一、前言
线性代数与微积分是深度学习的两大数学基石,网络运算、梯度下降、参数更新全部依托于此。本文结合理论概念 + PyTorch 代码实操,系统梳理向量、矩阵、范数、矩阵运算、求导、梯度、小批量梯度下降等核心内容,兼顾理论理解与工程落地,适合深度学习入门、算法进阶学习者使用。
二、线性代数核心概念
2.1 向量基础
2.1.1 向量加法
向量加法满足三角形法则 :可类比已知三角形两条边(带方向),求解第三条边,运算时大小与方向同步参与计算。
2.1.2 单位向量与施密特正交化
- 单位向量:对原始向量做缩放,使向量模长等于 1,仅保留方向信息。
- 施密特正交化 :将一组普通向量转换为两两正交的向量组;正交化后通常会做向量单位化,保证所有正交向量长度统一。
2.1.3 范数与正交矩阵
-
F 范数(弗罗贝尼乌斯范数) 针对矩阵设计,计算方式为:矩阵所有元素平方和后开平方根,逻辑和向量模长计算保持一致,是衡量矩阵 "长度 / 大小" 的常用指标。 公式简写:∣∣A∣∣F=∑i∑jaij2
-
正交矩阵
- 核心性质:矩阵内任意两行 / 两列向量内积为 0;矩阵与其转置矩阵的乘积为单位矩阵。
- 特殊拓展:置换矩阵是一类特殊的正交矩阵。
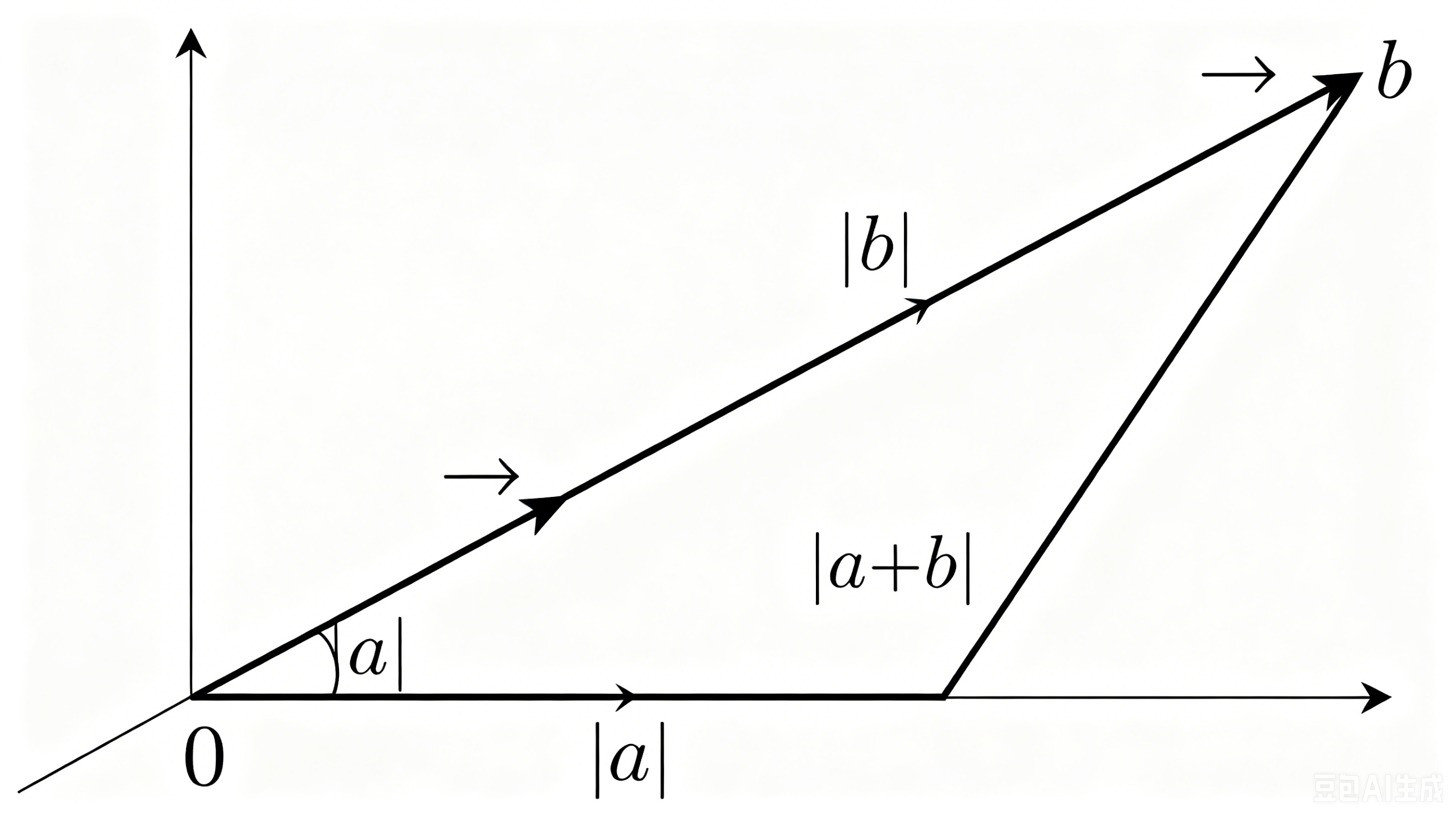 图 1:向量加法三角形法则示意图
图 1:向量加法三角形法则示意图
