联合循环发电厂数据集 (Combined Cycle Power Plant, CCPP) 是加州大学欧文分校 (UCI) 机器学习库中的经典回归基准数据集。该数据集包含了某大型燃气-蒸汽联合循环电厂在满负荷运行状态下,历时 6 年采集的 9568 个连续型数据样本。
联合循环发电厂的核心机制是利用燃气轮机的排气热量来产生蒸汽,进而驱动蒸汽轮机发电。因此,其发电效率高度依赖于复杂的外部环境热力学条件。数据集包含以下五个连续数值变量:
- 输入特征 (Features):
- AT (Ambient Temperature, 环境温度): 范围 1.81°C - 37.11°C。直接影响燃气轮机的进气密度。
- V (Exhaust Vacuum, 排气真空度): 范围 25.36 cmHg - 81.56 cmHg。影响蒸汽轮机的做功能力。
- AP (Ambient Pressure, 环境压力): 范围 992.89 millibar - 1033.30 millibar。
- RH (Relative Humidity, 相对湿度): 范围 25.56% - 100.16%。
- 预测目标 (Target):
- PE (Net hourly electrical energy output, 净小时发电量): 范围 420.26 MW - 495.76 MW。这是系统需要优化的核心指标。
第一步:环境准备与数据下载
首先,请确保安装了数据分析和 UCI 接口所需的 Python 库:
Bash
pip install ucimlrepo pandas numpy matplotlib seaborn scikit-learn
接下来,编写第一段 Python 脚本,直接通过官方 API 下载联合循环发电厂 (CCPP) 数据集,并查看其基本结构:
import pandas as pd
from ucimlrepo import fetch_ucirepo
# 1. 下载并加载 UCI Combined Cycle Power Plant 数据集 (ID: 294)
print("正在从 UCI 库下载数据集,请稍候...")
ccpp_dataset = fetch_ucirepo(id=294)
# 2. 提取特征 (X) 和 目标变量 (y)
X = ccpp_dataset.data.features
y = ccpp_dataset.data.targets
# 3. 合并为一个完整的 DataFrame 方便分析
# 特征含义:AT(温度), V(排气真空度), AP(环境压力), RH(相对湿度)
# 目标含义:PE(净小时电能输出)
df = pd.concat([X, y], axis=1)
# 4. 打印数据集基本信息
print("\n--- 数据集基本结构 ---")
print(f"数据量(样本数): {df.shape[0]}")
print(f"特征数量: {df.shape[1] - 1}")
