开篇
拥有越来越多 Skill,Agent 就会越来越强吗?
很多人学习 Agent 时,关注点都放在 Prompt、Tool、Skill 上。仿佛拥有越多 Skill,Agent 就越强大。
但真实情况恰恰相反:当 Skill 数量从 1 个变成 10 个、100 个时,最大的挑战已经不是能力不足,而是能力协作。
这篇文章讨论的核心问题:Skill 负责解决「做什么」,Workflow 负责解决「怎么协作」。
一、从 Anthropic Skills 说起
Skill 解决了加载问题,但没有解决协作问题
1.1 Skill 解决了什么问题
Anthropic 在 2025 年 10 月发布 Agent Skills 时,提出了**渐进式披露(Progressive Disclosure)**架构 ------ 用三层加载解决「Skill 怎么高效装入上下文」的问题:
- L1(Metadata):常驻上下文,只有名称和描述,约 20~100 Token/Skill。让 Agent 知道「有哪些能力可选」
- L2(Instructions):按需加载,触发后才注入完整的工作流定义和决策规则,低于 5000 Token/Skill
- L3(Resources) :延迟加载,脚本、文档、模板等通过工具调用获取,不占上下文
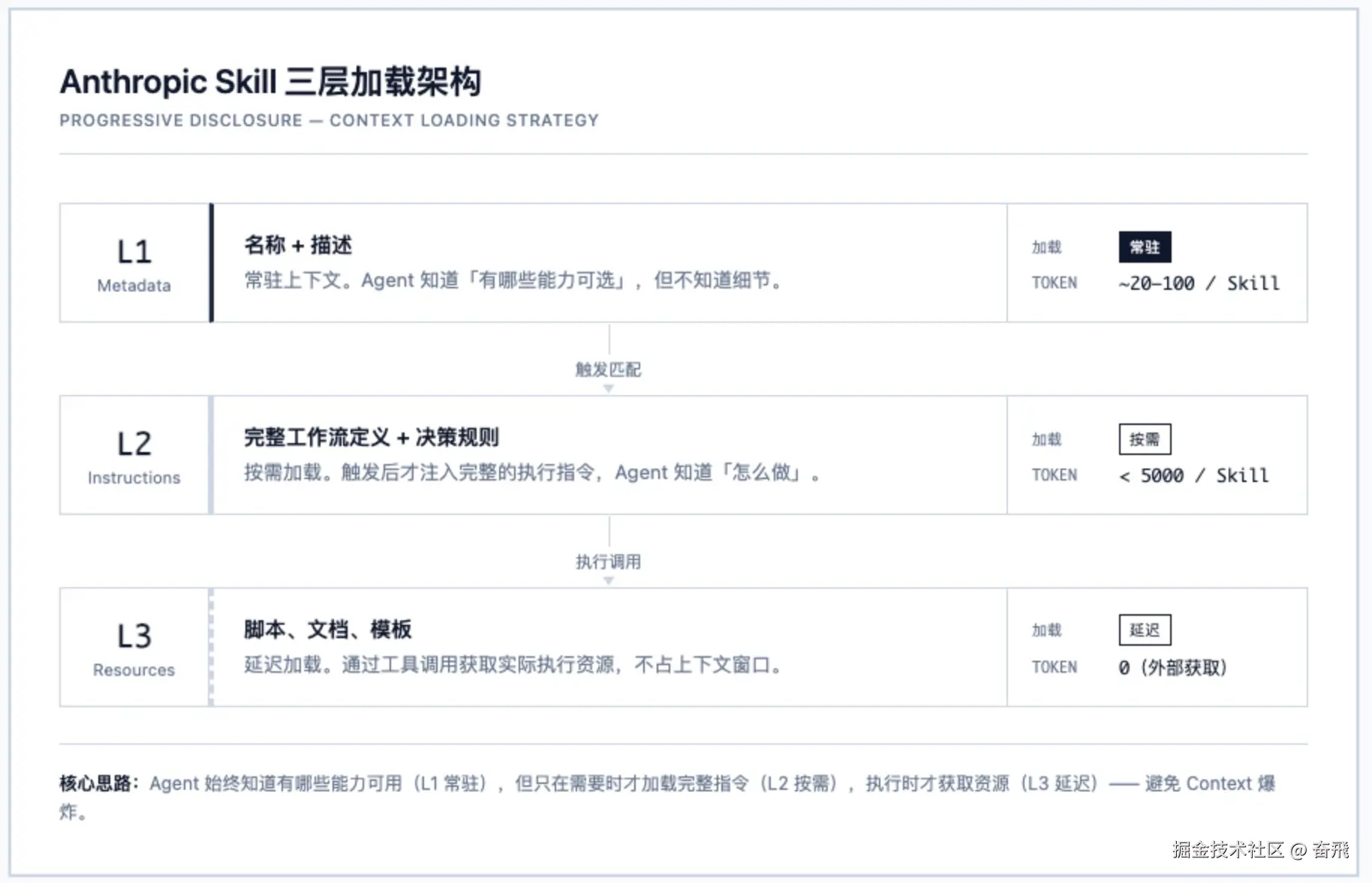
这套架构解决了加载效率问题:Agent 始终知道有哪些能力可用,但只在需要时才加载完整指令,执行时才获取资源 ------ 避免了 Context 爆炸。
1.2 Skill 没解决什么问题
假设你的 Agent 拥有四个 Skill:需求分析、代码生成、代码 Review、测试生成。
那么:
- 谁先执行?谁后执行?