三、PyTorch 向量与矩阵基础实操
下文代码基于 PyTorch 实现,涵盖张量创建、索引、维度、变形、四则运算等基础操作。
3.1 标量(单元素张量)运算
标量对应数学中的单个数值,是张量的最小单元,支持常规四则运算、幂指运算。
python
import torch
# 创建标量张量
x = torch.tensor([3.0])
y = torch.tensor([2.5])
# 四则运算
print(x + y)
print(x - y)
print(x * y)
print(x / y)
# 幂指运算
print(x ** y)3.2 一维向量(一维张量)
python
# 生成 0~3 的一维向量
x = torch.arange(4)
# 按索引访问元素
print(x[3])
# 获取向量长度
print(len(x))
# 获取张量形状/维度
print(x.shape)3.3 二维矩阵(二维张量)
python
# 生成 0~19 数据,变形为 5行4列 矩阵
stOriginal_Mat = torch.arange(20).reshape(5, 4)
# 矩阵转置
mat_T = stOriginal_Mat.T
# 判断是否为对称矩阵(二次型前置条件)
print(stOriginal_Mat.T == stOriginal_Mat)
# 手动创建矩阵
stDirectCreate_Mat = torch.tensor([[1, 3], [2, 4], [3, 5]])3.4 三维张量
深度学习中常用于存储批次图像、时序数据 ,格式一般为 (批次, 通道, 特征)。
python
# 生成 0~23 数据,变形为 2×3×4 三维数组
stOriginal_Mat3D = torch.arange(24).reshape(2, 3, 4)3.5 矩阵拷贝与数据类型
深度学习主流使用 32 位浮点数(float32) 进行运算,兼顾精度与算力。
python
# 创建 float32 类型矩阵
stSender_Mat = torch.arange(20, dtype=torch.float32).reshape(5, 4)
# 张量深拷贝(等价于 Numpy 的 copy())
stReciver_Mat = stSender_Mat.clone()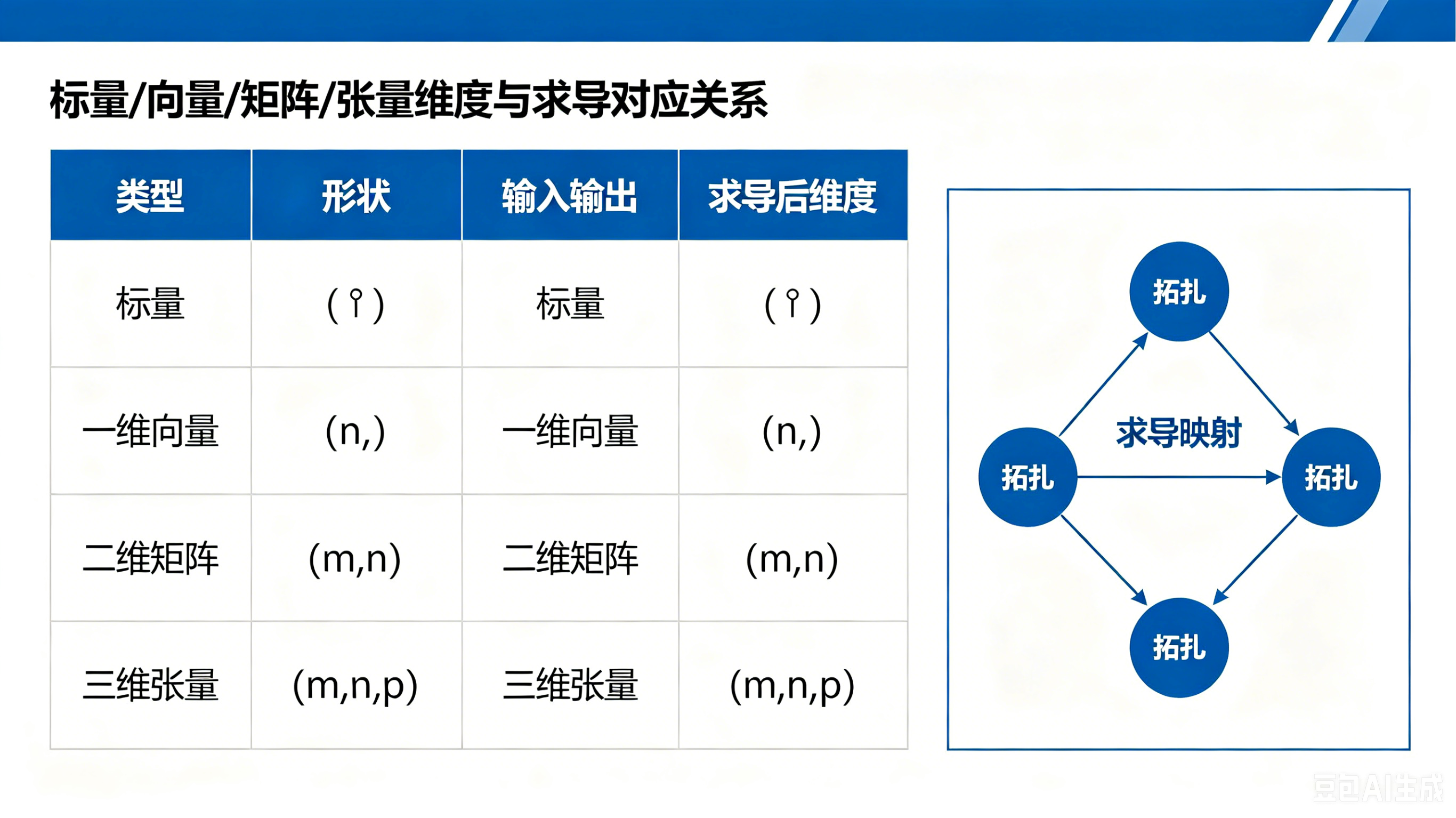 图 2:标量 / 向量 / 矩阵维度与求导对应关系图
图 2:标量 / 向量 / 矩阵维度与求导对应关系图
四、矩阵常用运算(PyTorch 实现)
4.1 哈达玛积(逐元素相乘)
两个同维度矩阵对应位置元素相乘,区别于数学矩阵乘法:
python
