"我们知道B站之所以能够产生这么多好的作品,重要的原因就是社区里的用户有着对内容的热爱,并且有着对内容极高程度的审美。AI是可以放大B站社区这种识别优质内容的能力,现在社区每个月有170多亿次的真实用户的交互,这些数据在AI时代其实都是非常珍贵的真人标注,而且这些真人是整个中国对内容最有热情和最有审美鉴赏能力的人。"
哔哩哔哩2026年Q1财报电话会提到了上述内容。那么问题来了:能不能让AI学会像B站用户一样,在视频发布的第一时间就判断出它是否会获得社区共鸣?
今天我们介绍的 CASTER,就是在回答这个问题。这项工作已被 ACL 2026 Main Conference 收录,是bilibili Index LLM Team在UGC内容理解方向的最新成果。
代码链接:github.com/bilibili/me...
模型链接:huggingface.co/IndexTeam/M...
数据集链接:huggingface.co/datasets/In...
让AI学会「站在观众角度思考」
传统视频质量评估(VQA)看的是画面清不清晰、有没有压缩失真。但在B站社区里,一条视频好不好,靠的从来不是画质。一段画质普通但极具创意的手书,可能获得百万播放和满屏弹幕;一段4K高清的vlog,也可能因为内容空洞而无人问津。
UGC质量的本质是社区共识,而不是像素质量。
CASTER做的事情是:给定一条视频的多模态信息(封面、关键帧、标题、标签、ASR等),让AI模拟不同类型观众的反应,然后从这些模拟反应中推断出这条内容能不能获得社区认可。
Social-CoT:不是逻辑推理,是社会认知推理
Social-CoT是我们提出的核心推理机制。与传统CoT进行逻辑推理不同,Social-CoT进行的是社会认知推理:
第一步:实例化多元观众人设
模型需要想象不同类型的观众:资深爱好者、偶然路过的用户、对该领域感兴趣的新人、挑剔的老用户等。每个人设代表了社区中的一种典型视角。
第二步:模拟情感反应路径
对于每个观众人设,模型需要推理:这个人看完视频后会有什么感受?会被哪个片段打动?会想发什么样的评论?这不是简单的情感分类,而是深入的共情推理。