- 前一步的输出怎么传给下一步?
- 代码 Review 不通过,怎么回到代码生成?
- 某一步失败了,整个流程怎么处理?
这些问题的答案是:它们不属于 Skill 的职责。Skill 只定义「一个能力怎么做」,不定义「多个能力怎么协作」。
解决协作问题的,是 Workflow。
二、Skill、Tool、Workflow 到底是什么关系
理清三者的层次
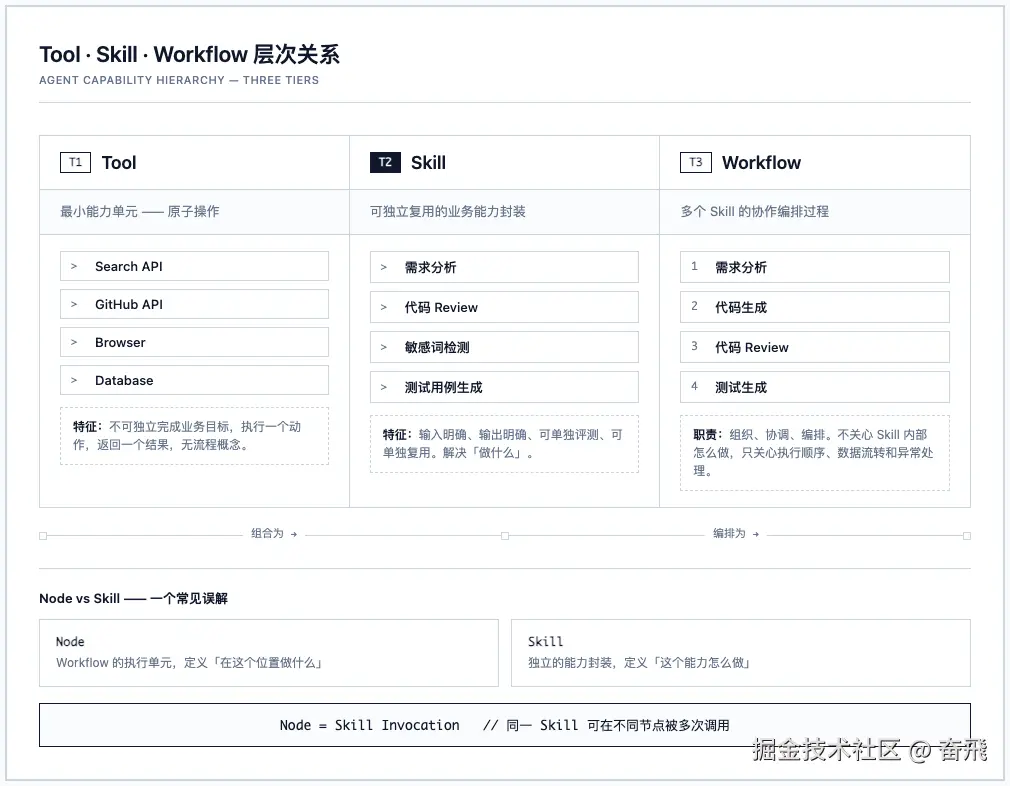
这三者在 Agent 生态中被高频混用,但它们有清晰的层次关系。
2.1 Tool:最小能力单元
Tool 是让 LLM 与外部世界交互的原子操作:
Search API--- 搜索GitHub API--- 读写仓库Browser--- 访问网页Database--- 查询数据
Tool 的特点是不可独立完成业务目标。它只执行一个动作,返回一个结果,没有流程概念。
2.2 Skill:可独立复用的业务能力
Skill 封装了一套完整的做事方法:
- 需求分析 --- 输入用户描述,输出结构化需求文档
- 代码 Review --- 输入代码变更,输出审查意见
- 敏感词检测 --- 输入文本,输出是否合规
- 测试用例生成 --- 输入需求或代码,输出测试用例
Skill 的特点是:输入明确、输出明确、可单独评测、可单独复用。
2.3 Workflow:多个 Skill 的协作过程
Workflow 定义多个 Skill 如何串联、分支、回退:
Workflow 的职责是三个字:组 织、协 调、编排。它不关心每个 Skill 内部怎么做,只关心它们之间的执行顺序、数据流转和异常处理。
2.4 一个容易误解的问题
Workflow 的节点是不是 Skill?
看这个例子:
markdown
CheckSensitive(敏感词检查)
↓
Answer(LLM 回答)直觉上,CheckSensitive 和 Answer 各是一个 Skill。但在 Workflow 中,它们是节点(Node)。
区别在于:
- Node = Workflow 的执行单元,定义了「在这个位置做什么」
- Skill = 独立的能力封装,定义了「这个能力怎么做」
- Node ≠ Skill ,更准确地说:Node = Skill Invocation(节点是对 Skill 的一次调用)
同一个 Skill 可以在 Workflow 的不同节点被调用多次,每次传入不同的参数。
三、为什么不能直接写代码
Workflow 到底比 if/else 强在哪?
这是很多有经验的开发者会问的问题:「我都懂状态管理和条件分支,直接写代码不行吗?」
3.1 简单场景 ------ 代码即可解决
javascript
// 敏感词检查 → 拦截或回答
const result = await checkSensitiveInput(userInput);
if (result.blocked) {
return result.message; // 拦截,不调用 LLM
}
return await answerQuestion(userInput);两三个节点、线性流程、没有回退 ------ 直接写代码完全没问题。
3.2 复杂场景 ------ 代码开始失控
但当流程变成这样:
markdown
Research(调研)
├── Search(搜索多个来源)
├── Extract(提取关键信息)
└── Summarize(汇总)
↓ 质量不达标
Research(重新调研)
Review(审查)
├── Auto Review(自动审查)
│ ↓ 不确定
└── Human Review(人工审查)
↓ 发现问题
代码修改 → 重新 Review你开始面对:
- 分支:根据搜索结果质量决定是否重新调研
- 回退:人工审查发现问题后,回到代码修改再重新审查
- 重试:搜索 API 超时,指数退避后重试
- 状态恢复:进程崩溃后,从最后成功的节点继续执行
用 if/else 写这些逻辑不是不行 ------ 但代码会迅速膨胀成一团难以维护的面条。每个分支、回退、重试逻辑散落在各处,改一个地方可能影响三个地方。
3.3 Workflow 的价值
Workflow 不是替代代码。它的价值是:
- 把流程逻辑从业务代码中抽离出来,变成可声明、可可视化、可调试的结构
- 提供开箱即用的状态管理、重试、断点恢复能力,不用每个项目重复实现
- 让流程可以被独立测试和版本管理,而非嵌在业务逻辑里
简单说:流程越复杂,Workflow 的价值越大。线性三步的流程用 if/else 就够了;有分支、回退、并发的流程,Workflow 才是正解。
四、三个真实场景暴露编排缺失
单个 Skill 能跑通,多个 Skill 一起跑就乱套
理论讲完了,看三个真实场景。它们分别暴露了多 Skill 协作中不同维度的问题。
场景一:不该执行的还是执行了
markdown
CheckSensitive(敏感词检查)
↓
Answer(LLM 回答)一个客服 Agent 拥有「敏感词检测」和「智能问答」两个 Skill。理想流程是先检测输入,通过后再调用 LLM 回答。
但实际运行中,两个 Skill 被顺序执行,无论输入是否合规,LLM 都会被调用 ------ 白白多消耗了一次 API 请求。
❗️ 问题本质 :缺少条件路由。执行完「检测」后,没有机制根据结果动态决定下一步是「继续」还是「终止」。
场景二:数据传递断裂
markdown
Search(搜索)
↓
Clean(清洗)
↓
Report(生成报告)一个研究 Agent 依次执行三个 Skill。第一步搜到了 20 条资料,第二步清洗后保留 8 条 ------ 但第三步启动时,Agent 只能看到最后一步的输出,前两步的结果已经不在上下文里了。
❗️ 问题本质 :缺少共享状态。每个 Skill 独立运行、独立返回,没有统一的「表单」在流程中流转和累积数据。
场景三:无限重试
markdown
Crawler(网页抓取)
↓
Timeout(超时)
↓
Retry(重试)
↓
Timeout(又超时)
↓
...一个数据采集 Agent 访问某个 URL 超时了,没有降级方案,反复用相同参数重试 ------ 陷入死循环。
❗️ 问题本质 :缺少容错机制。没有重试上限、没有降级路径、没有熔断逻辑。
五、Workflow 编排器到底在做什么
Agents decide. Orchestrators coordinate. Tools execute.
上面三个场景指向同一个结论:Skill 只负责「做好一件事」,而「多件事怎么串起来」需要一个独立的协调层 ------ 编排器(Orchestrator)。
编排器(Orchestrator)的工作可以拆成四件事。
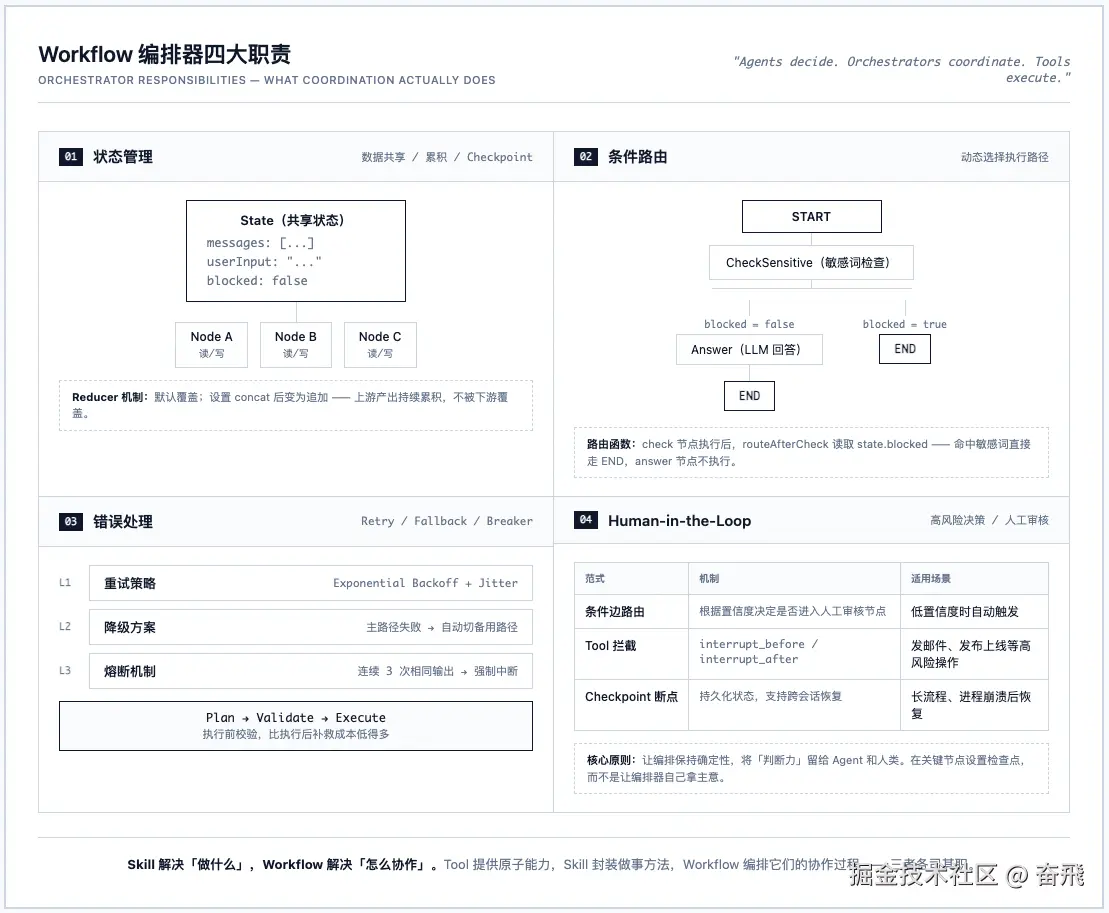
5.1 状态管理
解决:数据共享、数据累积、Checkpoint
状态(State)是整个工作流共享的数据对象。每个节点读取状态、处理、写回状态 ------ 下游节点可以拿到上游的所有产出。
yaml
┌─────────────────────────────┐
│ State(共享状态) │
│ messages: [...] │
│ userInput: "..." │
│ blocked: false │
└──────────┬──────────────────┘
│
┌───────────────┼───────────────┐
↓ ↓ ↓
Node A Node B Node C
读取/写入 读取/写入 读取/写入回看场景二 ------ 「搜索 → 清洗 → 报告」三步之间数据丢失 ------ 解法就是定义一个共享状态。以 LangGraph.js 为例:
javascript
// 【代码示意】用 Annotation 定义工作流共享状态
const StateAnnotation = Annotation.Root({
// reducer 控制为「追加」而非「覆盖」
messages: Annotation({
reducer: (current, update) => current.concat(update),
default: () => [],
}),
userInput: Annotation({ default: () => "" }),
