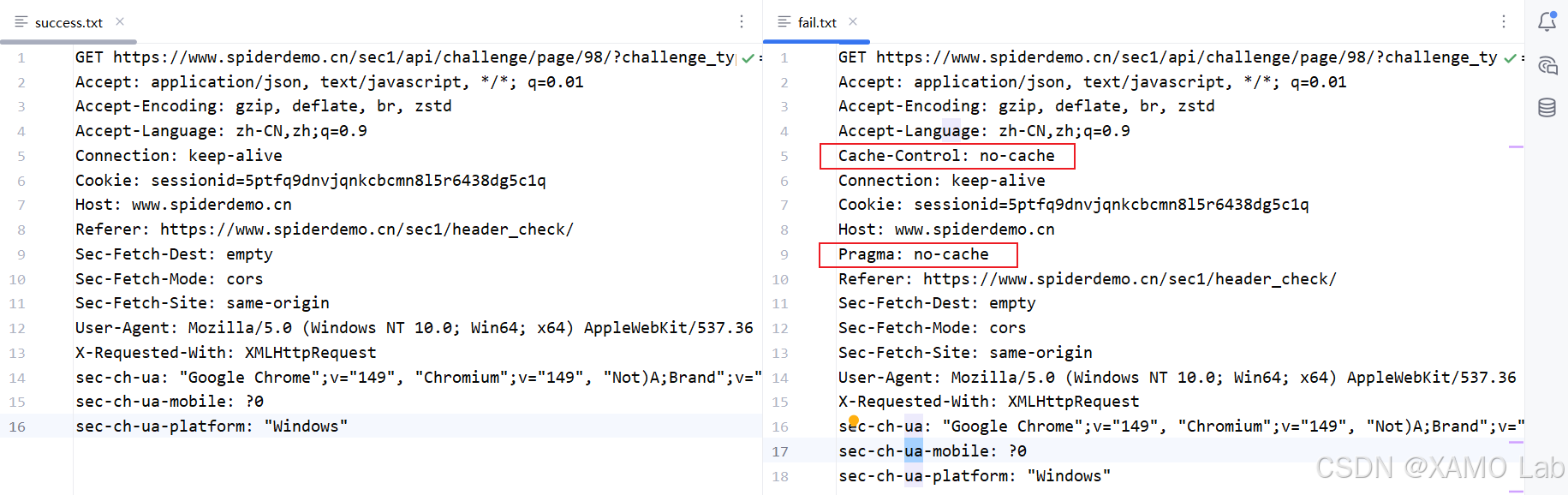
这里的关键点是:Disable cache 只在 DevTools 打开时生效 。当它被勾选后,Chrome 不仅会忽略缓存,还会在请求中附加 Pragma: no-cache 和 Cache-Control: no-cache。因此,真正触发服务端异常的不是 F12 本身,而是这个缓存开关改变了请求头。
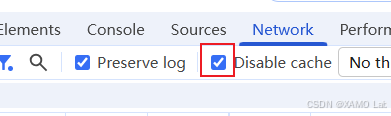
这意味着浏览器会明确告诉服务端:本次请求不要使用缓存。对普通网站来说这通常没问题,但本题服务端会校验这类缓存控制头,一旦请求中出现 Pragma: no-cache 或 Cache-Control: no-cache,就可能返回异常数据。
取消勾选 Disable cache,然后重新刷新页面并再次翻页,发现即使 DevTools 仍然打开,请求也能正常返回。由此可以确认:这里绕过的不是控制台检测,而是 Disable cache 导致的缓存请求头校验问题。
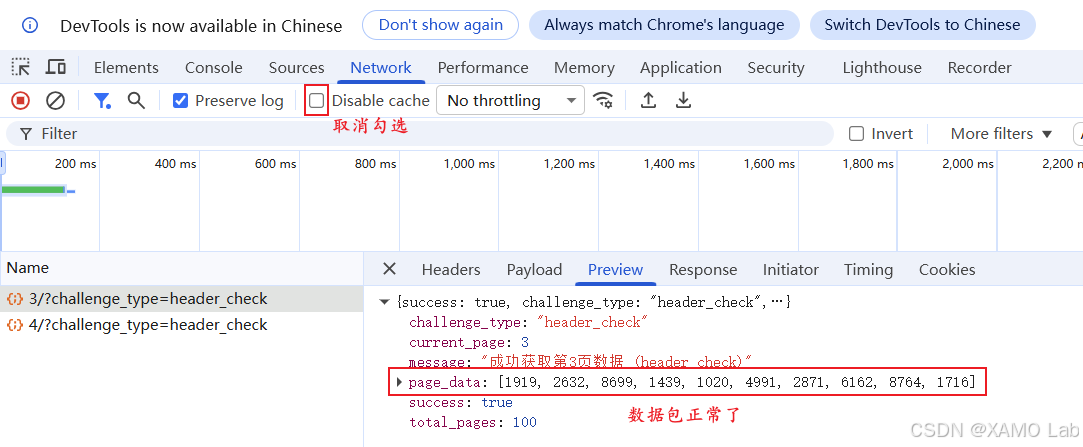
抓包正常后,我们就可以开始仔细分析数据包了。查看请求方式和 URL,发现是 GET 请求,除了 challenge_type=header_check 之外没有额外加密参数;请求头也不复杂,但要注意不要把异常请求中的 Pragma 和 Cache-Control 一起复制进 Python 代码:
python
GET https://www.spiderdemo.cn/sec1/api/challenge/page/19/?challenge_type=header_check HTTP/1.1
Host: www.spiderdemo.cn
Connection: keep-alive
sec-ch-ua-platform: "Windows"
X-Requested-With: XMLHttpRequest
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome......
Accept: application/json, text/javascript, */*; q=0.01
sec-ch-ua: "Google Chrome";v="141", "Not?A_Brand";v="8", "Chromium";v="141"
sec-ch-ua-mobile: ?0
Sec-Fetch-Site: same-origin
Sec-Fetch-Mode: cors