第三步:汇聚社区心智
综合所有模拟的观众反应,通过统计共识机制(Skellam Scoring)判断:这个内容是否能在社区层面产生正面共鸣?
这种"先模拟再判断"的结构,确保了最终的质量判断是从模拟的社区动态中因果推导出来的,而不是黑盒分类。下面是一个具体的Social-CoT示例:
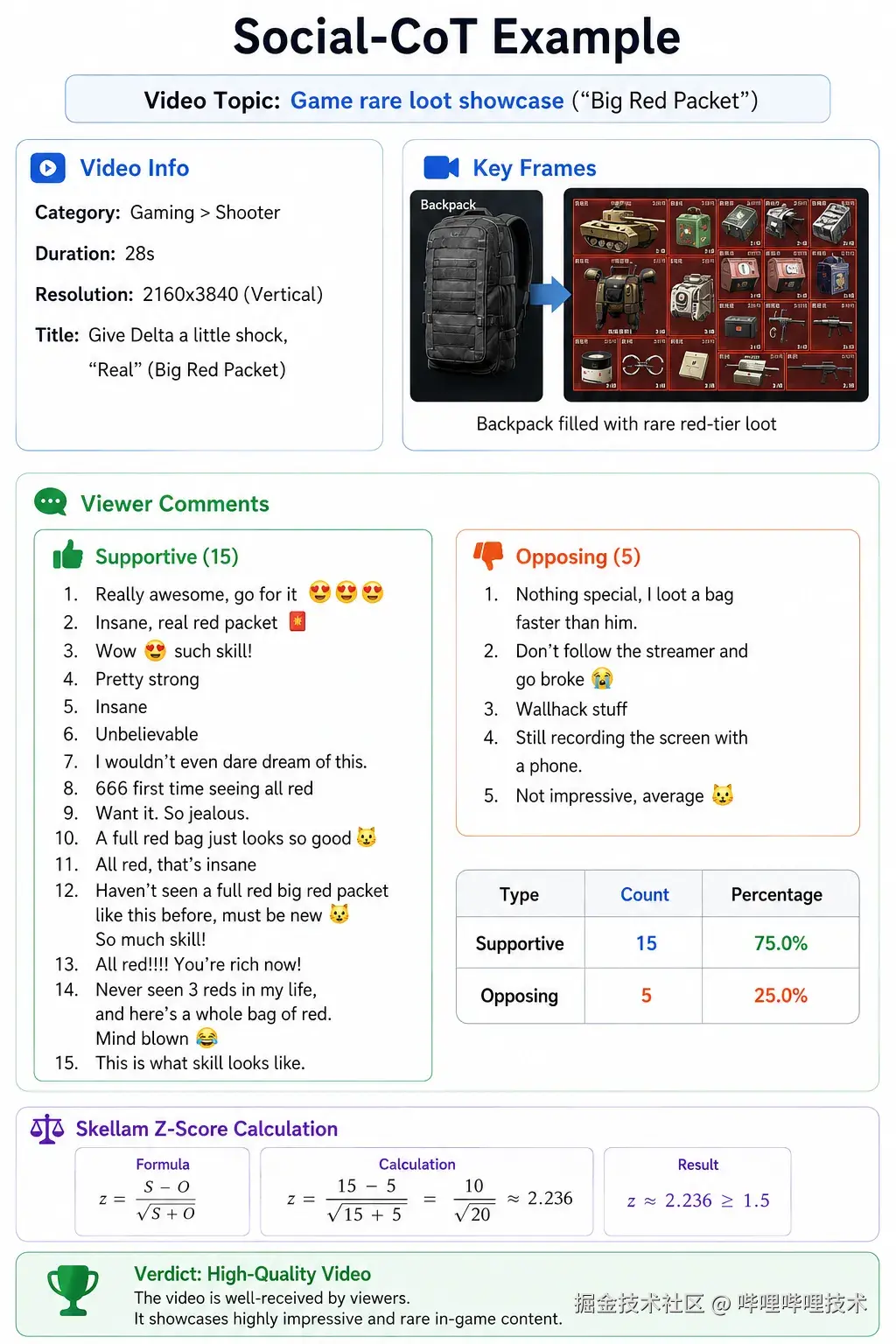
MEDEA框架
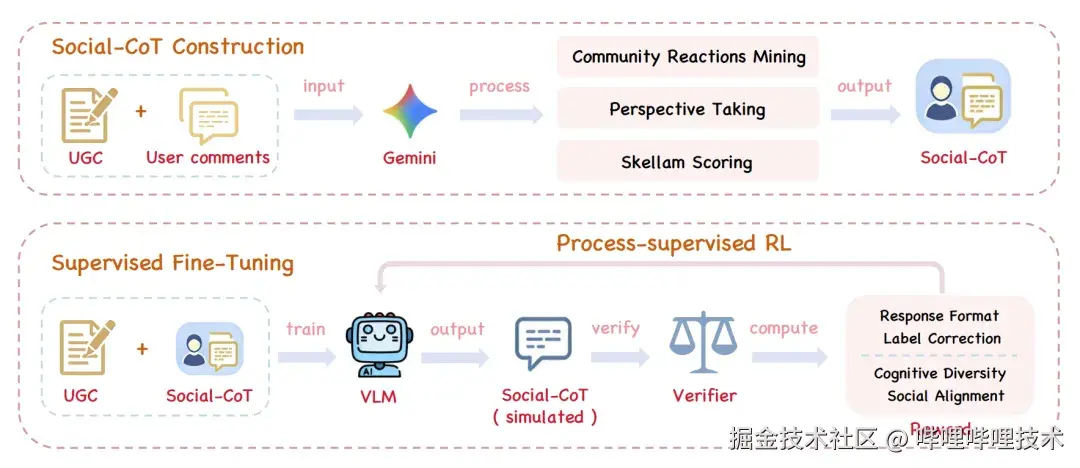
更进一步,我们把Social-CoT落地为可训练的系统,设计了MEDEA(Multimodal Engagement-Driven Evaluation Architecture)框架:
阶段一:挖掘真实社区智慧
基于B站生态用教师模型 (Gemini) 将社区智慧转换成结构化的Social-CoT推理路径,最终构建了54K条标注样本。
阶段二:SFT让模型学会Social-CoT的结构
通过监督微调,模型学会将视觉线索(光线、剪辑节奏)和文本信息(标题、标签)与社会解读对齐。
阶段三:RL对齐人类社区标准
使用GRPO算法 + 四维复合奖励:
- 格式奖励:输出遵循结构化格式
- 标签奖励:预测正确性
- 认知多样性约束:防止模型生成重复评论,必须探索完整分布
- 社会对齐奖励:模拟评论与真实高赞评论的语义相似度
其中社会对齐奖励是关键创新,没有它,模型会退化为生成「好美啊」「太棒了」这样的空泛模板;有了它,模型能生成具体且富有共情的解读,比如将冰岛vlog中风吹发丝的画面解读为「原始自然力量的震撼」。
CASTER-Bench:社区共鸣基准

为支持CASTER任务,我们发布了CASTER-Bench:
-
1485条UGC视频,覆盖30个主要内容品类(生活、知识、游戏、美食、科技、舞蹈等)
-
平均时长442秒(总时长182.5小时),远超现有VQA数据集的8-10秒短片
-
多模态信息完整:视频内容、封面图、标题、标签、分区、ASR