# 逐元素相乘
hadamard_res = stSender_Mat * stReciver_Mat4.2 矩阵求和、均值(按维度降维)
支持全局求和 、指定维度求和 ,keepdims=True 可保留原有维度,避免维度塌陷。
python
# 创建 2×5×4 三维矩阵
stExperiment_Mat = torch.arange(20 * 2).reshape(2, 5, 4)
print(stExperiment_Mat.shape)
# 1. 全局所有元素求和
total_sum = stExperiment_Mat.sum()
# 2. 按第0维求和(维度压缩)
axis0_sum = stExperiment_Mat.sum(axis=0)
print(axis0_sum, axis0_sum.shape)
# 3. 按维度求和,保留原始维度
keepdim_sum = stExperiment_Mat.sum(axis=0, keepdims=True)
# 4. 全局均值(均值 = 总和 / 元素总个数)
total_mean = stExperiment_Mat.mean()
element_num = stExperiment_Mat.numel()
print(total_mean == stExperiment_Mat.sum() / element_num)
# 5. 按维度求均值
axis0_mean = stExperiment_Mat.mean(axis=0)
print(axis0_mean == stExperiment_Mat.sum(axis=0) / stExperiment_Mat.shape[0])知识点:按指定维度求和 / 求均值,本质是降维操作 ;
keepdims=True在网络层拼接、维度对齐场景中高频使用。
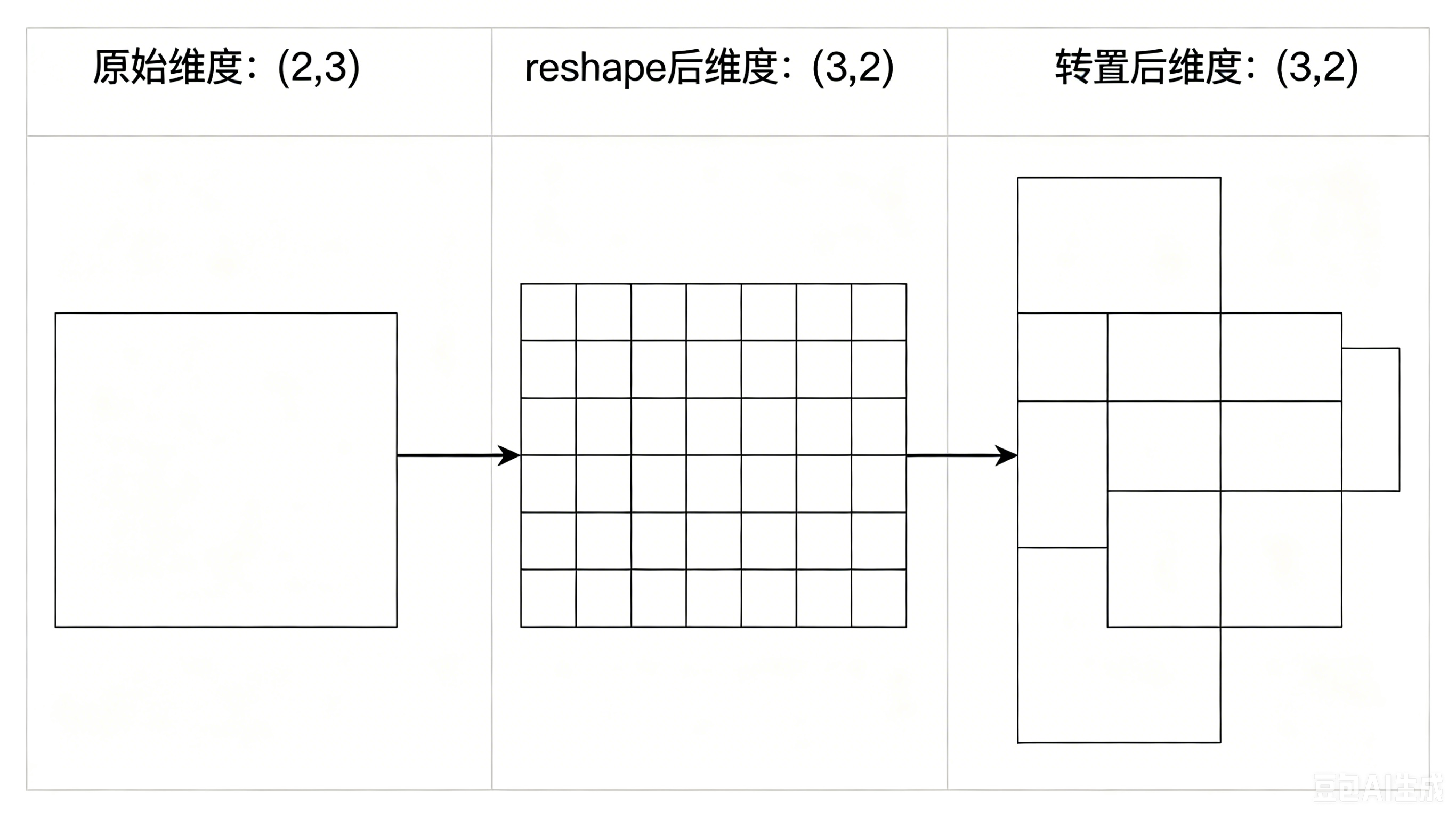 图 3:矩阵维度变换示意图
图 3:矩阵维度变换示意图
4.3 向量点积、矩阵 - 向量乘法
python
# 向量点积
vec1 = torch.tensor([1.0, 2.0, 3.0])
vec2 = torch.tensor([4.0, 5.0, 6.0])
dot_res = torch.dot(vec1, vec2)
# 矩阵 × 向量(齐次线性方程组 Ax 运算)
mat_A = torch.tensor([[1, 2], [3, 4]], dtype=torch.float32)
vec_x = torch.tensor([5, 6], dtype=torch.float32)
mv_res = torch.mv(mat_A, vec_x)4.4 求解矩阵 F 范数