Sec-Fetch-Dest: empty
Referer: https://www.spiderdemo.cn/sec1/header_check/
Accept-Encoding: gzip, deflate, br, zstd
Accept-Language: zh-CN,zh;q=0.9
Cookie: .......接下来,我们可以右键抓取的数据包,选择 Copy ⇒ Copy as cURL (bash),复制到 https://curlconverter.com/ 转换为 Python 代码,然后在 PyCharm 中进行请求测试。结果发现返回的数据仍然是错误的,如下图所示:
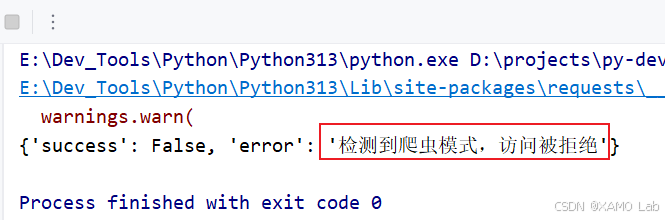
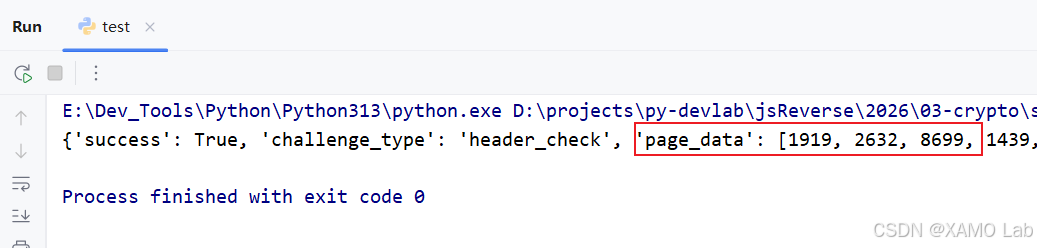
如果已经去掉 Pragma、Cache-Control 这类异常缓存头,参数也没有加密,但用 Python 的 requests 仍然拿不到正确数据,就不要马上断定一定是 TLS 指纹问题。更稳妥的判断是:脚本请求与浏览器请求仍然存在某些请求特征差异,可能是 TLS 指纹,也可能是请求头顺序、默认头处理、HTTP 连接行为等。这时可以先换用不同 HTTP/TLS 实现的请求库测试。这里改用 httpx 后可以正常获取数据,如下图所示:
紧接着继续验证:使用 curl_cffi 这类更贴近浏览器请求特征、并支持浏览器指纹模拟的库,也能成功请求并拿到正确数据:
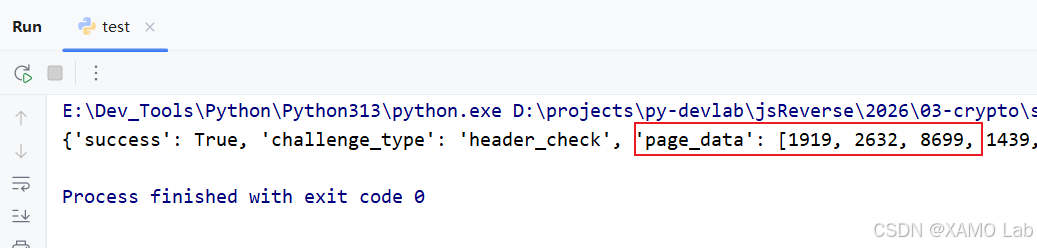
二、完整代码实现
python
# -*- coding: utf-8 -*-
"""
@File : solve.py
@Author : XAMO Lab
@Date : 2026/6/10 21:17
@Blog : https://blog.csdn.net/xw1680
@Tool : PyCharm
@Desc : SpiderDemo challenge 01 header check solution.
"""
import json
import sys
from concurrent.futures import ThreadPoolExecutor, as_completed
from pathlib import Path
from typing import Any
import httpx
from loguru import logger
CHALLENGE_TYPE = "header_check"
PLACEHOLDER_SESSIONID = "paste-your-sessionid-here"
def setup_logger() -> None:
logger.remove()
logger.add(
sys.stderr,
level="INFO",
colorize=True,
format="<green>{time:HH:mm:ss}</green> | <level>{level:<8}</level> | <level>{message}</level>",
)
def find_repo_root(start: Path) -> Path:
for path in (start, *start.parents):
if (path / ".git").exists():
return path
raise RuntimeError("Cannot find repository root from current file path.")
def load_spiderdemo_sessionid() -> str:
"""Load SpiderDemo sessionid from `.local/spiderdemo.json` under repo root."""
repo_root = find_repo_root(Path(__file__).resolve())
secret_file = repo_root / ".local" / "spiderdemo.json"
if not secret_file.exists():
raise FileNotFoundError(
f"Missing local secret file: {secret_file}. "
"Create it and add your latest sessionid."
)
data = json.loads(secret_file.read_text(encoding="utf-8"))
sessionid = data.get("sessionid", "").strip()
if not sessionid or sessionid == PLACEHOLDER_SESSIONID:
raise RuntimeError(f"Please update sessionid in {secret_file}.")
return sessionid
class HeaderCheckClient:
"""SpiderDemo challenge 01: header check."""
