基于商品评价的评论情感分析与可视化系统项目介绍
Python + SnowNLP + LDA + Hive + Flask
有需要本项目的代码或文档以及全部资源,或者部署调试可以私信博主。

图1 系统首页横幅与项目展示素材
1 项目整体介绍
这个项目围绕"商品评论怎么被看懂"这个问题展开。日常电商平台里,一件商品下面可能有几百条、几千条甚至上万条评价,人工一条条翻看不仅慢,而且很容易被个别极端评论带偏。项目的思路是把评论文本统一收集起来,经过清洗、分词、关键词提取、情感得分计算和主题建模,再把结果做成可以直接浏览的可视化页面。这样既能看总体口碑,也能看不同商品类别的具体关注点。
数据部分包含原始评论 50,785 条,清洗处理后保留有效评论 50,756 条,覆盖平板、手机、水果、洗发水、热水器、蒙牛、衣服、计算机、零食等 9 个类别。每条评论在处理后会形成商品类别、原始评论、清洗文本、分词结果、关键词和情感得分等字段,后续的图表、词云、主题模型和系统页面都围绕这些字段展开。
这套内容不是只停留在一个 Notebook 脚本里,而是把分析结果、入仓脚本和 Web 系统放在同一个项目包中。前面负责数据加工和模型分析,中间通过 Hive、Flume 等脚本体现数据仓库思路,后面再用 Flask 和后台模板把结果展示出来。对于课程设计、毕业设计或者实训项目来说,这种"数据处理 + 文本挖掘 + 大数据入仓 + 系统展示"的组合,整体完成度会比单纯输出几张图更强。
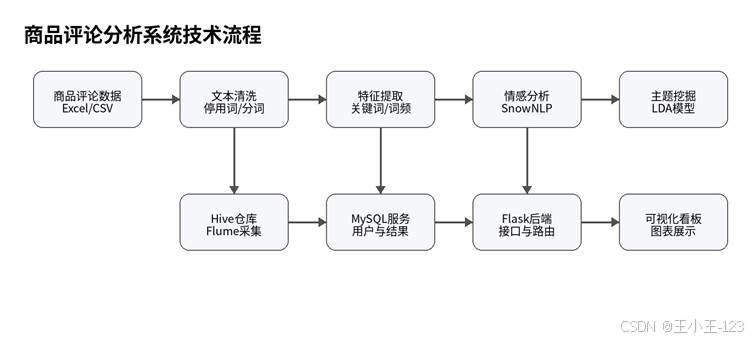
图2 商品评论分析系统技术流程
2 数据处理与分析思路
2.1 评论数据清洗
原始评论里通常会夹杂标点、空白字符、表情符号、英文逗号、特殊控制字符和一些无分析价值的词。如果这些内容直接进入分词和情感分析环节,会影响后续统计结果。项目中先对评论文本做统一规整,保留中文、英文、数字和常见标点,同时把逗号替换成更适合导入 Hive 的中文顿号,减少 CSV 入仓时字段错位的问题。
清洗后再配合停用词表进行分词过滤,去掉"这个、一个、可以、没有"等高频但价值较低的词,保留更能表达商品特征的关键词。处理后的数据继续输出为 Excel 和 CSV 两种格式,一方面方便后续建模复查,另一方面也能直接作为大数据平台和 Web 系统的数据来源。
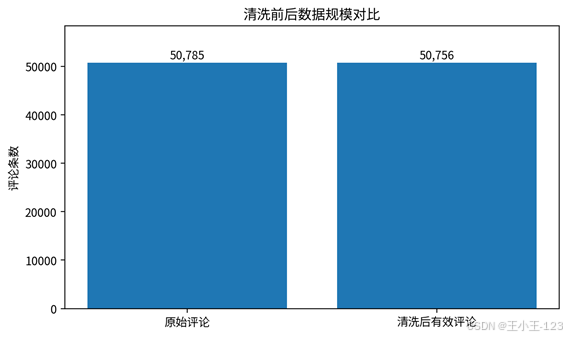
图3 清洗前后数据规模对比
2.2 商品类别与样本分布
从样本分布来看,平板、水果、衣服和洗发水评论数量较多,计算机、手机、蒙牛、零食和热水器数量相对少一些。这样的分布也比较贴近真实项目:不同品类的评论积累速度不完全一致,所以后续分析不能只看总量,还要按类别拆开观察。比如同样是正面评价,手机可能更关注屏幕、续航、信号,水果可能更关注新鲜、口感、包装,洗发水则会集中在香味、控油、发质等体验词上。
项目在可视化结果中没有把所有类别混成一张图,而是给每个类别单独生成词频、关键词词云、负面词云、情感分布和 LDA 页面。这一点比较适合做展示,因为读者进入系统后可以按商品类别逐一查看,也方便后续把某个品类扩展成独立分析模块。
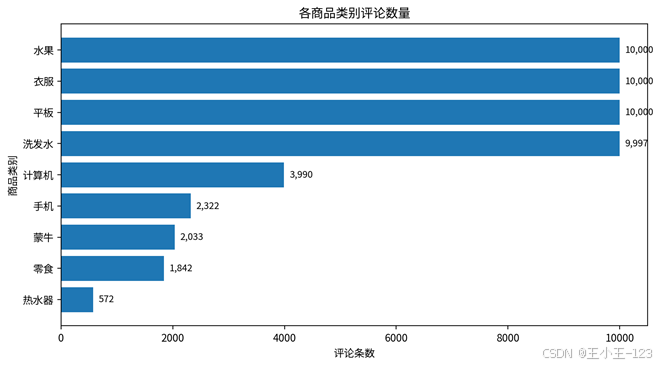
图4 各商品类别评论数量
3 核心功能展示
3.1 评论情感分析
情感分析部分采用 SnowNLP 对中文评论进行情感得分计算,得分越接近 1,说明评论越偏正向;得分越接近 0,则越偏负向。项目中进一步把评论划分为负面、中性和正面三类,便于从业务角度快速理解商品口碑。这样处理之后,系统不仅能告诉我们"评论里出现了什么词",还能进一步判断这些评论大体是在夸产品,还是在反馈问题。
从整体结果看,正负向评论数量比较接近,中性评论占比相对较低。这种结果说明商品评价文本的态度表达比较明显,用户往往会直接写出满意点或不满意点。对于展示页面来说,情感柱状图非常直观,适合放在系统首页或者单个商品类别详情页,用来快速呈现口碑倾向。
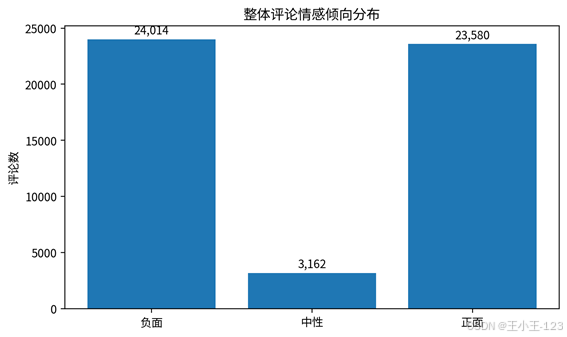
图5 整体评论情感倾向分布
进一步按商品类别拆开后,不同品类之间的情感差异会更加明显。有些类别正面评价比例更高,说明用户对体验、质量或价格更认可;有些类别负向评论更多,往往意味着售后、质量、使用体验、包装运输等环节可能存在集中问题。这里不需要把每一条评论都展开,只要把趋势展示出来,读者就能快速看到这个项目的分析能力。
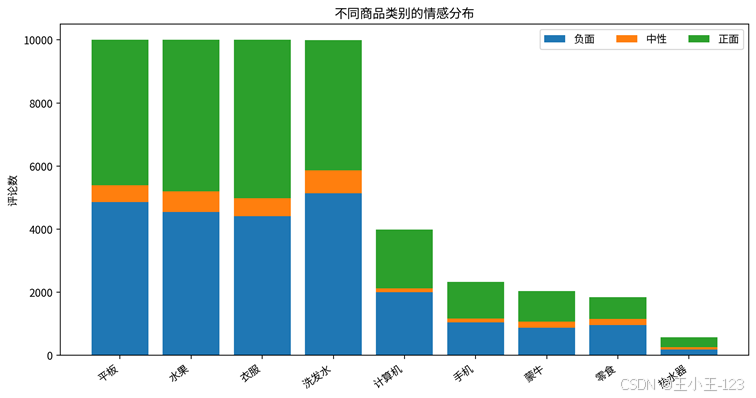
图6 不同商品类别情感分布
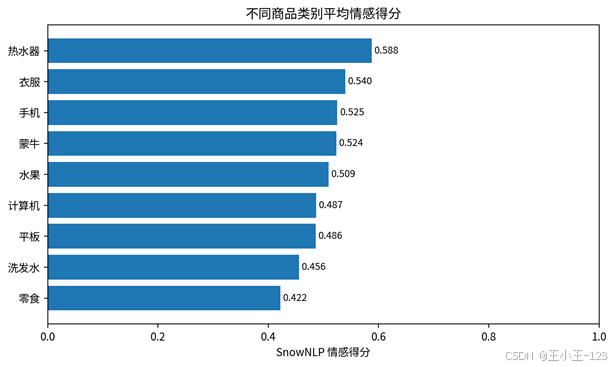
图7 不同商品类别平均情感得分
3.2 高频词统计与关键词词云
高频词统计是评论分析里最直接的一层。项目对每个商品类别分别统计分词结果,并生成词频条形图。条形图适合做"精确展示",能看清某个词出现了多少次;词云图适合做"快速感知",用户不需要读完整表格,就能知道评论主要围绕哪些词展开。两种图结合起来,既有视觉冲击力,也有基本的数据解释力。
从典型品类可以看到,不同商品的关注点并不一样。平板类评论更容易出现"屏幕、质量、京东、不错"等词;手机类评论会出现"电池、信号、铃声、死机、质量"等词;水果类更关注"新鲜、味道、包装、个头"等体验;衣服类则围绕"质量、面料、尺码、颜色、款式"等词展开。这种差异正是文本挖掘的价值:看似都是评论,拆开之后能直接看到品类特征。
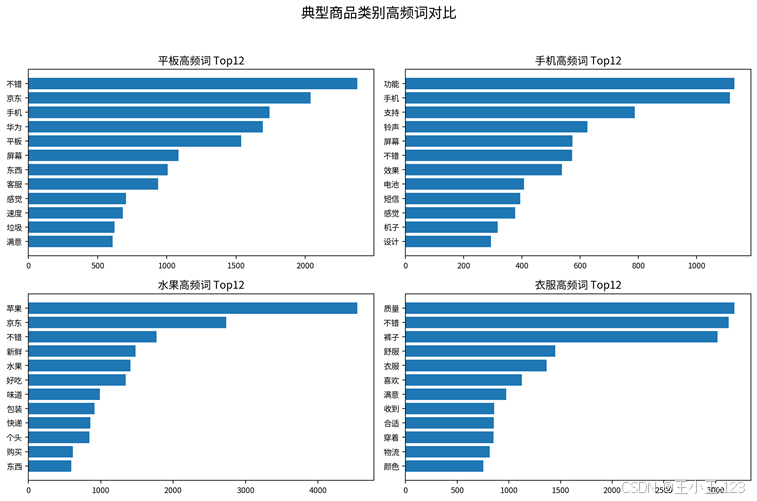
图8 典型商品类别高频词对比
在展示层面,词云图特别适合放在项目介绍中,因为它能让读者快速产生"这个系统真的分析了大量文本"的感受。项目包中已经生成了总评论词云、商品类别评论词云以及各商品类别的关键词词云,页面数量比较丰富,作为学生项目展示很容易形成完整效果。

图9 项目生成的总评论词云

图10 多类别关键词词云组合展示
3.3 负面评论词云
仅仅看正面评价还不够,真正有价值的部分往往藏在负面评论里。项目把低情感得分评论单独筛选出来,再生成负面评论词云,用来观察用户不满意的集中原因。比如手机类负面评论可能围绕"死机、信号、电池、维修、售后"等词展开;平板类可能更关注"质量、屏幕、卡顿、退换"等体验;水果类则可能集中在"不新鲜、坏果、包装、物流"等问题上。
这种模块可以直接服务于商品运营和质量改进:如果一个词在负面词云中反复出现,就说明它不只是个别用户的抱怨,而可能是一个需要重点关注的问题。项目展示时不需要把每条负面评论全部放出来,只保留词云和少量说明,既能体现分析深度,也不会让页面显得过于冗长。

图11 商品负面评论词云组合展示
3.4 LDA 主题挖掘
关键词和词频更多反映"词出现了多少",而 LDA 主题模型更适合观察"评论大概在讨论哪几类话题"。项目使用 Gensim 构建词典和语料库,对每个商品类别分别训练 LDA 模型,并结合主题一致性选择较合适的主题数量。最终通过 pyLDAvis 生成交互式 HTML 页面,可以查看主题之间的距离、主题占比,以及不同主题下的代表词。
从展示效果看,LDA 部分可以作为项目的文本挖掘亮点。比如同样是手机评论,可能会分成外观体验、功能设置、信号通话、故障售后等主题;平板评论可能会分成屏幕体验、购买物流、性能使用、价格评价等主题。相比只做情感分类,LDA 让项目从"好评/差评"进一步走向"为什么好、为什么差"。
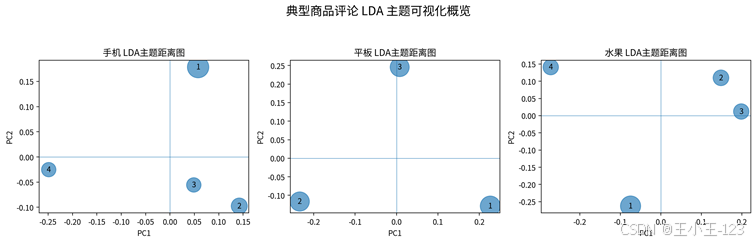
图12 典型商品评论 LDA 主题可视化概览
4 数据入仓与系统实现
4.1 Hive 与 Flume 脚本
项目包里单独保留了脚本文件夹,里面包括 Hive 建表语句、Flume 采集配置和启动脚本。Hive 表设计包含 id、types、comments、sentiment_score 等字段,并采用 ORC 存储。Flume 配置则通过 spooldir 监听本地目录,将清洗后的数据写入 Hive 表中。这样的设计让项目不只是"本地跑一遍图表",而是具备了向大数据平台迁移的基础。
对于实际部署,可以把 Python 处理后的 data.csv 放入指定目录,由 Flume 采集到 Hive,再由后端服务读取统计结果或同步到 MySQL。后续如果评论规模继续扩大,也可以把清洗、分词和情感计算拆成定时任务,形成"数据采集---清洗处理---入仓---可视化展示"的自动化链路。
4.2 Flask 后端与后台页面
Web 系统部分基于 Flask 编写,包含登录、注册、用户信息查询、用户资料修改、密码修改、退出登录等基础接口。数据库连接通过 MysqlHelper 封装,用户表结构保存在 user.sql 中。前端使用 Layui 后台模板,左侧菜单按分析结果分类组织,包括商品 LDA 可视化、商品负面评论词云、商品关键词词云、商品情感分布和商品词频展示。
这种页面结构非常适合做项目演示:用户进入系统后,不需要理解代码细节,只需要点击左侧菜单就能查看不同类别的分析图。每个图表都是提前生成好的 HTML 页面,加载速度快,展示效果也比较稳定。对学生项目而言,能够把算法结果放进后台系统里,是一个很明显的加分点。
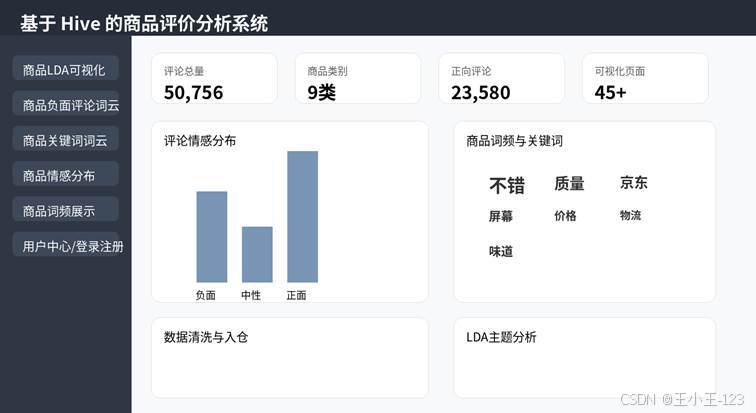
图13 系统界面效果示意图

图14 项目资源结构与核心文件
5 技术路线总结
整个项目的技术路线可以概括为五层:第一层是数据层,主要包括商品评价 Excel、清洗后的 Excel、CSV 文件和停用词库;第二层是文本处理层,完成正则清洗、停用词过滤、分词、关键词提取和词频统计;第三层是模型分析层,包括 SnowNLP 情感得分、Gensim LDA 主题建模和主题可视化;第四层是数据服务层,包括 Hive 入仓、Flume 采集、MySQL 用户数据和 Flask 接口;第五层是展示层,通过后台模板和可视化页面把分析结果呈现出来。
|--------|--------------------------------------|--------------------------|
| 模块 | 实现内容 | 展示价值 |
| 数据处理 | Excel/CSV读取、评论清洗、分词、停用词过滤、有效数据导出 | 把原始评价变成可分析、可入仓、可复用的数据 |
| 情感分析 | 基于 SnowNLP 输出情感得分,并按阈值划分负面、中性、正面 | 快速判断不同商品口碑倾向与问题集中区 |
| 关键词与词频 | TF-IDF关键词、词频统计、词云和条形图展示 | 让用户一眼看到消费者最常提到的卖点和痛点 |
| 主题挖掘 | Gensim LDA建模、主题一致性选择、pyLDAvis交互展示 | 进一步抽取不同类别评论背后的潜在关注主题 |
| 系统呈现 | Flask后端、MySQL用户表、Layui后台模板、HTML可视化页面 | 从算法脚本延伸到可登录、可查看、可管理的系统界面 |
| 数据入仓 | Flume采集、Hive建表、ORC存储、脚本化启动 | 体现大数据场景下的数据沉淀和后续扩展能力 |
如果把这套项目用于论文或课程设计,论文部分可以重点写数据清洗、情感分析、主题模型和系统实现;答辩展示则可以重点打开系统页面、词云图、情感分布图和 LDA 主题图。这样安排比较清晰:论文里讲方法,系统里看效果,资源包里有代码和数据支撑,整体闭环比较完整。
6 项目亮点
第一个亮点是分析维度比较全。项目不是只做一个情感分类,而是同时覆盖评论清洗、关键词提取、词频统计、词云展示、情感得分、负面评论分析和 LDA 主题挖掘,能够从多个角度解释商品评价。
第二个亮点是结果展示比较丰富。每个商品类别都有对应的可视化页面,既可以看总体,也可以看单个类别,适合做系统演示和项目宣传。尤其是词云、条形图和 LDA 页面,视觉效果比较明显,读者不用看太多文字也能理解项目做了什么。
第三个亮点是具备一定工程化思路。项目不仅有 Notebook 分析过程,还保留了 Hive、Flume、MySQL、Flask 和前端页面。即使后期不一定部署完整大数据环境,也能体现数据从本地文件到仓库、再到系统展示的完整路径。

图15 项目生成的商品类别评论词云总览
7 后续可以扩展的方向
后续如果继续完善,可以从三个方向增强。第一是数据来源扩展,把静态数据集升级为电商平台评论采集模块,支持按商品链接、关键词或店铺维度定时抓取。第二是模型升级,在 SnowNLP 情感分析之外,引入面向商品评论的情感词典、BERT 类预训练模型或方面级情感分析,把"差评"进一步拆到价格、物流、包装、质量、售后等方面。第三是系统功能扩展,把图表页面改造成可筛选、可检索、可导出的交互式看板,并增加用户上传评论文件后自动分析的功能。
如果继续往实用方向做,还可以加入商品对比分析、评论预警、差评聚类、关键词趋势变化和自动生成分析报告等功能。这样一来,项目就不只是展示评论结果,而是可以作为电商运营、商品质控和用户反馈分析的小型工具。
每文一语
会用数据说话,也要会把结果展示给别人看;工具用得顺,复杂问题也能一步步变简单。