使用 torch.norm() 直接计算矩阵 / 向量的 F 范数:
python
mat = torch.arange(9, dtype=torch.float32).reshape(3, 3)
f_norm = torch.norm(mat) # 计算F范数
print(f_norm)五、微积分基础:导数、偏导、梯度(深度学习核心)
5.1 核心概念
深度学习的参数更新完全依赖梯度,从标量、向量到矩阵,求导规则逐层拓展:
- 导数:标量对标量的变化率。
- 偏导数:多元函数中,固定其他变量,仅对单一变量求导。
- 梯度 :函数对向量 / 矩阵所有分量的偏导数集合,指示函数下降最快的方向。
- 亚导数:针对 ReLU 等不可导激活函数设计,保证梯度依然可正常回传。
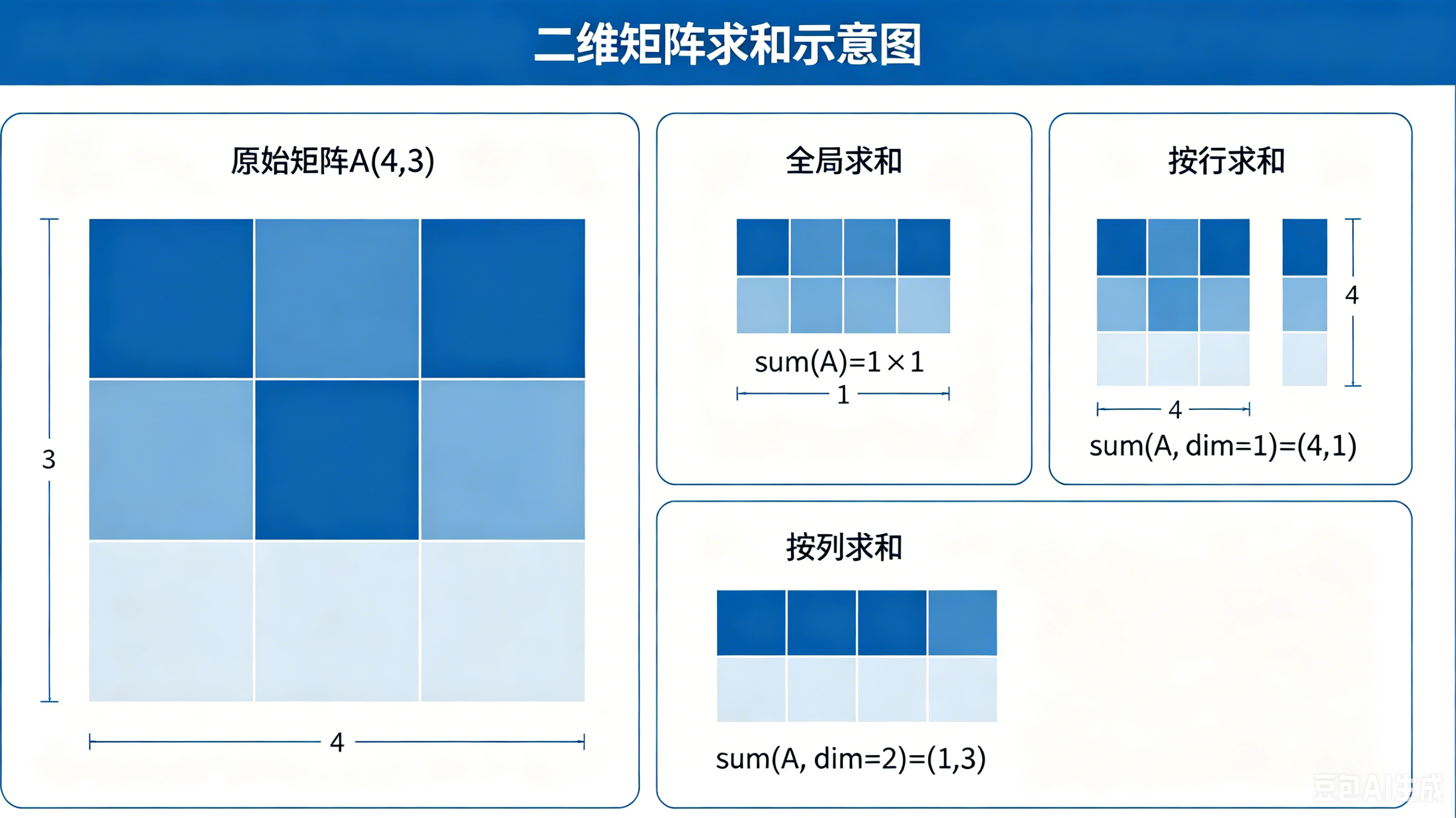 图 4:矩阵按维度求和示意图
图 4:矩阵按维度求和示意图
5.2 标量 / 向量 / 矩阵求导维度规则
深度学习求导会严格遵循维度匹配原则,下图为维度对应关系(配图参考):
- 标量 x→ 标量 y:求导结果仍为标量
- 向量 x(n,1)→ 标量 y:求导结果为同维度向量
- 矩阵 X(n,k)→ 标量 y:求导结果为同维度矩阵
- 高阶张量求导:维度跟随原始输入,保证运算合法。
六、优化算法:小批量随机梯度下降
6.1 算法定位