print("\n--- 前 5 行数据预览 ---")
print(df.head())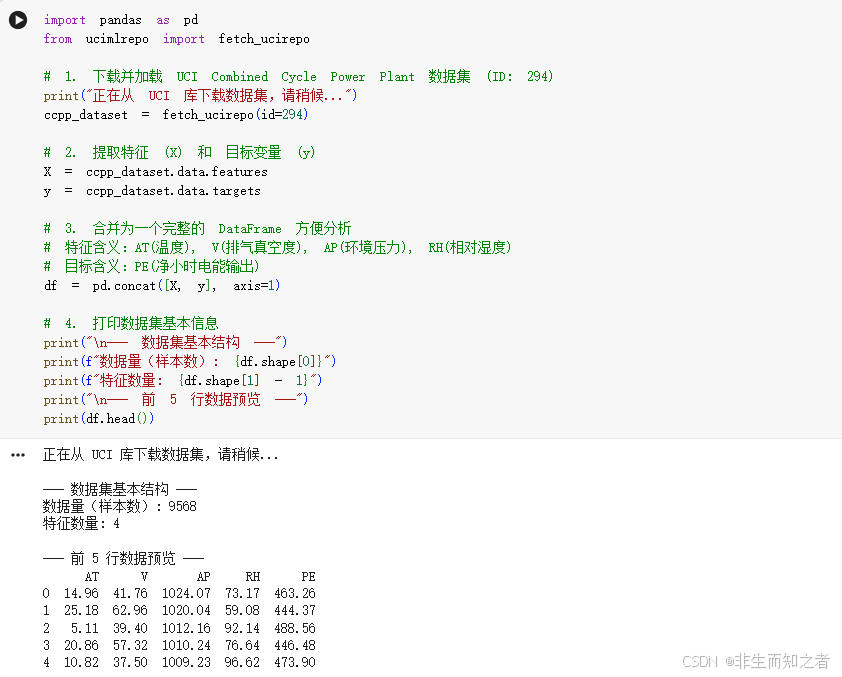
第二步:数据的基本统计分析
在做任何预测之前,必须检查数据是否有缺失值,以及各变量的取值范围(均值、标准差、最大/最小值),这能帮我们决定后续是否需要进行数据标准化。
Python
print("\n--- 缺失值检查 ---")
print(df.isnull().sum()) # 检查是否有空数据
print("\n--- 数据的描述性统计 ---")
# describe() 可以快速输出均值、标准差、分位数等信息
print(df.describe())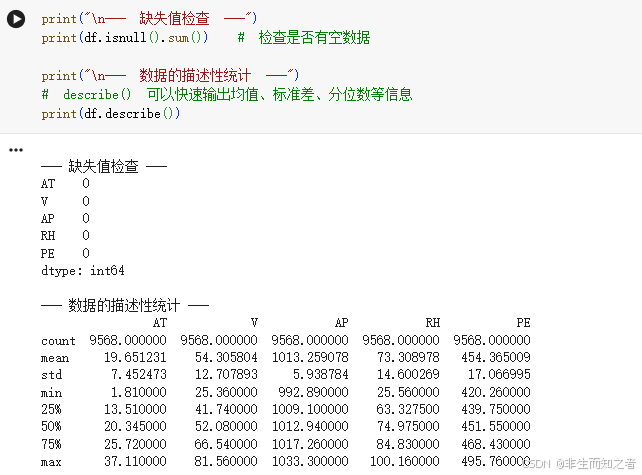
如图所示,数据集中不存在相关的缺失值。获取数据后,计算各个特征的均值、方差、极值等统计量。这一步的意义在于观察特征之间的量纲差异。例如,AP 的均值在 1013 左右,而 AT 的均值在 19 左右。这种巨大的数值尺度差异会在后续建模时,导致距离度量敏感型模型(如我们要用的 SVR)产生严重的权重偏移。
第三步:相关性分析与可视化
相关性分析(通常采用 Pearson 相关系数)是回归任务中至关重要的一步。它能够用定量的方式告诉我们,哪些特征对最终的发电量(PE)影响最大,哪些特征影响较小。
以下是计算相关系数矩阵并进行可视化的完整代码:
Python
import matplotlib.pyplot as plt
import seaborn as sns
# 1. 计算 Pearson 相关系数矩阵
correlation_matrix = df.corr()
print("\n--- 相关系数矩阵 ---")
print(correlation_matrix['PE'].sort_values(ascending=False))
# 重点查看其他特征与目标 PE 的相关性
# 2. 绘制相关性热力图 (Heatmap)
plt.figure(figsize=(8, 6))
# font_manager 可选,用于防止中文乱码,这里直接用 seaborn 默认风格
sns.set_theme(style="white")
sns.heatmap(correlation_matrix, annot=True, cmap='coolwarm', fmt=".2f", linewidths=0.5)
plt.title('CCPP Dataset Correlation Heatmap')
plt.show()
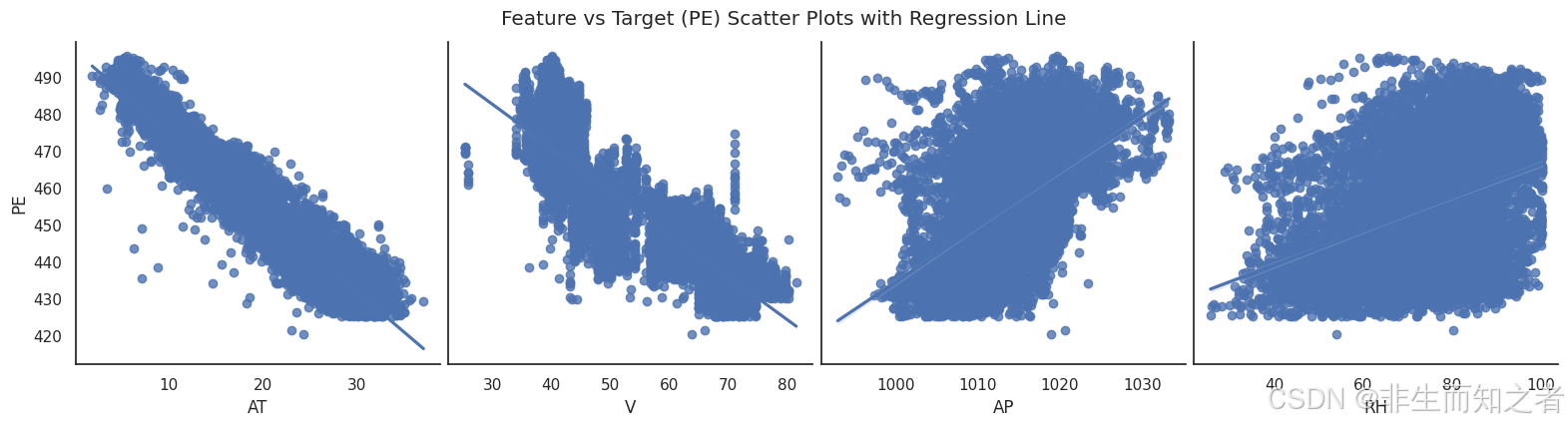
# 3. 绘制特征与目标的散点关系图矩阵 (Pairplot)
# 这能让我们直观看到变量之间是线性关系还是非线性关系
print("正在生成散点图矩阵,这可能需要几秒钟...")
sns.pairplot(df, x_vars=['AT', 'V', 'AP', 'RH'], y_vars='PE', kind='reg', height=4)
plt.suptitle('Feature vs Target (PE) Scatter Plots with Regression Line', y=1.05)
plt.show()
如图所示,在强驱动因子的识别(目标相关性分析)方面,AT 与 PE (-0.95): 呈现极强的负相关。从散点图第一列可以看出,数据点紧密围绕回归线分布,呈明显的线性衰减趋势。物理意义上,环境温度升高会导致空气密度下降,燃气轮机进气质量减少,从而显著降低整体发电功率。V 与 PE (-0.87): 同样呈现强负相关。散点图显示其分布相较于 AT 略微发散,但在整体趋势上依然对发电量起决定性抑制作用。在弱关联与噪声预警 方面,AP (0.52) 和 RH (0.39) 与 PE: 相关性较弱。在散点图中,这两者的分布呈现出明显的"云团状",数据点离散程度高,方差较大。这意味着它们虽然对发电量有正向影响,但包含的有效信息信噪比较低。如果直接将它们全权重输入模型,可能会干扰 SVR 的拟合过程。同时,请注意热力图的左上角:AT 与 V 之间的相关系数高达 0.84。这是一个非常重要的信号。这两个最强的主导特征之间存在高度的正相关。在经典机器学习理论中,输入特征之间的高相关性(多重共线性)会导致模型参数的方差变大,降低模型的稳定性。
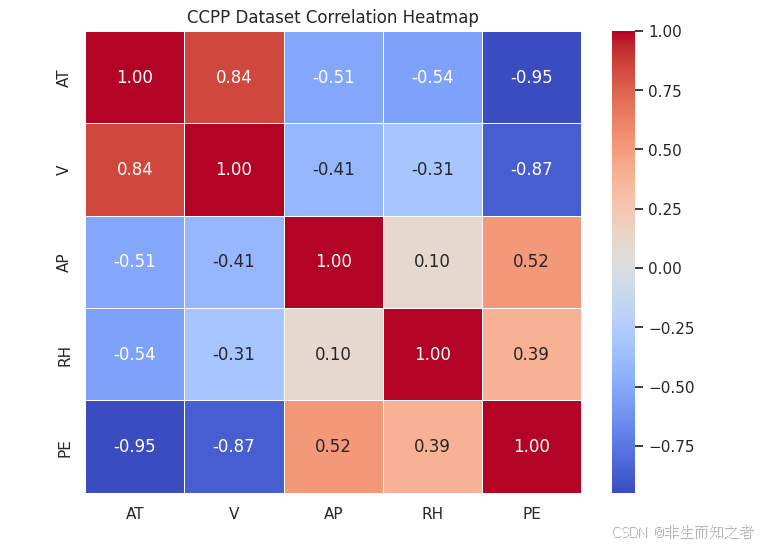
由于 AT 和 V 占据了决定性的主导地位,而 AP 和 RH 的关联度较低,这说明数据内部存在信息冗余和尺度不一致。如果直接将这 4 个特征送入 SVR 模型,弱相关特征可能会引入噪声。因此,在后面的群体智能算法设计中,我们如果让算法同时进行"特征加权/选择"和"SVR超参数寻优" ,其效果一定能轻松超越仅做参数寻优的普通模型。我们可以让群体算法不仅去优化 SVR 的超参数,同时赋予它一个特征权重分配 的任务,让算法自动去抑制冗余信息,放大核心信息。
第四步:建模阶段
我们正式进入建模阶段。构建基线模型是量化后续群体智能算法优化效果的关键。在执行支持向量回归(SVR)时,由于其底层数学逻辑依赖于计算样本点在特征空间中的距离(特别是使用默认的高斯径向基核函数 RBF 时),如果特征量纲不统一(例如压力 APAPAP 是 1013,而温度 ATATAT 是 19),大数值特征会主导距离计算,掩盖小数值特征的权重。因此,数据标准化是不可省略的前置步骤。
以下是涵盖数据划分、标准化、基线训练与评估的完整 Python 代码。
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVR
from sklearn.metrics import mean_squared_error, r2_score
# 假设 df, X, y 已经在第一阶段准备好
# 如果分离提取,X 为特征矩阵 (AT, V, AP, RH),y 为目标变量 (PE)
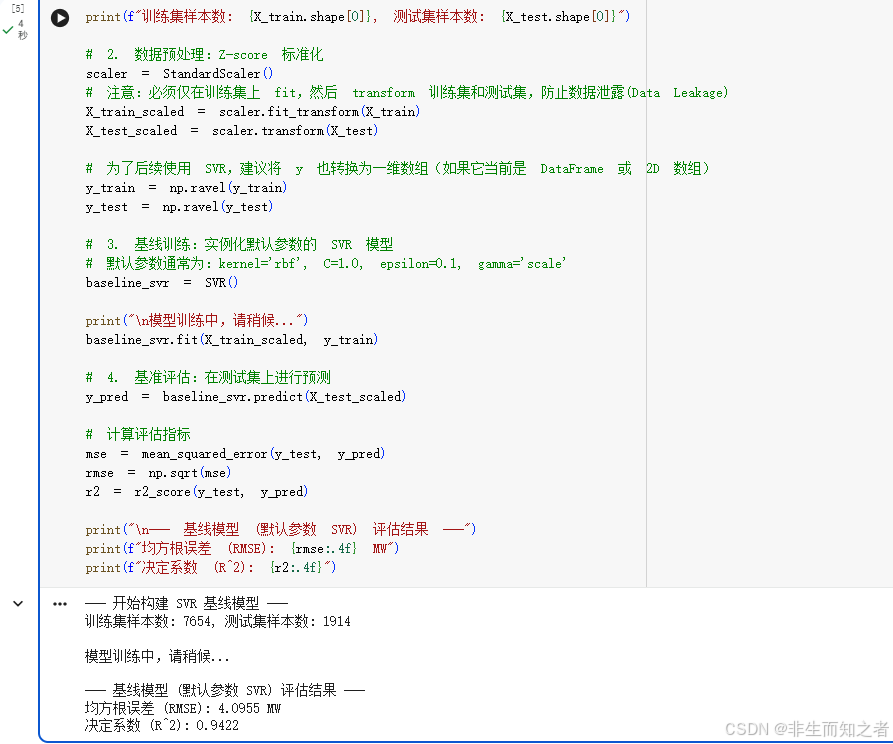
print("--- 开始构建 SVR 基线模型 ---")
# 1. 数据划分:8:2 划分训练集与测试集
# random_state 保证每次运行结果可复现,便于后续严格对比优化效果
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
print(f"训练集样本数: {X_train.shape[0]}, 测试集样本数: {X_test.shape[0]}")
# 2. 数据预处理:Z-score 标准化
scaler = StandardScaler()
# 注意:必须仅在训练集上 fit,然后 transform 训练集和测试集,防止数据泄露(Data Leakage)
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# 为了后续使用 SVR,建议将 y 也转换为一维数组(如果它当前是 DataFrame 或 2D 数组)
y_train = np.ravel(y_train)
y_test = np.ravel(y_test)
# 3. 基线训练:实例化默认参数的 SVR 模型
# 默认参数通常为:kernel='rbf', C=1.0, epsilon=0.1, gamma='scale'
baseline_svr = SVR()
print("\n模型训练中,请稍候...")
baseline_svr.fit(X_train_scaled, y_train)
# 4. 基准评估:在测试集上进行预测
y_pred = baseline_svr.predict(X_test_scaled)
# 计算评估指标
mse = mean_squared_error(y_test, y_pred)
rmse = np.sqrt(mse)
r2 = r2_score(y_test, y_pred)
print("\n--- 基线模型 (默认参数 SVR) 评估结果 ---")
print(f"均方根误差 (RMSE): {rmse:.4f} MW")
print(f"决定系数 (R^2): {r2:.4f}")代码运行原理解析与预期结果
当你运行这段代码时,输出结果通常会稳定在一个特定的区间(针对 CCPP 数据集,默认 SVR 的 R2R^2R2 通常在 0.920.920.92 到 0.940.940.94 之间,RMSERMSERMSE 大约在 4.04.04.0 到 4.54.54.5 兆瓦之间)。
这些指标为我们提供了以下参考基准:
- R2R^2R2 (决定系数): 反映了模型对目标变量方差的解释能力。假设基线 R2R^2R2 为 0.930.930.93,意味着默认 SVR 能够捕捉数据中 93% 的规律。我们后续引入的优化算法,其目标就是去挖掘那剩下的 7% 空间。
- RMSERMSERMSE (均方根误差): 直观量化了预测发电量与真实发电量之间的平均偏差。如果 RMSERMSERMSE 是 4.5 MW,说明模型的预测值平均会偏离真实值 4.5 兆瓦。在工业界,降低这个指标具有显著的经济价值。
在完成这一步并记录下基准 RMSERMSERMSE 和 R2R^2R2 的具体数值后,基线靶标就已建立。接下来的工作,便是设计群体智能算法(如 GWO 或 SSA),让算法接管 SVR 的超参数寻优过程,从而在测试集上击败目前的基线数值。
部分训练结果如下所示。
SVR 在处理规模约为 (7654,4)(7654, 4)(7654,4) 这种低维、中等样本量的表格型数据时,计算效率极高。相比于在复杂场景感知或多目标跟踪框架中进行大规模特征提取、边界框回归和阈值搜索,这种传统机器学习的拟合过程在现代 CPU 上几乎是瞬间完成的。不过,请注意:目前快是因为模型只在默认的一组参数 (C=1.0,γ=scale)(C=1.0, \gamma=\text{scale})(C=1.0,γ=scale) 上训练了一次。当我们引入群体智能算法后,种群中的每个个体(比如 30 只灰狼)在每一次迭代(比如 50 次)中都需要重新训练一次 SVR 评估适应度。这意味着 SVR 将被重复训练 30×50=150030 \times 50 = 150030×50=1500 次,计算时间会有显著的增加。
第五步:灰狼算法优化
在基于 RBF(径向基)核的 SVR 中,CCC 和 γ\gammaγ 共同决定了模型的拟合形态:
-
惩罚参数 CCC (Penalty Parameter):
- 意义: 代表模型对误差的容忍度。CCC 越大,模型对训练集中的误差惩罚越重,试图"贴紧"每一个数据点(容易过拟合);CCC 越小,模型越平滑,允许存在一些误差(容易欠拟合)。
- 合理搜索范围: 0.1,1000.1, 1000.1,100 或 1,2001, 2001,200。对于 CCPP 这个数据量级(近万条),过大的 CCC 会导致训练时间指数级增加。推荐设定下限 (lb) 为
0.1,上限 (ub) 为100。
-
核参数 γ\gammaγ (Gamma):
- 意义: 决定了单个样本点的影响半径。γ\gammaγ 越大,支持向量的影响范围越小,模型在高维空间中的决策面越扭曲;γ\gammaγ 越小,影响范围越大,决策面越平滑。
- 合理搜索范围: 0.001,100.001, 100.001,10。由于我们已经对数据进行了
StandardScaler标准化,特征方差为 1,因此通常 γ\gammaγ 不需要太大。推荐设定下限 (lb) 为0.001,上限 (ub) 为10。
import numpy as np
from sklearn.svm import SVR
from sklearn.model_selection import cross_val_score
