nano-vllm 用千行代码拆解 vLLM 核心,是读懂大模型推理最快的捷径。
1. 介绍
L13 给出 Qwen3 的骨架,L14 到 L17 拆解了注意力子层用到的模块:RMSNorm、RoPE、Linear 家族、注意力本体。还剩残差流的两端------开头把 token id 变成向量的 embed_tokens、结尾把 hidden 变成 logits 的 lm_head。本篇拆解这两个模块。
这两站其实是同一张 [vocab, hidden] 权重表的两个方向:embedding 拿 token id 取表的一行(输入端),lm_head 拿 hidden 跟表的每一行做内积、给每个 token 打分(输出端),找出得分最高的 token。
本篇聚焦单卡场景下的原理解释,后续介绍 embedding 和 lm_head 在多卡切分下如何计算。
2. 总览
残差流的两端分别连接了一个查表模块:开头 embed_tokens 把 token id 查成向量送进残差流,结尾 lm_head 把残差流末端的 hidden 算成全词表的分数 logits。中间是 N 层 decoder。
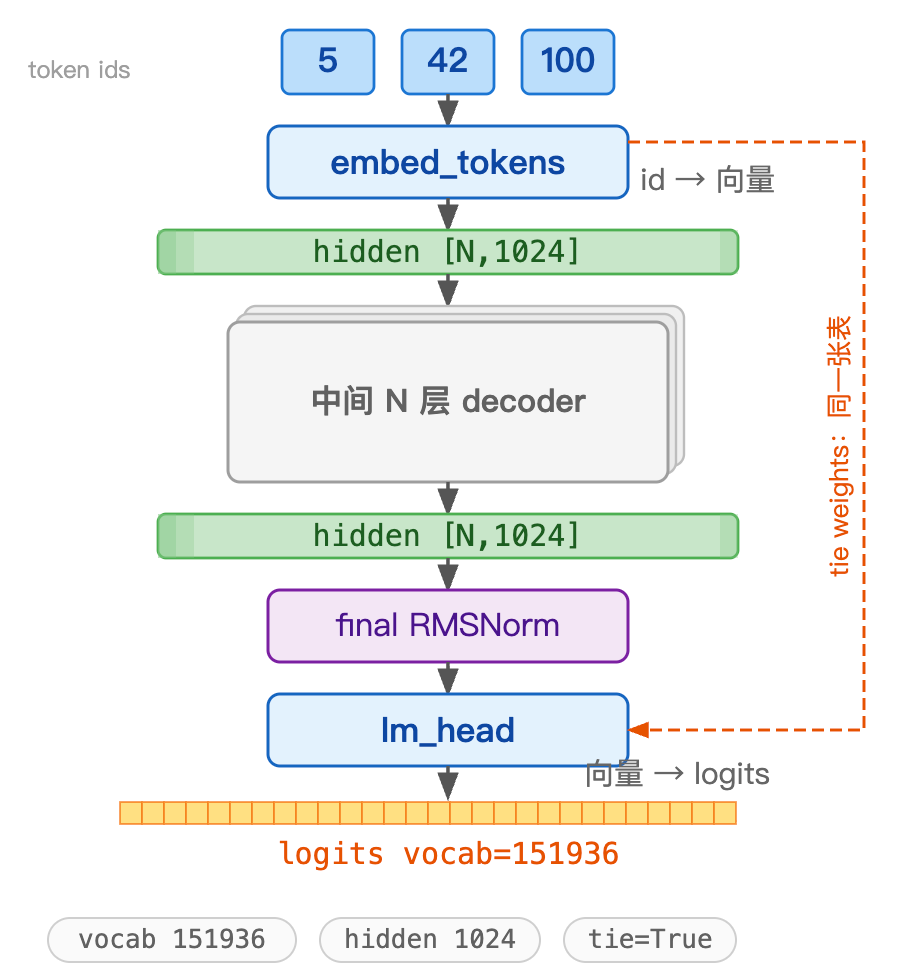
| 配置项 | 值 | 含义 |
|---|---|---|
vocab_size |
151936 | 词表大小 = 表的行数 |
hidden_size |
1024 | 隐藏维 = 表的列数 / 每个 token 的向量长度 |
tie_word_embeddings |
True | lm_head 与 embed_tokens 共享同一张表 |
3. 查表的两个方向
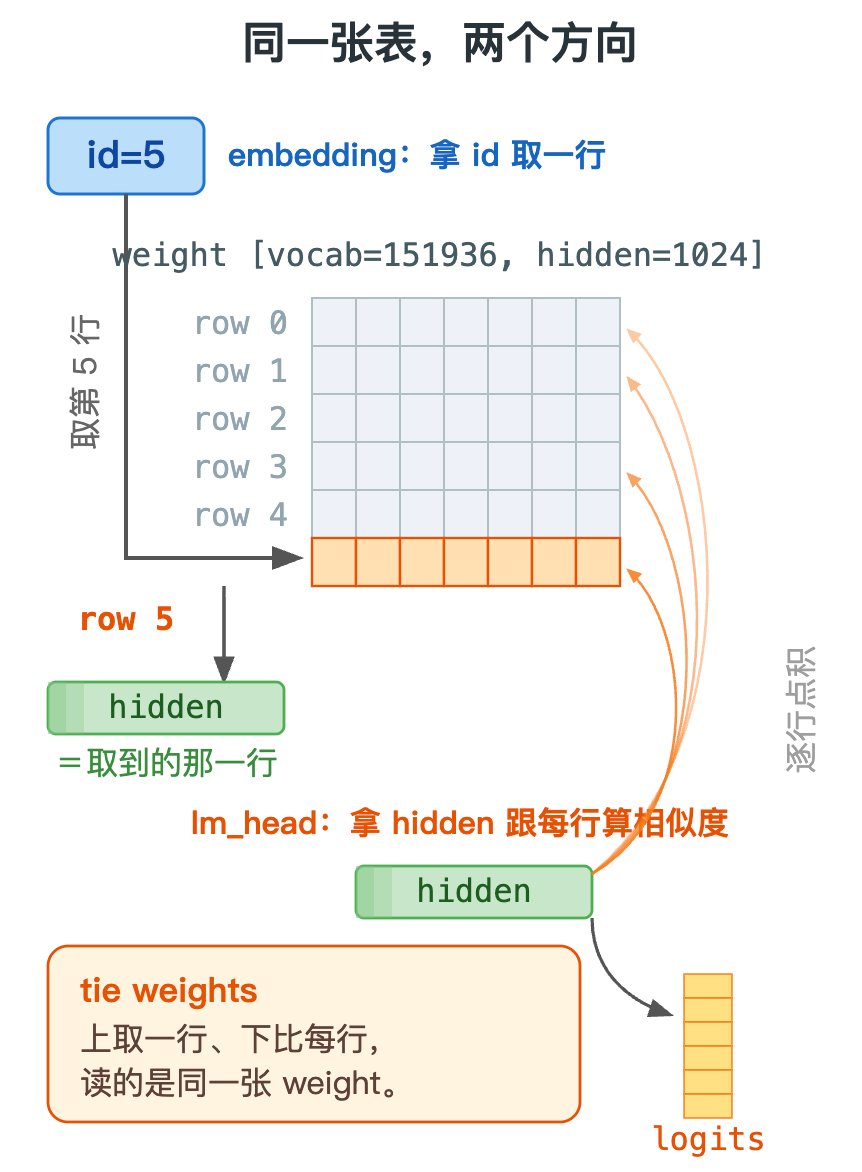
embedding 和 lm_head 共用一张 [vocab, hidden] 的权重表,区别只在用它的方向:embedding 拿一个 token id 去取表的一行 (得到这个 token 的向量),lm_head 拿一条 hidden 向量去跟表的每一行做内积(得到每个 token 的分数)。一个是「按行索引」,一个是「按行打分」,互为逆操作。
3.1 VocabParallelEmbedding:拿 id 取一行
把每个 token id 换成一条 hidden_size=1024 维向量。表是 [vocab, hidden],第 id 行就是这个 token 的向量;查表就是按行索引------F.embedding(ids, weight) 等价于 weight[ids]。
打个比方:一本字典,token id 是页码,翻到那一页就是这个词的向量。
为什么需要:模型只会算浮点向量,没法直接拿整数 id 做矩阵运算;得先把离散的 id 映射成连续向量,才能进残差流。
python
# VocabParallelEmbedding(embed_head.py 真实源码):本质是按行查表
import torch
from torch import nn
import torch.nn.functional as F
import torch.distributed as dist
class VocabParallelEmbedding(nn.Module):
def __init__(self, num_embeddings, embedding_dim):
super().__init__()
self.tp_rank = dist.get_rank() # 单卡 = 0
self.tp_size = dist.get_world_size() # 单卡 = 1