实验:全面超越GPT-5.2和Claude-4.5-opus
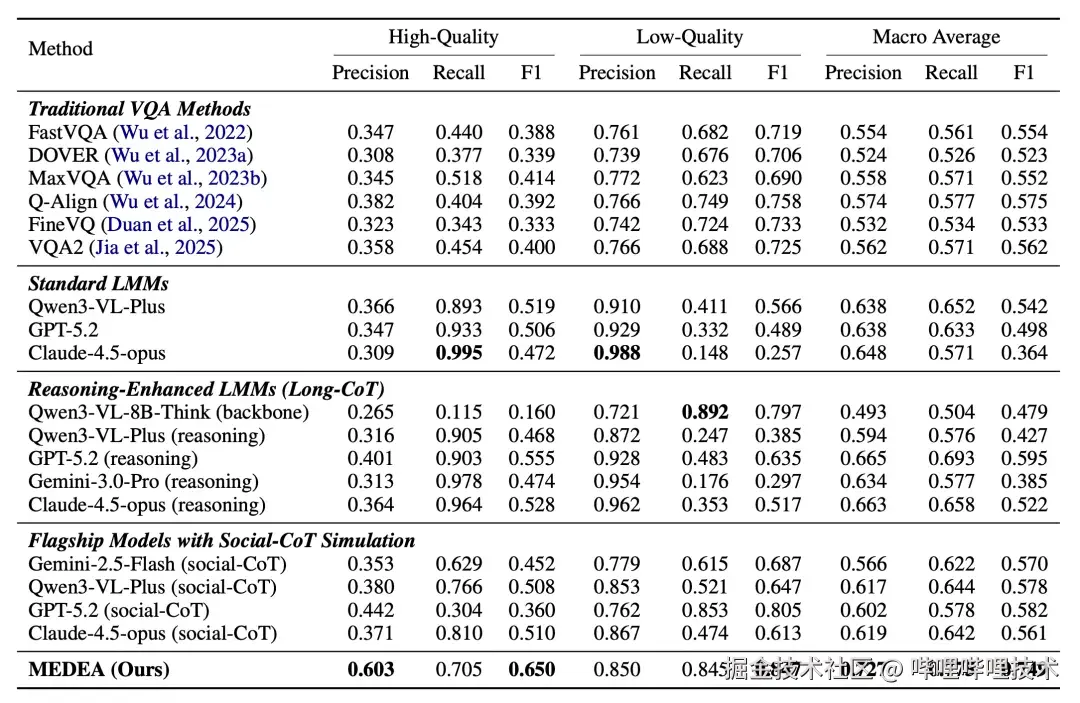
在CASTER-Bench上,MEDEA全面超越所有四类基线方法。
高质量类别(最关键指标):
-
MEDEA:F1 = 0.650,精确率 = 0.603,召回率 = 0.705
-
最强基线(GPT-5.2 reasoning):F1 = 0.555
-
提升幅度:+17.1%
各类基线的失败模式分析:
传统VQA方法(FastVQA、DOVER、MaxVQA等):
-
高质量F1仅0.33-0.41,几乎完全失效
-
原因:它们评估的是画面质量而非内容质量,信号层面的分析无法捕捉社区共鸣
标准大模型(GPT-5.2、Claude-4.5-Opus):
-
召回率极高(>90%)但精确率极低(~30%)
-
原因:"慷慨偏差":通过长上下文推理能在任何视频中找到优点,但缺乏区分"还行"和"真正优秀"的社会判断力
推理增强大模型(开启reasoning模式):
-
有所改善但仍不够(最高F1=0.555)
-
原因:逻辑推理能力不等于社会认知能力
Social-CoT提示的旗舰模型:
-
直接用Social-CoT提示词(不微调):F1=0.508
-
说明推理模式本身有帮助,但需要专门的训练才能真正内化"社区标准"
已在B站落地:更早发现优质内容
CASTER不只是一篇论文,它已经在B站的内容生态中实际部署运行。
通过将CASTER接入内容分发链路,系统能够在视频发布后的极早期(甚至在评论区形成之前),就识别出具有高社区共鸣潜力的优质稿件。这使得优质创作者的内容能更快地获得曝光,不再需要等待漫长的自然传播周期。
正如电话会议中提到:"我们花了很多时间让AI理解什么是高质量内容,并在更早的阶段识别这些高质量内容。" CASTER正是这一愿景的技术实现。
开发者交流
CASTER将于2026年7月5日在美国San Diego进行Poster展示,现场还会发放MEDEA精美无料,欢迎大家来交流!

-End-
作者丨bilibili Index LLM Team