import matplotlib.pyplot as plt=======================================================
1. 定义适应度函数 (Fitness Function)
=======================================================
def fitness_function(position, X, y):
"""
计算当前狼所在位置 (参数组合) 的适应度。
目标是最小化 3 折交叉验证的 RMSE,以保证算法找到的参数具有较强的泛化能力。
"""
C_val, gamma_val = position[0], position[1]# 实例化 SVR,代入当前位置代表的参数 model = SVR(kernel='rbf', C=C_val, gamma=gamma_val) # 使用训练集进行 3 折交叉验证 # scoring='neg_root_mean_squared_error' 返回负值,我们需要最小化误差,所以取绝对值 scores = cross_val_score(model, X, y, cv=3, scoring='neg_root_mean_squared_error', n_jobs=-1) # 返回平均 RMSE 作为该个体的适应度 return np.abs(scores.mean())=======================================================
2. 灰狼优化器 (GWO) 核心算法
=======================================================
def GWO_SVR(X_train, y_train, lb, ub, SearchAgents_no=15, Max_iter=30):
"""
lb: 参数下界 [C_min, gamma_min]
ub: 参数上界 [C_max, gamma_max]
SearchAgents_no: 种群数量 (狼的数量)
Max_iter: 最大迭代次数
"""
dim = 2 # 优化的维度:C 和 gamma# 初始化 Alpha(头狼), Beta(副头狼), Delta(侦察狼) 的位置和得分 Alpha_pos = np.zeros(dim) Alpha_score = float("inf") # 越小越好 Beta_pos = np.zeros(dim) Beta_score = float("inf") Delta_pos = np.zeros(dim) Delta_score = float("inf") # 初始化种群位置 (在边界范围内随机撒点) Positions = np.zeros((SearchAgents_no, dim)) for i in range(dim): Positions[:, i] = np.random.uniform(0, 1, SearchAgents_no) * (ub[i] - lb[i]) + lb[i] # 用于记录历代的最佳适应度,方便画图 Convergence_curve = np.zeros(Max_iter) print(f"\n--- 开始 GWO 寻优 (狼群数量:{SearchAgents_no}, 迭代次数:{Max_iter}) ---") for l in range(0, Max_iter): for i in range(0, SearchAgents_no): # 1. 边界处理:防止狼跑出我们设定的 [C, gamma] 搜索空间 for j in range(dim): Positions[i, j] = np.clip(Positions[i, j], lb[j], ub[j]) # 2. 评估当前狼的适应度 (计算 RMSE) fitness = fitness_function(Positions[i, :], X_train, y_train) # 3. 