assert num_embeddings % self.tp_size == 0
self.num_embeddings = num_embeddings
self.num_embeddings_per_partition = num_embeddings // self.tp_size # 单卡=全表
self.vocab_start_idx = self.num_embeddings_per_partition * self.tp_rank # 单卡=0
self.vocab_end_idx = self.vocab_start_idx + self.num_embeddings_per_partition
# 这张表 [行数, hidden]:embedding 与 lm_head 共享它
self.weight = nn.Parameter(
torch.empty(self.num_embeddings_per_partition, embedding_dim))
self.weight.weight_loader = self.weight_loader
def forward(self, x):
if self.tp_size > 1: # ↓ vocab 维 TP,单卡不走
mask = (x >= self.vocab_start_idx) & (x < self.vocab_end_idx)
x = mask * (x - self.vocab_start_idx)
y = F.embedding(x, self.weight) # 单卡核心:按 id 取表的一行
if self.tp_size > 1: # ↑ vocab 维 TP,单卡不走
y = mask.unsqueeze(1) * y
dist.all_reduce(y)
return y
python
import torch
import torch.nn.functional as F
# 查表 = 按行索引:造一张小表验证
weight = torch.randn(10, 4) # 10 个 token、每个 4 维的小词表
ids = torch.tensor([3, 7, 3]) # 要查的 token id(可重复)
y = F.embedding(ids, weight) # embedding 的核心一句
print("F.embedding 等于按行取 :", torch.allclose(y, weight[ids])) # True
print("形状 [len(ids), hidden] :", tuple(y.shape)) # (3, 4)
# 预期:
# F.embedding 等于按行取 : True
# 形状 [len(ids), hidden] : (3, 4)F.embedding 等于按行取 : True
形状 [len(ids), hidden] : (3, 4)3.2 ParallelLMHead:拿 hidden 算分
残差流末端的 hidden 要变成每个 token 的分数 logits,交给采样器选下一个 token。lm_head 干这件事,方向正好和 embedding 相反。
是什么 :lm_head 拿一条 hidden 向量,跟权重表的每一行 做内积,得到 vocab=151936 个分数------F.linear(x, weight)。embedding 是「拿 id 取一行」,lm_head 是「拿向量跟每一行做内积」,一对逆操作。
打个比方:embedding 是查字典取词向量;lm_head 是拿一个向量去跟字典里每个词比相似度,给每个词打分。
