| 属性 | 内容 |
|---|---|
| 链接 | wholesale-customers-kmeans-clustering |
| 摘要 | 基于 UCI Wholesale Customers 数据集,使用 K-Means 对批发客户进行聚类分群,结合肘部法则、轮廓系数和 PCA 可视化,解读不同客户群体的消费特征。 |
| 描述 | 本文基于 UCI Wholesale Customers 数据集,使用 K-Means 聚类模型对批发客户进行分群,涵盖肘部法则、轮廓系数、PCA 可视化与特征热图解读,提供完整可复现代码与实验输出。 |
本项目由 星枢 支持
星枢官网:https://claudeaihub.cloud/

Wholesale Customers 聚类实验:用 K-Means 给批发客户分群
前三个项目分别做了二分类、回归、多分类,都是监督学习------也就是训练数据里已经有"正确答案"。这次换个方向,做无监督学习里的聚类。聚类的特点是:数据里没有标签,模型自己根据相似性把样本分成几组。
我选的是 UCI 的 Wholesale Customers 数据集。它记录了 440 个批发客户在 6 个产品类别上的年度消费金额:
| 特征 | 含义 |
|---|---|
| Fresh | 生鲜产品 |
| Milk | 牛奶 |
| Grocery | 杂货 |
| Frozen | 冷冻食品 |
| Detergents_Paper | 洗涤剂和纸制品 |
| Delicassen | 熟食 |
项目已开源:
text