BASE_API_URL = "https://www.spiderdemo.cn/sec1/api/challenge"
TEMPLATE_URL = f"{BASE_API_URL}/page/{{}}/"
INIT_URL = f"{BASE_API_URL}/init/"
PAGE_URL = f"https://www.spiderdemo.cn/sec1/header_check/?challenge_type={CHALLENGE_TYPE}"
def __init__(self, session_id: str, max_workers: int = 10, timeout: float = 20.0):
self.cookies = {"sessionid": session_id}
self.headers = {
"accept": "application/json, text/javascript, */*; q=0.01",
"accept-language": "zh-CN,zh;q=0.9",
"referer": "https://www.spiderdemo.cn/sec1/header_check/",
"sec-ch-ua": '"Google Chrome";v="141", "Not?A_Brand";v="8", "Chromium";v="141"',
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": '"Windows"',
"sec-fetch-dest": "empty",
"sec-fetch-mode": "cors",
"sec-fetch-site": "same-origin",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 "
"(KHTML, like Gecko) Chrome/141.0.0.0 Safari/537.36",
"x-requested-with": "XMLHttpRequest",
}
self.params = {"challenge_type": CHALLENGE_TYPE}
self.max_workers = max_workers
self.timeout = timeout
def warmup(self, client: httpx.Client) -> None:
headers = {
**self.headers,
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8",
"sec-fetch-dest": "document",
"sec-fetch-mode": "navigate",
"sec-fetch-site": "same-origin",
"sec-fetch-user": "?1",
"upgrade-insecure-requests": "1",
}
response = client.get(self.PAGE_URL, headers=headers)
logger.info("Warmup challenge page | status={} | url={}", response.status_code, response.url)
response.raise_for_status()
def init_challenge(self, client: httpx.Client) -> None:
response = client.get(self.INIT_URL, params=self.params)
logger.info("Init challenge | status={} | url={}", response.status_code, response.url)
if response.status_code == 404:
logger.warning("Init endpoint not found, continue with page warmup only.")
logger.debug("Init response body: {}", response.text[:500])
return
if response.status_code >= 400:
self._log_bad_response(response)
response.raise_for_status()
def prepare_challenge(self, client: httpx.Client) -> None:
self.warmup(client)
self.init_challenge(client)
@staticmethod
def _log_bad_response(response: httpx.Response) -> None:
logger.error("HTTP {} | url={}", response.status_code, response.url)
logger.error("Response body: {}", response.text[:500])
@staticmethod
def _needs_init(response: httpx.Response) -> bool:
text = response.text
if "need_init" in text or "请先初始化" in text:
return True
try:
payload = response.json()
except ValueError:
return False
return bool(payload.get("need_init"))
def fetch_page(self, client: httpx.Client, page: int, retry_on_need_init: bool = True) -> int:
response = client.get(self.TEMPLATE_URL.format(page), params=self.params)
if response.status_code >= 400:
self._log_bad_response(response)
if retry_on_need_init and self._needs_init(response):
logger.warning("Challenge state is missing, reinitialize and retry page {:03d}.", page)
self.prepare_challenge(client)
response = client.get(self.TEMPLATE_URL.format(page), params=self.params)
if response.status_code >= 400:
self._log_bad_response(response)
response.raise_for_status()
payload: dict[str, Any] = response.json()
page_data = payload.get("page_data", [])
if not isinstance(page_data, list):
raise ValueError(f"Unexpected page_data type on page {page}: {type(page_data).__name__}")
page_sum = sum(page_data)
logger.info("Page {:03d} | count={} | sum={}", page, len(page_data), page_sum)
return page_sum
def run(self, start: int = 1, end: int = 100) -> int:
logger.info("Start crawling SpiderDemo header check pages {}-{}", start, end)
total = 0
with httpx.Client(cookies=self.cookies, headers=self.headers, timeout=self.timeout) as client:
self.prepare_challenge(client)
total = self.fetch_page(client, start)
concurrent_start = start + 1
if concurrent_start > end:
logger.success("Total sum: {}", total)
return total
with ThreadPoolExecutor(max_workers=self.max_workers) as pool:
futures = {
pool.submit(self.fetch_page, client, page): page
for page in range(concurrent_start, end + 1)
}
for future in as_completed(futures):
page = futures[future]
try:
total += future.result()
except Exception as exc:
logger.error("Page {:03d} failed: {}", page, exc)
raise
logger.success("Total sum: {}", total)
return total
if __name__ == "__main__":
setup_logger()
sessionid = load_spiderdemo_sessionid()
client = HeaderCheckClient(session_id=sessionid)
client.run()运行程序并提交结果如下:
