目录
1.2与进程之间的切换相比,线程之间的切换需要操作系统做的工作要少很多

在计算机并发编程领域,进程与线程是支撑系统并发执行的两大核心基础单元,而线程凭借轻量化的特性,成为当下高并发业务场景的首选并发方案。相较于传统进程,线程在资源占用、调度效率上具备显著差异化优势,能够极大降低系统调度开销、提升硬件资源利用率。但任何技术都存在双面性,线程并非适配所有场景,其共享资源的运行特性也带来了数据竞争、程序稳定性下降等一系列问题。为了清晰厘清线程的技术特性与适用边界,本文将从性能原理、优缺点及实际落地场景出发,全面剖析线程的核心机制与使用要点。
一线程的优点
1.1创建和删除一个新线程的代价要比创建一个新进程小得多
进程是资源分配的最小单位,线程是CPU调度的最小单位。 创建一个新进程相当于"另起炉灶"(需要为进程分配独立的地址空间,PCB......),而创建一个新线程相当于"在现有炉灶上多加一个灶眼"(只需分配一个tcb)。
1.2与进程之间的切换相比,线程之间的切换需要操作系统做的工作要少很多
CPU上下文切换时,需要保存和恢复的内容有寄存器状态,内存管理单元(MMU)状态,还会影响cpu缓存的内容。
1)最主要的区别是线程的切换虚拟内存空间依然是相同的,但是进程切换是不同的。这两种上
下文切换的处理都是通过操作系统内核来完成的。内核的这种切换过程伴随的最显著的性能
损耗是将寄存器中的内容切换出。将寄存器中的内容切换出是固定开销 ,但是MMU相关寄存器(如CR3)只有进程切换才需要切换。注意寄存器切换的损耗本身,不是造成进程切换比线程切换慢几十倍甚至上百倍的原因 。如果只算切出/切入寄存器的损耗,而不考虑缓存和TLB失效,那么进程和线程切换的代价相差很小,几乎可以忽略不计。
2)另外一个隐藏的损耗是上下文的切换会扰乱处理器的缓存机制。 简单的说,一旦去切换上下
文,处理器中所有已经缓存的内存地址一瞬间都作废了。还有一个显著的区别是当你改变虚
拟内存空间的时候,处理的页表缓冲TLB (快表)会被全部刷新,这将导致内存的访问在一
段时间内相当的低效。但是在线程的切换中,不会出现这个问题,当然还有硬件cache。
cpu缓存(缓存最近使用的数据和指令)
指令:lscpu 查看缓存信息
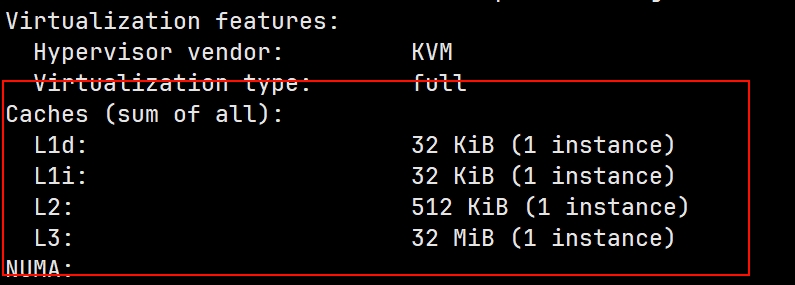
局部性原理:
CPU缓存很小(L1只有32KB,L2几百KB),而主存很大(16GB以上)。但现代CPU运行程序时,90%以上的内存访问都能在缓存中直接命中,而不是去慢得多的主存。
cpp
// 好局部性:顺序访问数组
int a[10000];
for (int i = 0; i < 10000; i++) {
a[i] = i; // 每次访问a[i]时,缓存都"恰好"已经包含了它
}缓存并不知道你会访问a[1],但它利用了空间局部性 ------当访问a[0]时,硬件一次性把a[0]及其附近的一整块数据(缓存行,通常64字节) 都加载到缓存中。
缓存本质上就是一种预加载机制 ,它基于一个核心假设:"你刚刚用过的数据,以及它旁边的数据,在不久的将来很可能也会被用到"。这就是局部性原理。
上下文切换时:
-
如果是 线程切换(同一进程内):新线程可以直接复用旧线程留下的缓存数据,因为这些数据对应的物理页属于同一个进程。
-
如果是 进程切换(不同进程间):旧进程的数据仍然留在缓存中,但新进程无法使用,因为对应的物理页属于另一个进程。新进程必须用自己的数据覆盖它们。
cpu怎么判断切换的是进程还是线程?
时间片决定切换的是进程还是线程。时间片是操作系统为每个调度单位(通常是线程,在某些简单操作系统中是进程)分配的CPU执行时间配额。

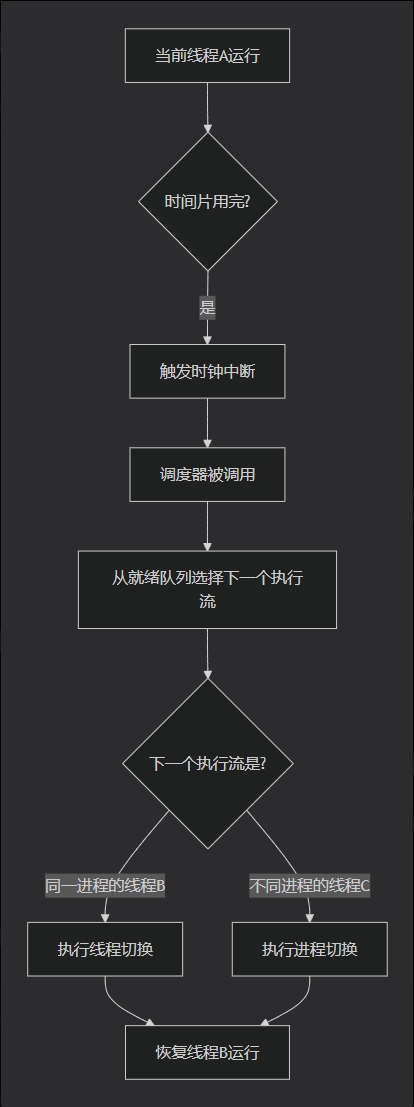
线程时间片在进程时间片里是平分的。时间片耗尽就除法调度。根据切换类型看会不会导致缓存失效。
MMU缓存(缓存最近使用的页表项)
TLB(Translation Lookaside Buffer,快表)是MMU内部的一个小容量、高速度的缓存 ,用于存储虚拟地址到物理地址的转换结果(即页表项)。
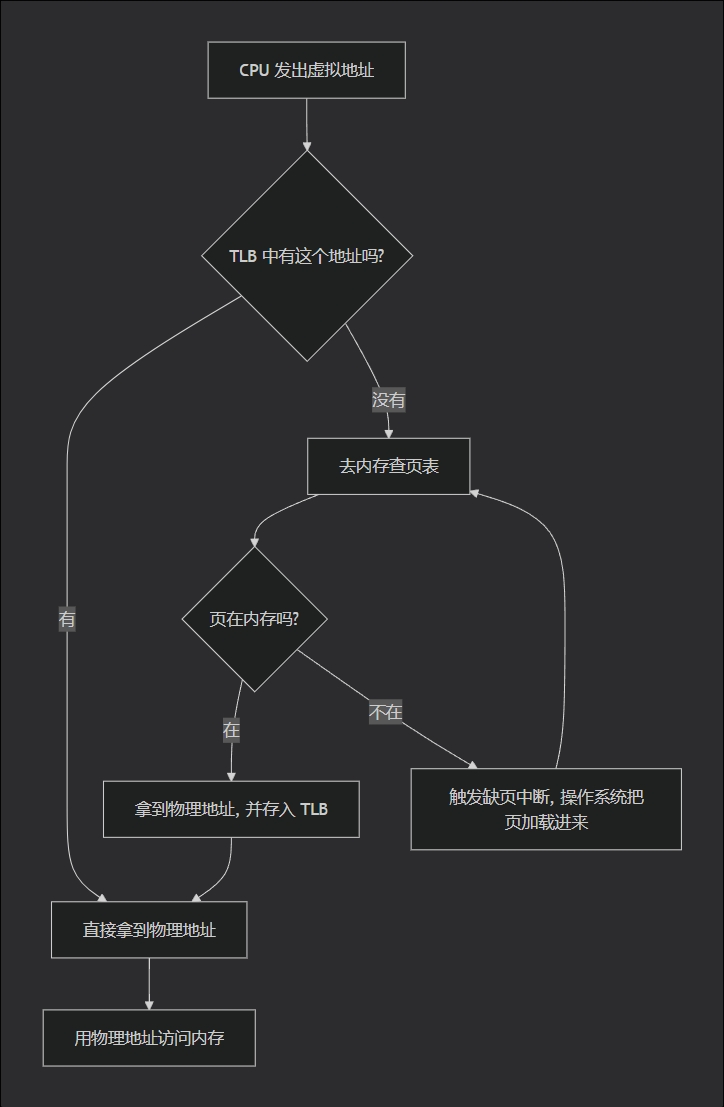
在上下文切换中,寄存器切换是"必须的固定开销",而缓存失效是"造成巨大性能落差的主因"。
1.3线程还有很好的并发性
1.能充分利用多处理器的可并行数量
2.在等待慢速I/O操作结束的同时,程序可执行其他的计算任务
3.计算密集型应用,为了能在多处理器系统上运行,将计算分解到多个线程中实现
4.I/O密集型应用,为了提高性能,将I/O操作重叠。线程可以同时等待不同的I/O操作。
二线程的缺点
1.性能损失
如果计算密集型线程的数量比可用的处理器多,那么可能会有较大的性能损失,这里的性能损失指
的是增加了额外的同步和调度开销,而可用的资源不变。
2.健壮性降低
cpp
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
// 全局共享变量
int shared_counter = 0;
// 每个线程执行的函数
void* increment_unsafe(void* arg) {
int times = *(int*)arg; // 从参数获取循环次数
for (int i = 0; i < times; ++i) {
// 非原子操作:读-改-写
shared_counter = shared_counter + 1;
}
return NULL;
}
int main() {
const int NUM_THREADS = 10;
const int INCREMENTS_PER_THREAD = 100000; // 每个线程10万次
pthread_t threads[NUM_THREADS];
int args[NUM_THREADS];
// 创建线程
for (int i = 0; i < NUM_THREADS; ++i) {
args[i] = INCREMENTS_PER_THREAD;
int ret = pthread_create(&threads[i], NULL, increment_unsafe, &args[i]);
if (ret != 0) {
fprintf(stderr, "创建线程失败: %d\n", ret);
exit(1);
}
}
// 等待所有线程结束
for (int i = 0; i < NUM_THREADS; ++i) {
pthread_join(threads[i], NULL);
}
// 输出结果
int expected = NUM_THREADS * INCREMENTS_PER_THREAD;
printf("期望值: %d\n", expected);
printf("实际值: %d\n", shared_counter);
printf("差值: %d\n", expected - shared_counter);
if (shared_counter != expected) {
printf("⚠️ 线程不安全:数据遭到破坏!\n");
}
return 0;
}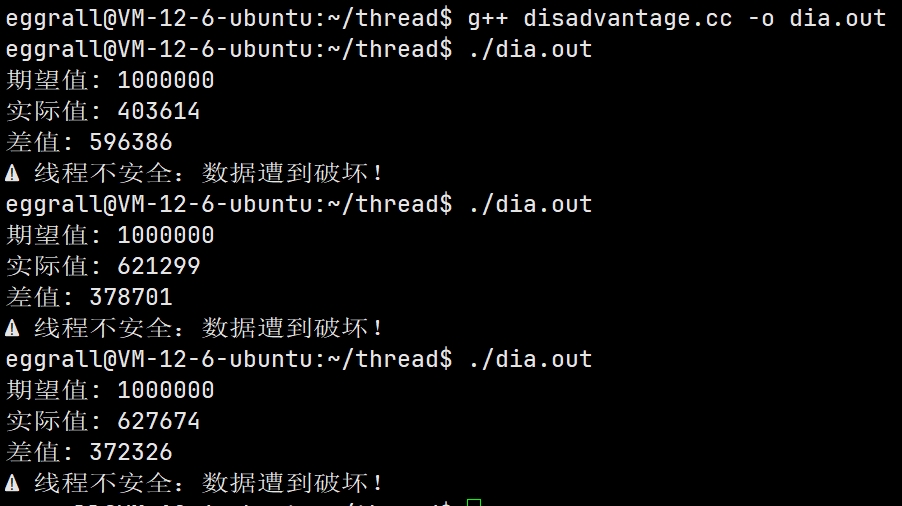
程序每次运行结果不同,且总是小于期望值
cpp
#include <iostream>
#include <pthread.h>
#include <unistd.h>
int main();
void *threadrun(void *args)
{
main();
return nullptr;
}
int main()
{
pthread_t t;
pthread_create(&t, nullptr, threadrun, nullptr);
return 0;
}它会引发无限递归 和栈溢出,最终导致程序崩溃。
在多线程中,重入函数是很常见的。
3.编程难度提高
三线程异常
单个线程如果出现除零,野指针问题导致线程崩溃,进程也会随着崩溃
线程是进程的执行分支,线程出异常,就类似进程出异常 ,进而触发信号机制,终止进程,进程
终止**,该进程内的所有线程也就随即退出**
四线程VS进程
1.进程间具有独立性,线程不独立
2.线程共享地址空间,也就共享进程资源
3.线程共享进程数据,但也拥有自己的一部分"私有"数据:

同一地址空间,因此Text Segment 、Data Segment 都是共享的,如果定义一个函数,在各线程中都可以调用,如果定义一个全局变量,在各线程中都可以访问到,除此之外,各线程还共享以下进程资源和环境:

进程和线程的关系如下图:
之前学习的单进程就是具有一个线程执行流的进程
五结语
综上所述,线程的核心价值集中于轻量化的调度能力与高效的并发处理性能,依托共享进程地址空间的运行机制,线程规避了进程创建与上下文切换的高额开销 ,能够充分释放多核处理器的算力优势,实现I/O操作重叠执行,大幅提升程序并发处理效率,这也是其广泛应用于高并发系统的核心原因。但与此同时,**多线程带来的资源竞争、数据不一致、单线程异常牵连整体进程崩溃等问题,也提升了程序开发与调试的复杂度。**因此,在实际项目开发中,我们不能盲目滥用多线程技术,需要结合业务场景权衡利弊,通过合理的同步机制规避并发风险,最大化发挥线程的轻量化并发优势,在保障程序健壮性与稳定性的前提下,实现系统性能的最优提升。