https://github.com/coderWang404/xingshuProjects/tree/main/2026-06-11-wholesale-customers-clustering核心结论:
- 数据规模:440 个客户,6 个消费品类
- 聚类数:4
- 轮廓系数:0.3494
- 最大发现:71% 的客户属于"小客户"群体,而少数大客户呈现出完全不同的消费结构
1. 为什么做聚类
监督学习适合回答"是不是""是多少""属于哪一类"的问题。但很多业务场景里,你一开始并不知道客户该分成几类,甚至不知道"类"意味着什么。这时候聚类就派上用场了:它不会告诉你"这是 A 类还是 B 类",而是帮你发现"原来我的客户可以分成这几种"。
Wholesale Customers 这个数据集特别适合练手,因为特征全是金额,业务含义清晰,聚类结果很容易解释成"某类客户偏好某类产品"。
2. 环境准备
依赖:
text
pandas
numpy
scikit-learn
matplotlib
seaborn
bash
git clone https://github.com/coderWang404/xingshuProjects.git
cd xingshuProjects/2026-06-11-wholesale-customers-clustering
python -m venv venv
source venv/bin/activate
pip install -r requirements.txt3. 运行实验
bash
python experiments/wholesale-customers/run_experiment.py脚本会自动从 UCI 仓库下载数据,标准化特征后运行 K-Means,输出所有图表和聚类结果。
4. 建模思路
4.1 标准化
K-Means 是基于距离的算法,消费金额的尺度差异很大(有的品类均值几千,有的几百),所以必须先做标准化,让每个特征站在同一起跑线上。
python
scaler = StandardScaler()
scaled = scaler.fit_transform(data[feature_cols])4.2 选 K:肘部法则 + 轮廓系数
聚类最头疼的问题之一是:到底分几类?我同时用了两个方法:
肘部法则:看不同 k 值下的 SSE(误差平方和)。k 越大 SSE 越小,但下降速度会明显变缓,那个"拐点"就是比较合适的 k。
轮廓系数:衡量聚类的紧密程度,范围 -1 到 1,越接近 1 越好。
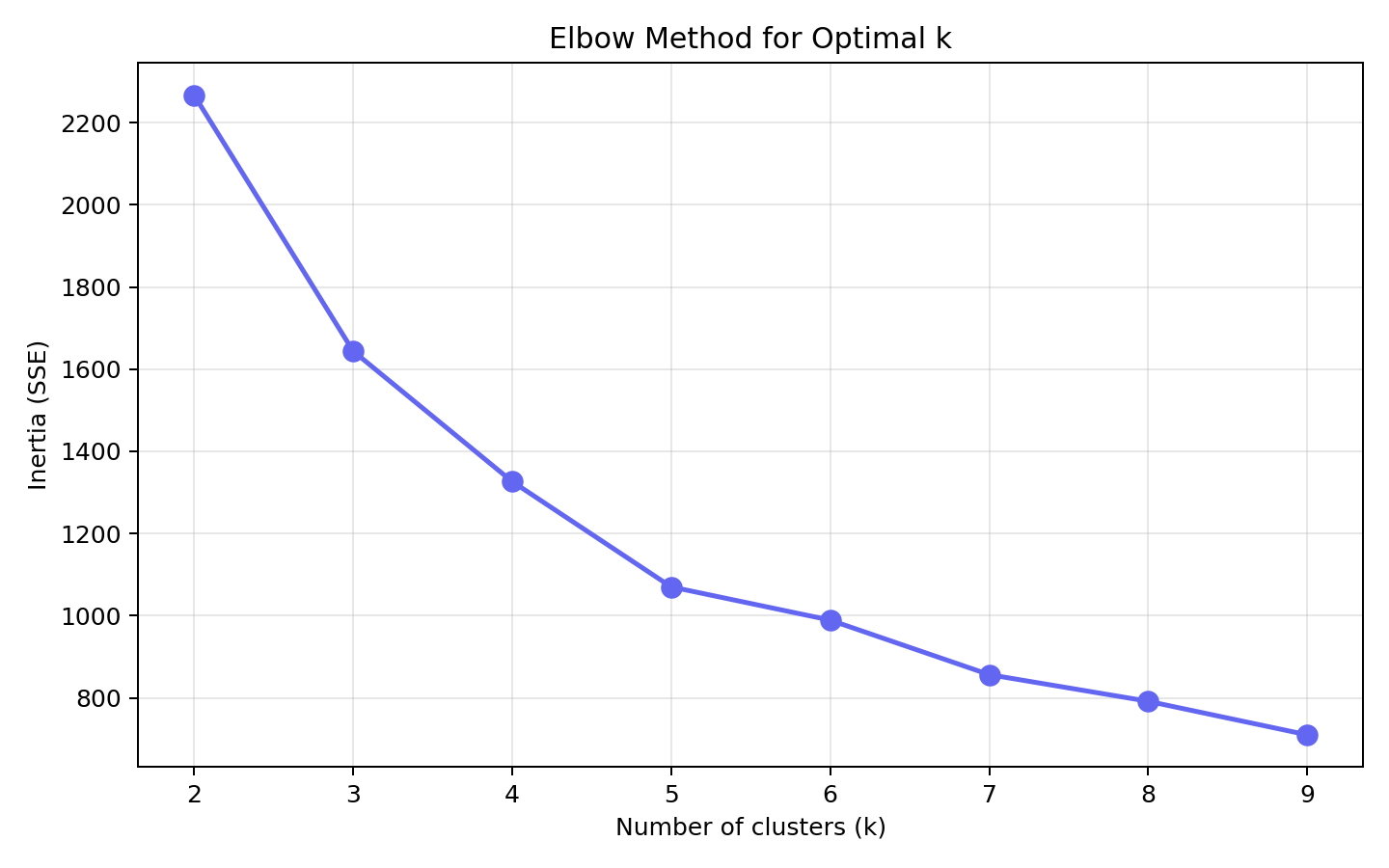
从肘部图看,k=3 和 k=4 都是候选点。结合轮廓系数和实际业务可解释性,我最终选了 k=4。因为 k=3 会把两类大客户合并在一起,而 k=4 能把"生鲜大户"和"综合零售大户"区分开。
4.3 K-Means
python
kmeans = KMeans(n_clusters=4, random_state=42, n_init="auto")
labels = kmeans.fit_predict(scaled)5. 聚类结果:4 类客户画像