为什么需要:要预测下一个 token,得先对整个词表打分,再交给采样器。
python
# ParallelLMHead(embed_head.py 真实源码):拿 hidden 跟表每行内积 + 取最后位
from nanovllm.utils.context import get_context
class ParallelLMHead(VocabParallelEmbedding): # 复用 embedding 的 weight 结构
def __init__(self, num_embeddings, embedding_dim, bias=False):
assert not bias
super().__init__(num_embeddings, embedding_dim)
def forward(self, x):
context = get_context() # 取本 step 元数据
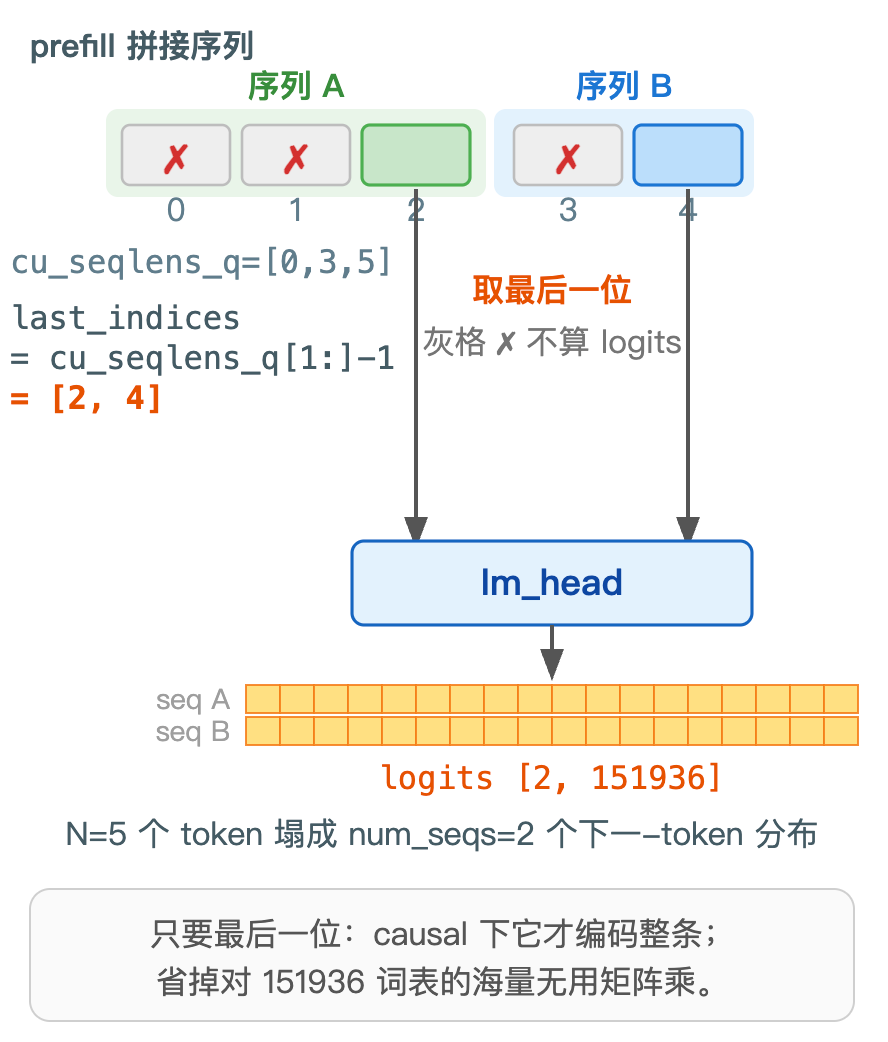
if context.is_prefill: # 取最后位:只留每条序列最后一个 token
last_indices = context.cu_seqlens_q[1:] - 1 # 每条序列末位下标
x = x[last_indices].contiguous()
logits = F.linear(x, self.weight) # 跟表每一行做内积 → vocab 个分数
if self.tp_size > 1: # ↓ vocab 维 TP:各卡局部 logits gather 到 rank0(后文介绍)
all_logits = [torch.empty_like(logits) for _ in range(self.tp_size)] if self.tp_rank == 0 else None
dist.gather(logits, all_logits, 0)
logits = torch.cat(all_logits, -1) if self.tp_rank == 0 else None
return logits
python
import torch
# prefill 两条序列拼在一起:A 3 个 token、B 2 个 token,共 N=5
cu_seqlens_q = torch.tensor([0, 3, 5]) # 累加边界(L11 算好)
last_indices = cu_seqlens_q[1:] - 1 # 每条序列最后一位的下标
print("last_indices :", last_indices.tolist()) # [2, 4]
hidden = torch.randn(5, 1024) # 5 个 token 的 hidden
picked = hidden[last_indices] # 只留位置 2、4
print("N 个 token 塌成 num_seqs :",
tuple(hidden.shape), "->", tuple(picked.shape)) # (5, 1024) -> (2, 1024)
# 预期:
# last_indices : [2, 4]
# N 个 token 塌成 num_seqs : (5, 1024) -> (2, 1024)last_indices : [2, 4]
N 个 token 塌成 num_seqs : (5, 1024) -> (2, 1024)4. 共享同一张表
前面说 embedding 和 lm_head 是一张表的两个方向。其实两者的 weight 指向的是同一块存储。
打个比方:进门查的字典和出门打分用的字典,是书架上同一本书,不是两本。
为什么需要:输入查表和输出打分本就是一张表的两个方向(取一行 vs 跟每行做内积),共享既省一整份参数、又让「token → 向量 → token」语义一致。
解决了什么 :vocab 151936 × hidden 1024 是张巨表,共享省掉整整一份参数(对 0.6B 这种小模型 embedding 占比很大);加载时也只需 safetensors 里的一份 embed_tokens.weight。
怎么解决 :__init__ 先建好两个模块、把 lm_head.weight 指到 embed 的 data;加载权重时,safetensors 里只有一份 model.embed_tokens.weight,copy_ 进这块共享存储后,lm_head 同时也就位了。
python
# 源码摘录
if config.tie_word_embeddings: # Qwen3-0.6B 为 True
self.lm_head.weight.data = self.model.embed_tokens.weight.data # 指向同一块存储5. 集成验证
加载真实 Qwen3-0.6B 的 embed_tokens 与 lm_head,验证本篇三件事:① embedding 查表就是按行索引、② lm_head 在 prefill 时只取每条序列最后一位算 logits、③ tie weights 让两者共享同一块存储。
python
import torch
import torch.distributed as dist
import torch.nn.functional as F
from modelscope import snapshot_download
from nanovllm.config import Config
from nanovllm.utils.context import set_context, reset_context
from nanovllm.engine.model_runner import ModelRunner
torch.cuda.set_device(0)
model_path = snapshot_download("Qwen/Qwen3-0.6B")
config = Config(model_path, enforce_eager=True, max_model_len=4096)
runner = ModelRunner(config, 0, [])
model = runner.model # Qwen3ForCausalLM(权重 bf16)
embed = model.model.embed_tokens # VocabParallelEmbedding
head = model.lm_head # ParallelLMHead
print("vocab / hidden :", tuple(embed.weight.shape)) # (151936, 1024)Downloading Model from https://www.modelscope.cn to directory: /root/.cache/modelscope/hub/models/Qwen/Qwen3-0.6B
2026-06-11 16:29:23,987 - modelscope - INFO - Target directory already exists, skipping creation.
vocab / hidden : (151936, 1024)
python
# ① embedding 查表 = 按行索引(真实词表)
ids = torch.tensor([100, 200, 300], device="cuda")
with torch.inference_mode():
y = embed(ids) # [3, 1024]
print("embed 查表 = 按行取 :",
torch.allclose(y, embed.weight[ids])) # True
print("形状 :", tuple(y.shape)) # (3, 1024)
# ③ tie weights:lm_head 与 embed 指向同一块存储
print("共享同一张表 :",
head.weight.data_ptr() == embed.weight.data_ptr()) # True
# 预期:
# embed 查表 = 按行取 : True
# 形状 : (3, 1024)
# 共享同一张表 : Trueembed 查表 = 按行取 : True
形状 : (3, 1024)
共享同一张表 : True
python
# ② lm_head 取最后位:构造 2 条序列的 hidden,走 prefill context
# 这不是真实前向(没跑中间层),只验证取最后位的选行与形状塌缩。
hidden = torch.randn(5, 1024, device="cuda", dtype=embed.weight.dtype) # 假 hidden
cu = torch.tensor([0, 3, 5], device="cuda", dtype=torch.int32) # A 3 + B 2 = 5
set_context(is_prefill=True, cu_seqlens_q=cu)
with torch.inference_mode():
logits = head(hidden) # 内部按 last_indices 切最后位再 F.linear
print("logits 形状塌成 num_seqs :", tuple(logits.shape)) # (2, 151936)
last_indices = (cu[1:] - 1).tolist() # [2, 4]
with torch.inference_mode():
expect = F.linear(hidden[last_indices], head.weight)
print("取最后位选行正确 :", torch.allclose(logits, expect)) # True
reset_context()
# 预期:
# logits 形状塌成 num_seqs : (2, 151936)
# 取最后位选行正确 : Truelogits 形状塌成 num_seqs : (2, 151936)
取最后位选行正确 : True6. 小结
残差流的首尾两端:开头 embed_tokens 拿 token id 查表取一行(输入端),结尾 lm_head 拿 hidden 跟同一张表每行做内积打分(输出端)。两者互为逆操作,tie_word_embeddings 让它们共享同一张 [vocab, hidden] 表。
一个要点:prefill 时 lm_head 用 cu_seqlens_q[1:]-1 只取每条序列最后一位算 logits------生成只看下一个 token,对全部位置算 × 151936 是白费;logits 形状因此从 [N 个 token, vocab] 变成 [序列条数, vocab],正好喂采样器。
下一篇讲解 decoder 层里剩下的 MLP:gate_up_proj 合并投影 → SiluAndMul → down_proj,也就是合并的 SwiGLU。