blocked: Annotation({ default: () => false }),
blockReason: Annotation({ default: () => "" }),
});这里的重点是 reducer:默认行为是新值覆盖 旧值;设置 concat 后变为追加。这样「搜索」写入的资料不会被「清洗」覆盖,而是持续累积。
5.2 条件路由
解决:动态选择执行路径
回看场景一:敏感词检测后,不该再调用 LLM。解法是在两个节点之间插入一个路由函数,根据状态动态决定走向。
javascript
// 路由函数:拦截则结束,否则进入 answer 节点
function routeAfterCheck(state) {
return state.blocked ? END : "answer";
}
// 将路由函数注册到工作流图
const graph = new StateGraph(StateAnnotation)
.addNode("check", checkSensitiveInput)
.addNode("answer", answerQuestion)
.addEdge(START, "check")
.addConditionalEdges("check", routeAfterCheck, {
answer: "answer",
[END]: END,
})
.addEdge("answer", END)
.compile();check 节点执行后,routeAfterCheck 读取 state.blocked ------ 命中敏感词则直接走 END,answer 节点根本不会被执行。
5.3 错误处理
解决:Retry、Fallback、Circuit Breaker
场景三是超时后无限重试。需要三层防线来兜底:
- 重试策略:指数退避 + 随机抖动(Exponential Backoff + Jitter),避免雪崩式重试
- 降级方案:主路径失败时自动切换到备用路径,而非原地等待
- 熔断机制:检测死循环 ------ 如果连续三次输出完全相同,说明 Agent 可能卡住了,强制中断
❗️ 原则:Plan → Validate → Execute。执行前做校验,比执行后补救成本低得多。
5.4 Human-in-the-Loop
解决:高风险决策、人工审核、长流程恢复
生产级 Workflow 需要在关键节点引入人工介入。LangGraph 提供了三种范式:
| 范式 | 机制 | 适用场景 |
|---|---|---|
| 条件边路由 | 根据置信度决定是否进入人工审核节点 | 低置信度时自动触发人工审核 |
| Tool 拦截 | interrupt_before / interrupt_after 在工具调用前后暂停 |
发送邮件、发布上线等高风险操作 |
| Checkpoint 断点 | 持久化状态,支持跨会话恢复 | 长时间运行的工作流、进程崩溃后恢复 |
⚠️ 核心原则:让编排保持确定性,将「判断力」留给 Agent 和人类。在关键节点设置检查点,而不是让编排器自己拿主意。
Skill 解决「做什么」,Workflow 解决「怎么协作」。Tool 提供原子能力,Skill 封装做事方法,Workflow 编排它们的协作过程 ------ 三者各司其职,Workflow 是那条主线。