小批量随机梯度下降(Mini-Batch SGD) 是目前深度学习框架默认优化算法,兼顾训练速度、泛化能力与硬件算力。
 图 5:F 范数计算原理图
图 5:F 范数计算原理图
6.2 两大核心超参数
- 批量大小(batch size):单次送入模型训练的样本数量,影响训练稳定性与算力占用。
- 学习率(learning rate):控制参数每次更新的步长,过大易震荡不收敛,过小训练速度极慢。
6.3 应用场景
该算法广泛用于拟合带噪声的线性模型、深度神经网络,是模型迭代更新的核心逻辑。
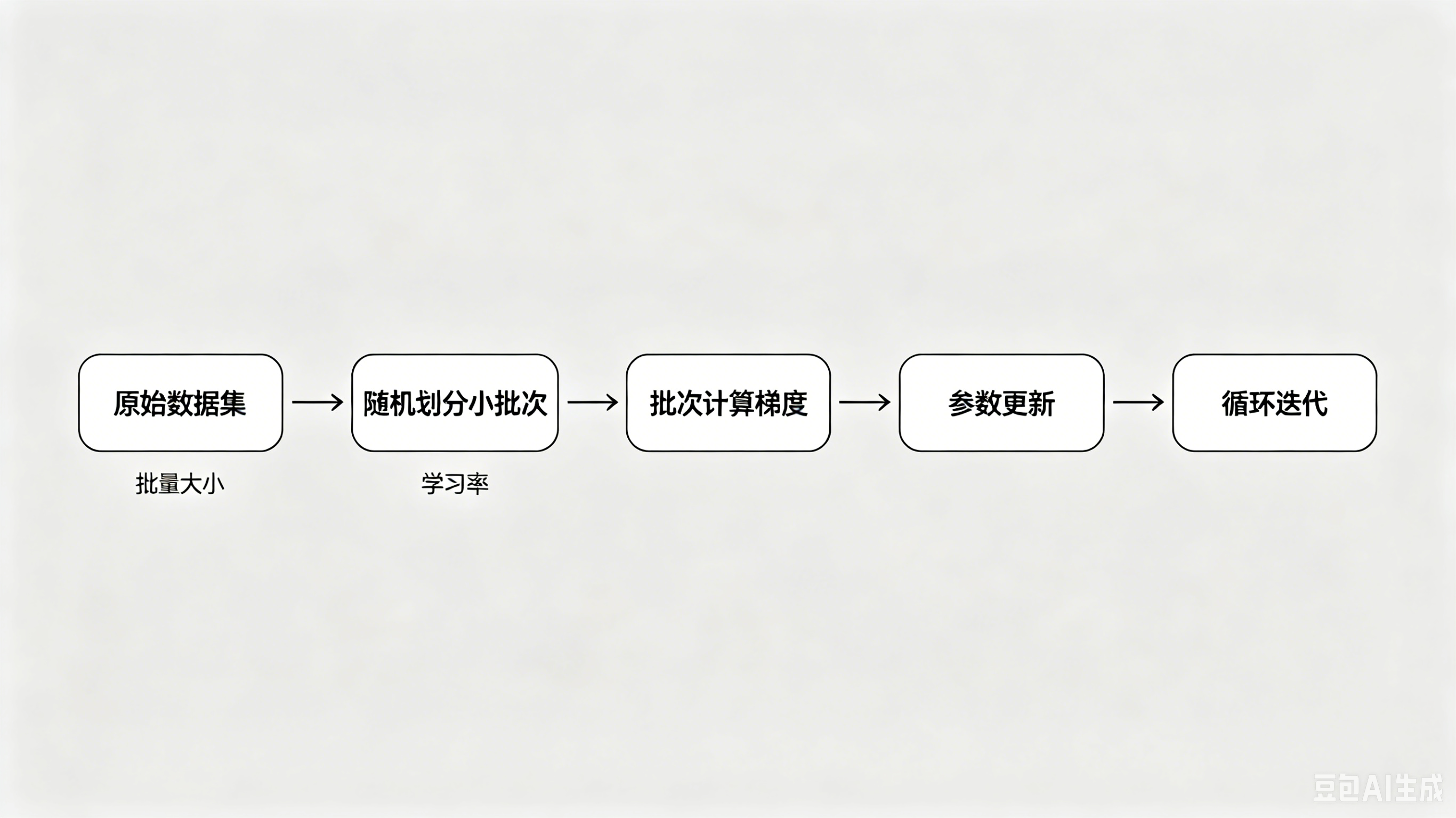 图 6:小批量梯度下降流程简图
图 6:小批量梯度下降流程简图
总结
- 线性代数 :向量、矩阵、范数、正交矩阵是张量运算的基础,PyTorch 张量操作完全对标数学定义,熟练掌握
reshape、sum、clone、矩阵乘法等接口是深度学习编码必备能力。 - 矩阵运算:逐元素积、矩阵向量乘法、按维度聚合(求和 / 均值)是网络前向传播的核心运算。
- 微积分:梯度是反向传播、参数更新的核心,理解不同维度数据的求导规则,才能读懂梯度回传逻辑。
- 优化算法 :小批量随机梯度下降为工业界通用方案,批量大小 和学习率是调参核心超参数。
数学理论 + 代码实操结合,才能真正吃透深度学习底层逻辑,为网络搭建、调优、排错打下基础。