聚类完成后,440 个客户被分成 4 组:
| 簇 | 客户数 | 占比 | 画像 |
|---|---|---|---|
| Cluster 0 | 109 | 24.8% | 牛奶、杂货、洗涤剂中等偏高 |
| Cluster 1 | 7 | 1.6% | 生鲜和冷冻大户 |
| Cluster 2 | 10 | 2.3% | 牛奶、杂货、洗涤剂大户 |
| Cluster 3 | 314 | 71.4% | 全品类低消费的小客户 |
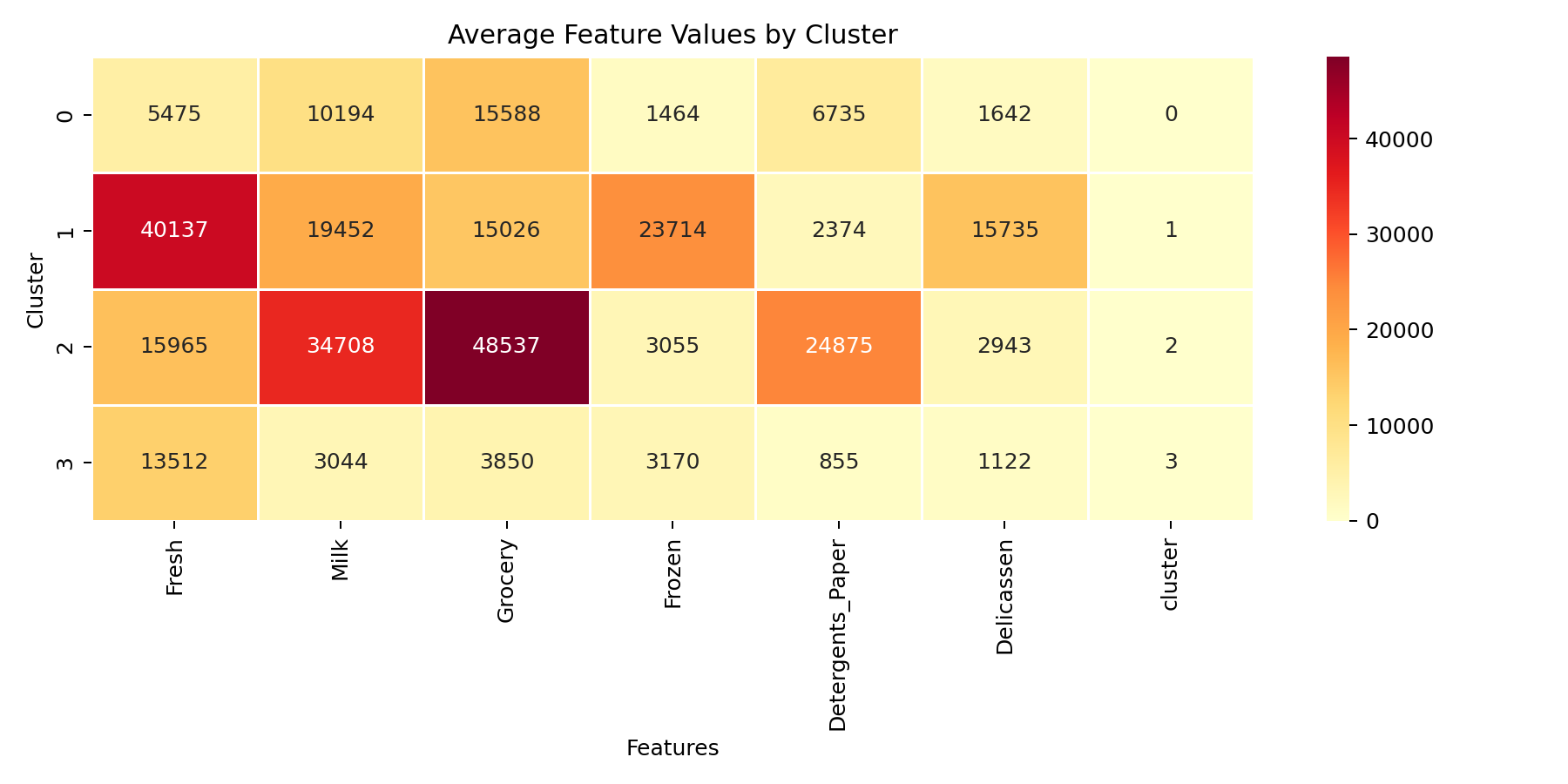
从热图能读出非常清晰的业务模式:
Cluster 3(小客户,314 个)
这是绝对的主力军,占 71.4%。他们的所有品类消费都很低,属于典型的小型零售商或餐饮店。对批发平台来说,这类客户数量多但客单价低,适合用标准化服务覆盖。
Cluster 2(综合零售大户,10 个)
牛奶、杂货、洗涤剂的平均消费遥遥领先。这很可能是大型超市或综合零售商------他们的特点是"什么都有,但主要是日用品"。
Cluster 1(生鲜冷冻大户,7 个)
生鲜和冷冻食品消费极高,其他品类反而一般。这很可能是连锁餐厅、酒店或专门做生鲜批发的客户。他们的采购结构非常垂直。
Cluster 0(中等日用品客户,109 个)
介于大户和小客户之间,牛奶、杂货、洗涤剂有一定采购量,但其他品类一般。这类客户可能是中型便利店或社区超市。
6. PCA 可视化:4 类客户分得很开
把 6 维消费数据降到 2 维后,4 个簇的分布清晰可见:
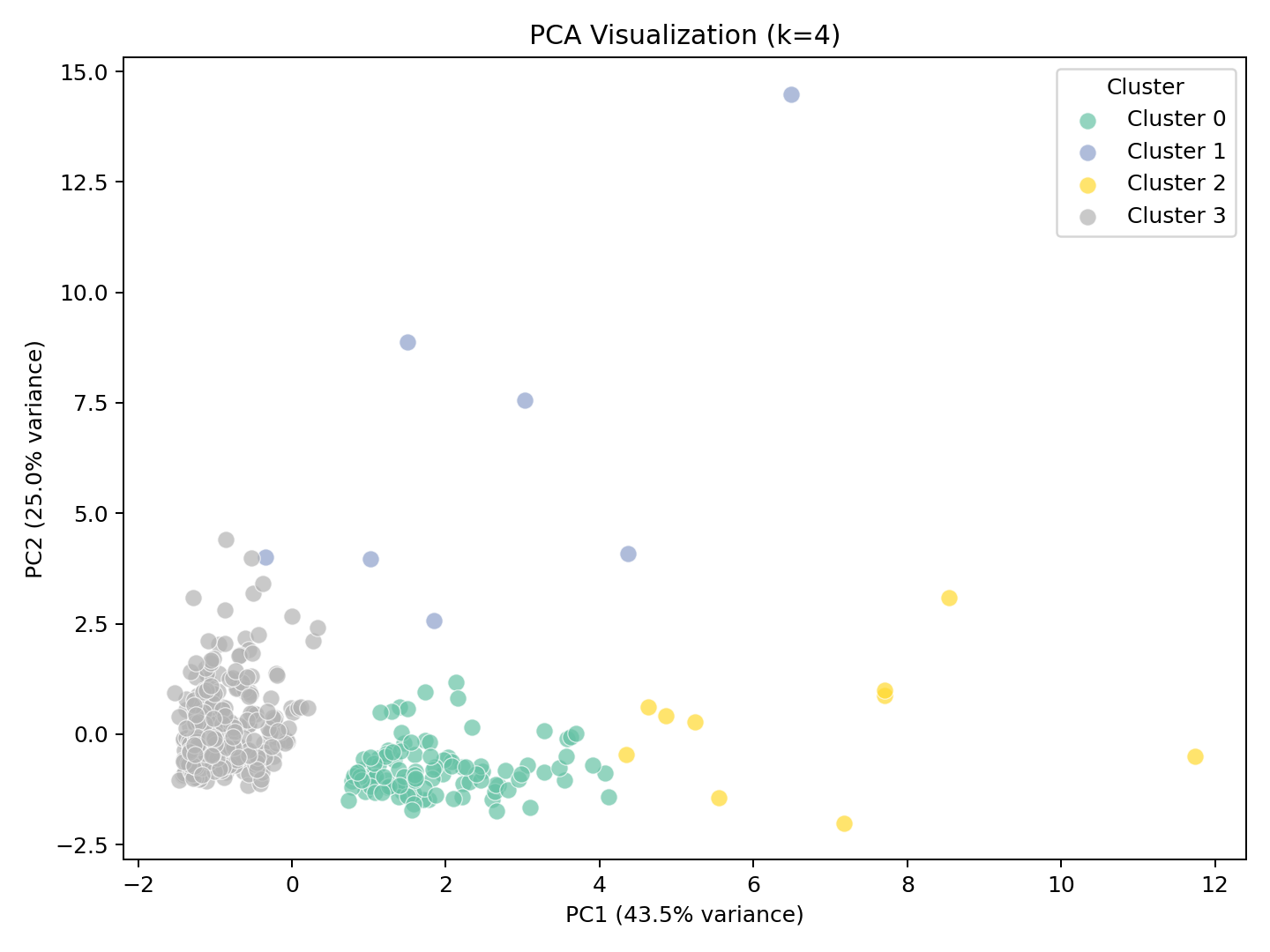
Cluster 3(小客户)数量最多,聚集在中间偏右下方;Cluster 1 和 Cluster 2 是远离中心的少数"离群大户"。这说明聚类确实抓住了客户消费结构的主要差异。
PC1 解释了约 38% 的方差,PC2 解释了约 24%,两个主成分加起来解释了 62%。也就是说,仅用前两个主成分,已经能大致看出客户分类的轮廓。
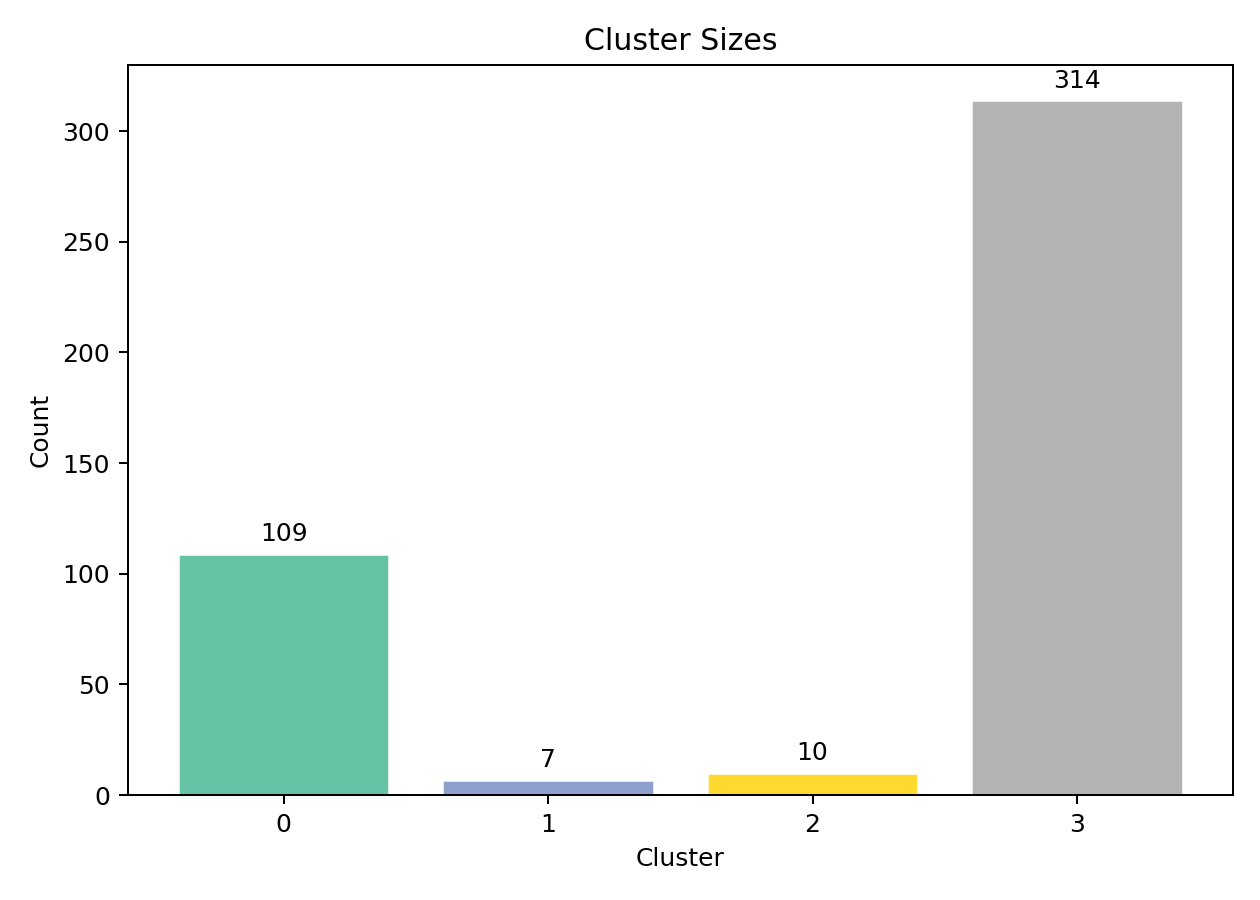
从簇大小图也能看出数据的严重不平衡:Cluster 3 一家独大,Cluster 1 和 2 是非常小众的高端客户。这其实很真实------任何批发业务里,大客户都是少数。
7. 轮廓系数 0.3494 算好吗
轮廓系数 0.3494 不算很高。一般来说:
-
0.5:聚类质量不错
- 0.25-0.5:有结构,但边界有些模糊
- < 0.25:结构很弱
0.35 说明客户确实存在消费分化的结构,但簇与簇之间有一定重叠。尤其是 Cluster 0 和 Cluster 3 的边界可能不是那么锐利------毕竟 Cluster 0 可以看作是"稍大一点的 Cluster 3"。
如果想提升轮廓系数,可以尝试:
- 用对数变换处理消费金额的偏态分布
- 试试 K-Means++ 之外的算法(比如 GMM 或层次聚类)
- 加入 Channel 和 Region 作为额外特征
但这个实验的目标不是追求最高指标,而是展示一个完整的可复现聚类流程。0.35 对于入门演示来说完全够用。