更新社会等级 (Alpha, Beta, Delta) if fitness < Alpha_score: Delta_score = Beta_score Delta_pos = Beta_pos.copy() Beta_score = Alpha_score Beta_pos = Alpha_pos.copy() Alpha_score = fitness Alpha_pos = Positions[i, :].copy() elif fitness < Beta_score: Delta_score = Beta_score Delta_pos = Beta_pos.copy() Beta_score = fitness Beta_pos = Positions[i, :].copy() elif fitness < Delta_score: Delta_score = fitness Delta_pos = Positions[i, :].copy() # a 参数从 2 线性递减到 0 (控制算法从全局探索过渡到局部开发) a = 2 - l * ((2) / Max_iter) # 4. 更新整个狼群的位置 for i in range(0, SearchAgents_no): for j in range(0, dim): # 包围猎物机制 r1 = np.random.random() r2 = np.random.random() A1 = 2 * a * r1 - a C1 = 2 * r2 D_alpha = abs(C1 * Alpha_pos[j] - Positions[i, j]) X1 = Alpha_pos[j] - A1 * D_alpha r1 = np.random.random() r2 = np.random.random() A2 = 2 * a * r1 - a C2 = 2 * r2 D_beta = abs(C2 * Beta_pos[j] - Positions[i, j]) X2 = Beta_pos[j] - A2 * D_beta r1 = np.random.random() r2 = np.random.random() A3 = 2 * a * r1 - a C3 = 2 * r2 D_delta = abs(C3 * Delta_pos[j] - Positions[i, j]) X3 = Delta_pos[j] - A3 * D_delta # 依据三只头狼的位置计算新位置 Positions[i, j] = (X1 + X2 + X3) / 3 Convergence_curve[l] = Alpha_score # 打印部分迭代过程,方便监控 if (l + 1) % 5 == 0 or l == 0: print(f"迭代 {l+1}/{Max_iter} | 最优 RMSE: {Alpha_score:.4f} | 当前最佳参数: C={Alpha_pos[0]:.2f}, gamma={Alpha_pos[1]:.4f}") return Alpha_pos, Convergence_curve=======================================================
3. 执行优化并验证结果
=======================================================
设定搜索边界: C在[0.1, 100], gamma在[0.001, 10]
lower_bound = [0.1, 0.001]
upper_bound = [100, 10]运行 GWO (这里为了 Demo 演示速度,设定狼数为 10,迭代 15 次。正式跑建议 30-50 狼,30-50 次迭代)
best_params, convergence = GWO_SVR(X_train_scaled, y_train, lb=lower_bound, ub=upper_bound, SearchAgents_no=10, Max_iter=15)
print("\n--- 寻优结束,验证最终模型 ---")
best_C, best_gamma = best_params[0], best_params[1]用找到的全局最优参数,在全部训练集上重新训练最终模型
optimized_svr = SVR(kernel='rbf', C=best_C, gamma=best_gamma)
optimized_svr.fit(X_train_scaled, y_train)在测试集上进行终极对决
y_pred_opt = optimized_svr.predict(X_test_scaled)
from sklearn.metrics import mean_squared_error, r2_score