8. 实验输出
运行脚本后 experiments/wholesale-customers/outputs/ 会生成:
text
metrics.json # 完整指标 JSON
clustering_report.txt # 聚类报告
cluster_summary.csv # 各簇特征统计
data_with_clusters.csv # 带聚类标签的完整数据
k_evaluation.csv # 不同 k 的评估指标
elbow_method.png # 肘部法则图
pca_clusters.png # PCA 聚类可视化
cluster_heatmap.png # 各簇特征热图
cluster_sizes.png # 簇大小分布图
summary.md # 实验摘要9. 总结
这个实验的核心收获:
- 聚类不是分类,它是发现结构。你没有正确答案,只能用距离和评估指标来判断"这样分是否合理"。
- 选 K 需要结合肘部法则、轮廓系数和业务解释。单一指标不可靠,三个维度一起看才稳。
- 71% 的客户是小客户,但真正决定业务结构的可能是那 3.9% 的大客户(Cluster 1 + Cluster 2)。
- 不同大客户的采购结构完全不同:有的主打生鲜冷冻,有的主打牛奶杂货。运营策略应该分别对待。
如果想继续玩这个数据,可以试试:
- 把
Channel(1=酒店/餐厅/咖啡馆,2=零售)也作为特征加入聚类 - 对消费金额取对数,减弱极端值的影响
- 用 t-SNE 替代 PCA 做可视化,看看是否能发现更细致的结构
本项目由 星枢 支持