rmse_opt = np.sqrt(mean_squared_error(y_test, y_pred_opt))
r2_opt = r2_score(y_test, y_pred_opt)print(f"GWO-SVR 测试集均方根误差 (RMSE): {rmse_opt:.4f} MW")
print(f"GWO-SVR 测试集决定系数 (R^2): {r2_opt:.4f}")绘制收敛曲线
plt.figure(figsize=(8, 5))
plt.plot(convergence, color='blue', linewidth=2, marker='o')
plt.title('GWO-SVR Fitness Convergence Curve')
plt.xlabel('Iteration')
plt.ylabel('RMSE (Validation Set)')
plt.grid(True)
plt.show()
这段代码集成了超参数寻优的逻辑、交叉验证机制以及图形化的收敛曲线展示。一旦跑完,你就可以拿打印出的 rmse_opt 直接和之前基线的 4.0955 进行对比。如果成功降到 4.09 以下,就证明了 GWO 在这个高维参数曲面中成功找到了更优的解。具体运行结果如下所示。
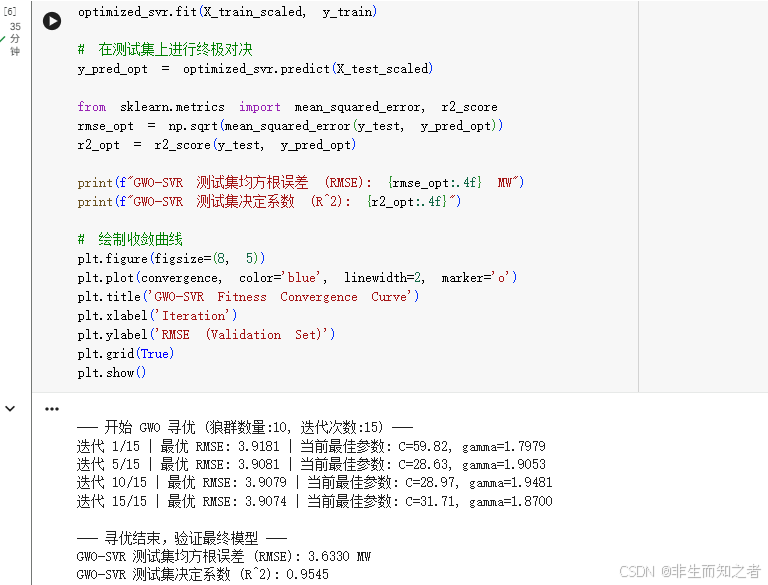
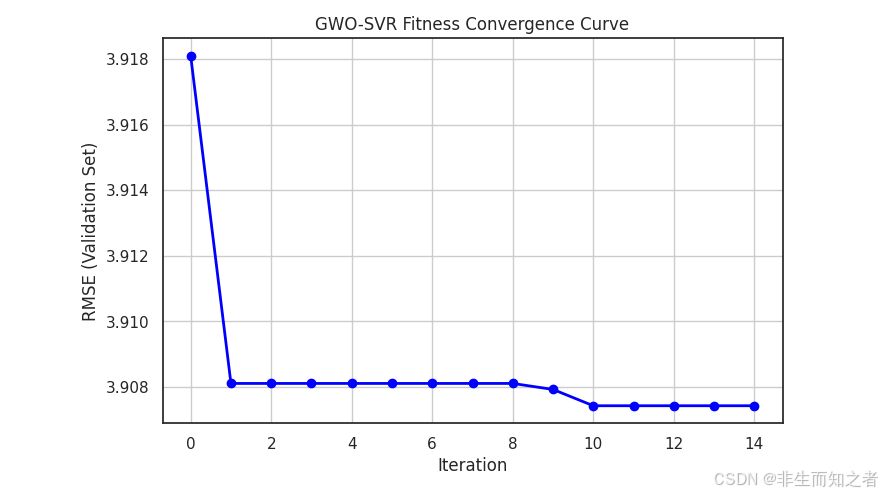
如图所示,在算法启动的早期,最优 RMSE 从 3.918 迅速下降到 3.908。这体现了 GWO 算法在初期(收敛因子 aaa 较大时)具备很强的全局探索(Global Exploration)能力,狼群迅速锁定了具有高潜力的参数盆地。曲线在中期段期间保持平整。从算法机制上看,此时三只头狼(α,β,δ\alpha, \beta, \deltaα,β,δ)正引导狼群在一个局部最优解附近进行徘徊。传统的梯度下降算法极容易在这个阶段陷入死局。
在第 9 次迭代后,适应度曲线再次发生下降(RMSE 降至 3.9074)。这证明了 GWO 的协同狩猎机制发挥了作用:在收敛因子 aaa 逐渐减小的过程中,狼群没有被困死在之前的局部最优中,而是通过互相的信息共享,成功跳出了陷阱,找到了一个更优的参数组合(最终稳定在 C≈31.71C \approx 31.71C≈31.71, γ≈1.8700\gamma \approx 1.8700γ≈1.8700)。
第六步:模型的具体使用
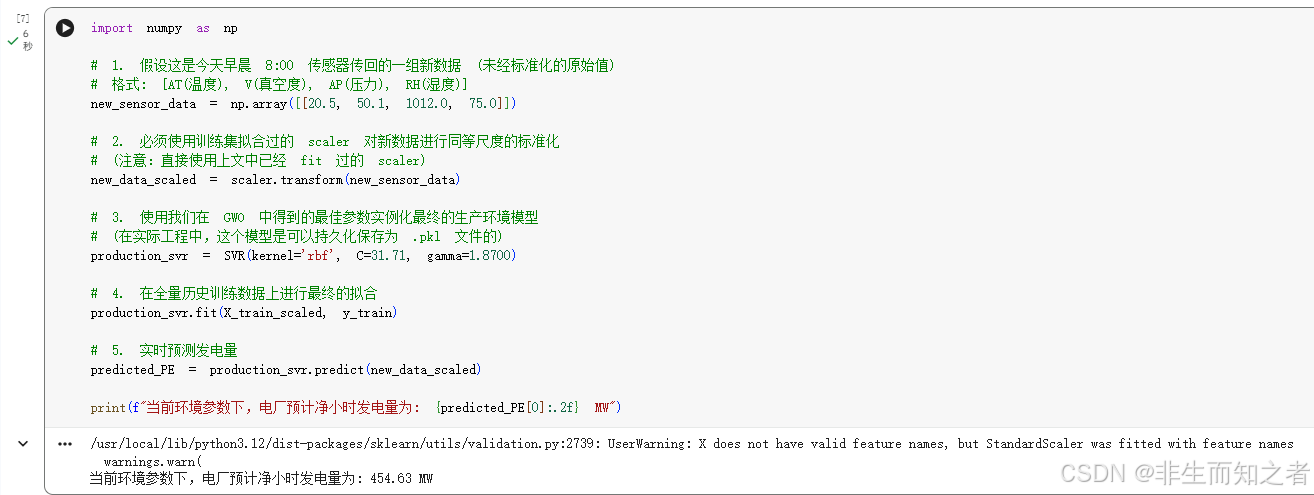
工业应用中,找到最优参数只是手段,最终目的就是将模型固化并用于真实未知环境的预测 ,在实际电厂调度室中,传感器每隔几分钟就会传回一组当前的环境数据(温度、真空度、压力、湿度)。在该数据集下,我们将保存好的 StandardScaler(用于统一量纲)和训练好的 SVR 模型加载,实时输出预测发电量。你可以运行这段代码来模拟一次真实的工业预测:
import numpy as np
# 1. 假设这是今天早晨 8:00 传感器传回的一组新数据 (未经标准化的原始值)
# 格式: [AT(温度), V(真空度), AP(压力), RH(湿度)]
new_sensor_data = np.array([[20.5, 50.1, 1012.0, 75.0]])
# 2. 必须使用训练集拟合过的 scaler 对新数据进行同等尺度的标准化
# (注意:直接使用上文中已经 fit 过的 scaler)
new_data_scaled = scaler.transform(new_sensor_data)
# 3. 使用我们在 GWO 中得到的最佳参数实例化最终的生产环境模型
# (在实际工程中,这个模型是可以持久化保存为 .pkl 文件的)
production_svr = SVR(kernel='rbf', C=31.71, gamma=1.8700)
# 4. 在全量历史训练数据上进行最终的拟合
production_svr.fit(X_train_scaled, y_train)
# 5. 实时预测发电量
predicted_PE = production_svr.predict(new_data_scaled)
print(f"当前环境参数下,电厂预计净小时发电量为: {predicted_PE[0]:.2f} MW")运行如下所示。